文章目录
- 🍔简述布隆过滤器
- 🌺原理
- 🛸存入过程
- 🛸查询过程
- 🏳️🌈优缺点
- ⭐优点
- ⭐缺点
- 🌹代码实现(本地)
- 🌹代码实现(分布式)

🍔简述布隆过滤器
布隆过滤器的由来可以追溯到1970年代,由一个名叫Burton Howard Bloom的美国计算机科学家提出。他在1970年的一篇论文中首次描述了这个概念,并将其称为"Bloom filter"。
Bloom当时的目标是设计一种高效的数据结构,用于在大规模数据库中进行快速查询。他的主要思想是通过使用一个位数组和多个哈希函数,能够在不存储实际数据的情况下,快速判断一个元素是否存在于集合中。这种数据结构的提出,为解决大规模数据的查找问题提供了一种经济高效的方法。
布隆过滤器最初的应用场景是在数据库系统中,用于加速查询操作。它可以有效地减少磁盘I/O操作,提高查询效率,并节省存储空间。后来,布隆过滤器得到了广泛的应用,在各种领域都发挥了重要作用。
随着互联网的迅速发展和大数据时代的到来,布隆过滤器的应用范围越来越广泛。它被用于网络缓存、分布式系统、垃圾邮件过滤、URL去重、爬虫的URL判重、密码学等领域。由于其高效的查询性能和低存储成本,布隆过滤器成为了解决大规模数据处理和高并发访问的重要工具。
总结来说,布隆过滤器是由美国计算机科学家Burton Howard Bloom提出的一种高效的概率型数据结构,用于快速判断一个元素是否存在于集合中。它的提出解决了大规模数据查询的问题,并在各个领域得到了广泛的应用和发展。
🌺原理
布隆过滤器其实就是一个很长的二进制向量和一系列随机映射函数,主要用来判断一个元素是否存在一个集合中,存储的数据不是0就是1,默认是0
1代表存在某个数据,0代表不存在
🛸存入过程
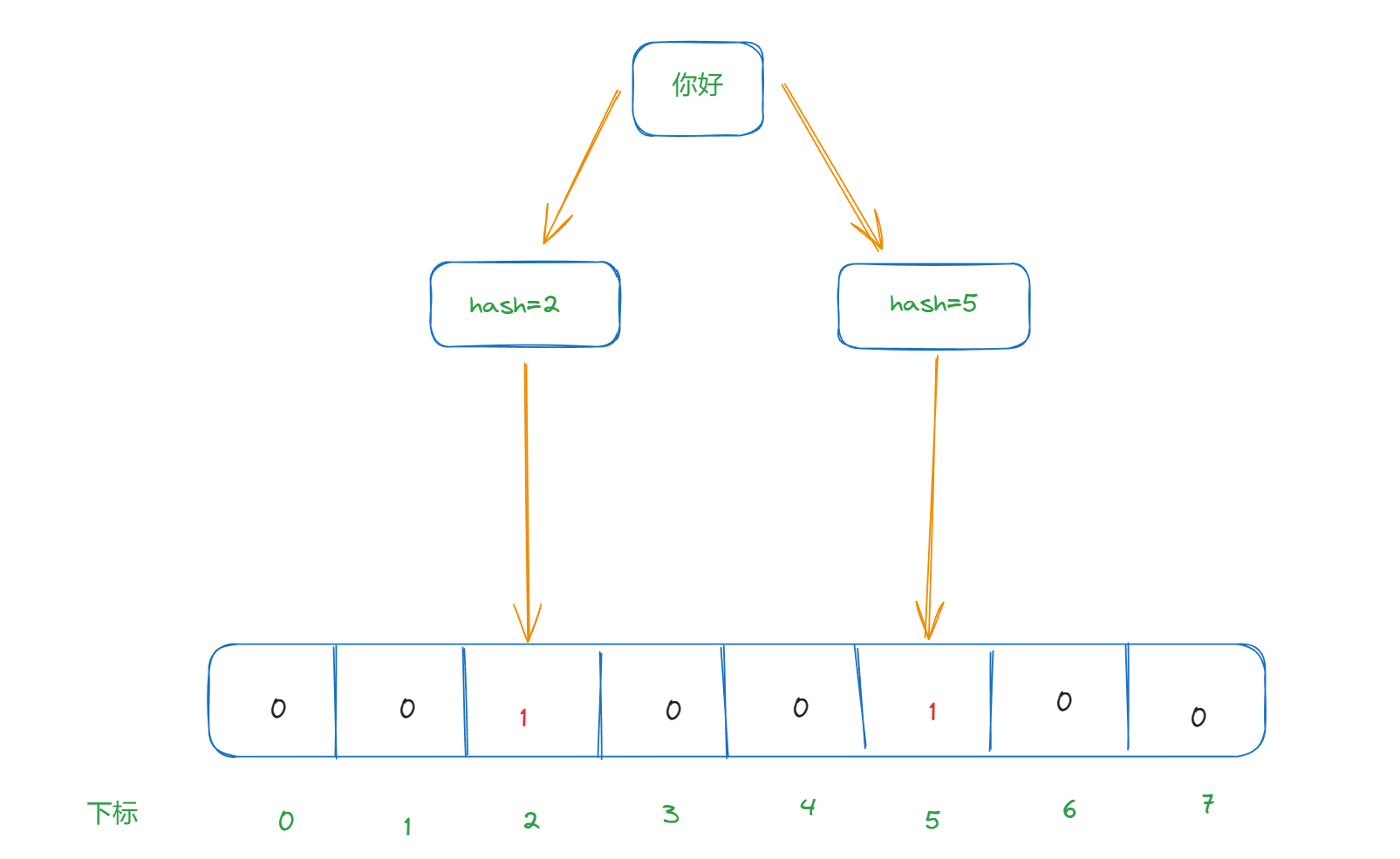
因为布隆过滤器就是一个二进制数据的集合,当有一个数据加入到这个集合的时候,会经过下面的步骤
- 通过k个哈希函数计算该数据,返回k个计算得到的hash值
- 这些k个hash值映射到对应的k个二进制的数组下标
将k个下标对应的二进制数据改为1
🛸查询过程
布隆过滤器主要就是来查询一个数据在不在这个二进制集合中,具体方法如下
- 通过k个hash函数计算该数据,得到hash值
- 通过hash值找到对应的二进制数字的下标
如果某一处的二进制数据为0,那么该数据不存在,如果都是1,那么该数据存在集合中
🏳️🌈优缺点
⭐优点
布隆过滤器具有以下几个主要的优点:
- 高效的查询性能:布隆过滤器通过位数组和多个哈希函数实现了快速的元素判断。在查询一个元素是否存在于集合中时,只需要进行多次哈希计算和位数组查询操作,而不需要真正地存储和比较元素本身。因此,查询的时间复杂度是常数级别的,具有非常高的查询效率。
- 较低的存储需求:布隆过滤器使用位数组表示元素的存在情况,而不需要存储实际的元素本身。且通过多个哈希函数的映射,可以将元素分散到位数组的多个位置上,从而进一步减少存储空间的需求。相比于直接存储元素本身的数据结构,布隆过滤器在存储方面具有较低的空间复杂度。
- 支持高并发访问:由于布隆过滤器的查询操作只涉及位数组的查询和哈希函数的计算,不需要对实际元素进行读写操作,所以在并发访问的场景下,不会出现数据读写冲突的问题。这使得布隆过滤器非常适合于高并发环境下的数据处理和查询。
- 可扩展性强:布隆过滤器可以根据需要动态地调整位数组的大小和哈希函数的个数,以适应不同规模和需求的数据集。通过增加位数组的长度和增加哈希函数的数量,可以提高布隆过滤器的准确性和容错性。
- 简单高效的实现:布隆过滤器的实现相对简单,只需要一个位数组和多个哈希函数即可。哈希函数的选择和设计也相对容易,可以根据实际需求进行调整。这使得布隆过滤器在实际应用中具有较好的可用性和灵活性。
综上所述,布隆过滤器具有高效的查询性能、较低的存储需求、支持高并发访问、可扩展性强和简单高效的实现等优点,使其成为解决大规模数据查询和去重等问题的有效工具。
⭐缺点
布隆过滤器虽然有很多优点,但也存在一些缺点,主要包括以下几个方面:
误判率(False Positive):由于布隆过滤器的设计特性,它可能会产生一定的误判率,即认为一个元素存在于集合中,但实际上并不存在。这是因为多个元素经过哈希函数映射后可能会映射到相同的位数组位置上,从而导致冲突。误判率随着位数组的大小和哈希函数的数量增加而降低,但无法完全消除。不支持删除操作:布隆过滤器的位数组中存储的是元素是否存在的信息,而不存储元素本身。因此,在布隆过滤器中删除一个元素是比较困难的,通常需要重新创建一个新的布隆过滤器。这限制了布隆过滤器在某些场景下的灵活性和可用性。- 无法获取具体元素:由于布隆过滤器只存储元素是否存在的信息,而不存储元素本身,因此无法直接获取具体的元素内容。如果需要获取具体元素,仍需使用其他数据结构进行进一步查询。
- 存储空间的浪费:虽然布隆过滤器相比其他数据结构具有较低的存储需求,但在一些特定情况下,由于需要保证较低的误判率,可能需要增加位数组的大小和哈希函数的数量,从而导致存储空间的浪费。
- 初始化时的时间和计算开销:布隆过滤器在初始化时需要分配位数组并进行哈希函数的计算,这个过程可能需要较多的时间和计算资源。尤其是在处理大规模数据集时,初始化的时间和计算开销会比较大。
综上所述,布隆过滤器的主要缺点包括误判率、不支持删除操作、无法获取具体元素、存储空间浪费以及初始化时的时间和计算开销。在使用布隆过滤器时,需要根据实际需求和场景权衡其优缺点,选择合适的数据结构。
假如“你好”和“hello”这2个数据的hash值一样,那么他们将会存储到同一位置
当我们要删除“hello”这个数据的时候,我们会删除存储“hello”这个数据的hash值的位置,由于“hello”和“你好”存储在同一位置,这样子会造成误删
同理
如果仅仅存储了hello,没有存储“你好”,当我们查询“你好”的时候,由于 假设“你好”和“hello”这2个数据的hash值一样,会造成误判
🌹代码实现(本地)
引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
编写核心代码,我们使用下面的代码来测试一下布隆过滤器的误判率
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterCase {
/**
* 预计要插入多少数据
*/
private static int size = 1000000;
/**
* 期望的误判率
*/
private static double fpp = 0.01;
/**
* 布隆过滤器
*/
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
public static void main(String[] args) {
// 插入10万样本数据
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
// 用另外十万测试数据,测试误判率
int count = 0;
for (int i = size; i < size + 100000; i++) {
if (bloomFilter.mightContain(i)) {
count++;
System.out.println(i + "误判了");
}
}
System.out.println("总共的误判数:" + count);
}
}
这里的误判率可以通过fpp参数进行调节,
fpp越小,需要的内存空间就越大:0.01需要900多万位数,0.03需要700多万位数。
fpp越小,集合添加数据时,就需要更多的hash函数运算更多的hash值,去存储到对应的数组下标里。
🌹代码实现(分布式)
上面使用Guava实现的布隆过滤器是把数据放在了本地内存中。分布式的场景中就不合适了,无法共享内存。
我们还可以用Redis来实现布隆过滤器,这里使用Redis封装好的客户端工具Redisson。
引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.13.4</version>
</dependency>
编写核心代码
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
config.useSingleServer().setPassword("1234");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("phoneList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%
bloomFilter.tryInit(100000000L,0.03);
//将号码10086插入到布隆过滤器中
bloomFilter.add("10086");
//判断下面号码是否在布隆过滤器中
//输出false
System.out.println(bloomFilter.contains("123456"));
//输出true
System.out.println(bloomFilter.contains("10086"));
}
}
代码参考文章:https://mp.weixin.qq.com/s/vwy5oGEWNuQ7k5DQfGrhCQ
在技术的道路上,我们不断探索、不断前行,不断面对挑战、不断突破自我。科技的发展改变着世界,而我们作为技术人员,也在这个过程中书写着自己的篇章。让我们携手并进,共同努力,开创美好的未来!愿我们在科技的征途上不断奋进,创造出更加美好、更加智能的明天!






![[每周一更]-(第87期):主流软件负载均衡器对比(LVS、Nginx、HAproxy)](https://img-blog.csdnimg.cn/direct/dd9cca31b86744678965db803e219e22.jpeg#pic_center)