二叉树
几乎每次蓝桥杯软件类大赛都会考核二叉树,它或者作为数据结构题出现,或者应用在其他算法中。大部分高级数据结构是基于二叉树的,例如常用的高级数据结构线段树就是基于二叉树的。二叉树应用广泛和它的形态有关。
二叉树的定义:
二叉树的第1层是一个结点,称为根,它最多有两个子结点,分别是左子结点、右子结点,以它们为根的子树称为左子树、右子树。二叉树上的每个结点,都是按照这个规则逐层往下构建出来的。


图3.4 二叉树的形态

满二叉树和完全二叉树是平衡的二叉树,因为每个结点的左右子树的数量都差不多。“链状”二叉树是不平衡的二叉树。只有在平衡的二叉树上才能进行高效的操作,而不平衡的二叉树退化成了线性结构,和低效的链表没多大区别。
二叉树的存储
在算法竞赛中,为了使代码简单高效,编程速度加快,一般用静态数组来实现二叉树。定义一个大小为N的静态结构体数组,用它来存储一棵二叉树。
struct Node { //静态二叉树
char value;
int lson, rson; //指向左右子结点的存储位置,编程时可把lson简写为ls或者l
} tree[N]; //编程时可把tree简写为t编程时一般不用tree[0],因为0被用来表示空结点,例如叶子结点tree[2]没有子结点,就把它的子结点lson和rson赋值为0。
二叉树的遍历
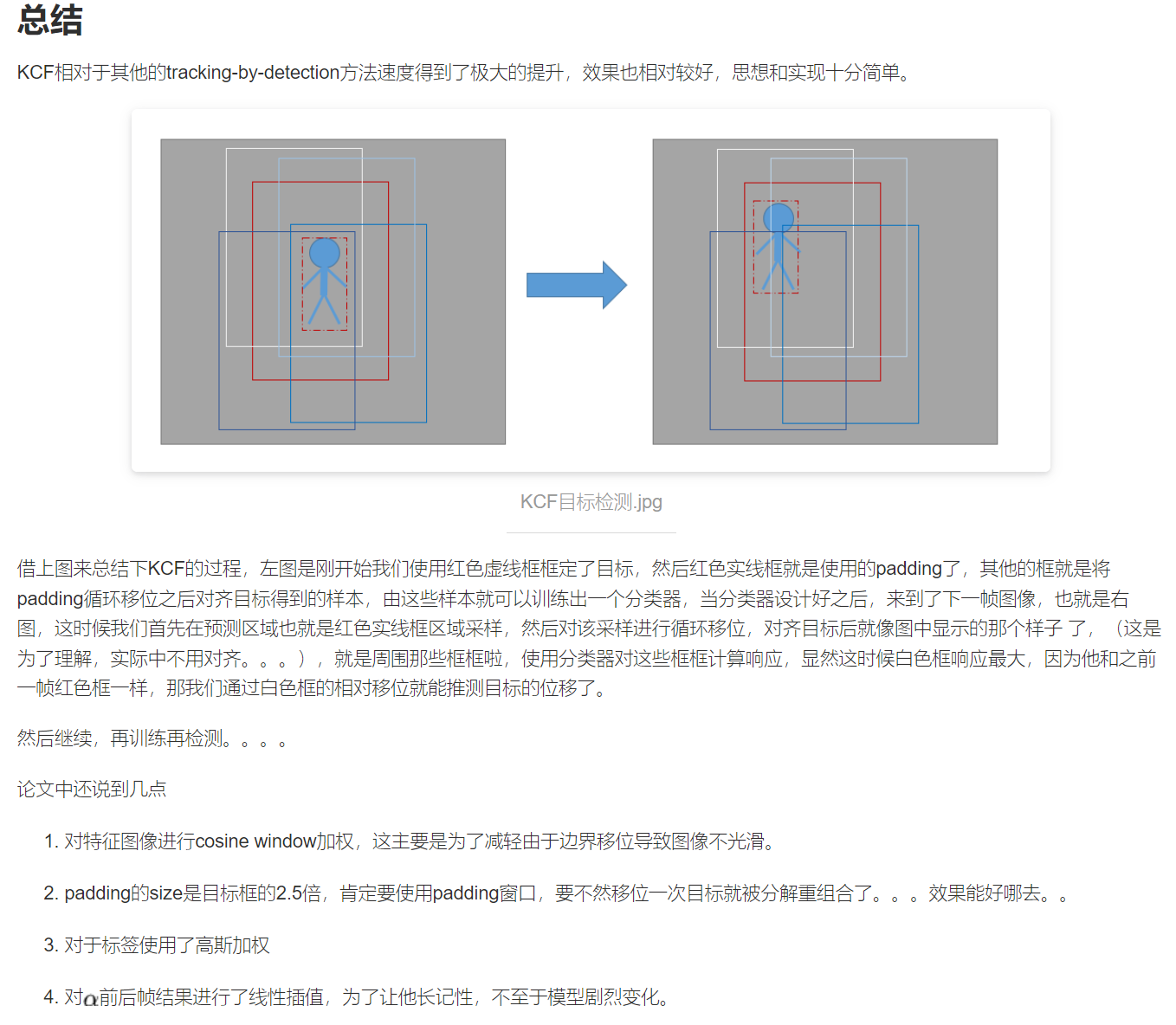
按访问二叉树的顺序,对父结点、左子结点、右子结点进行组合,有先(父)序遍历、中(父)序遍历、后(父)序遍历这3种访问顺序,这里默认左子结点在右子结点前面。后面的说明都以图3.6所示二叉树为例。

广度优先遍历:
有时需要按层次,一层一层地遍历二叉树,此时用BFS是最合适的。从根结点开始,在每一层,把下一层的结点放进队列。例如用BFS遍历图3.6所示的二叉树的步骤如表3.1所示。

表3.1 用BFS遍历二叉树
出队的顺序:EBGADFICH。按层次深度逐层输出。
在任意时刻,队列中最多只有相邻两层的结点。例如,第3步后,当前队列是GAD,是第2、3层的结点;第4步后,当前队列是ADFI,只有第3层的结点。
深度优先遍历:
用DFS遍历二叉树,代码极其简单。
(1)先序遍历。按父结点、左子结点、右子结点的顺序访问。
在图3.6中,访问返回的结果是EBADCGFIH。
先序遍历用递归实现非常简单,“伪”代码如下。
void preorder (node *root) {
cout << root ->value; //输出结点的值
preorder (root -> lson); //递归左子树
preorder (root -> rson); //递归右子树
}(2)中序遍历。按左子结点、父结点、右子结点的顺序访问。
在图3.6中,访问返回的结果是ABCDEFGHI。
中序遍历的递归“伪”代码如下。
void inorder (node *root){
inorder (root -> lson); //递归左子树
cout << root ->value; //输出
inorder (root -> rson); //递归右子树
}(3)后序遍历。按左子结点、右子结点、父结点的顺序访问。
在图3.6中,访问返回的结果是ACDBFHIGE。
后序遍历的递归“伪”代码如下。
void postorder (node *root){
postorder (root -> lson); //递归左子树
postorder (root -> rson); //递归右子树
cout << root ->value; //输出
}





![代码随想录算法训练营第十七天 | 110.平衡二叉树,257. 二叉树的所有路径,404.左叶子之和 [二叉树篇]](https://img-blog.csdnimg.cn/direct/370c75c760594b25b037ce1cded787fd.png)