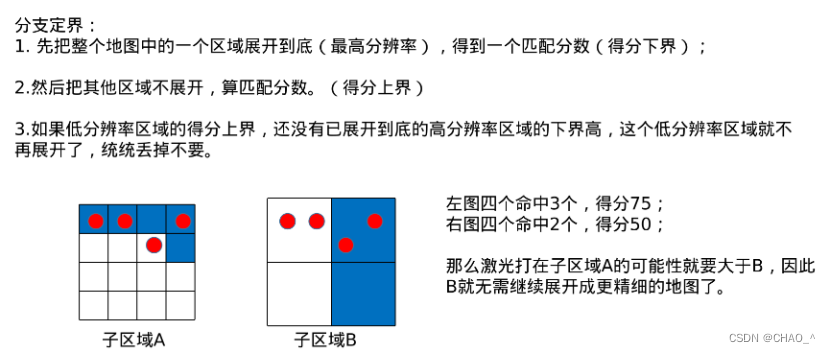
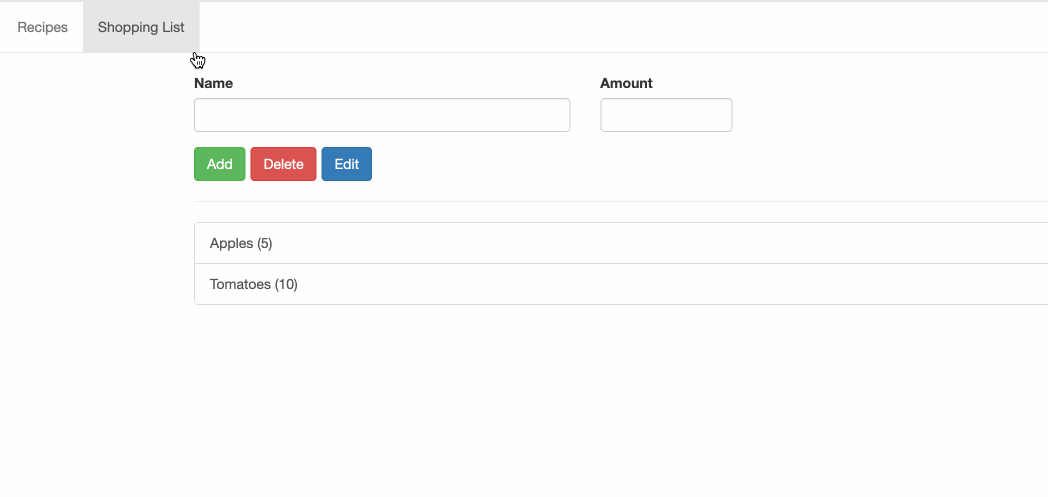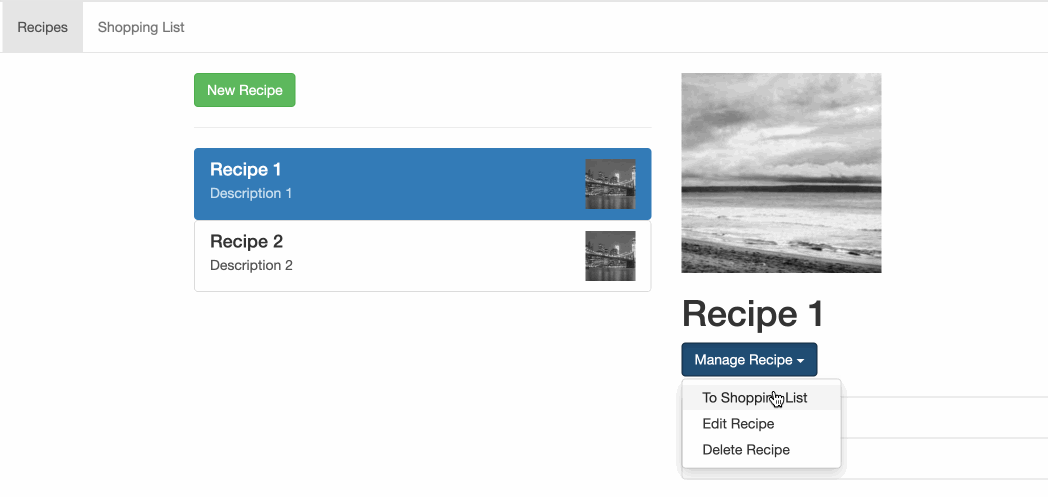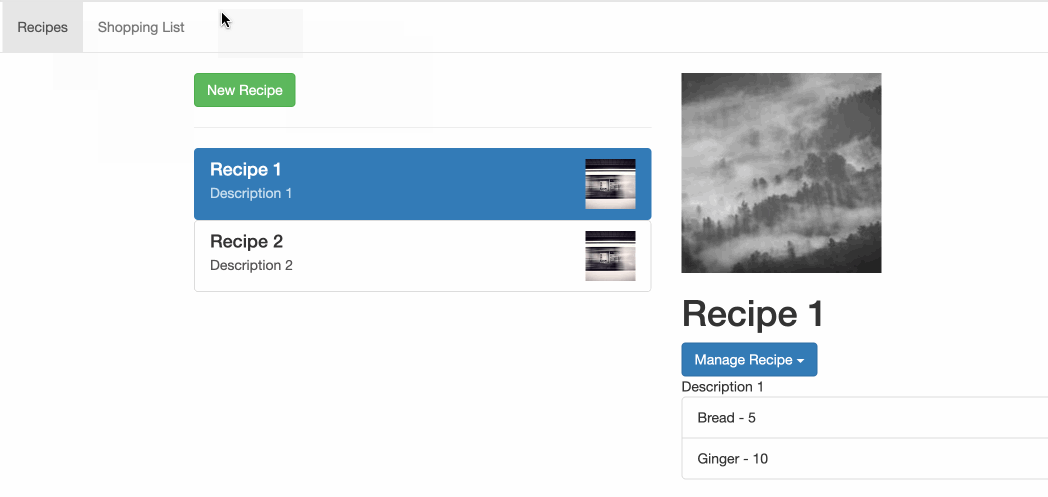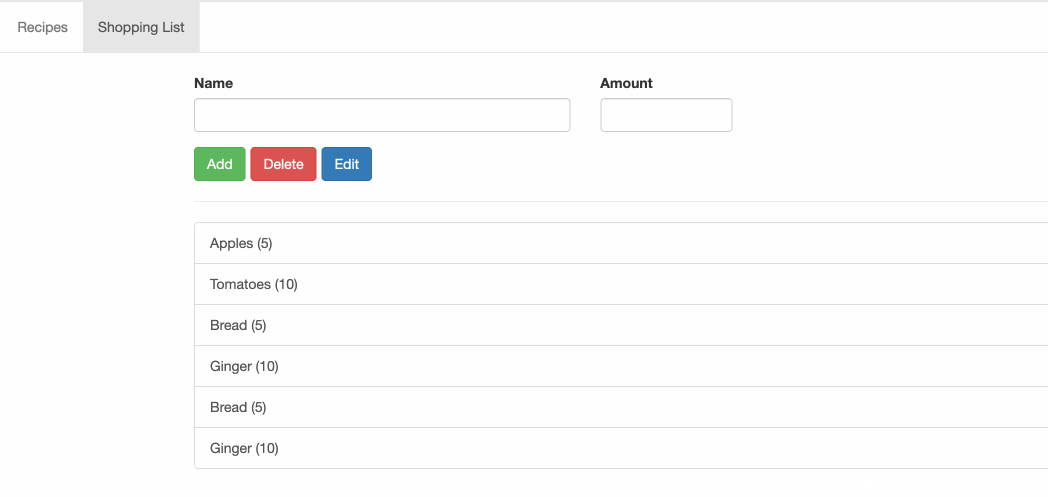
【框架地址】
https://github.com/WongKinYiu/yolov9
【yolov9简介】
在目标检测领域,YOLOv9 实现了一代更比一代强,利用新架构和方法让传统卷积在参数利用率方面胜过了深度卷积。
继 2023 年 1 月 正式发布一年多以后,YOLOv9 终于来了!
我们知道,YOLO 是一种基于图像全局信息进行预测的目标检测系统。自 2015 年 Joseph Redmon、Ali Farhadi 等人提出初代模型以来,领域内的研究者们已经对 YOLO 进行了多次更新迭代,模型性能越来越强大。
此次,YOLOv9 由中国台湾 Academia Sinica、台北科技大学等机构联合开发,相关的论文《Learning What You Want to Learn Using Programmable Gradient Information 》已经放出。

论文地址:https://arxiv.org/pdf/2402.13616.pdf
GitHub 地址:https://github.com/WongKinYiu/yolov9
如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。
因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。
研究者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。
此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。
研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与基于深度卷积开发的 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。
对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。下图 1 展示了一些比较结果。
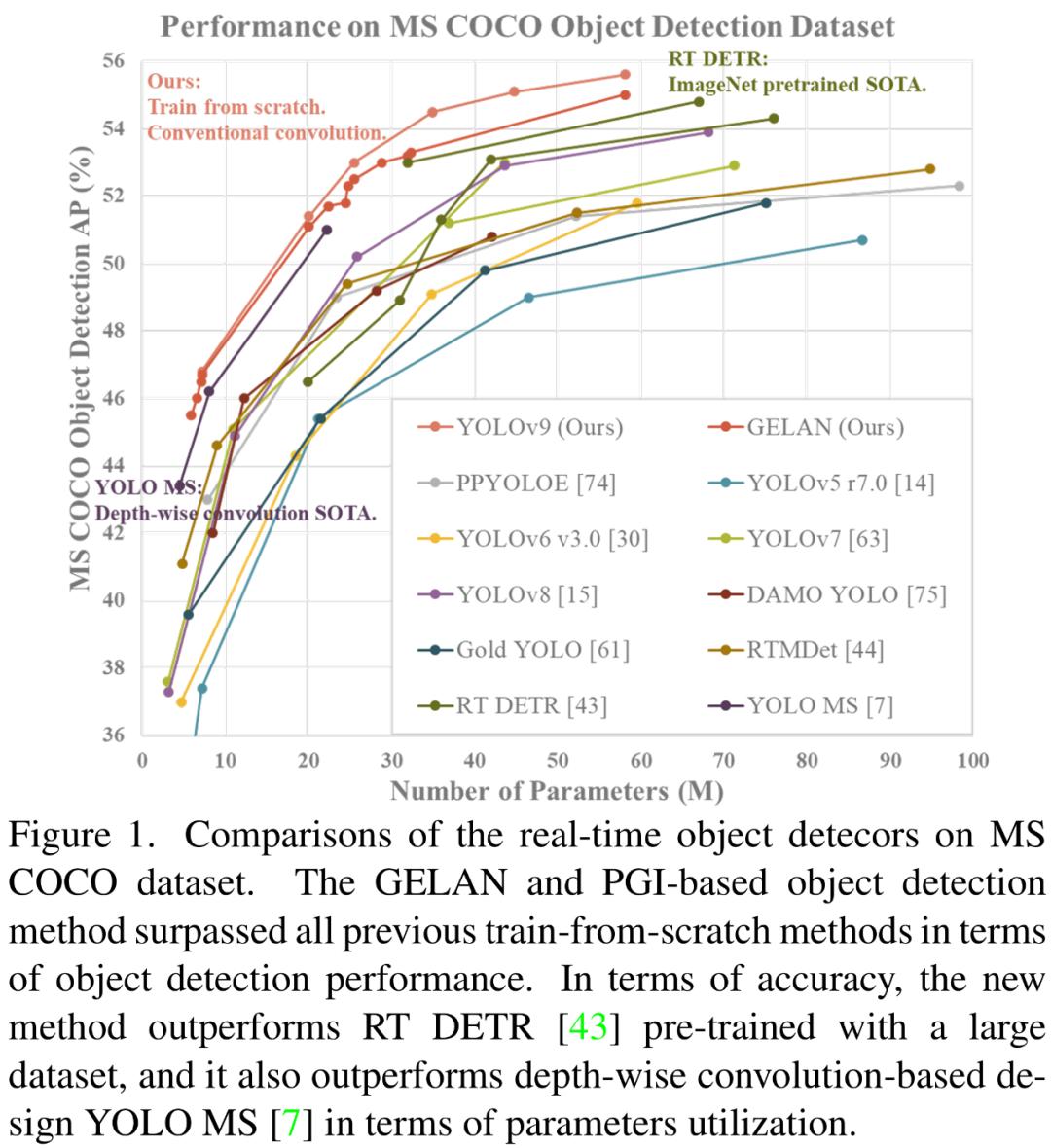
对于新发布的 YOLOv9,曾参与开发了 YOLOv7、YOLOv4、Scaled-YOLOv4 和 DPT 的 Alexey Bochkovskiy 给予了高度评价,表示 YOLOv9 优于任何基于卷积或 transformer 的目标检测器。
【效果演示】
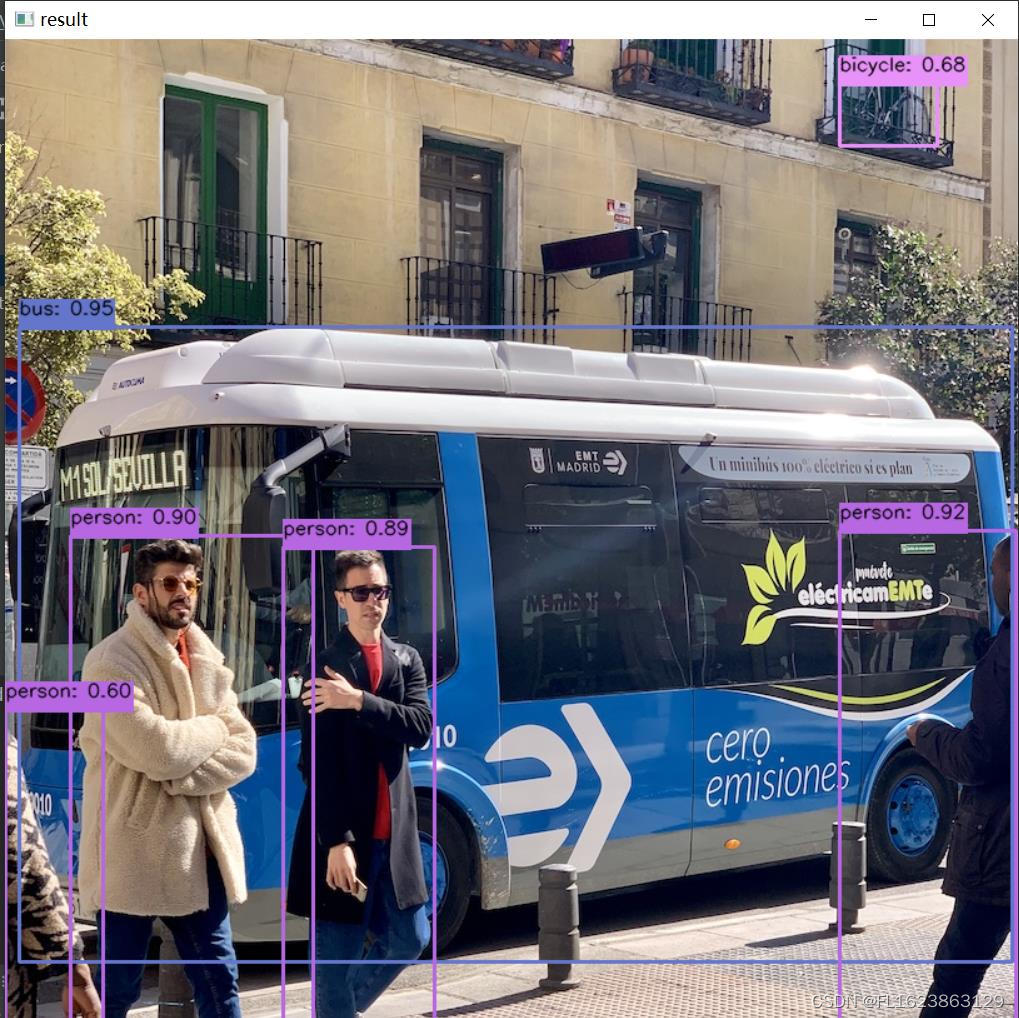
【代码演示】
from Yolov9Onnx import *
weight_path = "weights/yolov9-c.onnx"
image = cv2.imread("images/bus.jpg")
detector = Yolov9Onnx(model_path=f"{weight_path}", names=Yolov9Onnx.load_labels('labels.txt'))
detections = detector.inference_image(image)
detector.draw_image(image, detections=detections)
cv2.imshow("result", image)
cv2.waitKey(0)【视频演示】
https://www.bilibili.com/video/BV14C411x7NK/
【完整演示代码下载】
https://download.csdn.net/download/FL1623863129/88870739
【参考文献】
[1] https://www.thepaper.cn/newsDetail_forward_26439722