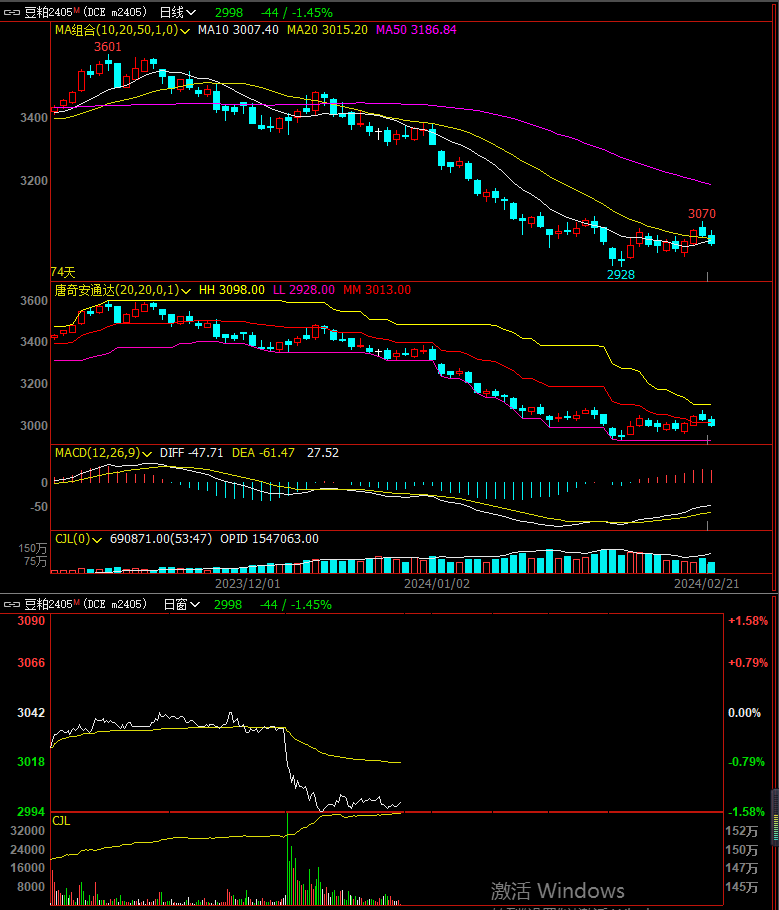
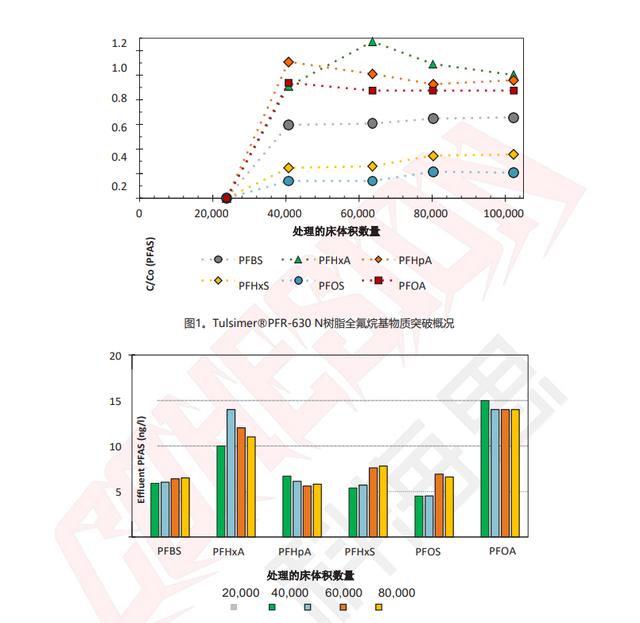
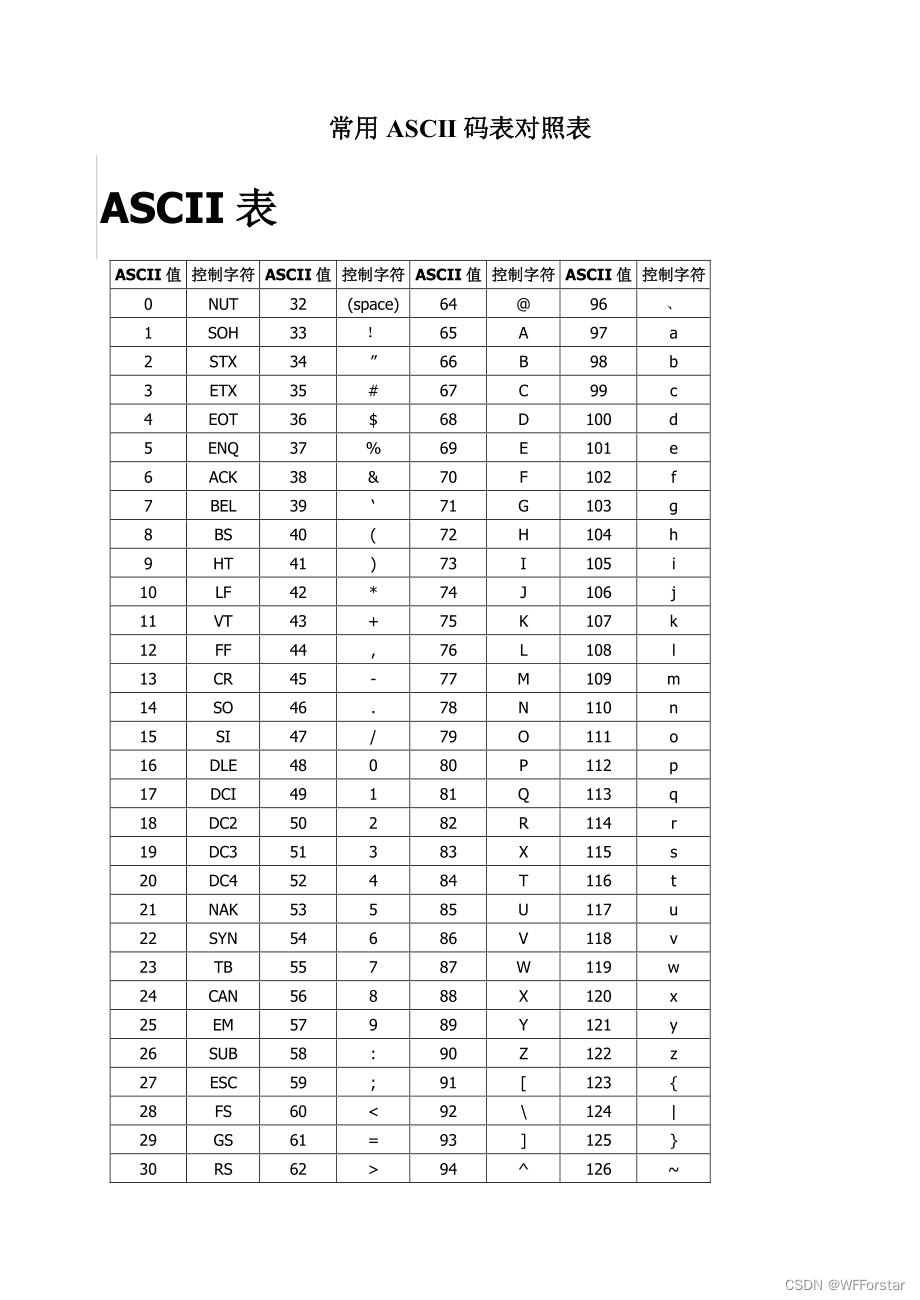
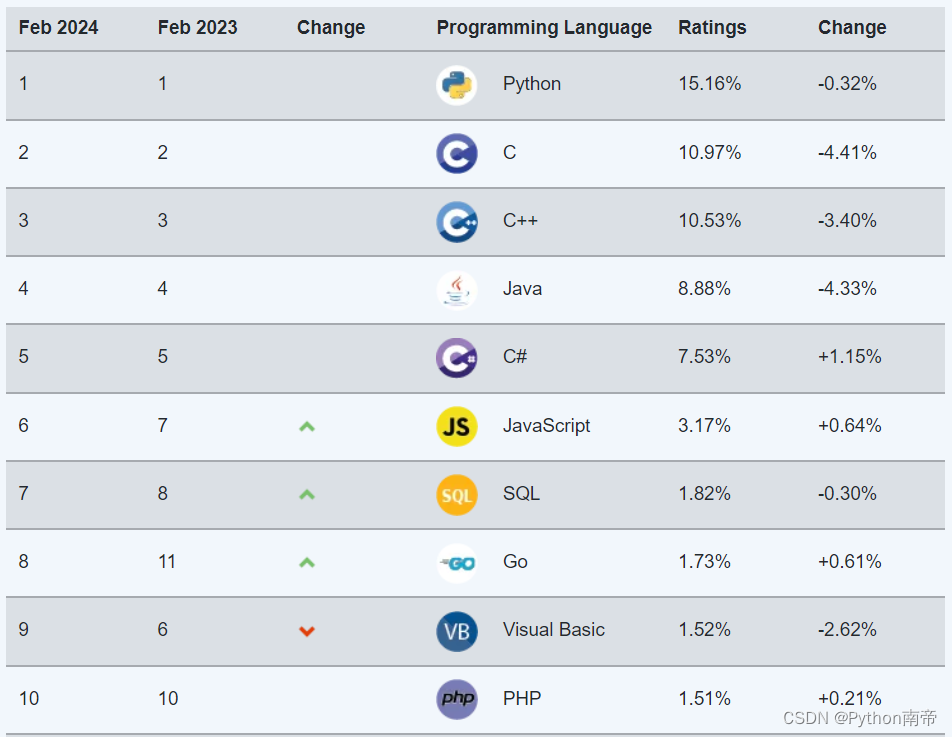
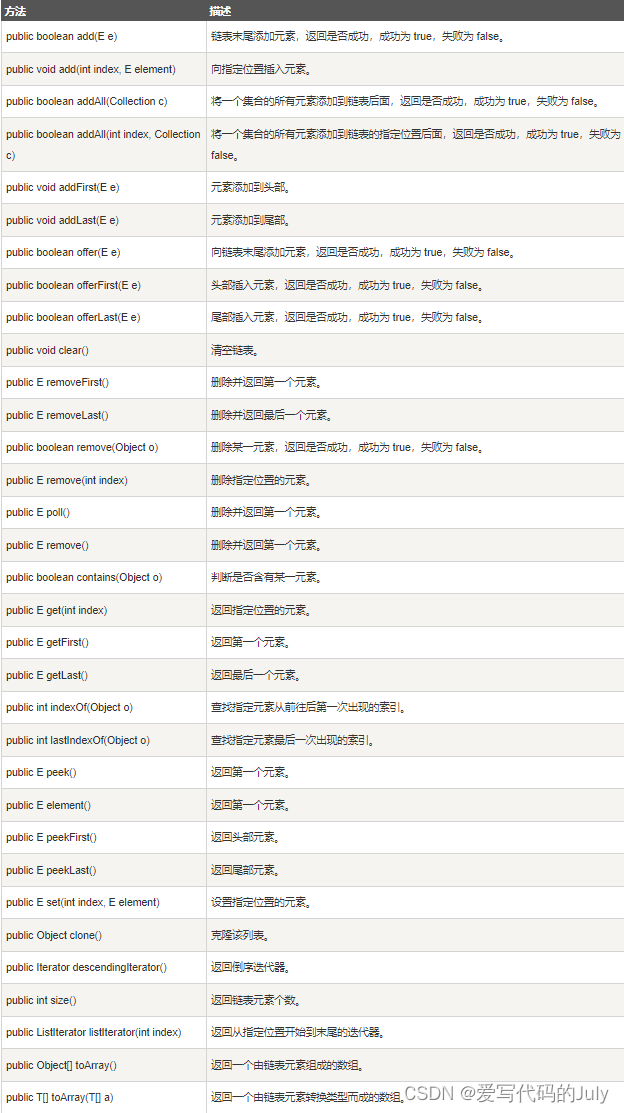
source:CV论文--2024.2.21
1、Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis
中文标题:二元不透明度网格:捕获精细的几何细节以进行基于网格的视图合成

简介:尽管基于表面的视图合成算法由于其低计算要求而吸引人,但往往难以重现细微结构。相比之下,更昂贵的方法,如将场景的几何形状建模为体密度场(例如NeRF),在重建精细几何细节方面表现出色。然而,密度场通常以"模糊"的方式表示几何形状,这影响了对表面的精确定位。
在本研究中,我们对密度场进行了修改,以鼓励其收敛到表面,同时不损害其重建细微结构的能力。首先,我们使用离散的不透明度网格表示,而不是连续的密度场。这使得不透明度值在表面处可以从零不连续地过渡到一。其次,我们通过每像素投射多条光线进行反锯齿处理。这样可以建模遮挡边界和亚像素结构,而无需使用半透明体素。第三,我们最小化不透明度值的二进制熵,通过鼓励不透明度值在训练结束时趋于二进制化,有助于提取表面几何形状。最后,我们开发了一种基于网格的融合策略,随后进行网格简化和外观模型拟合。我们的模型生成了紧凑的网格,可以在移动设备上实时渲染。与现有基于网格的方法相比,我们实现了显著更高的视图合成质量。
2、FiT: Flexible Vision Transformer for Diffusion Model
中文标题:FiT:用于扩散模型的灵活视觉transformer

简介:自然界具有无限分辨率。然而,现有的扩散模型(如扩散变压器)在处理超出其训练领域的图像分辨率时面临挑战。为了克服这一限制,我们引入了一种名为"Flexible Vision Transformer(FiT)"的变压器架构,专门用于生成具有无限制分辨率和长宽比的图像。
与传统方法将图像视为静态分辨率网格不同,FiT将图像视为动态大小的标记序列。这种新的视角使得FiT能够采用灵活的训练策略,在训练和推理阶段轻松适应不同的长宽比,从而促进分辨率的泛化,并消除由图像裁剪引起的偏差。
FiT通过精心调整的网络结构和集成的无需训练的外推技术得到增强,展现了在分辨率外推生成方面出色的灵活性。全面的实验展示了FiT在广泛的分辨率范围内的卓越性能,并证明了它在训练分辨率分布内外的有效性。
我们的代码库可在https://github.com/whlzy/FiT 找到。
3、Open3DSG: Open-Vocabulary 3D Scene Graphs from Point Clouds with Queryable Objects and Open-Set Relationships
中文标题:Open3DSG:来自点云的开放词汇 3D 场景图,具有可查询对象和开放集关系
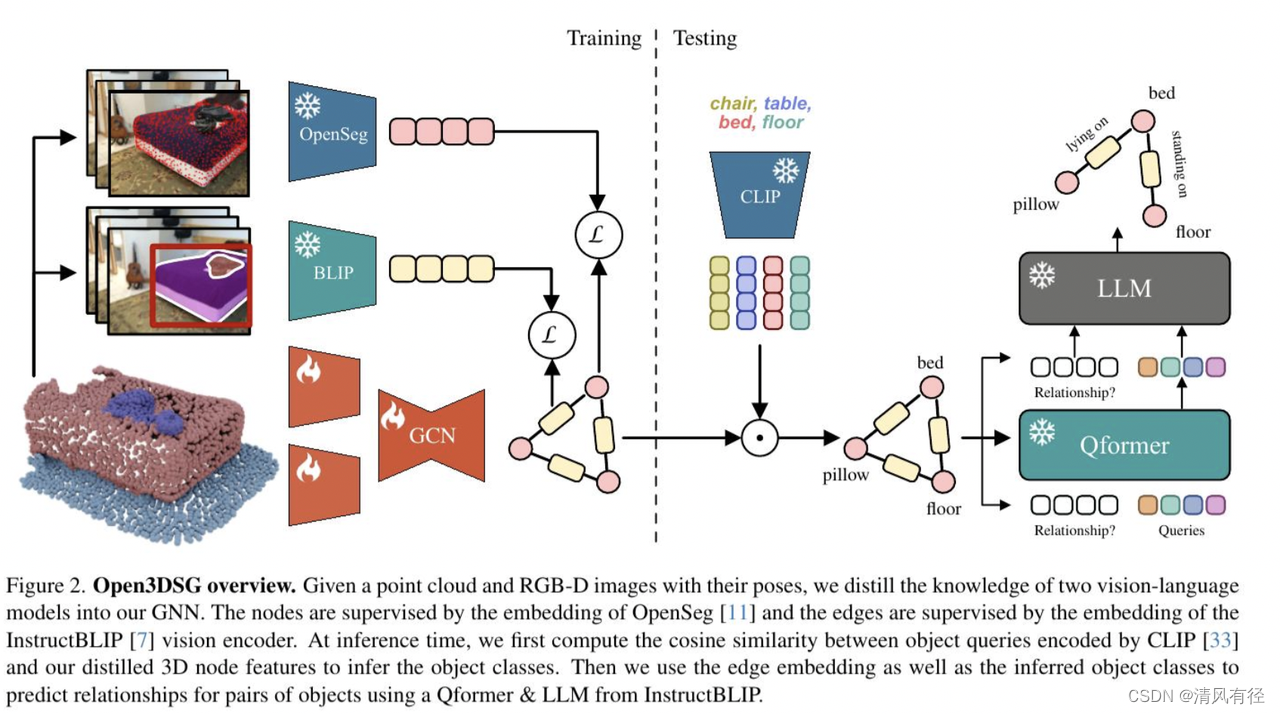
简介:当前的3D场景图预测方法依赖于标记的数据集,用于训练模型以识别已知对象类别和关系类别。为了克服这一限制,我们引入了Open3DSG,这是一种替代方法,可以在开放世界中学习3D场景图预测,而无需标记场景图数据。
我们将3D场景图预测的骨干特征与强大的开放世界2D视觉语言基础模型的特征空间进行共同嵌入。这使得我们能够通过从开放词汇表中查询对象类别,并结合场景图特征和查询的对象类别作为上下文来预测3D场景图。因此,我们可以从3D点云中以零样本方式预测3D场景图,而无需预先定义的标签集。
Open3DSG是首个能够不仅预测明确的开放词汇对象类别,而且预测不受预定义标签集限制的开放关系的3D点云方法。这使得在预测的3D场景图中能够表达罕见和特定的对象和关系。我们的实验结果表明,Open3DSG在预测任意对象类别以及描述空间、支持、语义和比较关系的复杂对象间关系方面非常有效。
![[经验] 什么是鄱阳湖旅游最主要的景点 #知识分享#知识分享](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fwww.hao123rr.com%2Fzb_users%2Fupload%2F2023%2F05%2F20230519204745168450046518177.jpg&pos_id=g5Ehc0Ar)