目的
先粗略地看一遍作者的书籍。
原文档地址
https://www.sigbus.info/compilerbook#
“低レイヤを知りたい人のためのCコンパイラ作成入門”
为想了解底层的人准备的C编译器制作入门
Rui Ueyama ruiu@cs.stanford.edu 2020-03-16
作者简介
https://www.sigbus.info/
植山瑠偉
谷歌软件工程师
我的专业知识涵盖从 HTML/JavaScript 到硬核系统编程。之前我曾在搜索 UI 方面工作。目前我全职从事 LLVM 项目的工作。
项目
lld,LLVM 链接器 - 一种高性能的可替换品,比 GNU gold 或 Microsoft Visual Studio 链接器快 2 倍以上。它具备生产级质量,被包括 FreeBSD 在内的各种操作系统使用为 /usr/bin/ld。我是该项目的原始设计者、实现者和所有者。
8cc C 编译器 - 我的爱好编译器。它是一个小型但功能齐全的编译器,旨在支持所有 C11 语言特性。它足够强大,可以在 Linux/x86-64 上自托管。
Gauche Scheme - 实现了各种功能,包括 Perl5 兼容的正则表达式引擎。https://practical-scheme.net/gauche/index.html
Go 编程语言 - 作为提交者,实现了各种性能优化并修复了错误。(补丁列表)
MiniLisp - 一种 Lisp 实现,用不到 1k 行的 C 代码编写,支持各种特性:全局变量、具有闭包的词法作用域局部变量、宏、用户定义函数和复制式垃圾收集器。https://github.com/rui314/minilisp
文章
我如何在 40 天内编写了一个自托管的 C 编译器
软件兼容性和我们自己的“用户代理”问题
我的“更差也更好”的故事
其他
Twitter / Facebook / LinkedIn / rui314@gmail.com
最后更新时间:2018 年 12 月
以下开始翻译
前言
本在线书籍正在编写中,尚未完成。 反馈表
为了使这本书能够收录丰富的内容,我对其进行了一些精心设计。本书旨在介绍如何编写一个将C语言源代码转换为汇编语言的程序,即C编译器。而且,我们将使用C语言本身来开发编译器。当前的目标是实现自举,即使得编译器可以使用其自身的源代码进行编译。
本书采用了逐步深入的方式进行解释,以确保编译器的解释难度不会突然增加。这样做的原因如下:
编译器可以在概念上分为多个阶段,如语法分析、中间处理、代码生成等。通常的教科书方法是为每个阶段编写一章进行解释,但这样的书籍往往会在中途变得过于狭隘和深入,读者很难跟上。
另外,按阶段进行开发的方法意味着,直到所有阶段都完成之前,我们无法运行编译器,从而无法意识到在理解和编写代码方面的错误,直到整个编译器开始工作之前,我们甚至可能不知道下一个阶段期望的输入是什么,因此也无法确定前一个阶段应该输出什么。由于无法编译任何代码,直到完成为止,因此很难保持动力。
为了避免陷入这个陷阱,本书采用了另一种方法。在本书的早期阶段,读者将实现一种非常简单的“独立语言”规范。由于该语言过于简单,因此在实现它时无需详细了解编译器的工作原理。随后,读者将在整本书的过程中逐步为“独立语言”添加功能,最终将其发展成与C语言匹配的语言。
这种逐步开发的方法意味着我们将一步步地构建编译器,同时进行详细的提交。在这种开发方法下,无论在何时读者都将具有关于如何创建合理语言的知识。这比只在编译器制作的某些方面过于专注要好得多。此外,到达本书结尾时,读者应该对各个主题都有全面的了解。
此外,本书还介绍了如何从零开始编写大型程序。构建大型程序所需的技能与学习数据结构和算法等内容略有不同,但几乎没有书籍介绍这方面的内容。而且,即使有书籍介绍,如果没有实际体验,也很难判断开发方法的优劣。因此,本书旨在使创建自制语言的过程成为一种良好的开发实践。
在编写本书时,我不仅仅是解释规范和CPU规范,还尽可能地解释了为什么会选择这样的设计。此外,我还在各个地方插入了有关编译器、CPU、计算机行业及其历史的专栏,以确保读者能够轻松愉快地阅读。
编译器制作是一项非常有趣的工作。一开始只能做一些非常简单的事情的自制语言,随着开发的进行,很快就会惊讶地发现它不知不觉地变得越来越像C语言,并且像魔法一样运行得很好。事实上,在开发的某个时刻,一个看似不可能编译的较大的测试代码却可以毫无错误地编译,并且完全正确地运行,这经常让人感到惊讶。这样的代码即使查看编译结果的汇编代码也很难理解。有时,我甚至觉得我的编译器拥有比我自己更高的智慧。尽管了解了编译器的工作原理,但它仍然有一种神奇的感觉,不知道为什么它可以如此顺利地运行。我相信,你也会被它的魅力所吸引。
好了,废话说了这么多,让我们马上开始与作者一起进入编译器开发的世界吧!
专栏:为什么选择C语言
在众多的编程语言中,为什么这本书选择了C语言?又或者为什么不是自制语言呢?实际上,并没有绝对必须选择C语言的理由,但如果要选择某种语言来学习生成本机代码的编译器制作方法,那么C语言是相当合理的选择之一。
在解释器方式的语言中,很难学到低层知识。然而在C语言中,通常会编译成汇编语言,因此通过制作编译器,不仅可以学习C语言本身,还可以了解CPU指令集以及程序的运行机制等。
由于C语言被广泛使用,一旦编译器正常工作,你可以下载并编译从网上下载的第三方源代码来进行尝试。例如,你可以构建迷你Unix系统xv6并进行探索。如果编译器的完成度足够高,甚至可以编译Linux内核。这样的乐趣在较小众的语言或自制语言中是无法体验到的。
作为一种静态类型的语言,类似C这样被编译为本机机器码的语言,还有C++。但是C++的语言规范过于庞大,不可能轻易制作自制编译器,因此在现实中并不是一个可行的选择。
设计并实现原创语言在锻炼语言设计感方面是不错的,但也存在陷阱。有些实现上麻烦的地方,在语言规范中可能会被避免,但在像C这样规范标准给出的语言中是无法做到的。这种限制从学习的角度来看是一件好事。
本书的表达方式
在本文中,函数、表达式、命令等将以等宽字体显示,如 main、foo=3、make。
跨越多行的代码将使用等宽字体显示,并显示在框中,如下所示:
int main() {
printf("Hello world!\n");
return 0;
}
框中包围的代码假定用户直接输入的情况下,以 开头的行表示命令提示符。请将该行中的 开头的行表示命令提示符。请将该行中的 开头的行表示命令提示符。请将该行中的之后的内容输入到Shell中(请不要输入 本身)。除了 本身)。除了 本身)。除了开头的行外,其余行表示输入命令后的输出内容。例如,下面的示例表示用户输入make并按下回车键后的执行结果。make命令的输出为make: Nothing to be done for `all’.
$ make
make: Nothing to be done for `all'.
本书假设的开发环境
本书假设读者使用的是普通的 64 位 Linux 环境,例如 Intel 或 AMD 的 PC。请根据您使用的发行版提前安装好 gcc、make 等开发工具。如果是 Ubuntu,您可以执行以下命令来安装本书使用的命令。
$ sudo apt update
$ sudo apt install -y gcc make git binutils libc6-dev
macOS与Linux在汇编级别上具有相当的兼容性,但并非完全兼容(具体来说,不支持"静态链接"功能)。尽管按照本书的内容创建适用于 macOS 的 C 编译器并非不可能,但实际尝试时,您可能会在各种微小的不兼容性方面遇到问题。同时学习 C 编译器开发技巧和 macOS 与 Linux 的差异并不是一个建议的做法,因为当某些东西无法正常工作时,您可能会不清楚哪一方的理解出现了问题。
因此,本书不包括 macOS。请使用某种虚拟环境在 macOS 上准备 Linux 环境。如果读者第一次准备 Linux 虚拟环境,可以参考附录3中有关使用 Docker 创建开发环境的方法。
Windows 与 Linux 在汇编级别上不兼容。然而,在 Windows 10 上,可以在 Windows 上以一种应用程序的形式运行 Linux,从而可以在 Windows 上进行开发。Windows 子系统(WSL)是提供此 Linux 兼容环境的应用程序。当在 Windows 上实践本书内容时,请安装 WSL,并在其中进行开发。
专栏:交叉编译器
编译器在运行的计算机称为"主机",编译器输出的代码在其中运行的计算机称为"目标机"。在本书中,两者都是64位的Linux环境,但主机和目标机不一定相同。
主机和目标机不同的编译器称为交叉编译器。例如,在Windows上运行并生成Raspberry Pi可执行文件的编译器就是交叉编译器。交叉编译器通常在目标计算机无法运行编译器,或者其环境很特殊时使用。
关于作者
植山類(@rui314)。高速链接器lld的原始作者和现任维护者,lld已被广泛用作多个操作系统和项目的标准链接器,包括Android(版本Q及更高版本)、FreeBSD(12及更高版本)、Nintendo Switch、Chrome和Firefox等(因此,由作者编写的工具生成的二进制文件可能已存在于读者的计算机上)。他也是紧凑型C编译器8cc的作者。他关于软件的论文主要发布在note上。
专栏:编译编译器的编译器
编译器本身用编程语言C编写并非罕见,这种自指的情况在C以外的语言实现中也十分常见。
如果已经存在语言X的实现,那么用该语言本身编写新的X编译器并不具有逻辑矛盾。如果想要进行自我托管,只需使用现有的编译器进行开发,直到自己的编译器完成,然后再进行切换即可。我们在本书中要做的正是这种方法。
但是,如果不存在现有的编译器,该怎么办呢?那时就只能使用另一种语言来编写。当打算自我托管并编写X语言的第一个编译器时,需要使用与X不同的现有语言Y进行编写,然后在编译器完成度提高后,需要将编译器从Y语言重新编写为X语言。
现代复杂的编程语言编译器也可以追溯到使用另一种语言编写该语言的实现,依次类推,最终,您应该能够追溯到某人在计算机的早期阶段直接使用机器语言编写的简单汇编程序。尽管我们无法确定现有的编译器是从单个还是多个祖先开始的,但现有的编译器几乎可以肯定是从极少数的祖先开始发展而来的。除了编译器之外,几乎所有的可执行文件都是由编译器生成的,因此,几乎所有现有的可执行文件都可以间接追溯到原始汇编程序的后代。这就像是生命起源的有趣故事一样。
机器语言和汇编语言
本章的目标是对构成计算机的组件以及我们的C编译器应该输出什么样的代码有一个大致的了解。我们不会深入探讨具体的CPU指令等内容。首先理解概念是非常重要的。
CPU和内存
构成计算机的组件大致可以分为CPU和内存两部分。内存是一种可以存储数据的设备,而CPU则是一种在读写内存的同时执行某些处理的设备。
概念上,对于CPU来说,内存看起来像是一个随机访问的大型字节数组。当CPU访问内存时,它会使用数字来指定要访问的内存字节的位置,这个数字称为“地址”。例如,“从地址16读取8个字节的数据”意味着从内存的第16个字节开始读取8个字节的数据。同样的概念也可以表达为“从16号地址读取8个字节的数据”。
CPU执行的程序和程序读写的数据都存储在内存中。CPU会在内部保持“当前正在执行的指令的地址”,从该地址读取指令并执行,然后读取并执行下一条指令。这个当前正在执行的指令的地址称为“程序计数器”(PC)或“指令指针”(IP)。指令形式本身称为“机器语言”。
程序计数器不一定会线性地执行下一条指令。通过使用CPU的“分支指令”,可以将程序计数器设置为除了下一条指令以外的任意地址。这个功能实现了if语句和循环等结构。将程序计数器设置到下一条指令以外的位置称为“跳转”或“分支”。
除了程序计数器之外,CPU还有少量的数据存储空间。例如,英特尔和AMD处理器有16个可以存储64位整数的空间。这些空间称为“寄存器”。内存对于CPU来说是外部设备,读写需要一定的时间,但是寄存器存在于CPU内部,可以立即访问,没有延迟。
许多机器语言都采用了一种格式,使用两个寄存器的值进行某种操作,然后将结果写回寄存器。因此,程序的执行过程是,CPU从内存中加载数据到寄存器中,然后在寄存器之间进行某种操作,最后将结果写回内存。
特定机器语言的指令的统称为“指令集架构”(instruction set architecture, ISA)或“指令集”。指令集不是一种,每个CPU都可以自行设计。但是,由于缺乏机器语言级别的兼容性会导致无法运行相同的程序,因此指令集的变化并不多。在个人电脑上,使用的是英特尔和其兼容芯片制造商AMD的x86-64指令集。x86-64是主要的指令集之一,但并不是唯一占主导地位的。例如,在iPhone和Android中使用的是ARM指令集。
专栏:x86-64命令集的名称
x86-64有时也被称为AMD64、Intel 64、x64等。同一指令集有多个名称的背后有着历史的原因。
x86指令集是由英特尔在1978年创建的,但将其扩展为64位是由AMD完成的。当64位处理器变得必要时,约在2000年左右,英特尔全力投入开发全新指令集Itanium,而没有选择着手64位版x86,这与竞争的64位x86不同。AMD抓住了这个机会,制定并公开了64位x86的规格。这就是x86-64。后来由于Itanium的失败显而易见,英特尔不得不开始着手64位x86,但当时由于AMD64的实际芯片已经出现了相当数量,因此再开发一个与之类似但不同的扩展指令集变得困难。据说,微软也向英特尔施加了保持兼容性的压力。在那时,英特尔选择采用了几乎与AMD64完全相同的指令集,并将其命名为IA-32e(Intel Architecture 32 extensions)。这种将其命名为64位CPU本质上是Itanium的扩展的做法,透露出对未成功指令集的留恋。随后,英特尔开始完全放弃Itanium,并将IA-32e更名为普通的Intel 64。微软可能是因为名字太长,因此将x86-64称为x64。
出于以上原因,x86-64有很多不同的名称。
在开源项目中,似乎更倾向于使用不带有特定公司名称的x86-64这个名称。本书也一贯使用x86-64这个名称。
汇编语言是什么?
由于机器语言是 CPU 直接读取的,因此只考虑了 CPU 的需求,而没有考虑人类的易用性。尽管在二进制编辑器中编写这种机器语言并非不可能,但却是一项非常繁琐的工作。因此,汇编语言应运而生。汇编语言几乎是机器语言的一对一对应,但比机器语言更容易被人类理解。
对于输出原生二进制而非虚拟机或解释器的编译器来说,通常的目标是输出汇编语言。尽管有些编译器看起来直接输出机器语言,但在常见的配置下,它们实际上会先输出汇编语言,然后在后台启动汇编器。本书中的 C 编译器也会输出汇编语言。
将汇编代码转换为机器语言有时被称为“编译”,强调输入是汇编语言的情况下也会特别称为“汇编”。
读者们可能在某处看过汇编语言。如果您以前没有见过汇编语言,那么现在是一个好机会。您可以使用 objdump 命令,对一个适当的可执行文件进行反汇编,将其中的机器语言显示为汇编语言。以下是反汇编 ls 命令的结果。
$ objdump -d -M intel /bin/ls
/bin/ls: file format elf64-x86-64
Disassembly of section .init:
0000000000003d58 <_init@@Base>:
3d58: 48 83 ec 08 sub rsp,0x8
3d5c: 48 8b 05 7d b9 21 00 mov rax,QWORD PTR [rip+0x21b97d]
3d63: 48 85 c0 test rax,rax
3d66: 74 02 je 366a <_init@@Base+0x12>
3d68: ff d0 call rax
3d6a: 48 83 c4 08 add rsp,0x8
3d6e: c3 ret
...
在笔者的环境中,ls 命令包含大约两万条机器语言指令,因此反汇编的结果也将是一份接近两万行的巨大文件。这里只展示了其中的一小部分。
在汇编语言中,基本上是一行对应一个机器语言指令。作为示例,请看下一行。
3d58: 48 83 ec 08 sub rsp,0x8
这一行的含义是什么? 3d58 是存储机器语言的内存地址。换句话说,在执行 ls 命令时,该行指令将被放置在内存地址 0x3d58 处,并且当程序计数器为 0x3d58 时,该指令将被执行。接下来的四个十六进制数是实际的机器语言。CPU 会读取这些数据,并将其作为指令执行。sub rsp,0x8 是对应该机器语言指令的汇编语言。有关 CPU 的指令集将在后面的章节中进行说明,但该指令是从 RSP 寄存器中减去 8(subtract = 减去)的命令。
C和相应的汇编语言
简单的例子
为了了解 C 编译器生成的输出是什么样子,让我们比较一下 C 代码和相应的汇编代码。作为最简单的例子,考虑以下 C 程序:
int main() {
return 42;
}
如果将该程序保存为 test1.c 文件,则可以使用以下命令编译并验证 main 函数是否实际返回了 42:
$ cc -o test1 test1.c
$ ./test1
$ echo $?
42
在 C 中,main 函数返回的值将成为整个程序的退出代码。虽然程序的退出代码不会显示在屏幕上,但它会被隐式设置为 shell 的 $? 变量,因此可以通过使用 echo 命令在命令结束后立即查看该命令的退出代码。在这里,我们可以看到返回值正确地为 42。
现在,以下是对应于这个 C 程序的汇编程序:
.intel_syntax noprefix
.globl main
main:
mov rax, 42
ret
在这个汇编代码中,定义了一个全局标签 main,并且在标签后面跟着 main 函数的代码。在这里,我们将值 42 设置到名为 RAX 的寄存器中,并从 main 返回。虽然有 16 个寄存器可以存放整数值,其中包括 RAX,但约定为函数返回时 RAX 中的值是函数的返回值,因此在这里我们将值设置到了 RAX 中。
让我们实际汇编并运行此汇编程序。由于汇编文件的扩展名为 .s,所以请将上面的汇编代码写入 test2.s,并执行以下命令:
$ cc -o test2 test2.s
$ ./test2
$ echo $?
42
与 C 时一样,返回值为 42。
总的来说,可以说 C 编译器在读取像 test1.c 这样的 C 代码时,会生成像 test2.s 这样的汇编代码。
包含函数调用的示例
让我们看一个稍微复杂一点的例子,了解带有函数调用的代码会被转换成怎样的汇编代码。
函数调用不仅仅是一次跳转,调用的函数执行完毕后,必须返回到原来执行的位置。原来执行的地址被称为“返回地址”。如果只有一层函数调用,可以将返回地址保存在 CPU 的某个寄存器中,但是由于函数调用可以嵌套得很深,因此返回地址需要保存在内存中。实际上,返回地址被保存在内存栈上。
栈可以使用一个变量来实现,该变量保存了栈顶的地址。保存栈顶的存储区域称为“栈指针”。x86-64 为了支持函数式编程,提供了专用于栈指针的寄存器以及使用该寄存器的指令。将数据推送到栈上称为“压栈”,从栈上弹出的数据称为“出栈”。
现在,让我们看一个函数调用的实例。考虑以下 C 代码:
int plus(int x, int y) {
return x + y;
}
int main() {
return plus(3, 4);
}
这段 C 代码对应的汇编如下所示:
.intel_syntax noprefix
.globl plus, main
plus:
add rsi, rdi
mov rax, rsi
ret
main:
mov rdi, 3
mov rsi, 4
call plus
ret
第一行是指定汇编语法的命令。从第二行开始的 .globl 行指示汇编器 plus 和 main 这两个函数不仅仅在文件作用域中可见,而是在整个程序中都可见。这个可以先不用太在意。
首先看看 main。在 C 中,main 通过带参数调用 plus 函数。在汇编中,第一个参数被约定为存储在 RDI 寄存器中,第二个参数存储在 RSI 寄存器中,所以在 main 的前两行中将值设置为相应的寄存器中。
call 是一个调用函数的指令。具体来说,call 执行以下操作:
- 将
call后面的指令地址压入栈中 - 跳转到作为参数给定的地址
因此,当执行 call 指令时,CPU 将开始执行 plus 函数。
现在看看 plus 函数。plus 函数有三条指令。
add 是加法指令。在这种情况下,将 RSI 寄存器和 RDI 寄存器相加的结果保存在 RSI 寄存器中。由于 x86-64 整数运算指令通常只接受两个寄存器作为参数,所以结果将以覆盖第一个参数寄存器的形式保存。
函数的返回值应该存储在 RAX 中。因此,我们需要将加法的结果复制到 RAX 中。这里我们使用 mov 指令来完成这个任务。mov 是 move 的缩写,实际上并不移动数据,而是复制数据的指令。
在 plus 函数的最后,调用 ret 返回。具体来说,ret 执行以下操作:
- 从栈中弹出一个地址
- 跳转到该地址
因此,ret 是一个与 call 成对使用的指令,用于恢复调用之前的函数执行。call 和 ret 是成对出现的指令。
返回到 plus 的调用点后,是 main 的 ret 指令。由于原始 C 代码中,plus 的返回值直接由 main 返回,因此在这里,由于 plus 的返回值已经在 RAX 中,因此可以直接从 main 返回,作为 main 的返回值。
本章小结
本章主要介绍了计算机内部的工作原理以及C编译器需要做些什么。当查看汇编语言和机器语言时,可能会觉得与C语言相去甚远,看起来像是一团杂乱的数据块,但实际上反映了C语言的结构,读者可能会有这样的感觉。
由于本书还没有详细解释具体的机器语言,所以我认为读者可能不会理解objdump显示的汇编代码中每条指令的含义,但是我认为可以想象每条指令并没有做太多的事情。在本章阶段,掌握这种感觉已经足够了。
以下是本章的要点:
- CPU通过读写内存来推进程序的执行。
- CPU执行的程序和程序处理的数据都存储在内存中,CPU按顺序从内存中读取机器语言指令,并执行这些指令。
- CPU有一些称为寄存器的小型存储区,许多机器语言指令都是在寄存器之间操作的。
- 汇编语言是一种将机器语言变得更易读的语言,C编译器通常会输出汇编语言。
- C的函数在汇编中也成为函数。
- 函数调用是使用堆栈来实现的。
专栏:在线编译器
观察C代码及其编译结果是学习汇编语言的好方法,但是多次编辑源代码、编译并检查输出的汇编代码是一个有些麻烦的过程。有一个可以减少这种麻烦的优秀网站,那就是Compiler Explorer(也称为godbolt)。在Compiler Explorer上,将代码输入左侧文本框中,右侧即时显示相应的汇编输出。当想要确认C代码转换为何种汇编时,使用这个网站是一个不错的选择。
附注:前段时间用过这个Compiler Explorer ,似乎有bug,跟html语言关键字冲突相关。
创建一个简易计算器级别的语言
在本章中,作为创建C编译器的第一步,我们将支持四则运算以及其他算术运算符,以便编译类似以下的表达式:
30 + (4 - 2) * -5
这似乎是一个无关紧要的目标,但实际上这是一个相当困难的目标。数学表达式具有一些结构,比如括号内的表达式优先级较高,乘法优先于加法等等,如果不以某种方式理解这些结构,就无法正确计算。然而,输入的数学表达式只是一个平坦的字符序列,并没有结构化的数据。为了正确评估表达式,我们需要解析字符序列,并巧妙地推导出其中隐藏的结构。
在没有任何背景知识的情况下解决这类语法分析问题相当困难。事实上,这类问题曾经被认为是困难的问题,特别是从1950年代到1970年代,这一问题被积极研究,并开发出了各种算法。由于这些成果,现在语法分析并不是一个特别困难的问题,只要了解方法就可以。
本章将介绍语法分析中最常见的算法之一,即“递归下降语法分析法”。像GCC和Clang等您日常使用的C/C++编译器也使用了递归下降语法分析法。
不仅仅是编译器,在编程过程中,经常需要阅读某种结构化的文本。本章学到的技术可以直接应用于这类问题。学习本章中的语法分析技术可以说是一项终身技能。阅读本章,理解算法,并将语法分析技术添加到您的程序员工具箱中。
步骤1:创建编译整数的语言
首先考虑最简单的C语言子集。读者们会想象出怎样的语言呢?也许是只有main函数的语言。又或者是只有一个表达式的语言。仔细考虑后,我们可以认为仅由一个整数组成的语言是可能的,也是最简单的子集。
在这一步,我们首先实现这个最简单的语言。
在这一步中,我们将创建一个程序,从输入中读取一个数,然后将该数作为程序的退出码输出的汇编编译器。换句话说,输入只是一个像42这样的字符串,我们将创建一个编译器,读取该数并输出以下类型的汇编:
.intel_syntax noprefix
.globl main
main:
mov rax, 42
ret
.intel_syntax noprefix是一个汇编命令,用于选择本书使用的Intel语法,这是多种汇编写法中的一种。在创建此编译器时,请确保始终将此行放在开头。其他行与前几章中的描述相同。
读者可能会认为,“这种程序不能称为编译器”,作者也是这样认为的。然而,这个程序接受一个由一个数字组成的语言作为输入,并输出与该数字对应的代码,这在定义上就是一个合格的编译器。这样简单的程序一旦进行修改,就很快就能够实现相当复杂的功能,所以让我们先完成这一步吧。
事实上,从整个开发过程来看,这一步非常重要。因为我们将使用在这一步创建的内容作为整个开发的骨架。在这一步中,我们不仅要创建编译器本身,还要创建构建文件(Makefile)、自动测试以及设置git存储库。让我们逐一看看这些工作。
值得一提的是,本书中要创建的C编译器名为9cc。cc是C编译器的缩写。数字9并没有特殊的含义,只是因为作者之前创建的C编译器名为8cc,所以为了表示它的下一个版本,就将它命名为了9cc。当然,读者们可以自由地选择喜欢的名字。不过,请不要为了事先想好名字而耽误了开始编写编译器的时间。因为无论是GitHub存储库还是名称,都可以在之后进行更改,所以用一个合适的名字开始是没有问题的。
专栏:Intel格式和AT&T格式
除了本书中使用的Intel格式外,Unix系统中也广泛使用一种称为AT&T格式的汇编语法。gcc和objdump默认情况下会以AT&T格式输出汇编代码。
在AT&T格式中,结果寄存器位于第二个参数位置。因此,在有两个参数的指令中,参数的顺序是相反的。寄存器名称前面会加上%前缀,比如%rax。对于数值,需要在前面加上$前缀,比如$42。
此外,在引用内存时,AT&T格式使用()而不是[],并以独特的方式书写表达式。以下是一些示例,用于对比:
mov rbp, rsp // Intel
mov %rsp, %rbp // AT&T
mov rax, 8 // Intel
mov $8, %rax // AT&T
mov [rbp + rcx * 4 - 8], rax // Intel
mov %rax, -8(rbp, rcx, 4) // AT&T
在本次编译器的开发中,我们考虑了可读性,并选择使用了Intel格式。因为Intel的指令集手册中使用了Intel格式,所以可以直接将手册中的描述转化为代码。无论是AT&T格式还是Intel格式,它们的表达能力是相同的。无论选择哪种格式,生成的机器码指令序列都是相同的。
编写编译器主体部分
通常情况下,我们会将文件作为编译器的输入,但在这里我们将直接将代码作为命令的第一个参数传递。我们将读取第一个参数作为数字,并将其嵌入到固定格式的汇编代码中,代码如下所示:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv) {
if (argc != 2) {
fprintf(stderr, "参数数量不正确\n");
return 1;
}
printf(".intel_syntax noprefix\n");
printf(".globl main\n");
printf("main:\n");
printf(" mov rax, %d\n", atoi(argv[1]));
printf(" ret\n");
return 0;
}
创建一个名为9cc的空文件夹,并在其中创建名为9cc.c的文件,并使用以上内容填充该文件。然后,按照下面的步骤运行9cc以确认其工作方式:
$ cc -o 9cc 9cc.c
$ ./9cc 123 > tmp.s
第一行编译了9cc.c文件并生成了名为9cc的可执行文件。第二行将数字123作为输入传递给9cc,并将生成的汇编代码写入名为tmp.s的文件中。现在让我们来查看tmp.s文件的内容:
$ cat tmp.s
.intel_syntax noprefix
.globl main
main:
mov rax, 123
ret
正如您所见,生成得相当顺利。将生成的汇编文件传递给汇编器,就可以生成可执行文件了。
在Unix中,cc(或gcc)被认为不仅仅是C或C++的编译器,而是被称为许多语言的前端,它通过给定的文件扩展名来识别语言,并启动相应的编译器或汇编器。因此,在这里,与编译9cc相同的方式,如果将具有.s扩展名的汇编文件传递给cc,则可以进行汇编。下面是一个进行汇编并执行生成的可执行文件的示例:
$ cc -o tmp tmp.s
$ ./tmp
$ echo $?
123
在shell中,可以通过$?变量访问前一个命令的退出码。在上面的示例中,显示了与传递给9cc的参数相同的数字123。这意味着它正常运行了。请尝试提供不在0到255范围内的123以外的数字(Unix的进程退出代码范围为0到255),以确保9cc正常工作。
创建自动化测试
我认为很多业余编程者可能从未编写过测试,但在本书中,我们决定每次扩展编译器时都编写新的测试代码。一开始编写测试可能会感到有些麻烦,但很快你就会意识到测试的重要性。如果不编写测试代码,最终你只能手动执行相同的测试来确认功能是否正常,而手动执行测试要麻烦得多。
许多人认为编写测试很麻烦的印象大部分是来自测试框架过于繁琐,测试思想有时过于教条。例如像JUnit这样的测试框架具有许多方便的功能,但是学习和使用它们需要花费一些精力。因此,在本章中,我们不会介绍这些测试框架。相反,我们将使用非常简单的手写“测试框架”来编写测试,使用shell脚本来实现。
以下是用于测试的shell脚本test.sh。shell函数assert接受两个参数:输入值和期望输出值,然后将实际执行9cc的结果与期望的值进行比较。在定义了assert函数之后,shell脚本使用它来确保0和42都可以正确编译。
#!/bin/bash
assert() {
expected="$1"
input="$2"
./9cc "$input" > tmp.s
cc -o tmp tmp.s
./tmp
actual="$?"
if [ "$actual" = "$expected" ]; then
echo "$input => $actual"
else
echo "$input => $expected expected, but got $actual"
exit 1
fi
}
assert 0 0
assert 42 42
echo OK
使用上述内容创建test.sh,并使用chmod a+x test.sh命令将其设置为可执行文件。现在让我们运行test.sh并查看其效果。如果没有任何错误发生,test.sh最后会显示OK并退出。
$ ./test.sh
0 => 0
42 => 42
OK
如果发生错误,test.sh将不会显示OK。相反,它将显示以下内容,显示预期值和实际值不匹配的失败测试。
$ ./test.sh
0 => 0
42 expected, but got 123
当您想要调试测试脚本时,可以使用bash -x test.sh命令以带有-x选项的方式来执行脚本。使用-x选项,bash将显示执行跟踪如下所示:
$ bash -x test.sh
+ assert 0 0
+ expected=0
+ input=0
+ cc -o 9cc 9cc.c
+ ./9cc 0
+ cc -o tmp tmp.s
+ ./tmp
+ actual=0
+ '[' 0 '!=' 0 ']'
+ assert 42 42
+ expected=42
+ input=42
+ cc -o 9cc 9cc.c
+ ./9cc 42
+ cc -o tmp tmp.s
+ ./tmp
+ actual=42
+ '[' 42 '!=' 42 ']'
+ echo OK
OK
我们将在本书中使用的“测试框架”只是一个简单的shell脚本。这个脚本可能看起来比真正的测试框架(如JUnit)要简单得多,但这个shell脚本的简单性与9cc本身的简单性是平衡的,所以这种简单的测试方式更可取。自动化测试的要点在于,只要能够一次性运行自己编写的代码并机械地比较结果,就足够了,不要想得太复杂,首先进行测试是至关重要的。
使用 make 进行构建
在阅读本书的过程中,读者们可能会多次构建 9cc,甚至可能达到数百次或数千次。由于创建 9cc 的可执行文件,然后运行测试脚本的过程每次都相同,因此交给工具来完成这个任务会更加方便。在这种情况下,通常会使用 make 命令。
make 命令被执行时会读取当前目录中名为 Makefile 的文件,并执行其中写明的命令。Makefile 由以冒号结束的规则和规则的命令列表组成。下面的 Makefile 是为了自动化执行此步骤而准备的。
CFLAGS=-std=c11 -g -static
9cc: 9cc.c
test: 9cc
./test.sh
clean:
rm -f 9cc *.o *~ tmp*
.PHONY: test clean
请在与 9cc.c 相同的目录中创建一个名为 Makefile 的文件,并将上述内容复制进去。这样一来,只需运行 make 命令就能构建 9cc,运行 make test 就能执行测试。由于 make 能够理解文件的依赖关系,因此在修改了 9cc.c 后,在运行 make test 之前不需要先运行 make。只有当名为 9cc 的可执行文件旧于 9cc.c 时,make 才会在执行测试之前构建 9cc。
make clean 是一个用于清除临时文件的规则。虽然你可以手动运行 rm 来清理临时文件,但是如果不小心删除了不想删除的文件,那么会很麻烦,因此我们将这样的实用工具也写入了 Makefile。
需要注意的是,在编写 Makefile 时,缩进必须使用制表符而不能是空格。如果使用了 4 或 8 个空格,就会导致错误。虽然这只是一种不太方便的语法,但 make 是一个由上世纪 70 年代开发的古老工具,传统使然。
请务必向 cc 命令传递 -static 选项。关于此选项的含义,我们将在动态链接章节中进行说明。目前,您不需要特别考虑此选项的含义。
使用 Git 进行版本管理
本书将使用 Git 作为版本管理系统。在本书中,我们将逐步构建编译器,每个步骤都会创建一个 Git 提交,并编写提交消息。提交消息可以使用日语,只需简要总结实际进行了哪些更改即可。如果需要更详细的描述,可以在第一行后面留一个空行,然后写下详细说明。
在 Git 中,只有您手动生成的文件才会进行版本控制。例如,由于可以再次运行相同的命令来生成 9cc 的结果文件,因此生成的文件并不需要纳入版本控制。相反,应将这些文件排除在版本控制之外,并确保它们不会出现在存储库中,以避免每次提交的更改内容变得不必要地冗长。
您可以使用 .gitignore 文件来指定需要从版本控制中排除的文件模式。在与 9cc.c 相同的目录中,创建一个名为 .gitignore 的文件,并按以下内容设置,让 Git 忽略临时文件和编辑器的备份文件等。
*~
*.o
tmp*
a.out
9cc
如果您是第一次使用 Git,请告诉 Git 您的姓名和电子邮件地址。这些名称和电子邮件地址将记录在提交日志中。以下是设置作者姓名和电子邮件地址的示例。请读者们根据自己的情况设置姓名和电子邮件地址。
$ git config --global user.name "Rui Ueyama"
$ git config --global user.email "ruiu@cs.stanford.edu"
要创建提交,首先需要使用 git add 将发生更改的文件添加到暂存区。由于这是第一次提交,因此首先使用 git init 创建一个 Git 仓库,然后使用 git add 将创建的所有文件添加到暂存区。
$ git init
Initialized empty Git repository in /home/ruiu/9cc
$ git add 9cc.c test.sh Makefile .gitignore
然后使用 git commit 进行提交。
$ git commit -m "创建编译一个整数的编译器"
通过 -m 选项指定提交消息。如果不使用 -m 选项,则 Git 将会打开文本编辑器。您可以通过运行 git log -p 来确认提交是否成功。
$ git log -p
commit 0942e68a98a048503eadfee46add3b8b9c7ae8b1 (HEAD -> master)
Author: Rui Ueyama <ruiu@cs.stanford.edu>
Date: Sat Aug 4 23:12:31 2018 +0000
创建编译一个整数的编译器
diff --git a/9cc.c b/9cc.c
new file mode 100644
index 0000000..e6e4599
--- /dev/null
+++ b/9cc.c
@@ -0,0 +1,16 @@
+#include <stdio.h>
+#include <stdlib.h>
+
+int main(int argc, char **argv) {
+ if (argc != 2) {
...
最后,让我们将创建的 Git 存储库上传到 GitHub。尽管并非一定要上传到 GitHub,但也没有不上传的理由,而且 GitHub 也可用作代码的备份。要上传到 GitHub,请创建一个新的存储库(在本例中,我使用了名为 rui314 的用户创建了名为 9cc 的存储库),然后通过以下命令将该存储库添加为远程仓库。
$ git remote add origin git@github.com:rui314/9cc.git
然后,运行 git push 命令,将本地存储库的内容推送到 GitHub。在运行 git push 后,您可以在浏览器中打开 GitHub,并确认您的源代码已上传。
至此,第 1 步创建编译器的工作已经完成。虽然这一步的编译器可能过于简单以至于不足以称为编译器,但它却是一个包含了所有编译器所需要素的优秀程序。接下来,我们将不断扩展这个编译器,并最终将其发展成一个真正的 C 编译器。请先尝试享受第一步的成就感吧。
参考实现 (第一次代码提交)
f722daaaae060611
步骤2:创建可进行加减运算的编译器
在这一步中,我们将扩展之前创建的编译器,使其能够处理包含加减运算的表达式,例如2+11或5+20-4。
像5+20-4这样的表达式在编译时可以计算出结果的数值(在这个例子中是21),并将该数值嵌入到汇编代码中,但这样做会使编译器变成解释器而不是编译器,因此我们需要在运行时输出执行加减运算的汇编代码。执行加法和减法的汇编指令分别是add和sub。add接收两个寄存器作为参数,将它们的内容相加,并将结果写入第一个参数指定的寄存器。sub与add类似,但执行减法运算。使用这些指令,5+20-4的编译过程如下所示:
.intel_syntax noprefix
.globl main
main:
mov rax, 5
add rax, 20
sub rax, 4
ret
在上面的汇编代码中,通过mov将5设置到RAX中,然后将20加到RAX中,然后减去4。在执行ret时,RAX的值应该是5+20-4,即21。让我们执行并验证一下。将上面的代码保存到tmp.s中,然后汇编并执行:
$ cc -o tmp tmp.s
$ ./tmp
$ echo $?
21
如上所示,正确地显示了21。
现在,我们应该如何生成这个汇编文件呢?如果将这种加减运算的表达式视为一种“语言”,则可以将此语言定义如下:
- 首先有一个数字
- 然后后面跟着0个或多个“项”
- 项可以是后面跟着数字的+,或者后面跟着数字的-
将这个定义直接转换成C代码,得到如下程序:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv) {
if (argc != 2) {
fprintf(stderr, "Argument count is not correct\n");
return 1;
}
char *p = argv[1];
printf(".intel_syntax noprefix\n");
printf(".globl main\n");
printf("main:\n");
printf(" mov rax, %ld\n", strtol(p, &p, 10));
while (*p) {
if (*p == '+') {
p++;
printf(" add rax, %ld\n", strtol(p, &p, 10));
continue;
}
if (*p == '-') {
p++;
printf(" sub rax, %ld\n", strtol(p, &p, 10));
continue;
}
fprintf(stderr, "Unexpected character: '%c'\n", *p);
return 1;
}
printf(" ret\n");
return 0;
}
这段程序略长,但前半部分和ret行与之前相同。添加了一些用于读取项的代码。由于这次不仅仅是读取一个数字,数字后面跟着的是不知道的,因此需要知道读取了多少字符。atoi不会返回读取的字符数,因此不能确定下一项从哪里读取。因此,我们在这里使用了C标准库的strtol函数。
strtol读取数字后,会更新第二个参数指针,使其指向读取的最后一个字符的下一个字符。因此,读取数字后,如果下一个字符是+或-,则p应该指向该字符。在上面的程序中,利用这一事实,在while循环中依次读取项,并在每读取一项时输出一行汇编代码。
现在让我们运行这个修改后的编译器吧。一旦更新了9cc.c文件,只需运行make命令即可生成新的9cc文件。下面是执行示例:
$ make
$ ./9cc '5+20-4'
.intel_syntax noprefix
.globl main
main:
mov rax, 5
add rax, 20
sub rax, 4
ret
看起来汇编代码输出正常。为了测试这个新功能,让我们在test.sh中添加一行测试:
assert 21 "5+20-4"
完成这些后,让我们将更改提交到Git中。执行以下命令:
$ git add test.sh 9cc.c
$ git commit
执行git commit命令后,编辑器会启动,然后写下“添加加法和减法”,保存并退出编辑器。使用git log -p命令来确认提交是否按预期进行。最后,运行git push将提交推送到GitHub,至此,本步骤完成!
参考实现
afc9e8f05faddf05
步骤3:引入标记化器
在之前的步骤中,我们创建的编译器有一个缺点。如果输入中包含空白字符,那么在那一点就会出现错误。例如,给定包含空格的字符串"5 - 3",在尝试读取+或-时会遇到空格字符,导致编译失败。
$ ./9cc '5 - 3' > tmp.s
予期しない文字です: ' '
解决这个问题的方法有几种。一个明显的方法是在尝试读取+或-之前跳过空白字符。虽然这种方法没有特别的问题,但在这一步我们将选择另一种方法来解决问题。这种方法是在读取表达式之前将输入分割成单词。
与日语和英语类似,算术表达式或编程语言也可以被认为是由单词序列组成的。例如,5+20-4由5、+、20、-、4这5个单词组成。这些“单词”的概念在编程中通常称为“标记”(token)。空白字符只是用来分隔标记的,不是标记的一部分。因此,在将字符串分割为标记序列时,去除空白字符是很自然的。将字符串分割为标记序列称为“标记化”。
将字符串分割为标记序列还有其他好处。在将表达式分解为标记时,可以对每个标记进行分类和类型化。例如,+和-是符号,123是一个数字。通过在标记化过程中解释每个标记,可以减少在处理标记序列时需要考虑的事情。
在当前加减法能够处理的表达式语法中,标记的类型有+、-和数字这三种。此外,出于编译器实现的考虑,定义一个表示标记序列结束的特殊类型会使程序变得更简洁(类似于字符串以’\0’结尾)。我们将标记组织成一个通过指针连接的链表,以便处理任意长度的输入。
稍微有点长,但是下面是引入并改进了标记化器的编译器的版本。
#include <ctype.h>
#include <stdarg.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 标记的种类
typedef enum {
TK_RESERVED, // 符号
TK_NUM, // 整数标记
TK_EOF, // 表示输入结束的标记
} TokenKind;
typedef struct Token Token;
// 标记类型
struct Token {
TokenKind kind; // 标记的类型
Token *next; // 下一个输入标记
int val; // 如果kind为TK_NUM,则是该数字的值
char *str; // 标记字符串
};
// 当前正在分析的标记
Token *token;
// 报告错误的函数,与printf相同的参数
void error(char *fmt, ...) {
va_list ap;
va_start(ap, fmt);
vfprintf(stderr, fmt, ap);
fprintf(stderr, "\n");
exit(1);
}
// 如果下一个标记是预期的符号,则读取标记并返回true。否则返回false。
bool consume(char op) {
if (token->kind != TK_RESERVED || token->str[0] != op)
return false;
token = token->next;
return true;
}
// 如果下一个标记是预期的符号,则读取标记。否则报告错误。
void expect(char op) {
if (token->kind != TK_RESERVED || token->str[0] != op)
error("'%c'ではありません", op);
token = token->next;
}
// 如果下一个标记是一个数字,则读取标记并返回该数字。
// 否则报告错误。
int expect_number() {
if (token->kind != TK_NUM)
error("数ではありません");
int val = token->val;
token = token->next;
return val;
}
bool at_eof() {
return token->kind == TK_EOF;
}
// 创建一个新标记并将其连接到cur
Token *new_token(TokenKind kind, Token *cur, char *str) {
Token *tok = calloc(1, sizeof(Token));
tok->kind = kind;
tok->str = str;
cur->next = tok;
return tok;
}
// 将输入字符串p标记化并返回它
Token *tokenize(char *p) {
Token head;
head.next = NULL;
Token *cur = &head;
while (*p) {
// 跳过空白字符
if (isspace(*p)) {
p++;
continue;
}
if (*p == '+' || *p == '-') {
cur = new_token(TK_RESERVED, cur, p++);
continue;
}
if (isdigit(*p)) {
cur = new_token(TK_NUM, cur, p);
cur->val = strtol(p, &p, 10);
continue;
}
error("无法标记化");
}
new_token(TK_EOF, cur, p);
return head.next;
}
int main(int argc, char **argv) {
if (argc != 2) {
error("参数数量不正确");
return 1;
}
// 标记化
token = tokenize(argv[1]);
// 输出汇编的前半部分
printf(".intel_syntax noprefix\n");
printf(".globl main\n");
printf("main:\n");
// 表达式的开头必须是一个数字,检查它并输出第一个mov指令
printf(" mov rax, %d\n", expect_number());
// 消耗`+ <数>`或`- <数>`这样的标记序列,并输出汇编
while (!at_eof()) {
if (consume('+')) {
printf(" add rax, %d\n", expect_number());
continue;
}
expect('-');
printf(" sub rax, %d\n", expect_number());
}
printf(" ret\n");
return 0;
}
这段
代码大约有150行,虽然并不是非常短,但如果从上往下读,应该是可以读懂的。
让我们解释一些上面代码中使用的编程技巧。
- 解析器读取的标记序列由全局变量token表示。解析器通过遍历由指针连接的标记链表来读取输入。虽然这种全局变量的使用方式可能不太清晰,但实际上,将输入标记序列视为类似于标准输入流的流是使解析器代码更易读的一种方法。因此,在这里选择了这种风格。
- 将token分解为函数consume和expect等中不直接接触token的函数中。这些函数之外的函数不直接接触token。
- tokenize函数构建了一个连接列表。构建连接列表时,通过创建一个虚拟的head元素,并将新元素连接到该head后面,最后返回head->next,可以使代码更简洁。尽管这种方法会导致head元素分配的内存几乎没有被使用,但是局部变量的分配成本几乎为零,因此没有什么需要担心的。
- calloc函数类似于malloc,用于分配内存。与malloc不同,calloc会将分配的内存清零。在这里,我们选择使用calloc来节省清除元素的麻烦。
通过这个改进版本,应该已经能够跳过空白字符了。让我们添加以下测试行到test.sh中:
assert 41 " 12 + 34 - 5 "
在编写测试时,请确保整个表达式的结果在0到255之间。
将测试文件添加到git仓库后,这一步就完成了。
参考实现 ef6d1791eb2a5ef3
步骤4:改进错误消息
到目前为止,我们编写的编译器在输入有语法错误时只能知道出现了错误,但无法准确指出错误的位置。在这一步中,我们将改进这个问题,使其能够显示直观易懂的错误消息。具体来说,我们将能够显示像下面这样的错误消息:
$ ./9cc "1+3++" > tmp.s
1+3++
^ 数ではありません
$ ./9cc "1 + foo + 5" > tmp.s
1 + foo + 5
^ トークナイズできません
为了显示这样的错误消息,我们需要在发生错误时知道它发生在输入的第几个字节处。为此,我们决定将整个程序字符串保存在名为user_input的变量中,并定义一个新的错误显示函数,该函数接受一个指向字符串中间的指针。以下是该代码:
// 输入程序
char *user_input;
// 报告错误位置
void error_at(char *loc, char *fmt, ...) {
va_list ap;
va_start(ap, fmt);
int pos = loc - user_input;
fprintf(stderr, "%s\n", user_input);
fprintf(stderr, "%*s", pos, " "); // 输出pos个空格
fprintf(stderr, "^ ");
vfprintf(stderr, fmt, ap);
fprintf(stderr, "\n");
exit(1);
}
error_at函数接受的指针指向程序字符串的中间。通过将该指针与指向输入开头的指针进行减法操作,我们可以知道错误的位置在输入的第几个字节处,然后用^符号标记出来。
如果将argv[1]保存到user_input中,并将类似error("数ではありません")的代码更新为error_at(token->str, "数ではありません"),那么这一步就完成了。
在实际使用的编译器中,应该编写关于错误处理的测试。但是,由于目前错误消息仅用于调试目的,因此在此阶段不需要编写特定的测试。
参考实现 c6ff1d98a1419e69
专栏:源代码格式化器
就像日语文章中常常有错别字或者标点符号错误一样,如果源代码的缩进不正确或者空格使用不一致,那么即使代码本身是正确的,也不能称之为高质量的代码。在处理代码格式化等看似不那么重要的部分时,请注意要机械地应用一定的规则,以编写易于阅读的代码,避免分散注意力。
在团队开发时,需要商讨并决定使用何种格式,但在本书中由于是单人开发,因此可以从一些流行的格式中自行选择喜欢的格式。
最近开发的一些语言提供了语言官方的代码格式化工具,以消除关于选择哪种格式的讨论,尽管个人偏好可能会有所不同,但这不是必要的讨论。例如,Go语言提供了一个名为gofmt的命令,可以将源代码格式化为一致的风格。gofmt没有选项来选择格式,可以说是唯一的“Go官方格式”,这样做是为了消除有关如何进行格式化的问题,从而完全解决了Go语言的格式化问题。
在C和C++中,有一个称为clang-format的格式化工具,但在本书中,并不特别推荐使用这样的工具。请尽量避免编写格式不正确的代码,然后再对其进行格式化,而应该一开始就注意编写一致的代码。
专栏:缩进错误导致的安全漏洞
由于源代码的缩进错误,曾经在iOS和macOS中出现了严重的安全问题。下面是有bug的代码片段:
if ((err = ReadyHash(&SSLHashSHA1, &hashCtx)) != 0)
goto fail;
if ((err = SSLHashSHA1.update(&hashCtx, &clientRandom)) != 0)
goto fail;
if ((err = SSLHashSHA1.update(&hashCtx, &serverRandom)) != 0)
goto fail;
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
读者是否能够发现其中的bug?这段代码看起来像是普通的代码片段,但仔细观察会发现倒数第二个goto语句没有被包含在if语句中,因此它总是会被执行。
不幸的是,这段代码是写在用于验证TLS证书的函数中的,结果导致证书验证代码的大部分都被无条件地跳过,从而使得iOS/macOS将恶意证书当作合法证书接受(允许伪装HTTPS站点)。这个bug是在2014年被发现和修复的。由于额外的goto fail导致程序失败,因此这个bug被称为goto fail bug。
语法描述方法和递归下降语法分析
现在,我们想要向语言中添加乘法、除法以及优先级括号,即*、/、(),但为了实现这一点,有一个技术上的挑战。这是因为乘法和除法必须在表达式中首先进行计算的规则。例如,表达式1+23应该解释为1+(23),而不应该解释为(1+2)*3。这种规则,即哪个运算符首先“结合”,称为“运算符优先级”(operator precedence)。
如何处理运算符优先级呢? 在迄今为止创建的编译器中,我们只是从头开始读取令牌序列并输出汇编代码,因此如果直接添加和/,那么1+23就会被编译为(1+2)*3。
现有的编译器自然可以很好地处理运算符优先级。编译器的语法分析非常强大,只要代码符合语法规则,就可以正确地解释任何复杂的代码。这种编译器的行为甚至可能会让人感受到超越人类的智能,但实际上,计算机没有人类的文本理解能力,因此语法分析应该是完全由某种机械化的机制来完成的。那么它具体是如何运作的呢?
在本章中,让我们暂停一下编码,学习一些关于语法分析技术的知识。本章将按照以下顺序解释语法分析技术:
- 通过了解解析器输出的数据结构,首先了解最终目标。
- 学习定义语法规则的规则。
- 基于定义语法规则的规则,学习编写解析器的技巧。
- 使用树结构表示语法结构
在编程语言的解析器实现中,输入通常是一个扁平的令牌序列,而输出是表示嵌套结构的树。本书中创建的编译器也遵循了这种结构。
在C语言中,可以将诸如if和while之类的语法元素嵌套在一起。将这些内容用树结构表示是一种自然的表达方式。
表达式中存在着先计算括号中的内容,或者先计算乘除法而不是加减法的结构。这种结构一开始可能不太像树,但实际上使用树可以非常简单地表示表达式的结构。例如,表达式1*(2+3)可以通过以下树来表示。
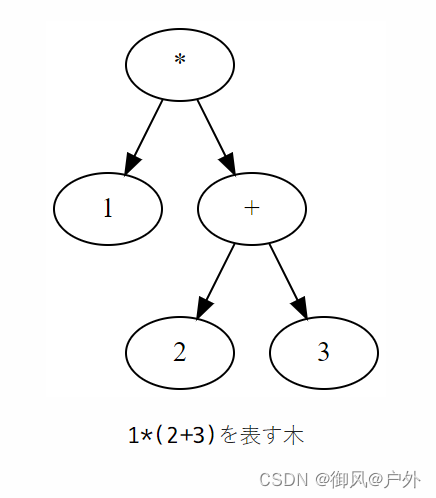
如果采用从树的末端开始逐步计算的规则,上述树表示了将1乘以2+3的表达式。换句话说,在上述树中,1*(2+3)的具体计算顺序通过树的形状本身得到了表达。
让我们举个例子。下面的树表示了7-3-3的表达式。
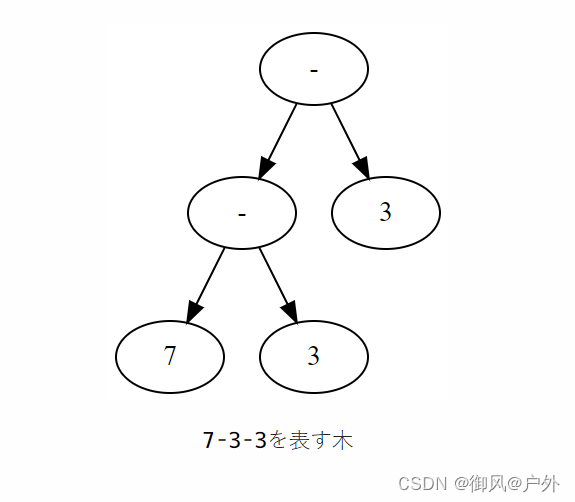
在上述树中,“减法必须从左边开始计算”的规则应用结果明确地反映在了树的形状中。也就是说,上述树表示了(7-3)-3 = 1这个表达式,并不是7-(3-3) = 7。如果是后者,相应的树将会在右侧变得更深。
在树结构中,通过增加树的深度,可以表示任意长的表达式。下面的树表示了12+34*5。
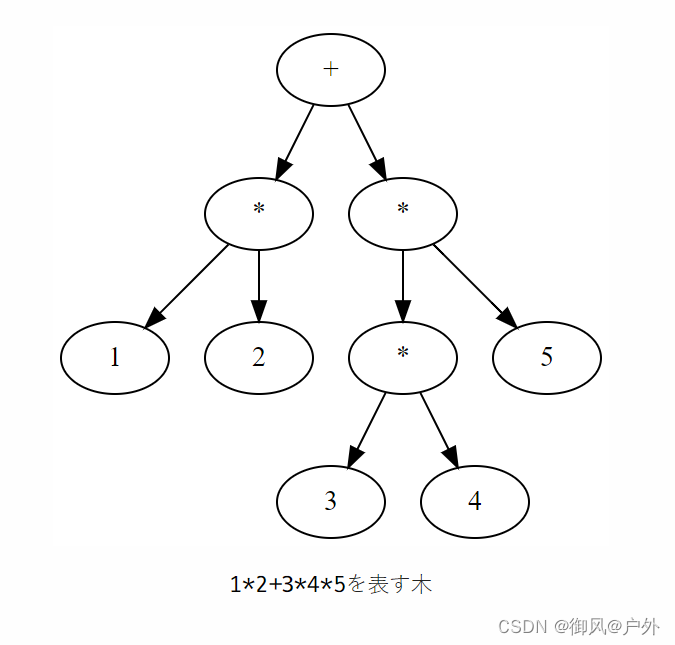
像上面的树一样的结构被称为“语法树”(syntax tree)。特别是,没有冗余元素,如用于分组的括号等,尽可能紧凑地表示的语法树被称为“抽象语法树”(abstract syntax tree,AST)。上面的语法树都可以称为抽象语法树。
由于抽象语法树是编译器的内部表示,因此可以根据实现的需要进行适当的定义。然而,像加法和乘法这样的算术运算符是针对左右两侧的操作数定义的,因此在任何编译器中,将其表示为二叉树是自然的。另一方面,像函数体内的表达式等按顺序执行的部分可以用扁平树表示。
在语法分析中,目标是构建抽象语法树。编译器首先进行语法分析,将输入的令牌序列转换为抽象语法树,然后将该语法树转换为汇编代码。
生成规则文法的定义
现在,让我们学习一下编程语言语法的描述方法。编程语言的大部分语法都是使用所谓的“生成规则”来定义的。生成规则是递归定义语法的规则。
让我们先来考虑一下自然语言。在日语中,语法是嵌套结构的。例如,句子“花很漂亮”中的名词“花”可以替换为“红花”这样的名词短语,这仍然是一个正确的句子,而“红”也可以进一步展开为“稍微红”的形容词,这同样是一个正确的句子。甚至可以将它嵌入到另一个句子中,比如“我觉得稍微红的花很漂亮”。
将这种语法视为一种“句子由主语和谓语组成”的规则,或者“名词短语由名词或者形容词后跟着名词短语的组合”这样的规则来定义。通过按照这些规则展开,可以生成无数符合定义语法的合法句子。
反之,也可以考虑针对已经存在的句子,考虑与之匹配的展开过程,从而了解该字符串具有什么样的结构。
尽管最初这种想法是为了自然语言而提出的,但由于与计算机处理数据的契合度非常高,生成规则在计算机科学中被广泛应用,包括编程语言等各个领域。
专栏: 乔姆斯基的生成语法
提出生成语法这一概念的是语言学家诺姆·乔姆斯基。他的想法对语言学和计算机科学产生了非常大的影响。
根据乔姆斯基的假设,人类之所以能够说话,是因为人类天生具有获取生成规则的专用电路,这些电路存在于大脑中。人类具有递归语言规则获取能力,因此可以说话。其他动物没有语言获取能力,他认为这是因为除了人类之外的动物大脑中不存在获取生成规则的电路。乔姆斯基的论断至今已有近60年,尚未得到证实或证伪,但目前仍被认为具有相当的说服力。
使用BNF描述生成规则
为了紧凑且易于理解地描述生成规则,存在一种记法称为BNF(巴科斯-诺尔范式),以及其扩展版本EBNF(扩展巴科斯-诺尔范式)。本书将使用EBNF来解释C语言的语法。在这一节中,首先解释BNF,然后解释EBNF的扩展部分。
在BNF中,每个生成规则以A = α₁α₂⋯的形式表示。这表示符号A可以扩展为α₁α₂⋯。α₁α₂⋯是一个包含零个或多个符号的序列,可以包含既不能进一步扩展的符号,又包含可进一步扩展(在任何一个生成规则的左侧)的符号。
既不能进一步扩展的符号称为“终结符号”(terminal symbol),而可以出现在某些生成规则左侧并且可以扩展的符号称为“非终结符号”(nonterminal symbol)。用这样的生成规则定义的语法通常称为“上下文无关文法”(context free grammar)。
非终结符号可以匹配多个生成规则。例如,如果存在A = α₁和A = α₂两个规则,则A可以展开为α₁或α₂,这意味着。
生成规则的右侧也可以为空。在这种规则中,左侧的符号将展开为空符号串(即为空)。但是,出于表示上的考虑,通常将右侧省略会使意义变得不明确,因此在这种情况下,通常会将ε(epsilon)写在右侧,表示空字符串。本书也采用了这种规则。
字符串用双引号括起来,比如"foo"。字符串始终是终结符。
以上是基本的BNF规则。在EBNF中,除了BNF的规则外,还可以使用以下符号来简洁地编写复杂的规则。
| 符号 | 含义 |
|---|---|
| A* | A的零次或多次重复 |
| A? | A或ε |
| A | B | A或B |
| ( … ) | 分组 |
例如,对于A = (“fizz” | “buzz”)*,A可以展开为零次或多次重复的"fizz"或"buzz"组成的字符串,即:
""
"fizz"
"buzz"
"fizzfizz"
"fizzbuzz"
"buzzfizz"
"buzzbuzz"
"fizzfizzfizz"
"fizzfizzbuzz"
⋯⋯
可以展开为其中任意一个。
专栏: BNF与EBNF
普通的BNF中没有像 *、?、|、( … ) 这样简洁的表示方法,但是通过以下方式可以将由BNF和EBNF生成的文本转换成相同的结果。
| EBNF | 对应的BNF |
|---|---|
| A = α* | A = αA 和 A = ε |
| A = α? | A = α 和 A = ε |
| A = α | β | A = α 和 A = β |
| A = α (β₁β₂⋯) γ | A = α B γ 和 B = β₁β₂⋯ |
例如,使用生成规则 A = αA 和 A = ε 时,从A生成ααα文本的展开顺序如下: A → αA → ααA → αααA → ααα。
因此,* 和 ? 等符号仅仅是一种简化表示方式,但通常更短的书写方式更易于理解和使用,因此在可以使用短记法的情况下,通常会选择使用它们来简洁地描述文法。
简单的生成规则
作为使用EBNF描述语法的示例,让我们考虑以下生成规则。
expr = num (“+” num | “-” num)*
这里假设 num 已经在其他地方被定义为表示数字的符号。在这个语法中,expr首先有一个num,然后是零个或多个"加号和num"或"减号和num"。这个规则实际上描述了加减法表达式的语法。
从expr开始展开,我们可以生成任意的加减法字符串,例如1,10+5,42-30+2等。请看下面的展开结果。
expr → num → “1”
expr → num “+” num
→ “10” “+” “5”
expr → num “-” num “+” num
→ “42” “-” “30” “+” “2”
除了使用箭头表示展开顺序之外,我们也可以使用树结构来表示。下面是上述表达式的语法树。
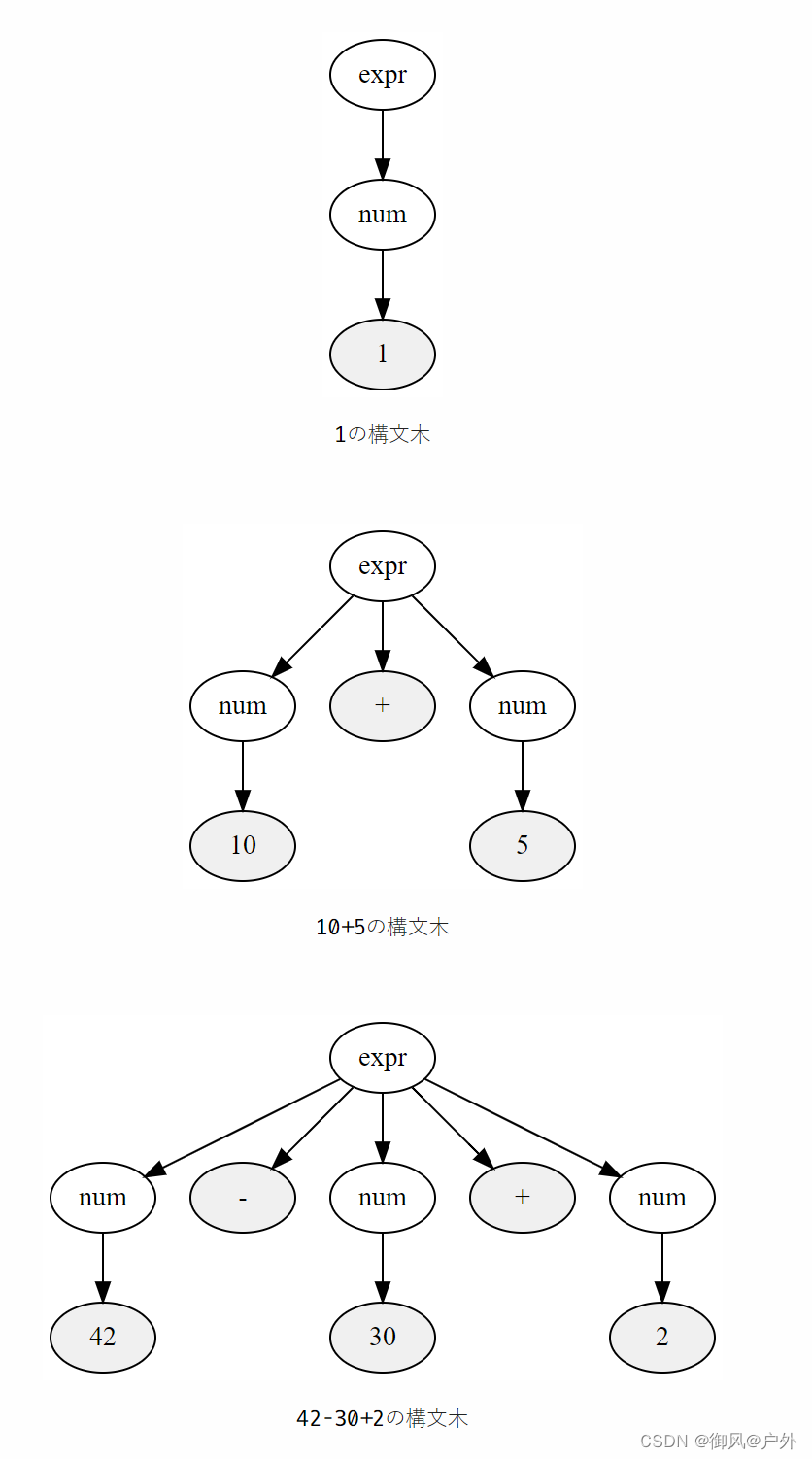
通过使用树结构,我们更清楚地知道了哪些非终端符号被展开为哪些符号。
类似上图中所示,包含输入中所有令牌的语法树与文法完全一致,这种树被称为"具体语法树"。这个术语经常用于与抽象语法树进行对比。
值得注意的是,在上述具体语法树中,未表达从左边计算加减法的规则。这样的规则在这里的语法中不是使用EBNF表达的,而是在语言规范中作为文字说明书写为“加减法从左至右计算”。解析器会同时考虑EBNF和说明书,读取表示表达式的令牌序列,并构建正确表示表达式评估顺序的抽象语法树。
因此,上述文法中,由EBNF表示的具体语法树和解析器的输出的抽象语法树的形式大致不匹配。虽然可以定义文法使得抽象语法树和具体语法树尽可能相似,但这样做会使文法变得冗长,使解析器的编写变得困难。上述文法的形式是一种平衡形式的文法,既严格又易于理解,同时也通过自然语言补充了明确性。
根据生成规则表示运算符优先级
生成规则是表示语法的强大工具。通过巧妙地设计文法,我们可以在生成规则中表示运算符的优先级。下面是这个文法的示例。
expr = mul ("+" mul | "-" mul)*
mul = num ("*" num | "/" num)*
在之前的规则中,expr直接展开为num,但是现在,expr通过mul展开为num。mul表示乘除法的生成规则,而expr表示进行加减法,可以将mul看作是一个组成部分。在这个文法中,乘除法优先于加减法的规则自然地在语法树中得到了体现。让我们看一些具体的例子。
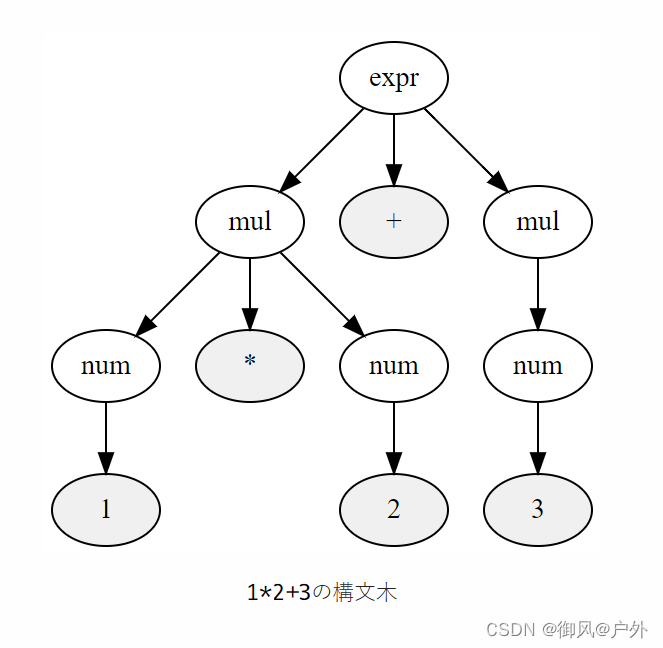
1*2+3的语法树
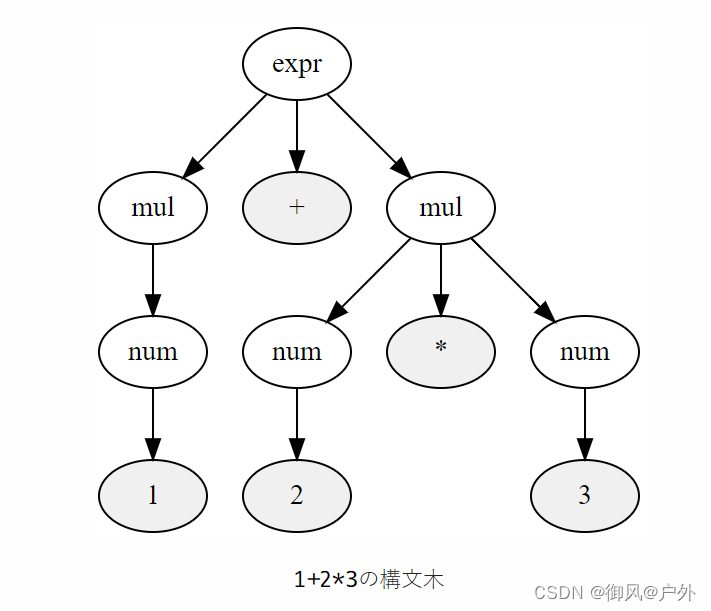
1+23的语法树
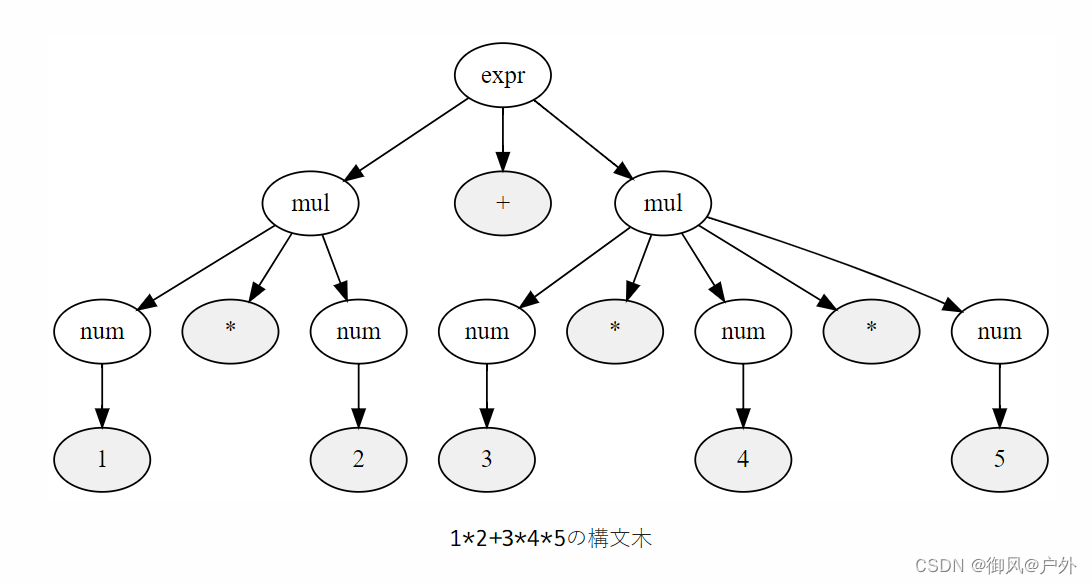
12+345的语法树
在上述语法树中,乘法始终出现在加法之前,向树的末端方向延伸。实际上,由于没有从mul返回到expr的规则,所以不能构造出乘法下面有加法的树。尽管如此,仍然感到奇怪的是,这样简单的规则竟能很好地在树形结构中表示优先级。我鼓励读者们将生成规则与语法树结合起来,验证语法树的正确性。
包含递归的生成规则
在生成文法中,我们可以普通地编写递归的语法。以下是将括号优先级添加到四则运算中的文法生成规则。
expr = mul ("+" mul | "-" mul)*
mul = primary ("*" primary | "/" primary)*
primary = num | "(" expr ")"
与以前的文法相比,上述文法中允许出现primary,即num或"(" expr “)”。换句话说,在这个新文法中,括号括起来的表达式与以前的单一数字一样被处理。让我们来看一个例子。
下面的树结构表示了1*2。
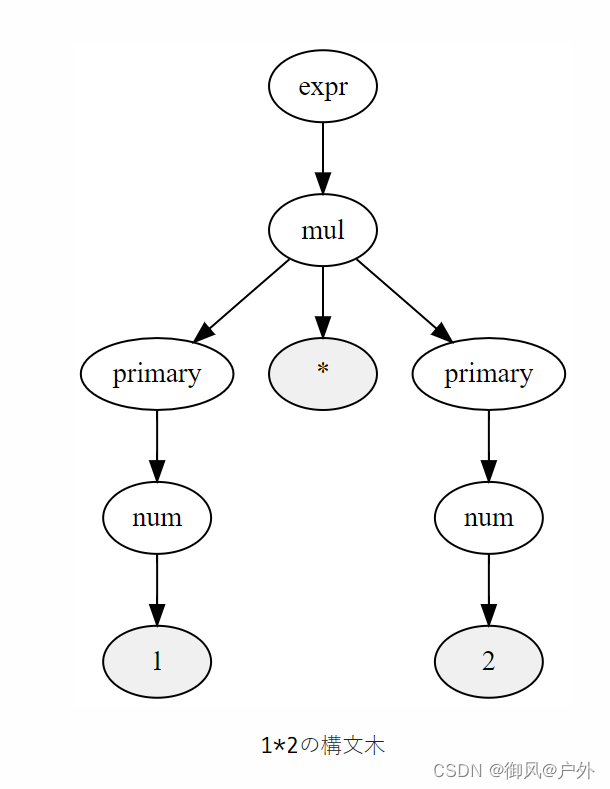
1*2的语法树
下面的树结构表示了1*(2+3)。
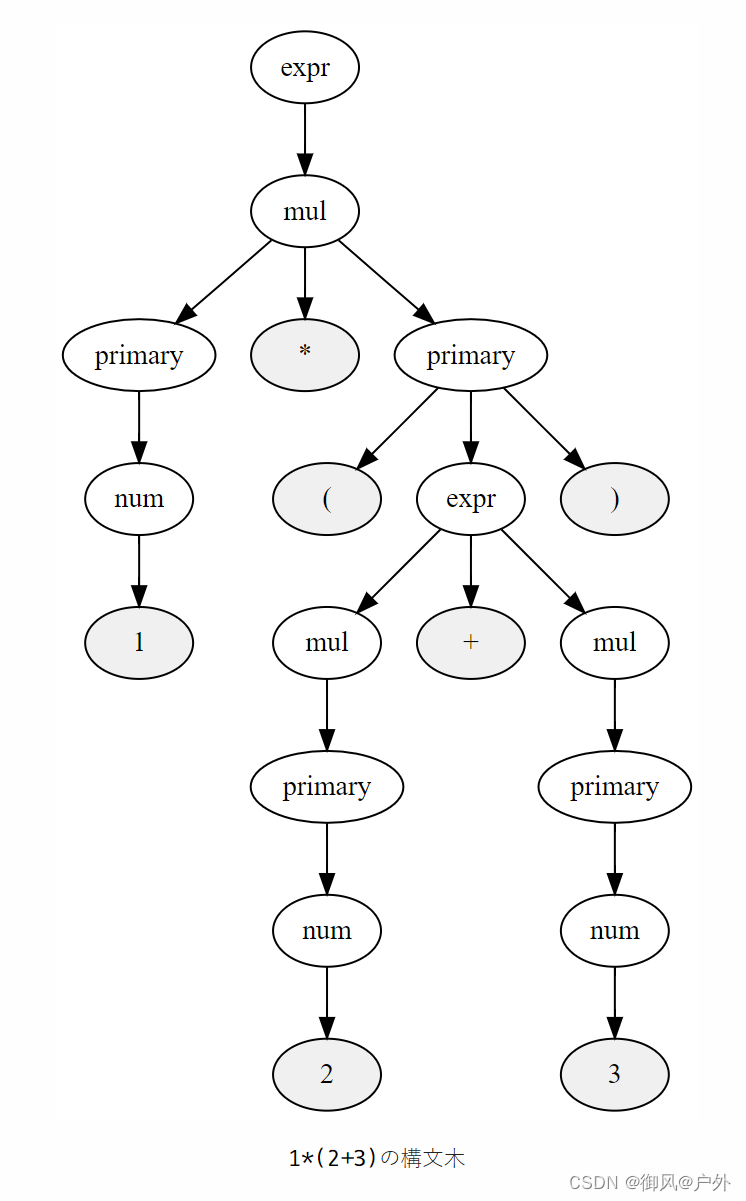
1*(2+3)的语法树
比较这两个树,我们可以看到mul右侧的primary的展开结果是唯一不同的。树结构中出现的末端primary可以展开为单个数字,也可以展开为括号括起来的任意表达式,这个规则在树结构中得到了准确的反映。能够用如此简单的生成规则来处理括号优先级,是不是有点令人感动呢?
递归下降语法分析
如果给定了C语言的生成规则,我们可以通过不断展开这些规则来机械地生成任意正确的C程序,从生成规则的角度来看。但在9cc中,我们实际上想要做的事情相反。我们希望从外部以字符串形式提供C程序,并了解展开后与输入字符串相同的展开步骤,即想要知道与输入相同的字符串形成的语法树结构。
实际上,对于某些生成规则,一旦给定规则,就可以机械地编写代码来找到与该规则生成的文本匹配的语法树。这里介绍的"递归下降语法分析法"就是这种技术之一。
例如,考虑四则运算的语法。再次列出四则运算的语法:
expr = mul ("+" mul | "-" mul)*
mul = primary ("*" primary | "/" primary)*
primary = num | "(" expr ")"
在使用递归下降语法分析器时的基本策略是将这些非终结符一一映射到函数。因此,解析器将具有expr、mul、primary这三个函数。每个函数将解析与其名称相对应的标记列。
具体来说,让我们来考虑一下代码。传递给解析器的输入是标记序列。由于我们希望从解析器返回抽象语法树,因此让我们定义抽象语法树节点的类型。节点的类型如下所示:
// 抽象语法树的节点类型
typedef enum {
ND_ADD, // +
ND_SUB, // -
ND_MUL, // *
ND_DIV, // /
ND_NUM, // 整数
} NodeKind;
typedef struct Node Node;
// 抽象语法树的节点类型
struct Node {
NodeKind kind; // 节点的类型
Node *lhs; // 左边
Node *rhs; // 右边
int val; // 仅当kind为ND_NUM时使用
};
这里的lhs和rhs分别是左手边和右手边的意思。
我们还定义了创建新节点的函数。在这个四则运算的语法中,我们有两种类型的二元操作符和数字,因此我们为这两种情况准备了两个函数。
Node *new_node(NodeKind kind, Node *lhs, Node *rhs) {
Node *node = calloc(1, sizeof(Node));
node->kind = kind;
node->lhs = lhs;
node->rhs = rhs;
return node;
}
Node *new_node_num(int val) {
Node *node = calloc(1, sizeof(Node));
node->kind = ND_NUM;
node->val = val;
return node;
}
现在,我们有了所有这些函数和数据类型,让我们来编写解析器。由于+和-是左结合的操作符,我们将以以下模式编写解析函数:
Node *expr() {
Node *node = mul();
for (;;) {
if (consume('+'))
node = new_node(ND_ADD, node, mul());
else if (consume('-'))
node = new_node(ND_SUB, node, mul());
else
return node;
}
}
这里的consume是在之前的步骤中定义的函数,它在输入流的下一个标记与参数匹配时,将输入向前移动一个标记并返回真。
请仔细阅读expr函数。您可能会注意到expr = mul (“+” mul | “-” mul)*这个生成规则直接映射到函数调用和循环。从expr函数返回的抽象语法树中,运算符是左结合的,换句话说,返回的节点的左侧分支更深。
我们还要定义mul函数,因为*和/也是左结合的操作符,所以我们可以使用相同的模式。该函数如下所示:
Node *mul() {
Node *node = primary();
for (;;) {
if (consume('*'))
node = new_node(ND_MUL, node, primary());
else if (consume('/'))
node = new_node(ND_DIV, node, primary());
else
return node;
}
}
这段代码的函数调用关系与mul = primary (“*” primary | “/” primary)*这个生成规则完全对应。
最后,让我们定义primary函数。由于primary不是左结合的操作符,所以上面的代码模式不适用,但我们可以通过直接映射primary = “(” expr “)” | num这个生成规则的函数调用来定义primary函数:
Node *primary() {
// 如果下一个标记是"(",则应该是"(" expr ")"。
if (consume('(')) {
Node *node = expr();
expect(')');
return node;
}
// 否则应该是数字。
return new_node_num(expect_number());
}
现在,我们有了所有的函数,但是我们是否真的可以解析标记序列呢?可能一开始不太清楚,但是使用这些函数确实可以很好地解析标记序列。让我们以表达式1+2 * 3为例。
首先调用的是expr。作为整个表达式的一部分,我们假定它是expr(在这种情况下,确实如此),并开始读取输入。接着,expr→mul→primary等函数调用,读取了1并返回1表示的语法树。
然后,在expr中,consume(‘+’)表达式为真,因此+标记被消耗掉,并且mul再次被调用。此时输入的剩余部分是2 * 3。
与上次相同,mul再次调用primary,并读取了2,但这次mul不会立即返回。由于mul中的consume('')表达式为真,mul再次调用primary,并读取了3。结果,mul返回了表示2 * 3的语法
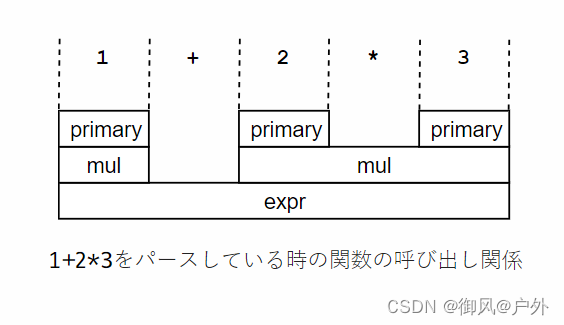
解析1+2 * 3时的函数调用关系
以下是一个稍微复杂一点的例子。下图显示了在解析12+(3+4)时的函数调用关系。
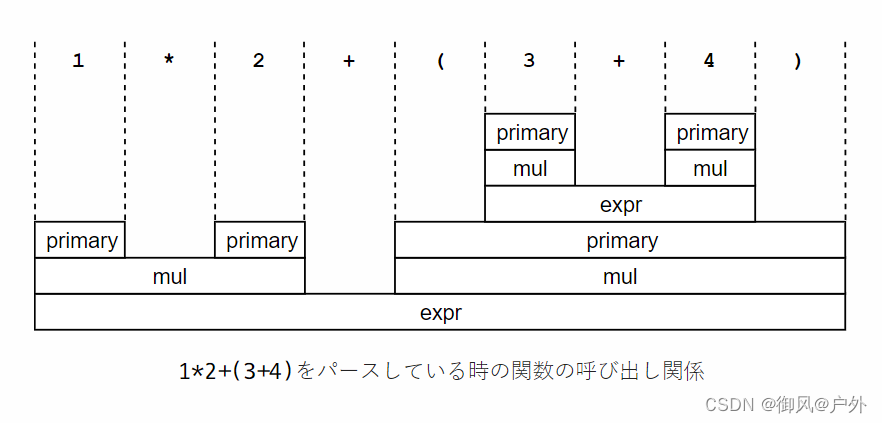
解析1*2+(3+4)时的函数调用关系
对于不熟悉递归的程序员来说,像上面这样的递归函数可能会感到难以理解。坦率地说,即使是作者这样非常熟悉递归的人,也会觉得这种代码像是一种魔法一样能运行。递归代码即使你理解了其原理,也会感觉有些神秘,但这可能就是它的本质。请尝试多次在脑海中追踪代码,并确保代码能够正常工作。
将单个生成规则映射到单个函数的语法分析技术称为"递归下降语法解析"。在上面的解析器中,我们预读了一个标记,然后决定调用哪个函数,或者返回。这种只预读一个标记的递归下降解析器称为LL(1)解析器。而能够编写LL(1)解析器的文法称为LL(1)文法。
栈机
前一章我们讲解了将令牌序列转换为抽象语法树的算法。通过选择考虑运算符优先级的文法,我们能够创建抽象语法树,其中*和/总是位于+和-之前。但是,我们应该如何将这棵树转换为汇编代码呢?本章将介绍这种方法。
首先,让我们思考为什么加法和减法不能像加法和减法一样简单地转换为汇编代码。在能够执行加法和减法的编译器中,我们将RAX寄存器用作结果寄存器,并在其中执行加法或减法。换句话说,在编译的程序中,我们仅保留了一个中间计算结果。
然而,当涉及到乘除法时,中间计算结果可能不止一个。例如,考虑表达式23+45。为了执行加法,我们需要计算23和45。换句话说,在这种情况下,我们需要同时保持两个中间计算结果,否则无法完成整个计算。
这种类型的计算可以很容易地通过一种称为“栈机”的计算机来完成。在这里,我们暂时离开由解析器创建的抽象语法树,学习一下栈机。
栈机的概念
栈机是一种具有栈作为数据存储区域的计算机。因此,在栈机中,“推入栈”和“弹出栈”是两个基本操作。推入操作将新元素放置在栈的顶部。弹出操作将从栈的顶部移除一个元素。
栈机中的运算指令作用于栈顶元素。例如,栈机的ADD指令从栈顶弹出两个元素,将它们相加,并将结果推入栈中(为了避免与x86-64指令混淆,我们将虚拟栈机指令全部使用大写字母表示)。换句话说,ADD指令将栈顶的两个元素替换为它们的和。
SUB、MUL和DIV指令与ADD类似,它们将栈顶的两个元素替换为它们的差、积或商。
PUSH指令将参数元素推入栈顶。虽然这里不使用,但也可以考虑从栈顶弹出并丢弃一个元素的POP指令。
现在,让我们使用这些指令来计算2 * 3+4 * 5。通过使用我们定义的栈机,应该可以使用以下代码来计算2 * 3+4 * 5。
// 计算2*3
PUSH 2
PUSH 3
MUL
// 计算4*5
PUSH 4
PUSH 5
MUL
// 计算2*3 + 4*5
ADD
让我们仔细看看这段代码。假设栈中已经有一些值,这里并不重要,我们用“⋯”表示。栈被假定为从上到下扩展。
前两个PUSH将2和3推入栈,因此在执行MUL之前,栈的状态如下:
| ⋯ |
|---|
| 2 |
| 3 |
MUL从栈顶弹出两个值,即3和2,将它们相乘得到6,并将结果推入栈中。因此,执行MUL后,栈的状态如下:
| ⋯ |
|---|
| 6 |
接下来的两个PUSH将4和5推入栈中,因此在执行第二个MUL之前,栈的状态应该如下:
| ⋯ |
|---|
| 6 |
| 4 |
| 5 |
在执行MUL之后,5和4被弹出,并被替换为它们的乘积,即20。因此,执行MUL后,栈的状态如下:
| ⋯ |
|---|
| 6 |
| 20 |
请注意,2 * 3和4 * 5的计算结果已经正确地保留在栈中。在这种状态下执行ADD,计算出20+6,并将结果推入栈中,最终栈的状态应该如下:
| ⋯ |
|---|
| 26 |
栈机的计算结果位于栈顶的值,因此26就是2 * 3+4*5的结果,说明这个表达式已经正确地计算出来了。
使用栈机,无论是什么样的表达式,只要它们遵循将计算结果作为一个元素保留在栈中的约定,就可以有效地通过以上方法编译。
专栏:CISC与RISC
x86-64是从1978年发布的8086逐步发展而来的指令集,是典型的“CISC”(复杂指令集计算机)风格的处理器。CISC处理器的特点包括:机器语言操作不仅可以涉及寄存器,还可以涉及内存地址;机器语言指令的长度可变;具有许多可以在一个指令中执行的复杂操作,这对汇编程序员来说非常方便,等等。
相对于CISC,1980年代发明的是“RISC”(精简指令集计算机)。RISC处理器的特点包括:运算必须在寄存器之间进行,而对内存的操作仅限于加载到寄存器和从寄存器存储;机器语言指令的长度在所有指令中都是相同的;没有为汇编程序员提供便利的复合指令,而只提供编译器生成的简单指令,等等。
x86-64是CISC的少数幸存者之一,除x86-64外的其他主要处理器几乎全部基于RISC。具体来说,ARM、PowerPC、SPARC、MIPS、RISC-V(精简指令集计算机五)等都是RISC处理器。
RISC不支持像x86-64那样的内存与寄存器之间的操作,也不存在寄存器的别名。也没有特定的整数寄存器在特定指令中特别使用的规则。从现代的角度来看,这种指令集看起来有些陈旧。
由于其简单的设计,RISC处理器易于加速,席卷了处理器行业。那么为什么x86-64能够成功存活呢?其中一个原因是市场对能够利用现有软件资产的高速x86处理器的巨大需求,以及英特尔及其兼容芯片制造商为满足这一需求而进行的技术创新。英特尔通过CPU指令解码器将x86指令转换为内部的某种RISC指令,从而在内部将x86转化为RISC处理器。这样就可以将RISC成功加速的技术应用到x86上。
将抽象语法树编译为堆栈机器代码
在本节中,我们将讨论将抽象语法树转换为堆栈机器代码的方法。一旦我们掌握了这种转换技巧,就可以解析由四则运算组成的表达式,构建抽象语法树,并将其编译成使用x86-64指令的堆栈机器,然后执行。换句话说,我们将能够编写能够执行四则运算的编译器。
在堆栈机器中,计算部分表达式后,无论结果是什么,都会在堆栈顶部留下一个值。例如,请考虑以下树形结构。
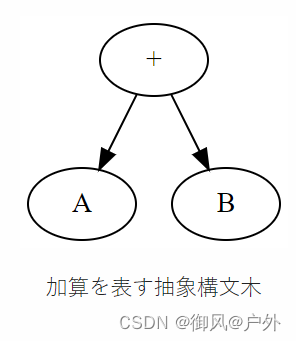
表示加法的抽象语法树
这里的A和B是对部分树的抽象表示,实际上它们代表某种类型的节点。然而,在编译整个树时,这些具体类型和树的形状并不重要。我们只需要按照以下步骤进行编译:
- 编译左子树
- 编译右子树
- 输出用于将堆栈中的两个值替换为它们的总和的代码
执行第一步后,无论具体的代码是什么,左子树的结果应该在堆栈顶部。同样地,执行第二步后,右子树的结果应该在堆栈顶部。因此,要计算整个树的值,我们只需将这两个值替换为它们的总和。
因此,编译抽象语法树为堆栈机器时,我们会递归地考虑,逐步输出代码,沿着树向下移动。对于不熟悉递归思想的读者来说,这可能有点困难,但是在处理像树这样的自相似数据结构时,递归是一个常见的技巧。
让我们通过下面的例子来具体考虑。
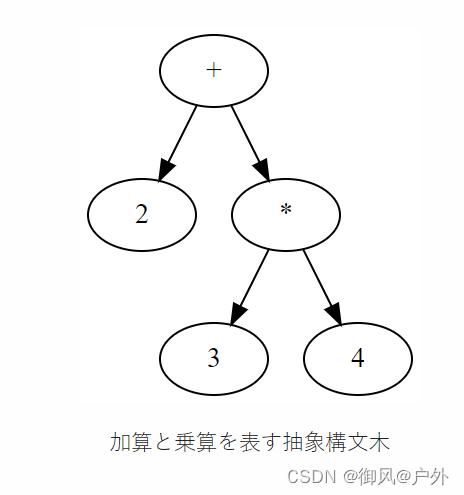
表示加法和乘法的抽象语法树
生成代码的函数将接收树的根节点。
按照上述步骤,该函数首先要做的是编译左子树。换句话说,它要编译数字2。由于计算2的结果仍然是2,因此左子树的编译结果是PUSH 2。
然后,生成代码的函数尝试编译右子树。这将导致递归地编译左子树,结果输出PUSH 3。接下来是编译右子树的右子树,这将输出PUSH 4。
然后,生成代码的函数会在递归调用返回时输出与部分树操作符类型相匹配的代码。首先输出的是用于将堆栈顶部的两个元素替换为它们的乘积的代码。然后,输出将堆栈顶部的两个元素替换为它们的总和的代码。结果,以下汇编代码将被输出:
PUSH 2
PUSH 3
PUSH 4
MUL
ADD
使用这种方法,我们可以将抽象语法树机械地转换为汇编代码。
在x86-64中实现堆栈机器的方法
到目前为止,我们讨论的是虚拟堆栈机器。实际的x86-64是一台寄存器机器,而不是堆栈机器。x86-64的运算通常针对两个寄存器定义,而不是针对堆栈顶部的两个值定义。因此,为了在x86-64上使用堆栈机器技术,我们需要在寄存器机器上以某种方式模拟堆栈机器。
在寄存器机器上模拟堆栈机器相对容易。我们只需要用多个指令来实现堆栈机器中的单个指令即可。
让我们来详细说明一下这种具体方法。
首先,我们需要准备一个寄存器来指向堆栈的顶部元素。这个寄存器称为堆栈指针。如果想要弹出堆栈顶部的两个值,那么我们需要取出堆栈指针指向的两个元素,并相应地更改堆栈指针的值。同样地,当要执行推入操作时,我们只需要在更改堆栈指针的值的同时将数据写入堆栈指针所指示的内存区域即可。
在x86-64中,RSP寄存器被设计为堆栈指针。x86-64的push和pop等指令隐式地使用RSP作为堆栈指针,并在更改其值的同时访问RSP指向的内存。因此,在使用x86-64指令集来模拟堆栈机器时,直接使用RSP作为堆栈指针是最直接的方法。现在让我们立即尝试将表达式1+2编译成x86-64,将x86-64视为堆栈机器。以下是x86-64的汇编代码。
// 推入左操作数和右操作数
push 1
push 2
// 弹出左操作数和右操作数到RAX和RDI,并执行加法
pop rdi
pop rax
add rax, rdi
// 推入相加的结果
push rax
由于x86-64没有"将RSP指向的两个元素相加"这样的指令,我们需要首先将它们加载到寄存器中,然后执行加法,并重新将结果推入堆栈。上面的add指令就是在执行这种操作。
类似地,如果我们尝试在x86-64中实现23+45,代码如下所示:
// 计算2*3并将结果推入堆栈
push 2
push 3
pop rdi
pop rax
mul rax, rdi
push rax
// 计算4*5并将结果推入堆栈
push 4
push 5
pop rdi
pop rax
mul rax, rdi
push rax
// 将堆栈顶部的两个值相加
// 即计算2*3+4*5
pop rdi
pop rax
add rax, rdi
push rax
通过使用x86-64的堆栈操作指令,我们可以在x86-64上运行非常接近堆栈机器的代码。
下面的gen函数是将此方法直接实现为C函数的示例。
void gen(Node *node) {
if (node->kind == ND_NUM) {
printf(" push %d\n", node->val);
return;
}
gen(node->lhs);
gen(node->rhs);
printf(" pop rdi\n");
printf(" pop rax\n");
switch (node->kind) {
case ND_ADD:
printf(" add rax, rdi\n");
break;
case ND_SUB:
printf(" sub rax, rdi\n");
break;
case ND_MUL:
printf(" imul rax, rdi\n");
break;
case ND_DIV:
printf(" cqo\n");
printf(" idiv rdi\n");
break;
}
printf(" push rax\n");
}
尽管这不是解析或代码生成的关键点,但由于上面的代码使用了一些技巧性的idiv指令,我们在这里解释一下。
idiv是进行有符号除法的指令。如果x86-64的idiv具有直观的规范,那么在上面的代码中本来应该是像idiv rax, rdi这样写的,但是x86-64没有这样的除法指令,而是通过idiv隐式地使用RDX和RAX,并将它们视为128位整数,然后用64位寄存器的值除以它们,商放入RAX中,余数放入RDX中。通过使用cqo指令,可以将RAX中的64位值扩展为128位,并将其设置到RDX和RAX中,因此在调用idiv之前,上面的代码调用cqo。
好了,现在堆栈机器的说明就到这里了。通过阅读到这一点,读者们应该已经能够将复杂的语法分析以及由此产生的抽象语法树转换为机器代码。为了充分利用这些知识,让我们回到编译器的制作工作吧!
专栏:优化编译器
在本章中作者使用的 x86-64 汇编代码可能看起来相当低效。例如,将数字推入堆栈然后再弹出的指令,可以用直接将该值移动到寄存器的指令来实现,这样只需一条指令就可以完成。有些读者可能已经产生了想要优化这种冗长代码的冲动。然而,请不要被这种诱惑所左右。在最初的代码生成中,优先考虑编译器实现的简易性,输出冗长的代码是可取的。
如果有必要,9cc可以随时添加优化通道。重新扫描生成的汇编代码,然后用另一组指令替换出现特定模式的指令序列并不困难。例如,“push 之后的 pop 可以替换为 mov”或者“连续的 add 指令,如果它们都在将立即数加到同一个寄存器上,则可以将它们替换为一条 add 指令,将这些立即数相加”,制定这样的规则并机械地应用它们,就可以将冗长的代码替换为更高效的代码,而不改变其含义。
将代码生成与优化混合在一起会使编译器变得复杂。如果一开始就变得很复杂,那么在后续添加优化通道就会变得困难。正如 Donald Knuth 所说:“过早的优化是万恶之源”。在您读者们所创建的编译器中,要考虑的只是实现的简易性。不必担心输出中明显的冗长,因为可以随后消除它们。
步骤5:创建支持四则运算的语言
在本章中,我们将修改之前创建的编译器,以便扩展其功能,使其能够处理带有优先级括号的四则运算表达式。由于我们已经拥有了必要的组件,因此需要编写的新代码非常少。请尝试修改编译器的 main 函数,以便使用新编写的解析器和代码生成器。代码应如下所示:
int main(int argc, char **argv) {
if (argc != 2) {
error("引数の個数が正しくありません");
return 1;
}
// 对输入进行词法分析和语法解析
user_input = argv[1];
token = tokenize(user_input);
Node *node = expr();
// 输出汇编代码的前半部分
printf(".intel_syntax noprefix\n");
printf(".globl main\n");
printf("main:\n");
// 通过抽象语法树进行代码生成
gen(node);
// 应该在栈顶留下整个表达式的值
// 将其加载到 RAX 中并将其作为函数的返回值
printf(" pop rax\n");
printf(" ret\n");
return 0;
}
经过这一步,您应该能够正确地编译加减乘除和包含优先级括号的表达式。我们添加一些测试吧。
assert 47 '5+6*7'
assert 15 '5*(9-6)'
assert 4 '(3+5)/2'
值得注意的是,出于说明的目的,我们一口气实现了 *、/、(), 但实际上最好是避免一次性实现所有功能。由于最初已经有了加减法的功能,因此首先尝试引入抽象语法树及其相关代码生成器,而不破坏现有功能。这样做时不需要添加新的测试。随后,再逐步添加 *、/、() 的功能,包括测试。
参考实现:
3c1e3831009edff2
专栏:9cc 中的内存管理
读者迄今为止可能会对这个编译器的内存管理方式感到好奇。在我们到目前为止看到的代码中,虽然使用了(malloc 的变体)calloc,但却没有调用 free。也就是说,分配的内存没有被释放。这不是有意的懒惰行为吗?
实际上,这种“不进行内存管理”的设计是作者在考虑了各种权衡之后有意选择的设计。
这种设计的优点是,通过不释放内存,可以编写出类似于具有垃圾收集器的语言的代码。这样一来,不仅不需要编写内存管理代码,而且可以从根本上杜绝手动内存管理所带来的奇怪 bug。
另一方面,不调用 free 会带来的问题在于,考虑到我们将在普通 PC 上运行这个编译器,实际上问题并不是很严重。编译器只是一个读取一个 C 文件并输出汇编代码的短命程序。随着程序的结束,由程序分配的所有内存都将被操作系统自动释放。因此,问题实际上只涉及到总共分配了多少内存,对于这个编译器,实测时即使编译了相当大的 C 文件,内存使用量也不会超过约100MiB。因此,不释放内存实际上是一种可行的策略。例如,D 语言的编译器 DMD 也采用了相同的策略,即只进行 malloc,不进行 free。
步骤6:一元加和一元减
减法运算符 - 不仅可以在两个项之间写成 5-3,还可以在单个项的前面写成 -3。类似地,加法运算符 + 也可以省略左侧而写成 +3。这样只接受一个项的运算符被称为 “一元运算符”。相反,接受两个项的运算符被称为 “二元运算符”。
除了 + 和 - 之外,C 还有一元运算符,如取地址的 & 和解引用的 *,但在本步骤中我们将仅实现 + 和 -。
一元加和一元减与二元加和二元减具有相同的符号,但定义不同。二元减被定义为从左操作数减去右操作数,而一元减没有左操作数,因此二元减的定义在一元减中没有意义。在 C 中,一元减被定义为翻转右操作数的正负。一元加直接返回右操作数的值。虽然一元加没有实际上的必要性,但由于一元减存在,一元加也一并存在。
- 和 - 可以被看作是具有相同名称但具有不同定义的多个一元运算符。一元和二元的区别将在语境中加以区分。包含一元 +/- 的新语法如下所示:
expr = mul ("+" mul | "-" mul)*
mul = unary ("*" unary | "/" unary)*
unary = ("+" | "-")? primary
primary = num | "(" expr ")"
上述新语法引入了一个新的非终结符 unary,并使 mul 使用 unary 而不是 primary。X? 表示可选,即 X 出现 0 次或 1 次的 EBNF 语法元素。规则 unary = (“+” | “-”)? primary 表示,非终结符 unary 可以有一个 + 或 -,也可以没有,然后是一个 primary。
请确保这种新语法可以匹配表达式,如 -3*+5 和 -(3+5)。以下是 -3*+5 的语法树。
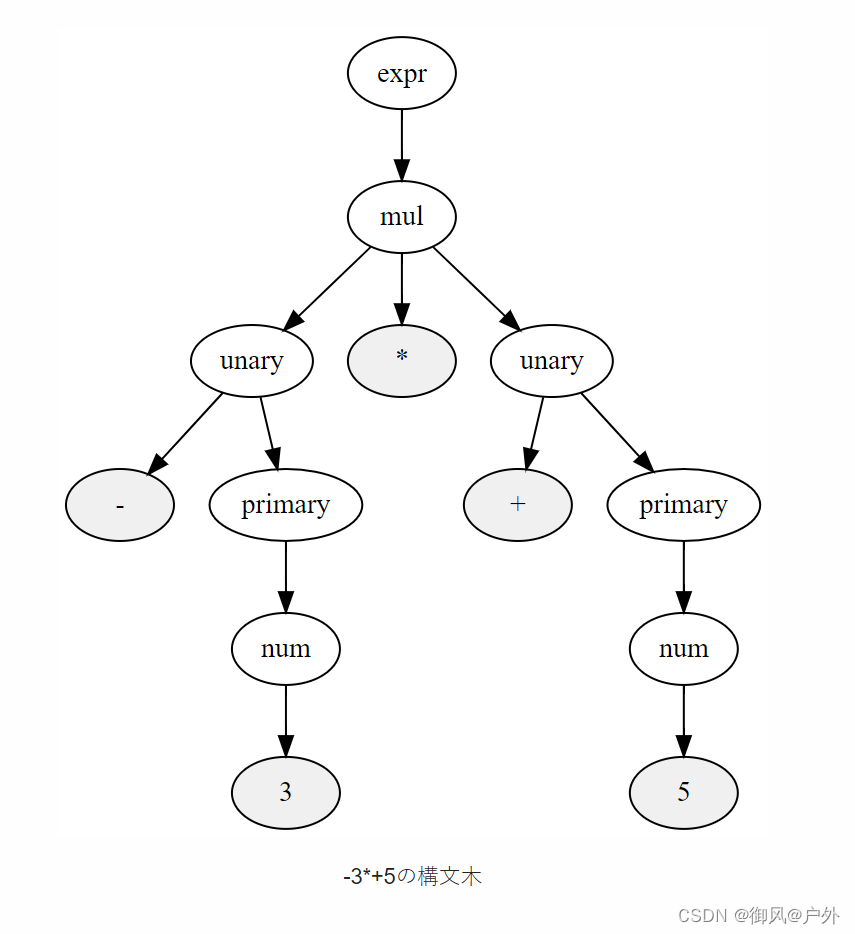
让我们根据这种新的语法来修改解析器。与以往一样,通过将语法直接映射到函数调用来修改解析器应该就可以了。下面是解析一元运算符的函数。
Node *unary() {
if (consume('+'))
return primary();
if (consume('-'))
return new_node(ND_SUB, new_node_num(0), primary());
return primary();
}
在这里,我们在解析阶段将 +x 替换为 x,-x 替换为 0-x。因此,在这个步骤中,不需要更改代码生成器。
写几个测试用例,然后将一元 +/- 添加到代码中一起提交,这一步就完成了。在编写测试时,请确保测试结果在0到255的范围内。例如,表达式 -10+20 使用一元 -,但整体值是正数,因此请使用这样的测试。
参考实现:
bb5fe99dbad62c95
专栏:一元加和一元减的语法优劣
一元加运算符并不存在于原始的 C 编译器中,在 1989 年 ANSI(美国国家标准协会)标准化 C 时才正式添加到语言中。考虑到已经存在一元减,有一元加会更对称,从而在某种意义上是有益的,但实际上一元加没有特别的用途。
另一方面,向语法中添加一元加可能会带来副作用。假设一个不熟悉 C 的人错误地将 += 运算符写为 i =+ 3。如果没有一元加,这将是一个无效的表达式,但由于有一元加,它将被解释为 i = +3,这与写成 i = +3 是一样的,这是一个有效的赋值表达式,并且编译器会默默地接受它。
ANSI C
语言标准化委员会在理解了以上问题的基础上决定添加一元加到语言中,那么读者们有何看法呢?如果你是当时的 C 标准化委员会成员,你会赞成吗?反对吗?
步骤7:比较运算符
在这一节中,我们将实现 <、<=、>、>=、== 、!= 这些比较运算符。这些比较运算符看起来具有特殊的意义,但实际上与 + 或 - 一样,它们只是接受两个整数并返回一个整数的普通二元运算符。例如,== 当两边相同时返回 1,否则返回 0,就像 + 返回两边相加的结果一样。
标记器的更改
到目前为止,我们处理的符号标记都是长度为1的字符,并且代码也基于此假设。但为了处理比较运算符如 ==,我们需要对代码进行泛化。为了能够在标记中保存字符串的长度,让我们给 Token 结构体添加一个名为 len 的成员。下面是新结构体的类型:
struct Token {
TokenKind kind; // 标记的类型
Token *next; // 下一个输入标记
int val; // 如果 kind 是 TK_NUM,则是数字值
char *str; // 标记字符串
int len; // 标记的长度
};
随着这个更改,我们还需要修改 consume 和 expect 等函数,使它们可以接受字符串而不是字符,并进行相应的改进。下面是一个示例,说明了所做的更改:
bool consume(char *op) {
if (token->kind != TK_RESERVED ||
strlen(op) != token->len ||
memcmp(token->str, op, token->len))
return false;
token = token->next;
return true;
}
当标记由多个字符组成时,需要首先对较长的标记进行标记化。例如,如果剩余字符串以 > 开头,那么应该首先检查是否是 >=,而不是先检查是否是 >,否则 >= 将错误地被标记为 > 和 = 两个标记。
新语法
为了在解析器中添加对比较运算符的支持,让我们考虑一下加入比较运算符后的文法会是怎样的。如果按照优先级从低到高的顺序写出迄今为止出现的运算符,那么如下所示:
- == !=
- < <= > >=
- + -
- * /
- 一元+ 一元-
- ()
优先级可以用生成式表示,并且优先级不同的运算符将映射到不同的非终结符。如果我们考虑了比较运算符,那么新的文法将如下所示:
expr = equality
equality = relational ("==" relational | "!=" relational)*
relational = add ("<" add | "<=" add | ">" add | ">=" add)*
add = mul ("+" mul | "-" mul)*
mul = unary ("*" unary | "/" unary)*
unary = ("+" | "-")? primary
primary = num | "(" expr ")"
在上述文法中,equality 表示 == 和 !=,relational 表示 <、<=、> 和 >=。这些非终结符可以直接映射到函数中,用于解析左结合的运算符。
值得注意的是,为了表示整个表达式是 equality,我们将 expr 和 equality 分开了。虽然 expr 的右侧可以直接写 equality 的右侧,但上述文法可能更易于理解。
专栏:简单且冗长的代码,以及高度简洁的代码
在递归下降语法分析中,由于代码几乎与生成规则直接对应,因此解析相似规则的函数看起来会很相似。到目前为止,我们编写的 relational、equality、add、mul 函数也应该看起来很相似。
思考如何通过 C 的宏、C++ 的模板、高阶函数或代码生成等元编程技术将这些函数中的共同模式有效地抽象化,可能是自然而然的想法。实际上,这样做是可能的。然而,在本书中,我们故意没有这样做。原因如下:
简单的代码虽然有些冗长,但理解起来很容易。即使以后需要对相似的函数进行相似的更改,实际上也不会太麻烦。另一方面,高度抽象化的代码则往往更难理解,因为首先需要理解抽象化机制,然后理解它是如何使用的,因此容易变得晦涩难懂。例如,如果从写一个函数来生成递归下降语法解析函数的元函数开始解释本书,那么本书就会变得更加晦涩。
并非始终要追求巧妙的简洁代码。如果总是追求这一点,那么代码很容易变得过于复杂,以至于无法再进一步简化。
代码编写者会成为代码的专家,因此,编写的代码往往会给人一种简洁而没有冗余的感觉,但大多数代码的读者并不会与作者有相同的感觉,而且其实他们也不需要掌握到那么高的程度,因此作为代码作者,我们的感觉需要保持一定的怀疑。故意写一些“看起来可能有更好的写法”的简单代码,根据需要适当地写是创建易于理解和维护的程序的重要技巧之一。
汇编代码的生成
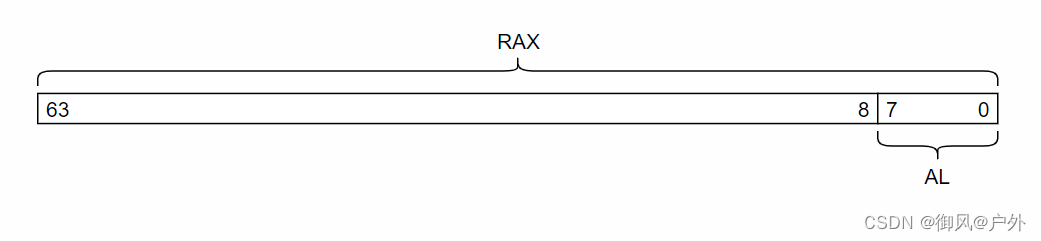
在 x86-64 中,比较使用 cmp 指令进行。下面是从堆栈弹出两个整数进行比较并将结果设置为 1 或 0 的代码:
pop rdi
pop rax
cmp rax, rdi
sete al
movzb rax, al
虽然这段代码是简短的汇编,但稍微有点复杂,让我们一步步来看看这段代码。
前两行弹出了两个值。第三行进行了比较。比较的结果将会存放在哪里呢?在 x86-64 中,比较指令的结果会被设置到一个特殊的“标志寄存器”中。标志寄存器是一个随着整数操作和比较操作更新的寄存器,其中包含了一些标志位,比如结果是否为零、是否有溢出、结果是否为负等。
由于标志寄存器不是普通的整数寄存器,所以如果我们想要将比较的结果设置到 RAX 中,我们需要从标志寄存器复制到 RAX。这就是 sete 指令的作用。sete 指令将在前面的 cmp 指令比较的两个寄存器相等时将指定的寄存器(这里是 AL)设置为 1。否则,将其设置为 0。
虽然 AL 是在本书之前没有出现过的新寄存器名,但实际上它只是指向 RAX 的最低 8 位的别名寄存器。因此,当 sete 设置 AL 时,实际上也自动更新了 RAX。但是需要注意,通过 AL 更新 RAX 时,RAX 的高 56 位保持不变。因此,如果想要设置整个 RAX 为 0 或 1,就需要清除 RAX 的高 56 位。这就是 movzb 指令的作用。虽然我们希望 sete 直接写入 RAX,但由于 sete 只能接受 8 位寄存器作为参数,因此在比较指令中,通常需要使用两条指令来设置 RAX 的值。
可以通过使用其他指令来代替sete来实现其他比较运算符。对于<,请使用setl,对于<=,请使用setle,对于!=,请使用setne。
和 >= 不需要在代码生成器中支持。请在解析器中交换双方,并将其替换为 < 或 <=。
参考实现:
6ddba4be5f633886
专栏:标志寄存器与硬件
在x86-64架构中,比较结果被暗示地保存在与普通整数寄存器不同的特殊寄存器中,这一规范可能一开始会感觉难以理解。实际上,在RISC处理器中,一些处理器不喜欢使用标志寄存器,而是使用指令集将比较结果设置到普通寄存器中。例如,RISC-V就是这样的指令集。
然而,从硬件实现的角度来看,如果采用简单的实现方式,创建标志寄存器是非常容易的。换句话说,当执行整数运算时,可以通过将结果的线路分支连接到另一个逻辑电路,并检查结果是零(所有线路是否都是0),还是负(最高位线路是否为1)等,然后将结果设置到标志寄存器的各个位上。带有标志寄存器的CPU正是这样实现的,每次执行整数运算时,标志寄存器也会被更新。
在这种机制下,不仅在cmp指令中,还在add和sub等指令中,标志寄存器都会被更新。实际上,cmp的本质是一个特殊的sub指令,它只更新标志寄存器。例如,执行sub rax, rdi,然后检查标志寄存器,就可以知道RAX和RDI的大小关系,但由于RAX会被更新,因此cmp被设计为不对整数寄存器进行写操作。
在软件中,“顺便计算某事”通常会导致额外的时间开销,但在硬件中,由于分支线路和额外的晶体管不会产生时间惩罚,因此每次更新标志寄存器的成本在简单的硬件实现中是不存在的。
分割编译与链接
到目前为止,我们一直在以每个C文件和每个测试用的Shell脚本各一个的文件结构进行开发。这种结构并没有问题,但随着源代码的逐渐变长,我们决定在这一阶段将其拆分为多个C文件,以提高可读性。在这一步中,我们将名为9cc.c的一个文件拆分为以下5个文件:
- 9cc.h:头文件
- main.c:主函数
- parse.c:解析器
- codegen.c:代码生成器
虽然main函数很小,也可以放到其他的C文件中,但由于它在意义上既不属于解析器parse.c,也不属于代码生成器codegen.c,因此我们决定将其放到一个单独的文件中。
在这一章节中,我们将解释分割编译的概念及其重要性,并随后介绍具体的步骤。
分割编译及其必要性
分割编译是指将一个程序分成多个源文件,并分别编译的过程。在分割编译中,编译器不会读取整个程序,而是会读取相应的片段并生成对应的输出。包含了单独的程序片段但无法单独执行的文件被称为“目标文件”(扩展名为.o)。在分割编译的最后,将这些目标文件链接在一起形成一个文件。将目标文件组合成一个可执行文件的程序称为“链接器”。
让我们先理解为什么需要分割编译。实际上,在技术上,并没有强制要求将源代码分割。如果将所有源代码一次性交给编译器,编译器理论上可以在没有链接器的情况下生成完整的可执行文件。
然而,采用这种方式,编译器必须完全了解程序所使用的所有代码。例如,像printf这样的标准库函数通常是由标准库的作者用C编写的函数,但为了省略链接的步骤,您需要每次将这些函数的源代码都传递给编译器。重复编译相同的函数通常只会浪费时间。因此,标准库通常以编译过的目标文件的形式分发,而不需要每次重新编译。换句话说,即使是由单个源代码组成的程序,在使用标准库时,实际上也在利用分割编译。
如果不进行分割编译,即使只修改了一行代码,也需要重新编译整个代码。在拥有数万行代码的大型项目中,编译通常需要数十秒。在大型项目中,源代码可能会超过一千万行,如果将其视为一个单元进行编译,那么编译时间将不会在一天内结束。此外,需要大约100GiB的内存。这样的构建过程是不现实的。
另外,如果将所有函数和变量都放在一个文件中,管理起来对于人类来说也很困难。
正因为以上原因,分割编译是必要的。
专栏:链接器的历史
将多个片段化的机器码例程连接起来形成一个程序的功能,自计算机问世以来就一直是必不可少的。1947年,约翰·莫奇利(ENIAC项目的领导者,第一台数字计算机ENIAC的项目领导者)描述了一个程序,可以重新定位从磁带读取的子程序并将其组合成一个程序。
即使在计算机的早期,通用的子例程也只需要编写一次,然后就可以从多个程序中使用,这就需要一个链接器来将程序的片段组合成可执行的程序。1947年是在汇编器还没有使用的年代,直接用机器码编写代码,所以对于程序员来说,链接器比汇编器更早被认为是一个需要创建的程序。
头文件的必要性和内容
在分割编译中,编译器只会查看程序的一部分代码,但编译器并非可以编译程序的任何小片段。例如,请考虑下面的代码:
void print_bar(struct Foo *obj) {
printf("%d\n", obj->bar);
}
在上面的代码中,如果知道结构体Foo的类型,就可以输出与该代码对应的汇编代码,但如果不知道,则无法编译此函数。
进行分割编译时,需要在每个C文件中包含足够的信息,以便单独编译每个文件。但是,如果将其他文件中的代码全部写在一个文件中,那么实际上就不是分割编译了,因此需要进行取舍,仅保留一定程度的信息。
作为一个例子,让我们考虑需要包含哪些信息才能生成调用其他C文件中函数的代码。编译器需要以下信息:
- 首先,需要知道某个标识符是函数名。
- 编译器生成的函数调用代码会将参数按照一定的顺序设置到寄存器中,并使用call命令跳转到另一个函数的开头。根据参数的类型,有时还需要将整数转换为浮点数等操作。还需要检查参数的类型和数量是否正确,如果错误,则需要显示错误消息。因此,需要知道函数的参数数量和每个参数的类型。
- 在调用的函数中发生了什么不重要,对于调用方来说,只需要简单地返回即可,因此在编译调用方函数时不需要调用函数的代码。
- 在分割编译时,不知道调用的函数地址,但汇编器可以先输出一个跳转到地址0的call命令,并在对象文件中保留“修正对象文件的X字节处为名称为Y的函数的地址”的信息。链接器会根据这些信息,在决定可执行文件的布局后,对程序片段进行二进制修补,修正跳转地址(这个操作称为“重定位”)。因此,虽然分割编译需要函数名,但函数地址是不需要的。
总结以上要求,只需除去函数体中的{ … },即可提供调用该函数所需的足够信息。这种省略了函数体的部分称为函数的“声明”(declaration)。声明只告诉编译器类型和名称,不包含函数代码。例如,以下是strncmp的声明:
int strncmp(const char *s1, const char *s2, size_t n);
编译器通过上述一行代码,即可了解strncmp的存在和其类型。对于函数,宣言中的extern关键字可选,比如:
extern int strncmp(const char *s1, const char *s2, size_t n);
对于函数,由于函数体被省略,使得声明与定义可以区分,因此通常不需要使用extern关键字。
此外,参数只需要了解其类型,因此在声明中参数名是可省略的,但为了更容易理解,通常在声明中也写出参数名是常见的做法。
再以另一个例子来考虑结构体类型。如果有两个以上的C文件使用相同的结构体,则需要在每个C文件中写下相同结构体的声明。如果一个C文件中没有使用的结构体,则其他C文件也不需要了解其存在。
在C语言中,为了一次性将其他C文件编译所需的声明整合到一起,通常将其写入称为头文件(扩展名为.h)中。将声明写入foo.h文件中,并在需要的其他C文件中写入#include “foo.h”,则#include行将被替换为foo.h文件的内容。
typedef等也用于向编译器提供类型信息。如果这些在多个C文件中使用,则需要在头文件中进行声明。
当编译器读取声明时,不会产生任何汇编代码。声明只是为了使用其他文件中的函数或变量所需的信息,本身并不包含函数或变量的定义。
结合到目前为止的分割编译的内容,“使用printf时,需要写#include <stdio.h>”这样的说法实际上是在做什么,我相信您现在已经理解了。C标准库会被隐式传递给链接器,因此链接器可以链接包含printf函数调用的对象文件并创建可执行文件。另一方面,编译器对于printf默认没有特殊的了解。printf不是内置函数,也不存在自动包含标准库的头文件的规范,因此刚开始时,编译器对printf一无所知。通过包含C标准库附带的头文件,编译器就可以了解printf的存在及其类型,并能够编译printf函数调用。
专栏:单遍编译器和前向声明
即使在C语言中,将所有函数都写在一个文件中时,有时也需要声明。在C语言规范中,编译器可以逐个函数地从头开始编译,而不必读取整个文件。因此,每个函数都必须在其在文件中出现之前的地方提供足够的信息才能进行编译。因此,如果要使用文件末尾定义的函数,则需要事先编写该函数的声明。这种声明称为“前向声明”。
通过巧妙地安排函数在文件中的顺序,大多数情况下都可以避免编写前向声明,但是如果要编写相互递归的函数,则前向声明就是必需的。
允许在不读取整个文件的情况下进行编译的C语言规范在内存非常有限的时代具有意义,但是现在来看,这种规范已经过时。如果编译器更加智能一些,应该可以避免为在同一文件中定义的函数编写声明。尽管如此,由于这种行为已成为语言规范的一部分,因此仍然需要记住它。
链接错误
当将所有的目标文件汇总后交给链接器时,这些文件必须包含足够的信息来构建完整的程序。
如果程序中只包含函数 foo 的声明而没有定义,那么每个 C 文件都可以正常编译,包括调用 foo 的代码。然而,当链接器试图创建完整的程序时,由于缺少 foo 的定义而无法进行修正,因此会导致错误。
链接时的错误称为链接错误。
如果多个目标文件中包含相同的函数或变量,也会导致链接错误。这是因为链接器无法确定在重复的情况下应该选择哪个。这种重复错误通常发生在错误地将定义写入头文件时。由于头文件被多个 C 文件包含,因此如果头文件中存在定义,就会导致多个 C 文件中存在重复的定义。为了解决这种错误,请确保在头文件中只写入声明,并将实体移至任何一个 C 文件中。
专栏:重复定义与链接错误
当存在重复定义时,链接器有时会选择保留其中一个并忽略其余的定义。在这种链接器中,重复定义不会导致错误。
实际的目标文件中也允许为每个定义选择是否允许重复,并且内联函数或C ++模板的展开结果等可以以允许重复的形式包含在目标文件中。目标文件的格式和链接器的行为相当复杂,有许多例外情况,但这些行为只是例外。通常情况下,默认情况下重复定义会导致错误。
全局变量的声明与定义
由于我们的编译器尚未支持全局变量,因此还没有全局变量的汇编示例,但从汇编的角度来看,全局变量与函数几乎相同。因此,与函数一样,全局变量也有声明和定义的区别。如果变量的实体在多个C文件中重复存在,通常会导致链接错误。
默认情况下,全局变量被分配到不可执行的内存区域,因此跳转到该区域会导致程序崩溃。然而,本质上,数据和代码之间没有区别。您可以在运行时将函数以数据的形式读取为全局变量,也可以通过更改内存属性以允许执行跳转到数据来将数据作为代码执行。
让我们通过实际的代码来验证函数和全局变量实质上只是存在于内存中的数据。在以下代码中,将标识符main定义为全局变量。main的内容是x86-64机器码。
char main[] = "\x48\xc7\xc0\x2a\x00\x00\x00\xc3";
将上述C代码保存为名为foo.c的文件并编译,然后使用objdump查看内容。默认情况下,objdump只会以十六进制显示全局变量的内容,但通过传递-D选项,您可以将数据强制反汇编为代码。
$ cc -c foo.c
$ objdump -D -M intel foo.o
Disassembly of section .data:
0000000000000000 <main>:
0: 48 c7 c0 2a 00 00 00 mov rax,0x2a
7: c3 ret
默认情况下,数据被映射到不可执行的区域,可以通过在编译时传递-Wl,–omagic选项来更改此行为。
$ cc -static -Wl,--omagic -o foo foo.o
函数和变量在汇编中都只是标签,并且属于相同的命名空间,因此链接器在汇总多个目标文件时不关心哪个是函数哪个是数据。因此,即使在C级别上将main定义为数据,链接也会成功。
让我们运行生成的文件。
$ ./foo
$ echo $?
42
如上所示,返回了42这个值。这意味着全局变量main的内容被执行为代码。
在C语法中,对于全局变量,如果加上extern关键字,就成为了声明。以下是int类型全局变量foo的声明。
extern int foo;
如果编写包含foo的程序,则需要将上述行写入头文件中,并在任何一个C文件中定义foo。以下是foo的定义。
int foo;
另外,在C中,未给出初始化表达式的全局变量将被初始化为0,因此这些变量与被初始化为0的变量(如0、{0, 0, …}、“\0\0\0\0…”)在语义上是相同的。
如果编写了初始化表达式,例如int foo = 3,则只需在定义中写入初始化表达式即可。声明只是为了告诉编译器变量的类型,因此不需要具体的初始化表达式。编译器在看到全局变量的声明时并不会特别输出汇编代码,因此在那个时候不需要知道它的内部是如何初始化的。
如果省略了初始化表达式,全局变量的声明和定义只有extern关键字的有无,因此它们的外观看起来是相似的,但声明和定义是不同的。请确保在这里完全理解这一点。
专栏:英特尔CPU的F00F漏洞
在1997年之前的英特尔Pentium处理器中存在一个严重的错误,即执行4个字节的指令F0 0F C7 C8会导致CPU完全挂起。
虽然不存在正式的与这个4个字节指令对应的汇编指令,但是如果勉强写成汇编,它将是lock cmpxchg8b eax指令。0F C7 C8是cmpxchg8b eax指令,它用于在寄存器和内存之间以原子方式(即使在多核CPU上也不会在中间状态上观察到其他核)交换8个字节的值。而F0是称为lock前缀的附加信息,具有使紧随其后的指令原子化的效果。然而,由于cmpxchg8b本身已经是原子的,所以lock cmpxchg8b eax是冗余且无效的写法。因此,这样的汇编指令在语法上是不存在的,字节序列F0 0F C7 C8不会出现在正常的程序中,因此在英特尔大量生产处理器之前,无法察觉到这个错误。
使用将main函数写为数据的技巧,可以用以下一行C代码来重现F00F漏洞:
char main[] = "\xf0\x0f\xc7\xc8";
在现代的x86架构中,这个函数是无害的,但是在1997年的Pentium处理器上,这一行代码就足以让系统挂起。
对于个人完全占有的PC来说,F00F漏洞并不是什么大问题,但是对于像云计算这样共享CPU的使用方式来说,这个漏洞是致命的。然而,最初认为F00F漏洞是无法修复的,只能通过回收更换CPU,但后来在操作系统内核的异常处理器级别上找到了一些巧妙的方法来避免这个错误,幸运的是,英特尔成功地避免了产品召回。
C标准库和归档文件
步骤8:文件分割和Makefile的更改
文件分割
请尝试按照本章开头所示的结构来分割文件。9cc.h是一个头文件。根据程序的组织方式,有时会为每个.c文件准备一个.h文件,但即使有多余的声明也不会造成特别大的问题,因此在这里我们不需要管理那么细致的依赖关系。准备一个名为9cc.h的文件,并在所有的C文件中包含它,格式为#include “9cc.h”。
Makefile的更改
现在,我们已经将程序更改为多个文件,让我们也更新一下Makefile。下面的Makefile用于编译并链接当前目录中的所有.c文件,以创建一个名为9cc的可执行文件。假设项目的头文件只有一个名为9cc.h的文件,并且在所有的.c文件中都包含了这个头文件。
CFLAGS=-std=c11 -g -static
SRCS=$(wildcard *.c)
OBJS=$(SRCS:.c=.o)
9cc: $(OBJS)
$(CC) -o 9cc $(OBJS) $(LDFLAGS)
$(OBJS): 9cc.h
test: 9cc
./test.sh
clean:
rm -f 9cc *.o *~ tmp*
.PHONY: test clean
请注意,Makefile中的缩进必须使用制表符而不是空格。
make是一个功能强大的工具,您并不一定非得精通它,但是至少要能够理解上面的Makefile,在许多情况下都会派上用场。因此,在本节中,我们将解释上面Makefile的内容。
在Makefile中,以冒号分隔的行以及以制表符缩进的零个或多个命令行组成一个规则。冒号前面的名称称为“目标”。冒号后面的零个或多个文件称为依赖文件。
当执行make foo时,make会尝试创建foo文件。如果指定的目标文件已经存在,则只有当目标文件比依赖文件旧时,make才会重新运行目标规则。这样做的目的是仅在源代码发生更改时重新生成二进制文件。
.PHONY是用于表示虚拟目标的特殊名称。例如,make test或make clean不是为了创建名为test或clean的文件,但是通常情况下make并不知道这一点,所以如果恰好存在名为test或clean的文件,那么make test或make clean将什么也不做。通过使用.PHONY来指定这样的虚拟目标,我们可以告诉make实际上不需要创建这些文件,而是应该无论指定的目标文件是否存在,都应该执行规则中的命令。
CFLAGS、SRCS和OBJS都是变量。
CFLAGS是由make内置规则识别的变量,用于指定传递给C编译器的命令行选项。在这里,我们传递了以下标志:
- -std=c11:指示使用C的最新标准C11编写的源代码
- -g:输出调试信息
- -static:进行静态链接
SRCS右边使用的wildcard是make提供的函数,用于将参数匹配的文件名展开。$(wildcard *.c)将扩展为main.c、parse.c和codegen.c。
OBJS右边使用了变量替换规则,这样做可以将.c替换为.o。由于SRCS是main.c、parse.c和codegen.c,所以OBJS就是main.o、parse.o和codegen.o。
有了这些基础知识,我们来追踪一下执行make 9cc会发生什么。make试图生成作为参数传递的目标文件,因此9cc文件成为最终的目标(如果没有指定参数,则会选择第一个规则,因此在这种情况下可以不指定9cc)。make会沿着依赖关系继续下去,尝试构建缺失或者过时的文件。
9cc的依赖文件是与.c文件相对应的.o文件。如果上次运行make时生成的.o文件仍然存在,并且与相应的.c文件相比是最新的,则make将不会再次运行相同的命令。只有在.o文件不存在或者.c文件比.o文件新时,才会运行编译器以生成.o文件。
$(OBJS): 9cc.h这个规则表示所有的.o文件都依赖于9cc.h。因此,如果更改了9cc.h,那么所有的.o文件都将被重新编译。
专栏:static关键字的不同含义
C语言中的static关键字主要有以下两种用途:
- 将局部变量声明为static,使其在函数退出后仍保留数值。
- 将全局变量或函数声明为static,将其作用域限定为文件范围。
尽管这两种用途并没有特别的共性,但由于使用了相同的关键字,因此在学习C语言时可能会产生混淆。理想情况下,对于第一种用途,应该使用“persistent”之类的词语,而对于第二种用途,应该使用“private”等不同的关键字。更进一步来说,对于第二种用途,将其默认为private,将全局范围的变量或函数标记为public可能更好。
C语言之所以重复使用关键字,是为了与早期编写的代码兼容。如果添加了新的关键字,如private等,那么已经使用该关键字作为变量或函数名的现有程序就无法编译。C语言为了避免这种情况,决定不增加新的关键字,而是重新利用现有的关键字。
在1970年代的某个时候,如果做出了添加新关键字而不是重用static关键字的决定,那么就不需要大量修改现有的代码。但是,想象自己面临这个问题时,也是一个相当困难的抉择。
函数与局部变量
在本章中,我们将实现函数和局部变量。同时,我们也将实现简单的控制结构。完成本章后,您将能够编译出以下示例代码:
// 求 m 到 n 的和
sum(m, n) {
acc = 0;
for (i = m; i <= n; i = i + 1)
acc = acc + i;
return acc;
}
main() {
return sum(1, 10); // 返回 55
}
尽管以上代码与C语言仍有一些差距,但可以说已经相当接近C语言了。
步骤9:单字符局部变量
到目前为止,我们已经能够创建一个可以执行算术运算的语言编译器。在本节中,我们将通过添加功能来使该语言可以使用变量。具体来说,我们的目标是能够编译包含多个带有变量的语句的代码。
a = 3;
b = 5 * 6 - 8;
a + b / 2;
我们将把最后一个表达式的结果作为整个程序的计算结果。相较于仅支持算术运算的语言而言,可以说这种语言已经有了相当“真实”的语言风格。
在本章中,我们首先将解释如何实现变量,然后逐步增加对变量的支持。
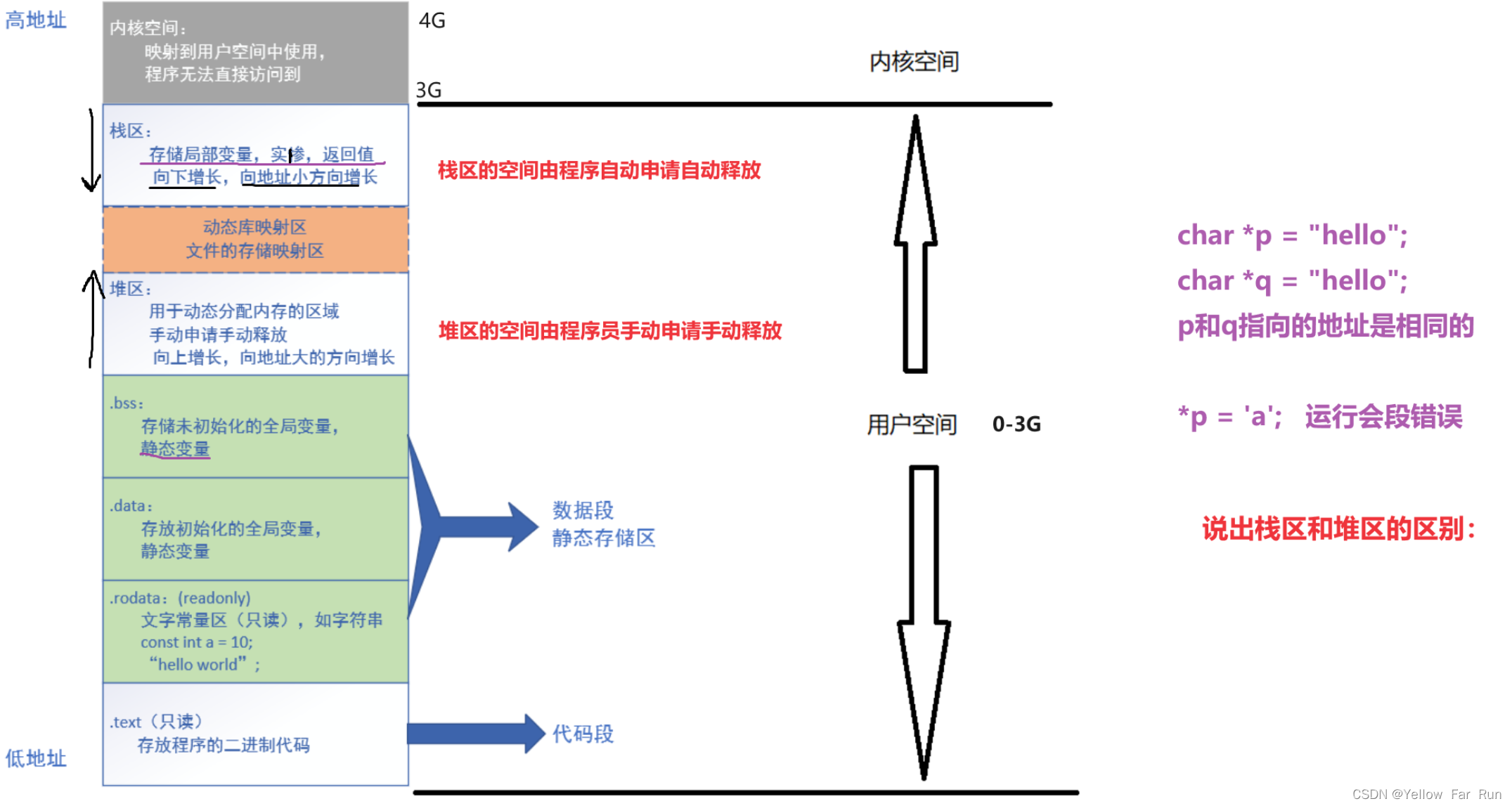
基于栈的变量空间
C中的变量存在于内存中。可以说,变量是对内存地址的命名。通过为内存地址命名,我们可以使用“访问变量a”而不是“访问内存地址0x6080”的方式来表示这个概念。
然而,函数的局部变量必须在每次函数调用时都单独存在。从实现的角度考虑,将变量的地址固定为“将函数f的局部变量a放在地址0x6080处”似乎是最简单的方法,但这样做在f递归调用时将无法正常工作。为了使局部变量在每次函数调用时都能够单独存在,C语言将局部变量存储在堆栈中。
让我们通过具体的例子来考虑堆栈的内容。假设我们有一个名为f的函数,它有局部变量a和b,然后另一个函数调用了f。由于函数调用的call指令会将返回地址推入堆栈,因此在调用f时,堆栈顶部将包含返回地址。此外,堆栈上原来可能已经包含了一些值。在此我们不关心具体的值,用“⋯⋯”来表示。下面是堆栈的布局示意图:
⋯⋯
返回地址 ← RSP
在这种情况下,要为a和b分配空间,需要将RSP下移16字节,以便为两个变量分配空间。然后堆栈将如下所示:
⋯⋯
返回地址
a
b ← RSP
通过这种布局,我们可以通过RSP+8来访问a,通过RSP来访问b。每次函数调用都会为局部变量分配的内存区域称为“函数帧”或“激活记录”。
由于我们的编译器会使用堆栈将中间计算结果压入/弹出,因此RSP的值会频繁变化,所以无法直接通过固定偏移量从RSP访问a和b。
为了解决这个问题,通常会使用另一个寄存器来进行实际的实现。在我们的编译器中(以及其他编译器中),请记住在执行函数时RSP可能会改变。因此,我们需要保存每个函数帧的开始位置。这样的寄存器被称为“基址寄存器”,其中存储的值称为“基址指针”。在x86-64中,惯例上使用RBP寄存器作为基址寄存器。
在函数执行期间,基址指针不应更改(这就是为什么要提供基址指针的原因)。在从一个函数返回时,需要保存原始基址指针,并在返回之前将其恢复为原始值。
下图显示了使用基址指针的函数调用的堆栈状态。假设函数g具有局部变量x和y,并调用f。在g执行期间,堆栈如下所示:
⋯⋯
g的返回地址
调用g时的RBP ← RBP
x
y ← RSP
现在调用f后的堆栈状态如下:
⋯⋯
g的返回地址
调用g时的RBP
x
y
f的返回地址
调用f时的RBP ← RBP
a
b ← RSP
这样一来,我们可以始终通过RBP-8来访问a,通过RBP-16来访问b。考虑到实际的堆栈布局,每个函数的变量数和大小不同,因此这个偏移量也会相应地改变。
从具体的汇编角度来看,编译器只需在每个函数的开头输出以下形式的常规指令即可:
push rbp
mov rbp, rsp
sub rsp, 16
编译器输出在函数开头的这种标准指令称为“前序”(prologue)。值得注意的是,16是一个示例值,实际上应该根据函数的变量数量和大小来确定。
从RSP指向返回地址的状态开始执行上面的代码,让我们确认生成了期望的函数帧。以下展示了每条指令执行后的堆栈状态:
- 在调用f之后的堆栈状态:
⋯⋯
g的返回地址
g的调用时RBP ← RBP
x
y
f的返回地址 ← RSP
- 执行push rbp后的堆栈状态:
⋯⋯
g的返回地址
g的调用时RBP ← RBP
x
y
f的返回地址
f的调用时RBP ← RSP
- 执行mov rbp, rsp后的堆栈状态:
⋯⋯
g的返回地址
g的调用时RBP
x
y
f的返回地址
f的调用时RBP ← RSP, RBP
- 执行sub rsp, 16后的堆栈状态:
⋯⋯
g的返回地址
g的调用时RBP
x
y
f的返回地址
f的调用时RBP ← RBP
a
b ← RSP
当从函数返回时,需要将原始值写回到RBP,将RSP指向返回地址,并调用ret指令(ret指令从堆栈中弹出地址并跳转到那个地址)。以下是执行此操作的简洁代码:
mov rsp, rbp
pop rbp
ret
编译器在函数末尾输出的这种标准指令称为“结尾部分”。
以下展示了执行结尾部分时的堆栈状态。下面RSP指向的堆栈区域被视为无效数据,因此在图中被省略。
- 执行mov rsp, rbp之前的堆栈状态:
⋯⋯
g的返回地址
g的调用时RBP
x
y
f的返回地址
f的调用时RBP ← RBP
a
b ← RSP
- 执行mov rsp, rbp后的堆栈状态:
⋯⋯
g的返回地址
g的调用时RBP
x
y
f的返回地址
f的调用时RBP ← RSP, RBP
- 执行pop rbp后的堆栈状态:
⋯⋯
g的返回地址
g的调用时RBP ← RBP
x
y
f的返回地址 ← RSP
- 执行ret后的堆栈状态:
⋯⋯
g的返回地址
g的调用时RBP ← RBP
x
y ← RSP
通过执行结尾部分,调用者函数g的堆栈状态得以恢复。call指令将下一条指令的地址压入堆栈。而结尾部分的ret指令则弹出该地址并跳转至其所指示的位置,从而实现了函数g的执行继续从call指令的下一条指令开始。这种行为与我们所了解的函数行为完全一致。
因此,函数调用和局部变量的实现就是这样的。
专栏:栈的增长方向
正如上文所述,x86-64架构的栈是从较大的地址向较小的地址增长的。相反的方向,也就是栈向上增长的方式似乎更自然,但为什么栈设计成向下增长呢?
实际上,栈向下增长并没有技术上的必然性。实际的CPU和ABI通常将栈的起始点放在较高的地址,使其向下增长,但实际上也有少数栈向上增长的架构。例如,8051微控制器、PA-RISC的ABI3、Multics4等,在这些架构中栈是向高地址方向增长的。
然而,栈向下增长并不是特别不自然的设计。
在电源开启后,当CPU从零开始执行程序时,起始执行地址通常由CPU规格决定。在常见的设计中,CPU通常从类似地址0的较低地址开始执行。因此,程序代码通常会被放置在较低的地址。为了确保栈不会与程序代码重叠,可以将它们尽可能分开放置,这样就会将栈放置在较高的地址,并设计其朝着地址空间的中心方向增长。这样一来,栈就会向下增长。
当然,也可以考虑与上述CPU不同的设计,这样做栈就更自然地向上增长。这实际上是一个并不重要的问题,事实上,机器栈向下增长只是作为行业的一般认识,这就是实际情况。
修改标记器
现在我们已经知道了如何实现变量,让我们立即开始实现。然而,要支持任意数量的变量可能会变得太复杂,所以在这一步中,我们将限制变量为小写字母,并且每个变量都固定地存在于RBP-8、RBP-16、RBP-24等位置。由于字母表有26个字母,我们决定在调用函数时将RSP下移208个字节,以确保所有单个字符变量的空间都被分配。
现在让我们开始实现。首先,让我们修改标记器,以便除了现有的语法元素之外,还可以标记单个字母变量。为此,我们需要添加一个新的令牌类型。由于变量名可以从str成员中读取,因此不需要在Token类型中添加新成员。因此,令牌类型将如下所示:
enum {
TK_RESERVED, // 符号
TK_IDENT, // 标识符
TK_NUM, // 整数令牌
TK_EOF, // 表示输入结束的令牌
} TokenKind;
请修改标记器,以便如果遇到小写字母,则创建一个TK_IDENT类型的令牌。您只需要在标记器中添加类似以下代码的if语句即可:
if ('a' <= *p && *p <= 'z') {
cur = new_token(TK_IDENT, cur, p++);
cur->len = 1;
continue;
}
修改解析器
在递归下降语法分析中,只要了解了语法,就可以将其机械地映射到函数调用中。因此,要考虑要添加到解析器中的更改,我们需要考虑新的语法如何。
我们将标识符命名为ident。这与num一样是终结符。由于变量可以在任何允许使用数字的地方使用,因此我们将num更改为num | ident,这样变量就可以在与数字相同的位置使用了。
除此之外,我们需要将赋值表达式添加到语法中。由于变量可以进行赋值,我们希望允许类似a=1的表达式。在这里,让我们按照C的方式进行设计,允许像a=b=1这样的写法。
此外,由于我们希望能够使用分号分隔的多个语句,因此新的语法将如下所示:
program = stmt*
stmt = expr ";"
expr = assign
assign = equality ("=" assign)?
equality = relational ("==" relational | "!=" relational)*
relational = add ("<" add | "<=" add | ">" add | ">=" add)*
add = mul ("+" mul | "-" mul)*
mul = unary ("*" unary | "/" unary)*
unary = ("+" | "-")? primary
primary = num | ident | "(" expr ")"
请先确保像42;或a=b=2; a+b;这样的程序符合这种语法。然后,对我们到目前为止创建的解析器进行修改,以便能够解析上述语法。当前阶段,您将能够解析类似a+1=5的表达式,但这是正确的行为。我们将在下一步中排除这种含义上不正确的表达式。修改解析器的过程并不复杂,您只需要像以前一样将语法元素直接映射到函数调用中即可。
由于我们允许使用分号分隔多个表达式,因此需要将多个节点保存在某个地方作为解析结果。目前,您可以创建一个全局数组,并按顺序将解析结果的节点存储在其中。最后一个节点应该用NULL填充,以便知道末尾在哪里。以下是添加的部分代码示例:
Node *code[100];
Node *assign() {
Node *node = equality();
if (consume("="))
node = new_node(ND_ASSIGN, node, assign());
return node;
}
Node *expr() {
return assign();
}
Node *stmt() {
Node *node = expr();
expect(";");
return node;
}
void program() {
int i = 0;
while (!at_eof())
code[i++] = stmt();
code[i] = NULL;
}
在抽象语法树中,我们需要能够表示新的“表示局部变量”的节点。为此,让我们添加一个新的节点类型和一个新的节点成员。例如,可能如下所示。在这个数据结构中,解析器将为标识符令牌创建一个ND_LVAR类型的节点并返回。
typedef enum {
ND_ADD, // +
ND_SUB, // -
ND_MUL, // *
ND_DIV, // /
ND_ASSIGN, // =
ND_LVAR, // 局部变量
ND_NUM, // 整数
} NodeKind;
typedef struct Node Node;
// 抽象语法树节点
struct Node {
NodeKind kind; // 节点类型
Node *lhs; // 左侧
Node *rhs; // 右侧
int val; // 仅在kind为ND_NUM时使用
int offset; // 仅在kind为ND_LVAR时使用
};
offset是一个成员,表示相对于局部变量基指针的偏移量。目前,由于变量a位于RBP-8,b位于RBP-16⋯⋯,因此在解析阶段可以确定偏移量。以下是读取标识符并返回ND_LVAR类型节点的代码示例:
Node *primary() {
...
Token *tok = consume_ident();
if (tok) {
Node *node = calloc(1, sizeof(Node));
node->kind = ND_LVAR;
node->offset = (tok->str[0] - 'a' + 1) * 8;
return node;
}
...
专栏:ASCII码
在ASCII码中,每个数字从0到127都分配了一个字符。下面是ASCII码中字符的分配表。
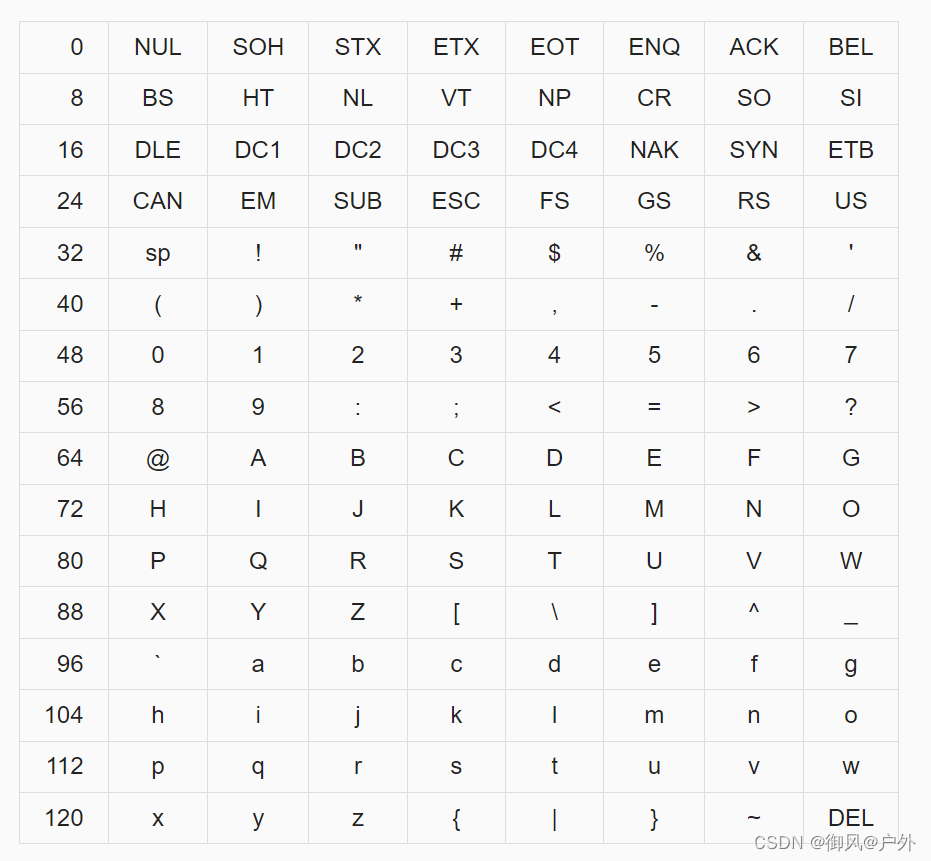
0〜31处是控制字符。尽管目前很少使用控制字符,除了NUL字符和换行符之外,大多数控制字符只是占据字符编码中的位置,但在ASCII码制定时,这些控制字符实际上经常被使用。在制定ASCII标准时,甚至有人建议在其中包含更多的控制字符,而不是小写字母5。
48〜58是数字,65〜90是大写字母,97〜122是小写字母。请注意这些字符是如何连续分配的。也就是说,0123456789或abcdefg…在字符编码中是连续的。将顺序定义的字符放置在连续的位置上似乎是理所当然的事情,但在当时流行的字符编码,例如EBCDIC中,由于穿孔卡的影响,字母并不是在编码上连续的。
在C语言中,字符只是整数类型的小值,将字符转换为数值并没有什么不同。换句话说,在ASCII基础上,例如’a’是97,'0’是48。在上面的代码中,有一个从字符减去’a’并将其作为数字的表达式,这样做可以计算给定字符距离’a’有多远。这种技术之所以可行,是因为在ASCII码中,字母是连续排列的。
左值和右值
与其他二元操作符不同,赋值表达式需要特别处理左值,让我们在这里解释一下。
赋值表达式的左边并不是任何表达式都被允许的。例如,你不能将1赋值为2。赋值类似于a=2是允许的,但类似于(a+1)=2这样的语句是不合法的。在9cc中暂时还不存在指针或结构体,但是如果存在的话,诸如*p=2这样的指向指针所指的位置的赋值,或者a.b=2这样的对结构体成员的赋值应该是合法的。如何区分这样的合法表达式和不合法表达式呢?
这个问题有一个简单的答案。在C中,左值可以基本上是指定内存地址的表达式。
变量存在于内存中并且具有地址,因此变量可以出现在赋值的左边。类似地,指针引用* p,因为p的值是地址,所以也可以出现在左边。对于类似a.b这样的结构体成员访问,因为它指向的是从结构体a的起始位置偏移b的成员地址,所以也可以出现在左边。
另一方面,类似于a+1的表达式的结果不是变量,因此它不能用作指定内存地址的表达式。由于这些临时值实际上仅存在于寄存器中,可能并不在内存中,即使在内存中存在,通常也无法从已知的变量固定偏移位置进行访问。因此,例如&(a+1),即使编写了也不允许获取a+1的结果地址,会导致编译错误。这样的表达式不能出现在赋值语句的左边。
能够出现在左边的值称为左值(lvalue),而不是左值的值称为右值(rvalue)。左值和右值也被称为lvalue和rvalue。在我们当前的语言中,变量是唯一的左值,其他所有值都是右值。
在生成变量的代码时,可以将左值作为起点进行考虑。如果变量出现在赋值的左边,则计算变量的地址作为左值,并将右边的评估结果存储在该地址中。这样就实现了赋值表达式。在其他上下文中出现变量时,同样需要计算变量的地址,然后通过该地址加载值,将左值转换为右值。这样就可以获取变量的值。
从任意地址加载值的方法
到目前为止,代码生成仅访问了堆栈顶部的内存,但在处理局部变量时,需要访问堆栈上的任意位置。下面我们来讨论一下内存访问的方法。
CPU不仅可以从堆栈顶部访问内存,还可以从内存的任意地址加载值或存储值。
加载值时,我们使用mov dst,[src]的语法。这条指令的意思是“将src寄存器的值视为地址,并从该地址加载值并将其保存到dst中”。例如,mov rdi,[rax]意味着从RAX中的地址加载值并将其设置到RDI中。
在存储时,我们使用mov [dst],src的语法。这条指令的意思是“将dst寄存器的值视为地址,并将src寄存器的值存储到该地址”。例如,mov [rdi],rax意味着将RAX的值存储到RDI中的地址。
push和pop是隐含地将RSP视为地址并执行内存访问的指令,因此实际上可以使用普通的内存访问指令用多条指令替换这些指令。也就是说,例如pop rax等同于:
mov rax, [rsp]
add rsp, 8
和两条指令,push rax等同于:
sub rsp, 8
mov [rsp], rax
和两条指令相同。
代码生成器的更改
利用到目前为止的知识,我们可以对代码生成器进行更改,以处理包含变量的表达式。在这次更改中,我们将添加一个函数,用于将表达式评估为左值。下面代码中的gen_lval函数就是实现这一功能的。gen_lval函数在给定节点表示变量时,计算该变量的地址并将其推送到堆栈上。否则,它会显示错误。这样,像(a+1)=2这样的表达式就会被排除在外。
要将变量用作右值,首先要对其进行左值评估,然后将计算结果视为地址,并从该地址加载值。以下是代码:
void gen_lval(Node *node) {
if (node->kind != ND_LVAR)
error("代入の左辺値が変数ではありません");
printf(" mov rax, rbp\n");
printf(" sub rax, %d\n", node->offset);
printf(" push rax\n");
}
void gen(Node *node) {
switch (node->kind) {
case ND_NUM:
printf(" push %d\n", node->val);
return;
case ND_LVAR:
gen_lval(node);
printf(" pop rax\n");
printf(" mov rax, [rax]\n");
printf(" push rax\n");
return;
case ND_ASSIGN:
gen_lval(node->lhs);
gen(node->rhs);
printf(" pop rdi\n");
printf(" pop rax\n");
printf(" mov [rax], rdi\n");
printf(" push rdi\n");
return;
}
gen(node->lhs);
gen(node->rhs);
printf(" pop rdi\n");
printf(" pop rax\n");
switch (node->kind) {
case '+':
printf(" add rax, rdi\n");
break;
case '-':
printf(" sub rax, rdi\n");
break;
case '*':
printf(" imul rax, rdi\n");
break;
case '/':
printf(" cqo\n");
printf(" idiv rdi\n");
}
printf(" push rax\n");
}
主函数的修改
现在,所有的部分都已经准备就绪,让我们修改主函数并实际运行编译器。
int main(int argc, char **argv) {
if (argc != 2) {
error("参数数量不正确");
return 1;
}
// 对输入进行标记化和解析
// 结果保存在code中
user_input = argv[1];
tokenize();
program();
// 输出汇编的前半部分
printf(".intel_syntax noprefix\n");
printf(".globl main\n");
printf("main:\n");
// 函数前言
// 分配26个变量的空间
printf(" push rbp\n");
printf(" mov rbp, rsp\n");
printf(" sub rsp, 208\n");
// 从第一个表达式开始按顺序生成代码
for (int i = 0; code[i]; i++) {
gen(code[i]);
// 期望栈中保留一个值作为表达式的评估结果
// 为防止栈溢出,弹出多余的值
printf(" pop rax\n");
}
// 函数尾声
// 最后一个表达式的结果仍然保存在RAX中,它将作为返回值
printf(" mov rsp, rbp\n");
printf(" pop rbp\n");
printf(" ret\n");
return 0;
}
步骤10:多字符的局部变量
在之前的章节中,我们将变量名固定为一个字符,并假设总是存在着26个局部变量,从a到z。在这一节中,我们将支持具有多个字符的标识符,并编译能够执行以下代码的程序。
foo = 1;
bar = 2 + 3;
return foo + bar; // 返回6
假设可以直接使用变量而不需要定义。因此,在解析器中,对于每个标识符,需要检查它之前是否已经出现过,如果是新的标识符,则自动将变量分配到堆栈空间中。
首先,需要修改标记器(tokenizer),以便可以读取由多个字符组成的标识符并将其识别为TK_IDENT类型的令牌。
变量将以链接列表的形式表示。我们将使用LVar结构体来表示一个变量,并通过名为locals的指针来保存第一个元素。代码如下所示:
typedef struct LVar LVar;
// 局部变量的类型
struct LVar {
LVar *next; // 下一个变量或NULL
char *name; // 变量名
int len; // 名称长度
int offset; // 相对于RBP的偏移
};
// 局部变量
LVar *locals;
在解析器中,当出现TK_IDENT类型的令牌时,将会执行以下代码。它将检查变量名是否已经存在于之前的变量列表中。通过遍历locals变量来检查,并根据情况选择使用现有的偏移量或创建新的LVar结构体。
下面是一个用于查找变量名的函数:
// 根据名称查找变量。如果找不到,则返回NULL。
LVar *find_lvar(Token *tok) {
for (LVar *var = locals; var; var = var->next)
if (var->len == tok->len && !memcmp(tok->str, var->name, var->len))
return var;
return NULL;
}
在解析器中,应该添加如下代码:
Token *tok = consume_ident();
if (tok) {
Node *node = calloc(1, sizeof(Node));
node->kind = ND_LVAR;
LVar *lvar = find_lvar(tok);
if (lvar) {
node->offset = lvar->offset;
} else {
lvar = calloc(1, sizeof(LVar));
lvar->next = locals;
lvar->name = tok->str;
lvar->len = tok->len;
lvar->offset = locals->offset + 8;
node->offset = lvar->offset;
locals = lvar;
}
return node;
}
专栏:机器码指令的频率
如果观察9cc生成的汇编代码,您会发现大量的数据传输指令,如mov和push,而实际计算的指令,如add和mul,则相对较少。其中一个原因是9cc没有进行优化,生成了大量无用的数据传输指令,但实际上,即使是优化后的编译器,最常见的指令也是数据传输指令。我们逆向汇编了/bin目录下的所有可执行文件,并统计了指令数,下面的图表显示了结果。
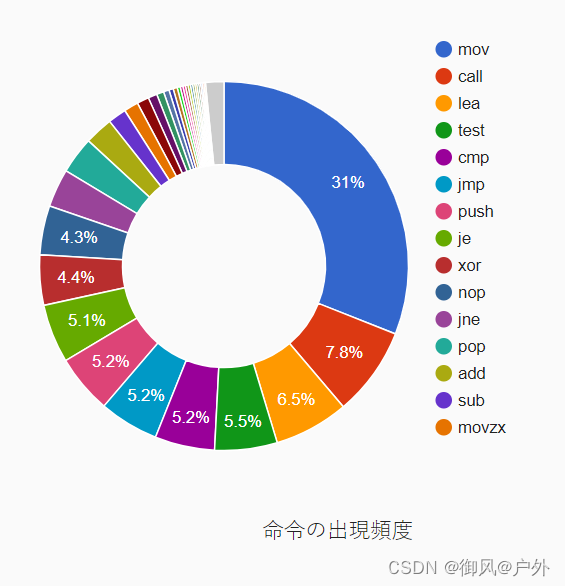
指令的频率
正如您所见,mov指令占据了几乎三分之一的指令总数。尽管计算机是一种数据处理机器,但数据传输是最常见的操作之一。考虑到“将数据移动到适当的位置”的操作是数据处理的核心之一,因此mov指令的大量出现似乎也是合理的结果。但这个结果可能会让许多读者感到意外。
步骤11:return语句
在这一章中,我们将添加return语句,使得可以编译执行以下类型的代码:
a = 3;
b = 5 * 6 - 8;
return a + b / 2;
我们将允许在程序中的任何位置编写return语句。与普通的C语言类似,程序的执行将在第一个return处中止并从函数中返回。例如,下面的程序将返回第一个return的值,即5:
return 5;
return 8;
为了实现这个功能,首先让我们考虑一下添加了return后的语法将会是什么样子。到目前为止,语句被视为仅仅是表达式,但在新的语法中,我们将允许return ;这样的结构。因此,新的语法将如下所示:
program = stmt*
stmt = expr ";"
| "return" expr ";"
...
要实现这一点,我们需要逐步修改标记器、解析器和代码生成器。
首先,在标记器中,我们需要识别return并将其表示为类型为TK_RETURN的令牌。与return、while、int等具有特殊语法含义的令牌(称为关键字)相比,关键字的数量是有限的,所以将每个令牌都赋予不同的类型会更加简单。
判断下一个标记是否为return很简单,只需要检查剩余的输入字符串是否以return开头。然而,这样做可能会导致错误地将returnx这样的标记误认为是return和x分开的两个标记。因此,在这里,除了确认输入以return开头外,还需要确认下一个字符是否是构成标记的字符之一。
以下是一个判断给定字符是否为构成标记的字符(即字母数字或下划线)的函数:
int is_alnum(char c) {
return ('a' <= c && c <= 'z') ||
('A' <= c && c <= 'Z') ||
('0' <= c && c <= '9') ||
(c == '_');
}
使用这个函数,我们可以修改tokenize函数以将return标记为TK_RETURN类型的令牌。
if (strncmp(p, "return", 6) == 0 && !is_alnum(p[6])) {
tokens[i].ty = TK_RETURN;
tokens[i].str = p;
i++;
p += 6;
continue;
}
接下来,让我们修改解析器,以便可以解析包含TK_RETURN的标记序列。为此,首先添加表示return语句的ND_RETURN类型节点。然后修改读取语句的函数,使其可以解析return语句。就像之前一样,通过将语法直接映射到函数调用来实现语法分析。以下是新的stmt函数:
Node *stmt() {
Node *node;
if (consume(TK_RETURN)) {
node = calloc(1, sizeof(Node));
node->kind = ND_RETURN;
node->lhs = expr();
} else {
node = expr();
}
if (!consume(';'))
error_at(tokens[pos].str, "';'ではないトークンです");
return node;
}
因为ND_RETURN类型的节点只在此处生成,所以我们选择在此处使用malloc直接设置值,而不是创建新函数。
最后,让我们修改代码生成器,以便对ND_RETURN类型的节点生成适当的汇编代码。以下是gen函数的一部分:
void gen(Node *node) {
if (node->kind == ND_RETURN) {
gen(node->lhs);
printf(" pop rax\n");
printf(" mov rsp, rbp\n");
printf(" pop rbp\n");
printf(" ret\n");
return;
}
...
在上面的代码中,gen(node->lhs)调用会输出作为return语句返回值的表达式的代码。该代码应该在栈顶留下一个值。在gen(node->lhs)之后,我们从堆栈中弹出该值并将其设置为RAX,然后从函数中返回。
在之前的章节中,我们在函数末尾总是输出一个ret指令。通过本章所述的方法实现return语句后,每个return语句都会输出多余的ret指令。这些指令可以合并,但为了简化实现,我们决定即使输出多个ret指令也没关系。在当前阶段,我们应该更注重实现的简洁性而不是处理这些细节。编写复杂代码的能力固然有用,但保持代码的简洁性同样重要。
专栏:语法层次结构
通常,我们经常使用“正则表达式”来判断输入是否符合某种规则,但一些相对复杂的语法无法用正则表达式来表示。例如,要判断字符串中的括号是否匹配,使用正则表达式基本上是不可能的。
上下文无关文法(可以用BNF表示的语法)比正则表达式更强大,例如,它可以表示括号匹配的字符串(用BNF表示为S → SS | “(” S “)” | ε)。然而,与正则表达式类似,上下文无关文法也有其局限性,它无法表示普通编程语言中出现的复杂规则。例如,“变量必须在使用之前声明”的规则是C语言语法的一部分,但这样的规则无法用上下文无关文法来表示。
如果编写了C语言的编译器,并且编译器没有错误,那么可以说,“编译器接受的输入是正确的C程序,而拒绝的输入是不正确的C程序”。换句话说,只要有普通计算机的能力,“是否符合C语法”的问题是可以确定的,因此,可以说编译器作为一个整体是比上下文无关文法更强大的语法判定机。因此,总是能够以YES/NO的方式判定语法匹配的语法称为可判定的(Decidable)。
我们也可以考虑不可判定的语法。例如,“给定一个计算机程序并执行它,判断该程序最终是执行exit函数而终止,还是继续无限执行”,这个问题通常是不可能在不实际执行程序的情况下以YES/NO来确定的(假设在一个具有无限内存的虚拟计算机上执行)。换句话说,对于停止的程序可以回答YES,但对于不停止的程序,由于可能会无限执行,因此无法回答NO。这样的语法,除了能够给出YES/NO回答外,还可能会导致判定机无法结束执行,这种语法被称为图灵可识别的(Turing-recognizable)。
因此,我们有着正则表达式 < 上下文无关文法 < 可判定 < 图灵可识别的等语法层次结构。这样的语法层次结构是计算机科学的一个重要研究领域。著名的未解决问题P≟NP也涉及到了语法层次结构的问题。
1973年的C编译器
到目前为止,我们一直在逐步开发编译器。从某种意义上说,这个开发过程可以说是在重复C的历史。
现在看来,当前的C语言中存在着一些不太清晰或不必要复杂的部分,但如果不了解历史,就无法理解这些。即使是当前C中令人费解的部分,通过阅读早期C的代码,观察早期C的形式以及之后语言和编译器的发展,会让很多事情豁然开朗。
C语言是为Unix开发的,开始于1972年。在1972年或1973年,也就是C历史的早期阶段,极少的源代码被保存在磁带上,从那里读取的文件已经在互联网上公开。让我们来看看当时的C编译器代码。下面是一个函数,它接受printf格式的消息并将其作为编译错误消息显示出来。
error(s, p1, p2) {
extern printf, line, fout, flush, putchar, nerror;
int f;
nerror++;
flush();
f = fout;
fout = 1;
printf("%d: ", line);
printf(s, p1, p2);
putchar('\n');
fout = f;
}
这似乎有些奇怪,像C但又不像C的语言。那时的C就是这样的。阅读这段代码时首先注意到的是,与我们之前制作的编译器的早期阶段一样,函数的返回值和参数没有类型。在这里,s应该是一个指向字符串的指针,p1和p2应该是整数,但在那个时代,因为所有的变量都是相同大小的,所以这些变量都是无类型的。
第2行列出了error函数引用的全局变量和函数声明。由于当时的C编译器没有头文件或C预处理器,程序员需要这样做来告诉编译器变量和函数的存在。
与我们现在的编译器一样,函数只检查函数名是否存在,而不检查参数的类型或数量是否匹配。在将期望的数量的参数压入堆栈后,只需跳转到函数主体,函数调用就会成功,因此这样做是可以的。
fout是一个全局变量,保存着输出文件的文件描述符号。在这个时代,还没有fprintf存在,所以要将字符串输出到标准错误输出而不是标准输出,需要通过全局变量来切换输出位置。
在error函数中,printf被调用了两次。第二次调用printf时,除了格式字符串之外,还传递了两个值。那么,如果要显示只有一个值的错误消息,该怎么办呢?
实际上,即使以较少的参数强行调用error函数,它也会正常工作。请记住,这个时候函数参数检查是不存在的。参数s,p1和p2只是简单地指向堆栈指针的第1、2、3个字,编译器并不关心是否实际传递了相应于p2的值。由于printf会访问格式字符串中包含的%d或%s的数量的多余参数,所以当消息只包含一个%d时,p2根本不会被访问。因此,参数数量不匹配也没有问题。
与现代的9cc类似,早期的C编译器有很多相似之处。
让我们再看一个代码示例。下面的代码将传入的字符串复制到静态分配的区域,并返回指向该区域开头的指针。换句话说,这是一个类似于使用静态区域的strdup的函数。
copy(s)
char s[]; {
extern tsp;
char tsp[], otsp[];
otsp = tsp;
while(*tsp++ = *s++);
return(otsp);
}
当时还没有发明int *p这种声明形式的语法。相反,指针类型是通过int p[]这样的声明来表示的。在参数列表和函数主体之间有一个变量定义的样子,这是为了将s声明为指针类型。
这个早期的C编译器还有一些值得注意的特点。
- 结构体在这个时候还不存在。
- 还没有&&和||等运算符。在这个时代,&和|只在if等条件语句中才是逻辑运算符。
- +=等运算符被写成=+。这个语法导致了一个问题,如果想给i赋值-1,而不加空格直接写i=-1的话,会被解释为i=-1,从而导致i被递减,这是一个意外的行为。
- 整数类型只有char和int,没有short或long。也没有声明复杂类型,比如"function pointer array"。
除了上述内容,70年代初期的C还缺乏许多其他功能。然而,即使如此,这个C编译器仍然是用C编写的,正如从上面的源代码中可以看出的那样。在连结体都不存在的时代,C已经在自举了。
通过查看古老的源代码,我们也可以推测一些C中令人费解的语法是如何演变成现在的形式的。如果extern、auto、int或char之后总是跟着变量名,那么变量定义的解析就会很简单。如果[]用于指针,那么只需要放在变量名后面,解
析也会很简单。但是,如果按照这种早期编译器所展现的方向来发展这种语法,最终就会变得复杂,这一点似乎也能理解。
现在,围绕Unix和C的共同创始人丹尼斯·里奇在1973年左右所做的工作正是在进行增量式的开发。他一边发展C语言本身,一边用C语言编写其编译器。当前的C语言并不是在特定的某个时间点达到了某种完美的形式,而只是在丹尼斯·里奇认为此时语言功能足够完善时,才算作完成。
我们的编译器也没有从一开始就追求完成形式。C的完美形式并不是特别重要的,所以追求它并没有那么重要。我们只需要在任何时候都继续开发具有合理功能集的语言,并最终将其发展成为C,这正是原始的C编译器所做的历史悠久的开发方法。让我们自信地继续前进!
专栏:Rob Pike的编程五大原则
9cc受到了Rob Pike对编程思想的影响。Rob Pike是C语言的作者Dennis Ritchie的前同事,也是Go语言的作者,与Unix的作者Ken Thompson一起开发了Unicode的UTF-8。
以下是Rob Pike的"编程的五个规则":
-
无法预测程序的哪个部分会消耗时间。瓶颈通常会在意想不到的地方出现,因此在确定瓶颈位置之前,不要盲目预测瓶颈位置并进行性能优化。
-
进行测量。不要在优化之前尝试优化。即使进行了测量,也不要在代码的极端缓慢部分之外进行优化。
-
复杂的算法在n很小时会变慢,而n通常很小。复杂的算法有很大的常数部分。除非知道n通常很大,否则应避免使用复杂的算法。(即使n很大,也应首先应用规则2。)
-
复杂的算法比简单的算法更容易出错,并且更难实现。应使用简单的算法和数据结构。
-
数据至关重要。选择正确的数据结构,并能够很好地表示数据,算法几乎总是显而易见的。数据结构而不是算法是编程的核心。
第12步:添加控制结构
本章及以后的章节正在撰写中。尽管到目前为止的章节我尽量写得详细,但我认为从这里开始的章节还没有达到公开的水平。然而,如果您已经阅读到这里,也许您也可以自己补充所需的内容,而且可能有人希望了解如何以最佳方式继续前进,因此,我会在这个意义上公开。
在这一节中,我们将向语言中添加if、if … else、while、for等控制结构。这些控制结构看起来可能很复杂,但如果直接将它们编译成汇编语言,则实现起来相对简单。
因为汇编语言中没有与C的控制结构相对应的内容,所以C的控制结构用分支指令和标签表示。从某种意义上说,这就像是用goto语句手动重写控制结构一样。就像人类可以手动将控制结构重写为goto语句一样,控制结构可以根据模式进行代码生成,从而轻松实现。
除了if、while、for之外,还有一些其他控制结构,比如do … while、goto、continue、break等,但在这个阶段还不需要实现它们。
以下是添加了if、while、for的新语法:
program = stmt*
stmt = expr ";"
| "if" "(" expr ")" stmt ("else" stmt)?
| "while" "(" expr ")" stmt
| "for" "(" expr? ";" expr? ";" expr? ")" stmt
| ...
...
要读取expr? ";"时,应先预读1个标记,并假设下一个标记是;,如果是,则认为expr不存在,否则读取expr即可。
if (A) B将编译为以下汇编:
编译A的代码 // 结果应该在栈顶
pop rax
cmp rax, 0
je .LendXXX
编译B的代码
.LendXXX:
换句话说,if (A) B将展开为:
if (A == 0)
goto end;
B;
end:
XXX应该是通用编号,以确保所有标签都是唯一的。
if (A) B else C将编译为以下汇编:
编译A的代码 // 结果应该在栈顶
pop rax
cmp rax, 0
je .LelseXXX
编译B的代码
jmp .LendXXX
.LelseXXX
编译C的代码
.LendXXX
换句话说,if (A) B else C将展开为:
if (A == 0)
goto els;
B;
goto end;
els:
C;
end:
编译if语句时,应该预读1个标记以检查是否有else,如果有,则将其编译为if … else,如果没有,则编译为没有else的if。
while (A) B将编译为以下汇编:
.LbeginXXX:
编译A的代码
pop rax
cmp rax, 0
je .LendXXX
编译B的代码
jmp .LbeginXXX
.LendXXX:
换句话说,while (A) B将展开为:
begin:
if (A == 0)
goto end;
B;
goto begin;
end:
for (A; B; C) D将编译为以下汇编:
编译A的代码
.LbeginXXX:
编译B的代码
pop rax
cmp rax, 0
je .LendXXX
编译D的代码
编译C的代码
jmp .LbeginXXX
.LendXXX:
对于for (A; B; C) D,以下是相应的C代码:
A;
begin:
if (B == 0)
goto end;
D;
C;
goto begin;
end:
需要注意的是,以.L开头的标签是汇编器特别识别的名称,它们自动成为文件范围内的标签。文件范围内的标签可以从同一文件中引用,但无法从其他文件引用。因此,建议让编译器为if和for创建的标签以.L开头,这样就不用担心与其他文件中的标签发生冲突了。
请使用cc编译一个小循环,并参考其汇编代码。
专栏:利用编译器检测运行时错误
在C语言中编写程序时,经常会出现超出数组边界写入数据,或者由于指针错误而破坏无关的数据结构的情况。由于这些错误可能导致安全漏洞,因此人们想到利用编译器的帮助,在运行时积极地检测这些错误。
例如,如果将-fstack-protector选项传递给GCC,编译后的函数将在函数前奏部分输出一个被称为"canary"(金丝雀)的随机整数,该整数大小与指针大小相同,并在结尾处检查canary的值是否已更改。这样做的好处是,如果由于数组缓冲区溢出而在不知情的情况下覆盖了栈的内容,那么canary的值几乎肯定已经改变,因此可以在函数返回时检测到错误。如果检测到错误,程序通常会立即退出。
LLVM中有一种名为TSan(ThreadSanitizer)的工具,它可以在运行时输出代码,以检测未正确锁定的情况下多个线程对共享数据结构的访问。另外,LLVM的UBSan(UndefinedBehaviorSanitizer)可以检测到C中的未定义行为是否被意外触发。例如,由于C中对有符号整数的溢出是未定义的行为,因此当发生有符号整数溢出时,UBSan将报告错误。
由于TSan等工具会导致程序运行速度减慢数倍,因此将其添加到常用程序的编译选项中是不现实的,但像栈canary这样的功能的运行时成本相对较低,因此在某些环境中可能已默认启用。
利用编译器提供的动态错误检测功能是近年来研究的热点,它对于使用不太安全的内存语言如C和C++编写相对安全的程序有很大的帮助。
步骤13:块
在这一步中,我们将支持在{ … }之间编写多个语句的 “块”(block)。块在正式术语中称为 “复合语句”(compound statement),但由于这是一个长单词,通常会简称为块。
块可以将多个语句组合成一个语句。在前面的步骤中,我们实现的if和while只允许一个语句在条件满足时执行,但通过在这一步中实现块,就可以像C语言一样,允许在其中用{}括起来的多个语句。
实际上,函数体本身也是一个块。语法上,函数体必须是一个块。函数定义中的{ … }实际上与if或while后面的{ … }在语法上是相同的。
以下是添加块的语法:
program = stmt*
stmt = expr ";"
| "{" stmt* "}"
| ...
...
在这个语法中,如果stmt以"{“开头,那么可以出现零个或多个stmt,直到出现”}“为止。为了解析stmt* “}”,请使用while循环重复调用stmt,直到出现”}",然后将结果作为向量返回。
为了实现块,需要添加表示块的节点类型ND_BLOCK。在表示节点的结构体Node中,需要添加一个包含块中包含的表达式的向量。在代码生成器中,当节点类型为ND_BLOCK时,需要按顺序生成其中的语句代码。请注意,每个语句都会在栈上留下一个值,所以不要忘记每次都将其弹出。
步骤14:支持函数调用
这一步的目标是使编译器能够识别像foo()这样没有参数的函数调用,并将其编译为call foo。
以下是添加函数调用的新语法:
...
primary = num
| ident ("(" ")")?
| "(" expr ")"
通过读取ident后的一个标记,可以尝试预读一个标记来区分其是变量名还是函数名。
在测试中,您可以准备一个类似于C文件中的int foo() { printf(“OK\n”); }的内容,并将其编译为对象文件使用cc -c,并链接您的编译器的输出。通过这样做,您应该能够正确链接整个程序,并确认您想要调用的函数是否被正确调用。
一旦这个部分运行起来了,接下来可以让它支持函数调用,例如foo(3, 4)。不需要检查参数的数量或类型。只需按顺序评估参数,将其复制到按照x86-64 ABI规范定义的顺序的寄存器中,并调用函数即可。不支持超过6个参数。
在测试中,您可以准备一个类似于int foo(int x, int y) { printf(“%d\n”, x + y); }的函数,并在链接后进行测试,以确认其正常工作。
x86-64的函数调用ABI(即使用以上方式进行调用)相对简单,但有一个注意点。在调用函数之前,RSP必须是16的倍数。由于push和pop每次都以8字节为单位更改RSP,因此在发出call指令时,RSP不一定是16的倍数。如果不遵守这个约定,那么依赖于RSP是16的倍数的函数将会以一半的概率出现神秘崩溃的现象。因此,在调用函数之前,请调整RSP以确保其是16的倍数。
步骤15:支持函数定义
一旦完成上述步骤,接下来就是支持函数定义。但是,由于C函数定义的语法比较复杂,我们不会一下子就全部实现。因为到目前为止,我们的语言只有int类型,所以我们将实现类似于省略类型名的foo(x, y) { … }的语法,而不是像int foo(int x, int y) { … }。
在被调用的函数内部,需要能够通过名称访问参数,例如x或y,但目前还无法直接通过名称访问传递的寄存器值。那么该怎么办呢?我们可以将参数作为本地变量编译,然后在函数的起始处,将寄存器的值写入这些本地变量的栈空间中。这样一来,我们就可以在接下来的操作中统一处理参数和本地变量,而无需区分它们。
直到现在,我们的语言整体都隐含地被包裹在main() { … }中,但我们将要废除这种方式,将所有代码写在某个函数中。这样一来,当解析顶层代码时,首先读取的标记必定是函数名,接下来应该是参数列表,然后是函数体,所以这变得相当容易。
完成这一步后,您应该可以计算并显示斐波那契数列,从而使程序变得更加有趣。
二进制级别的接口
C语言的规范涵盖了源代码级别的规范。例如,语言规范规定了如何编写函数定义,包含哪些文件可声明哪些函数等等。然而,将符合标准的C代码转换为何种机器语言并没有在语言规范中定义。C语言的标准并非基于特定的指令集,因此这是理所当然的。
因此,虽然在机器码级别上的规范看起来似乎不需要严格规定,但实际上每个平台都有一定程度的规范。这些规范被称为ABI(Application Binary Interface)。
到目前为止,在本书中解释的函数调用方式中,参数被放置在寄存器中的特定顺序。此外,返回值被设置在RAX中。这些函数调用规则称为“函数调用约定”(function calling convention),是ABI的一部分。
C语言的ABI还包括以下内容:
- 在函数调用中会改变和不会改变的寄存器(例如,RBP在返回之前将被恢复为原始值,但某些寄存器可以不恢复原始值)
- 类型大小(例如int或long)
- 结构体的布局规则(规定了结构体成员在内存中的实际布局规则)
- 位字段的布局规则(例如,从最低位开始排列位字段还是从最高位开始排列)
ABI只是软件级别的承诺,因此理论上可以考虑与本书所述的不同的ABI。然而,不兼容的ABI将无法互相调用,因此基本上由CPU和操作系统厂商定义了平台的标准ABI。在x86-64架构中,广泛使用的有Unix和macOS所使用的System V ABI,以及Windows所使用的Microsoft ABI。需要指出的是,这两种调用约定之间并没有必然的分歧,只是由于不同的人制定了不同的约定而已。
到目前为止,在本书中,我们已经展示了如何从自制的编译器中调用在另一个编译器中编译的函数等内容。这是因为我们的C编译器和其他编译器的ABI是相同的。
在计算机中表示整数
在这里,让我们了解一下计算机是如何表示整数,特别是负整数的。本章将介绍无符号数的表示方法以及带符号数的"二进制补码表示法"。
本书中,二进制位模式会附加0b前缀,并且为了方便阅读,每4位用下划线分隔,例如0b0001_1010。实际上,0b前缀可以直接在许多C编译器中使用作为编译器的独立扩展(但通常不包括下划线)。
无符号整数
无符号整数(unsigned integer)的表示与常规的二进制数相同。就像十进制数表示从个位开始的1、10、100、1000⋯⋯(即10的0次方、10的1次方、10的2次方、10的3次方⋯⋯)一样,二进制数表示从最低位开始的1、2、4、8⋯⋯(即2的0次方、2的1次方、2的2次方、2的3次方⋯⋯)。
例如,通过观察置为1的位的位置,就可以确定0b1110这个位模式表示的无符号整数的值。在这种情况下,第2位、第3位、第4位,即2的位、4的位、8的位都置为1,因此0b1110表示的值是2 + 4 + 8 = 14。下面是一些示例图形。
将1添加到无符号整数时,如下图所示,值会循环。这是4位整数的一个示例。
当运算结果溢出到另一个位时,会产生不同于无限位的结果,这称为"溢出"。例如,对于8位整数,1+3不会溢出,但200+100或20-30会溢出,分别变为44和246。数学上,这相当于模256的余数。
专栏:由溢出引起的有趣错误
数值溢出有时会导致意想不到的错误。在这里,我们将介绍一下游戏《文明》的第一版中出现的一个错误。
《文明》是一款战略模拟游戏,玩家可以选择成为像成吉思汗或伊丽莎白女王这样的角色,旨在通过征战或太空竞赛实现世界或宇宙的统治。
第一版《文明》中出现的错误是非暴力主义者甘地突然发起核攻击。原因是当文明采用民主制度时,攻击性会减少2。在第一版《文明》中,甘地的攻击性是所有玩家中最低的1,但随着游戏的进行,当印度文明采用民主制度时,攻击性减少2导致溢出到255,甘地突然成为了极端攻击性的玩家。而到了那个时候,通常每个文明都已经拥有了核武器,因此结果就是甘地在某个回合突然发动核战争。这种行为引起了人们的兴趣,因此在之后的《文明》系列中,这一现象成为了一个经典,但在第一版中,这却是一个意外的错误。
有符号整数
有符号整数(signed integer)采用了特殊处理最高有效位(most significant bit)的“二进制补码表示法”(two’s complement)。在二进制补码表示法中,对于n位整数,除了第n位之外,其余位与无符号数相同,但最高有效的n位不是表示为2的n-1,而是表示为-2的n-1。
具体来说,考虑4位二进制数,各位及其代表的数如下表所示:
| 4 | 3 | 2 | 1 | |
|---|---|---|---|---|
| 无符号情况 | 8 | 4 | 2 | 1 |
| 有符号情况 | -8 | 4 | 2 | 1 |
与无符号数相同,某个位模式表示的有符号值可通过观察置为1的位的位置来确定。例如,将0b1110视为4位有符号整数,则第2位、第3位、第4位,即2的位、4的位、-8的位都置为1,因此0b1110表示的值是2 + 4 + (-8) = -2。下面是一些示例图形。
按照这一规则,除非最高位为1,否则有符号整数表示的数与将其视为无符号整数解释的数相同。对于4位整数,0到7的数在有符号和无符号情况下具有相同的位模式。然而,如果第4位为1,则该位模式表示的数将是-8到-1(即0b1000到0b1111)之间的一个数。因为最高位为1表示负数,所以最高位有时也称为“符号位”。
将1添加到有符号整数时,如下图所示,值会循环。这是4位整数的一个示例。
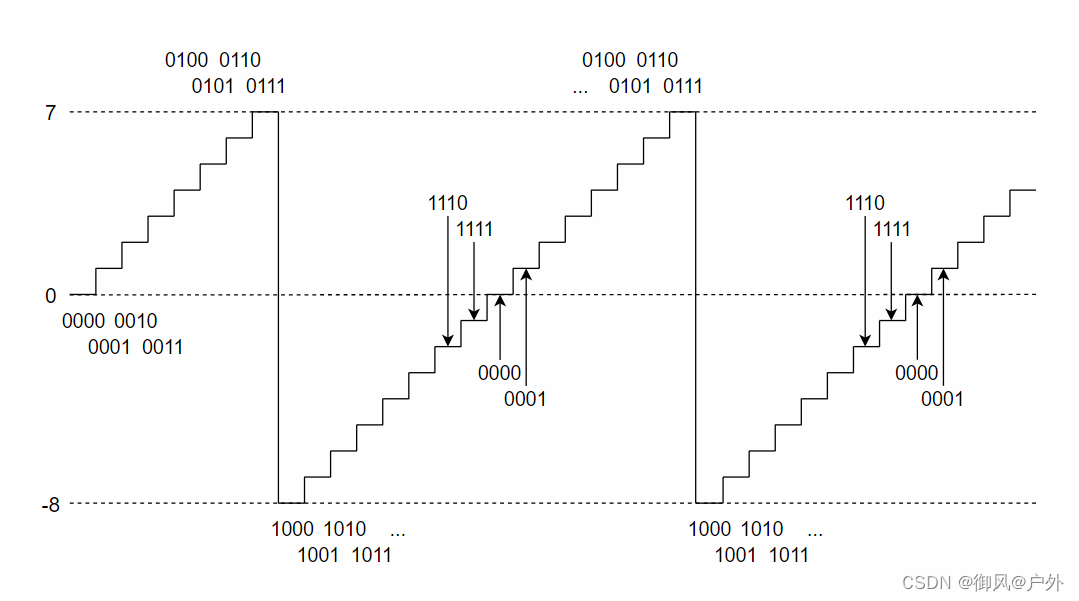
理解上述规则后,就能解释编程中常见的看似奇怪的有符号整数行为了。
当给有符号整数加1时,可能会出现溢出,从一个大数变为一个极小的数。读者们可能也经历过这种情况。通过考虑二进制补码表示法,就能理解到底发生了什么。例如,在8位有符号整数中,最大的数是0b0111_1111即127。加1后变为0b1000_0000,在二进制补码表示法中,这等同于-128。这是绝对值最大的负数。
当从main函数返回-3时,程序的退出代码应该是253。这是因为main函数将-3(即0b1111_1111_1111_1111_1111_1111_1111_1101)放入RAX,但接收端只会考虑RAX的低8位作为有意义的值,将其视为无符号整数处理,因此返回值是0b1111_1101,即253。
因此,一个位模式代表的数取决于阅读者的假设。就像纸上的文字实际上只是墨迹一样,只有将其视为文字的人才会赋予它意义一样,计算机内存中的内容也只是一系列的开关,本身并没有固有的意义。为了传递一个值,设置值的一方和读取值的一方必须就解释方式达成一致。
值得注意的是,在二进制补码表示法中,可以表示的负数比可以表示的正数多一个。例如,在8位整数中,-128是可表示的,但+128已经超出了可表示范围。这种正负范围不平衡是无法避免的,因为一旦为0分配了一个位模式,剩下的奇数模式就会导致正负数哪一个更多的问题。
符号扩展
在计算机中,经常需要进行扩展数值的位宽操作。例如,从内存中读取8位数值并将其设置到64位寄存器时,需要将8位值扩展到64位。
当处理无符号整数时,扩展值很简单,只需将高位用0填充即可。例如,将4位值0b1110 = 14 扩展为8位,结果为0b0000_1110 = 14。
然而,当处理有符号整数时,简单地用0填充高位会改变数值。例如,将4位值0b1110 = -2 扩展为8位时,如果错误地将其填充为0b0000_1110,则结果变为14。因为原始值本身是负数,但由于缺少符号位,被错误地解释为正数。
对于有符号整数的扩展,如果符号位为1,则需要将所有新的高位设置为1;如果符号位为0,则需要将所有新的高位设置为0。这个操作称为“符号扩展”。例如,将4位值0b1110 = -2 扩展为8位时,结果为0b1111_1110 = -2,这样就正确地扩展了位宽。
在无符号整数中,可以将数值左侧无限制的填充0,并在扩展时取出。

类似地,在有符号整数中,可以将数值左侧无限制的填充与符号位相同的值,并在扩展时取出。
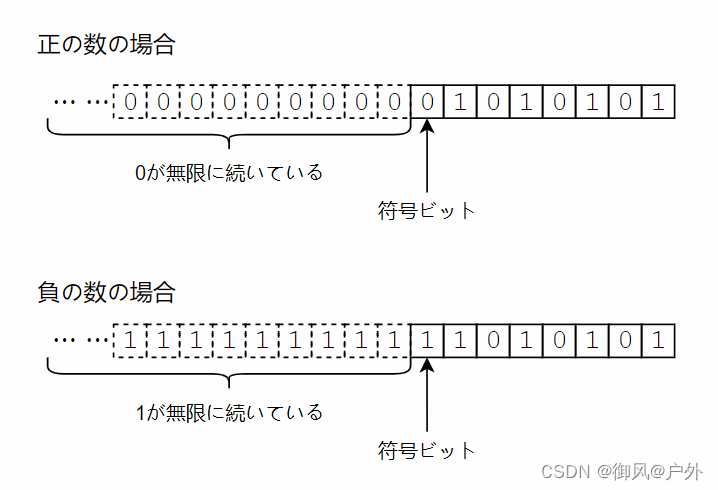
因此,当尝试将某个数值适配到更宽的位宽时,需要意识到自己处理的值是无符号还是有符号。
专栏:不需要符号扩展的负数表示
二进制补码表示法是广泛用于计算机中的有符号整数表示方法,但是当考虑将正负整数映射到位模式时,这并不是唯一的方法。例如,考虑负二进制,从低位到高位表示(-2)0、(-2)1、(-2)^2⋯⋯。下表展示了每个位表示的数,以及4位的情况对比。
| 4 | 3 | 2 | 1 | |
|---|---|---|---|---|
| 无符号 | 8 | 4 | 2 | 1 |
| 二进制补码 | -8 | 4 | 2 | 1 |
| 负二进制 | -8 | 4 | -2 | 1 |
在4位负二进制中,可以表示-10到5之间的16个整数,如下所示。
负二进制的缺点是处理起来比较复杂,例如处理进位等,而且在表示范围中心附近没有0的优点。但另一方面,负二进制具有不需要符号位的有趣特性。因此,当将负二进制的某一位数扩展到更大的位数时,可以始终使用0填充高位。
因此,计算机中整数的表示方法不仅限于二进制补码表示法,还有其他方法。在这些方法中,二进制补码表示法是最易于处理的表示方法,在几乎所有计算机上都被广泛使用。
符号的反转
虽然详细了解二进制补码表示并不一定是编译器编写所必需的知识,但掌握一些与二进制补码表示相关的技巧在某些时候会很方便。在这里,我将解释一种简单的方法来反转数字的正负。
在二进制补码表示中,执行“取反并加1”的操作可以反转数字的正负。例如,在8位有符号整数中,求解从3到-3的位模式的步骤如下:
- 用二进制表示数值。对于3,即为0b0000_0011。
- 对所有位进行取反。在这种情况下,结果为0b1111_1100。
- 加1。在这种情况下,结果为0b1111_1101。这就是-3的位模式。
掌握了以上方法,可以轻松地求解负数的位模式。
此外,有时也可以通过对具有符号位的位模式执行相同的操作来将其转换为正数,从而轻松地确定位模式所表示的数值。例如,要确定0b1111_1101表示的是什么,直接进行加法运算可能比较麻烦,但是通过取反并加1,得到0b0000_0011,即可轻松地知道其表示的是-3的反码。
以上技巧之所以有效,原因相对简单。由于到目前为止,尚未对二进制补码表示的运算进行数学上的严格定义,因此解释略显模糊。但其核心思想如下:
取反所有位等同于从-1开始减去该数值n。例如,位模式0b0011_0011的取反操作可以如下表示:
1111 1111
- 0011 0011
= 1100 1100
换句话说,将表示数值n的位模式取反等同于计算-1 - n。加1后,(-1 - n) + 1 = -n,这就可以得到-n相对于n的位模式。
专栏:字面数的基数
在C的标准规范中,可以用8进制、10进制或16进制来表示数字。通常情况下,写数字像123那样是10进制,以0x开头写数字像0x8040是16进制,以0开头写数字像0737是8进制。
也许有很多读者认为自己从来没用过在C中写8进制数的功能,但在这种语法中,甚至简单的0也会被认为是8进制的表示,所以实际上每个C程序员都会非常频繁地写8进制数。虽然这只是一个小知识,但仔细思考后会发现其中既有深层次的原因,又似乎没有。
首先,0作为数字表示法有些特殊。通常,像1这样的数不会写成01或001,因为十位数或百位数是0,但将这个规则直接应用到0上就变成空字符串了。由于在需要写0的情况下不写任何内容在实践中是不可行的,所以在这种情况下特别规定写0,但这样一来在C的语法中就会显得有些特殊。
指针和字符串字面量
到目前为止,我们已经建立了一种能够进行一定程度有意义计算的语言,但是在我们的语言中甚至还无法显示“Hello world”。现在是时候添加字符串,使程序能够输出有意义的消息了。
C中的字符串字面量与char类型、全局变量、数组密切相关。请考虑以下函数作为例子。
int main(int argc, char **argv) {
printf("Hello, world!\n");
}
上面的代码将编译成下面的代码。这里假设msg是一个与其他标识符不冲突的唯一标识符。
char msg[15] = "Hello, world!\n";
int main(int argc, char **argv) {
printf(msg);
}
我们的编译器目前还缺少一些支持字符串字面量的功能。为了支持字符串字面量,并且能够在printf等函数中显示消息,本章将逐步实现以下功能:
- 一元操作符&和*
- 指针
- 数组
- 全局变量
- char类型
- 字符串字面量
此外,我们还将在本章中添加测试上述功能所需的其他功能等。
步骤16:一元&和一元*
在这一步中,作为实现指针的第一步,我们将实现返回地址的一元&和引用地址的一元*。
这些操作符本来应该返回指针类型的值或者获取指针类型的值,但由于我们的编译器还没有除整数以外的其他类型,所以我们将用整数类型来代替指针类型。也就是说,&x会返回变量x的地址作为简单的整数。此外,*x将视x的值为地址,并从该地址读取值。
实现了这样的操作符后,下面的代码将能够运行。
x = 3;
y = &x;
return *y; // 返回3
此外,利用局部变量在内存中的连续分配,我们还可以通过指针间接地强制访问堆栈上的变量。在下面的代码中,我们假设变量y位于堆栈上的变量x的8个字节上方。
x = 3;
y = 5;
z = &y + 8;
return *z; // 返回3
在不区分指针类型和整数类型的实现中,例如*4这样的表达式将被视为从地址4处读取值的表达式,虽然这样做暂时可以接受。
实现起来相对简单。下面是添加了一元&和一元的语法。请根据这个语法修改解析器,将一元&和一元读取为名为ND_ADDR和ND_DEREF的节点类型。
unary = "+"? primary
| "-"? primary
| "*" unary
| "&" unary
对代码生成器的更改很小。更改点如下所示:
case ND_ADDR:
gen_lval(node->lhs);
return;
case ND_DEREF:
gen(node->lhs);
printf(" pop rax\n");
printf(" mov rax, [rax]\n");
printf(" push rax\n");
return;
步骤17:废除隐式变量定义,引入关键字int
到目前为止,所有变量和函数的返回值都隐式地设定为int。因此,不需要像int x;这样显式地指定变量类型,新的标识符都被视为新的变量名。但是从现在开始,我们不能再做出这样的假设了。因此,请实现以下功能:
- 不再将新标识符视为变量名,而是在出现未定义的变量时报错。
- 请以int x;这种形式定义变量。不需要支持初始化表达式,例如int x = 3;。也不需要支持int x, y;这样的形式。只需尽量实现简单的功能即可。
- 函数之前我们是以foo(x, y)这样的形式来写的,现在我们要改成int foo(int x, int y)。当前,顶级部分应该只包含函数定义,因此解析器首先应该读取int,然后一定是函数名,接着是int <参数名>的序列。不需要处理更复杂的语法,也不需要为“为将来的扩展做准备”而额外添加任何内容。只需编写足够解析"int <函数名>(<由int <变量名>重复组成的参数列表>)"的代码即可。
步骤18:引入指针类型
定义表示指针的类型
在这一步中,我们允许类型名不再只能是int,而是可以跟着0个或多个*。也就是说,我们要能够解析int *x或者int ***x这样的定义。
在编译器中当然需要处理“指向int的指针”这样的类型。例如,如果变量x是指向int的指针,那么编译器需要知道表达式*x是int类型的。由于类型可以变得非常复杂,比如“指向指针的指针的指针”,我们无法用固定大小的类型来表示它们。
那么应该怎么做呢?答案是使用指针。到目前为止,与变量关联的信息只是相对于基址指针(RBP)的偏移量。现在,您需要对此进行更改,以便变量可以具有类型。变量的类型大致应该是以下结构体:
struct Type {
enum { INT, PTR } ty;
struct Type *ptr_to;
};
这里的ty可以是int型或“指针到某类型”的两个值之一。ptr_to是一个只有在ty是“指针到某类型”时才有意义的成员。在这种情况下,它将指向被“~”指向的Type对象。例如,“指向int的指针”的类型在内部看起来应该是这样的。
表现“指向int的指针”的类型的数据结构
“指向指向int的指针”的类型将是这样的。
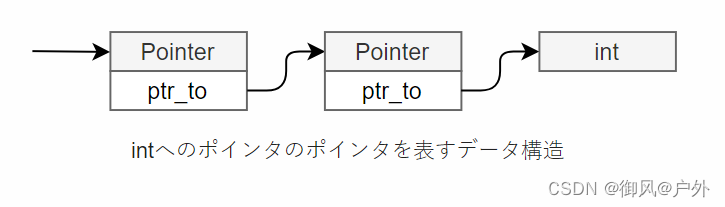
表现“指向int的指针”的指针的类型的数据结构
通过这种方式,您可以在编译器内部表示任意复杂的类型。
将值分配给指针指向的位置
左值是一个不仅仅是简单变量名的表达式,例如p=3,那么在编译时应该如何处理呢?与简单变量名时的基本概念基本相同。在这种情况下,首先要编译的是为了编译p作为左值的代码生成器。
在这个代码生成器中,您需要根据给定的语法树类型进行分支处理。对于简单变量,如前所述,您应该生成输出该变量地址的代码。在这里,因为有解引用操作符,所以您需要执行不同的操作。如果有解引用操作符,则请编译其中的语法树作为“右值”。然后,这将被编译成某种计算地址的代码(否则就无法对其进行解引用)。然后,您只需将该地址保留在堆栈上即可。
完成了这一步之后,您将能够编译类似以下的语句。
int x;
int *y;
y = &x;
*y = 3;
return x; // → 返回3
步骤19:实现指针的加减法
在这一步中,我们使指针类型的值p能够执行类似p+1或p-5这样的表达式。这看起来像是普通的整数加法,但实际上这是完全不同的操作。p+1并不是将p的地址加1,而是将p指向的下一个元素的指针,所以我们需要加上p指针所指向的数据类型的大小。例如,如果p指向int,则根据我们的ABI,p+1应该增加4个字节的地址。另一方面,如果p是指向指向int的指针,则p+1应该增加8个字节的地址。
因此,在指针的加减法中,我们需要知道类型的大小。目前,我们知道int大小为4,指针大小为8,因此请硬编码这些信息。
由于目前还没有分配连续内存的方法(我们的编译器还没有数组),因此编写测试有些困难。在这种情况下,您可以简单地借用外部编译器的帮助,使用那里的malloc,并在自己的编译器输出中使用这个辅助函数编写测试。例如,您可以这样进行测试:
int *p;
alloc4(&p, 1, 2, 4, 8);
int *q;
q = p + 2;
*q; // → 4
q = p + 3;
return *q; // → 8
专栏:int和long的大小
像x86-64 System V ABI这样的数据模型中,int是32位的,而long和指针是64位的,这种模型称为LP64。这意味着long和指针都是64位的。在同样的x86-64 ABI中,Windows采用LLP64,即int和long都是32位的,而long long和指针是64位的数据模型。
由于LP64和LLP64中long的大小不同,它们不具备ABI兼容性。例如,如果创建包含long成员的结构体,并将整个结构体直接写入文件,然后在读取时将文件中的数据直接强制转换为该结构体,那么在Unix和Windows之间无法互相传递文件并进行读取。
C规范规定int应该是“与执行环境的体系结构建议的自然大小相同的普通整数对象”,这意味着在64位计算机上似乎应该将int设置为64位。然而,什么是自然的是一个主观的问题,而且即使在64位计算机上,通常也可以自然地处理32位操作,因此在64位计算机上将int设置为32位并不一定是错误的。从实际角度来看,将int设置为64位会导致以下问题:
- 很少需要int为64位,所以将int设置为64位会浪费内存。
- 如果将short设置为16位,int和long设置为64位,那么将没有32位整数类型可用。
因此,大多数现有的64位计算机将int设置为32位。尽管如此,64位计算机上存在int为64位的ILP64。例如,据说旧版Cray超级计算机采用了ILP64。
步骤20:sizeof操作符
sizeof看起来像是一个函数,但在语法上它是一个一元操作符。在C中,大多数操作符都是符号,但实际上sizeof是个例外。
让我们稍微复习一下sizeof操作符的工作原理。sizeof操作符返回参数表达式的类型在内存中占用多少字节。例如,在我们的ABI中,sizeof(x)将返回4,如果x是int类型的话,返回8,如果x是指针的话。sizeof的参数可以是任何表达式,例如sizeof(x+3)将返回整体类型为int时为4,指针时为8。
虽然我们的编译器还没有数组,但是如果sizeof的参数是一个数组,它将返回整个数组的大小(以字节为单位)。例如,如果x被定义为int x[10],那么sizeof(x)将返回40。如果x被定义为int x[5][10],那么sizeof(x)将返回200,sizeof(x[0])将返回40,sizeof(x[0][0])将返回4。
sizeof操作符的参数只是用来确定类型的,不是实际执行的表达式。例如,写下sizeof(x[3]),并不会实际访问x[3]。由于在编译时就可以知道整个表达式x[3]的类型,因此sizeof(x[3])将在编译时被替换为该类型的大小。因此,指定给sizeof的具体表达式,例如x[3],在运行时将不再存在。
sizeof操作符的工作如下所示。
int x;
int *y;
sizeof(x); // 4
sizeof(y); // 8
sizeof(x + 3); // 4
sizeof(y + 3); // 8
sizeof(*y); // 4
// 任何表达式都可以作为sizeof的参数
sizeof(1); // 4
// sizeof的结果目前是int类型,因此与sizeof(int)相同
sizeof(sizeof(1)); // 4
现在让我们来实现这个sizeof操作符。要实现sizeof操作符,需要对令牌化器和解析器进行修改。
首先,在令牌化器中添加修改,使其将sizeof关键字识别为类型为TK_SIZEOF的令牌。
接下来,在解析器中进行修改,将sizeof替换为int型常数。以下是添加sizeof操作符后的语法。在这个语法中,sizeof是一元操作符,具有与一元加法和一元减法相同的优先级。这与C的语法相同。
unary = "sizeof" unary
| ("+" | "-")? primary
在这个语法中,不仅sizeof(x)形式被允许,sizeof x这种写法也被允许,这在实际的C中也是一样的。
在解析器中,当遇到sizeof操作符时,应该像平常一样解析参数表达式,并将其与int类型关联,然后将int替换为4,将指针替换为8。由于在解析器中替换为常数,所以不需要对代码生成树进行更改。
步骤21:实现数组
定义数组类型
在这一步中,我们将实现数组。到目前为止,我们只处理了适合存放在寄存器中的数据,但是现在首次出现了比寄存器更大的数据。
然而,C语法对数组有所限制。无法将数组作为函数参数传递,也无法将数组作为函数的返回值。如果编写了这样的代码,数组本身不会以值的形式传递,而是会自动创建一个指向该数组的指针,并将其传递。另外,也不支持直接将一个数组赋值给另一个数组(必须使用memcpy)。
因此,在函数和变量之间交换不适合放入寄存器的数据时,并不需要这些功能,只需有能在堆栈上分配比一个字更大的内存空间即可。
请让编译器能够读取如下变量定义:
int a[10];
上述a的类型是数组,该数组的长度为10,元素类型为int。与指针类型类似,数组类型也可以非常复杂,所以我们像步骤7一样,使用ptr_to来指示数组元素的类型。类型结构应该如下所示:
struct Type {
enum { INT, PTR, ARRAY } ty;
struct Type *ptr_to;
size_t array_size;
};
这里的array_size是仅在数组类型时有意义的字段,它是一个变量,保存数组的元素数。
一旦完成这一步,就应该很容易在堆栈上为数组分配空间了。要计算数组的字节大小,只需将数组元素的字节大小乘以数组的元素数即可。到目前为止,我们应该已经将堆栈空间分配为每个变量1个字,但现在请更改它,使得数组能够分配所需的空间。
实现从数组到指针的隐式类型转换
由于数组经常与指针一起使用,所以在C中,语法上没有严格区分数组和指针,它们似乎可以隐含地进行一些操作,但这导致了程序员对数组和指针之间的关系的理解变得模糊。因此,我们在这里解释一下数组和指针之间的关系。
首先,C中数组和指针是完全不同的类型。
指针是(在x86-64中)8字节的值的类型。与int有定义了+和-等运算符一样,对于指针也定义了+和-(稍有不同的形式)。除了这些运算符外,指针还定义了一元运算符,它可以用来引用指针所指向的内容。除了一元运算符之外,指针没有太多特别之处。可以说指针像int一样普通。
另一方面,数组是可以变成任意字节的类型。与指针不同,数组几乎没有定义运算符。定义的运算符只有返回数组大小的sizeof运算符和返回数组第一个元素的指针的&运算符。除此之外,没有其他可以应用于数组的运算符。
那么为什么可以编译类似a[3]的表达式呢?在C中,a[3]被定义为*(a+3)。因为数组没有定义+运算符,所以为什么可以这样呢?
这里就是数组隐式地转换为指针的语法起作用的地方。除了当作sizeof或一元&的操作数使用时,数组在语法上会自动转换为指向该数组的第一个元素的指针。因此,*(a+3)被解释为对数组a的第一个元素指针加3后解引用的表达式,结果就是访问数组的第3个元素。
在C中,没有用于数组访问的[]运算符。C中的[]只是用于通过指针访问数组元素的便捷表示法。
同样,将数组作为函数参数传递会将其隐式转换为指向数组第一个元素的指针,也可以将数组直接赋值给指针,看起来就好像在对指针进行赋值一样,但这也是因为上述原因。
因此,编译器在几乎所有运算符的实现中都需要将数组转换为指针。这并不难实现。除了实现sizeof和一元&之外,一旦解析了运算符的操作数,如果其类型为T的数组,则将其视为指向T的指针即可。在代码生成器中,数组类型的值应该生成一个将其地址推送到堆栈上的代码。
一旦完成了这一步,以下代码应该能够正常运行:
int a[2];
*a = 1;
*(a + 1) = 2;
int *p;
p = a;
return *p + *(p + 1); // → 3
专栏:语言律师
人们将精通正式语言规范的人称为"语言律师"(language lawyer)。在程序员的俚语词典"Jargon File"中,"语言律师"被解释为:
“语言律师 [名词]:对一种或多种编程语言(几乎)所有有用和奇怪的功能以及其限制都非常熟悉的资深软件工程师。一个人是否是语言律师,可以通过向其展示200页以上的手册中分散的五个句子并询问他是否能够回答"你应该看这里"来确定。”
“语言律师"一词还可用作动词,即"语言律师”(language lawyering)。
熟练的语言律师常常受到其他程序员的尊重。当作者在Google的C++编译器团队工作时,团队中有一个可以被称为终极语言律师的人物。当我们遇到C++中不明白的地方时,常常会得出这样的结论:去问他(即使是C++编译器的开发者,也经常会遇到自己不了解的C++规范)。实际上,他是Clang这个主要的C++编译器的核心实现者之一,也是C++规范的主要作者之一,对C++非常了解,但他也曾经说过"一旦觉得理解了C++,就会变得一头雾水",所以我记得C++语言规范的巨大和复杂的细节是相当大的。
在本书中,在编译器的完善之前,我们故意不深入C语言规范的细节。这是有原因的。虽然在实现存在规范的编程语言时,必须成为某种程度上的语言律师,但从一开始就过于关注细节并不是一种理想的开发方法。就像在画画时,不是只详细绘制一处,而是首先完成整体的草图一样,在实现编程语言时,初期不应过于关注细节,而是要在保持平衡的同时进行开发。
步骤22:实现数组下标
在C中,x[y]被定义为*(x+y)。因此,实现下标索引是相对简单的。只需在解析器中将x[y]简单地替换为*(x+y)即可。例如,a[3]将变为*(a+3)。
在这种语法中,由于3[a]展开为*(3+a),如果a[3]可行,那么3[a]也应该可行,但是在C中,像3[a]这样的表达式实际上是合法的。请尝试一下。
步骤23:实现全局变量
现在我们想要能够在程序中编写字符串文字了。在C中,字符串文字是char数组。由于我们已经实现了数组,所以这部分没有问题,但是字符串文字与在堆栈上的值存在一些区别,字符串文字不是存在于堆栈上的,而是存在于内存中的固定位置。因此,为了实现字符串文字,首先我们要添加全局变量。
到目前为止,我们只允许顶层定义函数。现在我们要更改语法,以便在顶层写入全局变量。
由于变量定义与函数定义的外观相似,因此解析起来会有些棘手。比较一下下面的四个定义:
int *foo;
int foo[10];
int *foo() {}
int foo() {}
前两个foo是变量定义,后两个是函数定义,但是在解析它们时,直到达到函数名或变量名并尝试读取下一个标记之前,是无法区分它们的。因此,首先我们要“读取类型名的前半部分”,然后应该是标识符,然后需要尝试先读取一个标记。如果读取的标记是"(",则说明正在解析函数定义,否则是变量定义。
将解析的全局变量名存入映射表中,以便通过名称进行查找。仅当变量名无法解析为局部变量时,才尝试解析为全局变量。这样可以自然地实现局部变量隐藏同名的全局变量的行为。
在解析器中,将对局部变量的引用和对全局变量的引用转换为抽象语法树的不同节点。由于名称在解析阶段已经解析,因此在那个阶段将它们分开也很自然。
到目前为止,所有变量都应该在堆栈上,所以读写变量是相对于RBP(基指针)的相对位置。全局变量不是在堆栈上的值,而是直接访问内存中的固定位置,因此编译器需要直接访问其地址。请参考实际的gcc输出。
一旦实现了这一步,你会惊讶地发现,局部变量和全局变量实际上是非常不同的东西。这是因为C语言很好地抽象了它们。虽然在表面上它们看起来是一样的,但实际上它们在内部实现上是非常不同的。
步骤24:实现字符类型
数组可以是比一个字更大的类型,但字符是小于一个字的类型。到目前为止,你可能已经需要编写一个函数,它接受一个表示类型的对象,并返回该类型的大小(以字节为单位)。现在添加字符类型,并对该函数进行更改,使其对字符类型返回1字节。
在这一步中,字符只是一个简单的小整数类型。通过类似于movsx ecx, BYTE PTR [rax]的指令,可以从rax指向的地址读取一个字节并将其放入ecx中。如果不需要符号扩展,可以使用movzx ecx, BYTE PTR [rax]指令。写入时,使用类似mov [rax], cl的指令,将8位寄存器用作源寄存器。
请参考实际编译器的输出。
一旦实现了这一步,以下代码应该能够正常运行:
char x[3];
x[0] = -1;
x[1] = 2;
int y;
y = 4;
return x[0] + y; // → 3
专栏: 8位寄存器和32位寄存器的区别
为什么读取1字节值时需要使用movsx或movzx呢?当读取4字节值时,只需使用普通的mov将其加载到下位32位别名的寄存器中就可以了,所以当读取char时,看起来只需要将其加载到AL中即可。但实际上这样做是不正确的。这个谜题的答案在x86-64规范中。
在x86-64中,当将值加载到下位32位别名寄存器中时,上位32位会被重置为0。然而,当加载到下位8位别名寄存器时,上位56位会保留之前的值。这是一个不一致的规范,但由于x86-64的历史悠久,这种不一致性在各个地方都存在。
x86-64从16位处理器8086发展而来,然后是32位、64位,因此首先有AL,然后是EAX,然后是RAX。换句话说,当将值加载到AL中时,上位24位被保留(不被重置)的规范最初就存在,然后在将其扩展到64位时,我们假设制定规范时已经存在这种规范:加载到EAX中
时,上位32位被重置。为什么要采取这种不一致的规范?有一个很好的原因。
现代处理器会检查指令之间的依赖关系,并且会并行执行不相关的指令(不使用前一条指令的结果)。因此,假设采用了加载时不重置上位32位的规范,那么如果将上位32位视为简单的垃圾并且只使用下位32位,然后在后续使用同一寄存器的指令之间会出现假的依赖关系。重置上位32位为符号扩展的规范可以消除依赖关系。因此,在将x86升级为64位时,我们选择了一种便于加速的规范,尽管这破坏了一致性。
步骤25:实现字符串文字
在这一步中,我们将使编译器能够解析由双引号括起来的字符串,并将其编译成代码。由于我们已经具备了数组、全局变量和字符类型,因此我认为这一步相对简单。
首先,我们需要修改标记器,以便当找到双引号时,读取到下一个双引号为止,并创建一个字符串标记。在这一步中,我们不需要实现由反斜杠转义等功能。重要的是按照步骤逐步进行,即使看起来实现起来很简单,也不要着急。
在生成汇编代码时,无法在生成的机器代码中输出表示字符串文字的数据。在生成汇编代码时,需要将全局数据和代码分开写。换句话说,在生成代码时,我们想要首先输出在代码中出现的所有字符串文字,然后再输出代码。但是,遍历语法树以执行此操作可能会很麻烦。要实现这一点,最简单的方法是使用一个向量来保存到目前为止看到的所有字符串文字,并让解析器每次看到一个字符串时将其简单地添加到向量中。
请参考实际编译器的输出。
到这一步,你应该已经能够使用printf输出字符串了。现在是一个很好的机会,使用你自己编写的编程语言编写一些更复杂的程序,而不仅仅是测试代码。例如,你可能会尝试用自制语言编写8皇后问题的解决方案?人类从数字计算机的发明到开发出能够轻松编写这种水平代码的编程语言,历经了几十年的时间。而现在你只花了几周就实现了这个功能,这是人类和你的伟大进步。
(调用可变参数函数时,AL寄存器用于存储浮点数参数的个数。我们的编译器尚未支持浮点数,因此在调用函数之前,始终将AL设置为0。)
步骤26:从文件读取输入
到目前为止,我们一直将C代码作为参数直接传递给编译器,但随着输入变得越来越长,现在应该考虑像普通C编译器一样接受文件名作为命令行参数。打开给定的文件并读取其内容,返回以’\0’结尾的字符串的函数可以简洁地写成如下:
#include <errno.h>
#include <stdio.h>
#include <string.h>
// 返回指定文件的内容
char *read_file(char *path) {
// 打开文件
FILE *fp = fopen(path, "r");
if (!fp)
error("cannot open %s: %s", path, strerror(errno));
// 获取文件长度
if (fseek(fp, 0, SEEK_END) == -1)
error("%s: fseek: %s", path, strerror(errno));
size_t size = ftell(fp);
if (fseek(fp, 0, SEEK_SET) == -1)
error("%s: fseek: %s", path, strerror(errno));
// 读取文件内容
char *buf = calloc(1, size + 2);
fread(buf, size, 1, fp);
// 确保文件以"\n\0"结尾
if (size == 0 || buf[size - 1] != '\n')
buf[size++] = '\n';
buf[size] = '\0';
fclose(fp);
return buf;
}
由于我们的编译器的实现限制,最好是所有行都以换行符结尾,而不是以换行符或EOF结尾的数据。因此,如果文件的最后一个字节不是\n,则自动添加\n。
严格来说,此函数对于给定特殊文件的随机访问情况可能不起作用。例如,当指定文件名为/dev/stdin时,或者将命名管道指定为文件名时,可能会显示出像/dev/stdin: fseek: Illegal seek这样的错误消息。然而,实际上这个函数对于大多数情况来说都足够用了。请使用此函数读取文件内容,并将其视为输入。
由于输入文件通常包含多行内容,因此我们还应该加强显示错误消息的函数。当发生错误时,显示输入文件名、出错行的行号和行的内容是一个好主意,这样错误消息会像下面这样:
foo.c:10: x = y + + 5;
^ 表达式无效
要显示这种类型的错误消息,函数将是这样的:
// 输入文件名
char *filename;
// 用于报告错误位置的函数
// 显示如下格式的错误消息
//
// foo.c:10: x = y + + 5;
// ^ 表达式无效
void error_at(char *loc, char *msg) {
// 获取包含loc的行的起始点和结束点
char *line = loc;
while (user_input < line && line[-1] != '\n')
line--;
char *end = loc;
while (*end != '\n')
end++;
// 确定找到的行是整个文件的第几行
int line_num = 1;
for (char *p = user_input; p < line; p++)
if (*p == '\n')
line_num++;
// 显示包含的行,以及文件名和行号
int indent = fprintf(stderr, "%s:%d: ", filename, line_num);
fprintf(stderr, "%.*s\n", (int)(end - line), line);
// 使用"^"指示错误位置,并显示错误消息
int pos = loc - line + indent;
fprintf(stderr, "%*s", pos, ""); // 输出pos个空格
fprintf(stderr, "^ %s\n", msg);
exit(1);
}
这个错误消息输出程序虽然相
当简单,但可以说是以相当正式的格式输出错误消息了。
专栏:错误恢复
如果输入的代码在语法上有错误,许多编译器会尝试跳过错误位置,继续解析以尽可能多地发现错误。这样做的目的是尽可能多地发现错误,而不仅仅是发现一个。从错误中恢复并继续解析的功能称为“错误恢复”。
在早期的编译器中,错误恢复是非常重要的功能。在20世纪60年代和70年代,程序员使用计算机中心的大型计算机进行时间共享,从提交代码到获取编译结果,有时需要等待一整晚。在这样的环境中,对于编译器来说,尽可能多地指出可识别的错误是至关重要的一项工作。在早期编译器的教科书中,错误恢复是语法分析的一个重要主题。
现在随着开发使用编译器更加交互式,错误恢复不再是一个非常重要的主题。我们的编译器只会显示第一个错误消息。通常情况下,这已经足够了。
步骤27:行注释和块注释
我们的编译器也逐渐进化,现在可以编写更复杂的代码了。在这种情况下,注释变得必不可少。在这一章中,我们将实现注释功能。
在C语言中有两种类型的注释。一种是行注释,即//到行尾的内容都是注释。另一种是块注释,即/开头,/结尾。块注释中的内容,除了*/这两个字符之外的所有内容都会被跳过。
从语法上来说,注释被视为一个空白字符。因此,在标记器中,自然而然地将注释与空白字符一样跳过是合理的。以下是跳过注释的代码示例:
void tokenize() {
char *p = user_input;
while (*p) {
// 跳过空白字符
if (isspace(*p)) {
p++;
continue;
}
// 跳过行注释
if (strncmp(p, "//", 2) == 0) {
p += 2;
while (*p != '\n')
p++;
continue;
}
// 跳过块注释
if (strncmp(p, "/*", 2) == 0) {
char *q = strstr(p + 2, "*/");
if (!q)
error_at(p, "未闭合的注释");
p = q + 2;
continue;
}
...
在这里,为了找到块注释的结束,我们使用了C标准库中的strstr函数。strstr函数在字符串中查找另一个字符串,如果找到了,就返回指向该字符串开头的指针,如果找不到,则返回NULL。
专栏:行注释
在原始的C语言中只有块注释,而行注释是在C开发了近30年后的1999年正式添加到规范中的。最初的设想是这样一个改变不会破坏兼容性,但实际上在一些微妙的情况下,原本正常工作的代码可能会产生不同的含义。
具体来说,下面的代码,如果只支持块注释,则会被解释为a/b,如果支持行注释,则会被解释为a。
a//*
// */ b
专栏:块注释和嵌套
块注释不能嵌套。由于/*在注释中没有特殊含义,因此如果您注释掉现有的块注释
/* /* ... */ */
那么,第一个*/将结束注释,第二个*/将导致语法错误。
当您想要注释掉一行或多行可能包含块注释的代码时,您可以使用C预处理器,例如:
#if 0
...
#endif
将代码放在#if 0和#endif之间。
步骤28:用C重新编写测试
在这一步中,我们将重新编写测试以加速make test的执行。到这一步为止,您可能已经编写了100个以上的测试用例的shell脚本。在shell脚本中,每个测试用例启动了多个进程。换句话说,对于每个测试用例,启动了自制编译器、汇编器、链接器以及测试本身的多个进程。
启动进程并不是一件快速的事情,即使是小型程序也不例外。因此,如果这样的操作重复了数百次,那么总体来说会花费相当可观的时间。我相信您的测试脚本现在可能需要几秒钟才能完成执行。
最初使用shell脚本编写测试的原因是因为没有其他办法可以进行正常的测试。在电子计算器级别的语言阶段,由于缺乏if和==等功能,无法在该语言中验证计算结果是否正确。但是现在我们已经可以验证结果是否正确了。现在我们可以比较结果是否正确,如果错误就输出错误消息(字符串)并退出。
因此,在这一步中,请将之前用shell脚本编写的测试重写为C文件。
程序执行图像和初始化表达式
到目前为止,我们的编译器已经支持了函数、全局变量和局部变量等编程的主要要素。另外,通过学习分割编译和链接,您应该已经了解了如何将程序分成小块进行编译,然后最终将它们合并成一个文件。
本章将介绍操作系统如何执行可执行文件。通过阅读本章,您将了解到可执行文件中包含了哪些数据,以及在调用main函数之前发生了什么。
此外,在本章中,我们还将介绍变量的初始化表达式,即以下代码将如何编译,并向我们的编译器添加初始化表达式的支持。
int x = 3;
int y[3] = {1, 2, 3};
char *msg1 = "foo";
char msg2[] = "bar";
令人意外的是,要支持初始化表达式,我们需要了解程序在到达main函数之前的工作方式。
值得一提的是,在这一章中,我们将只讨论简单的静态链接的可执行文件格式。这种格式的文件被称为“静态链接”执行文件。与静态链接相对应的是“动态链接”,其中一个程序的片段被分开放在多个文件中,并且在运行时它们会在内存中组合在一起执行。尽管动态链接广泛使用,但我们将在单独的章节中介绍它。首先,让我们深入了解静态链接的基本模型。
可执行文件的结构
可执行文件由文件头和一个或多个称为“段”(segment)的区域组成。一个可执行文件通常至少有两个段,其中包含可执行代码和数据。包含可执行代码的段称为“文本段”(text segment),包含其他数据的段称为“数据段”(data segment)。实际的可执行文件中还可能包含其他段,但为了理解基础原理,我们暂时忽略这些。
需要注意的是,尽管在常规的上层语言中,“文本”一词通常与文本文件中的文本相关,但在低层级上,“文本”通常指的是机器码数据。此外,机器码实际上只是一系列字节,因此“文本和数据”通常指的是“除了文本之外的数据”。在本章中,当我们提到数据时,我们指的是除文本以外的数据。
作为链接器的输入,目标文件中的文本和数据是分开的。链接器会从多个目标文件中读取文本,并将它们连接在一起形成一个文本段,类似地,它会将来自多个目标文件的数据连接在一起形成一个数据段。
可执行文件的文件头包含了每个段在运行时应该放置的内存地址。当您运行可执行文件时,操作系统的“程序加载器”(program loader)或简称“加载器”会根据该信息从可执行文件中复制文本和数据到内存中。
以下是可执行文件及其加载到内存中的图示。
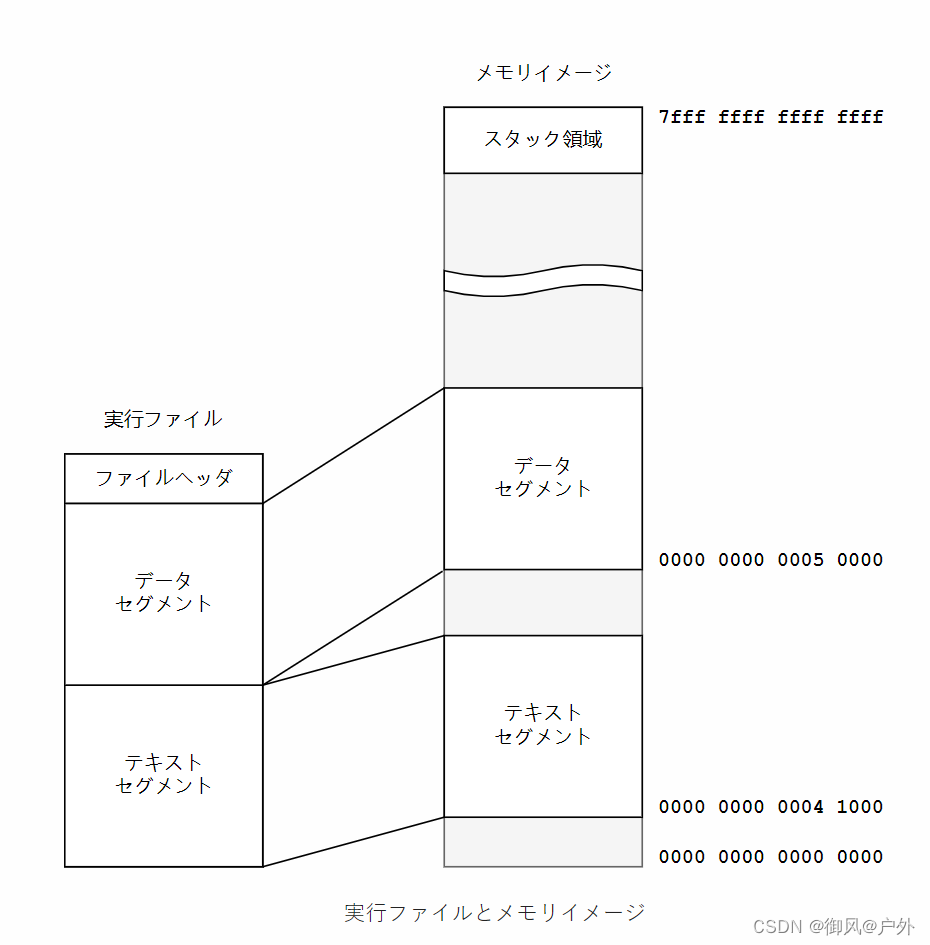
假设在该图示的可执行文件中,文本段被加载到地址0x41000,数据段被加载到地址0x50000。
文件头中还包含了开始执行的地址信息。例如,如果文件头中写入了从地址0x41040开始执行的信息,则加载器将可执行文件加载到内存后,设置堆栈指针为0x7fff_ffff_ffff_ffff,并跳转到地址0x41040开始执行用户程序。
数据段的内容
文本段的内容明显是机器语言,但数据段中包含了什么呢?答案是,数据段包含了全局变量和文字字符串等文字常量。
局部变量既不直接放在文本段,也不直接放在数据段中。局部变量是程序在动态堆栈空间上创建的,因此在将程序加载到内存后,它们并不存在。
在C的执行模型中,程序几乎直接将可执行文件加载到内存中,以便开始执行main函数。因此,全局变量必须从可执行文件的数据段复制到内存中,并确保它们具有适当的初始值。
由于这种限制,例如对于全局变量,不能使用下面这样的函数调用初始化表达式:
int foo = bar();
如果存在需要动态初始化的全局变量,必须在执行main函数之前由某人执行上述表达式。但是,由于C中不存在在main函数之前执行的初始化机制,因此无法执行此类初始化。
换句话说,全局变量必须在链接时具有完成的值,并且必须作为其字节序列直接放入可执行文件中。这样的值仅限于以下表达式:
- 常数表达式
- 全局变量或函数的地址
- 将常数添加到全局变量或函数地址的结果
如何将文字常量或字符串等常数表达式直接设置为文本段的固定值是显而易见的。
全局变量或函数的地址通常在编译时确定,但在链接器完成可执行文件时通常会确定。因此,对于指针类型的全局变量,例如int *x = &y;这样的定义是合法的。链接器自行决定程序段的布局,并且自然也知道函数和全局变量的加载地址,因此x的内容可以在链接时填充。
此外,由于链接器支持在标签地址中添加常数,因此像int *x = &y + 3;这样的定义也是合法的。
除了上述模式之外,不能将其他表达式用作初始化表达式。例如,不能在全局变量的初始化表达式中使用全局变量的值(而不是地址)。像ptrdiff_t x = &y - &z;这样计算两个全局变量地址之差的表达式原则上在链接时可以求值,但是由于链接器不支持计算这样两个标签之间的差值,因此无法在初始化表达式中编写此类表达式。全局变量的初始化表达式仅限于上述限定的几种模式。
在C中,作为全局变量的初始化表达式的例子可以用如下方式表示:
int a = 3;
char b[] = "foobar";
int *c = &a;
char *d = b + 3;
每个表达式对应的汇编代码如下:
a:
.long 3
b:
.byte 0x66 // 'f'
.byte 0x6f // 'o'
.byte 0x6f // 'o'
.byte 0x62 // 'b'
.byte 0x61 // 'a'
.byte 0x72 // 'r'
.byte 0 // '\0'
c:
.quad a
d:
.quad b + 3
连续的.byte可以使用.ascii指令来替代,例如.ascii "foobar\0"。
专栏:全局变量的动态初始化
在C语言中,全局变量的内容必须静态确定,但在C++中,可以使用任意表达式对全局变量进行初始化。换句话说,在C++中,全局变量的初始化表达式将在调用main函数之前执行。其工作原理如下:
- C++编译器将全局变量的初始化表达式汇总到一个函数中,并将该函数指针输出到称为.init_array的特殊节(section)中。
- 链接器将来自多个输入文件的.init_array节连接到一起,并输出到.init_array段(segment)中(因此.init_array段将包含函数指针数组)。
- 加载器在将控制传递给main函数之前,顺序执行.init_array段中的函数指针。
通过编译器、链接器和程序加载器的协同工作,实现了全局变量的动态初始化。
虽然可以使用与C++相同的机制来实现C中全局变量的动态初始化,但故意将这种功能从C语言规范中排除了。
在C语言规范的设计选择中,虽然编写程序时会受到许多限制,但在执行程序时,即使在资源有限的加载器或无加载器的环境(例如在计算机启动时直接从ROM执行的代码)中,也能完全符合语言规范。因此,这只是一种权衡,而不是谁更优秀的讨论。
初始化表达式的语法
初始化表达式乍看起来只是赋值表达式,但实际上初始化表达式与赋值表达式在语法上有很大的区别,初始化表达式有一些特殊的写法是只允许在初始化表达式中的。现在让我们来仔细了解这些特殊的写法。
首先,在初始化表达式中可以对数组进行初始化。例如,下面的表达式初始化了数组x,使得x[0]、x[1]、x[2]分别为0、1、2。
int x[3] = {0, 1, 2};
如果给出了初始化表达式,那么数组的长度可以省略,通过右侧元素的数量就可以知道数组的长度。例如,上述表达式与下面的表达式是相同的。
int x[] = {0, 1, 2};
如果明确给出了数组的长度,并且只提供了部分初始化表达式,剩余的元素必须用0来初始化。因此,下面这两个表达式是相同的。
int x[5] = {1, 2, 3, 0, 0};
int x[5] = {1, 2, 3};
另外,对于char数组的初始化表达式,有一种特殊的语法,可以使用字面量字符串作为初始化表达式,如下所示:
char msg[] = "foo";
上述表达式与下面的表达式是相同的。
char msg[4] = {'f', 'o', 'o', '\0'};
全局变量的初始化表达式
全局变量的初始化表达式必须在编译时进行计算。计算结果可以是简单的字节序列,也可以是函数或全局变量的指针。对于指针,它可以具有一个整数来表示其偏移量。
未提供初始化表达式的全局变量必须以全0的形式初始化。这是由C的语法规定的。
如果初始化表达式的结果不是上述计算结果之一,请将其视为编译错误。
局部变量的初始化表达式
局部变量的初始化表达式在外观上与全局变量的初始化表达式相同,但意义大不相同。局部变量的初始化表达式是在其所在位置执行的表达式。因此,其内容在编译时无需确定。
基本上,类似于int x = 5;这样的语句会被编译成类似于int x; x = 5;这样的两个语句。
类似于int x[] = {1, 2, foo()};这样的语句会被编译成类似于以下的语句:
int x[3];
x[0] = 1;
x[1] = 2;
x[2] = foo();
未提供初始化表达式的局部变量的内容是未定义的。因此,这样的变量不需要初始化。
专栏:字的大小
在x86-64中,“字”这个术语既表示16位数据又表示64位数据。这是一个令人困惑的情况,但背后有历史原因。
“字”这个术语原本指的是计算机上能够自然处理的最大整数或地址的大小。在64位处理器x86-64中,64位被称为一个字,这源自这一概念。
另一方面,将16位称为一个字,源自于16位处理器8086的术语。当英特尔的工程师们将8086扩展为32位处理器386时,为了避免“字”大小的变化,他们将32位称为“双字”(double word或dword)。同样,当他们将386扩展为64位处理器x86-64时,他们将64位称为“四倍字”(quad word或qword)。正是出于这种兼容性考虑,才导致了“字”这个术语有两种不同的含义。
第29步及以后:【待补充】
静态链接与动态链接
到目前为止,本书只使用了静态链接的功能。静态链接是一个直接的执行模型,通过专注于这个模型的解释,可以更容易地解释汇编代码和执行文件的内存映像等内容,但实际上,在创建通常的执行文件时,并不广泛使用静态链接。实际上,通常使用的是动态链接而不是静态链接。
本章将介绍静态链接和动态链接。
默认情况下,编译器和链接器会尝试生成执行动态链接的执行文件。读者们可能已经注意到了,如果在这里之前忘记给cc加上-static选项,可能会看到如下错误(如果没有看到,请尝试从Makefile中删除-static选项然后重新运行make)。
$ cc -o tmp tmp.s
/usr/bin/ld: /tmp/ccaRuuub.o: relocation R_X86_64_32S against `.data' can not be used when making a PIE object; recompile with -fPIC
/usr/bin/ld: final link failed: Nonrepresentable section on output
链接器默认会执行动态链接,但是要执行动态链接,就必须从编译器输出可能执行动态链接的汇编代码。目前的9cc还不会生成这样的代码,因此,如果忘记加上-static选项,就会看到上面的错误。通过阅读本章,您将了解上述错误的含义,并且将了解需要采取什么措施来解决该错误。
静态链接
静态链接的可执行文件是自包含的,不需要在运行时引用其他文件的可执行文件。例如,像printf这样的函数位于libc标准库中,而不是用户编写的函数,但是当使用静态链接创建可执行文件时,printf的代码将被从libc复制到可执行文件中。运行静态链接的程序时不需要libc。这是因为libc中的必要代码和数据已经复制到可执行文件中了。
下面我们来看看实际上,简单程序hello.c是如何被静态链接到可执行文件的。
#include <stdio.h>
int main() {
printf("Hello world!\n");
}
要将hello.c文件编译并链接成名为hello的可执行文件,您可以输入以下命令。
$ cc -c hello.c
$ cc -o hello hello.o
上面的命令中,第一行编译了hello.c并创建了对象文件hello.o,第二行将其链接为可执行文件。您也可以将这两个命令合并为cc -o hello hello.c,这样编译器在启动时会执行上述两个命令的等效操作。
在hello.c中,我们包含了stdio.h,但是像本书中所看到的那样,头文件并不包含函数体的代码。因此,当编译hello.o时,编译器知道stdio.h中声明了printf函数的存在和其类型,但是它对printf的实际代码一无所知。因此,hello.o中不会包含printf的代码。事实上,hello.o中只包含main的定义。将hello.o与包含printf的对象文件组合起来形成可执行文件是链接器的工作。
通过cc通过链接器启动时,除了命令行传递的名为hello.o的文件之外,还会传递系统标准库的路径/usr/lib/x86_64-linux-gnu/libc.a。printf函数包含在该libc.a库中。 .a是一个类似.tar或.zip的存档文件。让我们来看看它的内容。
$ ar t /usr/lib/x86_64-linux-gnu/libc.a
...
printf_size.o
fprintf.o
printf.o
snprintf.o
sprintf.o
...
musl的printf.c
存档文件中包含:
静态链接的可执行文件的执行模型是简单的。在运行时,由于只有可执行文件存在于内存中,因此可以将可执行文件的各个段加载到内存的任意位置。当尝试将其加载到链接时确定的默认地址时,加载不会失败,因为在加载可执行文件之前,内存中没有任何内容。因此,静态链接中的所有全局变量和函数的地址都可以在链接时确定。
静态链接的优点包括:
- 简单快速,加载速度快
- 不需要依赖其他文件,只需复制可执行文件即可运行
- 即使存在微妙的
版本差异,静态链接时复制的库代码和数据都是固定的,因此无论在何种环境下,相同的可执行文件都可以以相同的方式运行
静态链接的缺点包括:
- 由于复制了执行文件所使用的库函数或代码,因此磁盘和内存会有少量浪费
- 如果库的bug被修复,需要重新链接现有的可执行文件才能反映这些更改
另一方面,动态链接的可执行文件在运行时需要其他文件,如.so(Unix)或.dll(Windows)。 .so或.dll包含了printf等函数的代码以及全局变量,例如errno。 .so或.dll等文件被称为动态库或简单地称为库或DSO(动态共享对象)。
C的类型语法
C的类型语法以其不必要的复杂性而闻名。C的开发者Dennis Ritchie在他与合著者合著的书籍《C程序设计语言》(通常称为“K&R”)中甚至写道:“C语言声明的语法,尤其是涉及指向函数的指针的声明的语法,经常受到批评。”。这表明即使是C的作者也暗示了这种类型语法的设计并不完美。
尽管如此,一旦理解了这种语法的规则,它并不是那么难以理解。
本章将解释如何阅读C的类型语法。通过逐步理解,到本章结束时,读者应该能够解读复杂类型如void (*x)(int)或void (signal(int, void ()(int)))(int)。
类型图表
C中可表示的类型本身相对简单。为了区分类型的语法复杂性和类型本身的复杂性,暂时将语法放在一边,只考虑类型本身。
像指针和数组这样的复杂类型可以用箭头连接的简单类型图来表示。例如,下图表示“指向int的指针的指针”的类型。
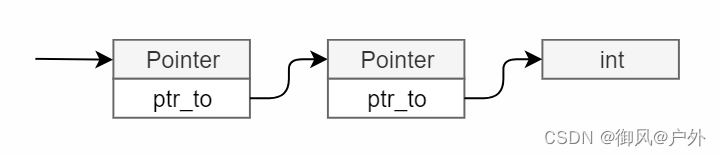
在日语中,应该从箭头的终点到起点读作“int的指针的指针”。而在英语中,则沿着箭头的方向读作a pointer to a pointer to an int。
假设变量x具有上述图示的类型。对于“x的类型是什么?”这个问题,最简洁的答案是“指针”,因为第一个箭头指向的是指针类型。请注意,x首先是一个指针,而不是像int这样的类型。“指针指向的类型是什么?”这个问题的答案也是“指针”,因为它指向的是第一个箭头指向的类型。最后,“指针指向的类型是什么?”这个问题的答案是“int”。
下图表示“指向int的指针的数组”,数组的长度为20。实际上,在编译器中,数组的长度被表示为数组类型的成员,如下图所示。
假设变量x具有上述图示的类型,那么x将是一个长度为20的数组类型,其元素为指针,而指针指向的是int。
函数类型也可以用图表来表示。下图表示了一个接受int和指向int的指针两个参数,并返回指向void的指针的函数类型。
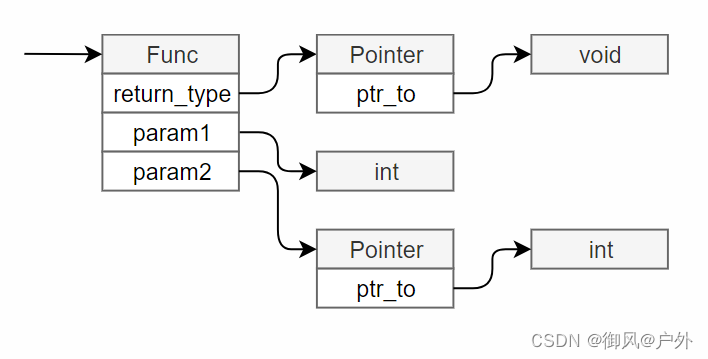
最后,让我们举一个更复杂的例子。下图表示了一个返回指向接受int的函数并返回int的指针的函数指针的类型。虽然用语言描述起来复杂,但在图中只是长而已,结构却是简单明了的。
假设变量x具有上述图示的类型,那么x将是一个指针类型,它指向一个函数,该函数的参数类型为int,返回类型为指针类型,指向的是一个函数,该函数的返回类型为int。
在编译器内部,类型被表示为上述图表所示的方式。换句话说,指针、数组、函数等相关的复杂类型在编译器内部以与上述图表相同的顺序,用指针连接的简单类型结构体来表示。因此,可以说这些图表才是类型的真正面貌。
类型表示法
像上面的图表一样,使用图表可以更容易地理解类型,但每次为了理解类型都要画图有点麻烦。在这一节中,我们将考虑一种更紧凑的表示法,而不会损失图表的易读性。
除了包含函数类型外,图表中的所有框都将按顺序连接在一起,没有分支。因此,如果只有指针或数组等简单类型,那么通过将类型的名称从左到右直接写在一起,就可以用文字表示图表。
让我们考虑具体的表示法。我们将使用符号表示指针。另外,用[n]表示长度为n的数组,用int等内置类型的名称表示类型。这样一来,下面的图表可以用 * int表示。
由于从箭头的起点开始依次出现指针、指针、int,所以它可以表示为* * int。相反,如果给定* * int表示,也可以绘制出上面的图表。换句话说,这种文本表示法可以用简洁的文字来写出与图表相同的信息。
下面的图表可以用[20] * int表示。
对于函数,我们将采用“func(参数类型,…)返回类型”的写法。例如,下面的图表表示的类型是func(int, * int) * void。请读者确认这种表示法与图表是一致的。
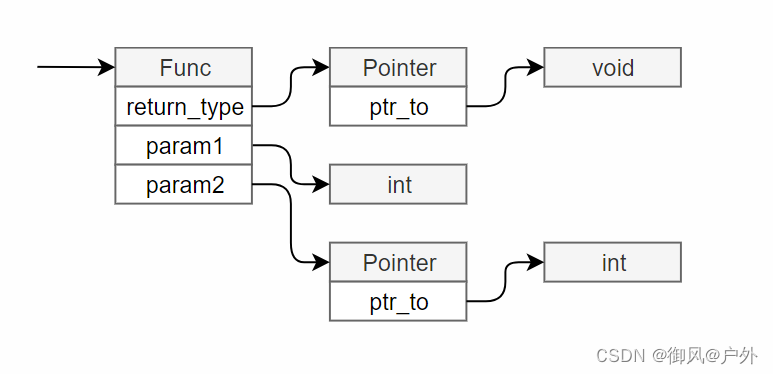
最后,下面的图表表示的类型是* func(int) * func() int。
到目前为止,我们介绍的表示法可能是最直接、最简单的文本表示方式了。实际上,编程语言Go的类型语法与我们这里介绍的语法完全相同。Go语言是由创建C语言的人参与开发的语言,但在Go语言中,借鉴了C语言的经验教训,类型语法进行了微妙的改进。
C的类型解读
在本节中,我们将结合学习的类型表示法和C的类型表示法,来学习如何解读C的类型。
C的类型可以分解为以下4部分:
- 基本类型
- 表示指针的星号
- 标识符或用括号括起来的嵌套类型
- 表示函数或数组的括号
例如,int x,其基本类型是int,没有表示指针的星号,标识符是x,也没有函数或数组的括号。unsigned int x(),其基本类型是unsigned int,有一个表示指针的星号,标识符是x,函数的括号是()。void ** (x)(),其基本类型是void,有两个表示指针的星号 **,嵌套类型是x,函数的括号是()。
非嵌套类型的解读
如果指针后面跟着的是一个普通标识符,那么解读类型相对比较简单。
如果没有函数或数组的括号,类型的表示和意义如下表所示。我们采用了与上面介绍的Go语言相同的表示法。
C的类型表示 意义
int x int
int *x * int
int **x * * int
如果有函数的括号,基本类型和表示指针的星号将表示返回值的类型。以下是示例:
C的类型表示 意义
int x() func() int
int *x() func() * int
int **x(int) func(int) * * int
当解析成没有函数的括号的类型时,即int x、int *x、int **x的类型,我们可以看到它们只是跟在func(…)的后面。
类似地,如果有数组的括号,它们的意义是“…的数组”。以下是示例:
C的类型表示 意义
int x[5] [5] int
int *x[5] [5] * int
int **x[4][5] [4] [5] * * int
例如,对于类型int *x[5],x的类型是长度为5的数组,数组的元素是指针,而指针指向的是int。就像函数一样,如果没有数组的括号,类型就会跟在[…]后面。
嵌套类型的解读
如果指针后面不是标识符而是括号,那么该括号表示嵌套的类型。当存在嵌套类型时,可以分别解析括号内外的类型,然后将它们组合在一起,得到整体的类型。
举个例子,让我们来解析声明int (*x)()。
如果将int (x)()整体看作一个标识符(我们随便给它取名为y),以此方式解释类型,我们会得到int y(),看起来就是这个样子。因此,外部的类型是func() int。而对于括号内的x这个类型,它表示了* ___ 这样的类型。由于括号内并未指明基本类型(如int等),所以类型并不完整,我们用 ___ 来表示缺失的基本部分。
通过分别解析括号内外的类型,我们得到了两个类型func() int和* ___。将外部的类型填入内部缺失的部分,就得到了完整的类型。在这种情况下,整体的类型是* func() int。也就是说,声明int (*x)()中,x是一个指针,指向的是一个函数,该函数的返回值是int。
再举一个例子,void (x[20])(int),如果将第一个括号视为标识符,我们可以得到void y(int),这样的结构。所以外部类型表示为func(int) void。而括号内的x[20]表示[20] * ___。将这两者组合起来,就得到了[20] * func(int) void。也就是说,x是一个长度为20的数组类型,数组的元素是指针,指向的是一个以int为参数的函数,该函数的返回类型是void。
通过这种方法,我们可以解读任何复杂的类型。我们以Unix的signal函数的类型作为一个极端的例子来尝试解读。signal函数是一个因为其类型看上去非常难以理解而出名的函数。以下是signal函数的声明:
void (*signal(int, void (*)(int)))(int);
即使是这样非常复杂的类型,通过分解和解读,我们也可以解读它。首先,将外部和内部的括号分开来看。如果将第一个括号视为标识符,我们可以得到func(int) void这样的类型。而内部的括号是signal(int, void ()(int)),表示了没有基本类型,有一个指针表示为*,一个标识符为signal,以及一个括号表示为一组函数参数,有两个参数。因此,粗略的类型为func(参数1, 参数2) * ___。我们来看一下参数的类型:
- 第一个参数是int,即基本类型为int。
- 第二个参数是void ()(int),表示没有基本类型,括号内部表示为 func(int) void,因为没有指明基本类型,所以缺失的部分用___表示。再加上*,所以这个参数的类型是* func(int) void。
将这些参数的类型填入func的参数部分,我们得到了func(int, * func(int) void) * ___。
最后,将内部的类型和外部的类型组合在一起,得到了最终的结果,即func(int, * func(int) void) * func(int) void。
因此,signal是一个函数,它接受两个参数:
- 一个int类型的参数。
- 一个指向以int为参数的void类型函数的指针。
signal的返回类型是指针,该指针指向一个以int为参数的void类型函数。
专栏:C类型语法的意图
C类型的语法设计是基于“就像使用时一样书写类型会更容易理解”的想法。根据这种设计原则,例如int x[20]这样的声明,意味着当你写 x[20]时,x的类型会被确定为int。这个问题可以看作是“在int foo = * x[20]中,x的类型是什么?”这样的问题。
如果将int *(*x[20])()这样的声明看作是为了确保int foo = *(x[20])()不会出现类型错误而确定x的类型,那么我们可以认为x首先必须是一个数组,然后数组的元素应该是一个可以通过解引用的指针,然后该指针应该是一个函数调用,所以指针的末尾应该是一个函数,返回的是一个指向函数的指针,该函数的返回类型应该是int。
C的类型语法虽然感觉有点荒谬,但从设计方针来看还是合理的。然而,最终结果是它变成了糟糕的设计,这是无法否认的。

结束语
本书的正文内容采用了Markdown格式编写。将Markdown转换为HTML使用了Pandoc,创建语法树图使用了Graphviz,创建其他图表使用了draw.io。
附录1:x86-64指令集速查表
本章节总结了在本书中编写的编译器中使用的x86-64指令集的功能。为了简洁表达,本章使用了以下缩写符号。
- src、dst:任意两个相同大小的寄存器
- r8、r16、r32、r64:分别表示8位、16位、32位、64位的寄存器
- imm:立即数
- reg1:reg2:表示两个寄存器reg1和reg2,作为高位和低位,组成一个无法容纳在128位寄存器中的大数的表示法
整数寄存器列表
总结了64位整数寄存器及其别名的名称。
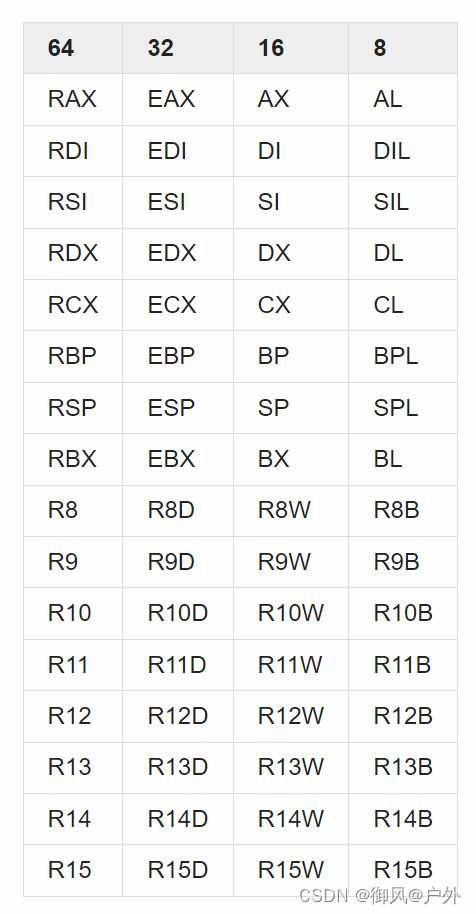
在ABI中的使用方法如下。对于不需要恢复原始值的寄存器,在其旁标记了✔。
寄存器 使用方式
RAX 返回值/参数数量 ✔
RDI 第1个参数 ✔
RSI 第2个参数 ✔
RDX 第3个参数 ✔
RCX 第4个参数 ✔
RBP 基址指针
RSP 栈指针
RBX (无特别用途)
R8 第5个参数 ✔
R9 第6个参数 ✔
R10 (无特别用途) ✔
R11 (无特别用途) ✔
R12 (无特别用途)
R13 (无特别用途)
R14 (无特别用途)
R15 (无特别用途)
在进行函数调用时,必须在调用call指令时保证RSP是16的倍数(即对齐到16)。不符合此条件的函数调用不符合ABI,并且可能导致部分函数崩溃。
内存访问
mov dst, [r64] 从r64指向的地址加载值到dst
mov [r64], src 将src的值存储到r64指向的地址
push r64/imm 减少RSP 8,并将r64/imm存储到RSP
pop r64 从RSP加载到r64,并增加RSP 8
函数调用
call label 将RIP推送到栈上并跳转到label
call r64 将RIP推送到栈上并跳转到r64的地址
ret 从栈中弹出地址并跳转到该地址
leave 相当于mov rsp, rbp,然后pop rbp
条件分支
cmp reg1, reg2/imm
je label 如果reg1 == reg2/imm,则跳转到label
cmp reg1, reg2/imm
jne label 如果reg1 != reg2/imm,则跳转到label
cmp reg1, reg2/imm
jl label 如果reg1 < reg2,则跳转到label(带符号比较)
cmp reg1, reg2/imm
jle label 如果reg1 <= reg2,则跳转到label(带符号比较)
条件赋值
cmp reg1, reg2/imm
sete al
movzb eax, al RAX = (reg1 == reg2) ? 1 : 0
cmp reg1, reg2/imm
setne al
movzb eax, al RAX = (reg1 != reg2) ? 1 : 0
cmp reg1, reg2/imm
setl al
movzb eax, al RAX = (reg1 > reg2) ? 1 : 0(带符号比较)
cmp reg1, reg2/imm
setle al
movzb eax, al RAX = (reg1 >= reg2) ? 1 : 0(带符号比较)
整数和逻辑运算
add dst, src/imm dst = dst + src/imm
sub dst, src/imm dst = dst - src/imm
mul src RDX:RAX = RAX * src
imul dst, src dst = dst * src
div r32 EAX = EDX:EAX / r32
EDX = EDX:EAX % r32
div r64 RAX = RDX:RAX / r64
RDX = RDX:RAX % r64
idiv r32/r64 带符号的div版本
cqo 将RAX符号扩展为128位,并存储在RDX:RAX中
and dst, src dst = src & dst
or dst, src dst = src | dst
xor dst, src dst = src ^ dst
neg dst dst = -dst
not dst dst = ~dst
shl dst, imm/CL 将dst左移imm或CL寄存器的值(如果用寄存器指定移位量,则只能使用CL)
shr dst, imm/CL 将dst逻辑右移imm或CL寄存器的值
移入的高位位将被清零
sar dst, imm/CL 将dst算术右移imm或CL寄存器的值
移入的高位位将与原始dst的符号位相同
lea dst, [src] 执行[src]的地址计算,但不进行内存访问,直接将地址计算结果存储到dst
movsb dst, r8 将r8符号扩展后存储到dst
movzb dst, r8 将r8零扩展后存储到dst
movsw dst, r16 将r16符号扩展后存储到dst
movzw dst, r16 将r16零扩展后存储到dst
附录2:使用Git进行版本管理
Git最初是为了Linux内核的版本管理而开发的。Linux内核是一个由数千名开发人员组成的庞大项目,因此,为了满足其复杂的工作流程,Git具有丰富的功能。虽然这些功能很方便,但在个人开发中,如果只有自己一个提交者,则不需要掌握Git的功能。要精通Git需要学习很多内容,但在这本书中,您需要记住的内容很少。为了初次使用Git的人,我准备了以下速查表。
git add 文件名
将新创建的文件添加到仓库中
git commit -A
将工作树中所有更改一起提交(打开编辑器以输入提交消息)
git reset --hard
撤消自上次提交以来对工作树的所有更改
git log -p
查看过去的提交
git push
将仓库推送到上游(如GitHub等)
使用Git的工作流程
对于首次使用版本管理系统的人来说,让我们稍微解释一下Git和版本管理系统的概念。
Git是一个管理带有文件更改历史记录的数据库的工具。这个数据库被称为仓库。从GitHub等地方克隆仓库后,仓库会被下载,然后从仓库中,默认的最新状态的目录树会展开到当前目录下。
从仓库中展开的目录树称为“工作树”。我希望大家能够编辑工作树中的源文件并进行编译,但工作树本身并不是仓库的一部分。工作树就像从zip文件中展开的文件一样,即使对其进行了更改,原始仓库也保持不变。
对工作树所做的更改将被组织成“提交”的单位,并一次性写回到仓库中。这样一来,数据库就会被更新,然后可以继续进行其他更改。使用Git时,您将以更改文件,然后提交的方式推进开发。
提交时的注意事项
请用日语编写提交消息。例如,“添加和/作为运算符,但不处理运算符的优先级”等一行消息即可。
请尽量将提交单元拆分得更小。例如,当您在更改代码时,可能会想要进行一些小的重构,但在这种情况下,请将重构作为单独的提交提交。不建议将两个或更多不同的功能合并到一个提交中。
不需要使用Git的高级功能。例如,您不应该需要使用分支。
请始终将功能添加的代码与用于测试该功能的代码一起提交。此外,请在提交之前先运行测试,确保现有功能未受损,并且新功能也正常运行。换句话说,您的目标是,无论检出仓库的哪个时间点,编译和测试都会通过。但是,如果不小心提交了无法通过测试的代码,请不要修改git的提交日志。只需在下一个提交中进行修复。
Git的内部结构
阅读Git文档时,您会发现其中有很多巧妙的功能,但是,如果您在心中建立Git数据保存方式的模型,您将更容易理解这些功能。因此,在这里,我将解释Git的内部结构。
Git是一种文件系统,作为用户程序实现。 Git数据库的结构与文件系统非常相似。但是,通常的文件系统使用文件名来访问文件,而Git使用文件的哈希值作为名称。
这种根据文件内容确定名称的机制称为内容寻址。在内容寻址文件系统中,如果名称相同,则内容相同。此外,具有不同内容的文件不能具有相同的名称(相同的哈希值)。这是通过使用加密安全的哈希函数来保证的。在这种文件系统中,不需要为文件单独命名,一旦确定了名称,文件的内容也就确定了。
提交在Git的内部也是文件。这个文件除了包含提交消息外,还包含属于该提交的文件的哈希值以及前一个提交的哈希值。
要从Git文件系统中获取文件,必须知道您想要的文件的哈希值。
如果不知道提交文件的哈希值,则无法获取提交文件,这就有点像鸡和蛋的问题,但实际上,仓库中除了文件系统外,还包括了提交文件的哈希值及其名称的目录,因此可以使用它来找到提交。例如,仓库中包含了关于“master”这个名称的信息(默认展开到工作树的历史记录),提交的哈希值是da39a3ee5e…。通过这些信息,Git可以展开master所指向的文件到工作树。
在内部,提交的过程是这样的:将更改的文件添加到Git内部文件系统中,然后添加包含这些文件的哈希值和前一个提交的哈希值的提交文件,最后通过使用该提交文件的哈希值更新目录。
举例来说,要想使 master 分支的最后一次提交消失(虽然不建议这样做),只需查看 master 分支当前指向的提交文件,获取上一个提交的哈希值,然后使用该哈希值来覆盖 master 分支即可。另外,“分支”本身只是指有两个以上的提交引用,并且这两个提交都在目录中的情况,这只是一个简单的说明而已。
在这种 content-addressable 的版本管理系统中,也存在着安全性的优点。一个提交的名称(提交文件的哈希值)包含了其所属的所有文件的哈希值以及前一个提交文件的哈希值。前一个提交文件又包含了更早前一个提交文件的哈希值,因此最终在计算最新提交的哈希值时,所有提交的哈希值都被包含在内。因此,即使想要在不改变哈希值的情况下悄悄修改提交的内容或历史记录也是基本不可能的。这是一个有趣的特性。
当学习 Git 功能时,请始终牢记这种 content-addressable 的文件系统。你会发现很多事情都变得更加清晰易懂。
附录3:使用Docker创建开发环境
在本附录中,我们将介绍如何使用Docker在macOS上构建和运行Linux应用程序。
Docker是提供Linux虚拟环境的软件。与完整功能的虚拟机不同,Docker直接在虚拟环境中提供Linux系统调用。由于这种区别,与完整的虚拟化相比,Docker启动更快,整体上更轻量。Docker经常用于将应用程序部署到云计算机上。
如果要使用Docker在macOS上开发Linux应用程序,可以考虑以下两种系统配置:
- 将Docker内外的环境视为完全不同的环境,并在开发Linux应用程序时,在Docker内执行所有操作的配置。
- 对于不依赖于平台的常规开发工作,如源代码编辑和git操作,可以在Docker外执行,只在Docker内执行构建和测试命令的配置。
前者的配置非常简单,因为它与在Mac上准备Linux机器进行开发的方式相同,但是需要设置Linux开发环境,包括编辑器等,因此设置稍微复杂一些。另一方面,后者的配置不需要在Docker中“生活”,因此不需要准备环境设置,但是在Docker内外切换有些麻烦。
上述两种配置都可以选择,但为了避免说明Linux环境设置步骤,本书选择了后者的配置。因此,我们将明确在Linux环境中运行的命令,并在Docker内执行它们。
设置步骤
要设置使用Docker的Linux开发环境,请首先下载并安装Docker Desktop for Mac。然后,执行以下命令可以创建名为compilerbook的Docker映像。
$ docker build -t compilerbook https://www.sigbus.info/compilerbook/Dockerfile
“Docker映像”或“映像”是包含构成Linux环境所需的所有文件和设置的内容。实际启动的映像称为“Docker容器”或简称“容器”(类似于执行文件和进程的关系)。
要创建容器并在其中运行命令,请使用docker run命令的映像名称和命令作为参数。以下是在compilerbook容器中执行ls /命令的示例。
$ docker run --rm compilerbook ls /
bin
root
dev
etc
...
容器可以持续在后台运行,但由于我们只需要交互式使用,所以通过给出–rm选项,使命令结束后容器也会终止。因此,每次输入该命令时,都会创建并销毁容器。
使用容器进行构建
要在容器中运行make并编译源文件,需要使容器能够看到在Docker外部编辑的源文件。
使用docker run,通过-v :选项,可以将外部环境的路径作为在Docker内可见。此外,还可以使用-w选项指定要执行命令时的当前目录。使用这些选项,可以将源文件的目录设置为当前目录,然后在其中执行make。
假设源文件位于主目录的名为9cc的子目录中。要在容器中执行make test以运行,请执行以下命令。
$ docker run --rm -v $HOME/9cc:/9cc -w /9cc compilerbook make test
请确保按照上述方式执行构建和测试命令。
如果要启动交互式地使用容器中的shell,请使用-it选项运行docker run。
$ docker run --rm -it -v $HOME/9cc:/9cc compilerbook
在容器中添加新应用程序
尽管上述步骤已安装了一系列开发工具,但有时可能需要安装其他应用程序。下面将介绍如何执行此操作。
Docker容器是临时存在的。即使在容器内安装应用程序并从其中的shell退出,这些更改也不会反映到原始映像中。 Docker通过这种方式确保每次启动应用程序时都从相同的新状态开始,但是当您希望对映像进行更改时,此性质可能会成为问题。
要将更改保存到映像中,请显式运行docker commit命令。
例如,假设您想要安装curl命令。在这种情况下,首先创建容器如下。
$ docker run -it compilerbook
请注意,我们没有传递–rm选项。然后,从容器的shell中使用apt安装curl,然后使用exit命令退出容器。
$ sudo apt update
$ sudo apt install -y curl
$ exit
由于我们在docker run中没有使用–rm选项,因此即使从容器的shell退出,容器也会保持悬挂状态。使用docker container ls -a命令,您将看到悬挂的容器,如下所示。
$ docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a377e570d1da compilerbook "/bin/bash" 7 seconds ago Exited (0) 5 seconds ago pedantic_noyce
应该能够看到已经执行了名为 compilerbook 的图像的容器,其 ID 是 a377e570d1da。使用 docker commit 命令可以将容器保存为一个新的镜像。
$ docker commit a377e570d1da compilerbook
通过上述步骤,可以将更改保存到镜像中。
暂停的容器或旧的镜像等,即使它们仍然存在,只会消耗少量磁盘空间,通常不会造成太大问题。但如果担心的话,可以通过执行 docker system prune 命令来进行清理。
参考资料
- Compiler Explorer:方便的在线编译器
- N1570 [PDF]:C11语言规范的最终草稿(与官方规范书内容相同)
- N1570:C11语言规范的HTML版本
- X4J11/86-196 [PDF]:C预处理器宏展开算法的解释
- Rationale for American National Standard for Information Systems - Programming Language - C:标准化委员会决定C89语言规范的背景解释
- 8cc:作者编写的C编译器
- 9cc:作者编写的C编译器
- 从零开始开发C编译器(日志)
- An Incremental Approach to Compiler Construction [PDF]:关于增量式编译器构建的论文
- Crafting Interpreters:Robert Nystrom先生的在线书籍
- A Retargetable C Compiler:设计与实现。David R. Hanson和Christopher W. Fraser:有关简单C编译器lcc实现的解释书