参考:论文英文题目:Correction of uneven illumination in color microscopic image based on fully convolutional network
参考论文链接:https://opg.optica.org/oe/fulltext.cfm?uri=oe-29-18-28503&id=457387
在做显微图像相关任务是,遇到由于显微光源或者光学系统孔阑造成的图像局部阴影问题,也可称作图像渐晕。为了校正这类图像问题,看了一些相关的论文。传统方法的校正总是不太理想颜色偏移啊之类的问题,某类算法可能就针对一定领域,像暗场的光照校正与明场的光照校正方法和原理就完全不同,一般就是估计光照背景,暗场是减去光照背景,明场就是除光照背景。所以就想试试深度学习的方法,有些模型不是端到端的,处理起来还是比较麻烦,接下来看看这个端到端的模型。
图像校正在深度学习领域本质上还是类似于风格迁移。在训练时将调整好的图像作为参考,给模型输入原图让模型去学习这类校正过程。
论文模型
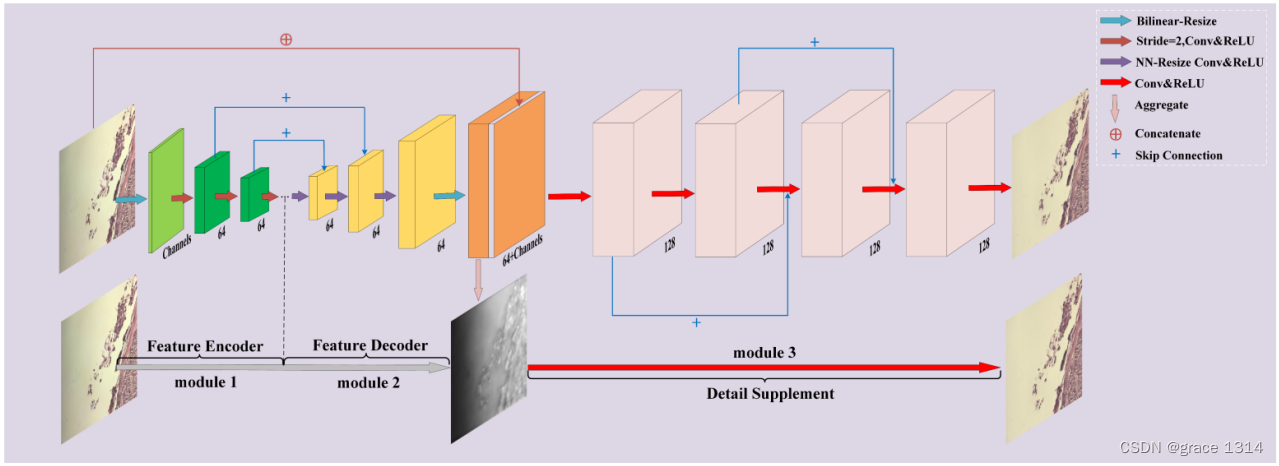
论文模型总体上来说很简单,论文中说是3部。特征编码,特征解码,细节补充。本质就是unet+带残差结构的FCN。
但论文这里对UNet的具体结构进行了改进:
1.图像在输出后模型后采用双线性插值将原始图像缩放到特定大小
2.下采样没有用池化层,而是选择用步长为2的卷积直接将特征图尺寸减半。标准Unet是卷积,relu,在池化下采样,这种结构对于不均匀光照成像有一些缺陷。例如,它使 标准U-Net缺乏全局颜色信息,这导致生成的图像颜色不一致。减少了网络层数并提高了网 络效率。
3.编码也就是下采样阶段,卷积后得到的feturemap通道数没有增加,标准Unet会增加。
4.解码也就是上采样阶段,没有用标准Unet的反卷积上采样,因为通过反卷积重建的高分辨率特征通常 会有“不均匀重叠”,导致在后来重构的图像中出现高频棋盘格伪影或低频伪影。所以这里采用最近邻插值的方法进行上采样,后卷积,避免图像边界的伪影。NN调整大小卷积(最近邻插值与相同卷积)在防止图像伪影方面取得了最佳效果。最重要的是,NN调整大小卷积在保持瓶颈层传递的照明信息方面表现更佳,这被认为有助于预测图像照明分布。
5.在上采样到与输入图像大小一致的featuremap后,来了与原图来了一个跳过卷积。不同于U-Net,我们提出方法中的跳过连接使得特征解码器 模块中的特征图和特征编码器模块中相应位置的特征图(通过ReLU激活)直接相加。通过添加编码 器网络的局部特征,强迫解码器网络预测更多的特征信息,而不是预测特定的语义像素值。这有利于对输入 图像的光分布的表征。
标准U-Net通过使用复制和裁剪操作,在编码器-解码器模块中完成相应通道特征信息的融合。裁剪操作使得编码器-解码器模块中相应的特征图的大小一致。复制操作是相应特征的连接。
6.细节补充模块,5个卷积层重构最终输出图像,中间加了两个skip connection。
卷积核大小一般为3*3大小,并由Relu函数激活。
在最后输出时,我试了以下,relu可加可不加。
7.损失函数使用的时SSIM结构相似性,还有L1损失函数,结构相似性(SSIM)指数是一 种基于感知的度量[56]。它定义了结构信息(即,在空间上彼此接近的像素高度相关)作为独立于照明和对 比度信息的属性,以反映场景中物体的结构。然后,将图像失真建模为照明、对比度和结构的组合,并采用L1来进一步优化重构图像的亮度和颜色。
所以一个深度学习任务,除了模型的输入输出,还需要好的损失函数,光照不均的重建与图像的内容结构,以及亮度有关,所以采用这两个作为损失函数是没啥问题。
数据集
论文中的数据集是自己的,没有公开,通过作者联系邮箱要也没给,那就只能用github上公开的数据集了。
数据集链接:GitHub - pair-kopti/Shading-correction
内容:分为correct(已校正),original(未校正)
这个数据集据说是通过专业人士调整的,质量确实挺高的。Sensor 2020与Slide images下一个就行,建议下第二个,还有下载时最好用git工具下,直接下太大了,下的不完整。


sensor 2020里大小为5.63GB,分类两个大文件夹correct与original,里面包含40个小文件。
每个小文件中大约为100张彩色图片,图片大小为2304*1719,还是蛮大的。
Slide image 中就小一些,1.24GB,也有小文件,大概10个,每个小文件也是包含大约100张图,图片大小同样为2304*1719。
在数据集文件注释中说Slide image是用于深度学习训练的,看自己个人吧,我感觉都能用。
不过这个数据集还是比较单一的,我也试了一下自己拍的图像,还是校正后差的多,还是得需要自己的数据集进行训练,才能用。
论文代码复现
好了,不多说了,下面直接上代码。
首先呢,模型架构
import torch
import torch.nn as nn
import torch.nn.functional as F
class Encoder(nn.Module):
def __init__(self, in_channel, out_channel):
super(Encoder, self).__init__()
# 一层卷积 一层relu 完成下采样
self.conv_relu = nn.Sequential(
# 先卷两次
nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv_relu(x)
return x
class Decoder(nn.Module):
def __init__(self, in_channel, out_channel):
super(Decoder, self).__init__()
# 相同卷积
self.conv_relu = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv_relu(x)
x = F.interpolate(x, scale_factor=2, mode='nearest')
return x
class DS(nn.Module):
def __init__(self, in_channel, out_channel):
super(DS, self).__init__()
self.conv_relu1 = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
self.conv_relu2 = nn.Sequential(
nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
self.conv_relu3 = nn.Sequential(
nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
x1 = self.conv_relu1(x)
x2 = x + self.conv_relu2(x1)
x3 = x1 + self.conv_relu3(x2)
return x3
class MICnet(nn.Module):
def __init__(self):
super(MICnet, self).__init__()
self.encode1 = Encoder(3, 64)
self.encode2 = Encoder(64, 64)
self.encode3 = Encoder(64, 64)
self.encode4 = Encoder(64, 64)
self.encode5 = Encoder(64, 64)
self.decode1 = Decoder(64, 64)
self.decode2 = Decoder(64, 64)
self.decode3 = Decoder(64, 64)
self.decode4 = Decoder(64, 64)
self.conv_relu1 = nn.Sequential(
nn.Conv2d(67, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
self.conv_relu2 = nn.Sequential(
nn.Conv2d(128, 3, kernel_size=3, stride=1, padding=1),
)
self.DS = DS(128,128)
def forward(self, x):
resize = F.interpolate(x, size=(96, 96), align_corners=False, mode='bilinear')
# 下采样编码
encode1 = self.encode1(resize)
encode2 = self.encode2(encode1)
encode3 = self.encode2(encode2)
encode4 = self.encode2(encode3)
encode5 = self.encode2(encode4)
# 谷底上采样次
x_mid = F.interpolate(encode5, scale_factor=2, mode='nearest')
add1 = x_mid + encode4
decode1 = self.decode1(add1)
add2 = decode1 + encode3
decode2 = self.decode2(add2)
add3 = decode2 + encode2
decode3 = self.decode3(add3)
add4 = decode3 + encode1
decode4 = self.decode4(add4)
# 双线性插值和输入尺寸一致 编码,解码结束
midblock1 = F.interpolate(decode4, size=(x.shape[2], x.shape[3]), mode='bilinear', align_corners=False)
midblock = torch.cat((x, midblock1), dim=1)
# 做一次conv进入细节补充模块
conv1 = self.conv_relu1(midblock)
ds = self.DS(conv1)
result = self.conv_relu2(ds)
return result模型大概框架就是这样,DS就是残差那一部分,只不过分开写了,encoder与decoder是Unet的一下层。
2.数据集制作
import os
import glob
import cv2
import numpy as np
import torch
import torch.nn.functional as F
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import random
import matplotlib.pyplot as plt
# 数据目录
ci_set = "./Shading-correction/Slide images/Corrected (EMPTY-ZERO method)/"
or_set = "./Shading-correction/Slide images/Original/"
ci_dirs = glob.glob(ci_set + '*')
or_dirs = glob.glob(or_set + '*')
or_img = []
ci_img = []
for subdir in or_dirs:
for filename in os.listdir(subdir):
img_path = subdir + "/" + filename
# print(img_path)
if '.jpg' in img_path:
or_img.append(img_path)
for subdir in ci_dirs:
for filename in os.listdir(subdir):
img_path = subdir + "/" + filename
if '.jpg' in img_path:
# print(img_path)
ci_img.append(img_path)
# 检查长度
# print(len(or_img)) # 994
# print(len(ci_img)) # 1000
ci_img_new = []
for i in range(len(or_img)):
or_img_name = or_img[i]
or_img_name = or_img_name[43:]
ci_img_name = ci_set + or_img_name
# print(ci_img_name)
ci_img_new.append(ci_img_name)
# print(len(or_img)) # 994
# print(len(ci_img_new)) # 1000
new_width = 1600
new_height = 1200
for i in range(len(or_img)):
or_img_ad = or_img[i]
ci_img_ad = ci_img_new[i]
or_img_1 = cv2.imread(or_img_ad)
or_img_resize = cv2.resize(or_img_1,(new_width,new_height),interpolation=cv2.INTER_LINEAR)
ci_img_1 = cv2.imread(ci_img_ad)
ci_img_resize = cv2.resize(ci_img_1, (new_width, new_height), interpolation=cv2.INTER_LINEAR)
or_img_filename = os.path.join('./data/or_data',f'{i+1}.jpg')
ci_img_filename = os.path.join('./data/ci_data', f'{i + 1}.jpg')
cv2.imwrite(or_img_filename, or_img_resize)
cv2.imwrite(ci_img_filename, ci_img_resize)这里因为之前的数据分散在各个文件夹里,我觉得太麻烦就全拿出来,放在一个文件夹了,or是原图,ci是校正后的图,并且保存在了data文件下。
import os
import glob
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import random
import matplotlib.pyplot as plt
or_data = "./data/or_data/"
ci_data = "./data/ci_data/"
ci_img_dirs = glob.glob(ci_data + '*')
or_img_dirs = glob.glob(or_data + '*')
# print(len(ci_img_dirs))
# print(len(or_img_dirs))
# 打乱
or_img_new = []
ci_img_new = []
index = list(range(len(or_img_dirs)))
random.shuffle(index)
for i in range(len(or_img_dirs)):
or_img_new.append(or_img_dirs[index[i]])
ci_img_new.append(ci_img_dirs[index[i]])
train_transformer = transforms.Compose([
transforms.ToTensor()
])
test_transformer = transforms.Compose([
transforms.ToTensor()
])
class ICdataSet(Dataset):
def __init__(self, or_img1, ic_img1, transformer):
self.or_img = or_img1
self.ic_img = ic_img1
self.transformer = transformer
def __getitem__(self, index):
or_img1 = self.or_img[index]
ic_img1 = self.ic_img[index]
or_img1_open = Image.open(or_img1)
or_img_tensor = self.transformer(or_img1_open)
ic_img1_open = Image.open(ic_img1)
ic_img_tensor = self.transformer(ic_img1_open)
return or_img_tensor, ic_img_tensor
def __len__(self):
return len(self.or_img)
# 划分数据集
# 按照train 8:test 1:valid 1 共994 所以 800,100,94
end1 = 800
end2 = -94
train_or = or_img_new[:end1]
train_ci = ci_img_new[:end1]
# print(len(train_ci))
test_or = or_img_new[end1 + 1:end1 + 1 + 100]
test_ci = ci_img_new[end1 + 1:end1 + 1 + 100]
# print(len(test_ci))
valid_or = or_img_new[-94:]
valid_ci = ci_img_new[-94:]
# print(len(valid_ci))
train_data = ICdataSet(train_or, train_ci, train_transformer)
test_data = ICdataSet(test_or, test_ci, test_transformer)
dl_train = DataLoader(train_data, batch_size=4, shuffle=True)
dl_test = DataLoader(test_data, batch_size=4, shuffle=True)
or1,ci1 = next(iter(dl_train))
plt.figure(figsize=(12,8))
for i,(img1,img2) in enumerate(zip(or1[:4],ci1[:4])):
#zip 打包为元组
img1 =img1.permute(1,2,0).numpy()
img2 = img2.permute(1, 2, 0).numpy()
plt.subplot(2,4,i+1)
plt.imshow(img1)
plt.subplot(2,4,i+5)
plt.imshow(img2)
plt.show()接下来就是将分好的数据制作成数据集,并使用dataloader加载。最后检查了一下可以不写。

可以看到数据是对应的,上面是原图,下面是校正后的图。这样就可以通过dataloder将图像喂给模型。
4.训练函数
import torch
import torch.nn as nn
import torch.nn.functional as F
import os
import glob
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import random
from pytorch_ssim import ssim
from tqdm import tqdm
import torch.optim.lr_scheduler as lrs
# 损失函数计算
def com_loss_fn(y_pred, y, sigma):
ssim_loss = 1 - ssim(y_pred,y)
l1_loss = F.l1_loss(y_pred,y)
batch_loss = sigma * ssim_loss + (1 - sigma) * l1_loss
return ssim_loss, l1_loss, batch_loss
# 训练函数
def train_epoch(model, trainloader, testloader, device, optimizer, epoch, sigma, scheduler):
SSIM_loss = 0
L1_loss = 0
Loss = 0
model.train()
for x, y in tqdm(trainloader):
x, y = x.to(device), y.to(device)
y_pred = model(x)
# 损失函数
batch_N = y.size(0)
ssim_loss,l1_loss,loss = com_loss_fn(y_pred, y, sigma)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
SSIM_loss += ssim_loss.item()
L1_loss += l1_loss.item()
Loss += loss.item
mean_SSIM_loss = SSIM_loss / len(trainloader.dataset)
mean_L1_loss = L1_loss / len(trainloader.dataset)
mean_Loss = Loss / len(trainloader.dataset)
scheduler.step()
test_SSIM_loss = 0
test_L1_loss = 0
test_Loss = 0
model.eval()
with torch.no_grad():
for x, y in tqdm(testloader):
x, y = x.to(device), y.to(device)
y_pred = model(x)
#损失计算
batch_N = y.size(0)
test_ssim_loss, test_l1_loss, test_loss = com_loss_fn(y_pred, y, sigma)
test_SSIM_loss += test_ssim_loss.item()
test_L1_loss += test_l1_loss.item()
test_Loss += test_loss.item()
test_mean_SSIM_loss = test_SSIM_loss / len(testloader.dataset)
test_mean_L1_loss = test_L1_loss / len(testloader.dataset)
test_mean_Loss = test_Loss / len(testloader.dataset)
staic_dict = model.state_dict()
torch.save(staic_dict, './checkpoint/{}_train_loss_{}_test_loss_{}.pth'.format(epoch, mean_Loss, test_mean_Loss))
torch.save(optimizer.state_dict(), './checkpoint/{}the epoch optimizer.pth'.format(epoch))
print('Learning rate:', scheduler.get_last_lr()[0])
print(
'epoch', epoch,
'train_ssim_loss', mean_SSIM_loss,
'train_l1_loss', mean_L1_loss,
'train_loss', mean_Loss,
'test_ssim_loss', test_mean_SSIM_loss,
'test_l1_loss', test_mean_L1_loss,
'test_loss', test_mean_Loss,
)
return mean_SSIM_loss, mean_L1_loss, mean_Loss, test_mean_SSIM_loss, test_mean_L1_loss, test_mean_Loss
# 载入数据制作数据集
or_data = "./data/or_data/"
ci_data = "./data/ci_data/"
ci_img_dirs = glob.glob(ci_data + '*')
or_img_dirs = glob.glob(or_data + '*')
# print(len(ci_img_dirs))
# print(len(or_img_dirs))
# 打乱
or_img_new = []
ci_img_new = []
index = list(range(len(or_img_dirs)))
random.shuffle(index)
for i in range(len(or_img_dirs)):
or_img_new.append(or_img_dirs[index[i]])
ci_img_new.append(ci_img_dirs[index[i]])
end1 = 800
end2 = -94
train_or = or_img_new[:end1]
train_ci = ci_img_new[:end1]
# print(len(train_ci))
test_or = or_img_new[end1 + 1:end1 + 1 + 100]
test_ci = ci_img_new[end1 + 1:end1 + 1 + 100]
# print(len(test_ci))
valid_or = or_img_new[-94:]
valid_ci = ci_img_new[-94:]
# 将valid信息写进txt文件备用:
valid_or_file = open('valid_or.txt', 'w')
for item in valid_or:
valid_or_file.write(str(item) + '\n')
valid_or_file.close()
valid_ci_file = open('valid_ci.txt', 'w')
for item in valid_ci:
valid_ci_file.write(str(item) + '\n')
valid_ci_file.close()
# print(len(valid_ci))
train_transformer = transforms.Compose([
transforms.ToTensor()
])
test_transformer = transforms.Compose([
transforms.ToTensor()
])
train_data = ICdataSet(train_or, train_ci, train_transformer)
test_data = ICdataSet(test_or, test_ci, test_transformer)
dl_train = DataLoader(train_data, batch_size=4, shuffle=True)
dl_test = DataLoader(test_data, batch_size=4, shuffle=True)
# 主要参数
model = MICnet()
device = 'cpu'
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
sigma = 0.4
scheduler = lrs.StepLR(optimizer, step_size=100, gamma=0.9)
epochs = 120
for epoch in range(epochs):
train_epoch(model, dl_train, dl_test, device, optimizer, epoch, sigma, scheduler)
这里损失函数ssim这里调了一个包pytorch_ssim。
需要的在这里取链接:https://pan.baidu.com/s/1kirMcwq_zsBjH7acaaXHAw?pwd=gcxy
提取码:gcxy
还有就是制作数据集时是打乱再分成train,test,vaild,为了防止训练后不知道那个是valid,挣了两个txt,一个存放valid_ci,校正后的图像名地址,还有valid_or原图名和地址,在后面模型验证时调用。
最后模型验证:
import torch
import torch.nn as nn
import torch.nn.functional as F
import os
import glob
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import random
from pytorch_ssim import ssim
from tqdm import tqdm
import torch.optim.lr_scheduler as lrs
from model_train import MICnet,ICdataSet
import matplotlib.pyplot as plt
#从valid_ci与valid_or,读取验证集文件地址
with open('valid_or.txt','r') as valid_or_dir:
valid_or_dirs = valid_or_dir.readlines()
#去除换行符
valid_or_dirs = [valid_or_dir.strip() for valid_or_dir in valid_or_dirs]
print(valid_or_dirs)
with open('valid_ci.txt','r') as valid_ci_dir:
valid_ci_dirs = valid_ci_dir.readlines()
#去除换行符
valid_ci_dirs = [valid_ci_dir.strip() for valid_ci_dir in valid_ci_dirs]
print(valid_ci_dirs)
valid_transformer = transforms.Compose([
transforms.ToTensor()
])
valid_data = ICdataSet(valid_or_dirs,valid_ci_dirs,valid_transformer)
dl_valid = DataLoader(valid_data,batch_size=1,shuffle=False)
or_img,ci_img = next(iter(dl_valid))
or_img = or_img.to('cuda')
model = MICnet()
start_dict = torch.load('')
model = model.to('cuda')
model.eval()
pred_ci_img = model(or_img)
print(pred_ci_img.shape)
pred_ci_img = pred_ci_img.squeeze(0)
plt.figure(figsize=(20, 20))
plt.subplot(1,2,1)
plt.imshow(or_img.permute(1, 2, 0).cpu().numpy())
plt.subplot(1,2,2)
plt.imshow(pred_ci_img.permute(1, 2, 0).cpu().numpy())
我的配置是3090,24G,输入的图像得resize成1000左右大小才能跑,大图跑起来非常慢,还容易爆显卡。所以在训练时resize的图像小一点好跑。
这篇论文最大作用就是应用于图像拼接场景。但是模型泛化能力不够,如果要用还是需要自己做数据集,但图像渐晕校正这一块,就是因为没有好的校正算法才想求助于深度学习的。所以还是得靠发展。
目前有几个好的思路:
将后面的FCN全卷积换成深度可分离卷积,减少参数量,因为这个模型参数量太大了,大图像进模型就跑不了,尤其是显微图像,一般都2000左右了。
试试vit transformer,就是一种编码解码结构。挺感叹的,深度学习发展至今起始很短,尤其是15年后开始蓬勃发展,一年一个大成果,各种模型网络井喷式出现,需要学习的也越来越多,目前检测,分割都已经到头了,大模型一出来解决了这种小模型泛化能力不强的问题,最后归根到底还是堆参数,模型才能进化,具有涌现的功能。
虽然但是,想要入门的同学还是可以大概看看学学,然后找一个好方向是最好的。