本系列将持续更新NLP相关模型与方法,欢迎关注!
简介
神经网络语言模型(NNLM)是一种人工智能模型,用于学习预测词序列中下一个词的概率分布。它是自然语言处理(NLP)中的一个强大工具,在机器翻译、语音识别和文本生成等领域都有广泛的应用。
Paper - A Neural Probabilistic Language Model(2003)[1]
原理
NNLM 首先学习词的分布式表示,也称为词嵌入,它捕捉了词之间的语义相似性。然后将这些嵌入输入到神经网络模型中,通常是一个前馈神经网络或循环神经网络(RNN),该模型根据前面的词提供的上下文来学习预测序列中的下一个词。
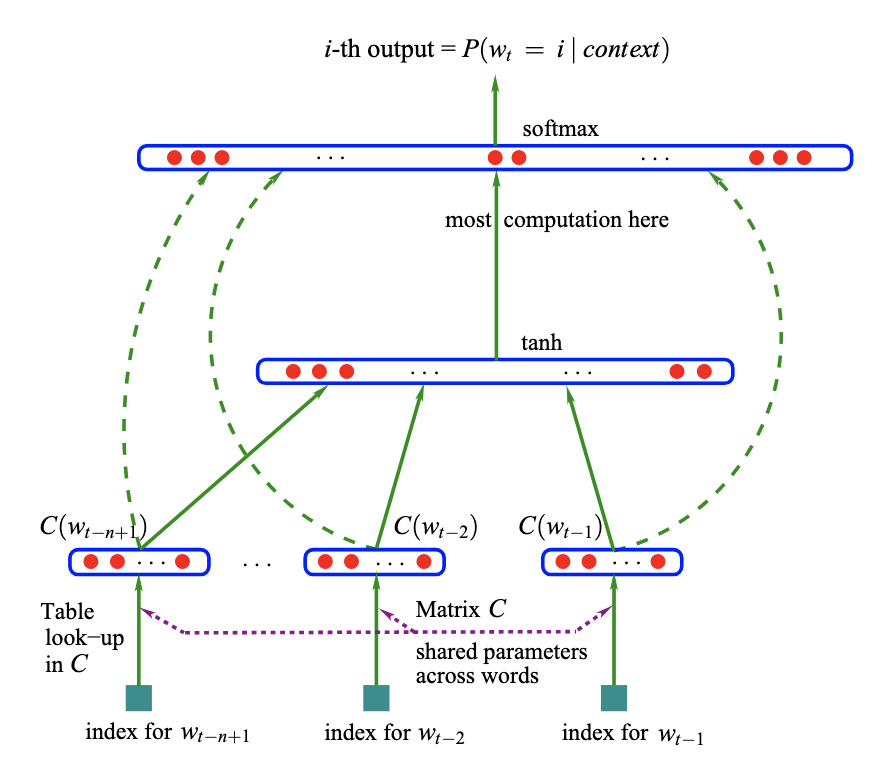
例如,给定句子“猫在坐在”,NNLM 可能会高概率地预测下一个词为“地板”,因为这是给定上下文的常见补充。
示例
假设我们有一个大型的文本语料库,比如一系列新闻文章。我们可以对这些数据进行 NNLM 训练,以学习单词和它们上下文之间的关系。训练完成后,模型可以生成连贯和与上下文相关的句子。
例如,如果我们提供初始短语“人工智能是”,NNLM 可能生成以下完成句子:“人工智能正在改变行业,重塑未来的工作。”
应用
-
机器翻译: NNLM 在机器翻译系统中发挥作用,通过预测源语言上下文的下一个词来生成流畅且准确的翻译。 -
语音识别: NNLM 在语音识别系统中起着至关重要的作用,通过从口语表达中预测最可能的词序列。 -
文本生成: NNLM 在各种文本生成任务中使用,包括对话生成、故事生成和内容摘要,在这些任务中,它们基于给定的输入生成连贯且与上下文相关的文本。 -
语言建模: NNLM 作为语言建模任务的基础,用于估计在给定上下文中序列单词发生的概率。这在拼写检查、自动完成和语法错误检测等任务中特别有用。
Code
# code by Tae Hwan Jung @graykode
import torch
import torch.nn as nn
import torch.optim as optim
def make_batch():
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split() # space tokenizer
input = [word_dict[n] for n in word[:-1]] # create (1~n-1) as input
target = word_dict[word[-1]] # create (n) as target, We usually call this 'casual language model'
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch
# Model
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Linear(n_step * m, n_hidden, bias=False)
self.d = nn.Parameter(torch.ones(n_hidden))
self.U = nn.Linear(n_hidden, n_class, bias=False)
self.W = nn.Linear(n_step * m, n_class, bias=False)
self.b = nn.Parameter(torch.ones(n_class))
def forward(self, X):
X = self.C(X) # X : [batch_size, n_step, m]
X = X.view(-1, n_step * m) # [batch_size, n_step * m]
tanh = torch.tanh(self.d + self.H(X)) # [batch_size, n_hidden]
output = self.b + self.W(X) + self.U(tanh) # [batch_size, n_class]
return output
if __name__ == '__main__':
n_step = 2 # number of steps, n-1 in paper
n_hidden = 2 # number of hidden size, h in paper
m = 2 # embedding size, m in paper
sentences = ["i like dog", "i love coffee", "i hate milk"]
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # number of Vocabulary
model = NNLM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
input_batch, target_batch = make_batch()
input_batch = torch.LongTensor(input_batch)
target_batch = torch.LongTensor(target_batch)
# Training
for epoch in range(5000):
optimizer.zero_grad()
output = model(input_batch)
# output : [batch_size, n_class], target_batch : [batch_size]
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
# Predict
predict = model(input_batch).data.max(1, keepdim=True)[1]
# Test
print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
总的来说,神经网络语言模型(NNLM)是自然语言处理中的强大工具,利用神经网络架构来预测文本序列中的下一个词。从机器翻译到文本生成,NNLM 继续推动人工智能在理解和生成人类语言方面的能力。
paper: http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
本文由 mdnice 多平台发布






![[计算机网络]深度学习传输层TCP协议](https://img-blog.csdnimg.cn/38b404e2e60b4b838209e68406184347.gif#pic_center#pic_center#pic_center#pic_center#pic_center)