说在前面
这是本系列的第二篇博客,主要是整理了一些经典模型的原理和结构,面试有时候也会问到这些模型的细节,因此都是需要十分熟悉的。光看原理还不够,最好是能用代码试着复现,可以看看李沐老师深度学习的教材,我也有参考部分沐神的思想。
具体模型
LeNet5
LeNet5有3个卷积层,2个池化层,2个全连接层。卷积层的卷积核都为5*5,stride=1,池化层都为Max pooling,激活函数为Sigmoid,具体网络结构如下图:

Input
输入图像统一归一化为28×28。
C1卷积层
经过(5×5×1)×6卷积核,stride=1, 生成featuremap为28×28×6。
S2池化层
经过(2×2)采样核,stride=2,生成featuremap为14×14×6。
C3卷积层
经过(5×5×6)×16卷积核,stride=1,生成featuremap为10×10×16。
S4池化层
经过(2×2)采样核,stride=2,生成featuremap为5×5×6。
C5卷积层
经过(5×5×16)×120卷积核,stride=1, 生成featuremap为1×1×120。
F6全连接层
输入为1×1×120,输出为1×1×84,总参数量为120×84。
Output全连接层
输入为1×1×84,输出为1×1×10,总参数量为84×10。10就是分类的类别数。

AlexNet
2012年,Imagenet比赛冠军—Alexnet (以第一作者Alex命名)直接刷新了ImageNet的识别率,奠定了深度学习在图像识别领域的优势地位。网络结构如下图:

Input
输入图像为224×224×3。
Conv1
经过(11×11×3)×96卷积核,stride=4, (224-11)/4+2=55,生成featuremap为55×55×96。
Pool1
经过3×3的池化核,stride=2,(55-3)/2+1=27,生成featuremap为27×27×96。
Norm1
local_size=5,生成featuremap为27×27×96。
Conv2
经过(5×5×96)×256的卷积核,pad=2,group=2,(27+2×2-5)/1+1=27,生成featuremap为27×27×256。
Pool2
经过3×3的池化核,stride=2,(27-3)/2+1=13,生成featuremap为13×13×256。
Norm2
local_size=5, 生成featuremap为13×13×256。
Conv3
经过(3×3×256)×384卷积核,pad=1, (13+1×2-3)/1+1=13,生成featuremap为13×13×384。
Conv4
经过(3×3×384)×384卷积核,pad=1,(13+1×2-3)/1+1=13,生成featuremap为13×13×384。
Conv5
经过(3×3×384)×256卷积核,pad=1,(13+1×2-3)/1+1=13,生成featuremap为13×13×256。
Pool5
经过(3×3)的池化核,stride=2,(13-3)/2+1=6,生成featuremap为6×6×256。
Fc6
输入为(6×6×256)×4096全连接,生成featuremap为1×1×4096。
Dropout6
在训练的时候以1/2概率使得隐藏层的某些神经元的输出为0,这样就丢掉了一半节点的输出,BP的时候也不更新这些节点,以下Droupout同理。
Fc7
输入为1×1×4096,输出为1×1×4096,总参数量为4096×4096。
Dropout7
生成featuremap为1×1×4096。
Fc8
输入为1×1×4096,输出为1000,总参数量为4096×1000。

总结:
-
AlexNet比LeNet更深,包括5个卷积层和3个全连接层;
-
使用ReLU激活函数,收敛很快,解决了Sigmoid在网络较深时出现的梯度弥散问题;
-
加入了dropout层,防止过拟合;
-
使用了LRN归一化层,对局部神经元的活动创建竞争机制,抑制反馈较小的神经元放大反应大的神经元,增强了模型的泛化能力;
-
使用裁剪、翻转等操作做数据增强,增强了模型的泛化能力;
-
分块训练,当年的GPU没有这么强大,Alexnet创新地将图像分为上下两块分别训练,然后用全连接层合并在一起;
-
总体的数据参数大概为240M。
VGGNet
VGGNet主要的贡献是利用带有很小卷积核(3×3)的网络结构对逐渐加深的网络进行评估,结果表明通过加深网络深度至16-19层可以极大地改进前人的网络结构。这些发现也是参加2014年ImageNet比赛的基础,并且在这次比赛中,分别在定位和分类跟踪任务中取得第一名和第二名。VGGNet的网络结构如下图:

类型从A到E。此处只讨论VGG16,即图中的类型D。如图中所示,共有13个卷积层,3个全连接层。其全部采用3×3卷积核,步长为1,和2×2最大池化核,步长为2。
Input层
输入图片为224×224×3。
CONV3-64
经过(3×3×3)×64卷积核,生成featuremap为224×224×64。
CONV3-64
经过(3×3×64)×64卷积核,生成featuremap为224×224×64。
Max pool
经过(2×2)max pool核,生成featuremap为112×112×64。
CONV3-128。
经过(3×3×64)×128卷积核,生成featuremap为112×112×128。
CONV3-128
经过(3×3×128)×128卷积,生成featuremap为112×112×128。
Max pool
经过(2×2)maxpool,生成featuremap为56×56×128。
CONV3-256
经过(3×3×128)×256卷积核,生成featuremap为56×56×256。
CONV3-256
经过(3×3×256)×256卷积核,生成featuremap为56×56×256。
CONV3-256
经过(3×3×256)×256卷积核,生成featuremap为56×56×256。
Max pool
经过(2×2)maxpool,生成featuremap为28×28×256
CONV3-512
经过(3×3×256)×512卷积核,生成featuremap为28×28×512
CONV3-512
经过(33512)512卷积核,生成featuremap为2828*512。
CONV3-512
经过(3×3×512)×512卷积核,生成featuremap为28×28×512。
Max pool
经过(2×2)maxpool,生成featuremap为14×14×512。
CONV3-512
经过(3×3×512)×512卷积核,生成featuremap为14×14×512。
CONV3-512
经过(3×3×512)×512卷积核,生成featuremap为14×14×512。
CONV3-512
经过(3×3×512)×512卷积核,生成featuremap为14×14×512。
Max pool
经过2×2卷积,生成featuremap为7×7×512。
FC-4096
输入为7×7×512,输出为1×1×4096,总参数量为7×7×512×4096。
FC-4096
输入为1×1×4096,输出为1×1×4096,总参数量为4096×4096。
FC-1000
输入为1×1×4096,输出为1000,总参数量为4096×1000。
总结:
- 共包含参数约为550M;
- 全部使用3×3的卷积核和2×2的最大池化核;
- 简化了卷积神经网络的结构。
RNN
RNN实际上有两种,一种是Recurrent Neural Networks,即循环神经网络,一种是Recursive Neural Networks,即递归神经网络。循环神经网络是首先被提出的,它是一种时间上进行线性递归的神经网络,也就是我们通常所说的RNN。
递归神经网络被视为循环神经网络的推广,这是一种在结构上进行递归的神经网络,常用于自然语言处理中的序列学习,它的输入数据本质不一定是时序的,但结构却往往更加复杂,我们这里只说循环神经网络。一个RNN的结构如下:

左侧就是模型的基本结构,右侧就是它在时间上进行展开的示意图。xt是时刻t的输入,相应的ht,ot分别是对应时刻t的隐藏层和输出层。
上面我们可以看出,一个RNN的输入包括了两个:一个是当前时刻输入xt,用于实时更新状态,另一个是上一时刻隐藏层的状态ht-1,用于记忆状态,而不同时刻的网络共用的是同一套参数。
RNN中常用的激活函数是tanh,所以上面的式子写成公式,就是:
h
t
=
tanh
(
W
(
x
t
h
t
−
1
)
)
\begin{equation} h_t=\tanh \left(\mathrm{W}\left(\begin{array}{c} x_t \\ h_{t-1} \end{array}\right)\right) \end{equation}
ht=tanh(W(xtht−1))
w就是要学习的权重。用几句代码表示RNN为:
class RNN:
def step(self, x):
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x)) # 更新隐藏层
y = np.dot(self.W_hy, self.h) # 得到输出
return y
普通卷积神经网络的优化使用的是反向传播,RNN使用的还是反向传播,不过是带时序的版本,即BPFT(backpropagation through time),它与BP的原理是完全一样的,只不过计算过程与时间有关。与普通的反向传播算法一样,它重复地使用链式法则,区别在于损失函数不仅依赖于当前时刻的输出层,也依赖于下一时刻。所以参数W在更新梯度时,必须考虑当前时刻的梯度和下一时刻的梯度,传播示意图如下:

LSTM
LSTM(长短时记忆网络,Long Short-Term Memory)是RNN的变种,用于处理序列数据,特别是对于长序列和处理长期依赖性非常有效。LSTM设计的目的是解决传统RNN在处理长序列时产生的梯度消失和梯度爆炸问题,通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息,而不像普通的RNN那样只有一种记忆叠加方式。用最简洁的话讲就是,网络决定要记住/忘记什么→有选择地更新单元状态值→网络决定当前状态的哪一部分可以输出。
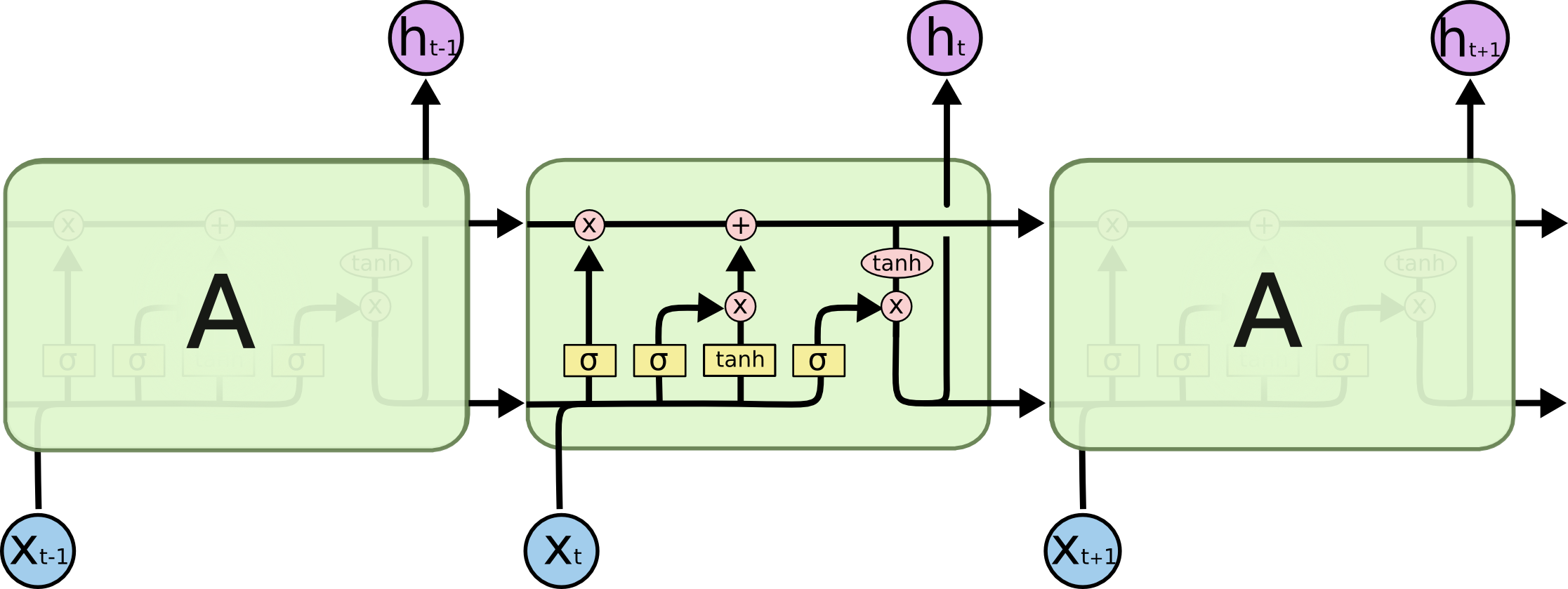
长短期记忆递归神经网络(Long short-term memory, LSTM)相比RNN多了一个状态cell state。这个cell state承载着之前所有状态的信息,每到新的时刻,就有相应的操作来决定舍弃什么旧的信息以及添加什么新的信息。这个状态与隐藏层状态h不同,在更新过程中,它的更新是缓慢的,而隐藏层状态h的更新是迅速的。LSTM的网络结构图如下,输入包括ht-1,xt,输出ht,状态为ct-1,ct。

遗忘门与遗忘阶段
遗忘门决定了要从上一个状态中舍弃什么信息,它输入上一状态的输出ht-1、当前状态输入信息xt到一个Sigmoid函数中,产生一个介于0到1之间的数值,与上一个时刻的状态ct-1相乘之后来确定舍弃(保留)多少信息。0 表示“完全舍弃”,1 表示“完全保留”,这个阶段完成了对上一个节点cell state进行选择性忘记,遗忘门和它的输出公式如下:
f
t
=
σ
(
w
f
x
t
+
u
f
h
t
−
1
)
\begin{equation} f_t=\sigma\left(w^f x_t+u^f h_{t-1}\right) \end{equation}
ft=σ(wfxt+ufht−1)
f t ∘ C t − 1 \begin{equation} f_t \circ C_{t-1} \end{equation} ft∘Ct−1
输入门与选择记忆阶段
选择记忆阶段,也就是对输入有选择性地进行“记忆”,重要的记录下来,不重要的少记一些,它决定了要往当前状态中保存什么新的信息。它输入上一状态的输出ht-1、当前输入信息xt到一个Sigmoid函数中,产生一个介于0到1之间的数值it来确定需要保留多少的新信息。“候选新信息”则通过输入上一状态的输出、当前状态输入信息和一个tanh激活函数生成。有了遗忘门和输入门之后,就得到了完整的下一时刻的状态Ct,它将用于产生下一状态的隐藏层ht,也就是当前单元的输出。输入门、候选新信息、新状态的公式分别如下:
i
t
=
σ
(
w
i
x
t
+
u
i
h
t
−
1
)
\begin{equation} i_t=\sigma\left(w^i x_t+u^i h_{t-1}\right) \end{equation}
it=σ(wixt+uiht−1)
C t ~ = tanh ( w C x t + u C h t − 1 ) \begin{equation} \widetilde{C_t}=\tanh \left(w^C x_t+u^C h_{t-1}\right) \end{equation} Ct =tanh(wCxt+uCht−1)
C t = f t ∘ C t − 1 + C t ~ ∘ i t \begin{equation} C_t=f_t \circ C_{t-1}+\widetilde{C_t} \circ i_t \end{equation} Ct=ft∘Ct−1+Ct ∘it
输出门与输出阶段
输出门决定了要从cell state中输出什么信息。 与之前类似,会先有一个Sigmoid函数产生一个介于0到1之间的数值Ot来确定我们需要输出多少cell state中的信息。 cell state的信息在与Ot相乘时首先会经过一个tanh层进行“激活”,得到的就是这个LSTM block的输出信息ht。输出门和输出信息的公式如下:
O
t
=
σ
(
w
o
x
t
+
u
o
h
t
−
1
)
\begin{equation} O_t=\sigma\left(w^o x_t+u^o h_{t-1}\right) \end{equation}
Ot=σ(woxt+uoht−1)
h t = O t ∘ tanh ( C t ) \begin{equation} h_t=O_t \circ \tanh \left(C_t\right) \end{equation} ht=Ot∘tanh(Ct)
ResNet
ResNet即残差神经网络,引入残差学习的思想。传统的卷积网络或者全连接网络在信息传递的时候或多或少会存在信息丢失,损耗等问题,同时还有导致梯度消失或者梯度爆炸,导致很深的网络无法训练。ResNet在一定程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络只需要学习输入、输出差别的那一部分,简化学习目标和难度。ResNet最大的区别在于有很多的旁路将输入直接连接到后面的层,这种结构也被称为shortcut或者skip connections,示意图如下:

可以使用一个非线性变化函数来描述一个网络的输入输出,即输入为X,输出为F(x),F通常包括了卷积,激活等操作。当我们强行将一个输入添加到函数的输出的时候,虽然我们仍然可以用G(x)来描述输入输出的关系,但是这个G(x)却可以明确的拆分为F(x)和X的线性叠加。这就是skip connect的思想,将输出表述为输入和输入的一个非线性变换的线性叠加,没用新的公式,没有新的理论,只是换了一种新的表达。
正常块和残差块的对比:

ResNet沿用了VGG完整的3×3卷积层设计。 残差块里首先有2个有相同输出通道数的3×3卷积层。 每个卷积层后接一个批量规范化层和ReLU激活函数。 然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。 这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。 如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算。
包含以及不包含1×1卷积层的残差块:

ResNet的前两层跟之前介绍的GoogLeNet中的一样: 在输出通道数为64、步幅为2的7×7卷积层后,接步幅为2的3×3的最大汇聚层。 不同之处在于ResNet每个卷积层后增加了批量规范化层。GoogLeNet在后面接了4个由Inception块组成的模块。 ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。 第一个模块的通道数同输入通道数一致。 由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。 之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。

结束
下一篇还没想好更什么内容,目前打算更AIGC或者大模型相关的题目,或者是手推系列,但是手推挺花时间的,往后拖拖也不一定🤔