java原生态提取图片内的文本信息操作Demo!现在市面上很多客户都有从图片中提取文本信息的业务需求,那么,java的操作案例代码就来了,但是有一个坏消息告诉大家,市面上开源的 插件包,目前我测试的提取效果,是不尽人意的。毕竟开源免费的,效果还好了,我暂时是没有找到的。以下代码仅供学习参考。真正高质量的插件包,还在继续探索发掘中。
package com.yrl.managedemo.util;
// Tesseract OCR库
import net.sourceforge.tess4j.*;
import javax.imageio.ImageIO;
import java.io.File;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
public class GetTextByVideo {
public static void main(String[] args) {
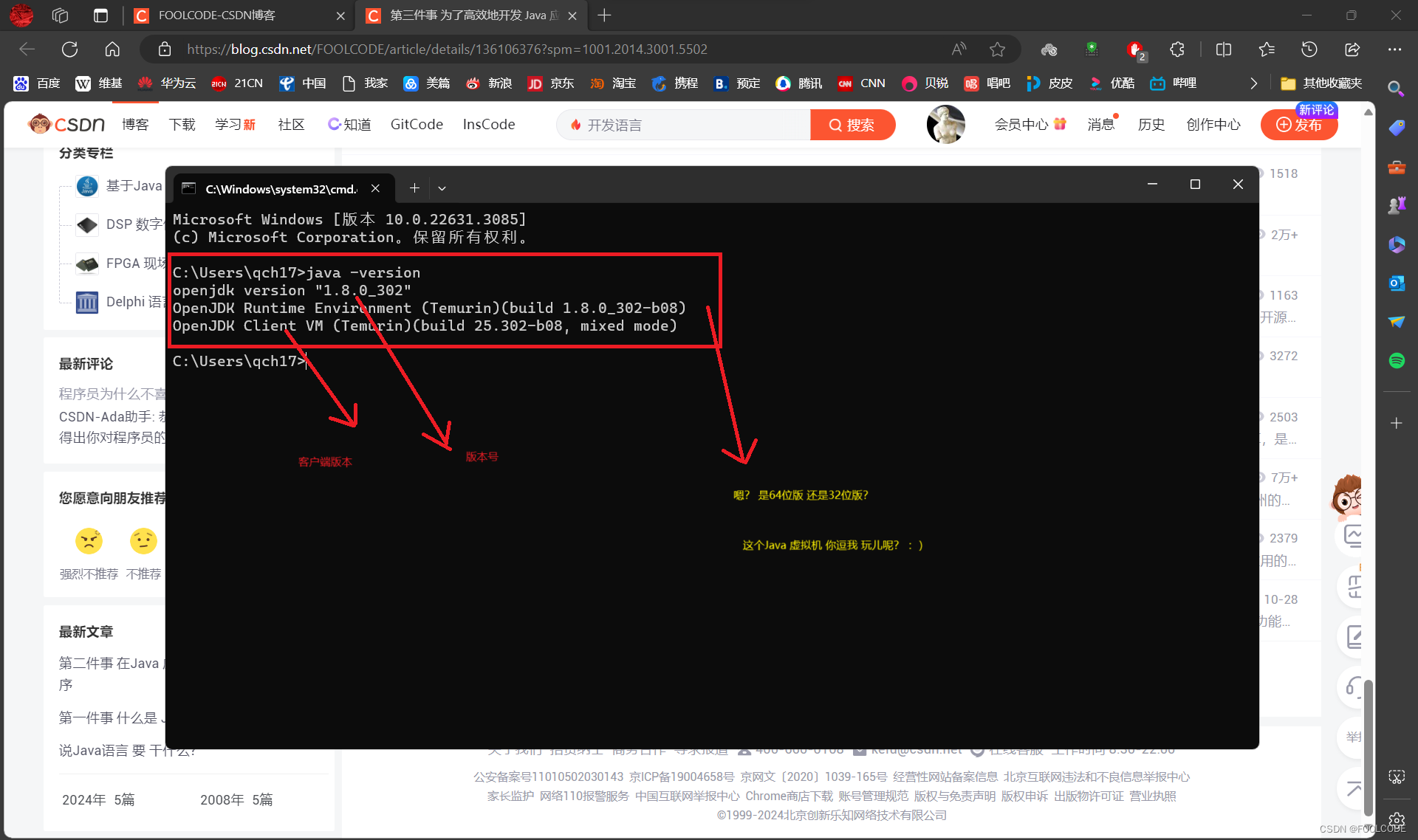
//jian.jpg
File imageFile = new File("H:\\base\\images\\002.png");
ITesseract instance = new Tesseract(); // JNA Interface Mapping
// 语言库的路径
instance.setDatapath("H:\\tessdata\\tessdata-master");
// 通过环境变量获取
//instance.setDatapath(System.getenv("TESSDATA_PREFIX"));
// 设置语言为中文, eng为英文
instance.setLanguage("chi_sim");
//设置图片的分辨率
instance.setTessVariable("user_defined_dpi", "72");
try {
long startTime = System.currentTimeMillis();
// 执行OCR操作
String result = instance.doOCR(imageFile);
System.out.println(result);
long endTime = System.currentTimeMillis();
System.out.println("Time is:" + (endTime - startTime)/1000 + " 秒");
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}
我们用到了这个开源的插件包,在pom.xml里面加入配置参数即可下载到本地maven仓库了。
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.4</version>
</dependency>
稍等片刻,下载完成后大家可以可以开始测试本地的提取操作效果了。
我自己设计了几个图片,分辨率都是72Dpi;
但是提取的效果真的是不尽人意啊。

第一张图片,蓝色背景,白色文字,提取效果如下所示:
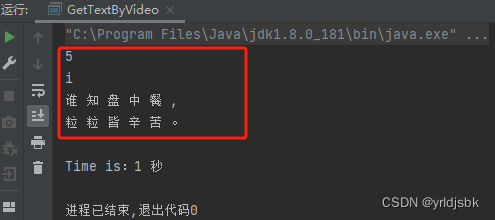
如图,前面2行文字,它好像不认识啊。后面2行文字,倒是提取出来了。给一个50分吧。不及格。
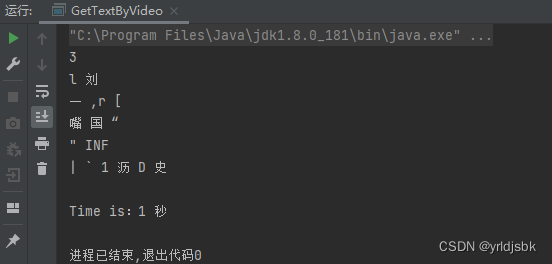
第二张图片:

来自优酷视频网站一个视频作品的截图图片。我们测试能不能提取出来里面的台词信息。结果如下:
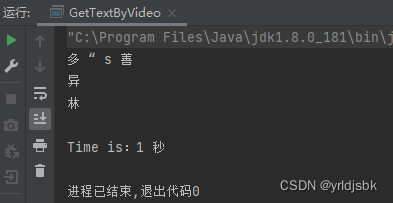
第三张图片,还是视频截图的图片,

提取结果如下所示。我们希望拿到里面的台词文本信息。
但是实际效果却是:
看到这里,后面的测试我们就不用再展示了吧。
由此可见,市面上开源的插件包,效果好不好,大家自己去衡量吧。
想真正做到那种有较为强悍的提取效果的软件包,估计真的是,要么你花钱买别人公司的成品。
要么,你自己投资花钱去训练大模型。