今天分享的是AI系列深度研究报告:《AI专题:AI浪潮,海外日新月异,国内奋力追赶》。
(报告出品方:方正证券)
报告共计:24页
来源:人工智能学派
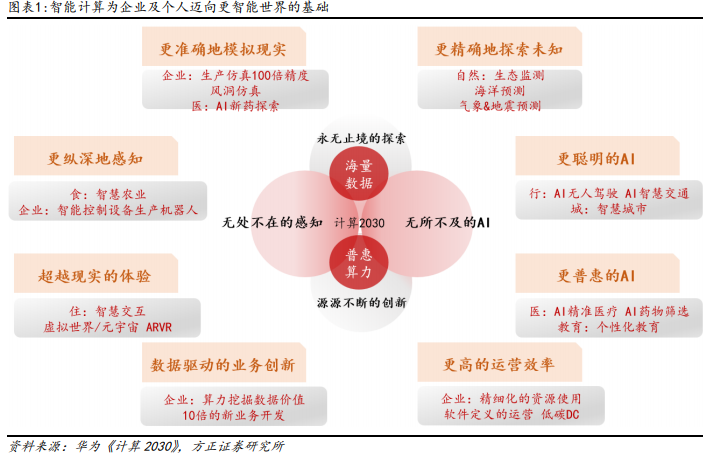
智算三方面奠基生产力革命,国家算网建设仍在加速
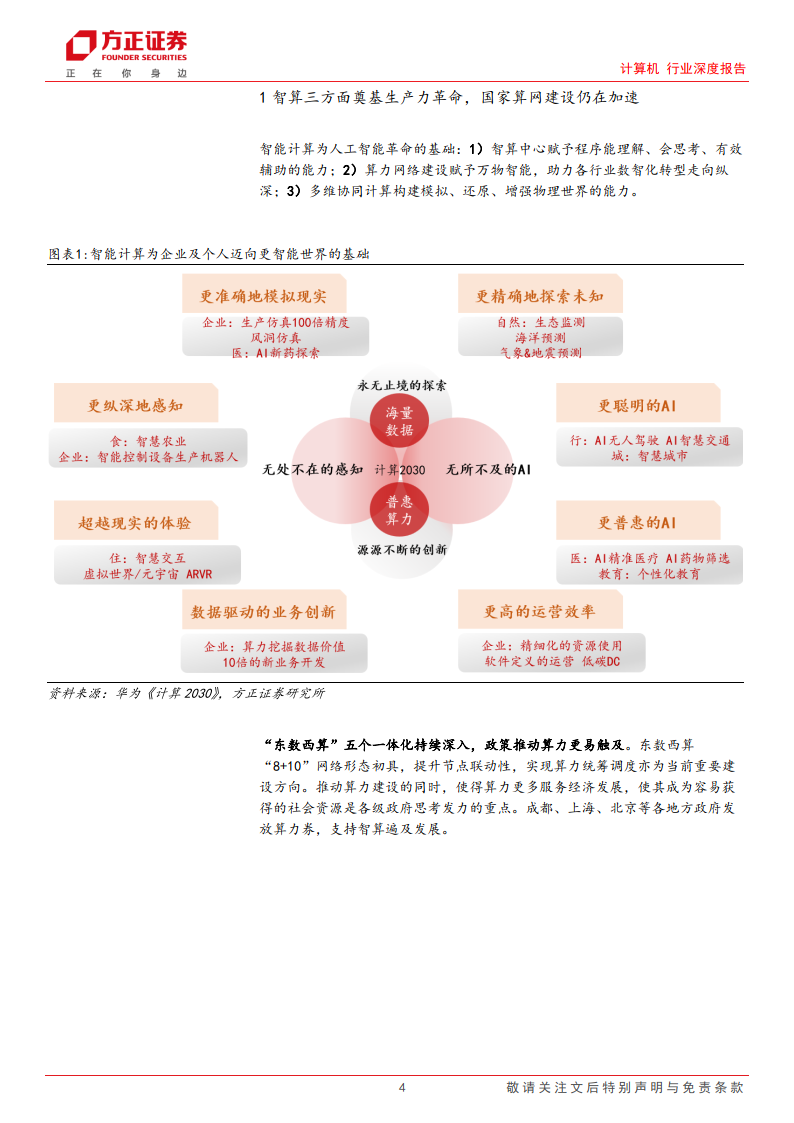
智能计算为人工智能革命的基础:
1)智算中心赋予程序能理解、会思考、有效辅助的能力;
2)算力网络建设赋予万物智能,助力各行业数智化转型走向纵深;
3)多维协同计算构建模拟、还原、增强物理世界的能力。
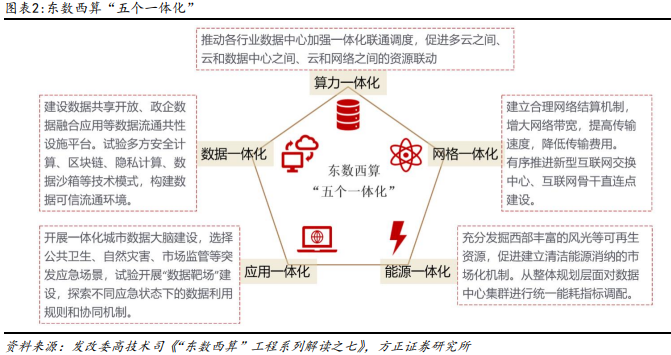
“东数西算”五个一体化持续深入,政策推动算力更易触及。东数西算 “8+10”网络形态初具,提升节点联动性,实现算力统筹调度亦为当前重要建 设方向。推动算力建设的同时,使得算力更多服务经济发展,使其成为容易获得的社会资源是各级政府思考发力的重点。成都、上海、北京等各地方政府发 放算力券,支持智算遍及发展。
2023 年智算中心建设步伐坚定,后续仍将保持
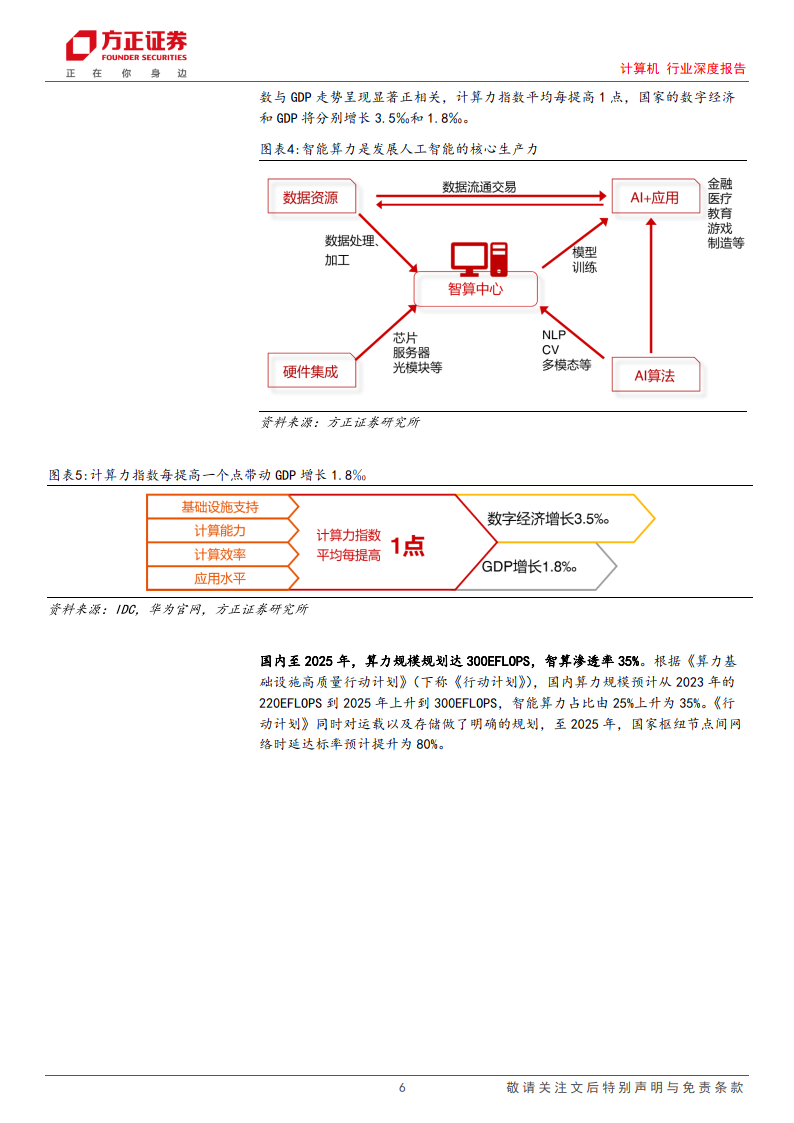
智算中心作为盘活数据资源,迭代落地 AI 算法的基础,向上拉动智算硬件巨大 的需求,向下促进 AI 应用繁荣,是 AI 时代重要的战略资源。智能算力是发展 人工智能的核心生产力,也是大国竞争的核心竞争力。正如国务院发展研究中 心副主任在 2023 中国国际大数据产业博览会上表示,中国市场规模大、应用场 景丰富、有制度优势,要加快算力网络建设,在全球竞争中赢得主动。根据 IDC 及浪潮信息联合发布的《2021-2022 全球计算力指数评估报告》,国家计算力指数与 GDP 走势呈现显著正相关,计算力指数平均每提高 1 点,国家的数字经济和 GDP 将分别增长 3.5‰和 1.8‰。
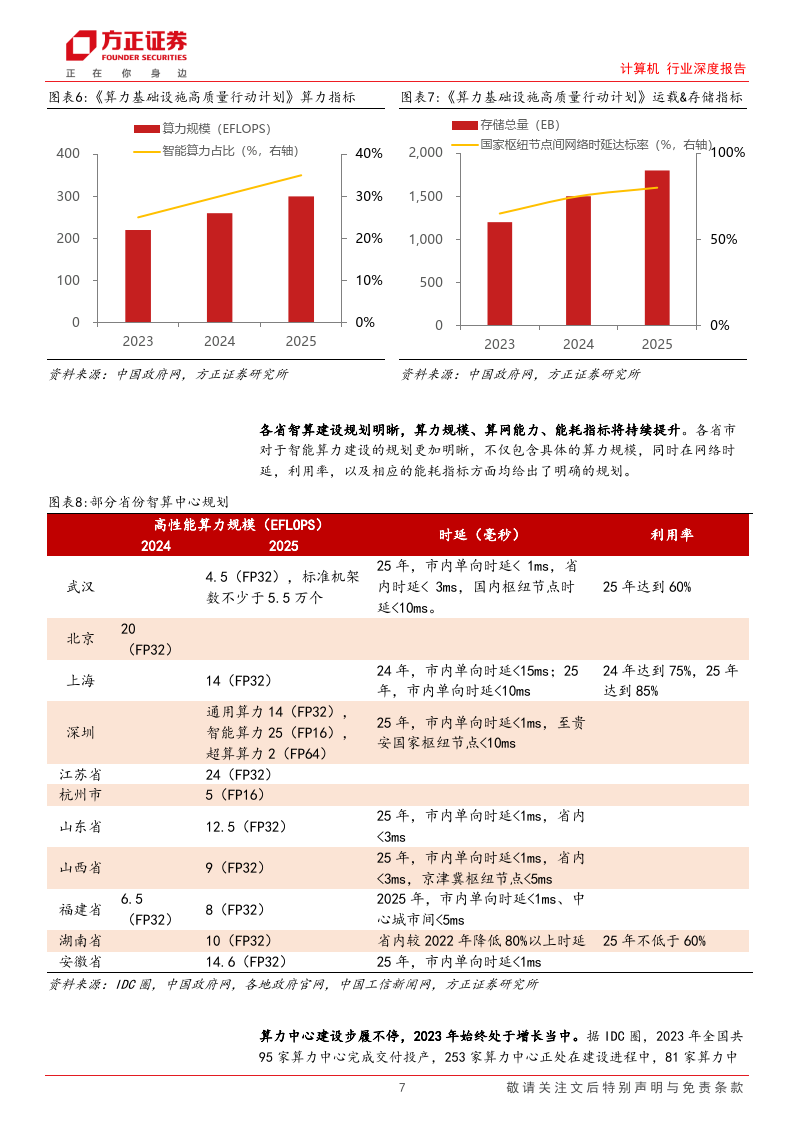
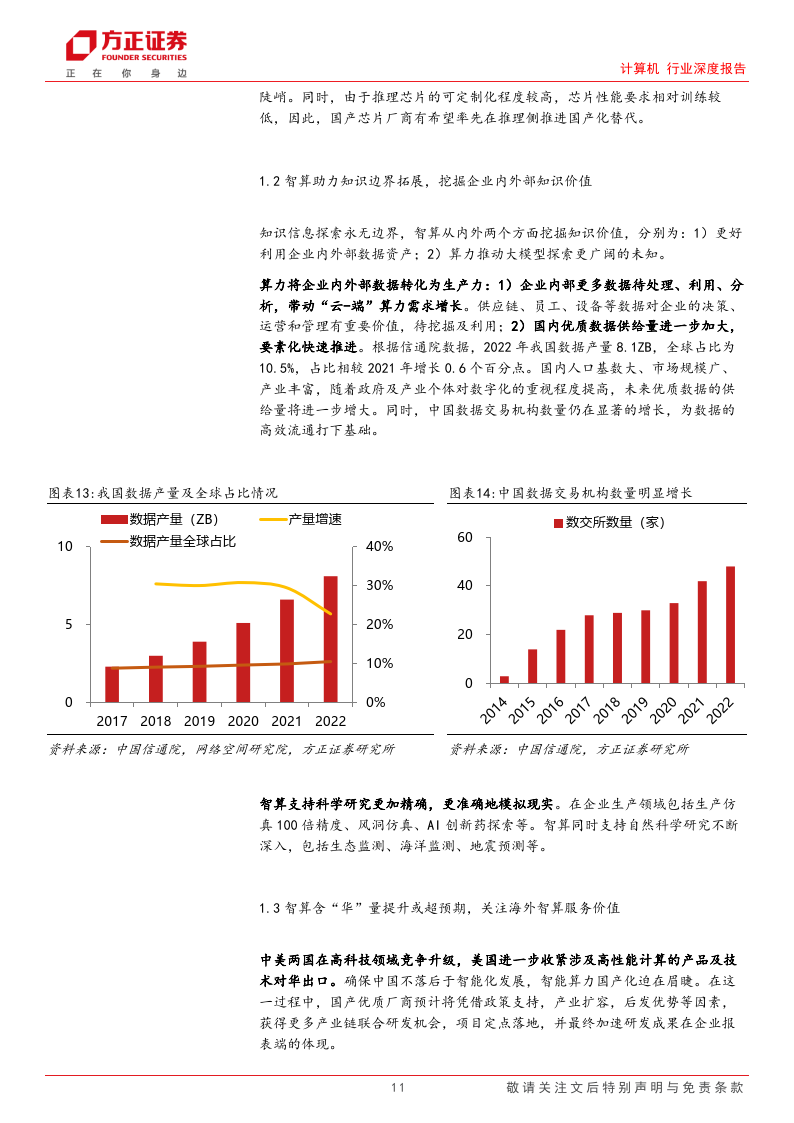
国内至 2025 年,算力规模规划达 300EFLOPS,智算渗透率 35%。根据《算力基 础设施高质量行动计划》(下称《行动计划》),国内算力规模预计从 2023 年的 220EFLOPS 到 2025 年上升到 300EFLOPS,智能算力占比由 25%上升为 35%。《行动计划》同时对运载以及存储做了明确的规划,至 2025 年,国家枢纽节点间网 络时延达标率预计提升为 80%。
各省智算建设规划明晰,算力规模、算网能力、能耗指标将持续提升。各省市对于智能算力建设的规划更加明晰,不仅包含具体的算力规模,同时在网络时 延,利用率,以及相应的能耗指标方面均给出了明确的规划。
算力中心建设步履不停,2023 年始终处于增长当中。据 IDC 圈,2023 年全国共 95 家算力中心完成交付投产,253 家算力中心正处在建设进程中,81 家算力中心启动开工建设,102 家算力中心进行招标和拟建设。算力中心的建设在全年都 处于增长状态,且在 5 月到 8 月增速最快。
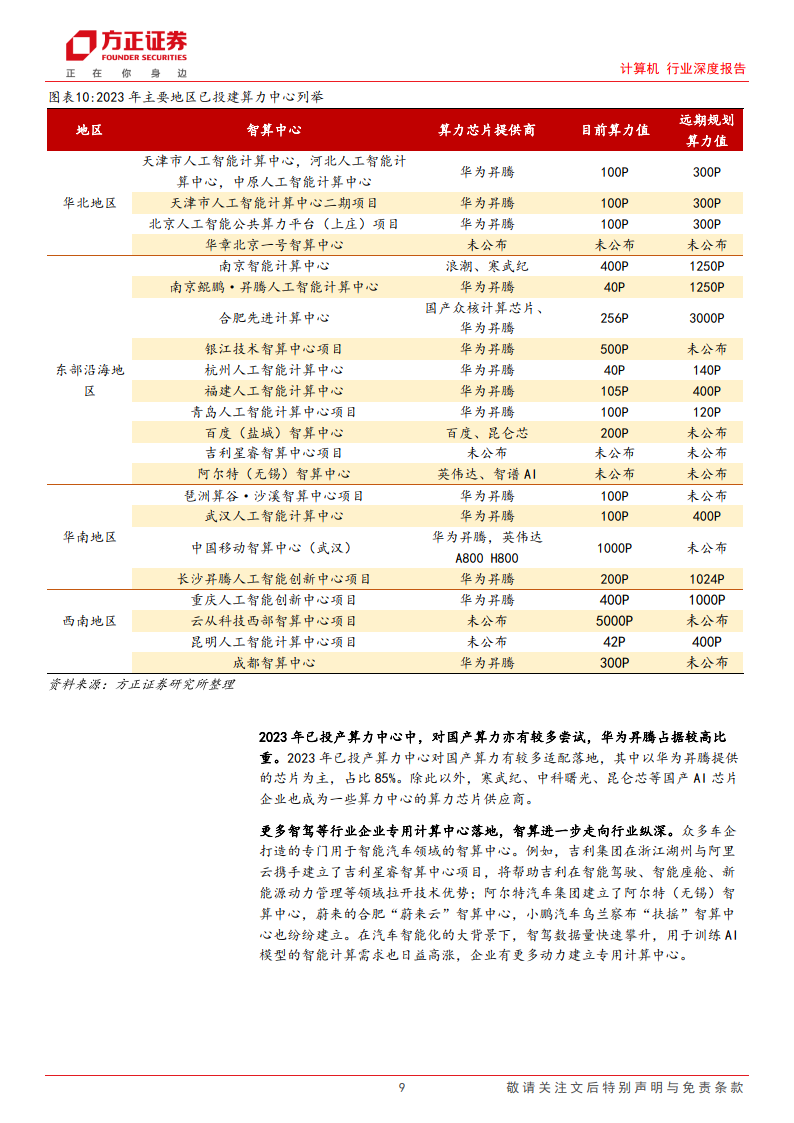
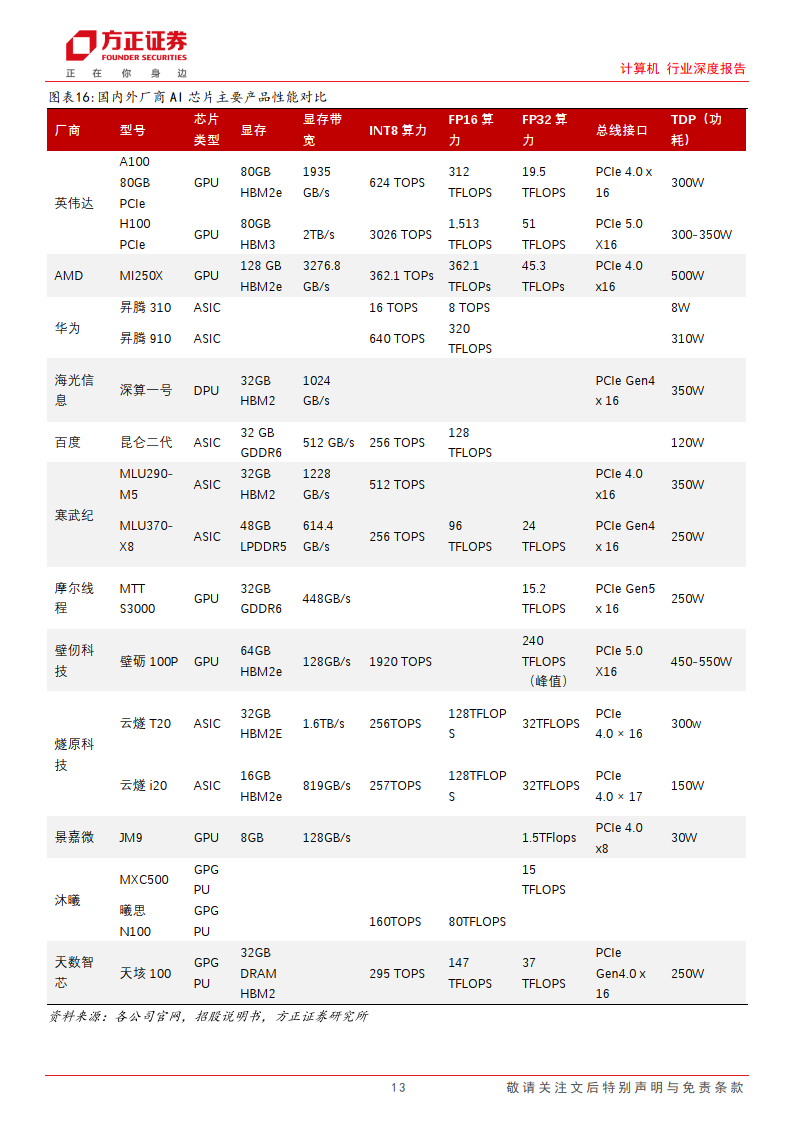
2023年已投产算力中心中,对国产算力亦有较多尝试,华为开腾占据较高比重。2023 年已投产算力中心对国产算力有较多适配落地,其中以华为开腾提供的芯片为主,占比 85%。除此以外,寒武纪、中科曙光、昆仑芯等国产A1芯片企业也成为一些算力中心的算力芯片供应商。
更多智驾等行业企业专用计算中心落地,智算进一步走向行业纵深。众多车企打造的专门用于智能汽车领域的智算中心。例如,吉利集团在浙江湖州与阿里云携手建立了吉利星容智算中心项目,将帮助吉利在智能驾驶、智能座舱、新能源动力管理等领域拉开技术优势:阿尔特汽车集团建立了阿尔特(无锡)智算中心,蔚来的合肥“蔚来云”智算中心,小鹏汽车乌兰察布“扶”智算中心也纷纷建立。在汽车智能化的大背景下,智驾数据量快速攀升,用于训练A1模型的智能计算需求也日益高涨,企业有更多动力建立专用计算中心。
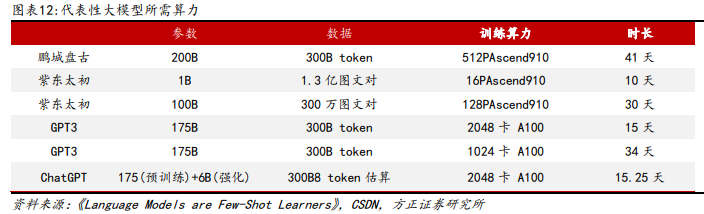
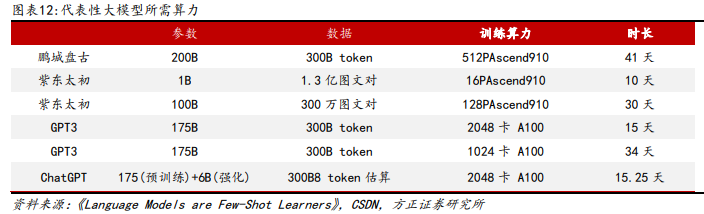
人工智能将继续从感知走向认知,模型训练需求远未及天花板。当前通用以及 垂类大模型仍有较大提升空间。由于每输入一个词都会导致模型所有参数的更 新,并且每个词需要消耗浮点算力,因此,总算力需求=模型参数量*训练词数* 每个词的运算量。1 个词更新 1 个参数,需要进行乘法及加法各 1 次,总共 2 次 浮点运算。模型训练需要反向传播算法,反向传播需要的运算次数是正向传播 的 2 倍,因此,训练时每个词的运算次数为 3 次(模型推理每个词的训练量为 1 次),也就是 6 次浮点运算。以 1750 亿参数的 GPT3 为例,带入上述公式计算可 得,模型训练所需要消耗的算力就达 3.14 * 10^23 次浮点运算(FLOPs)。如果 训练使用计算能力为 19.5 TFLOPs 的英伟达 A100,所需 GPU 数量 = 1.8 * 10^23 FLOPs / (19.5 * 10^12 FLOPs/s * 训练时间秒数),如果期望训练时间 为 15 天,则需要 2048 张 A100 GPU。








报告共计:24页
来源:人工智能学派