paper:An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
third-party implementation:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/vovnet.py
存在的问题
DenseNet通过密集连接保留不同感受野的中间特征,在目标检测任务中表现出了良好的性能。虽然特征重用使DenseNet能够通过少量的模型参数和FLOPs产生强大的特征,但用DenseNet骨干网络的检测模型的速度很慢能效也很低。作者发现通过密集连接而线性增加的输入通道,导致了沉重的内存访问成本,从而导致了计算开销和更多的能耗。
本文的创新点
为了解决DenseNet的低效问题,本文提出了一种高效的架构VoVNet,由One-Shot Aggregation(OSA)组成。OSA不仅保留了DenseNet的优势即具有多种感受野的多样性特征,同时通过在最后一个特征图只聚合所有特征一次克服了密集连接的低效问题。基于VoVNet的检测模型与基于DenseNet的检测模型相比,速度快了2x,能耗减少了1.6x - 4.1x。同时与在速度和能耗方面还优于广泛使用的ResNet骨干网络的检测模型。特别是,小目标的检测性能比DenseNet和ResNet得到了显著提升。
方法介绍
Factors of Efficient Network Design
作者首先分析高效网络设计的一些影响因素。当设计高效网络时,许多研究例如MobileNet v1、MobileNet v2、ShuffleNet v1、ShuffleNet v2、Pelee主要关注于使用深度卷积和1x1卷积的bottleneck结构来减少FLOPs和模型大小。但减小FLOPs和模型尺寸并不总是意味着GPU推理时间和能耗的减少。ShuffleNet v2通过实验表明在GPU上比具有相似数量FLOPs的MobileNet v2运行速度更快。《Understanding the limitations of existing energy-efficient design approaches for deep neural networks》这篇文章中指出尽管SqueezeNet的权重数量比AlexNet少50x,但能耗更高。这些现象表明FLOPs和模型尺寸是衡量实用性的间接度量指标,应该重新考虑基于这些指标设计网络。为了构建更高效的网络结构,专注于更实际和更有效的指标,如energy per image和frame per second(FPS),除了FLOPs和模型参数,考虑其它影响能耗和时间消耗的因素非常重要。
Memory Access Cost
第一个因素是内存访问成本memory access cost(MAC)。CNN的主要能耗来源是内存访问而不是计算。具体来说,从DRAM(Dynamic Random Access Memory)访问数据的能耗比计算本文高几个数量级。此外,内存访问的时间占能耗的一大部分甚至可能成为GPU进程的瓶颈。这意味着,即使在相同的计算量和参数量下,不同模型架构的总内存访问次数不同,能耗也会不同。
导致模型尺寸和内存访问数量之间差异的一个原因是中间激活内存占用intermediate activation memory footprint。《Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks》中指出,内存占用取决于filter参数和中间特征图。如果中间特征图很大,即使模型参数相同内存访问成本也会增加。所以,作者将MAC作为网络设计的一个重要因素。计算卷积层MAC如下
![]()
\(k,h,w,c_i,c_o\) 分别表示卷积核大小、输入和输出的高和宽、输入和输出的通道数。
GPU-Computation Efficiency
通过减少FLOPs来提高速度的网络结构是基于每个浮点操作在设备中以相同的速度处理的思想。但当网络部署在GPU上时这种想法是错误的。这是因为GPU的并行处理机制,由于GPU能够同时处理多个浮点操作进程,因此高效的利用其计算能力是非常重要的。我们使用术语GPU-computation efficiency来描述这个概念。
计算的张量越大,GPU的并行计算能力就能更好的被利用。将一个大的卷积操作切分成几个较小的碎片操作是的GPU的计算效率低下,因为更少的计算时并行处理的。这意味着在网络设计中如果behavior function相同,最好用较少的层来构建网络。此外,额外的会带来内核启动和同步kernel launching and synchronization从而导致额外的时间开销。
因此,虽然深度卷积和1x1 convolution bottleneck可以减少FLOPs,但因为采用了额外的1x1卷积对GPU的计算效率是有害的。GPU的计算效率随着模型架构的不同而变化,因为为了验证网络架构的计算效率,作者引入了FLOPs per Second(FLOP/s),它是用总的FLOPs除以实际的GPU推理时间。高的FLOP/s意味着可以更高效的利用GPU。
Proposed Method
Rethinking Dense Connection
聚合所有中间层的密集连接不可避免的会导致低效率,这是因为每一层的输入通道大小随着网络层的逐渐变深而线性增加。由于密集聚合,dense block在FLOPs或参数限制下只能生成少量的特征。换句话说,DenseNet通过密集连接,用特征的数量换特征的质量。尽管从表现来看这种交换是有益的,但从能源和时间的角度看还有一些其它缺点。
首先密集连接会导致较高的内存访问成本。一个卷积层内存访问操作数的下限可以表示为 \(MAC\ge 2\sqrt{\frac{hwB}{k^2} }+\frac{B}{hw} \) 当 \(B=k^2hwc_ic_o\) 是计算量。因为下限基于均值不等式,在固定的计算量或模型参数下,当输入和输出通道相等时MAC最小。密集连接增加了输入通道,而输出通道保持不变,因此每一层的输入和输出通道都不平衡,因此在相同计算量或参数的模型中DenseNet的MAC较高并消耗更多的能源和时间。
其次,密集连接采用了bottleneck结构,降低了GPU并行计算的效率。当模型比较大时,线性增加的输入大小是很严重的问题,因为它使整体的计算量相对深度呈二次方增长的关系。为了抑制这种增长,DenseNet采用了bottleneck结构,增加了一个1x1卷积来保持3x3卷积输入大小不变。尽管这样可以减少FLOPs和参数,但损害了GPU并行计算的效率。Bottleneck结构将一个3x3卷积分解成两个更小的层,带来了更多的sequential计算,降低了推理速度。
由于这些缺点,DenseNet在能源和时间方面变得低效。为了提高效率,作者首先研究了网络训练完后密集连接时如何聚合特征的。具体通过计算每一层输入权重的归一化L1范数来说明密集连接的连通性。这些值表明了前一层对相应层的标准化影响。如图2(top)所示

在Dense block3中,对角线附近的红框说明中间层上的聚合是活跃的。但是在分类层,只使用了一小部分的中间特征。相反在Dense block1中,transition layer很好地聚合了其大部分输入特征,而中间层则不能。
根据观察结果,作者假设中间层的聚合强度与最终层的聚合强度呈负相关,如果中间层的密集连接导致来自每一层的特征之间有相关性这种假设就是正确的。这意味着密集连接使靠后的中间层产生更好的特征,但与来自前面层的特征比较相似。在这种情况下,最后一层不需要学习聚合这两个特性,因为它们表示冗余的信息。因此靠前的中间层对最后一层的影响变小。
由于所有的中间层都被聚合来得到最后一层的特征。因此中间层的特征之间最好是互补的或相关性较小的。因此我们拓展我们的假设,即中间层的密集连接相对成本的影响较小。为了验证这个假设,我们设计了一个新的模块,它只在每个block的最后一层聚合中间特征。
One-Shot Aggregation
OSA模块如图1(b)所示,每个卷积层通过双向连接。一个是连接到后续层来得到更大感受野的特征,另一个是只在最后一层聚合一次。和DenseNet的区别在于每一层的输出没有被concat到后续所有层,从而使中间层的输入大小不变。

为了验证我们的假设,即中间层的聚集强度与最终层的聚集强度呈负相关,并且密集连接是冗余的,作者在OSA模块上进行了实验。作者设计了和DenseNet-40中密集连接相似参数和计算量的OSA模块。首先研究了OSA module和dense block层数相同的情况(12层)如图2(middle)所示,由于每个卷积层的输入变小了,输出比dense block更大。可以看到,由于中间层上的聚合被去掉,最终层上的聚合的强度更大了。
此外,OSA过渡层的权重和DenseNet的形式不同:浅层特征更多的聚合在过渡层。由于深层特征对过渡层的影响不大,我们可以减少层数又不带来很大的影响。所以作者将OSA重新配置为5层每层43个通道如图2(bottom)所示。令人惊讶的是,使用这个模块我们得到了5.44%的error rate,和DenseNet-40(5.24%)相似。这表明通过密集连接得到的中间特征的效果并没有预期的好。
尽管带有OSA模块的网络在CIFAR-10上的性能略有下降,这并不意味着它在检测任务上的表现就不好。它比dense block的MAC要少的多,根据式(1),用5层43通道的OSA模块替换DenseNet-40中的dense block,MAC将从3.7M减少到2.5M。这是因为OSA中间层具有相同大小的输入和输出,从而使MAC的值到lower boundary。这意味着如果MAC是能源和时间消耗的主要因素,我们可以构建更快更节能的网络。具体来说,由于检测要求比分类更高的分辨率,中间层的内存占用将变得更大,MAC将能更适当的反映能源和时间的消耗。
此外,OSA还提高了GPU的计算效率。OSA模块的中间层的输入大小是常量,因此就不需要额外的1x1卷积来降维。而且由于OSA聚合了浅层特征,需要的层数也更少。
Configuration of VoVNet
由于OSA模块的多样化特征表示和高效,我们可以通过叠加少量模块来构建精度高、速度快的VoVNet。基于图2中浅层特征更多被聚合的事实,我们可以用比DenseNet数量更少通道数更多的卷积来构建OSA module。作者设计了两种VoVNet:轻量的VoVNet-27-slim,以及大尺寸的VoVNet-39/57。VoVNet包含一个stem block其中有3层卷积,以及4个stage的OSA module最终输出stride=32。一个OSA module包含5个卷积层。跨stage时特征图通过stride=2的3x3 max pooling降采样。VoVNet-39/57在第4、5阶段有更多的OSA模块,降采样在最后一个模块中进行。
由于高层的语义信息在目标检测任务中非常重要,我们逐渐增加高层特征的比例,即逐渐增加特征的通道数。VoVNet的具体结构如表1所示

代码解析
这里以timm中的实现为例,VoVNet有多个stage构成,每个stage又包含多个osa block,一个osa block又包含多个卷积层,vovnet-39a的结构参数如下
vovnet39a=dict(
stem_chs=[64, 64, 128],
stage_conv_chs=[128, 160, 192, 224],
stage_out_chs=[256, 512, 768, 1024],
layer_per_block=5,
block_per_stage=[1, 1, 2, 2],
residual=False,
depthwise=False,
attn='',
)
ese_vovnet39b=dict(
stem_chs=[64, 64, 128],
stage_conv_chs=[128, 160, 192, 224],
stage_out_chs=[256, 512, 768, 1024],
layer_per_block=5,
block_per_stage=[1, 1, 2, 2],
residual=True,
depthwise=False,
attn='ese',
),'a'和'b'的区别在于每个osa block是否有像ResNet一样的shortcut,即residual=True,以及是否添加注意力模块。
一个完整的osa block如图1(b)所示,代码如下
class OsaBlock(nn.Module):
def __init__(
self, in_chs, mid_chs, out_chs, layer_per_block, residual=False,
depthwise=False, attn='', norm_layer=BatchNormAct2d, act_layer=nn.ReLU, drop_path=None):
super(OsaBlock, self).__init__()
self.residual = residual
self.depthwise = depthwise
conv_kwargs = dict(norm_layer=norm_layer, act_layer=act_layer)
next_in_chs = in_chs
if self.depthwise and next_in_chs != mid_chs:
assert not residual
self.conv_reduction = ConvNormAct(next_in_chs, mid_chs, 1, **conv_kwargs)
else:
self.conv_reduction = None
mid_convs = []
for i in range(layer_per_block):
if self.depthwise:
conv = SeparableConvNormAct(mid_chs, mid_chs, **conv_kwargs)
else:
conv = ConvNormAct(next_in_chs, mid_chs, 3, **conv_kwargs)
next_in_chs = mid_chs
mid_convs.append(conv)
self.conv_mid = SequentialAppendList(*mid_convs)
# feature aggregation
next_in_chs = in_chs + layer_per_block * mid_chs
self.conv_concat = ConvNormAct(next_in_chs, out_chs, **conv_kwargs)
self.attn = create_attn(attn, out_chs) if attn else None
self.drop_path = drop_path
def forward(self, x):
output = [x]
if self.conv_reduction is not None:
x = self.conv_reduction(x)
x = self.conv_mid(x, output)
x = self.conv_concat(x)
if self.attn is not None:
x = self.attn(x)
if self.drop_path is not None:
x = self.drop_path(x)
if self.residual:
x = x + output[0]
return x其中主要实现在self.conv_mid,SequentialAppendList实现如下,可以看到将每一层的输出都保存在concat_list里,最后一层将所有层的输出concat起来。在上面的self.conv_concat用1x1卷积进行降维。
class SequentialAppendList(nn.Sequential):
def __init__(self, *args):
super(SequentialAppendList, self).__init__(*args)
def forward(self, x: torch.Tensor, concat_list: List[torch.Tensor]) -> torch.Tensor:
for i, module in enumerate(self):
if i == 0:
concat_list.append(module(x))
else:
concat_list.append(module(concat_list[-1]))
x = torch.cat(concat_list, dim=1)
return x实验结果
用VoVNet-27-slim替换检测模型DSOD原本的backbone DenseNet-67,并与其它两个轻量检测模型的对别如下

计算和能源效率的对比如下
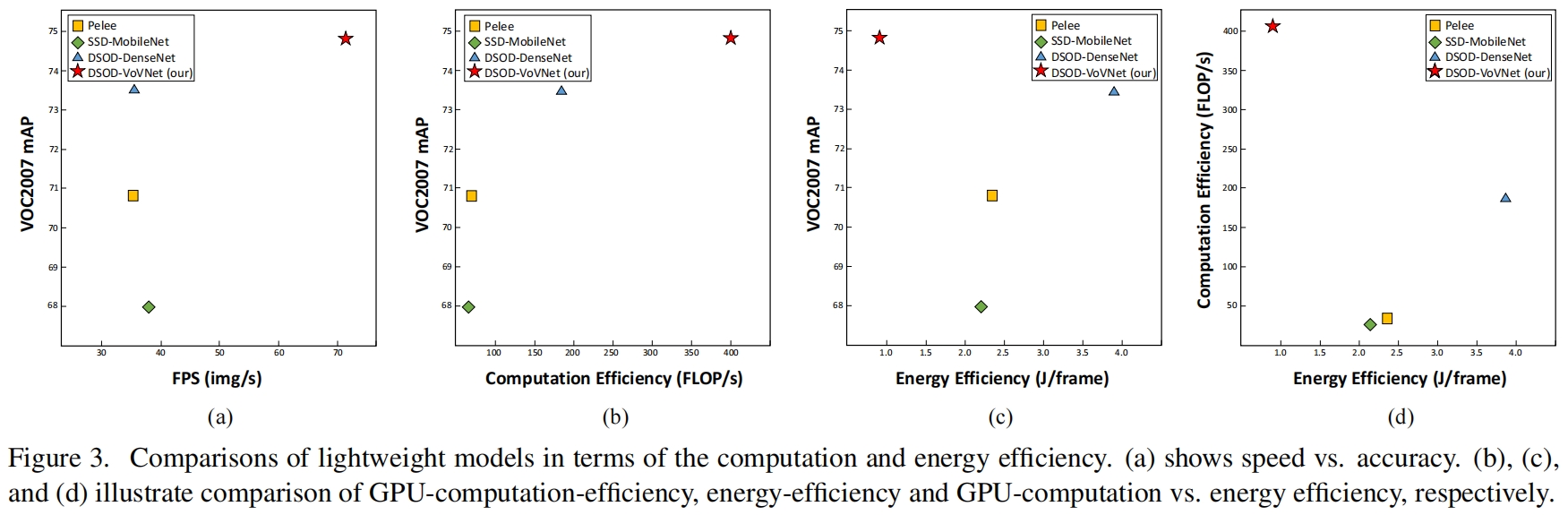
可以看到,VoVNet-27-slim的DSOD不仅取得了最高的mAP,同时在计算、能耗、速度方面都是最优的。
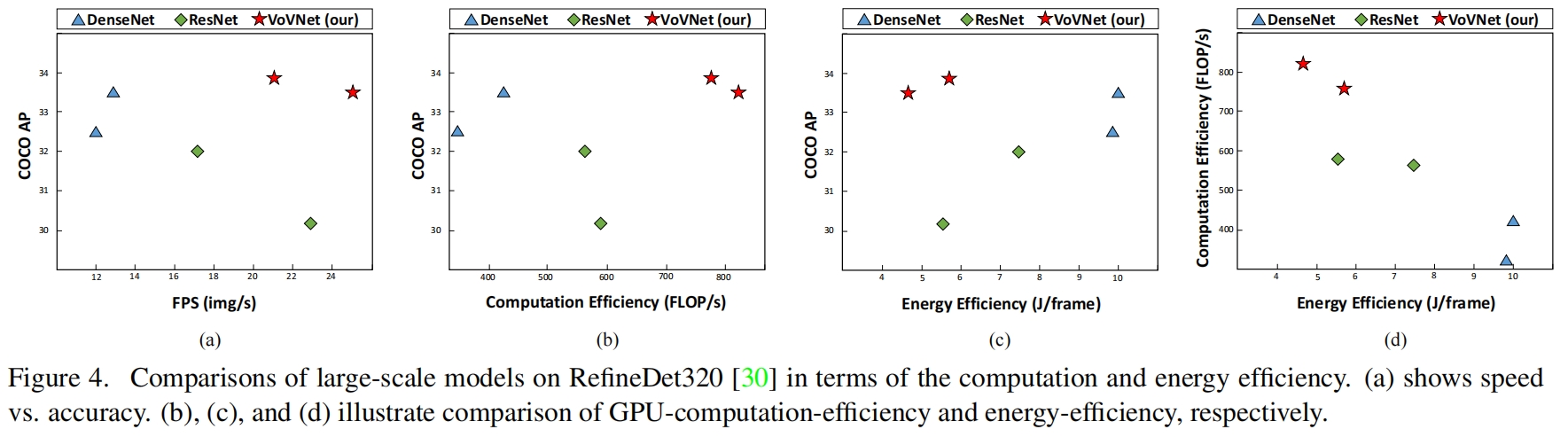
作者又比较了大型VoVNet的效果,检测模型用当时SOTA的RefineDet,backbone分别用VoVNet-39和VoVNet-57,在COCO上的精度对比如下

速度、能耗对比如下