CDP和Chrome
CDP和WebDriver Protocol
WebDriver和 Chrome DevTools Protocol(CDP) 是用于自动化浏览器的两个主要协议,大多数的浏览器自动化工具都是基于上述其中之一来实现的。可以通过这两种形式来和浏览器交互,通过代码来控制浏览器,完成浏览器的自动化行为(包括网页加载,爬虫,截图,导出pdf等)。
WebDriver Protocol
官网地址:链接
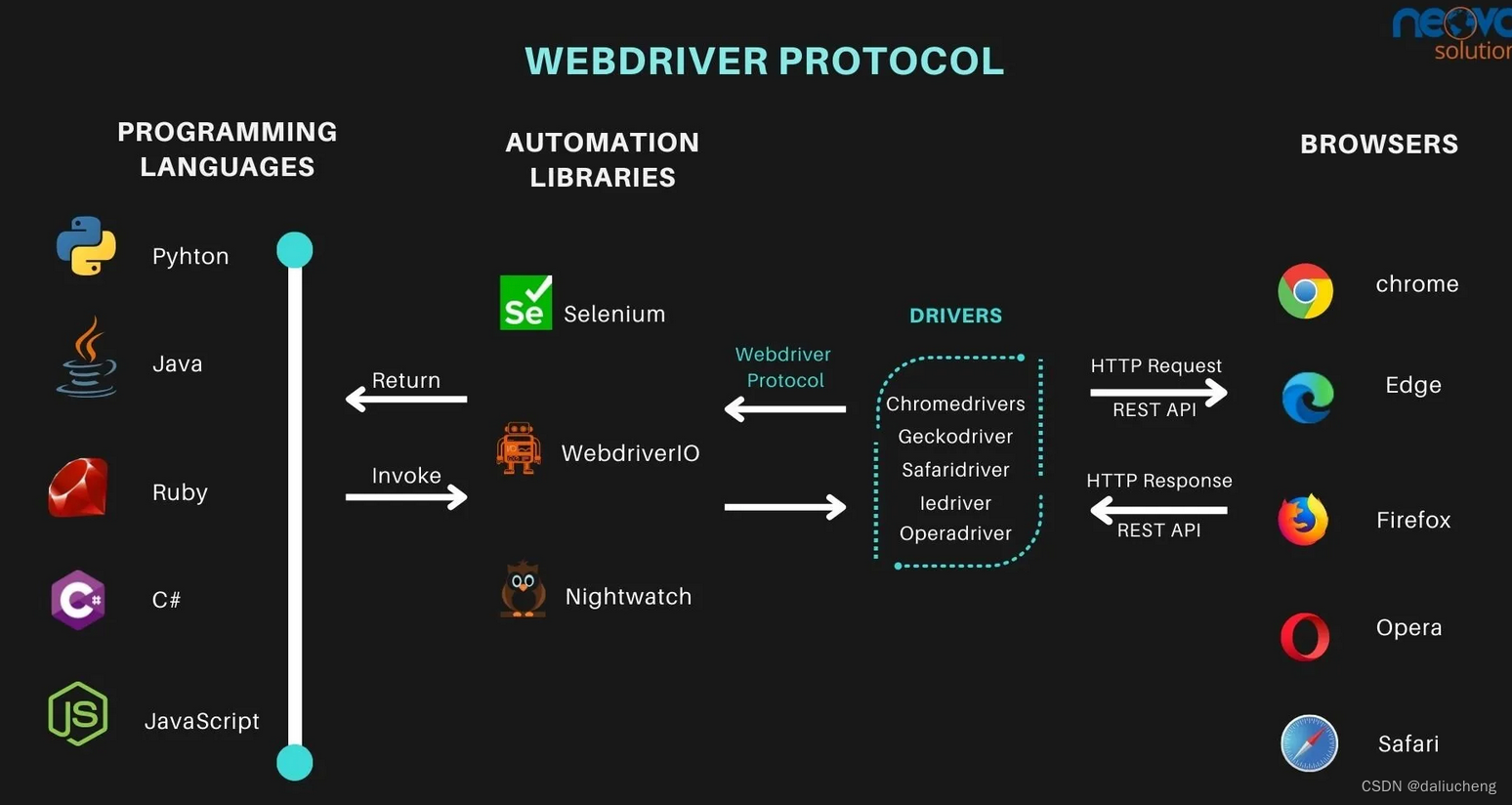
WebDriver 是一个用于控制浏览器的远程控制接口,由 Selenium HQ 开发,后来由 W3C 标准化。它提供了一个平台和语言中立的接口,支持几乎所有主流浏览器,如 Chrome、 Firefox、 Safari、 Edge、 Opera 等。
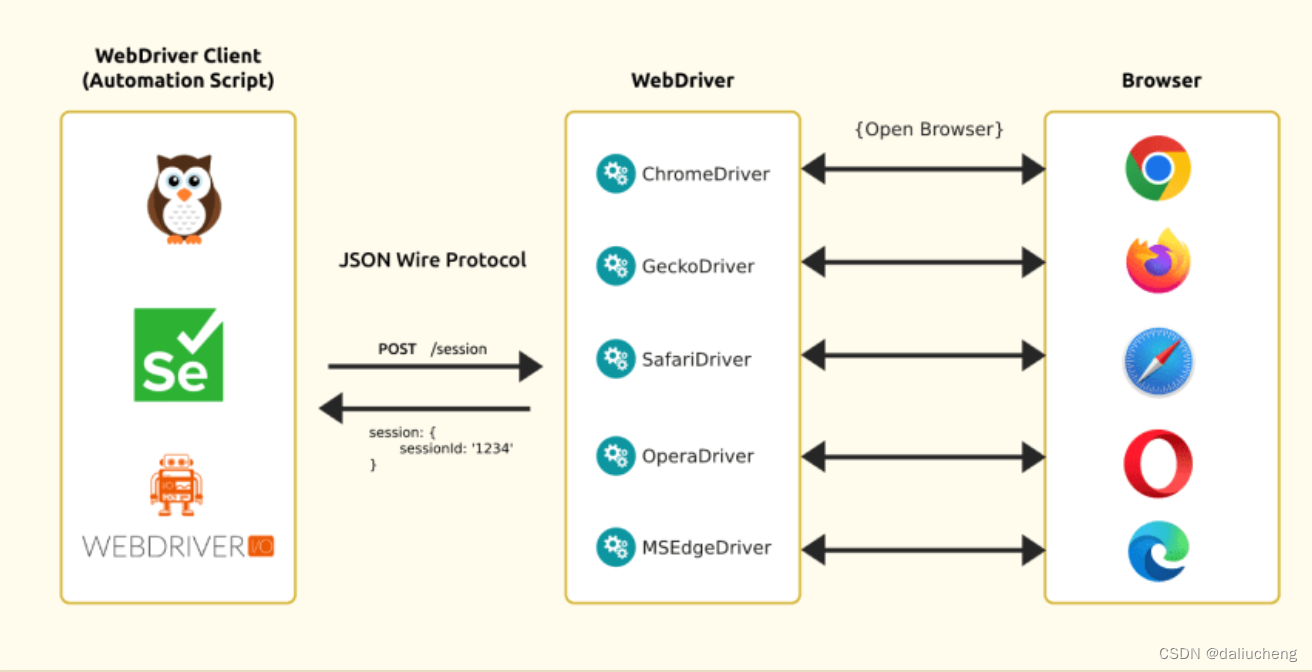
它和浏览器的通信是通过 JSON Wire 协议完成的,提供了RESTful的web服务,这个服务端就被称为服务端(也被称为webdriver),例如chromeDriver、geckoDriver等。
有服务端就有客户端,客户端可以选择任何语言,客户端和服务端交互,服务端和浏览器交互,从而操作浏览器。常见的客户端就是selenium,nightwatch,webdriverio
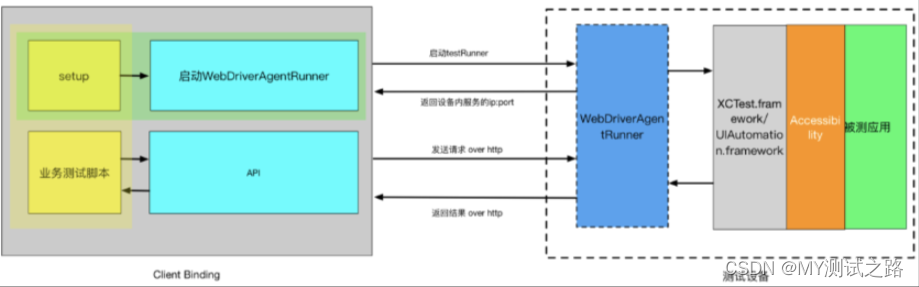
加上我们的自己写的自动化测试代码之后,交互流程如下:
Chrome DevTools Protocol
官网地址:链接
ChromeDevTools Protocol (CDP)是一个基于 Chromium 的浏览器的调试协议,如 Chrome、 Edge、 Opera 等。通过它可以直接和浏览器交互。控制浏览器的行为。
客户端和浏览器之间没有类似于WebDriver Protocol的服务端(webdriver),而是客户端通过WebSocket直接和浏览器连
类似网络驱动服务器(浏览器驱动程序)的中间人。相反,浏览器是由客户端使用 CDP 直接控制的。与浏览器的通信是通过套接字连接完成的,因此也支持双向通信。客户端通过WebSocket发送命令给浏览器,浏览器执行并返回响应。
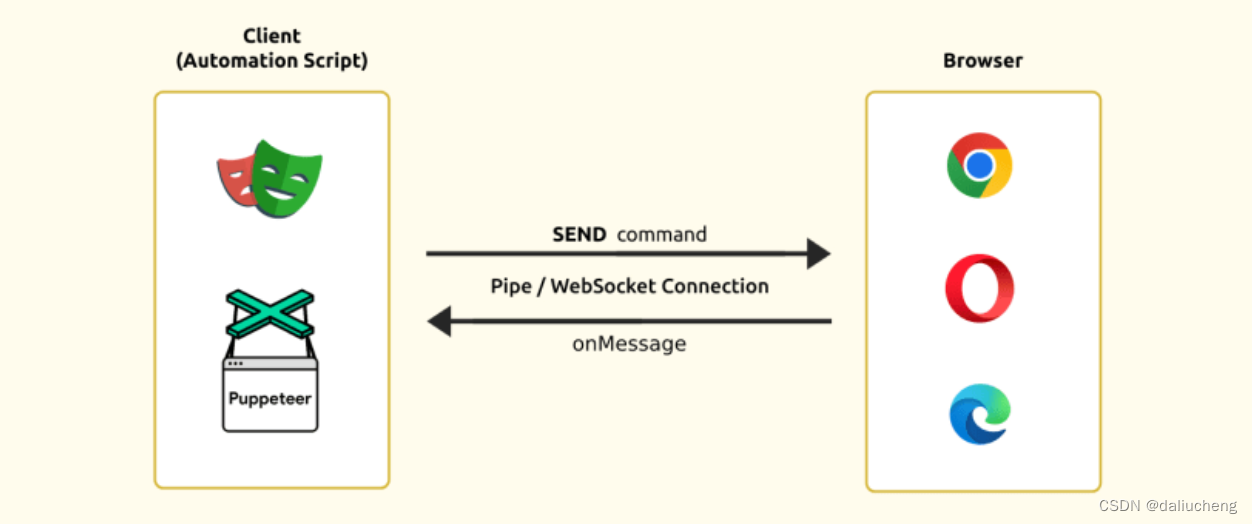
两个相当流行的工具是Puppeteer和Playwright。它们不依赖于webdriver,而是通过 Chrome DevTools Protocol (CDP)直接与浏览器通话。从而更加灵活稳定的控制浏览器。
区别
从代码层面来看,使用的代码接近底层,接近浏览器,代码就会变得更加的稳定和强大,但对于跨浏览器的支持会变得更少。另一方面,代码和浏览器的之间的抽象程度越高,支持的浏览器就越多,但代码会变得不稳定并且功能受限。
对比上面两种
-
WebDriver Protocol
支持的浏览器多,但不是很稳定,并且功能不强大。
-
Chrome DevTools Protocol
支持的浏览器少(只是相对WebDriver来说,Chrome能支持就能用),功能强大,稳定。
| Webdriver Protocol | Chrome DevTools Protocol |
|---|---|
| Developed by: W3C | Developed by: Chrome Developer Tools |
| 需要webdriver | 不需要webdriver |
| 相对较慢并且不是很稳定 | 速度快,较稳定 |
| 支持的浏览器多 | 支持部分浏览器 |
| 无法通过提供的api来访问浏览器中网络相关的信息 | 可以通过api来访问网络相关的信息 |
| 它的实现有:Selenium WebDriver 3, WebdriverIO, Nightwatch | 它的实现有:Playwright, Puppeteer, Selenium Webdriver 4, Cypress v7 |
不同的WebDriver有不同的实现方式,chromeDriver内部是通过DevTools protoco来控制浏览器的。
如何选择
如果跨浏览器很重要,就选webDriver,否则选择CDP
puppeteer
链接:官网,github,github-examples
Puppeteer 是 Chrome 开发团队在 2017 年发布的一个 Node.js 包,是它提供了一个高级 API,通过 DevTools 协议控制 Chrome/Chromium。
为什么选择它?
两个理由
- github中star数多
- Chrome开发团队
可以做什么?
简单来说,浏览器能做的,它都能做
- 截图和生成PDF
- 爬取 SPA 或 SSR 网站
- UI 自动化测试
- …
版本说明
从v1.7.0 版本以来,每次发布都会发布两个软件包:
-
puppeteer
它会自动下载一个最新版本的 Chrome 用于测试(macOS 约 170MB,Linux 约 282MB,Windows 约 280MB)以及一个 chrome-headless-shell 二进制文件(从 Puppeteer v21.6.0 开始),这个二进制文件保证可以与 Puppeteer 配合正常工作。默认情况下,浏览器会下载到 $HOME/.cache/puppeteer 文件夹中(从 Puppeteer v19.0.0 开始)。
通过puppeteer-core 控制它下载的浏览器
-
puppeteer-core
puppeteer-core 是一个库,用于帮助驱动任何支持 DevTools 协议的内容。
它不会下载浏览器,它提供了封装好的API和浏览器交互。
如果自己已经下载了浏览器,就可以使用它,但是必须在调用
puppeteer.launch的时候显式的指定executablePath(浏览器的执行位置)一般来说我会使用这个
代码
建议看这篇文章 结合项目来谈谈 Puppeteer 在结合 github-examples的例子。
注意点
-
在部署的时候,建议使用容器化,Chrome本身是内存大户,如果遇到内存飙升,代码是不太好发现这种情况的,不能及时kill掉。
-
在加载网页的时候不建议每次都关闭和开启一个新的。
Chrome的启动和关系是比较耗时的,每次启动会慢150ms到300ms
建议重复使用同一个Chrome。
-
Chrome使用一段时间之后,要关掉重启。
Chrome在我们自己的电脑中有的时候,页面都会崩溃,浏览器也会崩溃。在服务器这种情况下,肯定也会出现,建议在内存中设置调用阈值,比如加载了100个网页,重启一次。这样可降低崩溃的概率。
-
容器化部署之后,建议一个容器中只启动一个Chrome。
这样会让代码简单并且出现问题好排查。这就要求Chrome在代码中是单例
-
在整个Chrome做操作期间,对Chrome崩溃的情况做处理
在业务代码期间,建议使用try catch 来捕获异常,对于非业务异常,需要关闭掉Chrome。防止出现多个Chrome。
-
Chrome在关闭的时候出现异常,也需要处理
在调用
close()api来关闭Chrome的时候,可能会报错(可能Chrome在这个时候被操作系统kill掉,会出现孤儿进程)。建议:在这个时候直接通过shell脚本来强行kill掉
#!/bin/bash pids=$(ps -ef | grep "[c]hrome" | grep -v 'kill_chrome_processes.sh' |awk '{print $2}') for pid in $pids; do echo "Terminating PID $pid" kill $pid done echo "All chrome processes have been terminated."孤儿进程:
父进程启动了子进程,子进程在没有退出的情况下,父进程退出了。此时子进程会被init进程接管。
-
尽量关闭掉无用的功能,让他越简单越好。
比如:
-no-sandbox,--disable-extensions,--disable-gpu,--disable_scrollbars -
共享内存
Chrome 默认使用 /dev/shm 共享内存,但是 docker 默认/dev/shm 只有64MB,显然是不够使用的,提供两种方式来解决:
- 启动 docker 时添加参数 --shm-size=1gb 来增大 /dev/shm 共享内存,但是 swarm 目前不支持 shm-size 参数
- 启动 Chrome 添加参数 - disable-dev-shm-usage,禁止使用 /dev/shm 共享内存
参考文档
- https://www.neovasolutions.com/2022/05/19/browser-automation-tools-protocols-webdriver-vs-cdp/
- https://dev.to/jankaritech/different-approaches-protocols-to-automate-the-browser-39f1
- https://stackoverflow.com/questions/50939116/what-is-the-difference-between-webdriver-and-devtool-protocol
- https://zhuanlan.zhihu.com/p/76237595
关于博客这件事,我是把它当做我的笔记,里面有很多的内容反映了我思考的过程,因为思维有限,不免有些内容有出入,如果有问题,欢迎指出。一同探讨。谢谢。