1 数仓分层
1.1 数仓分层的意义
- **数据复用,减少重复开发:**规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。数据的逐层加工原则,下层包含了上层数据加工所需要的全量数据,这样的加工方式避免了每个数据开发人员都重新从源系统抽取数据进行加工。通过汇总层的引人,避免了下游用户逻辑的重复计算, 节省了用户的开发时间和精力,同时也节省了计算和存储。极大地减少不必要的数据冗余,也能实现计算结果复用,极大地降低存储和计算成本。
- **数据血缘追踪:**简单来讲可以这样理解,我们最终给业务呈现的是一张直接使用的业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
- **把复杂问题简单化。**讲一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
1.2 数仓分层规范
数仓从下往上一般分ODS->DWD->DWS-ADS 4层。

2 主流数仓架构
目前主流数据仓库建设主要分两种,基于Lakehouse(湖仓一体)的流批一体架构和基于MPP数据库的轻量级数据仓库。

一个企业数仓的整体逻辑如上图所示,数仓在构建的时候通常需要 ETL 处理和分层设计,基于业务系统采集的结构化和非结构化数据进行各种 ETL 处理成为 DWD 层,再基于 DWD 层设计上层的数据模型层,形成 DM,中间会有 DWB/DWS 作为部分中间过程数据。
从技术选型来说,从数据源的 ETL 到数据模型的构建通常需要长时任务,也就是整个任务的运行时间通常是小时及以上级别。而 DM 层主要是支持业务的需求,对实效性要求比较高,通常运行在 DM 层上的任务时间在分钟作为单位。
基于如上的分层设计的架构图可以发现,虽然目前有非常多的组件,像 Presto,Doris,ClickHouse,Hive 等等,但是这些组件各自工作在不同的场景下,像数仓构建和交互式分析就是两个典型的场景。
交互式分析强调的是时效性,一个查询可以快速出结果,像 Presto,Doris,ClickHouse 虽然也可以处理海量数据,甚至达到 PB 及以上,但是主要还是是用在交互式分析上,也就是基于数据仓库的 DM 层,给用户提供基于业务的交互式分析查询,方便用户快速进行探索。由于这类引擎更聚焦在交互式分析上,因此对于长时任务的支持度并不友好,为了达到快速获取计算结果,这类引擎重度依赖内存资源,需要给这类服务配置很高的硬件资源,这类组件通常有着如下约束:
- 没有任务级的重试,失败了只能重跑 Query,代价较高。
- 一般全内存计算,无 shuffle 或 shuffle 不落盘,无法执行海量数据。
- 架构为了查询速度快,执行前已经调度好了 task 执行的节点,节点故障无法重新调度。
一旦发生任务异常,例如网络抖动引起的任务失败,机器宕机引起的节点丢失,再次重试所消耗的时间几乎等于全新重新提交一个任务,在分布式任务的背景下,任务运行的时间越长,出现错误的概率越高,对于此类组件的使用业界最佳实践的建议也是不超过 30 分钟左右的查询使用这类引擎是比较合适的。
而在离线数仓场景下,几乎所有任务都是长时任务,也就是任务运行时常在小时及以上,这时就要求执行 ETL 和构建数仓模型的组件服务需要具有较高的容错性和稳定性,当任务发生错误的时候可以以低成本的方式快速恢复,尽可能避免因为部分节点状态异常导致整个任务完全失败。
可以发现在这样的诉求下类似于 Presto,Doris,ClickHouse 就很难满足这样的要求,而像 Hive,Spark 这类计算引擎依托于 Yarn 做资源管理,对于分布式任务的重试,调度,切换有着非常可靠的保证。Hive,Spark 等组件自身基于可重算的数据落盘机制,确保某个节点出现故障或者部分任务失败后可以快速进行恢复。数据保存于 HDFS 等分布式存储系统上,自身不管理数据,具有极高的稳定性和容错处理机制。
反过来,因为 Hive,Spark 更善于处理这类批处理的长时任务,因此这类组件不擅长与上层的交互式分析,对于这种对于时效性要求更高的场景,都不能很好的满足。所以在考虑构建数仓的时候,通常会选择 Hive,Spark 等组件来负责,而在上层提供交互式分析查询的时候,通常会使用 Presto,Doris,ClickHouse 等组件。
归纳下来如下:
- **Doris,ClickHouse,Presto:**更注重交互式分析,对单机资源配置要求很高,重度依赖内存,缺乏容错恢复,任务重试等机制,适合于 30 分钟以内的任务,通常工作在企业的 DM 层直接面向业务,处理业务需求。
- **Spark,Hive:**更注重任务的稳定性,对网络,IO 要求比较高,有着完善的中间临时文件落盘,节点任务失败的重试恢复,更加合适小时及以上的长时任务运行,工作在企业的的 ETL 和数据模型构建层,负责清洗和加工上层业务所需要的数据,用来支撑整个企业的数仓构建。
2.1 基于湖仓一体的流批一体架构
目前市面上核心的数据湖开源产品大致有这么几个:Apache Hudi、Apache Iceberg和 Delta。国内使用jiao较多的为Apache Hudi。

此架构可以满足目前业务需求:
- 批处理:采用Spark 进行批处理加工任务
- 流处理:采用Flink + Hudi完成流处理任务
- 交互式分析:离线数据采用导入到Doris或者Doris联邦查询的方式进行交互式分析;实时数据ADS层直接在Doris提供交互式分析能力。
- 机器学习:机器学习应用采用分布式机器学习框架Spark ML进行模型训练。
优点:
-
超大规模大数据平台主流架构,经过主流大厂验证,运行稳定可靠。
-
实时场景支持数仓分层模型,可支持复杂逻辑大量数据的实时增量计算。
-
实时数仓基于 Flink-SQL 实现了流批一体,批处理和流处理同一套代码,代码维护成本低;
-
存储数据多元化,结构化数据、半结构化数据和非结构化数据都能存储。
缺点:
- 组件过多,数据链路长,运维成本高,对开发人员要求高。
- 组件过多,成本高。
2.2 基于MPP数据库的轻量级数据仓库
目前主流开源OLAP MPP数据库有 Doris, ClickHouse, Presto等,尤其以Doris势头强劲。
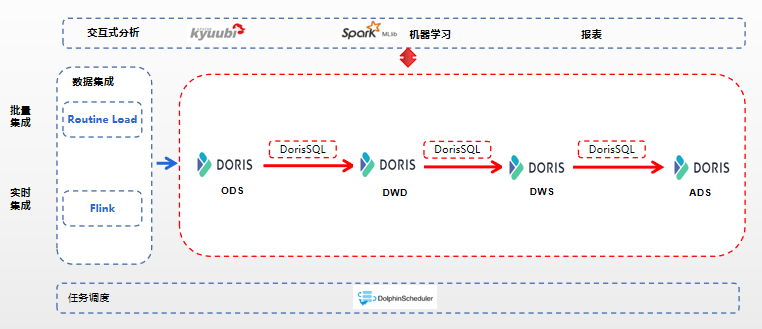
此架构可以满足目前业务需求:
- 批处理:采用DorisSQL进行批处理任务加工。
- 流处理:采用Flink + Doris完成ODS层的实时构建,后面采用DorisSQL定时调度完成增量数据的构建。
- 交互式分析:使用Doris对外提供服务。
- 机器学习:机器学习应用采用分布式机器学习框架Spark ML进行模型训练。但是每次模型训练都需要从Doris中读取数据,给Doris造成压力。
优点:
- 组件单一,数据链路少,运维成本低,对开发人员要求低。
- 组件单一,建设成本低。
缺点:
- 实时场景不支持数仓分层模型
- 批处理也在Doris加工,Doris是基于内存计算的,当大规模数据量进行加工时,容易遇到瓶颈。
2.3 湖仓一体和MPP对比
| 开源数仓架构 | 数据量 | 运维成本 | 开发成本 | 团队人数 |
|---|---|---|---|---|
| 湖仓一体(Hudi) | 0-100PB级 | 高 | 高 | 10人以上 |
| MPP(Doris) | 10PB以下 | 低 | 低 | 10人以下 |

![[经验] 什么是鄱阳湖旅游最主要的景点 #知识分享#知识分享](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fwww.hao123rr.com%2Fzb_users%2Fupload%2F2023%2F05%2F20230519204745168450046518177.jpg&pos_id=g5Ehc0Ar)