因为用到了某家带bpu的(懂的都懂) 他们支持这个只是demo做的有点差 还没有c++的~~
因为他们用所以就搬来了 勿怪啊 基于昨天和他们相关的tops 又说说这个!!
FCOS是一种基于全卷积的单阶段目标检测算法,并且是一种Anchor box free的算法。其实现了无Anchor,无Proposal,并且提出了Center-ness的思想,极大的提升了Anchor-Free目标检测算法的性能。
全卷积单阶段目标检测
类型:基于multy-level的目标检测模型
Paper link:https://arxiv.org/pdf/1904.01355.pdf
Code link:https://github.com/tianzhi0549/FCOS
anchor box 的弊端:
1.太多超参数,调试复杂
检测性能对anchor的尺寸、宽高比、数量十分敏感。比如RetinaNet中,调整超参数能够影响4%的AP在COCO数据集上。因此对于anchor的超参数需要细致调整。
2.难以处理尺度变化很大的目标,尤其是很小的目标
预定义的anchor框尺寸和宽高比是固定的也会妨碍检测模型的泛化性能,检测模型会难以处理尺度变化很大的目标,尤其是很小的目标。
3.通用性差
对于新的检测任务就需要重新设计anchor
4.negative sample 占比太大,正负样本不均衡
为了获得更高的找回率,基于anchor的模型会在输入图像上密集放置anchor框,大多数anchor框在训练阶段被认为是负例,过多的负例加剧了正负样本之间的不平衡。
5.计算复杂
大量的anchor框也会明显增加计算量和内存占用,尤其在iou计算的阶段。
问题:
全卷积FCN神经网络在密集预测任务(语义分割、高度估计、关键点检测、计数)上获得了巨大的成功。作为其中一种高层的视觉任务,目标检测因为用到了anchor,可能是唯一一个没有纯粹全卷积像素级预测的任务了。很自然我们会疑问:我们能通过简单的像素级预测来做目标检测吗,像语义分割中的FCN那样?
现有方法和存在的问题:
一些工作尝试去构造一种FCN-base的框架,如DenseBox、UintBox。具体来说,这些FCN-base的模型直接在特征图的一层的每个空间位置上预测一个4D向量和一个类别。如图1左所示,4D向量 (l,t,r,b)表示该位置到边界框四条边的偏移量。这些模型和语义分割的FCNs很像,除了每个位置需要回归一个4D向量以外。
DenseBox图像金字塔多次重复计算
为了处理不同尺寸的边界框,DenseBox将训练样本缩放成固定尺寸,从而在特征金字塔上进行检测,这和一次计算所有卷积的FCNs理念不同。
重叠处的像素回归的框是不明确的
而且,这些方法主要用在特定区域的检测上,比如场景文字检测和人脸检测,因为边界框大大重叠,所以这方法不适合在通用目标检测上使用。如图1右所示,高度重叠的边界框会给训练带来问题:重叠处的像素回归的框是不明确的。

如左图所式,FCOS预测一个4D向量 (l,t,r,b)来编码每个前景像素点对应边界框的位置(训练时由ground-truth监督)。右图展示了一个像素点对应多个边界框,这可能会给边界框的回归带来问题。
解决方法
1.使用FPN可以大幅度减弱目标分类和回归的这种不明确性。
2.“中心度”(center-ness)分支来预测一个像素到对应边界框中心的偏移,差的边界框会被”中心度“分支抑制
这种新的检测模型有如下优势:
- 检测和其他FCNs的任务(如语义分割)统一,使它便于在任务间复用。
- 检测也可以是proposal free和anchor free的,显著降低参数量。设计参数一般需要多次调整,用上很多tricks来获得好的性能。因此我们新的检测框架使检测模型大大简化,尤其是在训练阶段。而且我们的方法完全避免了anchor的复杂的iou计算和匹配,降低了两倍的内存占用。
- 毫无疑问,我们达到了单阶段检测器sota的性能,而且我们提出的FCOS也可以用做RPN网络,在其他RPN的双阶段检测器中,达到了更好的性能。考虑到这是一个简单的、anchor free的、性能卓越的模型,我们建议学界重新思考anchor的必要性,而后者在当下被认为是检测中理所应当的标准。
- 提出了模型通过少量调整可以立刻用于解决其他视觉任务,包括实例分割、关键点检测。我们相信这种新的方法可以成为实例级预测问题的新的baseline。
方法
在这首先推导目标检测在像素级预测范式中的形式。其次展示了如何利用多层预测来提高召回率,解决训练中重叠边界框的不确定性的问题。最后,提出了“中心度”分支,抑制差的检测框,大幅度提高总体性能。
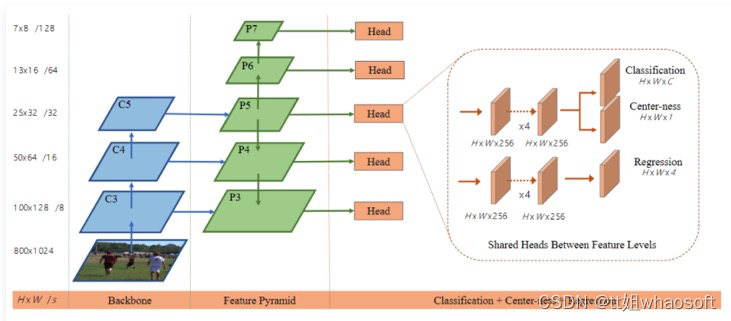
1.网络结构
FCOS采用的网络架构和RetinaNet一样,都是采用FPN架构,如图2所示,每个特征图后是检测器,检测器包含3个分支:classification,regression和center-ness。
2.正负样本定义

如果其落在任何GT的中心区域,就认为这个位置为正样本,并负责预测这个GT,在映射后的该点直接回归目标框,而不是把这个点看成目标框的中心点进行回归;否则为负样本。如果落在多个GT的区域内,则称其为模糊样本(ambiguous)。
3.FPN结构和ambiguous样本的处理
重叠框会在训练过程中带来二义性模糊的问题,因为重叠区域的像素需要判断:我到底该去回归哪个框呢?这是导致FCN based模型性能较差的一个原因。对于anchor-based方法,采用FPN时会将不同大小的anchor放置在不同大小的特征图上,特征图越小,感受野相应更大,用来检测更大的物体。同样地,这种设计理念可以用在FCOS模型上,以解决前面所说的模糊样本问题。

上python
class Scale(nn.Module):
def __init__(self, init_value=1.0):
super(Scale, self).__init__()
self.scale = nn.Parameter(torch.FloatTensor([init_value]))
def forward(self, input):
return input * self.scale但是现在的版本中,前面已经提到每个特征图上的回归值其实是已经除以特征图的 s 进行缩放,这样就和学习一个scale值基本等同,所以加不加这个策略都可以。
模糊样本的出现大部分是由于物体重叠造成的,但是重叠的物体大部分其大小是不同的,所以FPN的使用可以更一步解决模糊样本问题。
4.网络输出和loss定义
- classification分支
和RetinaNet一样采用 C 个二分类,classification分支共输出C个预测值,loss采用focal loss。
2. regression分支
regression分支每个位置预测一个实数向量 t=(l,t,r,b) ,其对应的target为当前位置与GT框4个顶点间的距离:
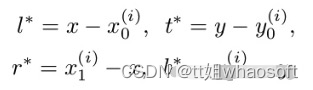
loss计算使用的是IOU loss。
3. ceterness分支
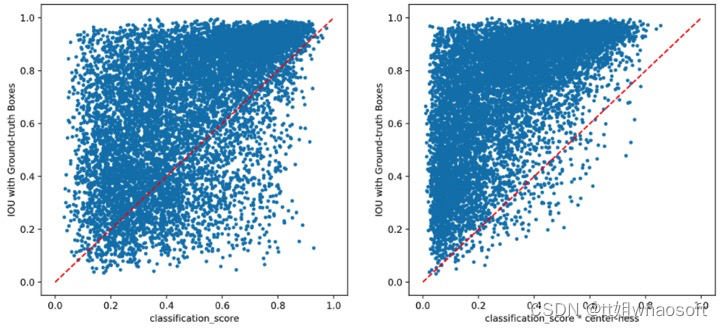
FCOS在regression分支的末尾添加了一个额外的center-ness分支(最早的版本是放在classification分支,但是放在regression分支效果更好)来抑制那些由那些偏离目标中心的位置所预测的低质量检测框。center-ness分支只预测一个值:当前位置与要预测的物体中心点之间的归一化距离,值在[0, 1]之间,图4给出了可视化效果,其中红色和蓝色值分别1和0,其它颜色介于两者之间,从物体中心向外,center-ness从1递减为0。
给定回归的 target=(l∗,t∗,r∗,b∗) ,center-ness的target定义为:

centerness 可视化
centerness 的loss计算使用BCE损失。
最终的loss是三个loss相加。(以下是分类和回归loss)
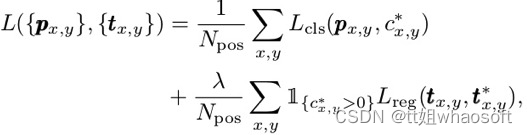
在测试阶段,最终的置信度为center-ness和分类概率的乘积:
六、实验
简要提一下,日后如果感兴趣再补。
COCO训练集上训练,验证集上测试和消融研究,在测试集上提交得到最终结果。
如果没额外说明:
训练: 主干resnet50,优化器SGD训练90K次迭代,初始学习率0.01,batchsize=16,学习率在60K和80K次迭代时减小10倍,衰减系数1e-4,动量0.9。用ImageNet预训练模型,RetinaNet中的初始化方法初始化其他参数,输入图像短边固定在800,长边小于等于1333。
预测: 输入图像经过模型,后处理和RetinaNet相同(包括超参数)。
消融分析
- BPR:我们看到RetinaNet还是很强的,但是在使用了多层级FPN预测后,FCOS的召回也很棒。
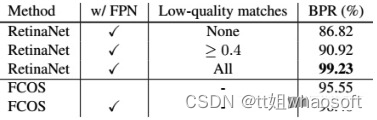
- 二义性样本:使用了FPN后,二义性样本减小明显(第二列为不同类别的二义性样本个数)。

- FPN:FPN同样提升了10几个点

- 候选框数量、存储:因为没有anchor,所以对比单个像素点上9个anchor框少了9倍的候选框数量就很显然了,与此同时,显存占用也只有一半,性能总体没掉,甚至看AP还比RetinaNet高。

- 中心度:从上至下分别是没用中心度、使用每个像素上回归出来的向量计算得到中心度(间接的方法)、使用文中提到的额外分支预测的中心度(直接的方法+)。可见这个额外分支虽然只有单层,但在全指标上都有明显的提升。

- RPN:FCOS可以作为two-stage模型的RPN网络,提了不少点。

- 模型对比:文中结果看看起来基本稳坐one-stage方法第一的宝座。但模型共享了头部网络,也减小了anchor算iou的计算量,但是全文通篇没有提到前向速度。我姑且估计是因为ResNe(X)t-50/101+FPN的多层级预测减慢了速度,可以跑跑开源代码试试。
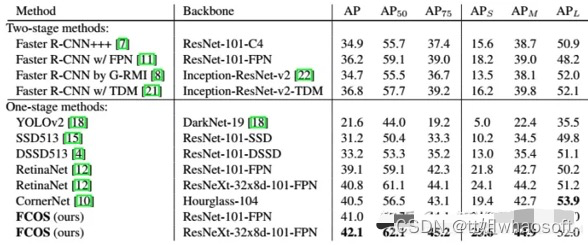
- 改进(这个作者不放在算法设计部分而是放在实验部分,不起眼但是很重要):
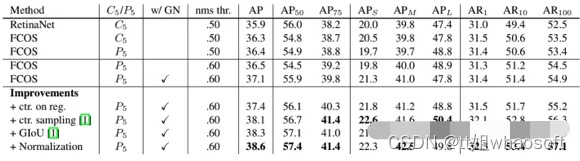
-
- “ctr. on reg.”: 将 center-ness分支移到regression branch.
- “ctr. sampling”: 只采样中心点附近的 ground-truth boxes作为正样本.
- “GIoU”: 使用GIOUloss
- “Normalization”: 将regression targets 除以 the strides:
- centerness可视化
如左图所式,FCOS预测一个4D向量 (l,t,r,b)来编码每个前景像素点对应边界框的位置(训练时由ground-truth监督)。右图展示了一个像素点对应多个边界框,这可能会给边界框的回归带来问题。
分类得分乘以ceterness之后,,低质量的不准的框大大减少,相当于减少了FP.
下面在复习一下~~ whaosoft aiot http://143ai.com
经典单阶段Anchor-Free目标检测模型
Anchor free的好处是:
- 避免了Anchor Box带来的复杂计算,如计算重合度IoU;
- 避免了Anchor Box相关的超参数设置,其对性能影响较大;
因此,FCOS的优点是:
- 其可以和其他使用FCN结构的任务相统一,方便其他任务方法之间的re-use
- proposal free和anchor free,减少了超参数数量,更简单
- 减少了计算复杂度,如IoU计算
- FCOS在单阶段算法中性能不错,并且证明了FCOS替换两阶段算法里的RPNs也可以取得更好的性能
- 适用于各种instance-wise的预测问题
FCOS包含三个大模块:


正负样本定义
一个目标检测算法性能的优异性,最大影响因素就是如何定义正负样本。而FCOS的定义方式非常通俗易懂。主要分为两步: (1) 设置regress_ranges=((-1, 64), (64, 128), (128, 256), (256, 512),(512, INF),用于将不同大小的bbox分配到不同的FPN层进行预测即距离4条边的最大值在给定范围内 (2) 设置center_sampling_ratio=1.5,用于确定对于任意一个输出层距离bbox中心多远的区域属于正样本(基于gt bbox中心点进行扩展出正方形,扩展范围是center_sample_radius×stride,正方形区域就当做新的gt bbox),该值越大,扩张比例越大,选择正样本区域越大;(细节:如果扩展比例过大,导致中心采样区域超过了gt bbox本身范围了,此时需要截断操作)
损失函数
上面已经发了~~!!
Center-ness的计算公式如下,其范围为0-1,训练阶段使用BCE Loss并和之前的损失函数相加,测试阶段用于加权预测得分:
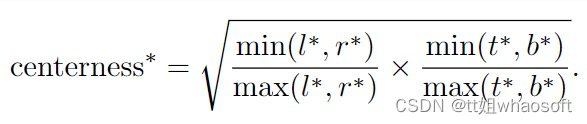
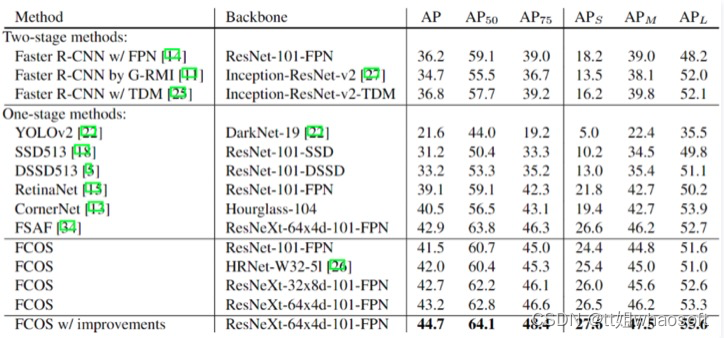
实验结果
对比实验结果:
有无Center-ness分支的消融实验:

替换RPN的消融实验:








![[SpringBoot] 多模块统一返回格式带分页信息](https://img-blog.csdnimg.cn/2c616a4ab4f14f8ba67f1385beff5ba2.png)