文章目录
前言
一、Encoder 家族
1. BERT
2. DistilBERT
3. RoBERTa
4. XML
5. XML-RoBERTa
6. ALBERT
7. ELECTRA
8. DeBERTa
二、Decoder 家族
1. GPT
2. GPT-2
3. CTRL
4. GPT-3
5. GPT-Neo / GPT-J-6B
三、Encoder-Decoder 家族
1. T5
2. BART
3. M2M-100
4. BigBird
前言
最初的Transformer是基于广泛应用在机器翻译领域的Encoder-Decoder架构:
Encoder:
将由 token 组成的输入序列转成由称为隐藏状态(hidden state)或者上下文(context)的embedding向量组成的序列。
Decoder:
根据 Encoder 的隐藏状态迭代生成组成输出序列的 token。

从上图我们可以看到:
- 输入文本被 tokenized 成 token embedding。由于注意力机制不知道 token 的相对位置,因此我们需要一种方法将一些有关 token 位置的信息注入到输入中,以对文本的顺序性质进行建模。因此,token embedding 与包含每个 token 的位置信息的 position embedding 相组合。
- encoder 由一堆 encoder 层组成,类似于计算机视觉中堆叠的卷积层。decoder也是如此,它有自己的 decoder 层块。
- encoder 的输出被馈送到每隔 decoder 层,然后 decoder 生成序列中最可能的下一个 token 的预测。然后,此步骤的输出被反馈到 decoder 以生成下一个 token,依次类推,直到到达特殊的序列结束(End of Sequence,EOS)token。以上图为例,想象一下 decoder 已经预测了“Die”和“Zeit”。现在,它将根据这两个预测 token 以及所有 encoder 的输出来预测下一个 token “fliegt”。在下一步中,decoder 继续将“fliegt”作为附加输入。我们重复这个过程,直到 decoder 预测出 EOS token 或者达到最大输出长度限制。
Transformer 架构最初是为机器翻译等序列到序列任务而设计的,但 encoder 和 decoder 块很快就被改编为独立模型。尽管现在有数千种不同的 Transformer 模型,但大多数属于以下三种类型之一:
(1)Encoder-only
这些模型将文本输入序列转换为丰富的数字表示,非常适合文本分类或命名实体识别等任务。BERT(Bidirectional Encoder Representation Transformers)及其变体,例如 RoBERTa 和 DistilBERT,都属于此类架构。在该架构中为给定 token 计算的表示取决于左侧(token之前)和右侧(token之后)的上下文。所以通常称为双向注意力(bidirectional attention)。
(2)Decoder-only
用户给定一段文本提示,这些模型将通过迭代预测最可能出现的下一个单词来自动补充余下的文本。GPT(Generative Pretrained Transformer)模型系列属于此类。在该架构中为给定 token 计算的表示仅取决于左侧上下文。所以通常称为因果注意力(causal attention)或自回归注意力(autoregression attention)。
(3)Encoder-Decoder
它们用于对从一个文本序列到另一个文本序列的复杂映射进行建模,比如机器翻译和文本摘要。除了我们所看到的结合了 encoder 和 decoder 的Transformer 架构之外,BART(Bidirectional Auto-Regressive Transformers)和 T5(Text-To-Text Transfer Transformer)模型也属于此类。
实际上,decoder-only 架构和 encoder-only 架构的应用程序之间的区别有点模糊。例如,GPT 系列中的纯 decoder 模型可以为翻译等任务做好准备,这些任务通常被认为是序列到序列的任务。类似地,像 BERT 这样的纯 encoder 模型可以应用于通常与 encoder-decoder 或纯 decoder 模型相关的摘要任务。
随着时间的推移,三种主要架构都经历了自己的演变。
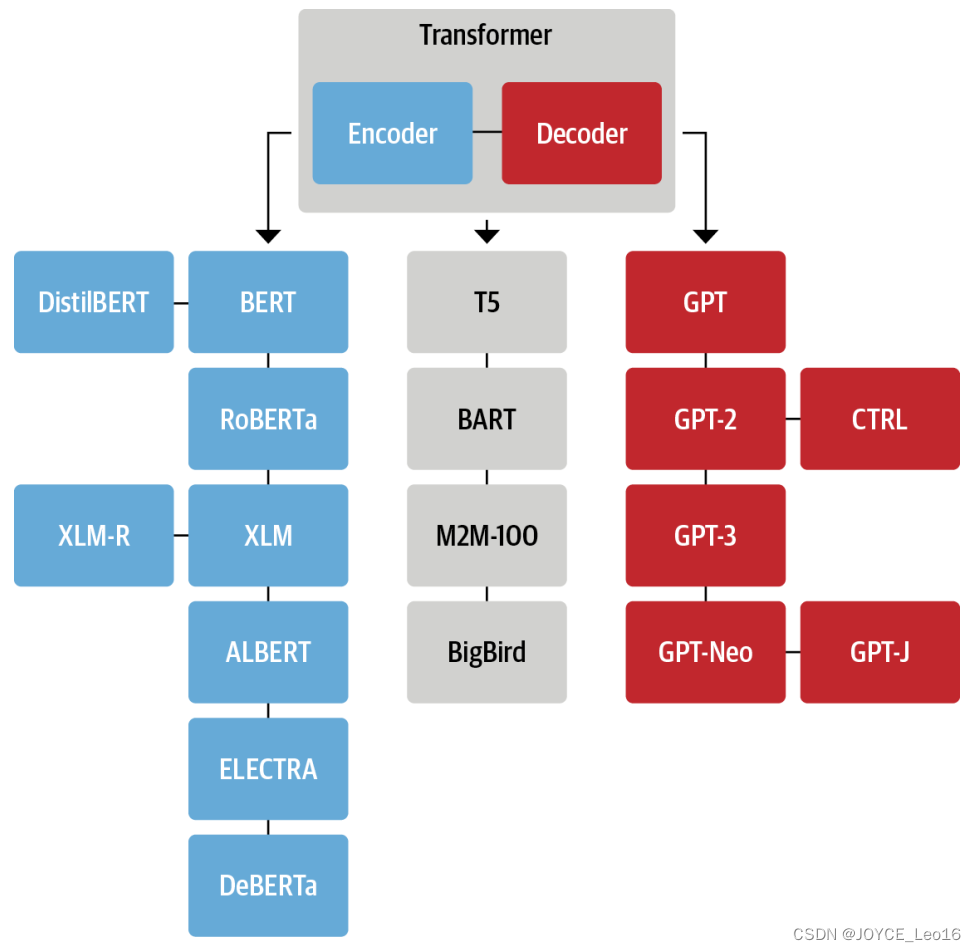
上图这个家谱只是突出显示了一些架构里程碑。
一、Encoder 家族
第一个基于 Transformer 架构的 encoder-only 模型是 BERT。encoder-only 模型仍然主导着 NLU(Natural Language Understanding)任务(例如文本分类、命名实体识别和问题解答)的研究和行业。接下来简单介绍一下 BERT 模型及其变体:
1. BERT
BERT 的预训练目标有两个:预测文本中的 mask token;确定一个文本段落是否紧跟着另一个文本段落。前一个任务称为 Masked Language Modeling(MLM),后一个称为 Next Sentence Prediction(NSP)。
2. DistilBERT
尽管BERT的预测能力很强,但是由于其庞大的尺寸,我们无法在低延迟要求的生产环境中部署。通过在预训练过程中使用知识蒸馏(knowledge distillation)技术,DistilBERT 可以达到BERT 97% 的性能,但是体积仅有BERT的 40%,速度比BERT快60%。
3. RoBERTa
BERT 发布后的一项研究表明,通过修改预训练方案可以进一步提高其性能。RoBERTa 的训练时间更长、批次更大、训练数据更多,并且它放弃了 NSP 任务。总之,与原始 BERT 模型相比,这些变化显著提高了其性能。
4. XML
在跨语言语言模型 (cross-lingual language model,XLM) 的工作中,探索了构建多语言模型的几个预训练目标,包括来自类 GPT 模型的自回归语言建模和来自 BERT 的 MLM。此外,XLM 预训练论文的作者介绍了翻译语言模型(translation language modeling,TLM),它是 MLM 对多语言输入的扩展。通过对这些预训练任务进行实验,他们在多个多语言 NLU 基准测试以及翻译任务上取得了领先成绩。
5. XML-RoBERTa
继 XLM 和 RoBERTa 的工作之后,XLM-RoBERTa 或 XLM-R 模型通过大规模升级训练数据,使多语言预训练更进一步。使用 Common Crawl 语料库,其开发人员创建了一个包含 2.5TB 文本的数据集;然后他们在这个数据集上用 MLM 训练了一个 encoder。由于数据集仅包含没有并行文本(即翻译)的数据,因此 XLM 的 TLM 目标被删除。这种方法大幅击败了 XLM 和多语言 BERT 变体,尤其是在缺乏足够语料的语言上。
6. ALBERT
ALBERT模型引入了三个变化,使encoder 架构更加高效。首先,它将 token embedding 维度与隐藏维度解耦,从而允许 embedding 维度较小,从而节省参数,尤其是当词汇量变大时。其次,所有层共享相同的参数,这进一步减少了有效参数的数量。最后,NSP目标被句子排序预测取代:模型需要预测两个连续句子的顺序是否交换,而不是预测它们是否属于在一起。这些变化使得用更少的参数训练更大的模型成为可能,并在NLU任务上达到卓越的性能。
7. ELECTRA
标准MLM预训练目标的一个限制是,在每个训练步骤中,仅更新 mask token 的表示,而其他输入token则不更新。为了解决这个问题,ELECTRA使用双模型方法:第一个模型(通常很小)的工作原理类似于标准 masked language model,并预测 mask token。第二个模型称为鉴别器,然后负责预测第一个模型输出中的哪些 token是最初的 mask token。因此,判别器需要对每个 token进行二分类,这使得训练效率提高了30倍。对于下游任务,鉴别器像标准 BERT 模型一样进行微调。
8. DeBERTa
DeBERTa 模型引入了两个架构变化。首先,每个 token 都表示为两个向量:一个表示内容,另一个表示相对位置。通过将 token 的内容与其相对位置分开,自注意力层可以更好地对附近 token 对的依赖性进行建模。另一方面,单词的绝对位置也很重要,尤其是对于解码而言。因此,在 token 解码头的 softmax 层之前添加了绝对 position embedding。DeBERTa 是第一个在 SuperGLUE 基准测试上击败人类基线的模型,SuperGLUE 基准测试是 GLUE 的更困难版本,由多个用于衡量 NLU 性能的子任务组成。
二、Decoder 家族
Transformer decoder 模型的进展在很大程度上是由OpenAI引领的。这些模型非常擅长预测序列中的下一个单词,因此主要用于文本生成任务。它们的进步是通过使用更大的数据集并将语言模型扩展到越来越大的尺寸来推动的。
1. GPT
GPT的引入结合了NLP中的两个关键思想:新颖高效的Transformer decoder 架构和迁移学习。在该设置中,通过 根据先前的单词预测下一个单词来对模型进行预训练。该模型在 BookCorpus 上进行训练,并在分类等下游任务上取得了很好的效果。
2. GPT-2
受到简单且可扩展的预训练方法成功的启发,通过升级原始模型和训练集诞生了 GPT-2。该模型能够生成连贯文本的长序列。由于担心可能被滥用,该模型以分阶段的方式发布,先发布较小的模型,然后发布完整的模型。
3. CTRL
像GPT-2这样的模型可以继续输入序列(也称为提示:prompt)。然而,用户对生成序列的样式几乎没有控制权。CTRL(Conditional Transformer Language)模型通过在序列开头添加“控制 token”来解决此问题。这些允许控制生成文本的样式,从而允许多样化的生成。
4. GPT-3
成功将 GPT 扩展到 GPT-2 后,对不同规模的语言模型行为的全面分析表明,存在简单的幂律来控制计算、数据集大小、模型大小和语言模型性能之间的关系。受这些见解的启发,GPT-2 被放大了 100 倍,生成了具有 1750 亿(175B)个参数的 GPT-3。除了能够生成令人印象深刻的真实文本段落之外,该模型还表现出少量学习能力:通过一些新颖任务的示例(例如将文本翻译为代码),该模型能够在新示例上完成该任务。OpenAI 并没有开源这个模型,我们只能通过 OpenAI API 提供接口来访问 GPT-3。
5. GPT-Neo / GPT-J-6B
GPT-Neo 和 GPT-J-6B 是类似 GPT 的模型,由 EleutherAI 训练,EleutherAI 是一个旨在重新创建和发布 GPT-3 规模模型的研究人员社区。当前模型是完整 175B 模型的较小变体,具有 1.3B、2.7B 和 6B 个参数,与 OpenAI 提供的较小 GPT-3 模型具有竞争力。
三、Encoder-Decoder 家族
尽管使用单个 encoder 或 decoder 堆栈构建模型已变得很常见,但 Transformer 架构有多种 encoder-decoder 变体,它们在 NLU 和 NLG 领域都有新颖的应用:
1. T5
T5 模型通过将所有 NLU 和 NLG 任务转换为文本到文本任务来统一它们。所有任务都被构建为序列到序列的任务,其中采用 encoder-decoder 架构是很自然的。例如,对于文本分类问题,这意味着文本用作encoder 输入,并且 decoder 必须将标签生成为普通文本而不是类别。T5 架构采用原有的 Transformer 架构。使用大型爬网 C4 数据集,通过将所有这些任务转换为文本到文本任务,使用 MLM 以及 SuperGLUE 任务对模型进行预训练。11B 模型在多个基准测试中产生了领先的结果。
2. BART
BART 在 encoder-decoder 架构中结合了 BERT 和 GPT 的预训练过程。输入序列会经历几种可能的转换之一,从简单的 mask token 到句子排列、删除 token 和文档旋转。这些修改后的输入通过 encoder 传递,decoder 必须重建原始文本。这使得模型更加灵活,因为可以将其用于 NLU 和 NLG 任务,并且在这两个任务上都实现了领先的性能。
3. M2M-100
通常,翻译模型是针对一种语言对和翻译方向构建的。当然,这并不能扩展到许多语言,此外,语言对之间可能存在共享知识,可用于稀有语言之间的翻译。M2M-100 是第一个可以在 100 种语言之间进行翻译的翻译模型。这可以在稀有语言和代表性不足的语言之间进行高质量翻译。该模型使用前缀 token(类似于特殊的 [CLS] token)来指示源语言和目标语言。
4. BigBird
由于注意力机制的二次内存要求,Transformer 模型的一个主要限制是最大上下文大小。BigBird 通过使用线性扩展的稀疏注意力形式来解决这个问题。这允许上下文从大多数 BERT 模型中的 512 个 token 大幅扩展至 BigBird 中的 4096 个。这在需要保留长依赖性的情况下特别有用,例如在文本摘要中。
参考:PyTorch研习社