项目地址:使用PaddleNLP UIE模型抽取PDF版上市公司公告 - 飞桨AI Studio星河社区 (baidu.com)
背景介绍
本项目将演示如何通过PDFPlumber库和PaddleNLP UIE模型,抽取公告中的相关信息。本次任务的PDF内容是破产清算的相关公告,目标是获取受理时间,受理法院,相关公司等内容,作为市场分析的关键数据。
公告示例
证券代码:000033 证券简称:*ST新都 公告编号:2016-05-19 深圳新都酒店股份有限公司关于公司第二大股东破产清算的公告 本公司及董事会全体成员保证公告内容的真实、准确和完整,没有虚假记载、误导性陈述或者重大遗漏。 2016年5月18日,公司收到公司股东深圳市瀚明投资有限公司的管理人送达的(2016)瀚明管发字第024号《通报函》,主要内容如下: “深圳市中级人民法院于2016年4月19日依法裁定受理申请人上海超创企业服务中心(有限合伙)提出的对深圳市瀚明投资有限公司(以下简称“瀚明投资”)进行破产清算的申请,并指定深圳市正源清算事务有限公司和深圳市理恪德清算事务有限公司担任瀚明投资管理人。瀚明投资破产清算的各项工作目前正在有序推进中。” 瀚明投资的破产清算将导致其持有本公司45551000股(占公司总股本的 10.6%)股权的处置及归属存在不确定性,瀚明投资破产清算不会对本公司正常经营产生影响。 本公司将根据瀚明投资破产清算进程履行公告义务。 特此公告。 深圳新都酒店股份有限公司 董事会 2016年5月18日
技术方案
UIE介绍
信息抽取指的是自动从无结构或半结构的文本中抽取出结构化信息的任务, 主要包含了实体识别、关系抽取、事件抽取、评论抽取等任务。
-
实体抽取 命名实体识别(Named Entity Recognition,简称NER),是指识别文本中具有特定意义的实体。在开放域信息抽取中,抽取的类别没有限制,用户可以自己定义。
-
关系抽取 关系抽取(Relation Extraction,简称RE),是指从文本中识别实体并抽取实体之间的语义关系,进而获取三元组信息,即<主体,谓语,客体>。
-
事件抽取 事件抽取 (Event Extraction, 简称EE),是指从自然语言文本中抽取预定义的事件触发词(Trigger)和事件论元(Argument),组合为相应的事件结构化信息。
传统的预训练-微调范式下,序列标注方案比较常用。UIE(Universal Information Extraction,通用信息抽取) 开创了基于Prompt的信息抽取多任务统一建模方式,通过大规模多任务预训练学习的通用抽取能力,不限定行业领域和抽取目标。UIE 具备强大的零样本抽取和小样本快速迁移能力。例如,在金融领域的事件抽取任务上,仅仅标注5条样本,F1值就提升了25个点!
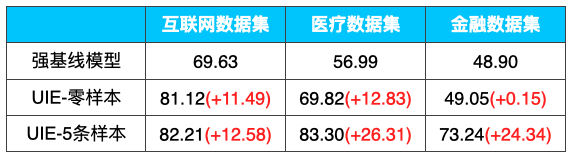
通过调用 PaddleNLP Taskflow API 直接使用UIE进行零样本抽取,同时,PaddleNLP也打通了数据标注-微调训练-预测部署全流程,方便大家进行定制训练。
应用示例
UIE不限定行业领域和抽取目标,以下是一些零样本行业示例:
- 法律场景-判决书抽取

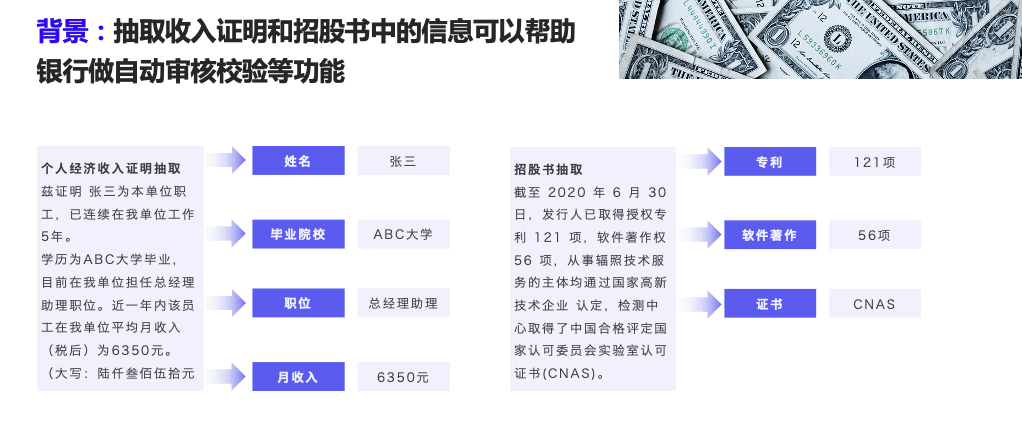
- 金融场景-收入证明、招股书抽取
代码实践
环境准备
# 安装最新版 PaddleNLP
!pip install --upgrade paddlenlp --user
# 安装PDFPlumber
!pip install pdfplumber --userPDF文档解析
本次任务使用的PDF都是从相关网站直接获取的可编辑格式,使用PDFPlumber库提取PDF中的内容并保存成为txt格式,便于输入UIE模型中。扫描件等图片格式的PDF需要OCR技术,推荐使用PaddleOCR。
# 导入PDFPlumber
import pdfplumber as ppl
# 导入正则表达式相关库
import re # 使用 PDFPlumber 库打开PDF文件
pdf_path = "work/input/000011_61727994c8c8ae10ff7ce243.pdf"
pdf = ppl.open(pdf_path)
# 获得 PDFPlumber 的对象,可以查看其中的文字内容
for page in pdf.pages:
print(page.extract_text())深圳市物业发展(集团)股份有限公司
证券代码:000011 200011 股票简称:深物业A 深物业B 编号:2014-3号
关于海南公司进行破产清算的进展公告
本公司及董事会全体成员保证公告内容的真实、准确、
完整、及时、公平,没有虚假记载、误导性陈述或者重大遗
漏。
本公司于 2011 年 11 月 25 日第七届董事会第四次会议作
出董事会决议,拟对本公司下属全资子公司-海南新达开发总
公司(以下简称“海南公司”)进行破产清算(详见本公司于
2011 年 11 月 28 日发布的《董事会决议公告》)。本公司于 2013
年 9 月 26 日以海南公司多年来处于严重亏损状态,无法清偿
到期债务为由向海南省海口市中级人民法院(以下简称“海
口中院”)申请对海南公司进行破产清算。
一、最新进展情况
2014 年 3 月 14 日本公司收到海口中院下发的(2013)
海中法破(预)字第 7 号《民事裁定书》,海口中院于 2014
年2月27日裁定受理本公司提出的对海南公司破产清算的申
请,现将有关情况公告如下:
海口中院认为:新达公司的住所地在海口市国贸大道 48
号新达商务大厦,该司是由海南省工商行政管理局核准登记
的企业,故海口中院对本案有管辖权。因新达公司不能清偿
到期债务,故深物业股份公司提出对新达公司进行破产清算
1
的申请符合受理条件。依照《中华人民共和国企业破产法》
第二条第一款、第三条、第七条第二款之规定,裁定如下:
受理申请人深圳市物业发展(集团)股份有限公司对被
申请人海南新达开发总公司破产清算的申请。
本裁定自即日起生效。
二、其他情况
本公司已对海南公司账务进行了全额计提,破产清算对
本公司财务状况无影响。
具体情况请查阅本公司2011年11月28日发布的《董事会
决议公告》。
特此公告
备查文件:海南省海口市中级人民法院《民事裁定书》((2013)
海中法破(预)字第 7 号)
深圳市物业发展(集团)股份有限公司
董事会
二〇一四年三月十五日
2
对于表格的提取,PDFPlumber可以返回半结构化的表格数据,但是想要准确还原原有的表格结构,还需要根据不同的表格状况作出调整。
pdf_path = "work/input/000525_61d01fedb68daaca17ea0dad.pdf"
pdf = ppl.open(pdf_path)
# 获得PDFPlumber的对象,可以查看其中的文字内容
for page in pdf.pages:
print(page.extract_table())[['股东名称', '持股数量\n(股)', '持股 \n比例', '质押', None, None, '司法冻结', None, None, '轮候冻结', None, None], [None, None, None, '累计数量\n(股)', '占其所\n持股份\n比例', '占公司\n总股本\n比例', '累计数量\n(股)', '占其所\n持股份\n比例', '占公司\n总股本\n比例', '累计数量\n(股)', '占其所持\n股份比例', '占公司总\n股本比例'], ['南一农集团', '182924731', '31.50%', '167850000', '91.76%', '28.90%', '182424031', '99.73%', '31.41%', '1559040275', '852.29%', '268.44%']] None
对于一般的纯文字PDF,使用PDFPlumber读取并保存为txt格式。
pdf_path = "work/input/000011_61727994c8c8ae10ff7ce243.pdf"
pdf = ppl.open(pdf_path)
texts = []
# 按页打开,合并所有内容,对于多页或一页PDF都可以使用
for page in pdf.pages:
text = page.extract_text()
texts.append(text)
txt_string = ''.join(texts)
# 保存为和原PDF同名的txt文件
txt_path = pdf_path.split('.')[0] + '.txt'
with open(txt_path, "w", encoding='utf-8') as f:
f.write(txt_string)
f.close()数据预处理
从txt中读取文本,作为信息抽取的输入。对于比较长的文本,可能需要人工的设定一些分割关键词,分段输入以提升抽取的效果。
with open(txt_path, 'r') as f:
file_data = f.readlines()
record = ''
for data in file_data:
record += data
print(record)深圳市物业发展(集团)股份有限公司
证券代码:000011 200011 股票简称:深物业A 深物业B 编号:2014-3号
关于海南公司进行破产清算的进展公告
本公司及董事会全体成员保证公告内容的真实、准确、
完整、及时、公平,没有虚假记载、误导性陈述或者重大遗
漏。
本公司于 2011 年 11 月 25 日第七届董事会第四次会议作
出董事会决议,拟对本公司下属全资子公司-海南新达开发总
公司(以下简称“海南公司”)进行破产清算(详见本公司于
2011 年 11 月 28 日发布的《董事会决议公告》)。本公司于 2013
年 9 月 26 日以海南公司多年来处于严重亏损状态,无法清偿
到期债务为由向海南省海口市中级人民法院(以下简称“海
口中院”)申请对海南公司进行破产清算。
一、最新进展情况
2014 年 3 月 14 日本公司收到海口中院下发的(2013)
海中法破(预)字第 7 号《民事裁定书》,海口中院于 2014
年2月27日裁定受理本公司提出的对海南公司破产清算的申
请,现将有关情况公告如下:
海口中院认为:新达公司的住所地在海口市国贸大道 48
号新达商务大厦,该司是由海南省工商行政管理局核准登记
的企业,故海口中院对本案有管辖权。因新达公司不能清偿
到期债务,故深物业股份公司提出对新达公司进行破产清算
1
的申请符合受理条件。依照《中华人民共和国企业破产法》
第二条第一款、第三条、第七条第二款之规定,裁定如下:
受理申请人深圳市物业发展(集团)股份有限公司对被
申请人海南新达开发总公司破产清算的申请。
本裁定自即日起生效。
二、其他情况
本公司已对海南公司账务进行了全额计提,破产清算对
本公司财务状况无影响。
具体情况请查阅本公司2011年11月28日发布的《董事会
决议公告》。
特此公告
备查文件:海南省海口市中级人民法院《民事裁定书》((2013)
海中法破(预)字第 7 号)
深圳市物业发展(集团)股份有限公司
董事会
二〇一四年三月十五日
2
使用 UIE 进行信息抽取
我们使用PaddleNLP Taskflow API直接抽取公告中的关键信息,无需训练哦。
详情可参考:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie 。
第一次使用时,会自动下载默认模型到默认的位置。此方案无需依赖GPU也可以运行。
# 使用pprint增加输出可读性
from pprint import pprint
from paddlenlp import Taskflow实体抽取
针对同一篇公告,可以设置不同的任务,根据需求,改变schema而不需要重新训练通用模型。对于本示例,第一个任务是获得受理的法院和受理时间,属于实体抽取的任务。
import paddlenlp
paddlenlp.__version__# 设置不同的schema
# 实体抽取
from paddlenlp import Taskflow
schema = ['受理时间', '受理法院']
ie = Taskflow('information_extraction', schema=schema)
pprint(ie(record))[2022-09-08 16:13:09,325] [ INFO] - Downloading model_state.pdparams from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base_v1.0/model_state.pdparams 100%|██████████| 450M/450M [00:13<00:00, 33.9MB/s] [2022-09-08 16:13:24,402] [ INFO] - Downloading model_config.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/model_config.json 100%|██████████| 377/377 [00:00<00:00, 308kB/s] [2022-09-08 16:13:24,463] [ INFO] - Downloading vocab.txt from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/vocab.txt 100%|██████████| 182k/182k [00:00<00:00, 2.30MB/s] [2022-09-08 16:13:24,607] [ INFO] - Downloading special_tokens_map.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/special_tokens_map.json 100%|██████████| 112/112 [00:00<00:00, 144kB/s] [2022-09-08 16:13:24,670] [ INFO] - Downloading tokenizer_config.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/tokenizer_config.json 100%|██████████| 172/172 [00:00<00:00, 236kB/s] [2022-09-08 16:13:24,734] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base'. W0908 16:13:24.764302 11173 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0908 16:13:24.768028 11173 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2. [2022-09-08 16:13:27,395] [ INFO] - Converting to the inference model cost a little time. [2022-09-08 16:13:38,248] [ INFO] - The inference model save in the path:/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base/static/inference
[{'受理时间': [{'end': 440,
'probability': 0.8998520281582252,
'start': 429,
'text': '2014\n年2月27日'}],
'受理法院': [{'end': 824,
'probability': 0.45413020967631823,
'start': 812,
'text': '海南省海口市中级人民法院'}]}]
关系抽取
第二个任务是获得公告中提到的公司之间的关系,是一个关系抽取的任务。对于比较短的公告,在本示例中选择将全文直接输入进行抽取,并不会影响效果。对于长篇幅的公告,多个任务都使用全文作为输入会降低性能。
# 关系抽取
# print(record)
from paddlenlp import Taskflow
schema = {'公司': ['母公司', '子公司', '股东']}
ie.set_schema(schema)
pprint(ie(record))[{'公司': [{'end': 876,
'probability': 0.2903287813637405,
'relations': {'子公司': [{'end': 212,
'probability': 0.8585539059833636,
'start': 202,
'text': '海南新达开发总\n公司'}]},
'start': 859,
'text': '深圳市物业发展(集团)股份有限公司'},
{'end': 571,
'probability': 0.45863343911127075,
'relations': {'子公司': [{'end': 212,
'probability': 0.7908269167861341,
'start': 202,
'text': '海南新达开发总\n公司'}],
'股东': [{'end': 668,
'probability': 0.300250129676769,
'start': 651,
'text': '深圳市物业发展(集团)股份有限公司'}]},
'start': 564,
'text': '深物业股份公司'},
{'end': 668,
'probability': 0.32902502812567036,
'relations': {'子公司': [{'end': 212,
'probability': 0.8585539059833636,
'start': 202,
'text': '海南新达开发总\n公司'}]},
'start': 651,
'text': '深圳市物业发展(集团)股份有限公司'}]}]
长文本的答案获取
UIE对于词和句子的抽取效果比较好,但是对应大段的文字结果,还是需要传统的正则方式作为配合,在本次使用的pdf中,还需要获得法院具体的判决结果,使用正则表达式可灵活匹配想要的结果。
start_word = '如下'
end_word = '特此公告'
start = re.search(start_word, record)
end = re.search(end_word, record)
print(record[start.span()[1]:end.span()[0]]): 海口中院认为:新达公司的住所地在海口市国贸大道 48 号新达商务大厦,该司是由海南省工商行政管理局核准登记 的企业,故海口中院对本案有管辖权。因新达公司不能清偿 到期债务,故深物业股份公司提出对新达公司进行破产清算 1 的申请符合受理条件。依照《中华人民共和国企业破产法》 第二条第一款、第三条、第七条第二款之规定,裁定如下: 受理申请人深圳市物业发展(集团)股份有限公司对被 申请人海南新达开发总公司破产清算的申请。 本裁定自即日起生效。 二、其他情况 本公司已对海南公司账务进行了全额计提,破产清算对 本公司财务状况无影响。 具体情况请查阅本公司2011年11月28日发布的《董事会 决议公告》。
事件抽取
使用UIE进行信息抽取时,如果遇到效果不好的情况,则需要根据实际任务调整schema,比如抽取董事会公告时,如果将会议作为事件抽取,则无法获得完整的信息。
# 已经转为txt保存的公告文件
with open('work/input/000061_61ac2b0f13d6467b056b263d.txt', 'r') as f:
file_data = f.readlines()
record = ''
for data in file_data:
record += data
print(record)
schema = {"会议": ['时间', '应到', '实到', '主持']}
ie = Taskflow('information_extraction', schema=schema)
pprint(ie(record))证券代码:000061 证券简称:农产品 公告编号:2021-044
深圳市农产品集团股份有限公司
第八届董事会第四十八次会议决议公告
本公司及董事会全体成员保证信息披露的内容真实、准确、完
整,没有虚假记载、误导性陈述或重大遗漏。
深圳市农产品集团股份有限公司(以下简称“公司”)第八届董
事会第四十八次会议于 2021 年 10 月 27 日(星期三)上午 10:00 在
深圳市福田区深南大道 7028 号时代科技大厦 13 楼海吉星会议室召
开。会议通知于 2021 年 10 月 24 日以书面或电子邮件形式发出。会
议应到董事 12 名,实到董事 10 名,独立董事宁钟先生因公未能出
席会议,委托独立董事刘鲁鱼先生代为出席并表决;董事陈穗生先
生因公未能出席会议,委托董事向自力先生代为出席并表决。公司
监事及高级管理人员列席了本次会议。本次会议的召开符合《公司
法》及公司《章程》的规定。会议由董事长黄伟先生主持,经全体
与会董事认真审议并逐项表决通过以下议案:
一、2021 年第三季度报告
详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券
报》、《上海证券报》、《证券日报》及巨潮资讯网的《2021 年第三季
度报告》(公告编号:2021-046)。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
二、关于同意全资子公司收购担保公司 60%股权的议案 详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券
报》、《上海证券报》、《证券日报》及巨潮资讯网的《关于同意全资
子公司收购担保公司 60%股权的公告》(公告编号:2021-047)。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
三、关于同意控股子公司广西新柳邕公司为认购广西新柳邕项
目的银行按揭贷款客户提供阶段性担保的议案
详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券
报》、《上海证券报》、《证券日报》及巨潮资讯网的《关于控股子公
司广西新柳邕公司为认购广西新柳邕项目的银行按揭贷款客户提供
阶段性担保的公告》(公告编号:2021-048)。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
四、关于续聘会计师事务所的议案
详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券
报》、《上海证券报》、《证券日报》及巨潮资讯网的《关于拟续聘会
计师事务所的公告》(公告编号:2021-049)。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
本议案尚须提交公司股东大会审议。
五、关于向银行申请综合授信额度的议案
公司部分银行授信额度即将到期,为保障公司有充足的银行授信额度,同意公司向以下两家银行申请综合授信额度,具体如下:
一、向中国民生银行股份有限公司深圳分行申请不超过人民币 5
亿元综合授信额度。
二、向招商银行股份有限公司深圳分行申请不超过人民币 6 亿
元综合授信额度。
上述合计不超过 11 亿元的综合授信额度,期限不超过三年,担
保方式为信用担保。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
六、经理层《岗位聘任协议》
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
七、经理层《年度经营业绩责任书》
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
八、经理层《任期经营业绩责任书》
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
九、关于暂不召开股东大会的议案
本次董事会后,暂不召集股东大会审议本次董事会通过的《关
于续聘会计师事务所的议案》,该议案后续将与其他需提交股东大会
议案一并提交股东大会审议,公司将另行召开董事会,确定并公告股东大会的召开时间。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
特此公告。
深圳市农产品集团股份有限公司
董 事 会
二〇二一年十月二十九日
[2022-09-08 16:13:44,394] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base'.
[{'会议': [{'end': 1134,
'probability': 0.7193688610271387,
'relations': {'主持': [{'end': 428,
'probability': 0.47974251889164066,
'start': 426,
'text': '黄伟'}]},
'start': 1130,
'text': '股东大会'}]}]
结果说明UIE并没有将相关的内容和“会议”这个事件联系起来,此时使用实体抽取的schema,将所需的信息作为单独的实体进行抽取,就可以提升效果。
schema = ['会议时间', '应到', '实到', '主持人']
ie = Taskflow('information_extraction', schema=schema)
pprint(ie(record))[{'主持人': [{'end': 428,
'probability': 0.32195555942341514,
'start': 426,
'text': '黄伟'}],
'会议时间': [{'end': 204,
'probability': 0.7182057639475943,
'start': 175,
'text': '2021 年 10 月 27 日(星期三)上午 10:00'}],
'实到': [{'end': 302,
'probability': 0.956548146017763,
'start': 295,
'text': '董事 10 名'}],
'应到': [{'end': 292,
'probability': 0.9237980841199089,
'start': 285,
'text': '董事 12 名'}]}]
使用正则提升效果
对于长文本,可以根据关键词进行分割后抽取,但是对于多个实体,比如这篇公告中,通过的多个议案,就无法使用UIE抽取。
schema = ['通过议案']
start_word = '通过以下议案'
start = re.search(start_word, record)
input_data = record[start.span()[0]:]
print(input_data)
ie = Taskflow('information_extraction', schema=schema)
pprint(ie(input_data))通过以下议案:
一、2021 年第三季度报告
详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券
报》、《上海证券报》、《证券日报》及巨潮资讯网的《2021 年第三季
度报告》(公告编号:2021-046)。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
二、关于同意全资子公司收购担保公司 60%股权的议案 详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券
报》、《上海证券报》、《证券日报》及巨潮资讯网的《关于同意全资
子公司收购担保公司 60%股权的公告》(公告编号:2021-047)。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
三、关于同意控股子公司广西新柳邕公司为认购广西新柳邕项
目的银行按揭贷款客户提供阶段性担保的议案
详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券
报》、《上海证券报》、《证券日报》及巨潮资讯网的《关于控股子公
司广西新柳邕公司为认购广西新柳邕项目的银行按揭贷款客户提供
阶段性担保的公告》(公告编号:2021-048)。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
四、关于续聘会计师事务所的议案
详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券
报》、《上海证券报》、《证券日报》及巨潮资讯网的《关于拟续聘会
计师事务所的公告》(公告编号:2021-049)。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
本议案尚须提交公司股东大会审议。
五、关于向银行申请综合授信额度的议案
公司部分银行授信额度即将到期,为保障公司有充足的银行授信额度,同意公司向以下两家银行申请综合授信额度,具体如下:
一、向中国民生银行股份有限公司深圳分行申请不超过人民币 5
亿元综合授信额度。
二、向招商银行股份有限公司深圳分行申请不超过人民币 6 亿
元综合授信额度。
上述合计不超过 11 亿元的综合授信额度,期限不超过三年,担
保方式为信用担保。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
六、经理层《岗位聘任协议》
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
七、经理层《年度经营业绩责任书》
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
八、经理层《任期经营业绩责任书》
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
九、关于暂不召开股东大会的议案
本次董事会后,暂不召集股东大会审议本次董事会通过的《关
于续聘会计师事务所的议案》,该议案后续将与其他需提交股东大会
议案一并提交股东大会审议,公司将另行召开董事会,确定并公告股东大会的召开时间。
同意票数 12 票,反对票数 0 票,弃权票数 0 票。
特此公告。
深圳市农产品集团股份有限公司
董 事 会
二〇二一年十月二十九日
[2022-09-08 16:13:50,534] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base'.
[{'通过议案': [{'end': 1129,
'probability': 0.7701290743143261,
'start': 1113,
'text': '《关\n于续聘会计师事务所的议案》'}]}]
根据需要抽取信息的特征,此时则需要使用正则的方式来对相关的条目进行抽取,设定适当的正则抽取规则。
# 正则匹配“一 二 三 四 五 六 七 八 九 十”
print(re.findall(r"[\u4e00\u4e8c\u4e09\u56db\u4e94\u516d\u4e03\u516b\u4e5d\u5341]、.*\n", input_data))['一、2021 年第三季度报告 \n', '二、关于同意全资子公司收购担保公司 60%股权的议案 详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券\n', '三、关于同意控股子公司广西新柳邕公司为认购广西新柳邕项\n', '四、关于续聘会计师事务所的议案 \n', '五、关于向银行申请综合授信额度的议案 \n', '一、向中国民生银行股份有限公司深圳分行申请不超过人民币 5\n', '二、向招商银行股份有限公司深圳分行申请不超过人民币 6 亿\n', '六、经理层《岗位聘任协议》 \n', '七、经理层《年度经营业绩责任书》 \n', '八、经理层《任期经营业绩责任书》 \n', '九、关于暂不召开股东大会的议案 \n']
效果提升
除了通过根据文本的特征,制定适合的正则规则外,也可以通过增加小样本训练提升数据。
推荐使用数据标注平台doccano或labelstudio进行数据标注,同时 PaddleNLP 也支持微调训练、预测部署,具体的使用方法可以参考:
-
工单信息抽取
-
快递单信息抽取
当然,最全的信息在官方文档上哦:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie









![【sgCreateTableData】自定义小工具:敏捷开发→自动化生成表格列数据数组[基于el-table]](https://img-blog.csdnimg.cn/direct/6aba114194844c62b8bf03cba32ba571.gif)