文章目录
- 1、了解索引
- 2、聚簇、非聚簇索引
- 3、操作
- 1、主键索引
- 2、唯一键索引
- 3、普通索引
- 4、注意事项
- 4、全文索引
1、了解索引
MySQL服务器是在内存中的,所有数据库的CURD操作都是在内存中进行,索引也是如此。索引是用来提高性能的,它通过组织数据的方式来提高效率。
MySQL工作在应用层。磁盘的IO以4KB为单位,MySQL则是16KB,由磁盘往系统内部的缓冲区放入数据,达到16KB后再放入MySQL的缓冲区。
MySQL 中的数据文件,是以page为单位保存在磁盘当中的。CURD 操作,都需要通过计算,找到对应的插入位置,或者找到对应要修改或者查询的数据。而只要涉及计算,就需要CPU参与,而为了便于CPU参与,一定要能够先将数据移动到内存当中。所以在特定时间内,数据一定是磁盘中有,内存中也有。后续操作完内存数据之后,以特定的刷新策略,刷新到磁盘。而这时,就涉及到磁盘和内存的数据交互,也就是IO了。而此时IO的基本单位就是Page。
为了更好的进行上面的操作, MySQL 服务器在内存中运行的时候,在服务器内部,就申请了被称为 Buffer Pool 的大内存空间,来进行各种缓存。其实就是很大的内存空间,来和磁盘数据进行IO交互。
主键索引(primary key)
唯一索引(unique)
普通索引(index)
全文索引(fulltext) – 解决中子文索引问题。
create table if not exists user ( id int primary key, age int not null, name varchar(16) not null );
insert into user (id, age, name) values(3, 18, '杨过');
insert into user (id, age, name) values(4, 16, '小龙女');
insert into user (id, age, name) values(2, 26, '黄蓉');
insert into user (id, age, name) values(5, 36, '郭靖');
insert into user (id, age, name) values(1, 56, '欧阳锋');
创建一个具有主键的表,乱序插入数据,数据会自动排序。MySQL对于多个同时存在的page会先描述再组织,page内部有一些管理信息,在MySQL的缓冲区内对所有的page进行管理,不同的page有两个指针,和其它page组成双链表。一个page会保存好很多信息,用户就可以直接在内存中交互,page通过预加载机制和局部性原理来保存很多信息方便用户IO。IO次数多对IO效率影响很大。
插入时的排序是mysql服务自己做的,也是为了更好地管理数据。page之间,page内部都是链式结构。MySQL中有一部分空间,用来存放页目录,目录有两个字段,一个指向起始数据记录的key值,也就是它的序号,另一个指向这个记录的起始地址。要查找的记录,比如4,那就从头开始看两个目录之间的范围有没有4,没有就继续往下找,有就进入这个范围,继续找。page逐渐增多时,MySQL会自动扩容,并将这些新增的page继续管理起来。
page之间有页目录,page内部也有目录,内部的目录只保存自己目录的数据记录的起始编号。一个page大概可以管理1300多个page,一个page管理的很多个子page,这些子page还可以有自己的子page,MySQL管理page的结构就是B+树。叶子节点保存数据,非叶子节点只保存目录项,叶子节点全部用链表级联起来。所以这棵树是矮胖型的,那么途径的路上节点就比较少,找到目标数据需要更少的page,IO次数就会更少,也就提高了效率。
整个结构是mysql的innode db下的索引结构。建表插入数据的时候,就是在该结构下进行CURD。即使没有主键,也是如此,因为有默认主键。索引自顶向下搜索。
2、聚簇、非聚簇索引
除了上面所说的innnode db的索引,还有MyISAM的存储引擎。采用B+树,叶子节点存放数据记录的地址,而上面的叶子节点还会存放起始编号。上面的是聚簇索引,叶子节点只存放地址的是非聚簇索引。
建立非聚簇索引的表
create table test2( id int primary key, name varchar(20) not null )engine=myisam;
myisam可以给一张表建立多个索引,索引本质就是B+树这个数据结构。innodb如果没有主键索引,那么建立的普通(辅助)索引中,叶子节点没有数据,只有对应记录的key值。通过辅助索引找到主键,用主键到主索引中检索获得记录,这是回表查询。
3、操作
1、主键索引
有3种方式。第一种就是之前在创建表时,某一列后加上primary key,之后不需要再做什么,就创建了主键索引;第二种和第一种一样,只是写法不一样
//第一种
>create table user(id int primary key, name varchar(20));
//第二种
>>create table user(id int, name varchar(20), primary key(id));
第三种
create table user(id int, name varchar(20));
//创建表以后再添加主键
alter table user add primary key(id);
查看索引
show index from 表名;
show keys from 表名;
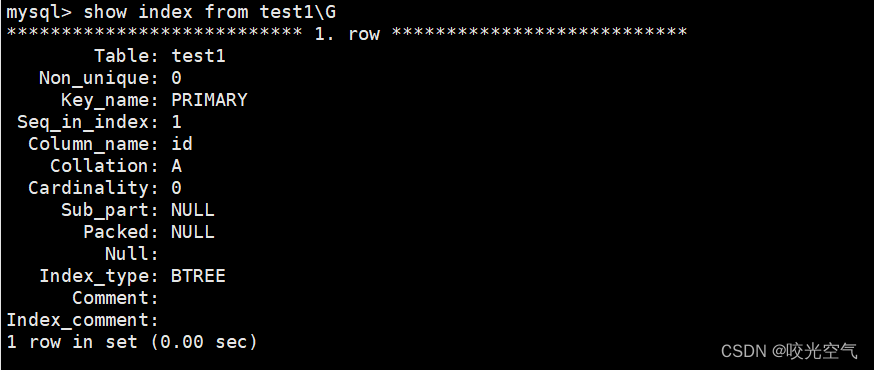
BTREE就表示B+树。
删除索引
alter table 表名 drop primary key;
主键索引特点
一个表中,最多有一个主键索引,也可以使用复合主键
主键索引的效率高(主键不可重复)
创建主键索引的列,它的值不能为null,且不能重复
主键索引的列基本上是int
2、唯一键索引
//第一种
create table user(id int primary key, name varchar(20) unique);
//第二种
create table user(id int primary key, name varchar(20), unique(name));
//第三种
create table user(id int primary key, name varchar(30));
alter table user add unique(name);
唯一键索引特点
一个表中,可以有多个唯一索引
查询效率高
如果在某一列建立唯一索引,必须保证这列不能有重复数据
如果一个唯一索引上指定not null,等价于主键索引
删除唯一键索引
alter table 表名 drop index Key_name;
3、普通索引
//第一种
create table user(id int primary key, name varchar(20), index(name));
//第二种
create table user(id int primary key, name varchar(20));
alter table user add index(name);
//第三种, 可以给普通索引自己起名
create table user(id int primary key, name varchar(20));
create index 索引名 on user(name);
普通索引特点
一个表中可以有多个普通索引,普通索引在实际开发中用的比较多
如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引
删除普通索引
alter table 表名 drop index Key_name;
drop index Key_name on 表名;
可以写index(a, b),也就是把两列合起来做一个普通索引,这也就是复合索引。查找时必须两者都符合才能找到。默认a是key值。复合索引在show index时会显示多个Key_name相同的部分,删除时也会删除多个。
索引覆盖是指在复合索引中搜索时能够直接搜索到需要的数据,那就不需要回表查询。索引在匹配时,都是从记录的最左侧开始匹配。
4、注意事项
比较频繁作为查询条件的字段应该创建索引
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
更新非常频繁的字段不适合作创建索引
不会出现在where子句中的字段不该创建索引
4、全文索引
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,且要求存储引擎必须是MyISAM,只支持英文,如果要支持中文就用sphinx的中文版coreseek。
在mysql语句之前写上explain可以看到要这条语句的执行计划。
全文索引例子
select * from 表名 where match( , ) against (‘’);
match使用全文索引,against用来匹配。
结束。
![[嵌入式系统-16]:RT-Thread -2- 主要功能功能组件详解与API函数说明、API参考手册入口](https://img-blog.csdnimg.cn/direct/0bd93e5cfc5c4628ab88ec58fe77723b.png)




![[杂记]mmdetection3.x中的数据流与基本流程详解(数据集读取, 数据增强, 训练)](https://img-blog.csdnimg.cn/direct/6e510634ee994db6b5b73d7bb42f58f7.png)