在之前的文章《2024 年,一个大数据从业者决定……》《存储技术背后的那些事儿》中,我们粗略地回顾了大数据领域的存储技术。在解决了「数据怎么存」之后,下一步就是解决「数据怎么用」的问题。
其实在大数据技术兴起之前,对于用户来讲并没有存储和计算的区分,都是用一套数据库或数据仓库的产品来解决问题。而在数据量爆炸性增长后,情况就变得不一样了。单机系统无法存储如此之多的数据,先是过渡到了分库分表这类伪分布式技术,又到了 Hadoop 时代基于分布式文件系统的方案,后来又到了数据库基于一致性协议的分布式架构,最终演进为现在的存算分离的架构。
最近十几年,Data Infra 领域的计算技术以及相关公司层出不穷,最终要解决的根本问题其实只有一个:如何让用户在既灵活又高效,架构既简单又兼具高扩展性,接口既兼容老用户习惯、又能满足新用户场景的前提下使用海量数据。
解读一下,需求如下:
数据量大、数据种类多、数据逻辑复杂
支持 SQL 接口,让习惯了 SQL 接口的 BI 老用户们实现无缝迁移,同时要想办法支持 AI 场景的接口——Python
交互式查询延迟要低,能支持复杂的数据清洗任务,数据接入要实时
架构尽量简单,不要有太多的运维成本,同时还能支持纵向、横向的水平扩展,有足够的弹性
据太可研究所(techinstitute)所知,目前市面上没有哪款产品能同时满足以上所有要求,如果有,那一定是骗人的。所以在计算领域诞生了众多计算引擎、数据库、计算平台、流处理、ETL 等产品,甚至还有一个品类专门做数据集成,把数据在各个产品之间来回同步,对外再提供统一的接口。
不过,如果在计算领域只能选一个产品作为代表,那毫无疑问一定是 Spark。从 09 年诞生起到现在,Spark 已经发布至 3.5.0 版本,社区依旧有很强的生命力,可以说穿越了一个技术迭代周期。它背后的商业公司 Databricks 已经融到了 I 轮,估值 430 亿💲,我们不妨沿着 Spark 的发展历史梳理一下计算引擎技术的变革。
Vol.1
大数据计算的场景主要分两类,一是离线数据处理,二是交互式数据查询。离线数据处理的的特点产生的数据量大、任务时间长(任务时长在分钟级甚至是小时级),主要对应数据清洗任务;交互式查询的特点是任务时间短、并发大、输出结果小,主要对应 BI 分析场景。
时间拨回 2010 年之前,彼时 Spark 还没开源,当时计算引擎几乎只有 Hadoop 配套的 MapReduce 可以用,早年间手写 MapReduce 任务是一件门槛很高的事情。MapReduce 提供的接口非常简单,只有 mapper、reducer、partitioner、combiner 等寥寥几个,任务之间传输数据只有序列化存到 hdfs 这一条路,而真实世界的任务不可能只有 Word Count 这种 demo。所以要写好 MapReduce 肯定要深入理解其中的原理,要处理数据倾斜、复杂的参数配置、任务编排、中间结果落盘等。现在 MapReduce 已经属于半入土的技术了,但它还为业界留下了大量的徒子徒孙,例如各个云厂商的 EMR 产品,就是一种传承。
Spark 开源之后为业界带来了新的方案,RDD 的抽象可以让用户像正常编写代码一样写分布式任务,还支持 Python、Java、Scala 三种接口,大大降低了用户编写任务的门槛。总结下来,Spark 能短时间内获得用户的青睐有以下几点:
更好的设计,包括基于宽窄依赖的 dag 设计,能大大简化 job 编排
性能更高,计算在内存而非全程依赖 hdfs,这是Spark 早期最大的卖点,直到 Spark2.x 的官网上还一直放着一张和 mapreduce 的性能对比,直到这几年没人关心 mapreduce 之后才撤掉
更优雅的接口,RDD 的抽象以及配套的 API 更符合人类的直觉
API 丰富,除了 RDD 和配套的算子,还支持了Python 接口,这直接让受众提升了一个数量级
但早期的 Spark 也有很多问题,例如内存管理不当导致程序 OOM、数据倾斜问题、继承了 Hadoop 那套复杂的配置。Spark 诞生之初非常积极地融入 Hadoop 体系,例如,代码里依赖了大量 Hadoop 的包,文件系统和文件访问接口沿用了 Hadoop 的设计,资源管理一开始只有 Hadoop 的 Yarn。直到现在这些代码依旧大量使用,未来也不可能再做修改,所以说尽管 Hadoop 可能不复存在,但 Hadoop 的代码会一直保留下去,在很多计算引擎里面发挥着不可替代的作用。
Vol.2
无论是非常难用的 MapReduce 接口,还是相对没那么难用的 Spark RDD 接口,受众只是研发人员,接口是代码。
无论是做数据清洗的数据工程师,还是使用 BI 的数据分析师,最熟悉的接口还是 SQL。
因此,市面上便诞生了大量 SQL on Hadoop 的产品,很多产品直到现在也还很有生命力。
最早出现的是 Hive,Hive 的影响力在大数据生态里太大,大到很多人都以为它是 Hadoop 原生自带的产品,不知道它是 Facebook 开源的。Hive 主要的能力只有一个就是把 SQL 翻译成 MapReduce 任务,这件事说来简单,好像也就是本科生大作业的水平,但想把它做好却是件非常有挑战性的工作,早期也只有 Hive 做到了,而且成为了事实上的标准。
要把 SQL 翻译成 MapReduce 任务,需要有几个必备组件,一是 SQL 相关的 Parser、Planner、Optimizer、Executor,基本上是一个 SQL 数据库的标配,二是 metadata,需要存储数据库、表、分区等信息,以及表和 HDFS数据之间的关系。
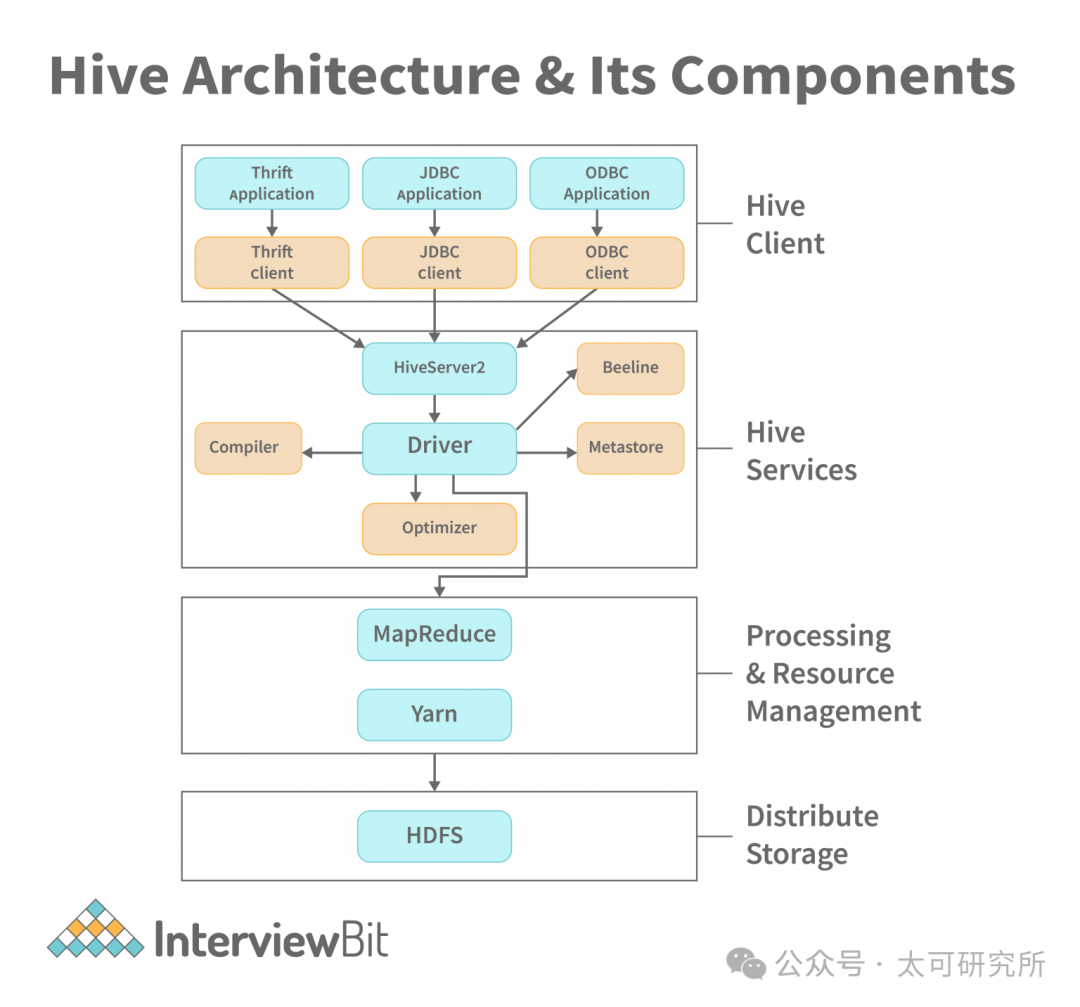 图源|https://www.interviewbit.com/blog/hive-architecture/
图源|https://www.interviewbit.com/blog/hive-architecture/
Hive 的这套思路影响了后来众多的计算引擎,例如 Spark SQL、Presto 等默认都会支持 Hive Metastore。Hive 的架构最大的瓶颈就在 MapReduce 上,无法做到低延迟的查询,也就无法解决用户低延迟、交互式分析的需求。有个很直观的例子,每次用户提交一个 Hive 查询,可以去喝一杯咖啡再回来看结果。此外,哪怕是离线数据清洗的任务使用 Hive 也相对较慢。
Spark 在 2012 年发布的 0.8 版本中开发了 Spark SQL 模块,类似 Hive 的思路,把 SQL 编译成 RDD 任务,同时期的 Presto 也进入了 Apache 孵化器,目标也是解决大数据场景下交互式分析的场景。Spark 和 Presto 支持 SQL 的时间相仿,但后来走上了相当不同的道路,Presto 的定位更接近一个 OLAP 数据库,重心在交互式查询场景,而 Spark 则将注意力放在数据处理任务上,是一个开发分布式任务的框架,自始至终都不是一个完整的数据库,市面上基于 Spark 开发的数据库产品,倒是有不少。
通过 SQL 交互在 10 年代早期,逐渐变成了主流使用大数据产品的主流范式,包括离线任务、交互式查询的接口都逐渐统一到了SQL。随着数据量进一步增长,查询性能一直解决得不好,哪怕是 Spark SQL、Presto,也只能把延迟降低到分钟级别,还是远远无法满足业务的需求。
这种情况直到 2015 年 Kylin 开源才得以解决,基于Cube、预计算技术第一次将大数据领域的交互式查询延迟降低到了秒级,做到了和传统数仓达类似的查询体验。但 kylin 的做法代价也很大,用户需要自定义各种模型、Cube、维度、指标等等概念非常复杂,还要学会设计 rowkey 否则性能也不会很好。Kylin 的出现让业界看到了秒级延迟的可能性,至此内业一些同学甚至觉得大数据场景下 Hadoop + Hive + Spark + Kylin + HBase 可能就是最优解了,顶多还需要加上 Kafka + Flink 去解决实时数据的问题。
但是,2018 年 Clickhouse 横空出世,通过 SIMD、列存、索引优化、数据预热等一系列的暴力优化,竟然也可把查询延迟降低到秒级,而且架构极其简单,只要 Zookeeper + Clickhouse,就能解决上面一堆产品叠加才可解决的问题。这一下子戳中了 Hadoop 体系的痛点——Hadoop 体系产品太多、架构太复杂、运维困难。
自 ClickHouse 后,数据库产品们便开始疯狂吸收其优秀经验,大数据和数据库两个方向逐渐融合,业界重新开始思考「大数据技术真的需要单独的一个体系吗?」「Hadoop 的方向是对的吗?」「数据库能不能解决海量数据的场景?」这个话题有点宏大,可以放在以后讨论。
Vol.3
说回计算引擎,早期的引擎无论是 Hive 也好,Spark 的 RDD 接口也罢,都不适合实时的数据写入。而在大数据技术演进的这些年里,用户的场景也越来越复杂。早期的离线计算引擎只能提供离线数据导入,这就使得用户只能做 T+1 或近似 T+0 的分析。但很多场景需要的是实时分析,到现在,实时分析已经成为了新引擎的标配。
Spark 在 0.9 本版里提供了一套 Spark streaming 接口尝试解决实时的问题,但扒开 Spark streaming 的代码,不难发现它实际上是一段时间触发一个微批任务,对于延迟没那么敏感的用户其实已经够用了。当然也有想要近乎没有延迟的用户,例如金融交易监控、广告营销场景、物联网的场景等。
实时流数据的难度要远高于批处理,首先,如何做到低延迟就是个难点。其次,流数据本身质量远低于批数据,具体体现在流数据会有乱序、数据丢失、数据重复的问题。此外,要做流处理还需要确保任务能长期稳定地运行,这与批处理任务跑完就结束对稳定性的要求很不一样。最后,还有很复杂的数据状态管理,包括 checkpoint 管理、增量更新、状态数据一致性、持久化的问题。
Apache Flink 对这些问题解决的远比 Spark streaming 要好,所以在很长时间内 Flink 就是流计算的代名词。Spark 直到 2.0 发布了 structured streaming 模块之后,才有了和 Flink 同台竞技的资格。Flink 虽然在流计算场景里是无可争议的领导者,但在流计算的场景和市场空间远小于离线计算、交互式分析的市场。可以这样认为,其在数据分析领域锦上添花的功能而非必备能力,Flink 背后的团队和 Databricks 差距也很大,曾创业两次,又先后卖给阿里和 Confluent,这可能也是 Flink 的影响力远小于 Spark 的原因。
好了,本次的大数据计算技术漫谈(上)就先谈到这里,下周同一时间,咱们继续!
本文由 mdnice 多平台发布





![[AIGC] 使用Curl进行网络请求的常见用法](https://img-blog.csdnimg.cn/direct/8ea76ace68f74711a52fd98229319846.png)