在前面章节中我们了解了增强语法和属性语法,特别是看到了这两种语法的结合体,本节我们看看如何使用前面我们说过的自顶向下自动机来实现这两种语法结合体的解析,这里使用的方法也是成熟编译器常用的一种语法解析算法。
首先我们先给出上一节给出的混合语法:
stmt -> epsilon | {t=newName()} expr_(t) SEMI stmt
expr_(t) -> term_(t) expr_prime_(t)
expr_prime_(t) -> PLUS {t2 = newName()} term_(t2) {print(%s+=%s\n",t,t2) freenName(t2)} expr_prime_(t) | epsilon
term_(t) -> factor term_prime
term_prime_(t) -> MUL {t2 = newName()} factor_(t2) {print("%s*=%s\n",t,t2) freeName(t2)} term_prime_(t)
factor_(t) -> NUM {print("%s=%s\n",t, lexeme)} | LEFT_PAREN expr_(t) RIGHT_PAREN
在前面我们谈到 PDA 算法时说过,我们需要使用一个堆栈来存储状态机的当前状态,堆栈顶部的节点对应状态机当前所在节点,拿到当前节点和当前的输入后,我们到一个行动表里查询应该采取的行动。对应当前例子而言,状态机的节点就对应到语法中的终结符,非终结符,和行动(例如{t2=newName()}这种),对于当前语法而言,行动表对应的行动就是将对应表达式右边的符号逆向压入堆栈。
举个例子,假设当前堆栈顶部的元素是非终结符 stmt,如果此时输入对应的标签是 EOF,那么我们就采用 stmt -> epsilon 这个规则,于是就将 stmt 出栈,然后将 epsilon 入栈,于是此时堆栈顶部的节点就是 epsilon,对应该状态点,行动表对应的动作就是什么动作都不做。如果顶部元素为 stmt,同时当前输入不为空,那么对应的操作就是将语法右边的符号压入堆栈,此时我们要从最右边的符号开始压入,根据表达式 stmt -> {t=newName()} expr_(t) SEMI stmt,我们首先将 stmt 压入,然后压入 SEMI,接着是 expr(注意这里只压入符号,对于符号附带的属性我们需要另外处理),接着是{t=newName()}
如果当前堆栈顶部的元素是一个终结符,例如 NUM,那么行动表对应的动作就是检测当前输入的元素对应标签是否为 NUM,如果不是那么报告语法错误,识别过程结束,如果是,那么将当前终结符 NUM 弹出堆栈,然后根据当前堆栈顶部元素来采取相应动作。
现在还有一个问题在于如何处理语法符号所附带的属性。我们看下面这个语法:
expr_prime_(t) -> PLUS {t2 = newName()} term_(t2) {print(%s+=%s\n",t,t2)}
这里右边的符号 term 自己附带了一个属性,而这个属性由{t2=newName()}这个动作创建,同时{print(“%s+=%s\n”,t,t2)} 使用了两个属性,一个属性 t 来自与箭头左边 expr_prime 对应的属性,而 t2 对应 term 符号附带的属性,现在问题是当我们要执行这个操作时,我们如何获取这两个属性呢?
解决办法是再创建一个新的堆栈叫属性堆栈,堆栈中的元素对应如下的数据结构或者结构体:
type Attribute struct {
left string
right string}
我们每次将一个符号压入符号堆栈时,我们就创建上面的一个结构体实例,将 left, right 初始化为空字符串,然后将该实例也压入属性堆栈。其中 left 对应的就是箭头左边符号附带的属性,right 对应的是当前符号自身附带的属性,如果符号自己没有附带属性,那么 right 就保留为空字符串。
下面我们先给出解析算法的步骤说明,你看了可能会感觉懵逼,不用担心,只要我们使用代码来实现你就会立马明白:
算法数据结构:
1, 一个解析堆栈,堆栈元素为整形数值,用来代表语法解析中的符号
2, 一个属性堆栈,堆栈元素为结构体 Attribute
3, 一个字符串类型的变量 lhs,
初始化:
将语法解析的初始符号压入解析堆栈(对应上面例子就是 stmt)
初始化一个 Attribute 结构体实例,将其两个字段 left,right 初始化为空字符串然后压入属性堆栈。
执行如下步骤:
0:如果当前堆栈为空,解析结束
1,如果当前堆栈顶部元素是一个动作节点(例如 {t2 = newName()}),那么执行其对应操作,然后将其弹出栈顶。
2,如果当前栈顶元素是非终结符则执行如下步骤:
a,将变量 lhs 的值设置为当前属性堆栈顶部元素结构体中的 right 字段
b,将元素弹出堆栈,然后将它在解析式右边的符号,从最右边开始依次压入堆栈。每压入一个元素今日堆栈,那么就创建一个 Attribute 结构体实例,将其left,right 两个字段都初始化为 lhs,然后压入属性堆栈
c,跳转到步骤 0 重新执行。
3,如果堆栈顶部的元素是终结符,判断当前输入对应的标签跟终结符相匹配,如果不匹配则报错退出,如果匹配则将符号弹出堆栈,然后跳转到步骤 0
由于我们在属性堆栈压入了多个 Attribute 结构体实例,在语法解析过程中我们就需要引用属性堆栈中某个位置的元素,因此我们使用特定的符号来表示对特定属性对象的引用,我们使用符号"$$“表示引用当前属性堆栈栈顶元素的 left 字段,”$0"表示引用距离栈顶元素偏移 0 个位置的元素的 right 字段,“$1"表示引用距离栈顶偏移 1 个位置元素的 right 字段,”$2"表示引用距离栈顶偏移 2 个位置的元素的 right 字段,我们看个具体例子:
expr_prime -> PLUS {$1=$2=newName()} term {printf("%s+=%s\n", $$, $0); freeName($0)}
如果我们使用 valueStack 来表示属性堆栈的话,那么在执行动作{$1=$2=newName()},在代码上实现时就相当与:
t := newName()
stackTop = len(valueStack)-1
valueStack[stackTop-1].right = t //对应$1
valueStack[stackTop-2].right = t //对应$2
同理行动{printf(“%s+=%s\n”, $$,$0)}在代码实现上相当于:
stackTop = len(valueStack)-1
fmt.Printf("%s+=%s\n", valueStack[stackTop].left, valueStack[stackTop].right)
最后我们把前面的语法规则做一些修改以便后面代码实现:
stmt -> epsilon | {$1=$2=newName()} expr {freeName($0)} SEMI stmt
expr -> term expr_prime
expr_prime -> PLUS {$1=$2=newName()} term {printf("%s+=%s\n", $$, $0); freeName($0);} expr_prime| epsilon
term -> factor term_prime
term_prime -> MUL {$1=$2=newName();} factor {printf("%s *= %s\n", $$, $0); freeName($0);} term_prime | epsilon
factor -> NUM {printf("%s=%s\n", $$, lexer.lexeme)}
factor -> LEFT_PAREN expr RIGHT_PAREN
注意这里的$1, $2, $0 指示我们如何引用属性堆栈上的 Attribute 结构体对象,此外为了方便代码实现,我们把表达式中的各个元素在数值上做一些映射,把所有终结符映射到 1-255 这个区间的数值,于是有:
LEFT_PAREN -> 5, NUM -> 4, PLUS -> 2, RIGHT_PAREN -> 6, SEMI -> 1, MUL -> 3, EPSILON -> 255, EOF ->0
非终结符映射到数值区间 256->511:
expr -> 257, expr_prime -> 259, factor->260, stmt->256, term->258, term_prime->261
行动映射到数值区间 512以上:
{op(‘+’)} -> 512, {op(‘*’)}->513, {create_tmp(lexer.lexeme)}-> 514, {assign_name}->515,
{free_name}->516
这里 {op(‘+’)} 对应{printf(“%s+=%s\n”, KaTeX parse error: Can't use function '$' in math mode at position 3: , $̲0); freeName($0…, $0); freeName($0);}
{create_temp(lexer.lexeme)}对应{printf(“%s=%s\n”, $$, lexer.lexeme)}
{assign_name}对应{$1=$2=newName()}
{free_name}对应{freeName($0)}
接下来我们看看如何实现行动查询表,首先我们会在代码中构造一个映射表yy_pushtab,他对应我们的语法表达式,其内如如下:
//注意队列中的数值是表达式右边部分符号的逆向排列
yy_pushtab[0]=[255] //stmt-> epsilon
yy_pushtab[1]=[256, 1, 516,257,515] //stmt-> {$1=$2=newName()} expr {freeName($0)} SEMI stmt
yy_pushtab[2]=[259, 258] //expr -> term expr_prime
yy_pushtab[3]=[259, 512, 258, 515, 2] //expr_prime -> PLUS {assign_name} term {op('+')} expr_prime
yy_pushtab[4] = [255] //expr_prime -> epsilon
yy_pushtab[5] = [261, 260]//term -> factor term_prime
yy_pushtab[6]=[261, 513, 260, 515, 3]//MUL {assign_name} factor {op('*')} term_prime
yy_pushtab[7] = [255] //term_prime -> epsilon
yy_pushtab[8] =[514, 4] //factor ->num {create_tmp(lexer.lexeme)}
yy_pushtab[9] = [6, 257, 5] //factor -> LEFT_PAREN expr RIGHT_PAREN
接下来我们设置动作查询表yyd,也就给定当前节点和当前输入,状态机应该采取什么动作:
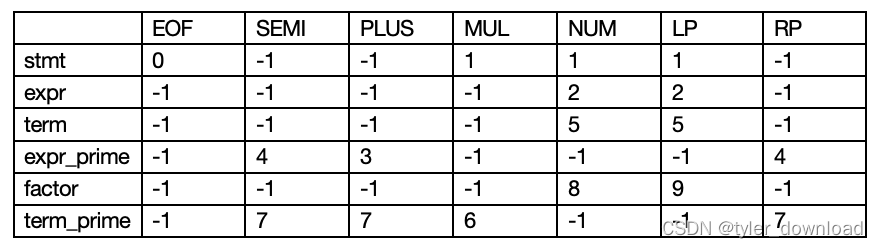
上面行动查询表的意思是,如果当前状态节点值为 stmt,如果当前输入是 EOF,那么就将 yy_pushtab[0]对应的数值压入解析堆栈,如果当前输入是 SEMI,由于表中数值是-1,因此表示解析出错,其他的依次类推。这里你是否有疑问,表中元素的取值是如何确定的?例如我们怎么知道 yyd[stmt][SEMI] 就应该等于-1,而 yyd[term][LP]就应该取值 5?个中原因我们还需要在后续章节中对相应的概念和算法进行说明,这里我们暂时放一放。
下面我们看看具体代码实现,新建一个目录名为 llma_parser,在里面添加文件 llma_parser.go,添加代码如下:
package llama_parser
import (
"fmt"
"lexer"
)
type Attribute struct {
left string
right string
}
const (
ERROR = -1
EOF = 0
SEMI = 2
PLUS = 3
MUL = 4
NUM = 5
LP = 6
RP = 7
EPSILON = 255
EXPR = 257
EXPR_PRIME = 259
FACTOR = 260
STMT = 256
TERM = 258
TERM_PRIME = 261
OP_PLUS = 512
OP_MUL = 513
CREATE_TMP = 514
ASSIGN_NAME = 515
FREE_NAME = 516
)
type ActionQuery struct {
state int
token lexer.Tag
}
type LLAMAParser struct {
parseStack []int
attributeStack []Attribute
yy_pushtab [][]int
yyd map[ActionQuery]int
parserLexer lexer.Lexer
registerNames []string
//存储当前已分配寄存器的名字
regiserStack []string
//当前可用寄存器名字的下标
registerNameIdx int
reverseToken []lexer.Token
}
func initYyPushTab(parser *LLAMAParser) {
// stmt -> epsilon
parser.yy_pushtab = append(parser.yy_pushtab, []int{EPSILON})
// stmt -> {assign_name} expr {free_name} semi stmt
parser.yy_pushtab = append(parser.yy_pushtab, []int{STMT, SEMI, FREE_NAME, EXPR, ASSIGN_NAME})
// expr -> term expr_prime
parser.yy_pushtab = append(parser.yy_pushtab, []int{EXPR_PRIME, TERM})
// expr_prime -> PLUS {assign_name} term {op('+')} expr_prime
parser.yy_pushtab = append(parser.yy_pushtab, []int{EXPR_PRIME, OP_PLUS, TERM, ASSIGN_NAME, PLUS})
// expr_prime -> epsilon
parser.yy_pushtab = append(parser.yy_pushtab, []int{EPSILON})
// term -> factor term_prime
parser.yy_pushtab = append(parser.yy_pushtab, []int{TERM_PRIME, FACTOR})
// term_prime -> MUL {assign_name} factor {op('*')} term_prime
parser.yy_pushtab = append(parser.yy_pushtab, []int{TERM_PRIME, OP_MUL, FACTOR, ASSIGN_NAME, MUL})
// term_prime -> epsilon
parser.yy_pushtab = append(parser.yy_pushtab, []int{EPSILON})
// factor -> NUM {create_tmp}
parser.yy_pushtab = append(parser.yy_pushtab, []int{CREATE_TMP, NUM})
// factor -> LP EXPR RP
parser.yy_pushtab = append(parser.yy_pushtab, []int{RP, EXPR, LP})
}
func initYYDRow(parser *LLAMAParser, state int,
tags []lexer.Tag, val int) {
for _, tag := range tags {
parser.yyd[ActionQuery{
state: state,
token: tag,
}] = val
}
}
func initActionMap(parser *LLAMAParser) {
//设置 yyd 表,后面我们能自动生成,这里我们先手动设置
initYYDRow(parser, STMT,
[]lexer.Tag{lexer.SEMI, lexer.PLUS,
lexer.MUL, lexer.RIGHT_BRACKET}, -1)
initYYDRow(parser, STMT, []lexer.Tag{lexer.EOF}, 0)
initYYDRow(parser, STMT, []lexer.Tag{lexer.NUM, lexer.LEFT_BRACKET}, 1)
initYYDRow(parser, EXPR, []lexer.Tag{lexer.EOF, lexer.SEMI, lexer.PLUS,
lexer.MUL, lexer.RIGHT_BRACKET}, -1)
initYYDRow(parser, EXPR, []lexer.Tag{lexer.NUM, lexer.LEFT_BRACKET}, 2)
initYYDRow(parser, TERM, []lexer.Tag{lexer.EOF, lexer.SEMI, lexer.PLUS,
lexer.MUL, lexer.RIGHT_BRACKET}, -1)
initYYDRow(parser, TERM, []lexer.Tag{lexer.NUM, lexer.LEFT_BRACKET}, 5)
initYYDRow(parser, EXPR_PRIME, []lexer.Tag{lexer.EOF,
lexer.MUL, lexer.NUM, lexer.LEFT_BRACKET}, -1)
initYYDRow(parser, EXPR_PRIME, []lexer.Tag{lexer.SEMI,
lexer.RIGHT_BRACKET}, 4)
initYYDRow(parser, EXPR_PRIME, []lexer.Tag{lexer.PLUS}, 3)
initYYDRow(parser, FACTOR, []lexer.Tag{lexer.EOF,
lexer.SEMI, lexer.PLUS, lexer.MUL, lexer.RIGHT_BRACKET}, -1)
initYYDRow(parser, FACTOR, []lexer.Tag{lexer.NUM}, 8)
initYYDRow(parser, FACTOR, []lexer.Tag{lexer.LEFT_BRACKET}, 9)
initYYDRow(parser, TERM_PRIME, []lexer.Tag{lexer.EOF,
lexer.MUL, lexer.NUM, lexer.MUL, lexer.LEFT_BRACKET}, -1)
initYYDRow(parser, TERM_PRIME, []lexer.Tag{lexer.MUL}, 6)
initYYDRow(parser, TERM_PRIME, []lexer.Tag{lexer.SEMI,
lexer.PLUS, lexer.RIGHT_BRACKET}, 7)
}
func NewLLAMAParser(parserLexer lexer.Lexer) *LLAMAParser {
parser := &LLAMAParser{
parseStack: make([]int, 0),
attributeStack: make([]Attribute, 0),
yy_pushtab: make([][]int, 0),
parserLexer: parserLexer,
yyd: make(map[ActionQuery]int),
registerNames: []string{"t0", "t1", "t2", "t3", "t4", "t5", "t6", "t7"},
regiserStack: make([]string, 0),
registerNameIdx: 0,
reverseToken: make([]lexer.Token, 0),
}
initYyPushTab(parser)
initActionMap(parser)
parser.parseStack = append(parser.parseStack, STMT)
parser.attributeStack = append(parser.attributeStack, Attribute{
left: "",
right: "",
})
return parser
}
func (l *LLAMAParser) get(state int, tag lexer.Tag) int {
return l.yyd[ActionQuery{
state: state,
token: tag,
}]
}
func (l *LLAMAParser) newName() string {
//返回一个寄存器的名字
if l.registerNameIdx >= len(l.registerNames) {
//没有寄存器可用
panic("register name running out")
}
name := l.registerNames[l.registerNameIdx]
l.registerNameIdx += 1
return name
}
func (l *LLAMAParser) putbackName(name string) {
//释放当前寄存器名字
if l.registerNameIdx > len(l.registerNames) {
panic("register name index out of bound")
}
if l.registerNameIdx == 0 {
panic("register name is full")
}
l.registerNameIdx -= 1
l.registerNames[l.registerNameIdx] = name
}
func (l *LLAMAParser) assignName() {
//{$1=$2 = newName}
stackTop := len(l.attributeStack) - 1
t := l.newName()
//$1 相当于 stackTop - 1, $2 相当于 stackTop - 2
l.attributeStack[stackTop-1].right = t
l.attributeStack[stackTop-2].right = t
}
func (l *LLAMAParser) freeName() {
//{freeName($0)}
stackTop := len(l.attributeStack) - 1
//$0 对应栈顶元素
l.putbackName(l.attributeStack[stackTop].right)
}
func (l *LLAMAParser) op(action string) {
//$$对应栈顶元素的 left 字段
//$0 对应栈顶元素的 right 字段
stackTop := len(l.attributeStack) - 1
fmt.Printf("%s %s= %s\n", l.attributeStack[stackTop].left,
action, l.attributeStack[stackTop].right)
l.freeName()
}
func (l *LLAMAParser) createTmp() {
//$$ 对应栈顶元素的 left 字段
stackTop := len(l.attributeStack) - 1
fmt.Printf("%s = %s\n", l.attributeStack[stackTop].left,
l.parserLexer.Lexeme)
}
func (l *LLAMAParser) putbackToken(token lexer.Token) {
l.reverseToken = append(l.reverseToken, token)
}
func (l *LLAMAParser) getToken() lexer.Token {
//先看看有没有上次退回去的 token
if len(l.reverseToken) > 0 {
token := l.reverseToken[len(l.reverseToken)-1]
l.reverseToken = l.reverseToken[0 : len(l.reverseToken)-1]
return token
}
token, err := l.parserLexer.Scan()
if err != nil && token.Tag != lexer.EOF {
sErr := fmt.Sprintf("get token with err:%s\n", err)
panic(sErr)
}
return token
}
func (l *LLAMAParser) match(tag lexer.Tag) {
token := l.getToken()
if token.Tag != tag {
panic("terminal symbol no match")
}
}
func (l *LLAMAParser) takeAction(action int, rightOnTop string) {
actions := l.yy_pushtab[action]
for _, val := range actions {
l.parseStack = append(l.parseStack, val)
l.attributeStack = append(l.attributeStack, Attribute{
left: rightOnTop,
right: rightOnTop,
})
}
}
func (l *LLAMAParser) isAction(symbol int) bool {
return symbol >= 512
}
/*
stmt -> epsilon | {$1=$2=newName()} expr {freeName($0)} SEMI stmt
expr -> term expr_prime
expr_prime -> PLUS {$1=$2=newName()} term {printf("%s+=%s\n", $$, $0); freeName($0);} expr_prime| epsilon
term -> factor term_prime
term_prime -> MUL {$1=$2=newName();} factor {printf("%s *= %s\n", $$, $0); freeName($0);} term_prime | epsilon
factor -> NUM {printf("%s=%s\n", $$, lexer.lexeme)}
*/
func (l *LLAMAParser) Parse() {
for len(l.parseStack) != 0 {
symbol := l.parseStack[len(l.parseStack)-1]
//顶部堆栈元素相当于表达式箭头左边的非终结符 s
l.parseStack = l.parseStack[0 : len(l.parseStack)-1]
rightOnTop := l.attributeStack[len(l.attributeStack)-1].right
if l.isAction(symbol) != true {
l.attributeStack = l.attributeStack[0 : len(l.attributeStack)-1]
}
switch symbol {
//匹配行动
case ASSIGN_NAME:
l.assignName()
l.attributeStack = l.attributeStack[0 : len(l.attributeStack)-1]
case CREATE_TMP:
l.createTmp()
l.attributeStack = l.attributeStack[0 : len(l.attributeStack)-1]
case FREE_NAME:
l.freeName()
l.attributeStack = l.attributeStack[0 : len(l.attributeStack)-1]
case OP_PLUS:
l.op("+")
l.attributeStack = l.attributeStack[0 : len(l.attributeStack)-1]
case OP_MUL:
l.op("*")
l.attributeStack = l.attributeStack[0 : len(l.attributeStack)-1]
//匹配终结符
case EOF:
l.match(lexer.EOF)
case NUM:
l.match(lexer.NUM)
case SEMI:
l.match(lexer.SEMI)
case PLUS:
l.match(lexer.PLUS)
case MUL:
l.match(lexer.MUL)
case LP:
l.match(lexer.LEFT_BRACKET)
case RP:
l.match(lexer.RIGHT_BRACKET)
//匹配非终结符
case STMT:
fallthrough
case EXPR:
fallthrough
case EXPR_PRIME:
fallthrough
case TERM:
fallthrough
case TERM_PRIME:
fallthrough
case FACTOR:
token := l.getToken()
l.putbackToken(token)
action := l.get(symbol, token.Tag)
if action == -1 {
panic("parse error, not action for given symbol and input")
}
l.takeAction(action, rightOnTop)
}
}
}
我们细说一下如上代码实现,首先需要说明的是上面代码在后续章节中会通过自动化的方式生成,因此我们这里先通过繁琐的手动方式做一遍。在代码实现中我们先定义结构体 Attribute 作为传递语法参数的对象。
函数initYyPushTab用于初始化要压入解析堆栈的符号,它本质上是将语法解析式右边的符号通过逆向的方式存放成一个队列。此外需要注意initYYDRow,和initActionMap两个函数,他们用于初始化行动查询表,注意看前面行动查询表,它每一行中有多列的内容有多种重复,因此initYYDRow通过循环的方式来设置表中一行的内容。
在构造函数NewLLAMAParser中,我们还初始化两个堆栈,一个是 parseStack,它对应解析堆栈,另一个是 attributeStack,它是属性堆栈。其他的函数例如 get, newName, assignName, freeName, createTmp, putbackToken, getToken 等实现跟我们前面的章节一样,isAction用于判断当前节点是否对应行动,它的判断依据就是当前节点数值是否大于 512。
在解析函数Parse中它的基本逻辑为,首先判断当前解析堆栈是否为空,如果为空,那么解析结束。如果不空,那么取出当前栈顶元素,同时也取出属性堆栈顶部元素的 right 字段。这里需要注意的是如果当前解析堆栈顶部元素不是行动,那么我们可以直接将属性堆栈顶部元素弹出,因为解析过程用不上,但如果当前元素是行动,那么就需要执行完对应代码后才能弹出属性堆栈顶部元素,因为该顶部元素需要在行动对应的代码执行过程中使用到。
如果解析堆栈顶部元素是终结符,那么我们必须判断当前读取的标签于对应的终结符相匹配,不然就是语法错误,如果是非终结符,那么我们就把对应语法解析式右边的符号压入堆栈即可,上面代码完成后执行结果如下:
t0 = 1
t1 = 2
t2 = 4
t3 = 3
t2 += t3
t1 *= t2
t0 += t1
可以看到其效果跟我们前面章节实现的一模一样,更多详细的讲解和调试演示请在 b 站搜索 coding 迪斯尼,本问代码下载地址为:
https://github.com/wycl16514/llma_parser


![[嵌入式系统-16]:RT-Thread -2- 主要功能功能组件详解与API函数说明、API参考手册入口](https://img-blog.csdnimg.cn/direct/0bd93e5cfc5c4628ab88ec58fe77723b.png)