- 是由Technische Universiteit Delft(代尔夫特理工大学)发表于ICCV,2019。
- 这篇文章的研究内容很有趣,没有关注如何提升深度网络的性能,而是关注单目深度估计的工作机理。
What they find?
- 所有的网络都忽略了物体的实际大小,而关注他们的垂直位置。而使用这些垂直位置需要知道相机的位姿。
- 然而我们发现网络只部分识别了相机俯仰角(pitch)和滚动角(roll)的变化。小的俯仰角变化都会干扰估计出的深度。
- 使用垂直图像位置允许网络估计对任意障碍物的深度-甚至是没有出现在训练集中的物体。
Introduction
- 当只有一张图像可用时,很难应用Epipolar Geometry, 算法需要依靠图像线索(Pictorial cues):纹理梯度和已知物体的面积。
- 人类感知深度只要依靠的线索可以总结为:
- 在图像中位置:遥远的物体趋向于位于地平线。
- 遮挡:遮挡提供了深度的顺序,但不提供距离信息。
- 纹理密度:距离较远的纹理表面在图像中看起来更细粒度。
- 线性预测:物理世界中的直线、平行线似乎在图像中汇合。
- 目标的面积:越远的目标越小。
- 阴影和光照:当表面正常指向光源时,表面显得更亮。光通常被认为是来自于上面的光。阴影通常提供关于表面内深度变化的信息。
- 焦点模糊:在焦平面前或后的物体会变模糊。
- 空中视角(天空):非常远的物体(公里)的对比度较小,呈现出蓝色。
- 论文认为只有在图像中的位置和目标的面积会影响KITTI单目深度估计。
Position vs. apparent size
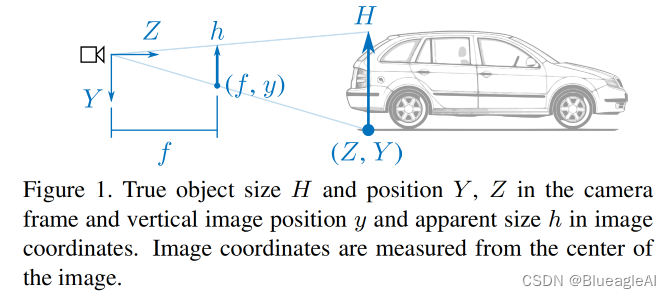
- 给定目标的真实世界尺寸和在图像中的尺寸h,距离可以计算为:
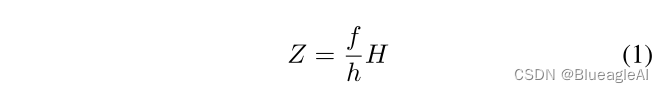
- 在Kitti数据集中每一种类的高度可以认为是固定的。所以网络有可能是用目标的表观大小估计其距离。
- 同时,网络也可以利用物体与地面的接触点位置y估计深度。给定相机距离地面的高度Y,距离可以估计为:

- 这个方法不需要目标的真实高度H,需要网络学习 ( Y , y h ) (Y,y_h) (Y,yh)。
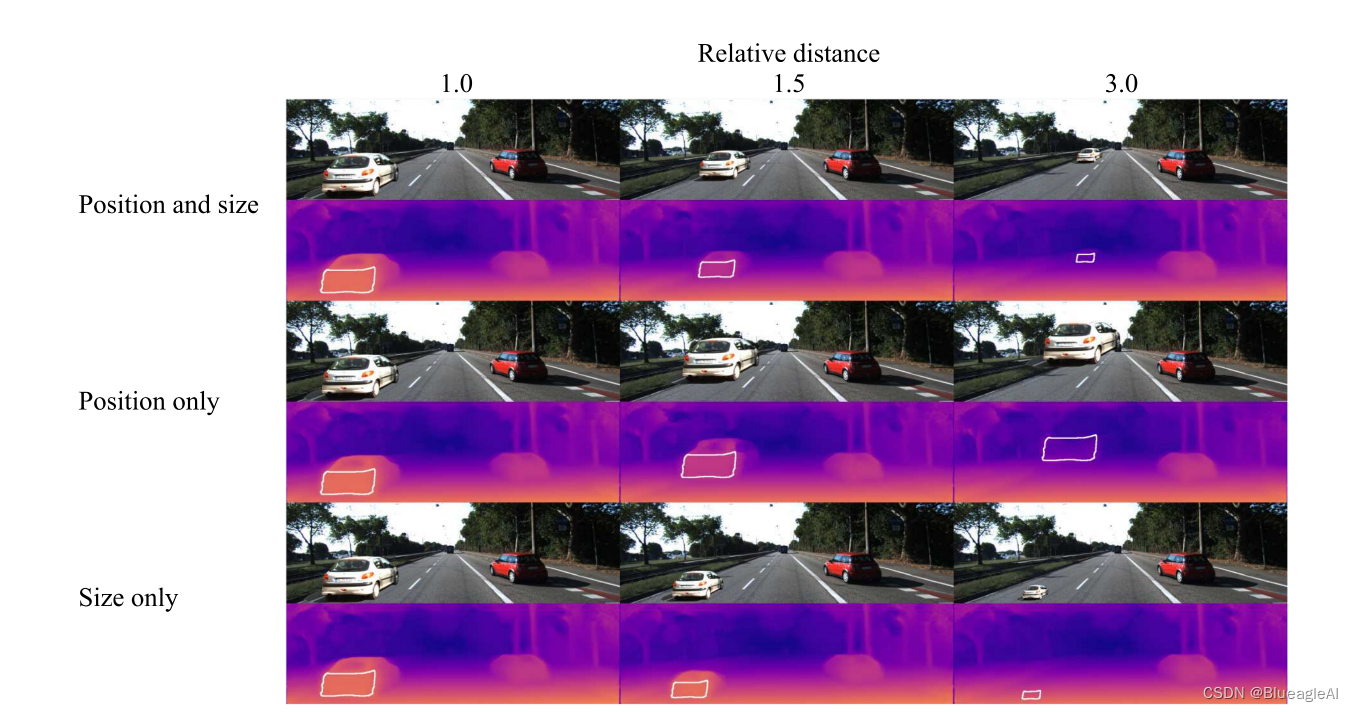
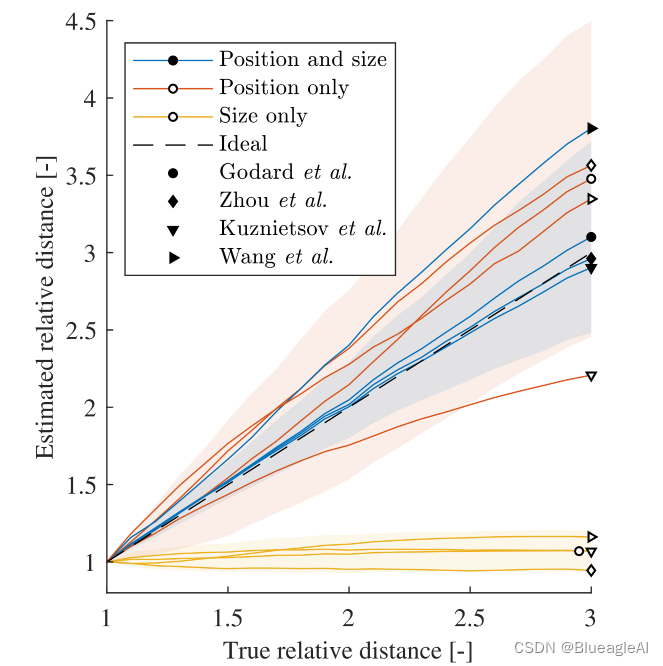
- 从试验结果看,网络对于距离的判断是由目标的垂直位置决定了。
- 而且当把图像进行垂直方向上的裁剪,估计出的深度也被明显改变了。所以网络并不是在找地平线而是在找垂直图像位置。而表观尺寸的变化有可能并不影响深度估计。
- 所有四个网络都表现出相似的行为,这也表明这是一个一般的属性,并不强烈依赖于网络架构或训练机制(半监督,双目,视频监督)
Camera Pose: constant or estimated?
- 对于使用垂直位置作为深度估计的线索,基本假设是知道相机的位姿。
- 有两种方式确定相机位姿:1.寻找地平线或者消失点。2.或者假设其恒定。
- 如果是第二种假设,则在一个相机上训练的深度网络就不能直接迁移到另一个相机。
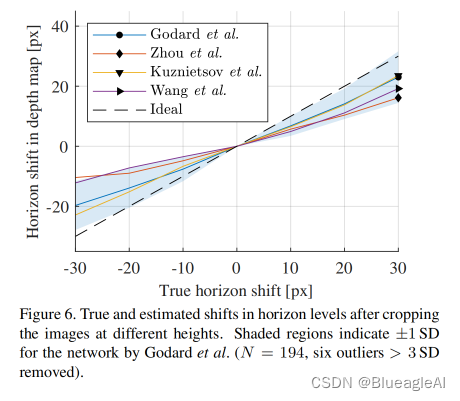
- 论文中的实验证明(图5,图6):所有的网络都能够检测到摄像机俯仰角的变化,但地平线的改变被轻视了。 总结一下就是改变相机俯仰角和地平线位置对深度估计有影响但是影响不大。

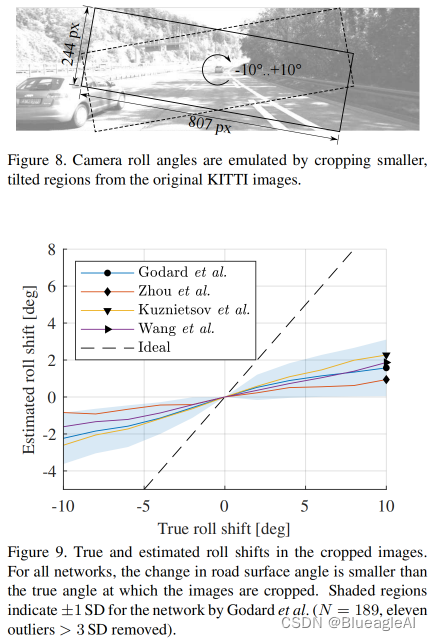
Camera roll
- 所有网络都能够检测相机的翻滚角,但是被严重低估了。
Obstacle recogition
- 正确估计目标的深度,网络要做的是:1).对于训练集中出现的物体进行记忆(车辆)。2).寻找目标与地面的接触点。3).寻找目标的轮廓并填充区域。
Color and Texture
- 目标的颜色并不强烈影响深度估计,但如果纹理被移除,性能会大减。梯度纹理对深度估计的影响更大。

Shape and contrast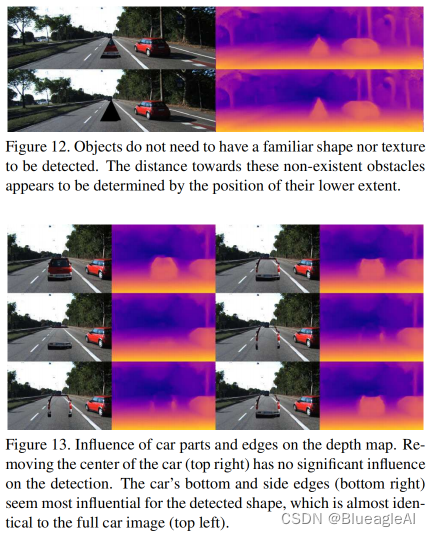
- (图12)目标不需要一个相同的形状和纹理被网络识别。
Reference
[1] Dijk, T. V., & Croon, G. D. (2019). How do neural networks see depth in single images?. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 2183-2191).