大模型向量库
- 向量:AI核心
- 向量库:语义近似搜索
- 大模型 + 向量库
- YOLO + 向量数据库
- 嵌入(Embedding)设计
- 最近邻搜索
- 近似近邻搜索
向量:AI核心
向量伴随着 AI 模型的发展而发展。
向量:AI 理解世界的通用数据形式,是多模态数据的压缩。
比如大模型输入输出都是文字文本,但模型实际接触和学习数据是向量化文本。
这个步骤叫 Embedding(嵌入),将文字文本转化为保留语义关系的向量文本。
embedding 模型对自然语言的压缩和总结,将高维数据映射到低维空间。
不仅文字,图像也是向量化之后进行处理:
向量库:语义近似搜索
传统数据库是基于文本的精确匹配、SQL语言查找符合条件的数据,适合关键字搜索。
向量库:专门存储和查询向量的数据库,适合语义搜索。

向量数据库步骤:
- 向量数据的存储:向量数据通常是高维的数值型数据,如图像特征向量、文本词向量等;向量数据库使用基于向量的存储结构,以便快速查询和处理;
- 向量索引:向量数据库使用PQ、LSH或HNSW等算法为向量编制索引,并将向量映射到数据结构,以便更快地进行搜索;
- 向量查询:向量数据库将查询向量与数据库中的向量进行比较,从而找到最近邻的向量;
- 查询结果的返回:向量数据库返回查询结果,通常包括与给定向量最相似的向量列表、向量之间的相似度得分等信息;该环节可以使用不同的相似性度量对最近邻重新排序。
传统数据库索引是精确匹配,要么符合查询要求(返回数据),要么不符合查询要求(无数据返回)。
向量搜索
- 在海量存储的向量中找到最符合要求的 Top N 个目标。
- 向量搜索是模糊匹配,返回的是相对最符合要求的N个数据,并没有精确标准答案
向量数据库
- 时间上:用以高效存储和搜索向量,自带语义理解(向量位置之间的相关性,距离越近越相关),为AI模型提供长期记忆功能
- 空间上:向量数据库本地部署后可以存储企业有关的大量隐私数据,通过特别的Agent大模型可以在有保护的情况下访问向量数据库
- 成本上:更低成本的搜索、查询、存储向量
- 速度上:保证100%信息完整的情况下,通过向量嵌入函数(embedding)精准描写非结构化数据的特征,从而提供查询、删除、修改、元数据过滤等操作,同时实现极高效率的近似搜索
- 功能上:跨模态搜索,例如让用户用文字来搜索图片,因为向量能够捕捉到语义相似性,使来自不同语言的查询和内容能够相互匹配。
传统数据库无法满足此类操作和需求,只能实现部分向量数据的存储,且无法高效搜索向量。
向量搜索能够实现对语义更为精准的理解,在多模态、不同语言等环境下能够输出更为准确的结果。
如:英文的Capital可以指“资本”或者“首都”,“从中国去美国”和“从美国去中国”存在方向,传统的数据库不能很好解决这些问题。
-
已知传统数据库,适合关键字搜索。
-
已知向量库,适合语义搜索。
那是不是还可以组合俩者,提供更加全面和精准的搜索?
或者加速搜索速度,先使用向量库进行初步的语义搜索以缩小搜索范围,然后在这个范围内使用传统数据库进行精确的关键字搜索。
大模型 + 向量库
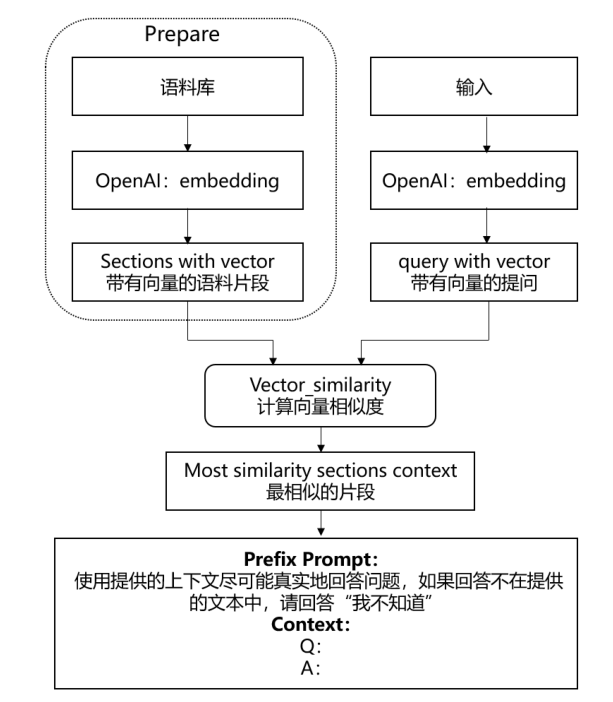
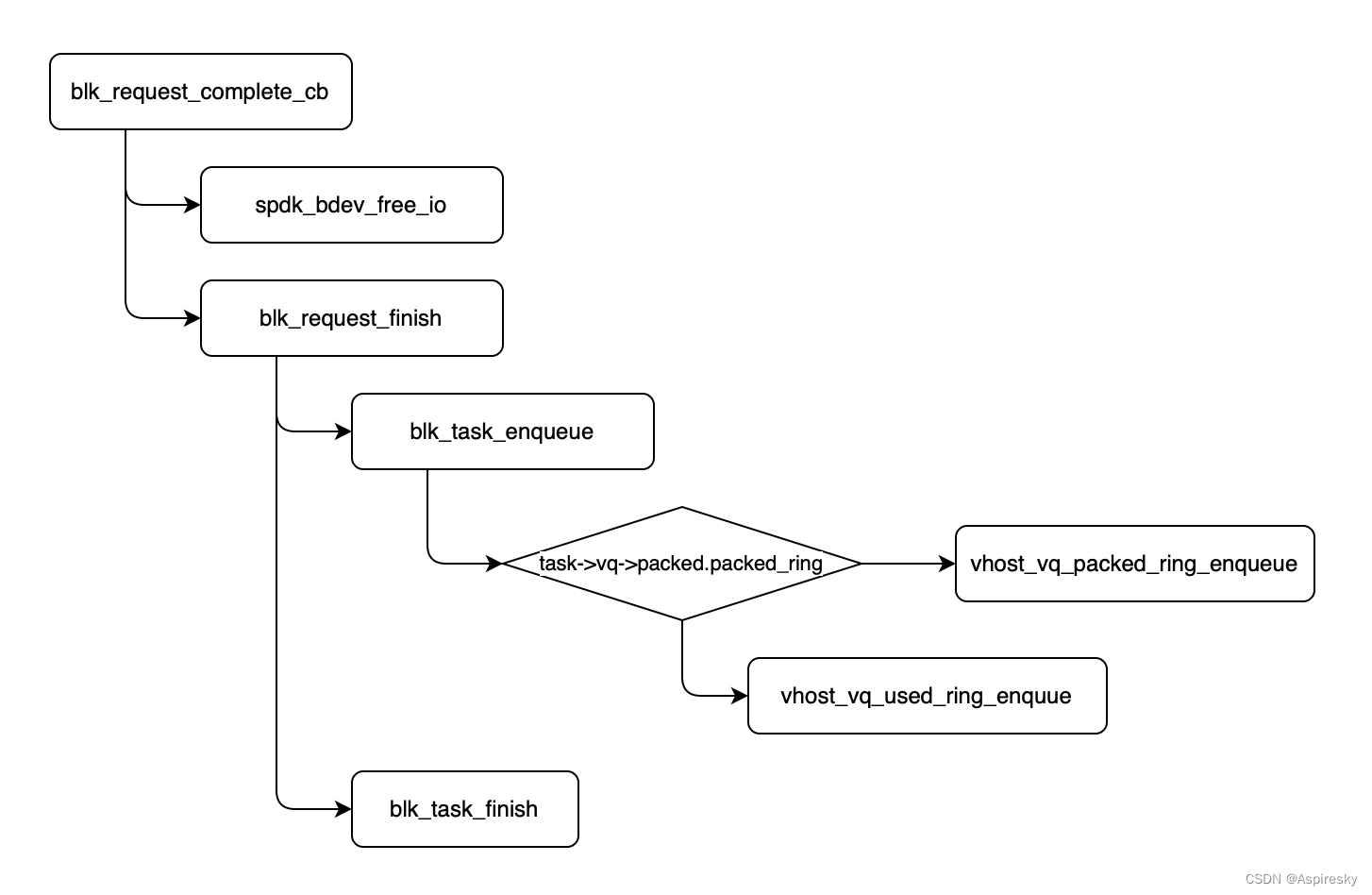
Step 1 语料库准备:
- 将与行业相关的大量知识或语料上传至向量数据库,储存为向量化文本;
Step 2 问题输入:
- 输入的问题被Embedding引擎变成带有向量的提问;
Step 3 向量搜索:
- 向量化问题进入提前准备好的向量数据库中,通过向量搜索引擎计算向量相似度,匹配出Top N条语义最相关的答案
Step 4 Prompt优化:
- 输出的Top N条Facts,和用户的问题一起作为prompt输入给模型。
Step 5 结果返回:
- 有记忆交互下得到的生成内容更精准且缓解了幻觉问题。
YOLO + 向量数据库
假设你正在使用YOLO模型来识别和分类眼底图像中的疾病,比如糖尿病性视网膜病变、青光眼等。
不使用向量数据库的情况:
- 每次识别都需要YOLO模型从头开始处理图像,并实时输出分类结果。
- 对于历史数据的搜索和比较可能需要重新运行模型或手动检查。
- 难以进行大规模的相似案例搜索,比如寻找有相似视网膜特征的病例进行对比分析。
- 每次查询都是独立的,不利用先前的计算结果和数据。
使用向量数据库的情况:
- YOLO模型可以将识别到的特征(例如视盘、视杯、血管异常等)转换为向量,并存储在向量数据库中。
- 一旦存储了特征向量,就可以快速进行相似性搜索,找到具有类似病理特征的其他眼底图像。
- 可以实现快速的案例检索,帮助医生进行诊断对比,或者用于研究和教育目的。
- 可以跟踪病情的进展,通过比较新旧图像的特征向量来观察病变的变化。
- 可以更高效地管理和利用存储的数据,为大数据分析和机器学习提供支持,可能还能发现新的疾病模式或趋势。
假设一个医院收集了数千张眼底图像,并使用YOLO模型来识别各种疾病标志。
如果没有向量数据库,每次新的病例来临时,医生可能需要手动查找和比较历史病例来辅助诊断。
这不仅费时,而且无法保证一致性和准确性,特别是在病例数量庞大时。
如果使用向量数据库,YOLO模型可以将每张图像中识别出的疾病标志转换为特征向量并存储。
当新病例来临时,模型会对新眼底图像进行分析,并将其特征向量与数据库中现有的向量进行比较。
这样可以迅速找到历史病例中与新病例具有相似特征的图像,为医生提供即时的、数据驱动的参考。
此外,医生还可以追踪特定患者的病情变化,通过比较同一患者不同时间点的眼底图像的特征向量。
用与不用向量数据库的具体区别:
- 诊断速度和效率:使用向量数据库可以大大加快诊断过程,因为相似性搜索可以即时完成。
- 诊断一致性:数据库可以帮助医生获得一致的比较结果,而不是依赖个人的记忆或手动搜索。
- 数据驱动的洞见:通过分析存储的特征向量,可能发现新的疾病模式或趋势,这对于医学研究和临床实践都是非常宝贵的。
- 患者跟踪和管理:医生可以更容易地跟踪患者的病情进展,并根据历史数据进行有效管理。
那俩者怎么结合呢?
使用YOLO模型和向量数据库进行目标检测和检索涉及几个步骤:
-
数据准备:
- 收集并标注眼底图像数据集。
- 对图像进行预处理,如调整大小、归一化等。
-
YOLO模型训练:
- 使用标注好的眼底图像数据集训练YOLO模型。
- 训练完成后,模型应能够在眼底图像中识别出疾病标志。
-
特征提取:
- 将训练好的YOLO模型应用于眼底图像。
- 模型将输出每个检测到的对象的边界框、类别标签和特征向量。
-
构建向量数据库:
- 设计数据库架构,用于存储特征向量以及与之关联的元数据(如图像ID、诊断结果等)。
- 选择适合高维向量检索的数据库系统,如使用Faiss、Annoy、Elasticsearch等。
-
存储特征向量:
- 将YOLO提取出的特征向量存储到向量数据库中。
- 确保数据库有适当的索引结构,以支持高效的检索。
-
实现检索功能:
- 开发一个界面或API,允许用户提交新的眼底图像。
- 使用YOLO模型提取新图像的特征向量。
- 将提取出的特征向量与数据库中存储的向量进行比较,找出最相似的匹配项。
-
使用检索结果:
- 将检索结果(相似的眼底图像或案例)展示给医生或研究人员。
- 结合医生的专业知识和模型的检索结果进行诊断或研究分析。
假设医生想要诊断一个新的眼底图像,以确定是否有糖尿病性视网膜病变的迹象。
医生通过界面上传图像,系统自动进行以下步骤:
- 使用YOLO模型对上传的图像进行处理,模型检测图像中的特征并生成特征向量。
- 特征向量被送到向量数据库进行检索,数据库快速返回最相似的历史案例。
- 医生收到系统提供的相似案例,这些案例包含历史图像、诊断信息和其他相关数据。
- 医生可以查看匹配的案例并参考这些信息,辅助自己作出诊断决策。
使用向量数据库可以大大加快医生访问和比较历史案例的速度,提高工作效率,并可能提高诊断的准确性。
嵌入(Embedding)设计
嵌入的核心思想是将每个单词或短语映射到一个高维空间(通常是数百到数千维)中的点。
这些点的相对位置可以表示不同单词之间的语义关系,例如同义词会在高维空间中彼此靠近,而无关的词则会相距较远。
举个例子:假设我们有三个单词:“猫”、“狗”和“汽车”。
在一个良好构建的嵌入空间中,“猫”和“狗”的向量会比“猫”和“汽车”的向量更为接近,因为“猫”和“狗”在语义上更相关(都是宠物),而“汽车”则与这两者在语义上相距较远。
设计步骤:
-
预处理文本数据:
- 清洗文本:去除无关字符、标点符号、HTML标签等。
- 分词(Tokenization):将文本分解成单词、短语或其他有意义的字符序列。
- 归一化(Normalization):转换为统一的大小写,进行词干提取(Stemming)或词形还原(Lemmatization)。
-
构建词汇表:
- 根据预处理后的文本,创建一个唯一单词的集合,称为词汇表。
- 可能会设置最小出现频率,排除出现次数过少的单词。
- 特殊标记:如未知词(UNK)、句子开始(SOS)、句子结束(EOS)等。
-
选择嵌入方法:
- One-hot Encoding:最简单的方法,每个单词由一个大向量表示,该向量中只有一个元素是1,其余都是0。
- Word Embeddings:
- 预训练嵌入(如Word2Vec、GloVe):使用大型文本语料库训练得到的,能够捕捉语义关系的密集向量。
- 自定义训练嵌入:在特定任务上从头开始训练得到的嵌入向量。
- 上下文嵌入(如BERT、GPT):生成的嵌入向量不仅取决于单词本身,还取决于单词在句子中的上下文。
-
嵌入向量的维度选择:
- 嵌入向量的维度通常是超参数,需要根据问题的复杂性和训练数据的大小进行调整。
- 维度越大,模型的表达能力越强,但计算量也越大,且可能导致过拟合。
-
训练嵌入层:
- 如果使用预训练的嵌入,可以直接加载到模型中,也可以进一步在特定任务上进行微调。
- 如果是自定义训练,将嵌入层作为模型的一部分,通过误差反向传播进行训练,学习到最适合当前任务的嵌入向量。
-
处理OOV(Out-of-Vocabulary)问题:
- 对于在词汇表中不存在的单词,通常会用特殊的UNK向量表示。
- 可以通过子词嵌入(如Byte-Pair Encoding)处理未知单词,将单词分解为更小的单位。
-
优化和评估:
- 使用验证集评估嵌入层对于任务的有效性。
- 调整嵌入层的参数或训练策略,以提高模型性能。
- 可视化嵌入向量,检查语义关系是否符合预期(如使用t-SNE技术)。
最近邻搜索
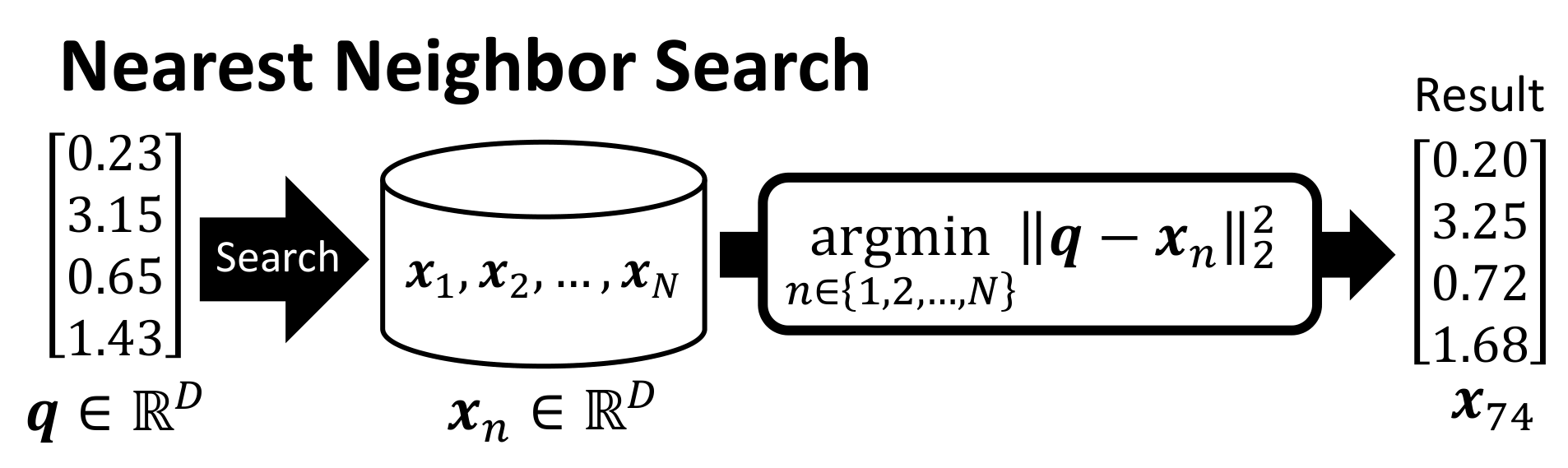
在D维空间中的查询向量q与一组向量x_1, x_2, ..., x_N进行比较,以找到最近的向量。
数学表达式是查询向量q与每个数据库向量x_n之间的平方欧几里得距离的argmin。
结果是查询q的最近向量x_74。

两种寻找最近邻的实现方式:
- 一种是简单的朴素实现
- 另一种是使用Facebook AI Research (FAIR)的Faiss库的快速实现。
朴素实现非常直接,使用简单的循环计算q和x之间的平方差。
Faiss实现,对查询数量较少的情况(M <= 20)使用SIMD(单指令多数据)以及对查询数量较多的情况使用BLAS(基本线性代数子程序)进行计算。
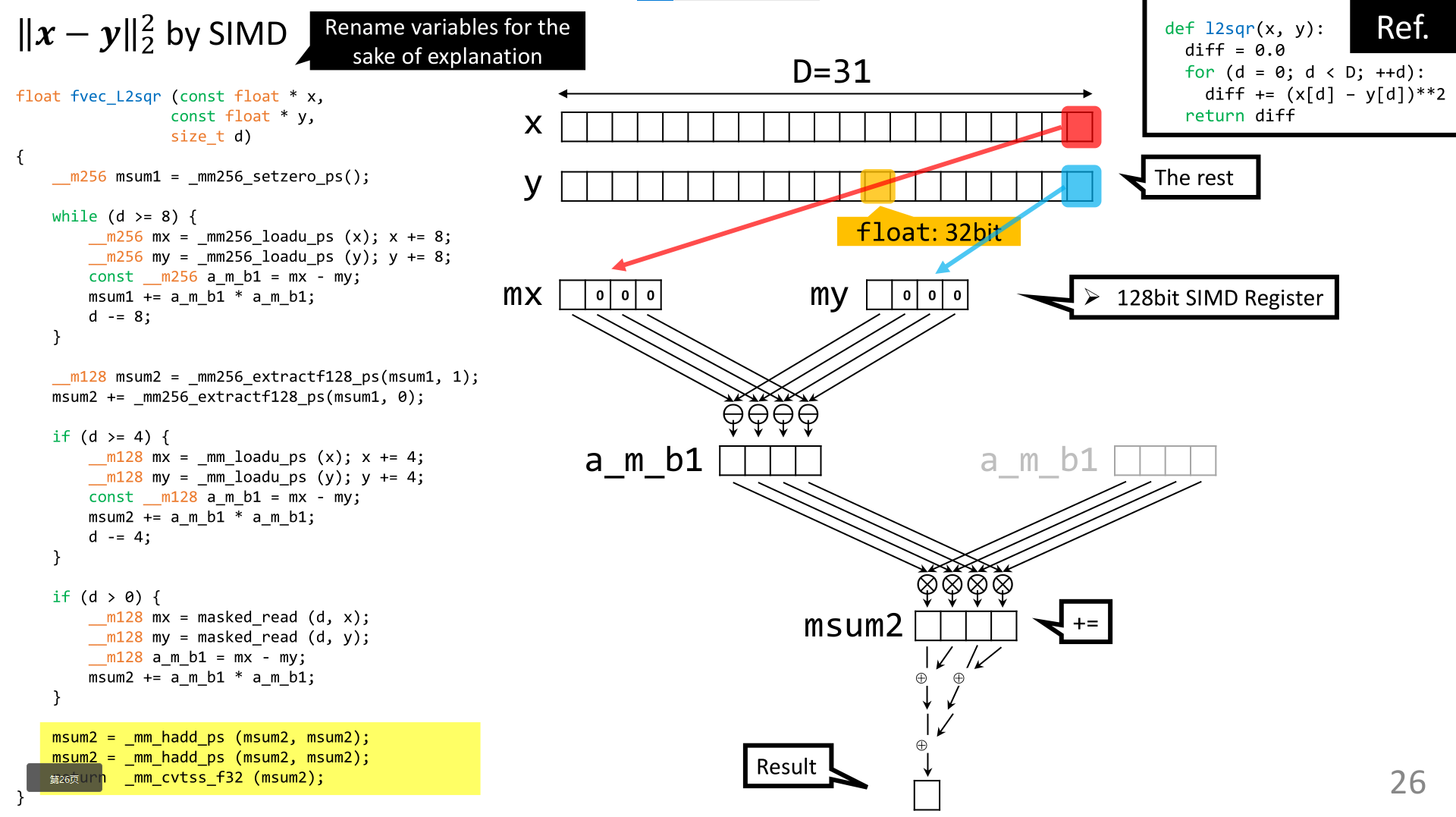
上图介绍了,向量如何组装进SIMD寄存器以及计算过程以达到结果。
如何使用SIMD指令计算平方欧几里得距离,这些指令允许并行计算,可以显著加快计算速度。

如何利用SIMD和BLAS进行大规模矩阵计算。
上图展示了如何将查询向量和数据库向量堆叠成矩阵,并使用sgemm函数(BLAS的矩阵乘法函数)来高效计算内积。
它还指出了不同BLAS实现之间的性能差异,比如Intel MKL和OpenBLAS,其中Intel MKL报告称比OpenBLAS快30%。
主要主题是最近邻搜索的优化,特别关注如何使用高级技术如SIMD和优化的库如BLAS高效计算高维向量之间的距离。
结论是,通过使用这些高级技术,可以在最近邻搜索中实现显著的性能提升,这对于机器学习和数据检索中的许多应用至关重要。
近似近邻搜索
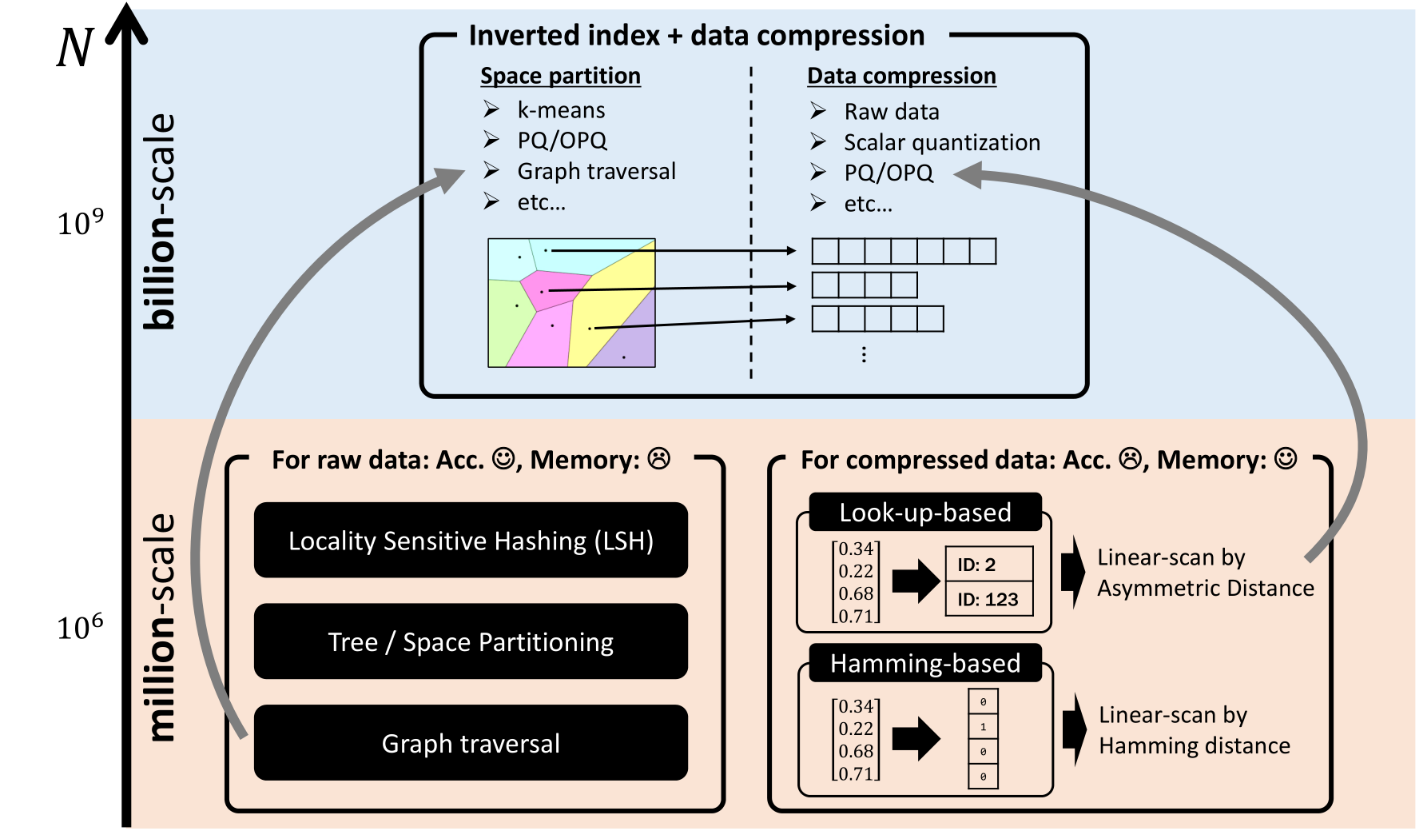
在不同数据规模下,原始数据与压缩数据处理的对比。
左侧是为原始数据设计的方法,如局部敏感哈希(LSH)、树/空间划分和图遍历,这些方法在较小规模的数据集上表现良好。
右侧是为压缩数据设计的方法,包括查找表和哈明距离基础上的线性扫描,适用于更大规模的数据集。
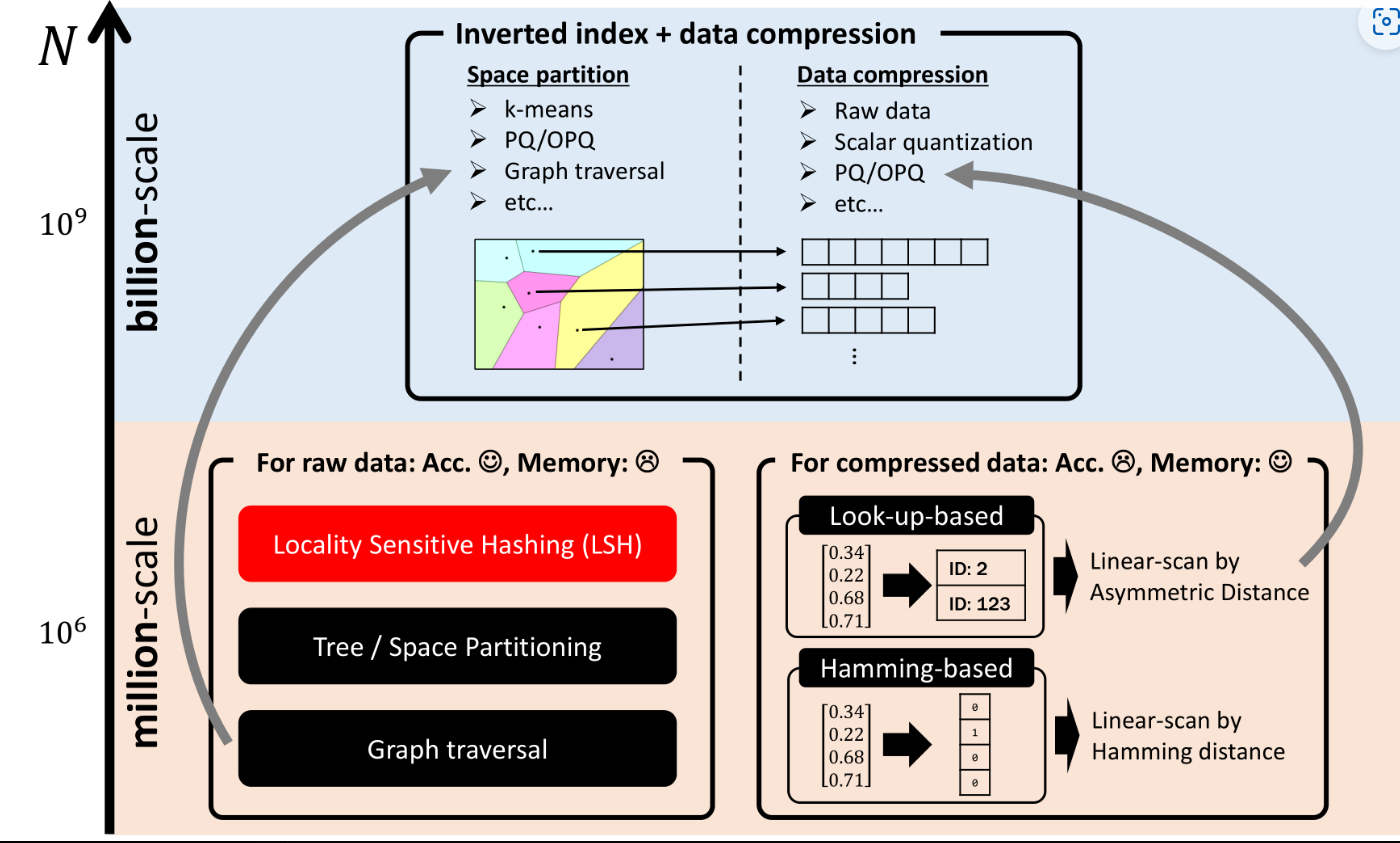
几乎与上图相同,但它标记了局部敏感哈希(LSH)方法,可能是为了强调这种方法在处理原始数据时的重要性。
MinHash-LSH 哈希模糊去重:如何解决医学大模型的大规模数据去重?
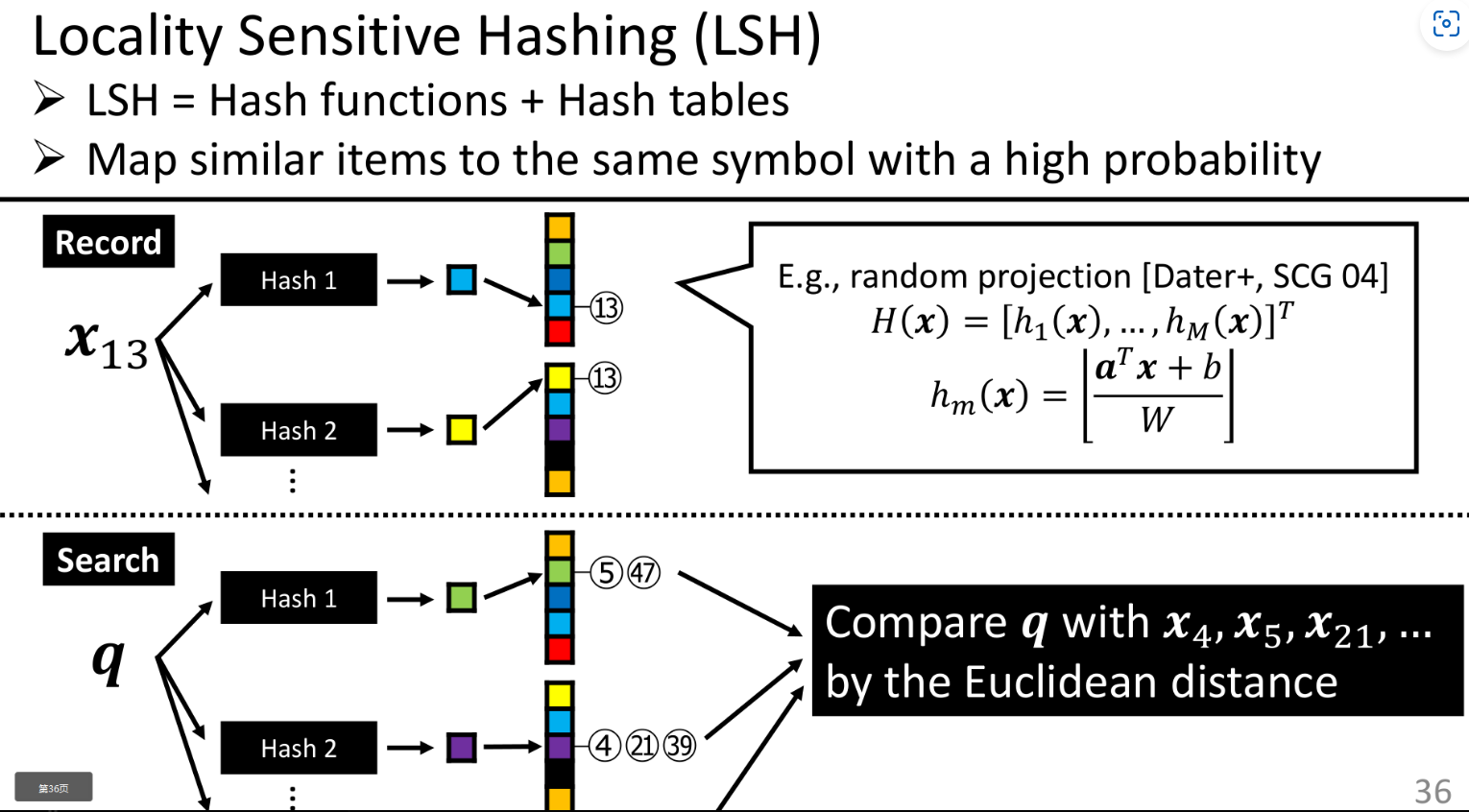
详细介绍了局部敏感哈希(LSH)的工作原理,它是一种通过哈希函数将相似项映射到相同符号的概率很高的技术。
图中展示了数据记录时如何应用多个哈希函数,并在搜索时如何使用相同的哈希函数来定位可能的候选项,然后通过欧几里得距离进行比较。