论文地址:https://arxiv.org/abs/2201.11279
代码地址:https://github.com/zudi-lin/rcan-it
论文小结
本文的工作,就是重新审视之前的RCAN,然后做实验来规范化SR任务的训练流程。
此外,作者得出一个结论:尽管RCAN是一个非常大的SR架构,拥有超过400个卷积层,但作者认为限制模型能力的主要问题仍然是欠拟合而不是过拟合。
增加训练迭代次数,能明显提高模型性能。而应用正则化技术通常会降低预测结果。作者将自己的模型表示为RCAN-it。(Residual Channel Attention Network,-it stands for imporved training)
总得来说,收获点就一句话:模型性能受限于欠拟合而不是过拟合。所以使用更大的训练步幅(因为原始训练没陷入长时间的收敛平原,仍在缓慢上升),减少使用正则化技术。
论文简介
通过更先进的训练策略,本文使用RCAN,在Manga109数据集的
×
2
\times2
×2任务上得到了
0.44
d
B
0.44 dB
0.44dB的PSNR值提升,达到了
39.88
d
B
39.88dB
39.88dB。这个指标已经足够优秀,可以媲美或者超过SOTA算法,比如CRAN和SwinIR。
结合自集成推断(self-ensemble inference),PSNR可以进一步提升到
40.04
d
B
40.04dB
40.04dB,优于现有的所有方法,不管带不带自集成推断结构。
在广泛使用的DF2K数据集上,作者发现模型性能受限于欠拟合而不是过拟合。所以,作者基于这个观察,可以得出几个结论:
首先,简单地增加训练迭代次数可以明显提高分数,而正则化技术通常会降低SR模型的性能。
其次,使用最先进的优化器和学习率调度策略的大批量训练方案(large-batch training scheme),该模型可以在减少4倍的训练时间情况下,匹配原始的训练结果。
第三,将ReLU更改为SiLU,这样简单的架构修改,可以实现延长两倍训练时间的类似训练结果。
第四,使用
×
2
\times2
×2模型作为
×
3
\times3
×3模型和
×
4
\times4
×4模型的初始化,可以减少训练时间和成本,同时仍然获得有竞争力的性能。
有一些工作为了保证训练的稳定性,使用warm-up技术来避免学习率突然上升。
像LAMB这样的优化器,通过分层自适应机制对Adam优化器进行了改进。
与超分任务不同,图像识别的主要挑战是过度拟合。所以权重衰减、更强的数据增强,Mixup和随机深度等正则化技术通常会提高深度分类模型的准确性。本文证明了深度超分模型的性能受到欠拟合的限制。
方法介绍
网络结构
RCAN是当时较为流行的一种SR架构,其是对EDSR等工作进行了三点主要改进。
(1)它在每个残差块的第二个
3
×
3
3\times3
3×3卷积层之后使用SE Blocks(squeeze-excitation)或者channel-attention block来对不同通道进行重新加权。
(2)它有新颖的残差设计,其带有长跳跃连接,以绕过低频信息并有利于更好地学习高频细节。
(3)RCAN是一个非常深的架构,具有很大的模型容量,因为它有
200
200
200个残差块和
400
400
400多个卷积层。
本文的工作基本保持RCAN架构不变。在架构角度上,唯一的修改就是使用SiLU(Sigmoid Linear Unit,也成为了Swish)激活函数代替了原始的ReLU激活函数。Swish激活函数的表示如下:其中 σ ( x ) \sigma(x) σ(x)是sigmoid函数。 f ( x ) = x ∗ σ ( x ) (1) f(x)=x*\sigma(x)\tag{1} f(x)=x∗σ(x)(1)
训练策略
大batchSize优化器
原始的RCAN训练策略是使用Adam优化器,小的batchSize(
B
S
=
16
BS=16
BS=16),小的学习率(
η
=
1
0
−
4
\eta=10^{-4}
η=10−4)。这个训练组合收敛缓慢,大概需要在单个GPU上收敛
7
7
7天。所以作者先使用多GPU训练,以支持大的batchSize。由于梯度更新下降的总数减少,所以应用了一个线性缩放规则:mini-batchSize放大了
k
k
k倍,那么学习率也乘以
k
k
k倍。
为了训练稳定性,作者使用
L
a
m
b
Lamb
Lamb优化器,这是一种专为大批量(large-batch)训练而设计的分层自适应优化器。同时还使用余弦退火代替了原始的多步学习率调度器,其唯一超参数就是迭代(或epochs)的总数。通过采用这些技术,作者有效地将batchSize大小增大了
16
16
16倍,并通过并行性大大节省了训练时间。

更长的训练
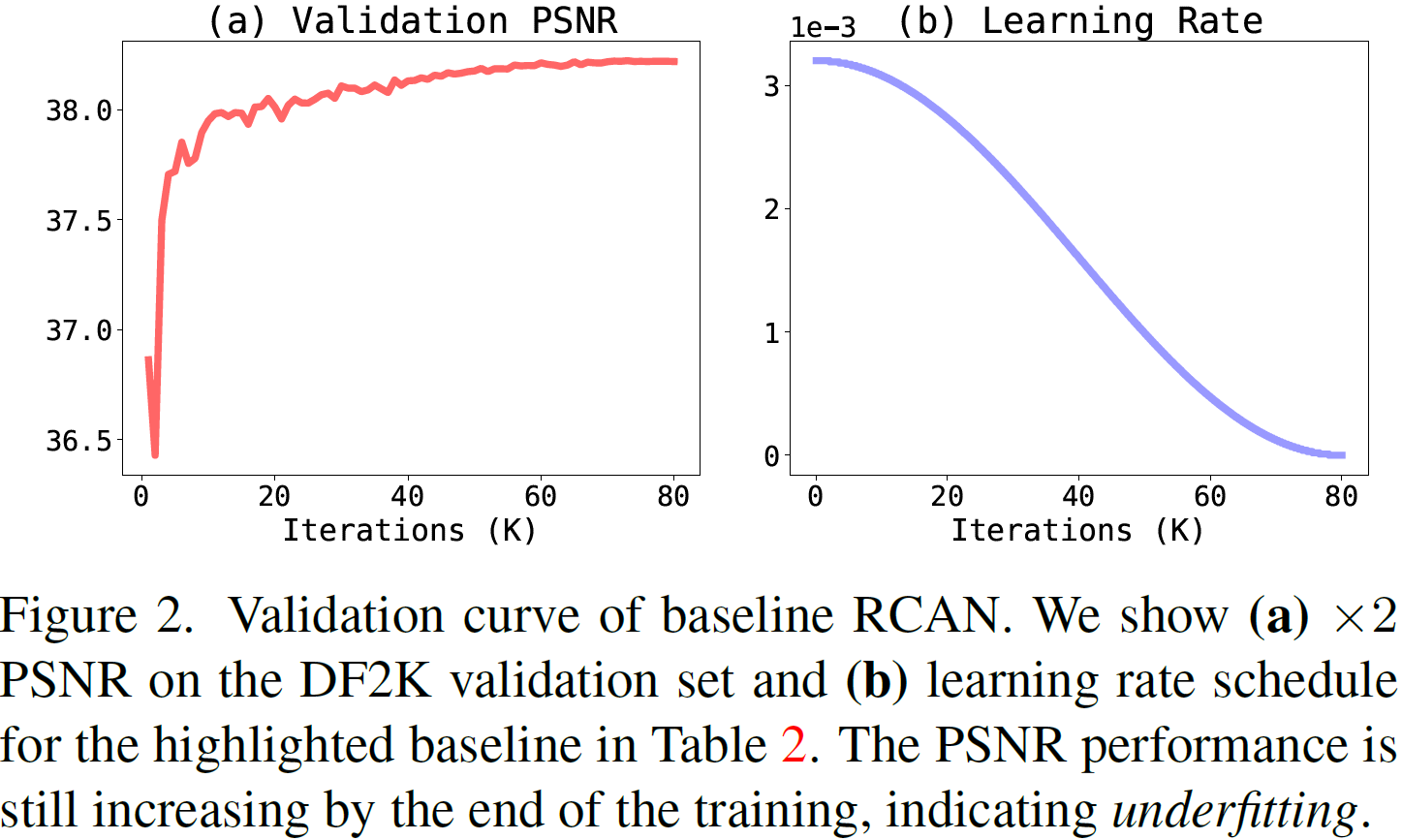
作者发现(如下图左所示),RCAN在baseline训练管道要结束的时候,RCAN的验证集PSNR指标仍在提高,这表明仍存在欠拟合问题。所以增加训练迭代次数,可以有效地减轻欠拟合问题。
大patchSize进行finetune
在Swinir有验证,使用更大patchSize的patch能提高性能。
但增大输入的长宽尺寸会带来GPU内存的急剧上升,导致训练耗时增加,甚至在硬件预算上不可行。
所以,作者将训练管道分为了两个阶段,(1)正常的patchSize尺寸(
48
×
48
48\times48
48×48);(2)更大的patchSize尺寸(
64
×
64
64\times64
64×64)用于finetune,同时使用更少的迭代次数。在更大的patchSize尺寸时,为了满足GPU内存,会缩小batchSize。
正则化技术
测试了一些数据增强技术,mixup,随机深度,随机翻转和通道打乱(channel shuffle)。mixup使用Beta( 0.15 , 0.15 0.15,0.15 0.15,0.15)来生成随机插值权重。对于随机深度,作者使用 0.5 0.5 0.5的概率随机跳过一个残差块。
尽管增加正则化可以有效地提高图像识别大模型的性能,但作者发现RCAN并不能从正则化中收益。因为它会出现欠拟合,而不是过拟合。
热启动
RCAN对于 × 2 , × 3 , × 4 \times2,\times3,\times4 ×2,×3,×4模型的主体结构是一样的,除了最后的预测模块(一个卷积和pixel shuffle)。所以可以使用 × 2 \times2 ×2的权重为 × 3 \times3 ×3模型和 × 4 \times4 ×4模型进行初始化。
训练的时候,由于尾部的预测模块不同。所以可以先将主体结构进行冻结,只finetune尾部的预测模块(速度快,只需要不到 1 1 1小时),然后再一起finetune整个模型。
论文实验
原论文实验管道和超参数更变
使用DF2K数据集用于训练,DF2K由DIV2K和Flickr2K组成,总共3550张图像。验证集为Set5、Set14、B100、Urban100、Manga109。指标评价选择PSNR和SSIM。指标评估的颜色空间为YCbCr空间的Y通道。损失函数都采用 L 1 L1 L1函数。使用随机水平和垂直翻转
模型选择的是RCAN,有 10 10 10个残差组(residual groups, RG),每个残差组有20个残差模块和一个卷积层。所有卷积层的通道数为 64 64 64,除了输入和上采样层。
原始训练策略是batchSize为
16
16
16,学习率为
η
=
1
0
−
4
\eta=10^{-4}
η=10−4,优化器为Adam(
β
1
=
0.9
,
β
2
=
0.999
\beta_1=0.9,\beta_2=0.999
β1=0.9,β2=0.999),训练
1725
K
1725K
1725K次迭代,每经过
20
%
20\%
20%次迭代衰减一半的学习率。
本文的训练策略更改为batchSize为
64
64
64,学习率
η
\eta
η使用线性所发规则。为了训练的稳定性,将Adam优化器更改为Lamb优化器。原始训练策略使用1张V100的GPU,作者使用4张。经过了
80
K
80K
80K次迭代,训练了1.6天。
由下表的对比可以看出,如果学习率 η \eta η是严格遵守线性缩放规则( 0.0016 = 256 16 ∗ 1 0 − 4 0.0016=\frac{256}{16}*10^{-4} 0.0016=16256∗10−4),那么对比原有的管道,会有指标上的性能差异。但如果使用 2 ∗ 1 0 − 4 2*10^{-4} 2∗10−4作为起始点,即 0.0032 = 256 16 ∗ 2 ∗ 1 0 − 4 0.0032=\frac{256}{16}*2*10^{-4} 0.0032=16256∗2∗10−4,那么就有和原始管道相近的性能,但只使用 23 % 23\% 23%的时间。所以,本文的baseline超参数为 B S = 16 , η = 0.0032 BS=16,\eta=0.0032 BS=16,η=0.0032。需要注意的是,这个RCAN指标是比原论文高的。因为其使用了更大的数据集(DF2K),原文只使用了DIV2K数据集。黑盒测试数值,无实际参考意义。
另外,作者注意到 ,使用更大的学习率会造成训练的不稳定。比如当 η = 0.0064 \eta=0.0064 η=0.0064时,在大约 2 K 2K 2K次迭代之后,会陷入无法收敛阶段(NaN)。当 η = 0.0048 \eta=0.0048 η=0.0048时,在大约 16 K 16K 16K次迭代后会陷入无法收敛阶段(NaN)。
训练管道修改
消融学习
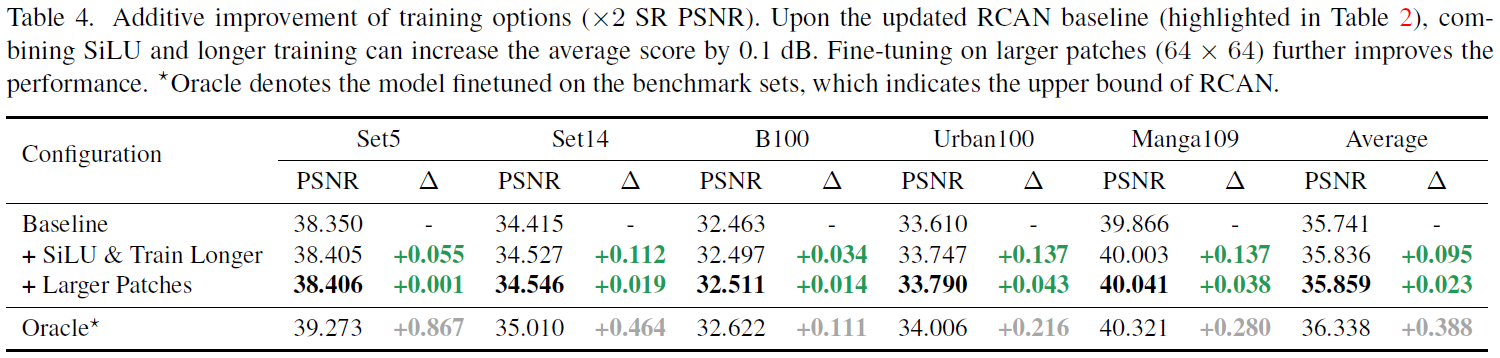
下表展示了架构修改、训练策略修改、正则化变化的消融学习。
对PSNR指标的增长有用的训练策略调整为:激活函数从ReLU改为SiLU,更长的训练周期(训练RCAN共
160
K
160K
160K,是baseline的两倍),使用更大patchSize输入进行finetune。这三个更改,对五个验证集都有指标的提升,且是相互独立的。三个更改平均能带来
0.042
d
B
0.042dB
0.042dB的提升。

同时,从上表可以看出,一些数据增强,都是会降低验证集的PSNR指标的。
集成效果
三个训练策略的组合带来的指标效果如下表所示:组合起来也带来提升。最后一行 Oracle结果,是在每个测试集上分别finetune的结果,也就是过拟合的结果,用以查看RCAN的上限值的。本文最好的RCAN效果和Oracle对比,仍有 0.388 0.388 0.388的PSNR指标差距。这表明,即使使用相对“过时”的RCAN架构,仍有很大的改进空间。
另外,已知Set5数据集有JPEG伪影,Manga数据集由漫画图像组成(合并本封面,是彩色的)。
相关训练结果
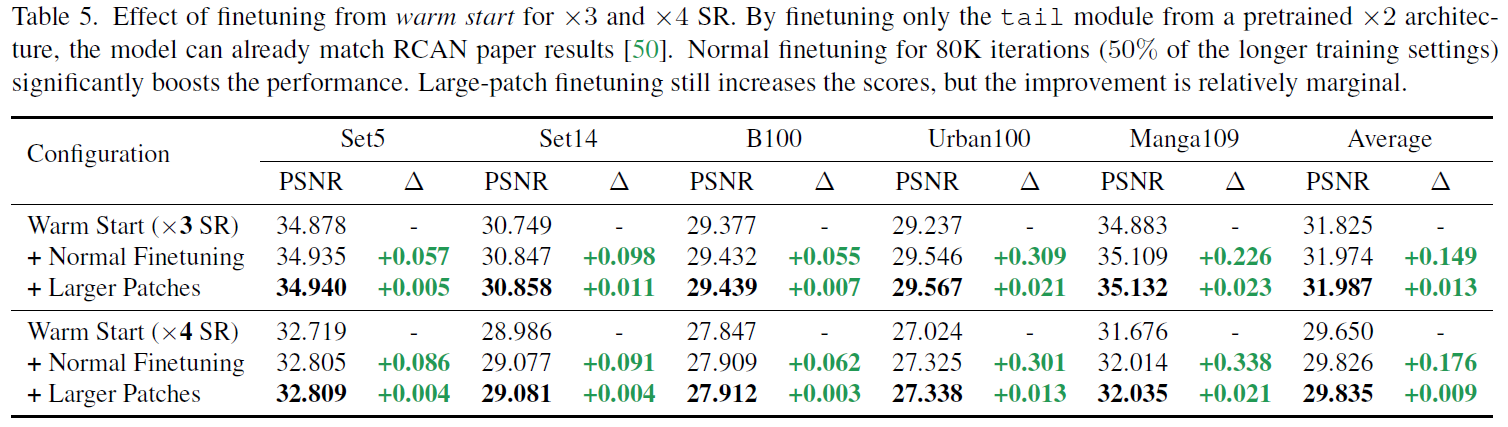
warm start的训练,以及扩大训练迭代次数的结果如下表。
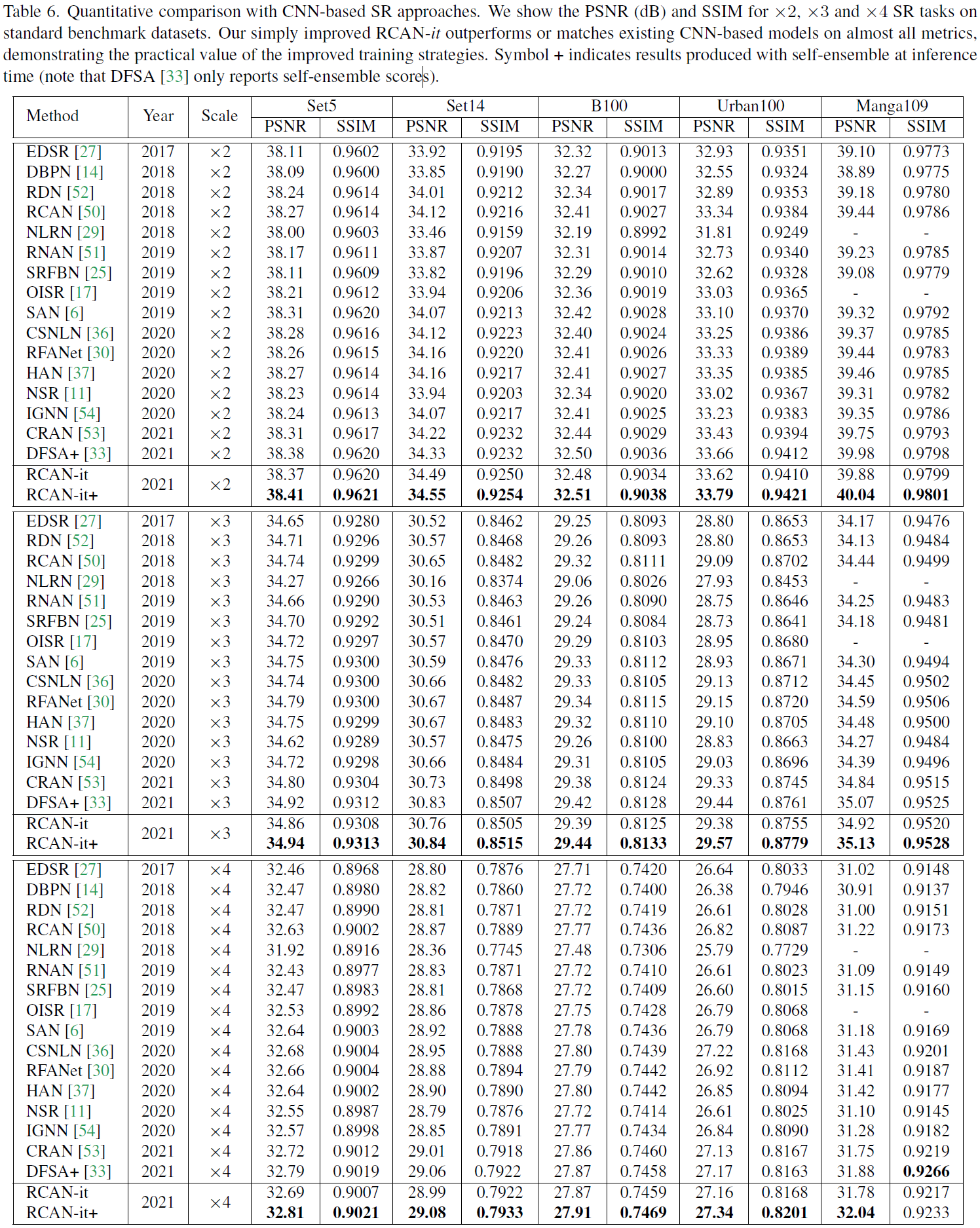
RCAN、RCAN-it与当时其他的SOTA超分算法进行定量对比。
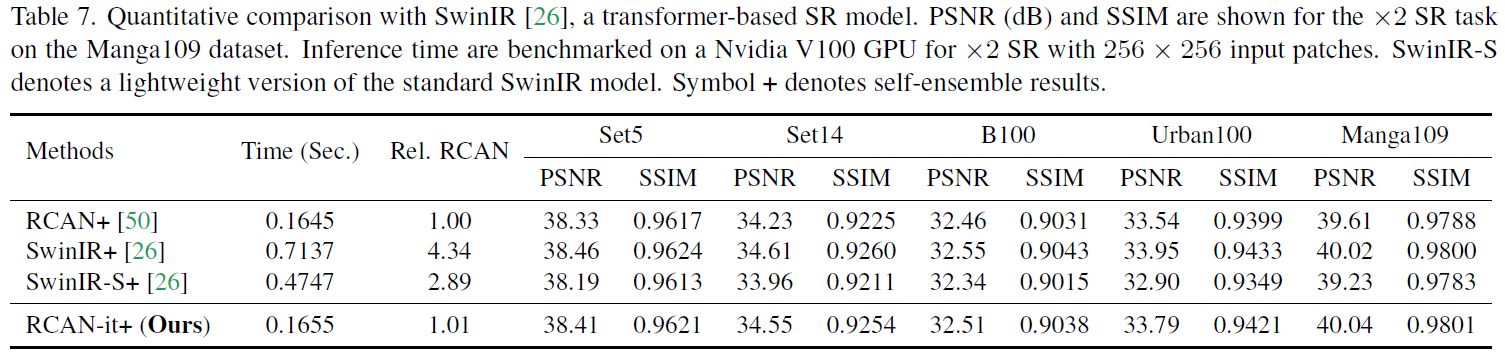
在公开数据集上的可视化对比。

具体来说,RCAN-it 重建了具有更高对比度的条带图案,而其他方法往往会产生不切实际的伪影(图 3,第 4 行)。 此外,在以前的模型中可以消除背景对比度较低的结构,而本文的 RCAN-it 可以保留它们(图 3,第一行)。 请注意,除了激活函数的小修改之外,RCAN-it 与现有方法相比,只需更好的训练即可重建高频细节,而不是引入专门用于学习高频分量的新模块或结构。