1.Spark Application程序入口为:SparkContext,任何一个应用首先需要构建SparkContext对象,两个步骤构建:
第一步,创建SparkConf对象。设置Spark Application基本信息,比如应用的名称AppName和应用运行Master。
第二步,基于SparkConf对象,创建SparkContext对象。

2.Python语言开发Spark程序步骤?
主要是获取SparkContext对象,基于SparkContext对象作为执行环境入口
3.如何提交Spark应用?
将程序上传到服务器上,通过spark-submit客户端工具进行提交。
在代码中不要设置master,如果设置,则以代码的master为准,spark-submit工具的设置就无效了。
提交程序到集群中的时候,读取的文件一定是各个机器都能访问到的地址,比如HDFS。
4.Spark集群角色回顾(YARN为例)
Master(ResourceManager)角色:集群大管家,整个集群的资源管理和分配。
Worker(NodeManager)角色:单个机器的管家,负责在单个服务器上提供运行容器,管理当前机器的资源。
Driver:单个Spark任务的管理者,管理Executor的任务执行和任务分解分配,类似YARN中的ApplicationMaster。
Executor:具体干活的进程,Spark的工作任务(Task)都有Executor来负责执行。
5.Python语言Spark程序运行的流程
Driver进程将构建的SparkContext对象序列化分发到各个Executor,Executor拿到SC(SparkContext)对象后,再各自的去HDFS中拿一部分数据进行处理。这就实现了分布式的处理HDFS中待处理的数据。然后再将各自处理完的数据结果汇总给Driver。(也就是说Driver开始,Driver汇总结束,中间全部是Executor分布式运行)
6.Python on Spark的运行原理
Spark是运行在Java虚拟机或者Scale虚拟机上的,因此Python语言是无法沟通的,因此有一个可以理解为Python Driver的东西和原始的JVM Driver进行通信(把python代码通过Py4j模块翻译为可以原生的JVMDriver去运行)
而在Executor端,Worker会启动一个pyspark的守护进程做一个中转站,完成python executor和JVM executor的中转。
整体流程:python代码来到Driver进程后,又Py4j转化为JVM Driver去命令各个Workder执行,然后Worker中的JVM Executor会通过pyspark守护进程来做中转,pyspark守护进程会将指令调度到pyspark worker去执行。(Executor端,本质上是python进程在工作,指令是由JVM Executor通过RPC通讯发送而来)
Python代码 ---> JVM代码 ---> JVM Driver ---> RPC ---> 调度JVM Executor ---> PySpark中转 ---> Python Executor进程
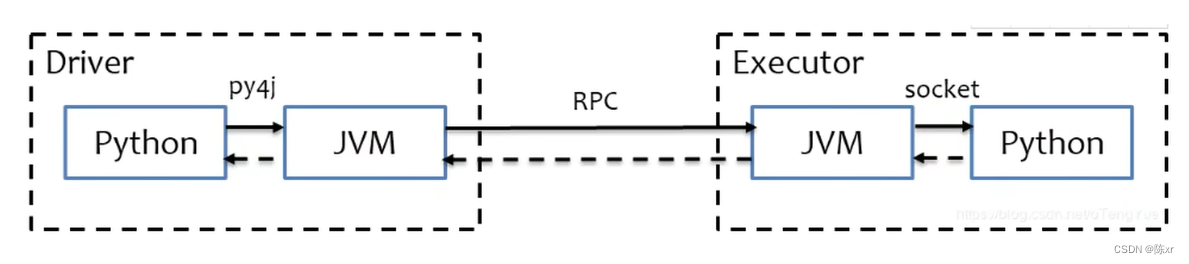
7.分布式代码执行的重要特征是什么?
代码在集群上运行,是被分布式运行的。(写的一份代码,但是运行是分布在多台机器上运行)
在Spark中,非任务处理部分由Driver执行(非RDD代码)
任务处理部分由Executor执行(RDD代码)
Executor的数量可以很多,所以任务的计算是分布式在运行的。
8.简述PySpark的架构体系
Python on Spark 在Driver端由JVM执行,Executor端由JVM做命令转发,底层由Python解释器来工作。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
接下来进入Spark Core阶段(也就是Spark的一些核心算子(算子:API))
9.为什么需要RDD
分布式计算需要的要素:
a.分区控制(不同服务器负责运行的那一部分)
b.Shuffle/洗牌操作(不同服务器上运行数据的交互,归纳合并等操作)
c.数据存储/序列化/发送
d.数据计算API
e.等一些列的操作
以上这些功能,不能简单地通过Python内置的本地集合对象(如List/字典等去完成)。我们在分布式框架中,需要有一个统一的数据抽象对象,来实现上述分布式计算所需的功能,这个抽象对象,就是RDD。
RDD可以视为整个Spark框架中最核心的数据抽象对象,基本上大部分核心功能,都是由RDD来提供的。
10.RDD的定义
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变,可以分区,里面的元素可以并行计算的集合。
Dataset:一个数据集合,用于存放数据的(本地集合是本进程集合,RDD是跨越机器的,因此RDD集合是跨进程集合)
Distributed:RDD中的数据是分布式存储的,可用于分布式计算。(RDD的数据是跨越机器存储的/跨进程)
Resilient:RDD中的数据可以存储在内存中或者磁盘中。
姑且:把RDD视为一个增强的List集合对象吧。
11.RDD的5大特性
a.RDD是有分区的
b.RDD的方法会作用在其所有的分区上
c.RDD之间是有依赖关系的(RDD有血缘关系),RDD之间会进行迭代,形成一个依赖链条
d.Key-Value类型的RDD可以有分区器
默认分区器:Hash分区规则,也可以手动自己设置一个分区器(rdd.partitionBy方法来设置)
这个特性是可选的,因为也并不是所有的RDD都是Key-Value类型的格式
Key-Value型RDD:RDD中存储的是二元元组,便是Key-Value型RDD
e.RDD的分区规划,会尽量靠近数据所在的服务器
因为这样可以走本地读取,避免网络读取,提高性能。
12.WordCount结合RDD特性进行执行流程分析
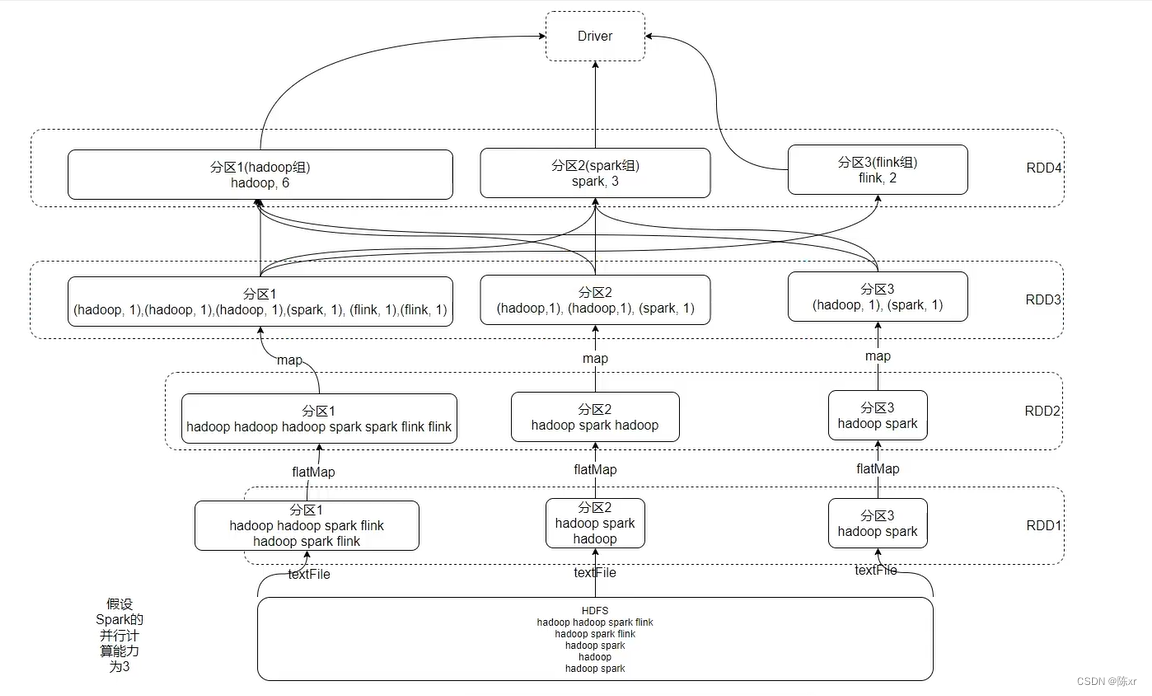
13.不论是python,Scala,Java,Spark RDD程序的程序入口都是SparkContext对象
只有构建出来SparkContext对象,才能基于它执行后续的API调用和计算操作
本质上,SparkContext对于编程来说,主要功能就是创建第一个RDD出来
14.RDD创建的两种方式
a.通过并行化集合创建(本地对象 转 分布式RDD)
就是sparkContext对象去调用parallelize(参数1,参数2) API就行了。参数1:集合对象,参数2:分区数
b.读取外部数据源(读取文件)
就是sparkContext对象去调用textFile(参数1,参数2)API就行了。参数1:文件路径(支持本地文件和HDFS文件等),参数2:表示最小分区数
15.什么是RDD的算子
分布式集合对象(RDD)的API就是算子,换个昵称罢了。
分布式对象的API就是算子,叫做算子只是为了区分本地对象的API,本地的叫方法or函数;分布式对象的叫算子,仅此而已。
RDD算子分为两类:Transaction转换算子;Action动作算子。
返回值仍然是RDD的就是转换算子,反之,返回值不是RDD的就是动作算子。
转换算子是提供执行计划,它是懒加载的,需要等动作算子开始执行,才能让转换算子所预设的计划进行工作。
16.常见的转换算子
map算子:将RDD数据的一条条的处理(处理的逻辑基于map算子中接受的处理函数),返回新的RDD
flatMap算子:对RDD执行map操作,然后进行解除嵌套操作。
解除嵌套eg:

reduceByKey算子:针对KV型RDD,自动按照Key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作
groupBy算子:将RDD的数据进行分组
Filter算子:过滤想要的数据进行保留
distinct算子:对RDD数据进行去重,返回新的RDD
union算子:2个RDD合并成1个RDD返回
join算子:对两个RDD执行JOIN操作(可以实现SQL的内/外连接),只能用于二元元组
intersection算子:求2个RDD的交集,返回一个新的RDD
glom算子:将RDD的数据,加上嵌套,这个嵌套按照分区来进行
比如RDD数据[1,2,3,4,5]有两个分区,那么被glom之后,数据变为[[1,2,3],[4,5]]
groupByKey算子:针对KV型RDD,自动按照key分组
sortBy算子:对RDD数据进行排序,,基于你指定的排序依据
sortByKey算子:针对KV型RDD数据,按照key进行排序
countByKey算子:统计key出现的次数(一般用于KV型RDD)
collects算子:将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象
fold算子:和reduce一样,接受传入逻辑进行聚合,聚合是带有初始值的
first算子:取出RDD的第一个元素
take算子:取RDD的前N个元素,组合成list返回
top算子:对RDD数据集进行降序排序,取出前N个
count算子:计算RDD有多少条数据,返回值是一个数字
takeSample算子:随机抽样RDD的数据
takeOrderd算子:对RDD进行排序取前N个
foreach算子:对RDD的每一个元素,执行你提供的逻辑的操作(和map一个意思),但是这个方法没有返回值
saveAsTextFile算子:将RDD的数据写入到文本文件中
mapPartitions算子:和map类似,但是map是一次传递分区中的一个数据,而mapPartitions一次传递一整个分区的数据过来进行计算。
foreachPartition算子:和普通的foreach一样,一次处理的是一整个分区数据
partitionBy算子:对RDD进行自定义分区操作
repartitions算子:对RDD分区执行重新分区