1、前言
前面我们在《微调实操一: 增量预训练(Pretraining)》和《微调实操二: 有监督微调(Supervised Finetuning)》实操的两个章节,学习了PT(Continue PreTraining)增量预训练和SFT(Supervised Fine-tuning)有监督微调过程,,今天我们进入第三阶段的微调, 第三阶段微调主流分成2种做法:
1.1 RLHF(Reinforcement Learning from Human Feedback)基于人类反馈对语言模型进行强化学习,分为两步:
1.1.1 RM(Reward Model)奖励模型建模,构造人类偏好排序数据集,训练奖励模型,用来建模人类偏好,主要是"HHH"原则,具体是"helpful, honest, harmless"
1.1.2 RL(Reinforcement Learning)强化学习,用奖励模型来训练SFT模型,生成模型使用奖励或惩罚来更新其策略,以便生成更高质量、更符合人类偏好的文本
1.2 DPO(Direct Preference Optimization): 直接偏好优化方法,DPO通过直接优化语言模型来实现对其行为的精确控制,而无需使用复杂的强化学习,也可以有效学习到人类偏好。
sft阶段解决的是指令微调(instruction Tuning),目标是增强(或解锁)大语言模型的能力。RLHF主要是进行对齐微调, 目标是将大语言模型的行为与人类的价值观或偏好对齐。
2、对齐微调
虽然大语言模型在多个自然语言处理任务上展示出了惊人 的能力。但是, 这些模型有时可能表现出意外的行为,例如制造虚假信息、追求不准确的目标,以及产生有害的、误导性的和偏见性的表达。对于 LLM, 语言建模目标通过单词预测对模型参数进行预训练,但缺乏对人类价值观或偏好的考虑。为了避免这些意外行为,研究提出了人类对齐,使大语言模型行为能够符合人类的期望。但是, 与初始的预训练和适应微调(例如指令微调)不同, 语言模型的对齐需要考虑不同的标准(例如有用性, 诚实性和无害性)。已有研究表明对齐微调可能会在某种程度上损害大语言模型的通用能力,这在相关研究中被称为对齐税。
3、基于人类反馈的强化学习(RLHF)
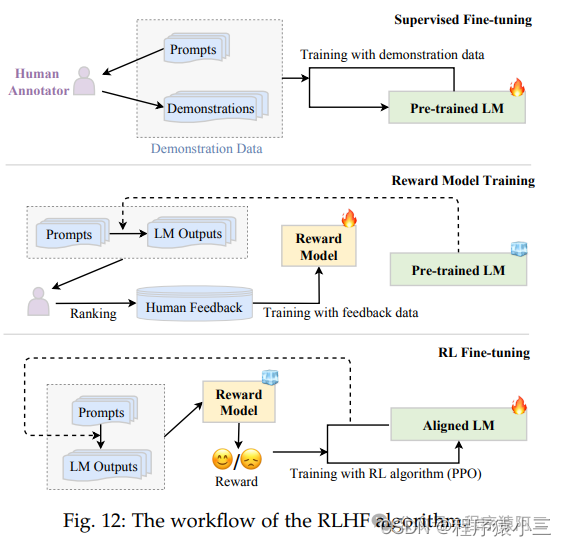
2.1 RM(Reward Model)阶段
第二步是使用人类反馈数据训练 RM(奖励模型)。具体来说,使用 LM 使用采样提示(来自监督数据集或人工生成的提示)作为输入来生成一定数量的输出文本,然后邀请人工标注员为这些对标注偏好。标注过程可以以多种形式进行,常见的做法是对生成的候选文本进行排序标注,这样可以减少标注者之间的不一致性。然后,需要训练 RM 预测人类偏好的输出。在实践中,目前可以使用 GPT-4 代替人类进行排序标注,从而降低人工标注成本。
2.1.1数据集格式

其中response_chosen 代表是好的回答, response_rejected代表的是不好的回答
2.1.2 合并指令微调的模型
!python /kaggle/working/MedicalGPT/merge_peft_adapter.py --model_type bloom \
--base_model merged-pt --lora_model outputs-sft-v1 --output_dir merged-sft/
2.1.3 RM训练脚本
%cd /kaggle/working/autoorder
!git pull
!pip install -r algorithm/llm/requirements.txt
!pip install Logbook
import os
os.environ['RUN_PACKAGE'] = 'algorithm.llm.train.reward_modeling'
os.environ['RUN_CLASS'] = 'RewardModeling'
print(os.getenv("RUN_PACKAGE"))
!python main.py \
--model_type bloom \
--model_name_or_path merged-sft \
--train_file_dir /kaggle/working/MedicalGPT/data/reward \
--validation_file_dir /kaggle/working/MedicalGPT/data/reward \
--per_device_train_batch_size 3 \
--per_device_eval_batch_size 1 \
--do_train \
--use_peft True \
--seed 42 \
--max_train_samples 1000 \
--max_eval_samples 10 \
--num_train_epochs 1 \
--learning_rate 2e-5 \
--warmup_ratio 0.05 \
--weight_decay 0.001 \
--logging_strategy steps \
--logging_steps 10 \
--eval_steps 50 \
--evaluation_strategy no \
--save_steps 500 \
--save_strategy steps \
--save_total_limit 3 \
--max_source_length 256 \
--max_target_length 256 \
--output_dir outputs-rm-v1 \
--overwrite_output_dir \
--ddp_timeout 30000 \
--logging_first_step True \
--target_modules all \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--torch_dtype float32 \
--device_map auto \
--report_to tensorboard \
--ddp_find_unused_parameters False \
--remove_unused_columns False \
--gradient_checkpointing True
2.2 RL(Reinforcement Learning)强化学习
对齐LM(语言模型)被形式化为 RL 问题。在此设置中,预训练的 LM 作为策略,将提示作为输入并返回输出文本,它的动作空间是 LM 的词表,状态是当前生成的 token 序列,奖励由 RM 生成。为了避免显着偏离初始(调整前)LM,通常将惩罚项纳入奖励函数。例如,InstructGPT 使用 PPO 算法针对 RM 优化 LM。对于每个输入提示,InstructGPT 计算当前 LM 和初始 LM 生成的结果之间的 KL 散度作为惩罚。
2.2.1 数据集格式
数据集格式和sft阶段是一样的。

2.2.1 合并RM的模型
!python /kaggle/working/MedicalGPT/merge_peft_adapter.py --model_type bloom \
--base_model merged-sft --lora_model outputs-rm-v1 --output_dir merged-rm/
2.2.2 RL训练的脚本
# ppo training
%cd /kaggle/working/autoorder
!git pull
!pip install -r algorithm/llm/requirements.txt
!pip install Logbook
import os
os.environ['RUN_PACKAGE'] = 'algorithm.llm.train.ppo_training'
os.environ['RUN_CLASS'] = 'PPOTraining'
print(os.getenv("RUN_PACKAGE"))
# /kaggle/working/MedicalGPT/ppo_training.py
!python main.py \
--model_type bloom \
--model_name_or_path merged-sft \
--reward_model_name_or_path merged-rm \
--torch_dtype float16 \
--device_map auto \
--train_file_dir /kaggle/working/MedicalGPT/data/finetune \
--validation_file_dir /kaggle/working/MedicalGPT/data/finetune \
--batch_size 4 \
--max_source_length 256 \
--max_target_length 256 \
--max_train_samples 1000 \
--use_peft True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--do_train \
--max_steps 64 \
--learning_rate 1e-5 \
--save_steps 50 \
--output_dir outputs-rl-v1 \
--early_stopping True \
--target_kl 0.1 \
--reward_baseline 0.0 \
--use_fast_tokenizer \
--report_to tensorboard
```