目录
一.Sora出道即巅峰
二.为何说Sora是该领域的巨头
三.Sora无敌的背后究竟有怎样先进的处理技术
1.Spacetime Latent Patches 潜变量时空碎片,建构视觉语言系统
2.扩散模型与Diffusion Transformer,组合成强大的信息提取器
3.DiT应用于潜变量时空碎片,学习获得海量视频中时空碎片的动态关联
4.Sora 或Lumiere 视频学习与生成的技术背后蕴含的原理分析
四.OpenAI官方给予Sora的说明
1.优势及缺陷
2.安全问题的考虑及解决方案
3.研究技术
五.穿梭于虚实之间的sora是否会打破虚拟与现实的平衡
Sora官网https://openai.com/sora
一.Sora出道即巅峰
Sora是OpenAI在2024年2月16日发布的首个文本生成视频模型。该模型能够理解复杂场景中不同元素之间的物理属性及其关系,从而深度模拟真实物理世界,生成具有多个角色、包含特定运动的复杂场景。Sora继承了Dall·E-3的画质和遵循指令能力,可以根据用户的文本提示快速制作长达一分钟的高保真视频,还能获取现有的静态图像并从中生成视频。
Sora的发布使内容创作领域的专业难度降低,作为实现通用人工智能(AGI)的重要里程碑,其问世标志着人工智能在理解真实世界场景并与之互动的能力方面实现了重大飞跃。
二.为何说Sora是该领域的巨头
Sora是OpenAI在2024年2月16日发布的首个文本生成视频模型,能够根据用户的文本提示快速制作长达一分钟的高保真视频。该模型具有以下特点:
- 超长时长:可以直接输出长达60秒的1080P高清视频,而其他竞品仅能实现20秒左右。
- 多视角切换:人物场景在三维空间的移动更为自然,并且能够理解车窗倒影等物理规律,进行交互。
- 多模态输入处理:可以接受文字、图片、视频的输入提示,能够根据图像创建视频或补充现有视频,还能沿时间线向前或向后扩展视频。
Sora主要按AI视频生成领域应用场景分类,可应用于内容创作与广告、影视制作与后期、教育与培训、社交媒体与娱乐、新闻与媒体、虚拟角色与动画等领域。
与其他视频生成模型相比,Sora具有以下优势:
- 生成视频的时间更长:Sora生成的视频时间最多可达1分钟,而其他文生视频大模型仅能生成3至4秒的视频。
- 视频质量更高:Sora生成的视频在时间维度上更加清晰稳定,景物也更符合描述。
- 对用户输入语言的理解更精准:Sora能够准确理解用户输入的语言,并表达出复杂的情感样态。
- 对物理世界模拟的能力更强:Sora能够模拟真实物理世界的运动,如物体的移动和相互作用,这被普遍认为是实现通用人工智能(AGI)的重要一步。
三.Sora无敌的背后究竟有怎样先进的处理技术
Sora的工作原理是通过大量的学习视频来理解现实世界的动态变化,并用计算机视觉技术来模拟这些变化,从而创作出全新的视觉内容。它已经不仅局限于学习图片和视频,同时它也在学习视频里那个世界的“物理规律”。
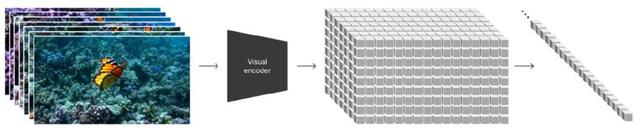
1.Spacetime Latent Patches 潜变量时空碎片,建构视觉语言系统
与ChatGPT首先引入Token Embedding思路一致,针对视觉数据的建模方法作为构建Sora最重要的第一步。碎片Patch已经被证明是一个有效的视觉数据表征模型,且高度可扩展表征不同类型的视频和图像。将视频压缩到一个低维的潜变量空间,然后将其拆解为时空碎片Spacetime Latent Patches。
有了时空碎片这一统一的语言,Sora自然解锁了多种技能:
1. 自然语言理解,
采用DALLE3 生成视频文本描述,用GPT丰富文本prompts,作为合成数据训练Sora,架起了GPT与Sora语言空间的更精确关联,等于在Token与Patch之间统一了“文字”;
2. 图像视频作为prompts,
用户提供的图像或视频可以自然地编码为时空碎片Patch,用于各种图像和视频编辑任务——静态图动画、扩展生成视频、视频连接或编辑等。
2.扩散模型与Diffusion Transformer,组合成强大的信息提取器
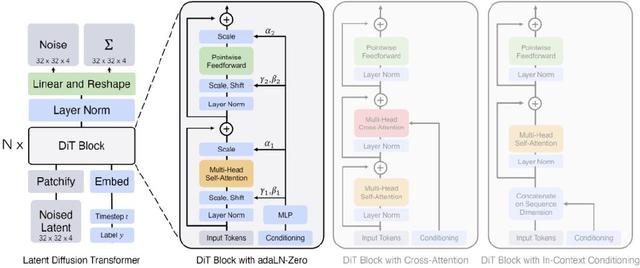
OpenAI讲Sora是一个Diffusion Transformer,这来自伯克利学者的工作Diffusion Transformer (摘取大佬原文https://blog.csdn.net/qq_44681809/article/details/135531494):“采用Transformer的可扩展扩散模型 Scalable diffusion models with transformers”[2],整体架构如下:
Diffusion Transformer (DiT)架构。
左:我们训练调节的潜DiT模型。输入潜变量被分解成几个patch并由几个DiT块处理。
右:DiT块的细节。我们对标准Transformer的变体进行了实验,这些变体通过自适应层归一化、交叉注意力和额外的输入token做调节。自适应层归一化效果最好。
扩散模型的工作原理是通过连续添加高斯噪声来破坏训练数据,然后通过逆转这个加噪过程来学习恢复数据。训练后可以使用扩散模型来生成数据,只需通过学习到的去噪过程来传递随机采样的噪声。扩散模型是一种潜变量模型,逐渐向数据添加噪声,以获得近似的后验
图像渐进地转化为纯高斯噪声。训练扩散模型的目标是学习逆过程,即训练pθ(xt-1|xt)。通过沿着这个过程链向后遍历,可以生成新的数据。
从信息熵的角度可以这样理解:结构化信息信息熵低,多轮加高斯噪音,提高其信息熵,逐步掩盖原来的结构信息。本就无序的非结构化部分,信息熵很高,添加少量高斯噪音,甚至不用添加高斯噪音,已然很无序。
在此视角下,学习到的内容其实是原来结构化信息(如图像)的“底片”。类似化学上的酸碱中和,本来很酸的地方,得放更多的碱,现在我们学到了放碱的分布和节奏,反过来,剔除碱的分布,酸的分布就被还原了。
基础的扩散模型,过程中不降维、无压缩,还原度比较高。学习过程中的概率分布作为潜变量参数化,训练获取其近似分布,用KL散度计算概率分布之间的距离[3]。Diffusion Transformer (DiT) 因为引入Transformer做多层多头注意力和归一化,因而引入了降维和压缩,diffusion方式下的底片信息提取过程,原理与LLM的重整化无异。
3.DiT应用于潜变量时空碎片,学习获得海量视频中时空碎片的动态关联
与“LLM在其高维语言空间中通过Transformer提取人类语言中无数的结构与关联信息”类似,Sora是个基于扩散模型的Transformer,被用于从高维的时空碎片长成的空间中,观察并提取丰富的时空碎片之间的关联与演化的动态过程。如果把前者对应人类读书,后者就是人类的视觉观察。
参照Google Lumiere的技术原理来大胆推演一下。视频其实是记录了时空信息的载体:时空碎片patch可以看作是三维空间的点集(x,y,z)的运动(t),或者说其实是个四维时空模型(x,y,z,t)。Sora和Lumiere之类的生成模型的第一步都是如何从中提取出相应的关键信息。
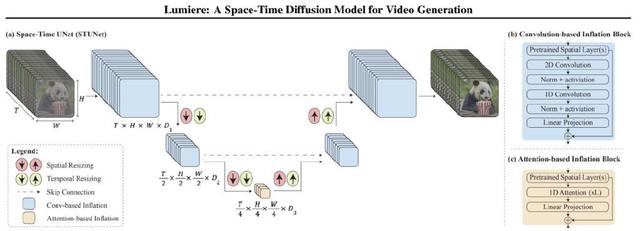
Lumiere(Google推出的AI视频大模型) STUNet架构。将预训练的T2I U-Net架构(Ho et al., 2022a)“膨胀”到一个时空UNet (STUNet),在空间和时间上对视频进行上下采样。
(a)STUNet激活图的示例;颜色表示不同时序模块产生的特征:
(b)基于卷积的块,由预训练的T2I层和因子化时空卷积组成
(c)在最粗的U-Net级别上基于注意力的块,其中预训练的T2I层和时间注意力。由于视频表征在最粗的级别上被压缩,我们使用有限的计算开销堆叠几个时间注意力层。
谷歌Lumiere: A Space-Time Diffusion Model for Video Generation[4]也选择了扩散模型,堆叠了归一化与注意力层,类似Sora的DiT,但细节如时长、分辨率、长宽比等的处理方式不同。细节决定成败,OpenAI称Sora摒弃了“其他文生视频调整视频大小、裁剪或修剪到标准大小的通常做法”,以可变时长、原始分辨率与长宽比训练视频生成获得重要优势,如采样灵活性,改进的创作与成帧
4.Sora 或Lumiere 视频学习与生成的技术背后蕴含的原理分析
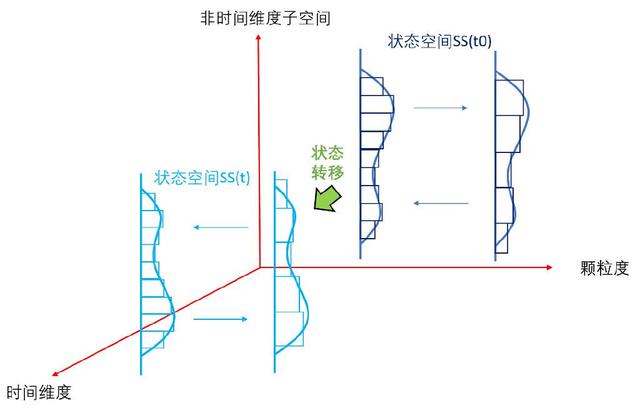
1. 状态空间对事物的表征和刻画:状态空间的高维度,某时刻的信息,即某时刻的事物的能量的概率分布,是众多维度的联合概率分布,各维度都可能具有连续性和非线性,如何用线性系统近似,并最大努力消除非线性的影响非常关键;不同层次的潜变量空间,对信息的提取,和粗颗粒度逐层抽象,都需要类似重整化群RG中的反复归一化,以消除“近似非线性处理”对整体概率为 1 的偏离。关于重整化群信息提取的原理,请参考笔者梳理的“大模型认知框架”,此处不再赘述。这里Sora采用的Diffusion Transformer (DiT) 架构与谷歌Lumiere 采用的Space-Time UNet (STUNet) 都具备注意力与归一化,神经网路架构差异看起来主要来自是否采用“调整视频大小、裁剪或修剪到标准大小的通常做法”。
2. 状态空间的动态性:即从时间的维度,研究整个状态空间的变迁。这个变迁是状态空间的大量非时间维度的信息逐层提取,叠加时间这一特殊维度的(状态-时间)序列sequence。不管是高维度低层次的细颗粒度的概率分布的时间变化,还是低维度高层次的粗颗粒度概率分布的时间变化,都是非线性时变系统,用线性时不变(LTI)的模型都是无法很好刻画的。
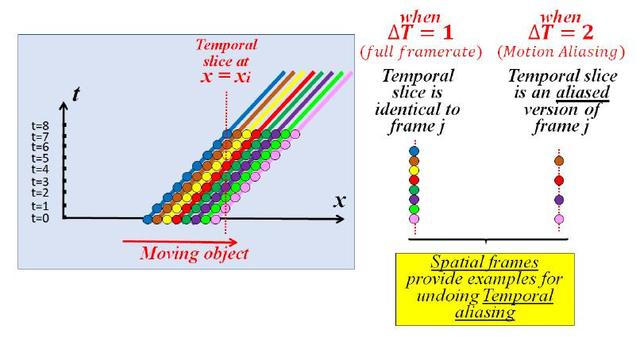
Sora的具体做法技术综述中没有透露。Lumiere的处理中可以窥见端倪。这里可以有多种建模的方式,最自然的方式就是 ((x,y,z), t )的方式,将事物整体的演化看成时间序列,但此种方式往往存在数字视频采样频率不足导致的运动模糊与运动混淆问题。比如高速运转的轮子有时候看起来像在倒转。
Nyquist-Shannon采样定理
告诉我们,对于模拟信号,如果希望同时看到信号的各种特性,采样频率应该大于原始模拟信号的最大频率的两倍,否则将发生混叠即相位或频率模糊。因而Lumiere采用了自监督时间超分辨率 (TSR) 与空间超分辨率 (SSR) 技术[5],将事物的运动建模成多维度两两组合的模型:(x,y), … ,(x,t),(y,t),(z,t)。
小的时空碎片会在视频序列的各个维度上重复出现,特别是空间和时间维度之间进行交换时,因而可以对其在时间域与空间域的表征做关联分析,慢逆时针有可能是快顺时针的假象,也可能就是慢逆时针。即使时域无法分辨,空域可以调整频率,看到更模糊或者没有特别变化的表征。当物体快速移动时,x-t和y-t切片中的Patch看起来是高分辨率x-y切片 (传统帧) 的低分辨率版本。在t方向上增加这些x-t和y-t切片的分辨率与增加视频的时间分辨率是一样的。因此,空间x-y视频帧提供了如何在同一视频中增加x-t和y-t切片的时间分辨率的示例。
即将t看成第四维度,可以用x-y高分辨率训练修正x-t, y-t。同理,当物体移动非常缓慢时,x-t和y-t切片中的Patch呈现为x-y帧中Patch的拉伸版本,表明这些时间切片可以为如何提高视频帧的空间分辨率提供示例。即时间切片,反过来提升空间分辨率。如果SSM学到了物理规律(如运动方程),直接输出高频帧理论上也应当可行。
“跨维”递归的一维图示。1D对象向右移动。当适当的采样时间 (T=1),时间切片类似于空间切片 (1D“帧”)。然而,当时间采样率过低 (T=2) 时,时间切片是空间切片的欠采样(混叠 aliasing)版本。因此,空间帧提供了消除时间混叠的示例。
3. 状态空间时间序列的非马尔可夫性:思考attention 的价值,时序数据上的attention注意到了什么?诸如趋势、周期性、 一次性事件等。非时间维度子空间内的attention,注意到的是范畴内与范畴间的关系, 即某个时刻的状态空间。状态空间的时序,研究的是状态空间的动力学,外在驱动“力”或因素导致的状态的“流动”,即状态空间t时刻与 t-n时刻之间的关系,注意到的是其时间依赖规律,往往不具备马尔可夫性。(马尔可夫性描述了一个系统在其当前状态下,其未来的状态只与其当前状态相关,而与之前的任何状态无关。)非马尔可夫性其实是世界的常态,事实上时延系统基本都是非马尔可夫的。时间维度的注意力与状态空间选择性非常关键。OpenAI对Sora视频生成模型的技术综述文章取了“视频生成模型作为世界模拟器video generation models as world simulators”的题目,可见其宏大的愿景。既然模拟世界,就绕不开万事万物的长程时间关联或者因果关系


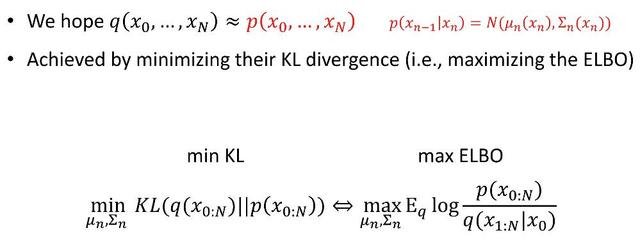
四.OpenAI官方给予Sora的说明
1.优势及缺陷
Sora能够生成具有多个字符、特定运动类型以及主题和背景的准确细节的复杂场景。该模型不仅能理解用户在提示符中的要求,还能理解这些东西在物理世界中是如何存在的。
该模型对语言有深刻的理解,使其能够准确地解释提示,并生成引人注目的字符,表达充满活力的情感。Sora还可以在一个生成的视频中创建多个镜头,这些镜头能够准确地持久化字符和视觉样式。
目前的模式存在弱点。它可能难以准确地模拟复杂场景的物理,也可能不理解因果的具体实例。例如,一个人可能会咬一口饼干,但之后,饼干可能没有咬痕。该模型还可能混淆提示的空间细节,例如,左右混淆,并且可能难以精确描述随时间发生的事件,比如遵循特定的摄像机轨迹。
2.安全问题的考虑及解决方案
在OpenAI的产品中提供Sora之前,我们将采取几个重要的安全措施。我们正在与red teamers合作--错误信息、仇恨内容和偏见等领域的领域专家--他们将对模型进行对抗性测试。我们还在构建一些工具来帮助检测误导性内容,例如一个检测分类器,它可以判断Sora何时生成视频。我们计划包括C2PA元数据未来如果我们将该模型部署在OpenAI产品中。
除了开发新技术为部署做准备之外,我们还利用现有安全方法我们为我们的产品打造的使用DALL·E 3的产品,该产品同样适用于Sora。
例如,一旦进入OpenAI产品,我们的文本分类器将检查并拒绝违反我们使用政策的文本输入提示,比如那些请求极端暴力、性内容、仇恨图像、名人肖像或他人IP的提示。我们还开发了健壮的图像分类器,用于检查生成的每个视频的帧,以帮助确保它在显示给用户之前符合我们的使用策略。
我们将与世界各地的决策者、教育工作者和艺术家接触,以了解他们的关切,并确定这项新技术的积极用例。尽管进行了广泛的研究和测试,但我们无法预测人们使用我们技术的所有有益方式,也无法预测人们滥用技术的所有方式。这就是为什么我们相信,随着时间的推移,从真实世界的使用中学习是创建和发布越来越安全的人工智能系统的关键组成部分。
3.研究技术
Sora是一种扩散模型,它通过从一个看起来类似静态噪声的视频开始生成视频,然后通过多次去除噪声逐渐将其转换。Sora能够同时生成整个视频,或者能够扩展已生成的视频使其更长。通过一次提供许多帧的模型前瞻,我们解决了一个具有挑战性的问题,即确保一个主题即使暂时消失也保持不变。
与GPT模型类似,Sora使用transformer架构,解锁了卓越的扩展性能。
我们将视频和图像表示为更小的数据单元,称为补丁,每个补丁都类似于GPT中的令牌。通过统一我们表示数据的方式,我们可以在比以前更广泛的可视化数据上训练扩散转换器,跨越不同的持续时间、分辨率和纵横比。
Sora建立在过去对DALL·E和GPT模型的研究之上。它使用了DALL·E 3中的重新捕获技术,该技术包括为可视化训练数据生成高度描述性的标题。因此,该模型能够更忠实地跟随用户在生成的视频中的文字说明。
除了能够仅仅从文字说明生成视频之外,该模型还能够获取现有的静止图像并从中生成视频,准确地动画图像的内容,并注意到小细节。该模型还可以获取现有视频并对其进行扩展或填充缺失的帧。技术报道.
五.穿梭于虚实之间的sora是否会打破虚拟与现实的平衡
对于这个问题我并没有答案,只是有一些担忧,在现实世界中由于AI绘图的发展,将静态图片作为某个事件证据的证明性大大降低,如果AI生成视频再超速发展,那未来我们还能看到多少真实的过去?又有多少是来源于虚拟,到底那些才是深埋于地底的现实,我们无从知晓.
视频好似已成为了链接虚拟与现实的最后一条锁链,当我们斩断它后,那些记录着现实的虚拟和那些自诩封存于虚拟的现实到底哪些才是我们真正经历过的,哪些是AI所代替的
我希望人类的未来不会取决于AI的未来
我看不清AI的未来,也捉摸不透人类的未来
PS:本文对于Sora的技术原理剖析摘自其他大佬,有兴趣者可以从浏览器搜索