用解析器解析出数据后,接下来就是存储数据了。数据的存储有多种多样,其中最简单的一种是将数据直接保存为文本文件,如TXT、JSON、CSV等。这里就介绍将数据直接保存为文本文件。
目录
一、Python存储数据的方法
1、 文件读取
2、 文件写入
3、文件复制
4、文件读写模式
二、TXT文本文件存储
三、JSON文件存储
1、对象和数组
2、读取JSON
3、输出JSON
四、CSV文件存储
1、写入
2、读取
一、Python存储数据的方法
在Python中有一个内置的方法--open方法可以将数据进行存储、读写,使用open方法操作文件就像把大象塞进冰箱一样, 可以分三步走,一是打开文件,二是操作文件,三是关闭文件。
1、 文件读取
- f=open(测试1.txt,mode='r,encoding=utf-8’) 读取指定位置的文件,文件编码为utf-8
- f.read() 读取文件的所有内容
- f.readline() 读取文件的一行数据
- f.readlines() 从文件中一次读取所有行到一个列表中
示例如下:
# 打开文件,指定文件位置,进行读取操作,采用utf-8编码
# f = open(r'D:\Python Files\Spider\文件操作\abc.txt', mode='r', encoding='utf-8')
# 读取文件所有数据
txt = f.read()
# 读取文件的一行数据
txt = f.readline()
print(txt, end='')
# 通过循环的方式,读取文件的每一行数据可以读取完文件的所有数据等于read方法
while txt:
txt = f.readline()
print(txt, end='')
# 从一个文件中一次读取所有行到一个列表中。
txt = f.readlines()
print(txt)
# 关闭文件
f.close()
print(f.closed)但是由于每次采用open方法需要手动的写close方法来关闭文件,如果不关闭文件容易出现文件数据丢失等问题。所以,python中有一个with方法,对文件操作完成后,会自动关闭文件。示例如下:
#输入文件路径,操作方法和编码方式,将其句柄赋给f,通过f来对文件进行操作,操作完后会自动关闭文件
with open('abc.txt', 'r', encoding='utf-8') as f:
txt = f.read()
print(f.closed)2、 文件写入
- f=open(‘测试1.txt',mode=w',encoding='utf-8') 指定文件的存储位置,文件编码为utf-8
- f.write(‘字符串’) 给文件写入字符串数据
- f.writelines(‘列表’) 给文件写入列表数据
示例如下:
s = '今天天气真好!'
l = ['a', 'b', 'c']
with open('测试2.txt', 'w', encoding='utf-8') as f:
f.write(s)
f.writelines(l)3、文件复制
现在,我们已经了解了文件的读取与写入,结合这两种办法可以进行文件复制。首先我们指定文件读取的位置和写入文件的存储位置,然后将读取的文件的数据写入指定存储文件的位置。这样,就实现了文件的复制。
示例代码如下:
复制文件
f1 = open('abc.txt', 'r', encoding='utf-8')
f2 = open('abc1.txt', 'w', encoding='utf-8')
f2.writelines(f1.readlines())
f1.close()
f2.close()4、文件读写模式
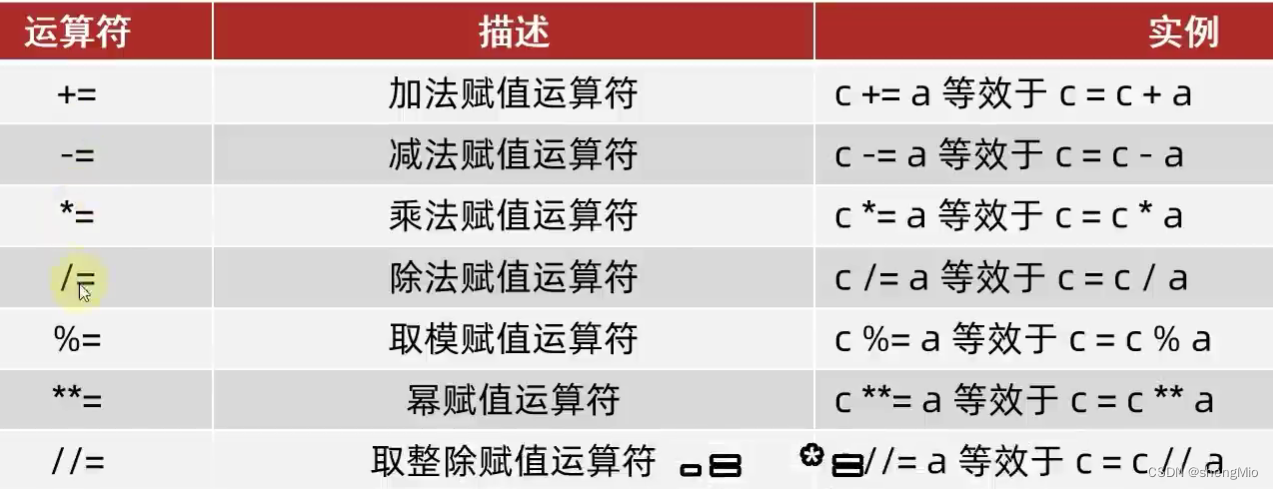
在使用open方法或者with方法的时候,需要传入一个参数来说明对文件的操作模式。存在各种形式的操作模式,每种操作模式的功能不同。下图介绍所有参数的操作模式:

二、TXT文本文件存储
将数据保存为TXT文件的操作非常简单,而且TXT文本几乎兼容任何平台,但不利于检索。如果对检索和数据结构的要求不高,追求方便的话就可以采用TXT文本存储。在将数据写入的时候,在指定文件的位置的时候,以txt做文件的后缀名,即可将数据以txt的形式存储。示例如下:
s = '今天天气真好!'
l = ['a', 'b', 'c']
with open('测试2.txt', 'w', encoding='utf-8') as f:
f.write(s)
f.writelines(l)这里将字符串信息和列表信息都以txt形式存储的测试2文件中,指定以utf-8的形式进行编码。
三、JSON文件存储
JSON,也就是JavaScript对象标记,通过对象和数组的组合来表示数据,构造简洁、结构化程度非常高,是一种轻量级的数据交换格式。
1、对象和数组
在JavaScript 语言中,一切皆为对象,因此任何支持的数据类型都可以通过 JSON 表示,例如字符串、数字、对象、数组等。其中对象和数组是比较特殊且常用的两种类型,下面简要介绍一下这两者。
对象在JavaScript 中是指用花括号{}包围起来的内容,数据结构是 {key1: value1, key2:value2,…}这种键值对结构。在面向对象的语言中,key表示对象的属性、value 表示属性对应的值,前者可以使用整数和字符串表示,后者可以是任意类型。
数组在 JavaScript 中是指用方括号[]包围起来的内容,数据结构是 ["java","javascript","vb",…]这种索引结构。在JavaScript 中,数组是一种比较特殊的数据类型,因为它也可以像对象那样使用键值对结构,但还是索引结构用得更多。同样,它的值可以是任意类型。所以,一个 JSON 对象可以写为如下形式:
[{
"name": "Bob",
"gender": "male",
"birthday": "1992-10-18"
},{
"name": "Selina",
"gender": "female",
"birthday": "1995-10-18"
}]由[ ]包围的内容相当于数组,数组中的每个元素都可以是任意类型,这个实例中的元素是对象,由{} 包围。JSON 可以由以上两种形式自由组合而成,能够嵌套无限次,并且结构清晰,是数据交换的极佳实现方式。
2、读取JSON
Python为我们提供了简易的JSON库,用来实现JSON文件的读写操作,可以调用loads方法将JSON文本字符串转为JSON对象。实际上,JSON对象就是Python中列表和字典的嵌套与组合。反过来,我们可以通过dumps方法将JSON对象转为文本字符串。
示例代码如下:
str = '''
[{
"name": "Bob",
"gender": "male",
"birthday": "1992-10-18"
},{
"name": "Selina",
"gender": "female",
"birthday": "1995-10-18"
}]
'''
import json
print(type(str))
data = json.loads(str)
print(data)
print(type(data))3、输出JSON
可以调用dumps方法将JSON对象转化为字符串,然后调用文件的write方法将字符串写入文本。
示例代码如下:
import json
data = [
{
'name':'Bob',
'gender':'male',
'birthday':'1970-01-01'
}
]
with open('data.json', 'w',encoding='utf-8') as f:
f.write(json.dumps(data))如果JSON对象中存在中文, 中文字符会被编码成Unicode字符。想要不将中文自动编码,直接输出中文,只需将参数ensure_ascii设置为False即可。示例代码如下:
import json
data = [
{
'name':'Bob',
'gender':'male',
'birthday':'1970-01-01'
}
]
with open('data.json', 'w',encoding='utf-8') as f:
f.write(json.dumps(data,ensure_ascii=False))四、CSV文件存储
CSV,逗号分割直或字符分割直,以纯文本的形式存储表格数据,相当于一个结构化表的纯文本形式。它不具备Excel中的数值、公式和格式等内容,就是以特定字符作为分隔符纯文本,结构简单清晰。
1、写入
在将数据写入的时候,在指定文件的位置的时候,以csv做文件的后缀名,即可将数据以csv的形式存储。
示例代码如下:
import csv
with open('data.csv', 'w') as csvfile:
wr = csv.writer(csvfile)
wr.writerow(['id','name','age'])
wr.writerow(['101','Mike','21'])
wr.writerow(['102', 'May', '22'])
wr.writerow(['103', 'Zang', '24'])结果如下:
id,name,age
101,Mike,21
102,May,22
103,Zang,24写入csv文件的文本默认以逗号分隔每条记录,每调用writerow方法是写入一行数据,如果想修改列与列之间的分隔符,可以传入delimiter参数。其代码如下:
import csv
with open('data.csv', 'w') as csvfile:
wr = csv.writer(csvfile,delimiter=' ')
wr.writerow(['id','name','age'])
wr.writerow(['101','Mike','21'])
wr.writerow(['102', 'May', '22'])
wr.writerow(['103', 'Zang', '24'])结果如下:
id name age
101 Mike 21
102 May 22
103 Zang 24还可以使用writerows方法同时写入多行,此时参数需要传入二维列表。示例代码如下:
import csv
with open('data.csv', 'w') as csvfile:
wr = csv.writer(csvfile)
wr.writerow(['id','name','age'])
wr.writerows([['101','Mike',21],['102', 'May', 22],['103', 'Zang', 24]])此外,爬取爬取的数据大都是结构化数据,这里一般用字典来表示。下面就尝试一下用字典来写入,示例代码如下:
import csv
with open('data.csv', 'w') as csvfile:
fieldnames = ['id', 'name', 'age']
wr = csv.DictWriter(csvfile, fieldnames=fieldnames)
wr.writeheader()
wr.writerow({'id':'101','name':'Mike','age':21})
wr.writerow({'id': '102', 'name': 'May', 'age': 32})
wr.writerow({'id': '103', 'name': 'Zang', 'age': 24})
2、读取
读取的时候,我们需要通过遍历列表的方式来读取CSV的内容。因为reader方法是将CSV中的内容每一行以列表的方式读出,如果有中文需要制定编码方式。示例代码如下:
import csv
with open('data.csv', 'r', encoding='utf-8') as csvfile:
r = csv.reader(csvfile)
for row in r:
print(row)结果如下:
['id', 'name', 'age']
[]
['101', 'Mike', '21']
[]
['102', 'May', '32']
[]
['103', 'Zang', '24']
[]