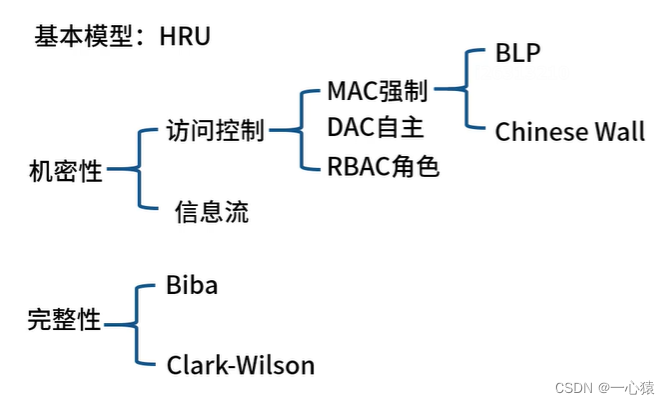
1、简介
当下最先进的深度学习架构之一,Transformer被广泛应用于自然语言处理领域。它不单替代了以前流行的循环神经网络(recurrent neural network, RNN)和长短期记忆(long short-term memory, LSTM)网络,并且以它为基础衍生出了诸如BERT、GPT-3、T5等知名架构。
本文将带领你深入了解Transformer的实现细节及工作原理。本章首先介绍Transformer的基本概念,然后通过一个文本翻译实例进一步讲解Transformer如何将编码器−解码器架构用于语言翻译任务。我们将通过探讨编码器(encoder)的组成部分了解它的工作原理。之后,我们将深入了解解码器(decoder)的组成部分。最后,我们将整合编码器和解码器,进而理解Transformer的整体工作原理。
2、Transformer简介
循环神经网络和长短期记忆网络已经广泛应用于时序任务,比如文本预测、机器翻译、文章生成等。然而,它们面临的一大问题就是如何记录长期依赖。
为了解决这个问题,一个名为Transformer的新架构应运而生。从那以后,Transformer被应用到多个自然语言处理方向,到目前为止还未有新的架构能够将其替代。可以说,它的出现是自然语言处理领域的突破,并为新的革命性架构(BERT、GPT-3、T5等)打下了理论基础。
Transformer完全依赖于注意力机制,并摒弃了循环。它使用的是一种特殊的注意力机制,称为自注意力(self-attention)。我们将在后面介绍具体细节。
让我们通过一个文本翻译实例来了解Transformer是如何工作的。Transformer由编码器和解码器两部分组成。首先,向编码器输入一句话(原句),让其学习这句话的特征[插图],再将特征作为输入传输给解码器。最后,此特征会通过解码器生成输出句(目标句)。
假设我们需要将一个句子从英文翻译为法文。如图所示,首先,我们需要将这个英文句子(原句)输进编码器。编码器将提取英文句子的特征并提供给解码器。最后,解码器通过特征完成法文句子(目标句)的翻译。
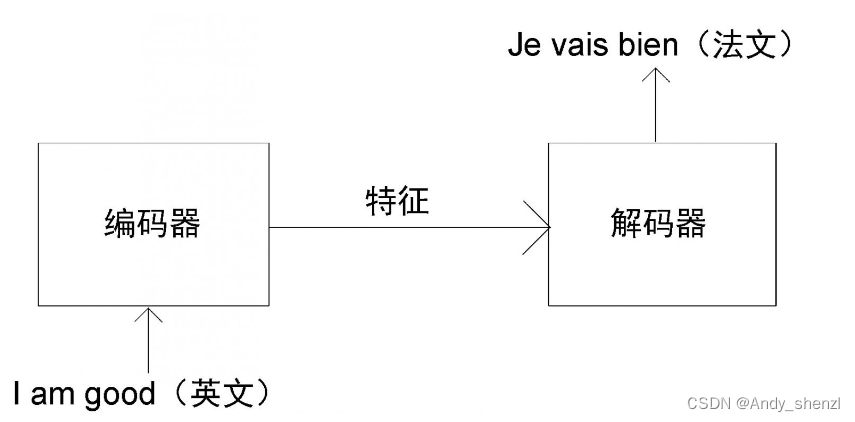
此方法看起来很简单,但是如何实现呢?Transformer中的编码器和解码器是如何将英文(原句)转换为法文(目标句)的呢?编码器和解码器的内部又是怎样工作的呢?接下来,我们将按照数据处理的顺序,依次讲解编码器和解码器.
2.1 理解编码器
Transformer中的编码器不止一个,而是由一组N 个编码器串联而成。一个编码器的输出作为下一个编码器的输入。在图中有N 个编码器,每一个编码器都从下方接收数据,再输出给上方。以此类推,原句中的特征会由最后一个编码器输出。编码器模块的主要功能就是提取原句中的特征。
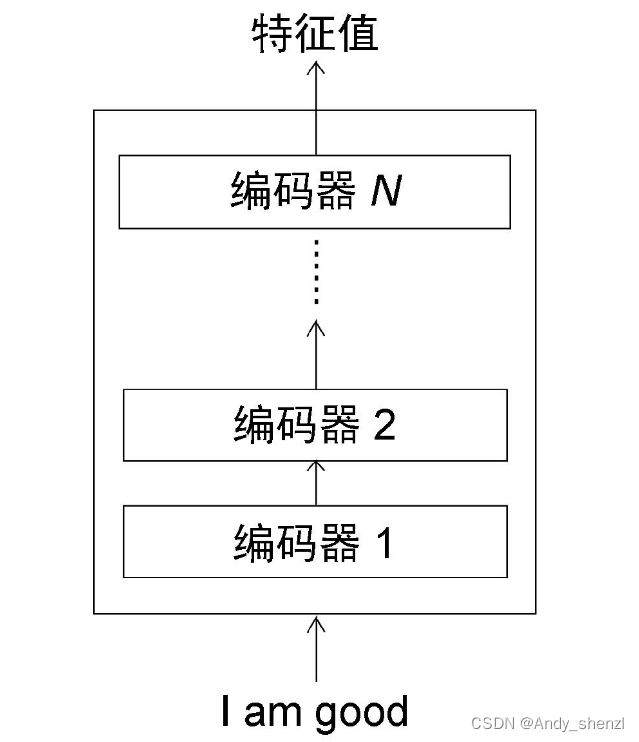
需要注意的是,在Transformer原论文“Attention Is All You Need”中,作者使用了N = 6,也就是说,一共有6个编码器叠加在一起。当然,我们可以尝试使用不同的N 值。这里为了方便理解,我们使用N=2,如图所示。
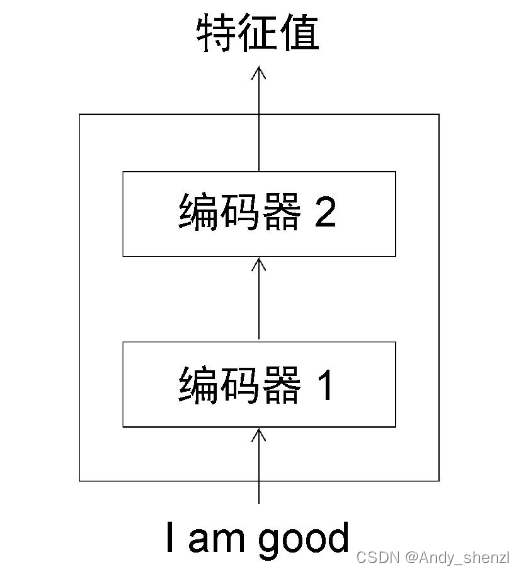
编码器到底是如何工作的呢?它又是如何提取出原句(输入句)的特征的呢?要进一步理解,我们可以将编码器再次分解。下图展示了编码器的组成部分。
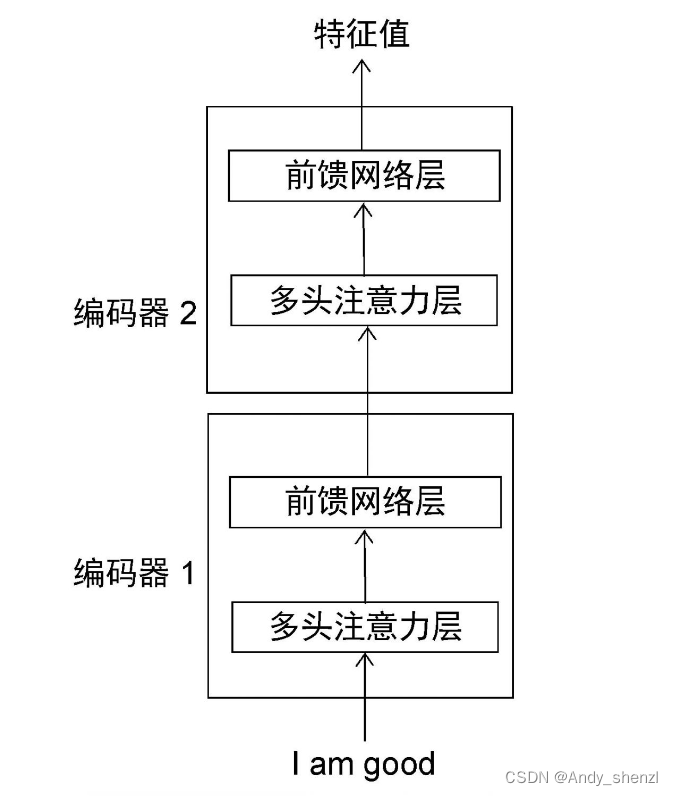
从上图中可知,每一个编码器的构造都是相同的,并且包含两个部分:
- 多头注意力层
- 前馈网络层
现在我们来学习这两部分是如何工作的。要了解多头注意力机制的工作原理,我们首先需要理解什么是自注意力机制。
2.2 自注意力机制
让我们通过一个例子来快速理解自注意力机制。请看下面的例句:
A dog ate the food because it was hungry(一只狗吃了食物,因为它很饿)
例句中的代词it(它)可以指代dog(狗)或者food(食物)。当读这段文字的时候,我们自然而然地认为it指代的是dog,而不是food。但是当计算机模型在面对这两种选择时该如何决定呢?这时,自注意力机制有助于解决这个问题。
还是以上句为例,我们的模型首先需要计算出单词A的特征值,其次计算dog的特征值,然后计算ate的特征值,以此类推。当计算每个词的特征值时,模型都需要遍历每个词与句子中其他词的关系。模型可以通过词与词之间的关系来更好地理解当前词的意思。
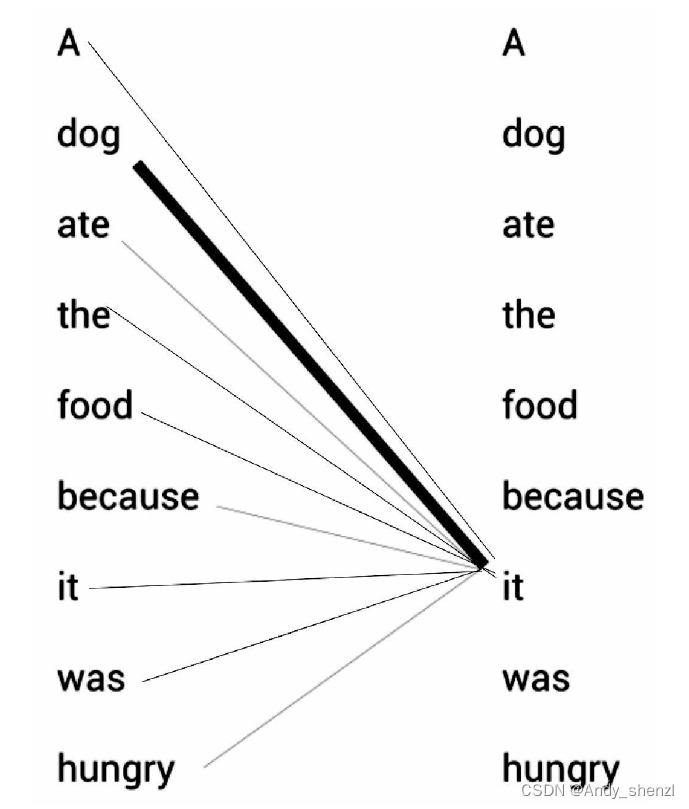
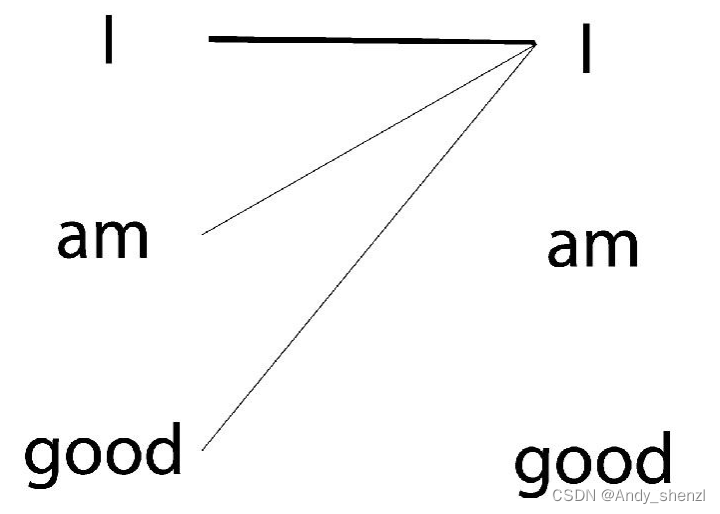
比如,当计算it的特征值时,模型会将it与句子中的其他词一一关联,以便更好地理解它的意思。如下图所示,it的特征值由它本身与句子中其他词的关系计算所得。通过关系连线,模型可以明确知道原句中it所指代的是dog而不是food,这是因为it与dog的关系更紧密,关系连线相较于其他词也更粗。
我们已经初步了解了什么是自注意力机制,下面我们将关注它具体是如何实现的。
为简单起见,我们假设输入句(原句)为I am good(我很好)。首先,我们将每个词转化为其对应的词嵌入向量。需要注意的是,嵌入只是词的特征向量,这个特征向量也是需要通过训练获得的。
单词I的词嵌入向量可以用x1来表示,相应地,am为x2,good为x3,即:
- 单词I的词嵌入向量 x 1 = [ 1.76 , 2.22 , … … , 6.66 ] x_1 = [1.76, 2.22 ,……, 6.66] x1=[1.76,2.22,……,6.66];
- 单词am的词嵌入向量 x 2 = [ 7.77 , 0.631 , … … , 5.35 ] x_2 = [7.77, 0.631 ,……, 5.35] x2=[7.77,0.631,……,5.35];
- 单词good的词嵌入向量 x 3 = [ 11.44 , 10.10 , … … , 3.33 ] x_3 = [11.44, 10.10 ,……, 3.33] x3=[11.44,10.10,……,3.33]。
这样一来,原句I am good就可以用一个矩阵[插图](输入矩阵或嵌入矩阵)来表示,如下图所示。

图1-6中的值为随意设定,只是为了让我们更好地理解其背后的数学原理。
通过输入矩阵X,我们可以看出,矩阵的第一行表示单词I的词嵌入向量。以此类推,第二行对应单词am的词嵌入向量,第三行对应单词good的词嵌入向量。所以矩阵X的维度为[句子的长度×词嵌入向量维度]。原句的长度为3,假设词嵌入向量维度为512,那么输入矩阵的维度就是[3×512]。
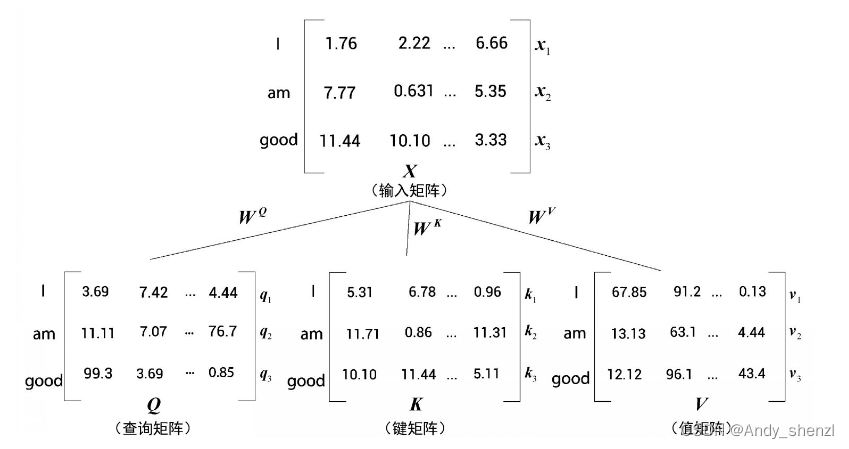
现在通过矩阵X,我们再创建三个新的矩阵:查询(query)矩阵Q、键(key)矩阵K,以及值(value)矩阵V。等一下,怎么又多了三个矩阵?为何需要创建它们?接下来,我们将继续了解在自注意力机制中如何使用这三个矩阵。
为了创建查询矩阵、键矩阵和值矩阵,我们需要先创建另外三个权重矩阵,分别为 W Q 、 W K 、 W V W^Q 、W^K、W^V WQ、WK、WV。用矩阵X分别乘以矩阵 W Q 、 W K 、 W V W^Q 、W^K、W^V WQ、WK、WV,就可以依次创建出查询矩阵Q、键矩阵K和值矩阵V。
值得注意的是,权重矩阵 W Q 、 W K 、 W V W^Q 、W^K、W^V WQ、WK、WV的初始值完全是随机的,但最优值则需要通过训练获得。我们取得的权值越优,通过计算所得的查询矩阵、键矩阵和值矩阵也会越精确。
如图所示,将输入矩阵X分别乘以 W Q 、 W K 、 W V W^Q 、W^K、W^V WQ、WK、WV后,我们就可以得出对应的查询矩阵、键矩阵和值矩阵。
根据上图,我们可以总结出以下三点。
- 三个矩阵的第一行 q 1 , k 1 , v 1 q_1,k_1,v_1 q1,k1,v1分别代表单词I的查询向量、键向量和值向量。
- 三个矩阵的第二行 q 2 , k 2 , v 2 q_2,k_2,v_2 q2,k2,v2分别代表单词am的查询向量、键向量和值向量。
- 三个矩阵的第三行 q 3 , k 3 , v 3 q_3,k_3,v_3 q3,k3,v3分别代表单词good的查询向量、键向量和值向量。
因为每个向量的维度均为64,所以对应的矩阵维度为[句子长度×64]。因为我们的句子长度为3,所以代入后可得维度为[3×64]。至此,我们还是不明白为什么要计算这些值。该如何使用查询矩阵、键矩阵和值矩阵呢?它们怎样才能用于自注意力模型呢?这些问题将在下面进行解答。
2.3 理解自注意力机制
目前,我们学习了如何计算查询矩阵Q、键矩阵K和值矩阵V,并知道它们是基于输入矩阵X计算而来的。现在,让我们学习查询矩阵、键矩阵和值矩阵如何应用于自注意力机制。
要计算一个词的特征值,自注意力机制会使该词与给定句子中的所有词联系起来。还是以I am good这句话为例。为了计算单词I的特征值,我们将单词I与句子中的所有单词一一关联,如图所示。
了解一个词与句子中所有词的相关程度有助于更精确地计算特征值。现在,让我们学习自注意力机制如何利用查询矩阵、键矩阵和值矩阵将一个词与句子中的所有词联系起来。自注意力机制包括4个步骤,我们来逐一学习。
第1步
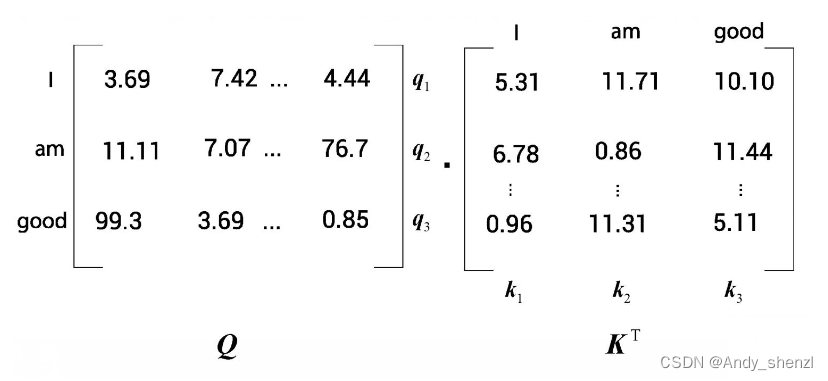
自注意力机制首先要计算查询矩阵Q与键矩阵V的点积,两个矩阵如图所示。
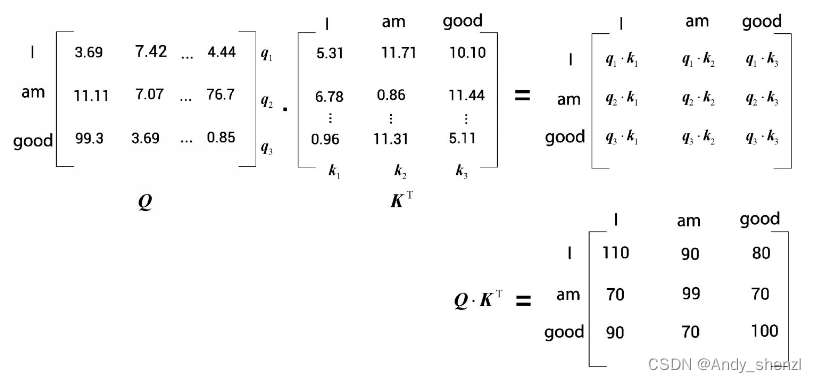
下图显示了查询矩阵Q与键矩阵
K
T
K^T
KT的点积结果
但为何需要计算查询矩阵与键矩阵的点积呢?
Q
⋅
K
T
Q · K^T
Q⋅KT到底是什么意思?下面,我们将通过细看
Q
⋅
K
T
Q · K^T
Q⋅KT的结果来理解以上问题。
首先,来看[插图]矩阵的第一行,如下图所示。可以看到,这一行计算的是查询向量 q 1 q_1 q1(I)与所有的键向量 k 1 k_1 k1(I)、 k 2 k_2 k2(am)和 k 3 ( g o o d ) k_3(good) k3(good)的点积。通过计算两个向量的点积可以知道它们之间的相似度。
因此,通过计算查询向量(
q
1
q_1
q1)和键向量(
k
1
,
k
2
,
k
3
k_1, k_2, k_3
k1,k2,k3)的点积,可以了解单词I与句子中的所有单词的相似度。我们了解到,I这个词与自己的关系比与am和good这两个词的关系更紧密,因为点积值
q
1
⋅
k
1
q_1·k_1
q1⋅k1大于
q
1
⋅
k
2
q_1·k_2
q1⋅k2和
q
1
⋅
k
3
q_1·k_3
q1⋅k3。
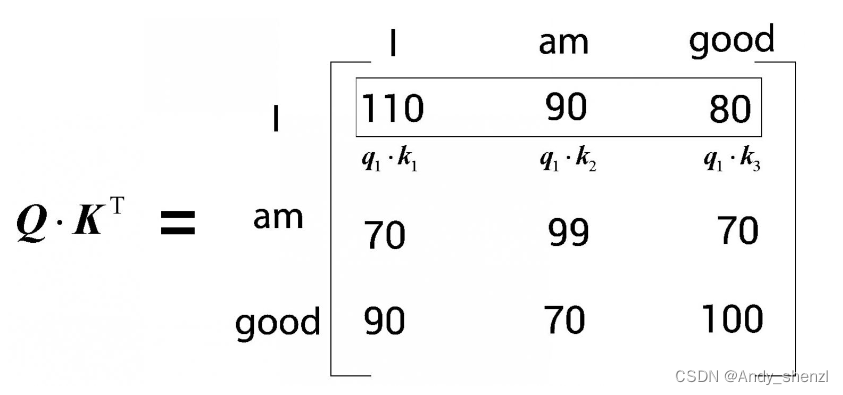
注意,这里使用的数值是任意选择的,只是为了让我们更好地理解背后的数学原理。
现在来看 Q ⋅ K T Q · K^T Q⋅KT矩阵的第二行,如下图所示。现在需要计算查询向量 q 2 q_2 q2(am)与所有的键向量 k 1 k_1 k1(I)、 k 2 k_2 k2(am)和 k 3 ( g o o d ) k_3(good) k3(good)的点积。这样一来,我们就可以知道am与句中所有词的相似度。通过查看 Q ⋅ K T Q · K^T Q⋅KT矩阵的第二行可以知道,单词am与自己的关系最为密切,因为点积值最大。
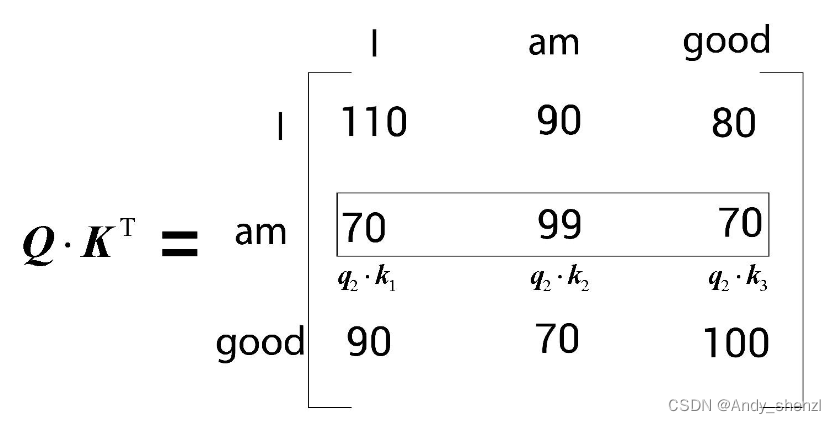
同理,来看
Q
⋅
K
T
Q · K^T
Q⋅KT矩阵的第三行。如下图所示,计算查询向量
q
3
q_3
q3(good)与所有键向量
k
1
k_1
k1(I)、
k
2
k_2
k2(am)和
k
3
(
g
o
o
d
)
k_3(good)
k3(good)的点积。
从结果可知,good与自己的关系更密切,因为点积值
q
3
⋅
k
3
q_3·k_3
q3⋅k3大于
q
3
⋅
k
1
q_3·k_1
q3⋅k1和
q
3
⋅
k
2
q_3·k_2
q3⋅k2。
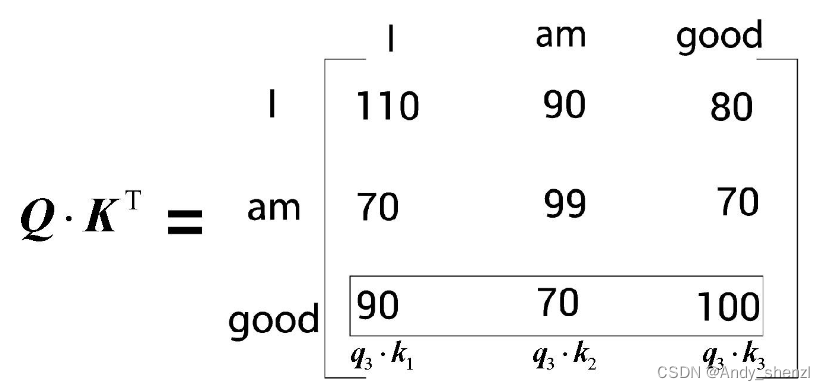
综上所述,计算查询矩阵Q与键矩阵
K
V
K^V
KV的点积,从而得到相似度分数。这有助于我们了解句子中每个词与所有其他词的相似度。
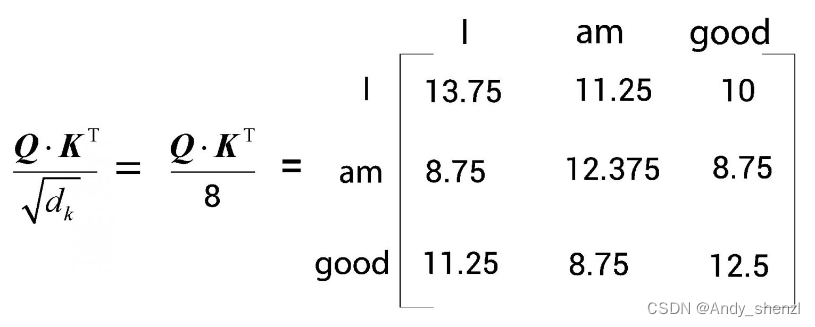
第2步
自注意力机制的第2步是将 Q ⋅ K T Q · K^T Q⋅KT矩阵除以键向量维度的平方根。这样做的目的主要是获得稳定的梯度。
我们用 d k d_k dk来表示键向量维度。然后,将 Q ⋅ K T Q · K^T Q⋅KT除以 d k \sqrt{d_k} dk。在本例中,键向量维度是64。取64的平方根,我们得到8。将第1步中算出的 Q ⋅ K T Q · K^T Q⋅KT除以8,如下图所示。
第3步
目前所得的相似度分数尚未被归一化,我们需要使用softmax函数对其进行归一化处理。如下图所示,应用softmax函数将使数值分布在0到1的范围内,且每一行的所有数之和等于1。
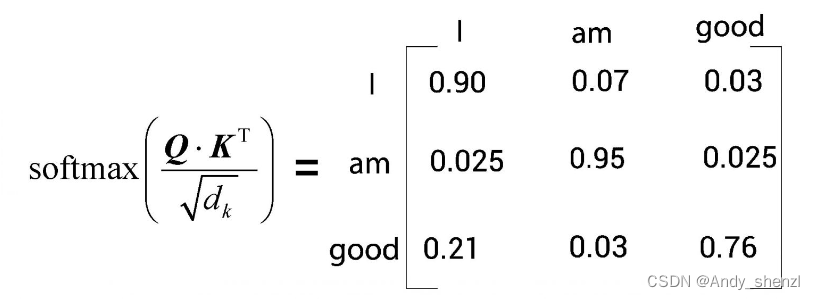
我们将上图中的矩阵称为分数矩阵。通过这些分数,我们可以了解句子中的每个词与所有词的相关程度。以图中的分数矩阵的第一行为例,它告诉我们,I这个词与它本身的相关程度是90%,与am这个词的相关程度是7%,与good这个词的相关程度是3%。
第4步
至此,我们计算了查询矩阵与键矩阵的点积,得到了分数,然后用softmax函数将分数归一化。自注意力机制的最后一步是计算注意力矩阵Z。注意力矩阵包含句子中每个单词的注意力值。它可以通过将分数矩阵softmax (
Q
⋅
K
T
/
d
k
Q · K^T/\sqrt{d_k}
Q⋅KT/dk)乘以值矩阵V得出,如图所示。
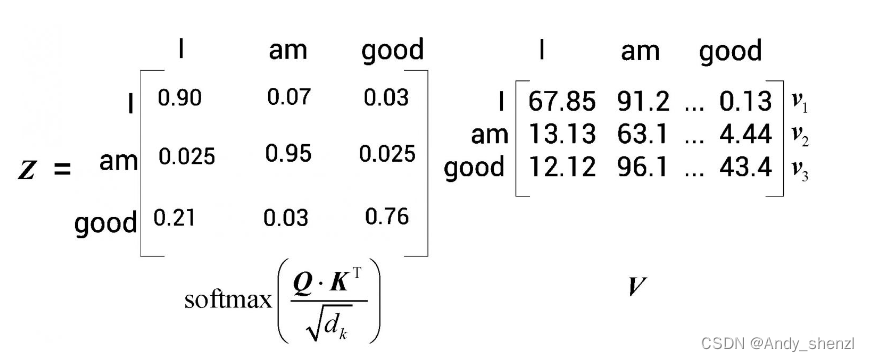
假设计算结果如下图所示。
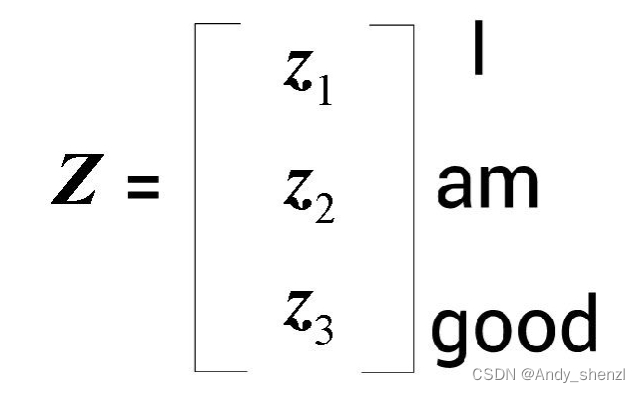 注意力矩阵Z就是值向量与分数加权之后求和所得到的结果。让我们逐行理解这个计算过程。首先,第一行
z
1
z_1
z1对应
注意力矩阵Z就是值向量与分数加权之后求和所得到的结果。让我们逐行理解这个计算过程。首先,第一行
z
1
z_1
z1对应I这个词的自注意力值,它通过下图所示的方法计算所得。

从上图中可以看出,单词I的自注意力值
z
1
z_1
z1是分数加权的值向量之和。所以,
z
1
z_1
z1的值将包含90%的值向量
v
1
v_1
v1(I)、7%的值向量
v
2
v_2
v2(am),以及3%的值向量
v
3
v_3
v3(good)。
这有什么用呢?为了回答这个问题,让我们回过头去看之前的例句:A dog ate the food because it was hungry(一只狗吃了食物,因为它很饿)。在这里,it这个词表示dog。我们将按照前面的步骤来计算it这个词的自注意力值。假设计算过程如图所示。

从图中可以看出,it这个词的自注意力值包含100%的值向量
v
2
v_2
v2(dog)。这有助于模型理解it这个词实际上指的是dog而不是food。这也再次说明,通过自注意力机制,我们可以了解一个词与句子中所有词的相关程度。回到I am good这个例子,单词am的自注意力值
v
2
v_2
v2也是分数加权的值向量之和,如图所示。

从上图中可以看出,
z
2
z_2
z2的值包含2.5%的值向量
v
1
v_1
v1(I)、95%的值向量
v
2
v_2
v2(am),以及2.5%的值向量
v
3
v_3
v3(good)。
同样,单词good的自注意力值
z
3
z_3
z3也是分数加权的值向量之和,如图所示。

可见,
z
3
z_3
z3的值包含21%的值向量
v
1
v_1
v1(I)、3%的值向量
v
2
v_2
v2(am),以及76%的值向量
v
3
v_3
v3(good)。
综上所述,注意力矩阵Z由句子中所有单词的自注意力值组成,它的计算公式如下。
Z = s o f t m a x ( Q ⋅ K T d k ) V Z = softmax(\frac{Q·K^T}{\sqrt{d_k}})V Z=softmax(dkQ⋅KT)V
现将自注意力机制的计算步骤总结如下:
(1) 计算查询矩阵与键矩阵的点积
Q
⋅
K
T
Q·K^T
Q⋅KT,求得相似值,称为分数;
(2) 将[插图]除以键向量维度的平方根
d
k
\sqrt{d_k}
dk;
(3) 用softmax函数对分数进行归一化处理,得到分数矩阵
s
o
f
t
m
a
x
(
Q
⋅
K
T
d
k
)
softmax(\frac{Q·K^T}{\sqrt{d_k}})
softmax(dkQ⋅KT);
(4) 通过将分数矩阵与值矩阵
V
V
V相乘,计算出注意力矩阵
Z
Z
Z。
自注意力机制的计算流程图如图所示。
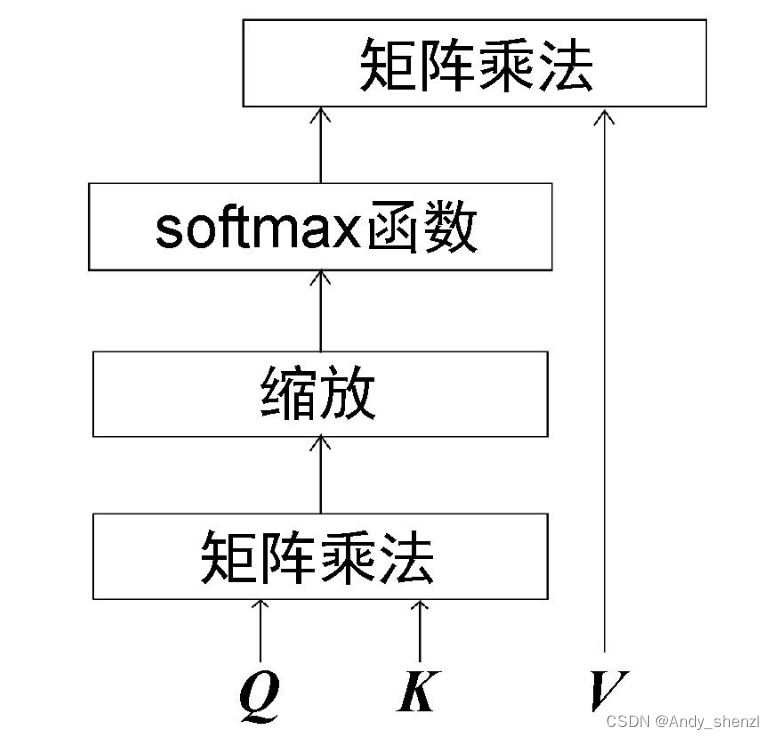
自注意力机制也被称为缩放点积注意力机制,这是因为其计算过程是先求查询矩阵与键矩阵的点积,再用
d
k
\sqrt{d_k}
dk对结果进行缩放。
我们已经了解了自注意力机制的工作原理。在下节中,我们将了解多头注意力层。