昨天白天,「现实不存在了」开始全网刷屏。
「我们这么快就步入下一个时代了?Sora简直太炸裂了」。

「这就是电影制作的未来」!

谷歌的Gemini Pro 1.5还没出几个小时的风头,天一亮,全世界的聚光灯就集中在了OpenAI的Sora身上。
Sora一出,众视频模型臣服。

就在几小时后,OpenAI Sora的技术报告也发布了!
其中,「里程碑」也成为报告中的关键词。

报告地址:https://openai.com/research/video-generation-models-as-world-simulators
技术报告主要介绍了两个方面:
(1)如何将不同类型的视觉数据转化为统一的格式,以便于对生成模型进行大规模训练的方法;
(2)对Sora的能力和局限性的定性评价。
不过遗憾的是,报告不包括模型和实现细节。嗯,OpenAI还是那个「OpenAI」。
就连马斯克都被Sora生成效果震撼到,并表示「gg人类」。
打造虚拟世界模拟器
此前,OpenAI的研究者一直在探索的一个难题就是,究竟怎样在视频数据上,应用大规模训练的生成模型?
为此,研究者同时对对持续时间、分辨率和宽高比各不相同的视频和图片进行了训练,而这一过程正是基于文本条件的扩散模型。
他们采用了Transformer架构,这种架构能够处理视频和图片中时空片段的潜代码。
随之诞生的最强大模型Sora,也就具备了生成一分钟高质量视频的能力。
OpenAI研究者发现了令人惊喜的一点:扩展视频生成模型的规模,是构建模拟物理世界通用模拟器的非常有希望的方向。
也就是说,顺着这个方向发展,或许LLM真的能够成为世界模型!
Sora的独到之处在于哪里?
要知道,以前的许多研究,都是通过各种技术对视频数据进行生成模型建模,比如循环网络、生成对抗网络、自回归Transformer和扩散模型等方法。
它们往往只关注于特定类型的视觉数据、较短的视频或者固定尺寸的视频。
而Sora与它们不同,它是一种通用的视觉数据模型,能够生成各种持续时间、宽高比和分辨率的视频和图片,甚至长达一分钟的高清视频。
有网友表示,「Sora虽然有一些不完美之处(可以检测出来),例如从物理效果可以看出它是人工合成的。但是,它将会革命性地改变许多行业。
想象一下可以生成动态的、个性化的广告视频进行精准定位,这将是一个万亿美元的产业」!

为了验证SORA的效果,业界大佬Gabor Cselle把它和Pika、RunwayML和Stable Video进行了对比。
首先,他采用了与OpenAI示例中相同的Prompt。
结果显示,其他主流工具生成的视频都大约只有5秒钟,而SORA可以在一段长达17秒视频场景中,保持动作和画面一致性。

随后,他将SORA的起始画面用作参照,努力通过调整命令提示和控制相机动作,尝试使其他模型产出与SORA类似的效果。
相比之下,SORA在处理较长视频场景方面的表现显著更出色。

看到如此震撼的效果,也难怪业内人士都在感叹,SORA在AI视频制作领域确实具有革命性意义。
将视觉数据转化为patch
LLM之所以会成功,就是因为它们在互联网规模的数据上进行了训练,获得了广泛能力。
它成功的一大关键,就是使用了token,这样,文本的多种形态——代码、数学公式以及各种自然语言,就优雅地统一了起来。
OpenAI的研究者,正是从中找到了灵感。
该如何让视觉数据的生成模型继承token的这种优势?
注意,不同于LLM使用的文本token,Sora使用的是视觉patch。
此前已有研究表明,patch对视觉数据建模非常有效。
OpenAI研究者惊喜地发现,patch这种高度可扩展的有效表征形式,正适用于训练能处理多种类型视频和图片的生成模型。
从宏观角度来看,研究者首先将视频压缩到一个低维潜空间中,随后把这种表征分解为时空patch,这样就实现了从视频到patch的转换。

视频压缩网络
研究者开发了一个网络,来减少视觉数据的维度。
这个网络可以接受原始视频作为输入,并输出一个在时间上和空间上都进行了压缩的潜表征。
Sora在这个压缩后的潜空间中进行训练,之后用于生成视频。
另外,研究者还设计了一个对应的解码器模型,用于将生成的潜数据转换回像素空间。
潜空间patch
对于一个压缩后的输入视频,研究者提取看一系列空间patch,作为Transformer的token使用。
这个方案同样适用于图像,因为图像可以被视为只有一帧的视频。
基于patch的表征方法,研究者使得Sora能够处理不同分辨率、持续时间和纵横比的视频和图像。
在推理时,可以通过在一个合适大小的网格中适当排列随机初始化的patch,从而控制生成视频的大小。
因此,视频模型Sora是一个扩散模型;它能够接受带有噪声的patch(和条件信息,如文本提示)作为输入,随后被训练,来预测原始的「干净」patch。
重要的是,Sora是基于Transformer的扩散模型。在以往,Transformer在语言模型、计算机视觉和图像生成等多个领域,都表现出卓越的扩展能力。

令人惊喜的是,在这项工作中,研究者发现作为视频模型的扩散Transformer,也能有效地扩展。
下图展示了训练过程中使用固定种子和输入的视频样本比较。
随着训练计算资源的增加,样本质量显著提升。

视频的多样化表现
传统上,图像和视频的生成技术往往会将视频统一调整到一个标准尺寸,比如4秒钟、分辨率256x256的视频。
然而,OpenAI研究者发现,直接在视频的原始尺寸上进行训练,能带来诸多好处。
灵活的视频制作
Sora能够制作各种尺寸的视频,从宽屏的1920x1080到竖屏的1080x1920,应有尽有。
这也就意味着,Sora能够为各种设备制作适配屏幕比例的内容!
它还可以先以较低分辨率快速制作出视频原型,再用相同的模型制作出全分辨率的视频。

更优的画面表现
实验发现,直接在视频原始比例上训练,能够显著提升视频的画面表现和构图效果。
因此,研究者将Sora与另一个版本的模型进行了比较,后者会将所有训练视频裁剪为正方形,这是生成模型训练中的常见做法。
与之相比,Sora生成的视频(右侧)在画面构成上则有了明显的改进。

深入的语言理解
训练文本到视频的生成系统,需要大量配有文本说明的视频。
研究者采用了DALL·E 3中的重新标注技术,应用在了视频上。
首先,研究者训练了一个能生成详细描述的标注模型,然后用它为训练集中的所有视频,生成文本说明。
他们发现,使用详细的视频说明进行训练,不仅能提高文本的准确性,还能提升视频的整体质量。
类似于DALL·E 3,研究者也使用了GPT,把用户的简短提示转化为详细的说明,然后这些说明会被输入到视频模型中。
这样,Sora就能根据用户的具体要求,生成高质量、准确无误的视频。
图像和视频的多样化提示
虽然展示的案例,都是Sora将文本转换为视频的demo,但其实,Sora的能力不止于此。
它还可以接受图像或视频等其他形式的输入。
这就让Sora能够完成一系列图像和视频编辑任务,比如制作无缝循环视频、给静态图片添加动态、在时间线上扩展视频的长度等等。
为DALL·E图像赋予生命
Sora能够接受一张图像和文本提示,然后基于这些输入生成视频。
下面即是Sora基于DALL·E 2和DALL·E 3图像生成的视频。

一只戴贝雷帽和黑高领衫的柴犬

一家五口怪物的插画,采用了简洁明快的扁平设计风格。其中包括一只毛茸茸的棕色怪物,一只光滑的黑色怪物长着天线,还有一只绿色的带斑点怪物和一只小巧的带波点怪物,它们在一个欢快的场景中相互玩耍。

一张逼真的云朵照片,上面写着「SORA」。

在一个典雅古老的大厅内,一道巨浪滔天,正要破浪而下。两位冲浪者把握时机,巧妙地滑行在浪尖上。
视频时间线的灵活扩展
Sora不仅能生成视频,还能将视频沿时间线向前或向后扩展。
可以看到,demo中的视频都是从同一个视频片段开始,向时间线的过去延伸。尽管开头各不相同,但它们最终都汇聚于同一个结尾。


而通过这种方法,我们就能将视频向两个方向延伸,创造出一个无缝的循环视频。

图像的生成能力
同样,Sora也拥有生成图像的能力。
为此,研究者将高斯噪声patch排列在空间网格中,时间范围为一帧。
该模型可生成不同大小的图像,分辨率最高可达2048x2048像素。

左:一位女士在秋季的特写照片,细节丰富,背景模糊。
右:一个生机勃勃的珊瑚礁,居住着五颜六色的鱼类和海洋生物。

左:一幅数字绘画,描绘了一只幼年老虎在苹果树下,采用了精美的哑光画风。
右:一个被雪覆盖的山村,温馨的小屋和壮丽的北极光相映成趣,画面细腻逼真,采用了50mm f/1.2镜头拍摄。
视频风格和环境的变换
利用扩散模型,就能通过文本提示来编辑图像和视频。
在这里,研究者将一种名为SDEdit的技术应用于Sora,使其能够不需要任何先验样本,即可改变视频的风格和环境。

视频之间的无缝连接
另外,还可以利用Sora在两个不同的视频之间创建平滑的过渡效果,即使这两个视频的主题和场景完全不同。
在下面的demo中,中间的视频就实现了从左侧到右侧视频的平滑过渡。
一个是城堡,一个是雪中小屋,非常自然地融进一个画面中。
,时长00:20
,时长00:17
,时长
,时长00:17
涌现的模拟能力
随着大规模训练的深入,可以发现视频模型展现出了许多令人兴奋的新能力。
Sora利用这些能力,能够在不需要专门针对3D空间、物体等设置特定规则的情况下,就模拟出人类、动物以及自然环境的某些特征。
这些能力的出现,完全得益于模型规模的扩大。
3D空间的真实感
Sora能创造出带有动态视角变化的视频,让人物和场景元素在三维空间中的移动,看起来十分自然。
如下,一对情侣漫步在雪天中的东京,视频的生成和真实的运镜效果大差不差了。

再比如,Sora拥有更加辽阔的视野,生成山水风景与人徒步爬山的视频,有种无人机拍摄出的巨制赶脚。

视频的一致性和物体的持续存在
在生成长视频时,保持场景和物体随时间的连续性一直是个挑战。
Sora能够较好地处理这一问题,即便在物体被遮挡或离开画面时,也能保持其存在感。
下面例子中,窗台前的花斑狗,即便中途有多个路人经过,它的样子依旧保持一致。

例如,它可以在一个视频中多次展示同一个角色,而且角色的外观在整个视频中保持一致。
赛博风格的机器人,从前到后旋转一圈,都没有跳帧。

与世界的互动
甚至,Sora能模拟出影响世界状态的简单行为。
比如,画家画的樱花树,水彩纸上留下了持久的笔触。

又或是,人吃汉堡时留下的咬痕清晰可见,Sora的生成符合物理世界的规则。

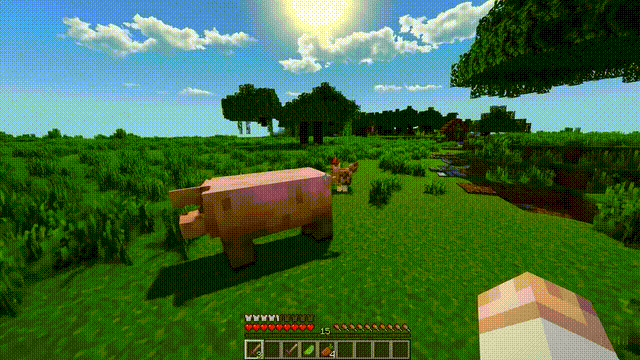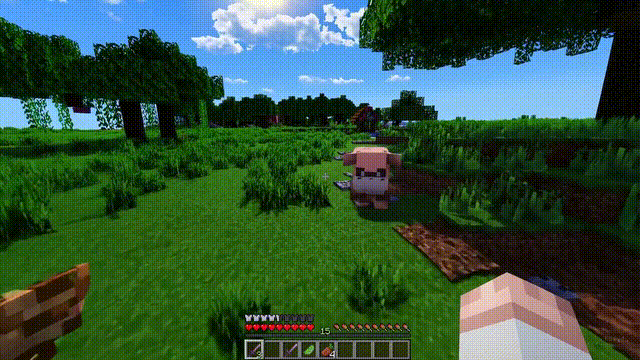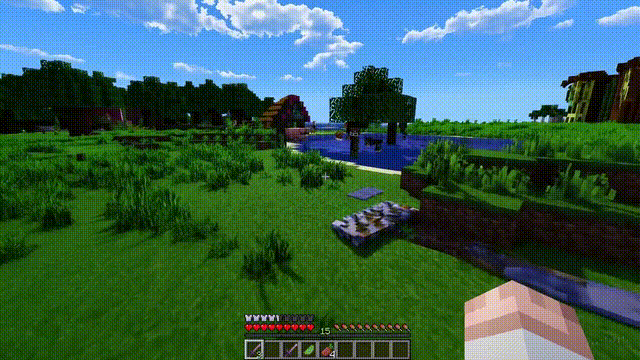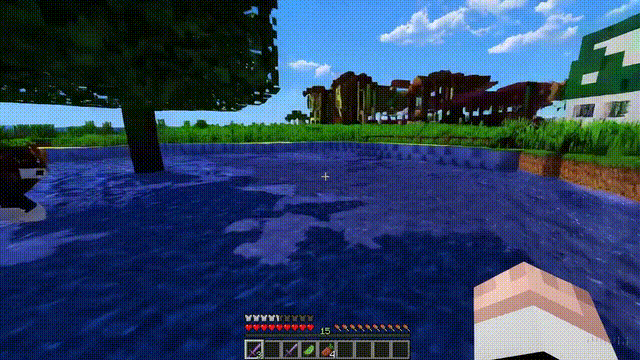
数字世界的模拟
Sora不仅能模拟现实世界,还能够模拟数字世界,比如视频游戏。
以「Minecraft」为例,Sora能够在控制玩家角色的同时,以高度逼真的方式渲染游戏世界和动态变化。
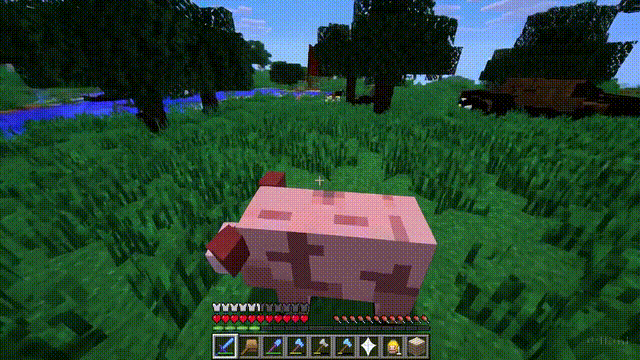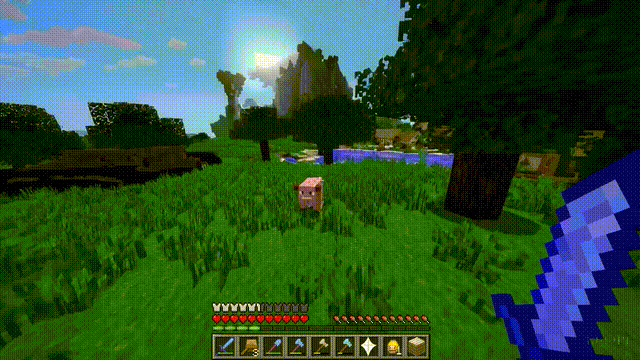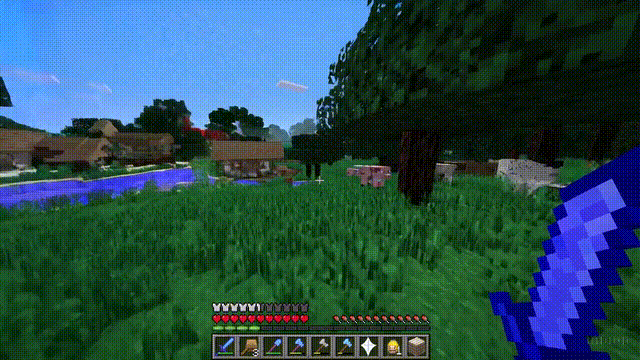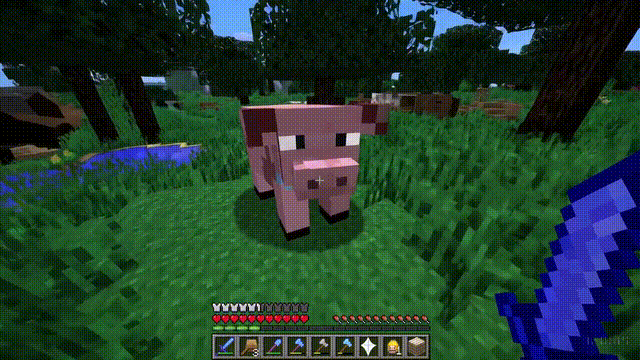
而且,只需通过简单的提示,如提及「Minecraft」,Sora就能展现这些能力。
这些新能力显示出,持续扩大视频模型规模是一个极有希望的方向,让模型向着精准模拟物理世界和数字世界、以及其中的生物和物体的高级模拟器发展。
涌现的模拟能力
当然,作为一个模拟器,Sora目前还存在不少的局限。
比如,它虽然能模拟一些基础物理互动,比如玻璃的碎裂,但还不够精确。

模拟吃食物的过程,也并不总是能准确反映物体状态的改变。
在网站首页上,OpenAI详细列出了模型的常见问题,比如在长视频中出现的逻辑不连贯,或者物体会无缘无故地出现。

最后,OpenAI表示,Sora目前所展现出的能力,证明了不但提升视频模式的规模是一个令人振奋的方向。
沿这个方向走下去,或许有一天,世界模型就会应运而生。
网友:未来游戏动嘴做
OpenAI给出众多的官方演示,看得出Sora似乎可以为更逼真的游戏生成铺路——仅凭文字描述就能生成程序游戏。
这既令人兴奋,又令人恐惧。
FutureHouseSF的联合创始人猜测,「或许Sora可以模拟我的世界。也许下一代游戏机将是「Sora box」,游戏将以2-3段文字的形式发布」。
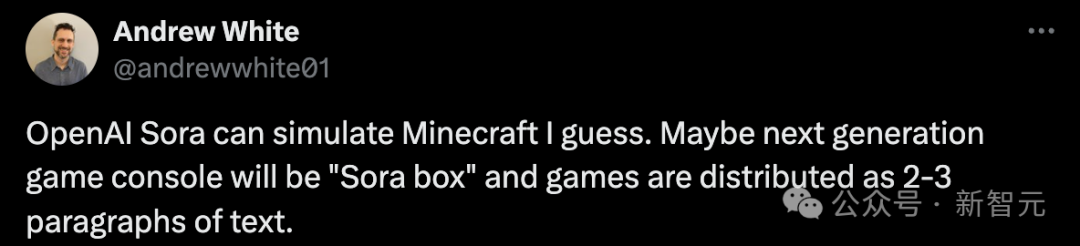
OpenAI技术人员Evan Morikawa称,「在OpenAI发布的Sora视频中,如下的视频让我大开眼界。通过经典渲染器渲染这个场景是非常困难的。Sora模拟物理的方式和我们不同。它肯定仍然会出错,但是我之前没有预测到它能做得这么逼真」。


有网友称,「人们没有把『每个人都会成为电影制作人』这句话当回事」。
我在15分钟内制作了这部20年代的预告片,使用了OpenAI Sora的片段,David Attenborough在Eleven Labs上的配音,并在iMovie上从YouTube上采样了一些自然音乐。


还有人称,「5年后,你将能够生成完全沉浸式的世界,并实时体验它们,「全息甲板」即将变成现实」!
有人甚至表示,自己完全被Sora的AI视频生成的出色效果惊呆了。
「它让现有的视频模型看起来像是愚蠢的玩具。每个人都将成为一名电影制作人」。

「新一代电影制作人即将与OpenAI的Sora一起涌现。再过10年,这将是一场有趣的比赛」!

「OpenAI的Sora暂不会取代好莱坞。它将为好莱坞以及个人电影制作者和内容创作者,带来巨大的推动力。
想象一下,只需3人团队,就能在一周内,完成一部120分钟的A级故事片的初稿创作和观众测试。这就是我们的目标」。







![[Flink01] 了解Flink](https://img-blog.csdnimg.cn/img_convert/b0b9d2f91f96416892929e5c57157887.png)