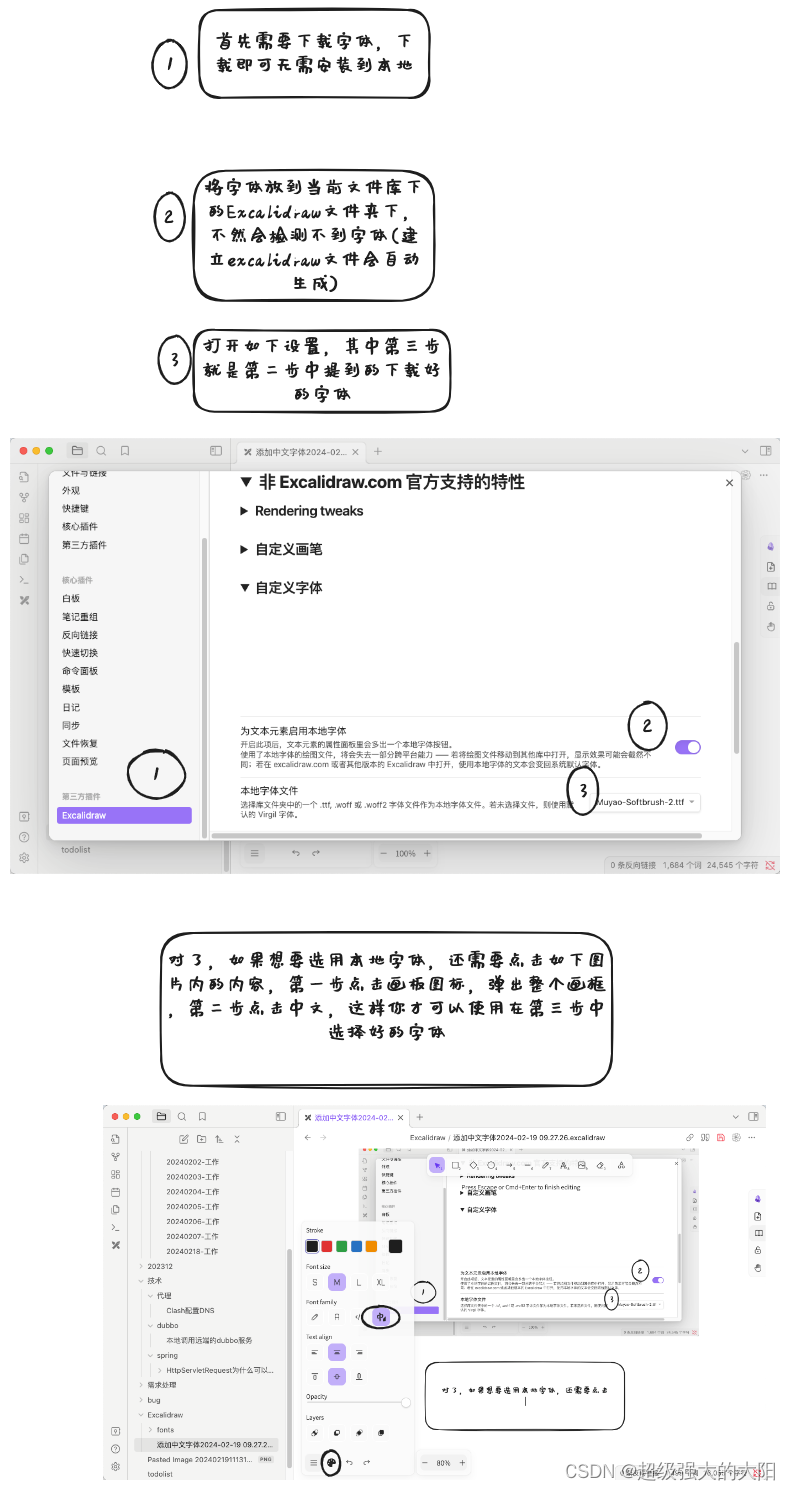
1.背景
最近在使用官网的教程训练chatGLM3,但是出现了“RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn”错误,查阅了官方的文档,目前这个问题还没什么解决方案
但是其中有人回复说:是注释掉503行的model.gradient_checkpointing_enable() 。个人验证确实是可以成功的,那么问题来了model.gradient_checkpointing_enable() 到底是干什么?为什么有它不行.
2.model.gradient_checkpointing_enable()的作用
这个函数调用启用了模型的梯度检查点。梯度检查点是一种优化技术,可用于减少训练时的内存消耗。通常,在反向传播期间,模型的中间激活值需要被保留以
计算梯度。启用梯度检查点后,系统只需在需要时计算和保留一部分中间激活值,从而减少内存需求。这对于处理大型模型或限制内存的环境中的训练任务非常有用。
这个函数的位置是在
/mnt/workspace/miniconda3/envs/chatglm3/lib/python3.10/site-packages/transformers/modeling_utils.py(2102)gradient_checkpointing_enable()
当然不同环境和版本会有差异,但是大体上不会根本上出入,关于其中的实现,大家可以去查看.
说到底这个函数只是为了节约内存的作用,所以去掉这个,对于上述问题解决是可行,但是具体为什么加了这个之后,chatGLM3微调会出现问题,这个会在另一篇文章进行深究, 在参阅资料发现, 还有很多节约显存的方法,接下来进行一一介绍:
3、Transformers的性能优化方法
算力依然是ai时代最重要的武器, 对于没有线买算力的伙伴而言,算力更是重中之重,节约使用GPU,人人有责, 因此引发学习到很多其他节约显存的方法,记录一下,方便自己和他人查阅学习.
(1)梯度累积(Gradient Accumulation)
(2)冻结(Freezing)
(3)自动混合精度(Automatic Mixed Precision)
(4)8位优化器(8-bit Optimizers)
(5)快速分词器(Fast Tokenizers)
(6)动态填充(Dynamic Padding)
(7)均匀动态填充(Uniform Dynamic Padding)
其中(1)~(4)包括上述说的gradient_checkpointing_enable()方法是适用于任何网络上, (5)~(7)一般是适用于自然语言的上的.
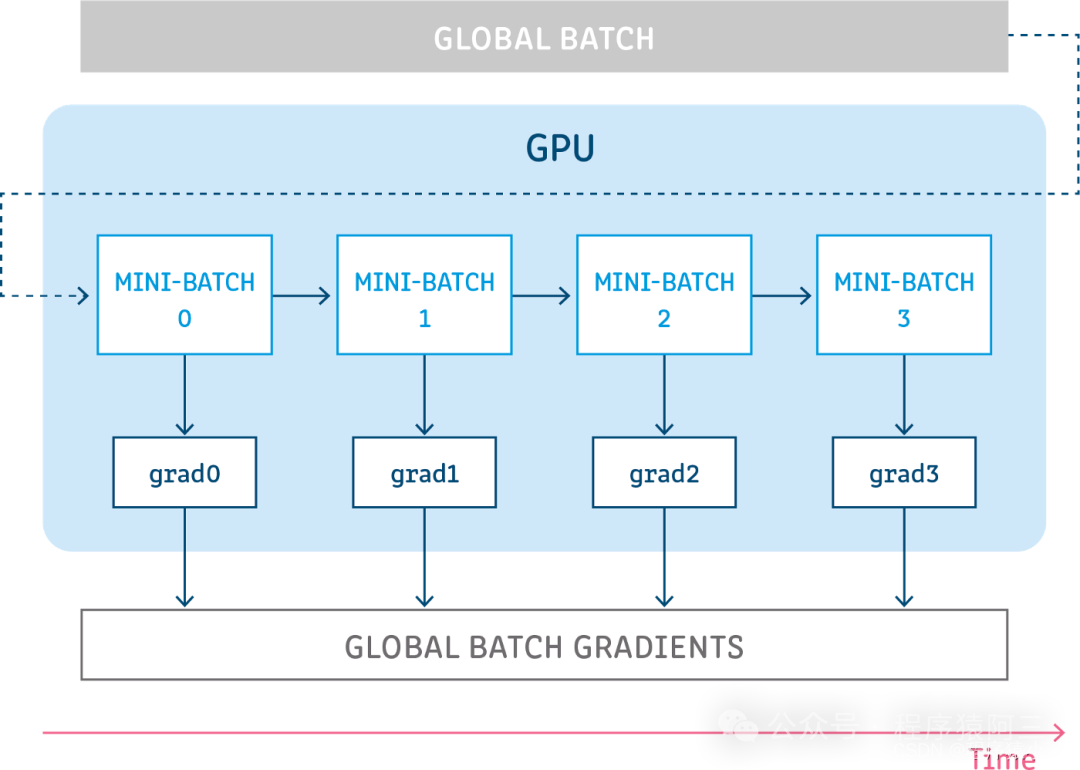
(1)梯度累积
我们都知道,最好是所有的样本的损失一起反向传播是最精确的,但是由于显存的限制,无法做到,所有样本计算和存储,又因为小批量,容易导致训练结果过分敏感样本,所以就有了中庸之道, 不大不小.
(2)冻结
冻结是一种非常有效的方法,通过取消计算模型某些层中的梯度计算(如embedding层,bert的前几层),可以大大加快训练速度并且降低了显存占用,而且几乎不会损失模型的性能, 特别是某种优化算法(如SGD、AdamW或RMSprop)执行优化步骤时,网络的底层的梯度就都很小,因此参数几乎保持不变,这也被称为梯度消失,因此,与其花费大量的时间和算力来计算底层这些“无用”梯度,并对此类梯度很小的参数进行优化,不如直接冻结它们,直接不计算梯度也不进行优化。
PyTorch为关闭梯度计算提供了一个舒适的API,可以通过torch.Tensor的属性requires_ grad设置。
def freeze(module):
"""
Freezes module's parameters.
"""
for parameter in module.parameters():
parameter.requires_grad = False
(3)自动混合精度
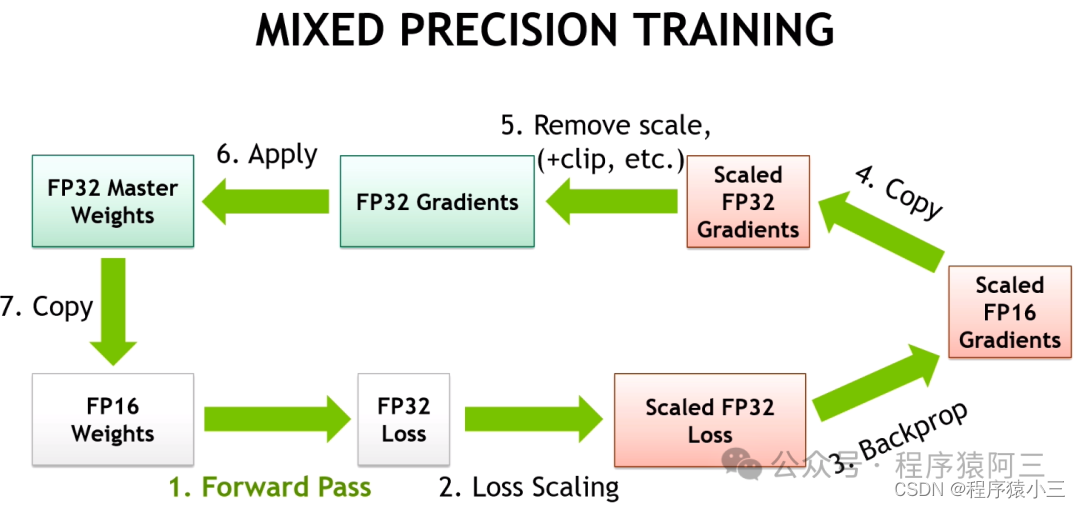
关键思想是使用较低的精度将模型的梯度和参数保留在内存中,即不使用全精度(float32),而是使用半精度(例如float16)将张量保存在内存中。然而,当以较低精度计算梯度时,某些值可能太小,以至于被视为零,这种现象被称为“溢出”。为了防止“溢出”,原始论文的作者提出了一种梯度缩放方法。
PyTorch提供了一个包:torch.cuda.amp,具有使用自动混合精度所需的功能(从降低精度到梯度缩放),自动混合精度作为上下文管理器实现,因此可以随时随地插入到训练和推理脚本中。
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for step, batch in enumerate(loader, 1):
# prepare inputs and targets for the model and loss function respectively.
# forward pass with `autocast` context manager
with autocast(enabled=True):
outputs = model(inputs)
# computing loss
loss = loss_fn(outputs, targets)
# scale gradint and perform backward pass
scaler.scale(loss).backward()
# before gradient clipping the optimizer parameters must be unscaled.
scaler.unscale_(optimizer)
# perform optimization step
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
scaler.step(optimizer)
(4)8位优化器
思想类似于自动混合精度(模型的参数和梯度使用较低的精度保存),但8-bit Optimizers还让优化器的状态使用低精度保存,作者为8位优化器提供了一个高级库,称为bitsandbytes。这种方式在大模型微调是非常常见的.
(5)快速分词器
HuggingFace Transformers提供两种类型的分词器:基本分词器和快速分词器。它们之间的主要区别在于,fast是在rust编写的,因为python在循环中非常慢,fast可以让我们在tokenize时获得额外的加速。下图是tokenize工作的原理示意,Tokenizer类型可以通过更改transformers.AutoTokenizerfrom_pretrained将use_fast属性设为True。
from transformers import AutoTokenizer
# initializing Base version of Tokenizer
model_path = "microsoft/deberta-v3-base"
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
print(f"Base version Tokenizer:\n\n{tokenizer}", end="\n"*3)
# initializing Fast version of Tokenizer
fast_tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True)
print(f"Fast version Tokenizer:\n\n{fast_tokenizer}")
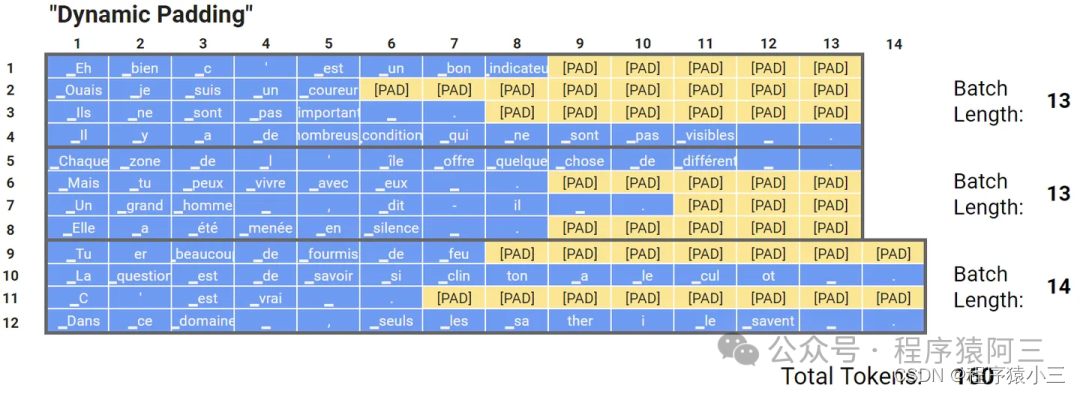
(6)动态填充
是为了解决固定长度填充的问题:
固定长度填充的过程: 批中的每个输入必须具有固定大小,所有批量数据的尺寸都一样。固定尺寸通常是根据数据集中的长度分布、特征数量和其他因素来选择的。在NLP任务中,输入大小称为文本长度,或者最大长度(max length)。然而,不同的文本具有不同的长度,为了处理这种情况,研究人员提出了填充标记和截断。当最大长度小于输入文本的长度时,会使用截断,因此会删除一些标记。当输入文本的长度小于最大长度时,会将填充标记,比如[PAD],添加到输入文本的末尾.
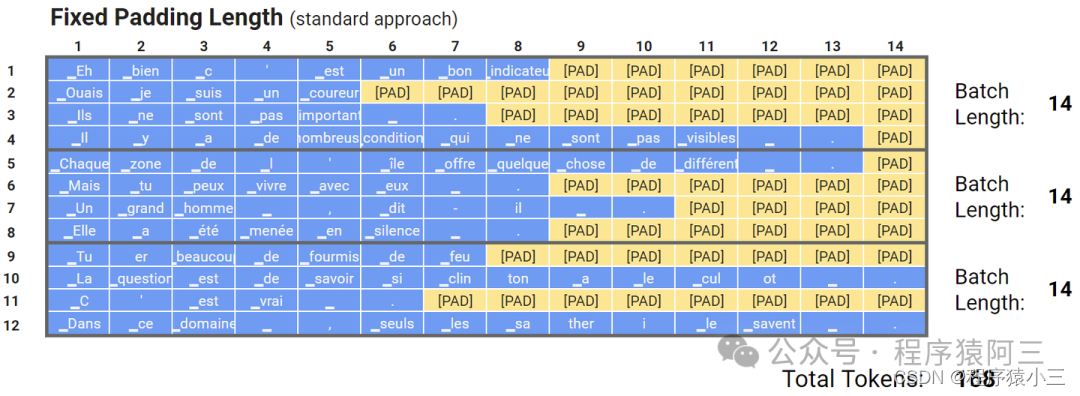
缺点也是非常明显:比如在输入文本相对于选定的最大长度非常短的情况下,效率就很低,需要更多的额外内存.
将批量的输入填充到这一批量的最大输入长度,如下图所示,这种方法可以将训练速度提高35%甚至50%,当然这种方法加速的效果取决于批量的大小以及文本长度的分布,批量越小,加速效果越明显,文本长度分布越不均,加速效果也越好。
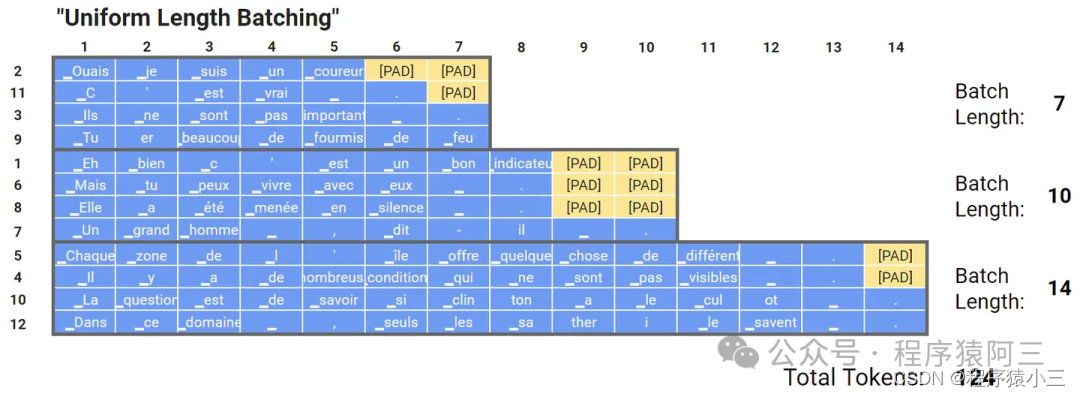
(7)均匀动态填充
分batch时,先按文本的长度对文本进行排序,这样同一个batch里面的文本长度就都差不多。这种方法非常有效,在训练或推理期间的计算量都比动态填充要来得少,这种方式比较适用于推理阶段,因为在训练的时候,更需要shuffle训练数据集
参考文章
1、Transformers的性能优化方法