得物面试:Kafka消息0丢失,如何实现?
尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题:
Kafka消息0丢失,如何实现?
kafka如何保证消息不丢失?
最近有小伙伴在面试得物,又遇到了相关的面试题。小伙伴懵了,因为没有遇到过,所以支支吾吾的说了几句,面试官不满意,面试挂了。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V140版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到文末公号【技术自由圈】获取

消息的发送流程
一条消息从生产到被消费,将会经历三个阶段:
- 生产阶段,Producer 新建消息,而后经过网络将消息投递给 MQ Broker
- 存储阶段,消息将会存储在 Broker 端磁盘中
- 消息阶段, Consumer 将会从 Broker 拉取消息
以上任一阶段, 都可能会丢失消息,只要这三个阶段0丢失,就能够完全解决消息丢失的问题。
生产阶段如何实现0丢失方式
从架构视角来说, kafka 生产者之所以会丢消息,和Producer 的高吞吐架构有关。
Producer 的高吞吐架构
Producer 的高吞吐架构: 异步发生+ 批量发送。
Kafka的Producer发送消息采用的是异步发送的方式。
在消息发送的过程中,涉及到了两个线程和一个队列:
- 业务线程 和 Sender线程
- 以及一个消息累积器 : RecordAccumulator。

Kafka Producer SDK会创建了一个消息累积器 RecordAccumulator,里边使用 双端队列 缓存消息, 业务线程 将消息加入到 RecordAccumulator ,业务线程就返回了。
这就是业务发送的妙处, 注意, 业务线程就返回了,但是底层的发送工作,还没开始。
谁来负责底层发送呢? Sender线程。
Sender线程不断从 RecordAccumulator 中拉取消息,负责发送到Kafka broker。

这回我们明白了, 原来机关在这里:
-
kafka在发送消息时,是由底层的SEND线程进行消息的批量发送,不是由业务代码线程执行发送的。
-
业务代码线程执行完send方法后,就返回了。
很多小伙伴 没有写个kafka发消息的代码,下面有一个demo,大家一看就明白了:
package org.example;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
Producer<String, String> producer = getProducer();
// Kafka 主题名称
String topic = "mytopic";
// 发送消息
String message = "Hello, Kafka!";
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
producer.send(record);
// 关闭 Kafka 生产者
producer.close();
}
private static Producer<String, String> getProducer() {
Properties properties = getProperties();
// 创建 Kafka 生产者
Producer<String, String> producer = new KafkaProducer<>(properties);
return producer;
}
private static Properties getProperties() {
// Kafka 服务器地址和端口
String bootstrapServers = "localhost:9092";
// Kafka 生产者配置
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
return properties;
}
}
消息到底发送给broker侧没有了?通过send方法其实是无法知道的。
上面的代码,创建消息之后,就开始发送消息了
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
producer.send(record);
其实,如果要想知道发现的结果,可以通过send方法的 Future实例去实现:
Future<RecordMetadata> future = producer.send(record);
Producer#send方法是一个异步方法,即它会立即返回一个Future对象,而不会等待消息发送完成。
可以使用Future对象来异步处理发送结果,例如等待发送完成或注册回调函数来处理结果。具体的办法是,给Future去注册回调函数处理结果,这样可以实现非阻塞的方式处理发送完成的回调。
Future去注册回调函数处理结果,下面是一个示例代码:
future.addCallback(new ListenableFutureCallback<RecordMetadata>() {
@Override
public void onSuccess(RecordMetadata metadata) {
System.out.println("消息发送成功,分区:" + metadata.partition() + ",偏移量:" + metadata.offset());
}
@Override
public void onFailure(Throwable ex) {
System.err.println("消息发送失败:" + ex.getMessage());
}
});
还没有其他的方法, 获取发送的处理结果呢?
其实,Producer#send方法有两个重载版本, 具体如下:
Future<RecordMetadata> send(ProducerRecord<K, V> record)
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)
除了上面尼恩给大家介绍的是一个参数的版本, 实际上还有一个两个参数的版本:
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)
通过这个版本, 大家可以注册回调函数的方式,完成发送结果的处理。通过回调函数版本,更好的实现非阻塞的方式处理发送完成的回调。
参考的代码如下:
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("Error sending message: " + exception.getMessage());
} else {
System.out.println("Message sent successfully! Topic: " + metadata.topic() +
", Partition: " + metadata.partition() + ", Offset: " + metadata.offset());
}
}
});
通过这个callback回调函数版本的send方法,如果Producer底层的send线程发送给broker端成功/(失败的)了,都可以回调callback函数,通知上层业务应用。
一般来说,大家在callback函数里,根据回调函数的参数,就能知道消息是否发送成功了,如果发送失败了,那么我们还可以在callback函数里重试。
Producer(生产者)保证消息不丢失的方法:
如果要保证 Producer(生产者)0 丢失, Producer 端的策略是啥呢?
尼恩从40岁老架构师的视角,给大家出个狠招, 包括下面的三板斧:
-
Producer一板斧:设置最高可靠的、最为严格的发送确认机制
-
Producer二板斧:设置严格的消息重试机制,比如增加重试次数
-
Producer三板斧:本地消息表+定时扫描

Producer一板斧:设置最高可靠的、最为严格的发送确认机制
Producer可以使用Kafka的acks参数来配置发送确认机制。这个acks参数用来指定分区中必须要有多少个副本收到这条消息,之后生产者才会认为这条消息是成功写入的。通过设置合适的acks参数值,Producer可以在消息发送后等待Broker的确认。
确认机制提供了不同级别的可靠性保证,包括:
- acks=0:Producer在发送消息后不会等待Broker的确认,这可能导致消息丢失风险。
- acks=1:Producer在发送消息后等待Broker的确认,确保至少将消息写入到Leader副本中。
- acks=all或acks=-1:Producer在发送消息后等待Broker的确认,确保将消息写入到所有ISR(In-Sync Replicas)副本中。这提供了最高的可靠性保证。
尼恩提示:由于acks 是生产者客户端中一个非常重要的参数,它涉及消息的可靠性和吞吐量之间的权衡,所以非常重要。
下面对于acks 参数的3种类型的值(都是字符串类型), 更加详细的介绍一下。
- acks = 1。默认值即为1。生产者发送消息之后,只要分区的 leader 副本成功写入消息,那么它就会收到来自服务端的成功响应。如果消息无法写入 leader 副本,比如在 leader 副本崩溃、重新选举新的 leader 副本的过程中,那么生产者就会收到一个错误的响应,为了避免消息丢失,生产者可以选择重发消息。如果消息写入 leader 副本并返回成功响应给生产者,且在被其他 follower 副本拉取之前 leader 副本崩溃,那么此时消息还是会丢失,因为新选举的 leader 副本中并没有这条对应的消息。acks 设置为1,是消息可靠性和吞吐量之间的折中方案。
- acks = 0。生产者发送消息之后不需要等待任何服务端的响应。如果在消息从发送到写入 Kafka 的过程中出现某些异常,导致 Kafka 并没有收到这条消息,那么生产者也无从得知,消息也就丢失了。在其他配置环境相同的情况下,acks 设置为0可以达到最大的吞吐量。
- acks = -1 或 acks = all。生产者在消息发送之后,需要等待 ISR 中的所有副本都成功写入消息之后才能够收到来自服务端的成功响应。在其他配置环境相同的情况下,acks 设置为 -1(all) 可以达到最强的可靠性。但这并不意味着消息就一定可靠,因为ISR中可能只有 leader 副本,这样就退化成了 acks=1 的情况。要获得更高的消息可靠性需要配合 min.insync.replicas 等参数的联动,消息可靠性分析的具体内容可以参考《图解Kafka之核心原理》。
注意 acks 参数配置的值是一个字符串类型,而不是整数类型。举个例子,将 acks 参数设置为0,需要采用下面这两种形式:
properties.put("acks", "0");
# 或者
properties.put(ProducerConfig.ACKS_CONFIG, "0");
设置最高可靠的发送确认机制,通过设置acks参数来控制消息的确认方式。
acks参数可以设置为"all"或者 -1,表示要求所有副本都确认消息,这样可以最大程度地保证消息的可靠性。
properties.put(ProducerConfig.ACKS_CONFIG, "all");
# 或者
properties.put(ProducerConfig.ACKS_CONFIG, "-1");
Producer二板斧:设置严格的消息重试机制,包括增加重试次数
很多消息,因为临时的网络问题或Broker故障而丢失。通过消息重试机制,可以保证消息不会因为临时的网络问题或Broker故障而丢失。
消息在从生产者发出到成功写入服务器之前可能发生一些临时性的异常,比如网络抖动、leader 副本的选举等,这种异常往往是可以自行恢复的,生产者可以通过配置 retries 大于0的值,以此通过内部重试来恢复而不是一味地将异常抛给生产者的应用程序。
所以,如果发送失败,Producer可以重新发送消息,直到成功或达到最大重试次数。
消息重试机制涉及到两个参数:
- retries
- retry.backoff.ms
下面有个例子(这里重试配置了 10 次,重试10 次之后没有答复,就会抛出异常,并且,下面的例子每一次重试直接的时间间隔是1秒):

retries 参数用来配置生产者重试的次数,默认值为0,也就是说,默认情况下,在发生异常的时候不进行任何重试动作。
retries 参数设置之后,如果重试达到设定的retries 次数,那么生产者就会放弃重试并返回异常。
当然,retries 重试还和另一个参数 retry.backoff.ms 有关,这个参数的默认值为100,它用来设定两次重试之间的时间间隔,默认为100ms,避免无效的频繁重试。
在配置 retries 和 retry.backoff.ms 之前,最好先估算一下可能的异常恢复时间,这样可以设定总的重试时间大于这个异常恢复时间,以此来避免生产者过早地放弃重试。
Producer三板斧:本地消息表+定时扫描
40岁老架构师尼恩慎重提示:前面两板斧,并不能保证100%的0丢失。
为啥呢?因为 broker端是异步落盘机制,异步落盘待会详细分析。总之,异步落盘就是broker 消息没有落盘,就返回结果的。
虽然第一板斧设置了最为严格的确认机制,在这里,尼恩提醒大家一个极端情况: 哪怕全部的broker 返回了确认结果, 消息也不一定落盘和被投递出去,如果broker 集体断电,还是丢了。
所以说:仅仅依靠回调函数的、设置最高可靠的确认机制,设置最重的重试策略,还是不能保证消息一定被consumer消费的。
另外,callback函数也是不可靠的。比如,刚好遇到在执行回调函数时,jvm OOM/ jvm假死的情况;那么回调函数是不能被执行的。
如何实现极端严格的场景下消息0丢失?尼恩告诉大家,可以和本地消息表事务机制类似,采用 本地消息表+定时扫描 的架构方案。
大概流程如下图

1、设计一个本地消息表,可以存储在DB里,或者其它存储引擎里,用户保存消息的消费状态
2、Producer 发送消息之前,首先保证消息的发生状态,并且初始化为待发送;
3、如果消费者(如库存服务)完成的消费,则通过RPC,调用Producer 去更新一下消息状态;
4、Producer 利用定时任务扫描 过期的消息(比如10分钟到期),再次进行发送。
在这里尼恩想说的是: 本地消息表+定时扫描 的架构方案 ,是业务层通过额外的机制来保证消息数据发送的完整性,是一种很重的方案。 这个方案的两个特点:
-
CP 不是 AP,性能低
-
需要 做好幂等性设计
CP 不是 AP的 需要权衡,请参见全网最好的架构设计个黄金法则,尼恩的 专门文章具体如下:
一张图总结架构设计的40个黄金法则
全网最好的幂等性 方案,请参见尼恩的 专门文章, 具体如下:
最系统的幂等性方案:一锁二判三更新

Broker端保证消息不丢失的方法:
首先,尼恩想说正常情况下,只要 Broker 在正常运行,就不会出现丢失消息的问题。但是如果 Broker 出现了故障,比如进程死掉了或者服务器宕机了,还是可能会丢失消息的。
如果确保万无一失,实现Broker端保证消息不丢失,有两板斧:
- Broker端第一板斧:设置严格的副本同步机制
- Broker端第二板斧:设置严格的消息刷盘机制

Broker端第一板斧:设置严格的副本同步机制
kafka应对此种情况,建议是通过多副本机制来解决的,核心思想也挺简单的:如果数据保存在一台机器上你觉得可靠性不够,那么我就把相同的数据保存到多台机器上,某台机器宕机了可以由其它机器提供相同的服务和数据。
要想达到上面效果,有三个关键参数需要配置
-
第1:在broker端 配置 min.insync.replicas参数设置至少为2
此参数代表了 上面的“大多数”副本。为2表示除了写入leader分区外,还需要写入到一个follower 分区副本里,broker端才会应答给生产端消息写入成功。此参数设置需要搭配第一个参数使用。 -
第2:在broker端配置 replicator.factor参数至少3
此参数表示:topic每个分区的副本数。如果配置为2,表示每个分区只有2个副本,在加上第二个参数消息写入时至少写入2个分区副本,则整个写入逻辑就表示集群中topic的分区副本不能有一个宕机。如果配置为3,则topic的每个分区副本数为3,再加上第二个参数min.insync.replicas为2,即每次,只需要写入2个分区副本即可,另外一个宕机也不影响,在保证了消息不丢的情况下,也能提高分区的可用性;只是有点费空间,毕竟多保存了一份相同的数据到另外一台机器上。 -
第3:unclean.leader.election.enable
此参数表示:没有和leader分区保持数据同步的副本分区是否也能参与leader分区的选举,建议设置为false,不允许。如果允许,这这些落后的副本分区竞选为leader分区后,则之前leader分区已保存的最新数据就有丢失的风险。注意在0.11版本之前默认为TRUE。
所以,通过如下配置来保证Broker消息可靠性:
- default.replication.factor:设置为大于等于3,保证一个partition中至少有两个Replica,并且replication.factor > min.insync.replicas
- min.insync.replicas:设置为大于等于2,保证ISR中至少有两个Replica
- unclean.leader.election.enable=false,那么就意味着非ISR中的副本不能够参与选举,避免脏Leader。

Kafka的ISR机制可自动动态调整同步复制的Replica,将慢(可能是暂时的慢)Follower踢出ISR,将同步赶上的Follower拉回ISR,避免最慢的Follower拖慢整体速度,最大限度地兼顾了可靠性和可用性。
Broker端第二板斧:设置严格的消息刷盘机制
无论是kafka、Rocketmq、还是Mysql,为了提升底层IO的写入性能,都会用到操作系统的 Page Cache 技术。注意,这里的 Page Cache 是操作系统提供的缓存机制。具体请参考尼恩的架构视频《葵花宝典》。
我们的kafka、Rocketmq、Mysql程序 在读写磁盘文件时,其实操作的都是内存,然后由操作系统决定什么时候将 Page Cache 里的数据真正刷入磁盘。如果 Page Cache 内存中数据还未刷入磁盘,而我们的服务器宕机了,这个时候还是会丢消息的。
刷盘的方式有同步刷盘和异步刷盘两种。
-
同步刷盘指的是:生产者消息发过来时,只有持久化到磁盘,RocketMQ、kafka的存储端Broker才返回一个成功的ACK响应,这就是同步刷盘。它保证消息不丢失,但是影响了性能。
-
异步刷盘指的是:消息写入PageCache缓存,就返回一个成功的ACK响应,不管消息有没有落盘,就返回一个成功的ACK响应。这样提高了MQ的性能,但是如果这时候机器断电了,就会丢失消息。
同步刷盘和异步刷盘的区别如下:
- 同步刷盘:当数据写如到内存中之后立刻刷盘(同步),在保证刷盘成功的前提下响应client。
- 异步刷盘:数据写入内存后,直接响应client。异步将内存中的数据持久化到磁盘上。
同步刷盘和异步输盘的优劣:
- 同步刷盘保证了数据的可靠性,保证数据不会丢失。
- 同步刷盘效率较低,因为client获取响应需要等待刷盘时间,为了提升效率,通常采用批量输盘的方式,每次刷盘将会flush内存中的所有数据。(若底层的存储为mmap,则每次刷盘将刷新所有的dirty页)
- 异步刷盘不能保证数据的可靠性.
- 异步刷盘可以提高系统的吞吐量.
- 常见的异步刷盘方式有两种,分别是定时刷盘和触发式刷盘。定时刷盘可设置为如每1s刷新一次内存.触发刷盘为当内存中数据到达一定的值,会触发异步刷盘程序进行刷盘。
Broker端第二板斧:设置严格的消息刷盘机制,设置为Kafka同步刷盘。
如何设置Kafka同步刷盘?
网上有一种说法,kafka不支持同步刷盘,这种说法,实际上是错的。
为啥了?可以通过参数的配置变成同步刷盘
log.flush.interval.messages //page cache里边多少条消息刷盘1次 ,默认值 LONG.MAX_VALUE
log.flush.interval.ms //隔多长时间刷盘1次,默认值 LONG.MAX_VALUE
log.flush.scheduler.interval.ms //周期性的刷盘,缺省3000,即3s。
源码里边,有这些参数的注释:
public static final String FLUSH_MESSAGES_INTERVAL_CONFIG = "flush.messages";
public static final String FLUSH_MESSAGES_INTERVAL_DOC = "This setting allows specifying an interval at " +
"which we will force an fsync of data written to the log 多少消息刷盘. For example if this was set to 1 we would fsync after every message 设置为1 就是1条消息就刷盘,也就是同步刷盘模式; if it were 5 we would fsync after every five messages. " +
"In general we recommend you not set this and use replication for durability and allow the " +
"operating system's background flush capabilities as it is more efficient. This setting can " +
"be overridden on a per-topic basis (see <a href=\"#topicconfigs\">the per-topic configuration section</a>).";
public static final String FLUSH_MS_CONFIG = "flush.ms";
public static final String FLUSH_MS_DOC = "This setting allows specifying a time interval at which we will " +
"force an fsync of data written to the log. For example if this was set to 1000 " +
"we would fsync after 1000 ms had passed. In general we recommend you not set " +
"this and use replication for durability and allow the operating system's background " +
"flush capabilities as it is more efficient.";
如果要同步刷盘,可以使用下面的配置:
# 当达到下面的消息数量时,会将数据flush到日志文件中。默认10000
#log.flush.interval.messages=10000
# 当达到下面的时间(ms)时,执行一次强制的flush操作。interval.ms和interval.messages无论哪个达到,都会flush。默认3000ms
#log.flush.interval.ms=1000
# 检查是否需要将日志flush的时间间隔
log.flush.scheduler.interval.ms = 3000
CP 不是 AP,CP性能很低,请参见全网最好的架构设计个黄金法则,尼恩的 专门文章具体如下:
一张图总结架构设计的40个黄金法则
设置了同步刷盘后,在掉电的情况下,数据是不丢失了,但是,kafka 吞吐量降低到了 500tps 以下。

而异步刷盘, 吞吐量 的单节点在 10000W以上,差异巨大的。
注意,同步刷盘,性能 足足相差20倍。

注意: 尼恩没有做对比测试,上面的数据,来自于互联网一个小伙伴的对比测试。 有兴趣的小伙伴,可以自己试试。
40岁老架构尼 恩提示:还是那句老化,CP 不是 AP的 需要权衡,请参见全网最好的架构设计40个黄金法则,尼恩的 专门文章具体如下:
一张图总结架构设计的40个黄金法则
Consumer(消费者)保证消息不丢失的方法:
如果要保证 Consumer(消费者)0 丢失, Consumer 端的策略是啥呢?
这个比较简单,只要一招就够:消费成功之后,手动ACK提交消费位移(位点)。
这一招分为两步:
-
设置enable.auto.commit 为 false
-
commitSync() 和 commitAsync() 组合使用进行手动提交

什么是Consumer 位移
Consumer 程序有个“位移”(/位点)的概念,表示的是这个 Consumer 当前消费到的 Topic Partion分区的位置。
下面这张图来自于官网,它清晰地展示了 Consumer 端的位移数据。
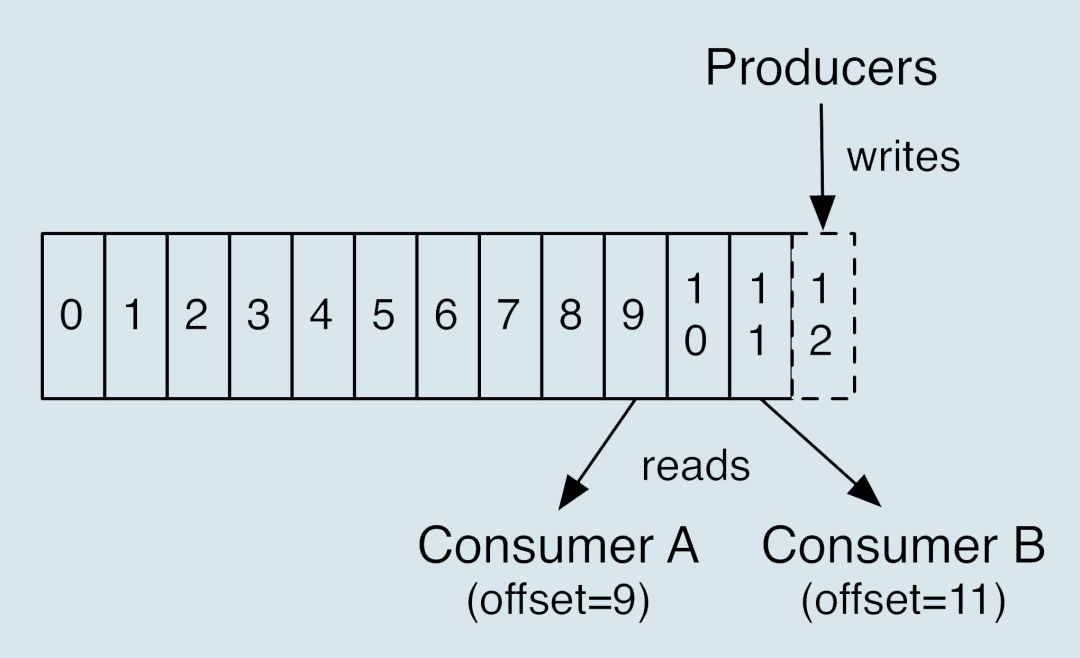
enable.auto.commit=false 关闭自动提交位移,消息处理完成之后再提交offset
consumer端需要为每个它要读取的分区保存消费进度,即分区中当前消费消息的位置,该位置称为位移(offset)。每个Consumer Group独立维护offset,互不干扰,不存在线程安全问题。kafka中的consumer group中使用一个map来保存其订阅的topic所属分区的offset:

实际上,这里的位移值通常是下一条待消费的消息的位置,因为位移是从0开始的,所以位移为N的消息其实是第N+1条消息。在consumer中有如下位置信息:

-
上次提交位移:consumer最后一次提交的offset值;
-
当前位置:consumer已经读取,但尚未提交时的位置;
-
水位:也称为高水位,代表consumer是否可读。对于处于水位以下(水位左侧)的所有消息,consumer是可以读取的,水位以上(水位又侧)的消息consumer不读取;
-
日志最新位移:也称日志终端位移,表示了某个分区副本当前保存消息对应的最大位移值。
consumer需要定期向Kafka提交自己的位置信息,这一过程称为位移提交(offset commit)。
consumer提交的对象,叫做 coordinator。
consumer会在所有的broker中选择一个broker作为consumer group的coordinator,coordinator用于实现组成员管理、消费分配方案制定以及位移提交等。
如何选择coordinator,依据就是kafka的内置topic(_consumer_offsets)。内置_consumer_offsets 的topic与普通topic一样,配置多个分区,每个分区有多个副本,它存在的唯一目的就是保存consumer提交的位移。
当消费者组首次启动的时候,由于没有初始的位移信息,coordinator需要为其确定初始位移值,这就是consumer参数 auto.offset.reset 的作用,通常情况下,consumer要么从最开始位移开始读取。
当cosumer运行一段时间之后,就需要提交自己的位移信息,如果consumer奔溃或者被关闭,它负责的分区就会被分配给其他consumer,因此一定要在其他consumer读取这些分区前,就做好位移提交,否则会出现重复消费。
consumer提交位移的主要机制,也是发消息实现的。具体来说,是通过向所属的coordinator发送位移提交请求消息来实现的。
每个位移提交请求都会向_consumer_offsets对应分区写入一条消息,消息的key是group.id,topic和分区的元组,value是位移值。
如果consumer为同一个group的同一个topic分区提交了多次位移,那么只有最新的那次提交的位移值是有效的,其余几次提交的位移值都已经过期,Kafka通过压实(compact)策略来处理这种消息使用模式,
consumer提交位移,有两大模式:
- 自动提交位移:Consumer可以选择启用自动提交位移的功能。当Consumer成功处理一批消息后,它会自动提交当前位移,标记为已消费。这样即使Consumer发生故障,它可以使用已提交的位移来恢复并继续消费之前未处理的消息。
- 手动提交位移:Consumer还可以选择手动提交位移的方式。在消费一批消息后,Consumer可以显式地提交位移,以确保处理的消息被正确记录。这样可以避免重复消费和位移丢失的问题。
Consumer 端有个参数 enable.auto.commit(默认值就是 true),把它设置为 true , 就是自动提交位移的。
自动提交的参考代码如下:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "2000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserialprops.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeseriKafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while(true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(),
}
和自动提交配合的参数,还有一个 auto.commit.interval.ms。它的默认值是 5 秒,表明 Kafka 每 5 秒会为你自动提交一次位移。
高并发场景,一定是多线程异步消费消息,自动提交就不管有没有消费成功, 位点都提交了,所以为了保证0丢失,消费者 Consumer 程序不要开启自动提交位移,而是要应用程序手动提交位移。
开启手动提交位移的方法就是设置enable.auto.commit 为 false。
但是,仅仅设置它为 false 还不够,这个配置只是告诉Kafka Consumer 不要自动提交位移而已,应用程序还需要调用相应的 API 手动提交位移。
手动提交位移的 API,一个最简单的是 同步提交位移,KafkaConsumer#commitSync()。该方法会提交KafkaConsumer#poll() 返回的最新位移。
下面这段代码展示了 commitSync() 的使用方法:
下面是手动提交位移的例子:
while(true) {
ConsumerRecords<String, String>records=
consumer.poll(Duration.ofSeconds(1));
process(records);
//处理消息
try {
consumer.commitSync();
}
catch (CommitFailedException e) {
handle(e);
//处理提交失败异常
}
}
可见,调用 consumer.commitSync() 方法的时机,是在你处理完了 poll() 方法返回的所有消息之后。
KafkaConsumer#commitSync() 它是一个同步操作,即该方法会一直等待,直到位移被成功提交才会返回。如果提交过程中出现异常,该方法会将异常信息抛出。
除了同步提交,Kafka 社区为手动提交位移提供了另一个异步 API 方法:KafkaConsumer#commitAsync()。
异步提交的优势:调用 commitAsync() 之后,它会立即返回,不会阻塞,因此不会影响 Consumer 应用的 TPS。
按照40岁老架构师 尼 恩经验: 异步往往配合了回调,Kafka 提供了回调函数(callback),回调用于处理提交之后的逻辑,比如记录日志或处理异常等。
下面这段代码展示了调用 commitAsync() 的方法:
while(true) {
ConsumerRecords<String, String>records=
consumer.poll(Duration.ofSeconds(1));
process(records);
//处理消息
consumer.commitAsync((offsets, exception) -> {
if(exception != null)
handle(exception);
}
);
如何又能保证 提交的高性能,又能重复利用 commitSync 的自动重试来规避那些瞬时错误(比如网络的瞬时抖动,Broker 端 GC 等)呢?
答案是: commitSync() 和 commitAsync() 组合使用。
它展示的是如何将两个 API 方法commitSync() 和 commitAsync() 组合使用进行手动提交。
try{
while(true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
process(records);
//处理消息
commitAysnc();
//使用异步提交规避阻塞
}
}
catch(Exception e) {
handle(e);
//处理异常
}
finally{
try{
consumer.commitSync();
//最后一次提交使用同步阻塞式提交
}
finally{
consumer.close();
Kafak 0丢失的最佳实践
-
不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。
记住,一定要使用带有回调通知的 send 方法。
-
设置 acks = all 设置最高可靠的、最为严格的发送确认机制。acks 设置成 all,则表明所有副本 Broker 都要接收到消息,该消息才算是“已提交”。这是最高等级的“已提交”定义。
-
设置 retries 为一个较大的值如10,设置严格的消息重试机制,包括增加重试次数。当出现网络的瞬时抖动时,消息发送可能会失败,retries 较大,能够自动重试消息发送,避免消息丢失。
-
Broker 端设置 unclean.leader.election.enable = false。它控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个 Broker 落后原先的 Leader 太多,那么它一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将该参数设置成 false,即不允许这种情况的发生。
-
Broker 端设置 replication.factor >= 3。这里想表述的是,最好将消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余。
-
Broker 端设置 min.insync.replicas > 1。控制的是消息至少要被写入到多少个副本才算是“已提交”。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1。
-
Broker 端设置 replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本挂机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置成 replication.factor = min.insync.replicas + 1。
-
Consumer 端 确保消息消费完成再提交。Consumer 端有个参数 enable.auto.commit 设置成 false,并采用将两个 API 方法commitSync() 和 commitAsync() 组合使用进行手动提交位移的方式。这对于单 Consumer 多线程处理的场景而言是至关重要的。
-
业务维度的的0丢失架构, 采用 本地消息表+定时扫描 架构方案,实现业务维度的 0丢失,100%可靠性。
如上,就是尼恩为大家梳理的,史上最牛掰的 答案, 全网最为爆表的方案。按照尼恩的套取去回到, 面试官一定惊到掉下巴。 offer直接奉上。此答案大家可以收藏一起,有时间看看。

说在最后:有问题找老架构取经
以上的内容,如果大家能对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。
最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,里边有大量的大厂真题、面试难题、架构难题。很多小伙伴刷完后, 吊打面试官, 大厂横着走。
在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来改简历、做帮扶。
遇到职业难题,找老架构取经, 可以省去太多的折腾,省去太多的弯路。
尼恩指导了大量的小伙伴上岸,前段时间,刚指导一个40岁+被裁小伙伴,拿到了一个年薪100W的offer。
狠狠卷,实现 “offer自由” 很容易的, 前段时间一个武汉的跟着尼恩卷了2年的小伙伴, 在极度严寒/痛苦被裁的环境下, offer拿到手软, 实现真正的 “offer自由” 。
尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓



![[AIGC] 使用Curl进行网络请求的常见用法](https://img-blog.csdnimg.cn/direct/8ea76ace68f74711a52fd98229319846.png)