简介:用于可视化和跟踪机器学习实验的工具。Weights & Biases 是一个机器学习平台,供开发人员更快地构建更好的模型。使用 W&B 的轻量级、可互操作的工具快速跟踪实验、对数据集进行版本和迭代、评估模型性能、重现模型、可视化结果和发现回归,并与同事分享结果。
github:wandb/wandb:🔥用于可视化和跟踪机器学习实验的工具。此存储库包含 CLI 和 Python API。 (github.com)
官网:Weights & Biases For Academic Research (wandb.ai)
api&入门&教程:W&B Docs | Weights & Biases Documentation (wandb.ai)
什么是W&B?
Weights & Biases (W&B) 是 AI 开发者平台,提供用于训练模型、微调模型和利用基础模型的工具。
在 5 分钟内设置 W&B,然后快速迭代机器学习管道,确信您的模型和数据在可靠的记录系统中得到跟踪和版本控制。
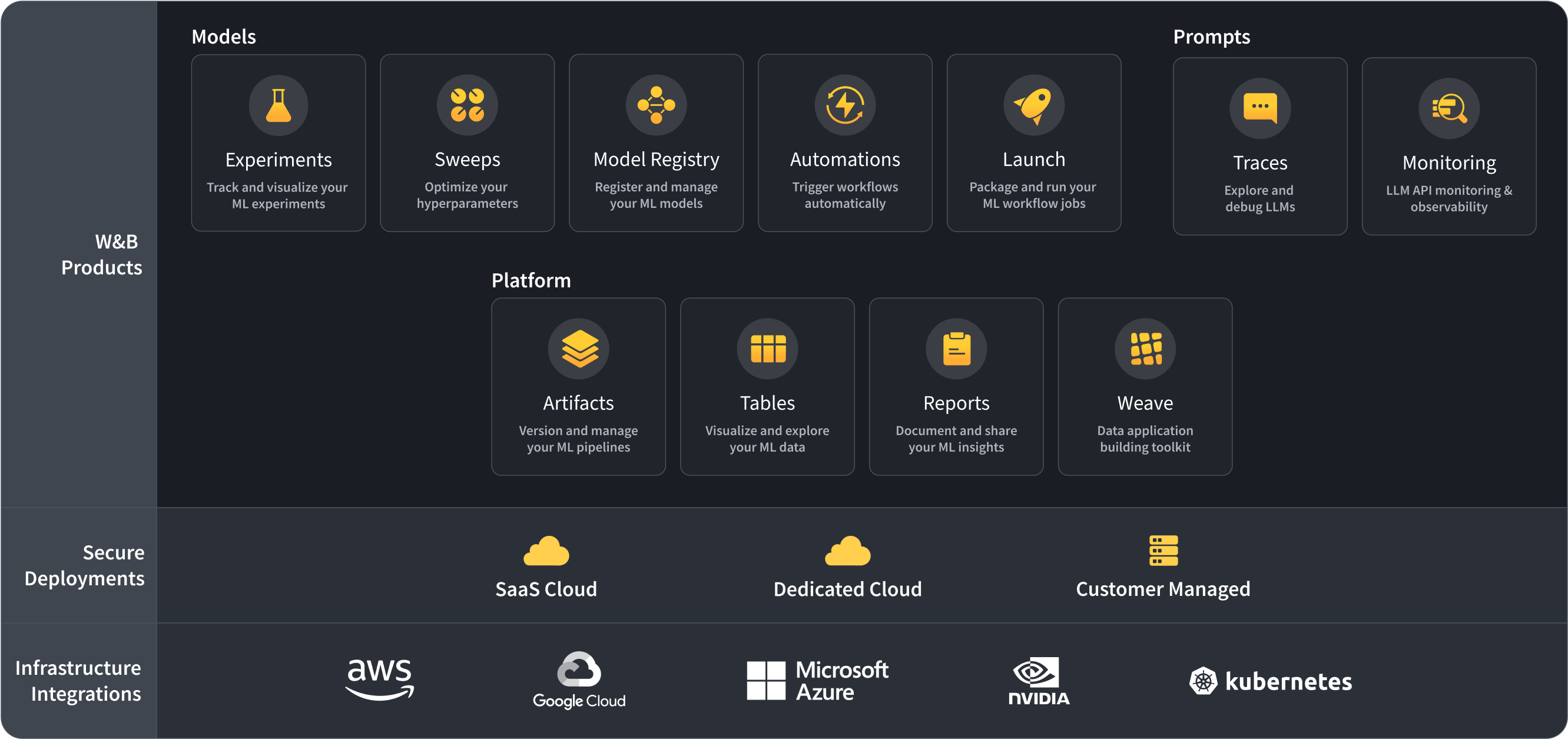
此图概述了 W&B 产品之间的关系。
W&B 模型是一组轻量级、可互操作的工具,用于机器学习从业者训练和微调模型。
实验:机器学习实验跟踪
模型注册表:集中管理生产模型
启动:缩放和自动化工作负载
扫描:超参数调优和模型优化
W&B Prompts 用于调试和评估 LLM。
W&B平台是一组强大的核心构建块,用于跟踪和可视化数据和模型,并传达结果。
项目:版本资产和轨道沿袭
表:可视化和查询表格数据
报告:记录和协作处理您的发现
编织查询和创建数据可视化效果
您是W&B的新用户吗?
演示视频:Weights & Biases End-to-End Demo (youtube.com)
使用以下资源开始探索 W&B:
简介笔记本:运行快速示例代码,在 5 分钟内跟踪实验
快速入门:阅读有关如何以及在何处将 W&B 添加到代码的快速概述
浏览我们的集成指南和我们的 W&B Easy Integration YouTube 播放列表,了解如何将 W&B 与您首选的机器学习框架集成。
查看 API 参考指南,了解有关 W&B Python 库、CLI 和 Weave 操作的技术规范。
W&B如何运作?
如果您是 W&B 的首次用户,我们建议您按以下顺序阅读以下部分:
了解 W&B 的基本计算单位 Runs。
使用实验创建和跟踪机器学习实验。
了解 W&B 灵活而轻量级的构建块,用于使用 Artifacts 进行数据集和模型版本控制。
自动执行超参数搜索,并使用扫描探索可能的模型空间。
使用模型管理管理从训练到生产的模型生命周期。
使用我们的数据可视化指南,可视化跨模型版本的预测。
组织 W&B 运行、嵌入和自动化可视化、描述您的发现,并使用报告与协作者共享更新。
快速入门
安装 W&B,并在几分钟内开始跟踪机器学习实验。
1. 创建一个帐户并安装 W&B
在开始之前,请确保创建一个帐户并安装 W&B:
- 在 https://wandb.ai/site 注册一个免费帐户,然后登录您的wandb帐户。
- 使用 pip 在 Python 3 环境中的计算机上安装 wandb 库。
以下代码片段演示了如何使用 W&B CLI 和 Python 库安装和登录 W&B:
安装 CLI 和 Python 库以与权重和偏差 API 进行交互:
!pip install wandb2. 登录 W&B
笔记本
接下来,导入 W&B Python SDK 并登录:
import wandb
wandb.login()出现提示时,请提供您的 API密钥。
3. 开始运行并跟踪超参数
使用 wandb.init() 在 Python 脚本或笔记本中初始化 W&B Run 对象,并使用超参数名称和值的键值对将字典传递给参数:config
run = wandb.init(
# Set the project where this run will be logged
project="my-awesome-project",
# Track hyperparameters and run metadata
config={
"learning_rate": 0.01,
"epochs": 10,
},
)运行是 W&B 的基本组成部分。您将经常使用它们来跟踪指标、创建日志、创建作业等。
把它们放在一起
综上所述,训练脚本可能类似于以下代码示例。突出显示的代码显示特定于 W&B 的代码。 请注意,我们添加了模拟机器学习训练的代码。
# train.py
import wandb
import random # for demo script
wandb.login()
epochs = 10
lr = 0.01
run = wandb.init(
# Set the project where this run will be logged
project="my-awesome-project",
# Track hyperparameters and run metadata
config={
"learning_rate": lr,
"epochs": epochs,
},
)
offset = random.random() / 5
print(f"lr: {lr}")
# simulating a training run
for epoch in range(2, epochs):
acc = 1 - 2**-epoch - random.random() / epoch - offset
loss = 2**-epoch + random.random() / epoch + offset
print(f"epoch={epoch}, accuracy={acc}, loss={loss}")
wandb.log({"accuracy": acc, "loss": loss})
# run.log_code()就是这样!导航到 W&B 应用程序, 查看 中我们使用 W&B 记录的指标(准确性和损失)在每个训练步骤中是如何改进的。

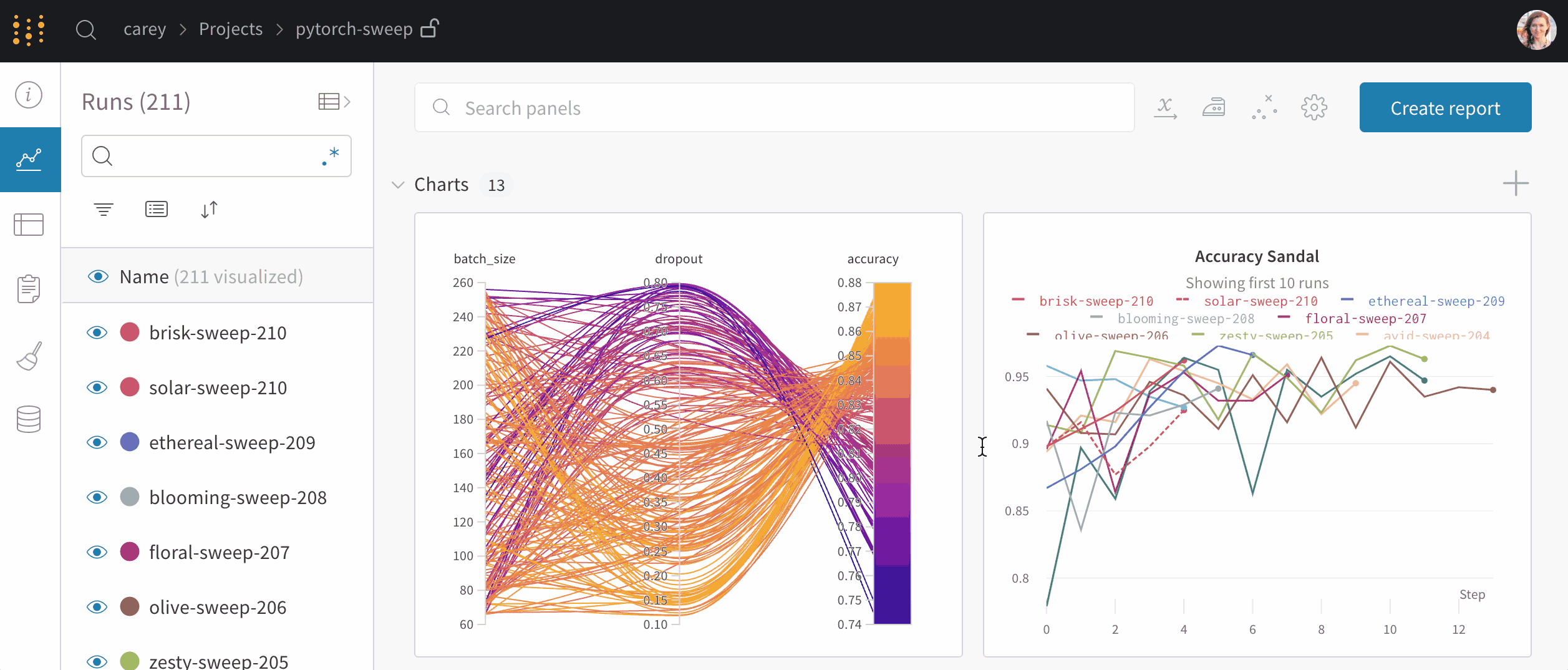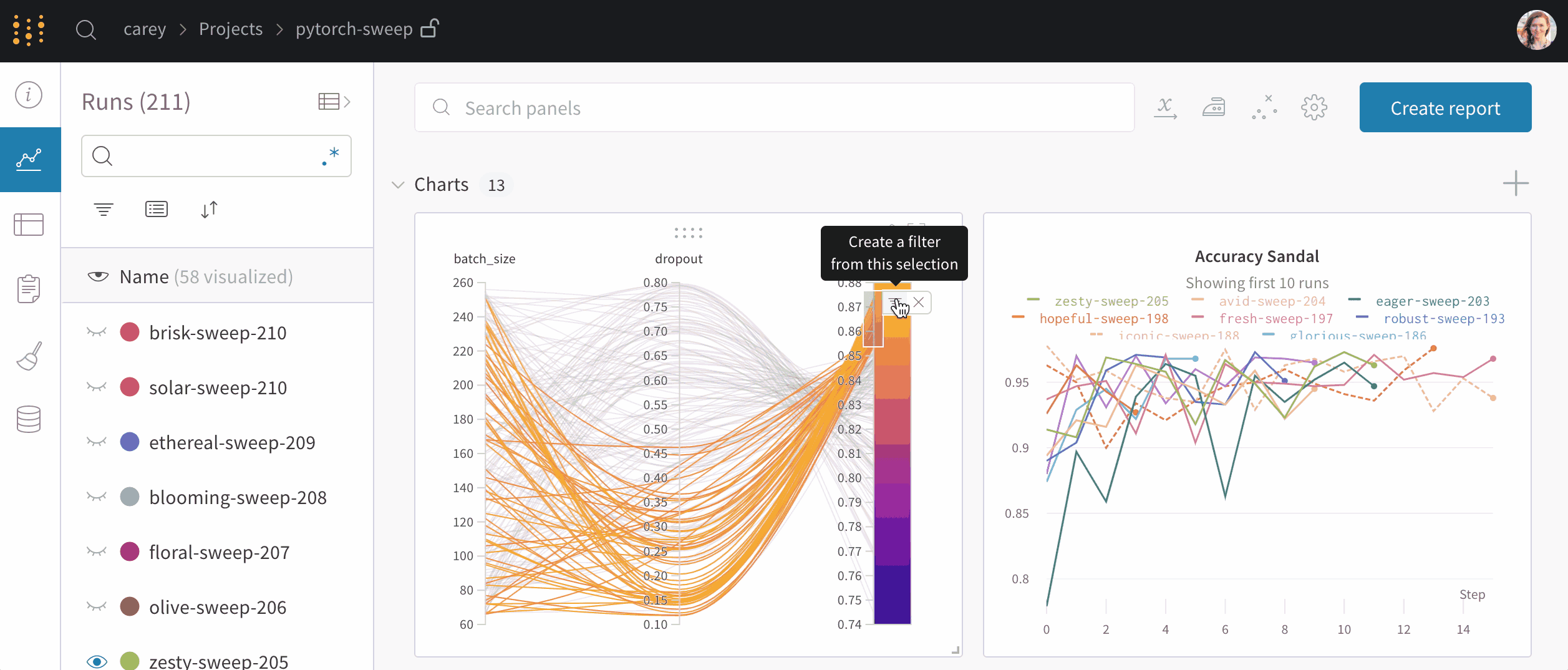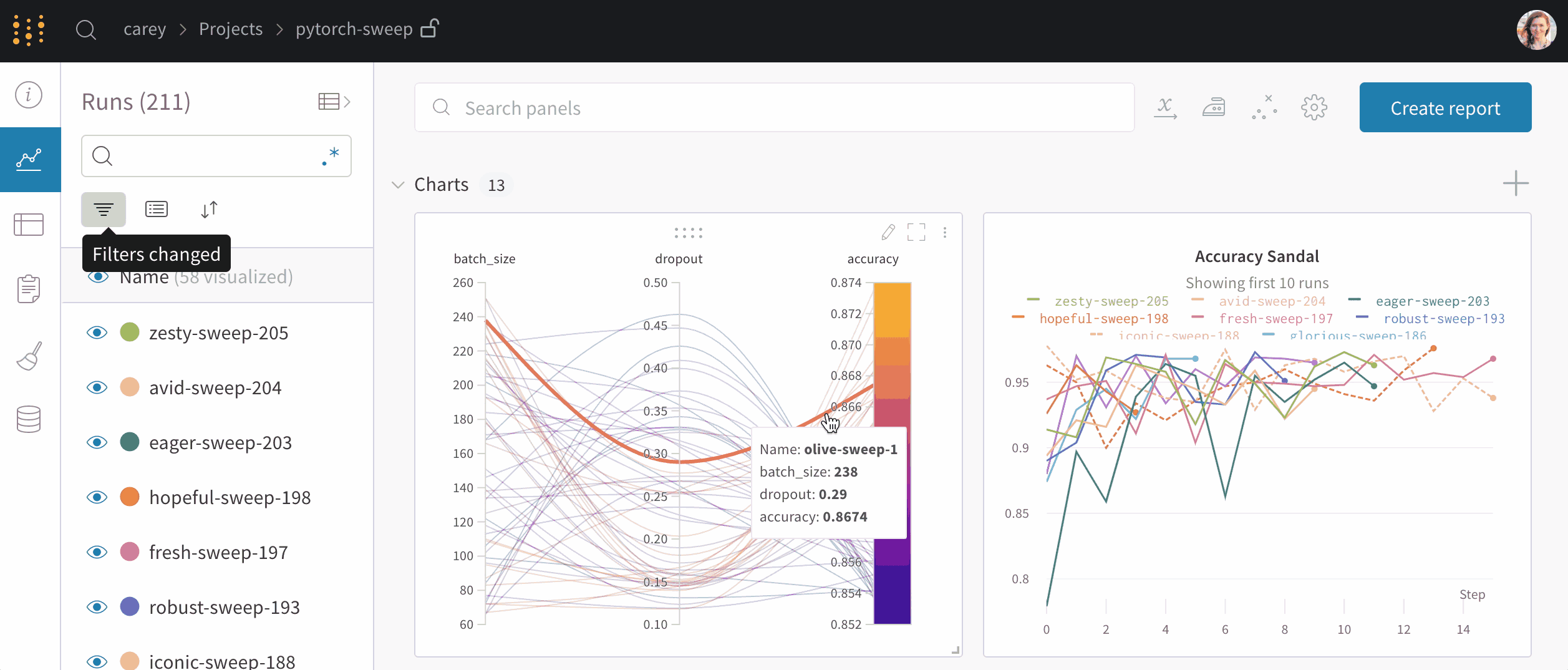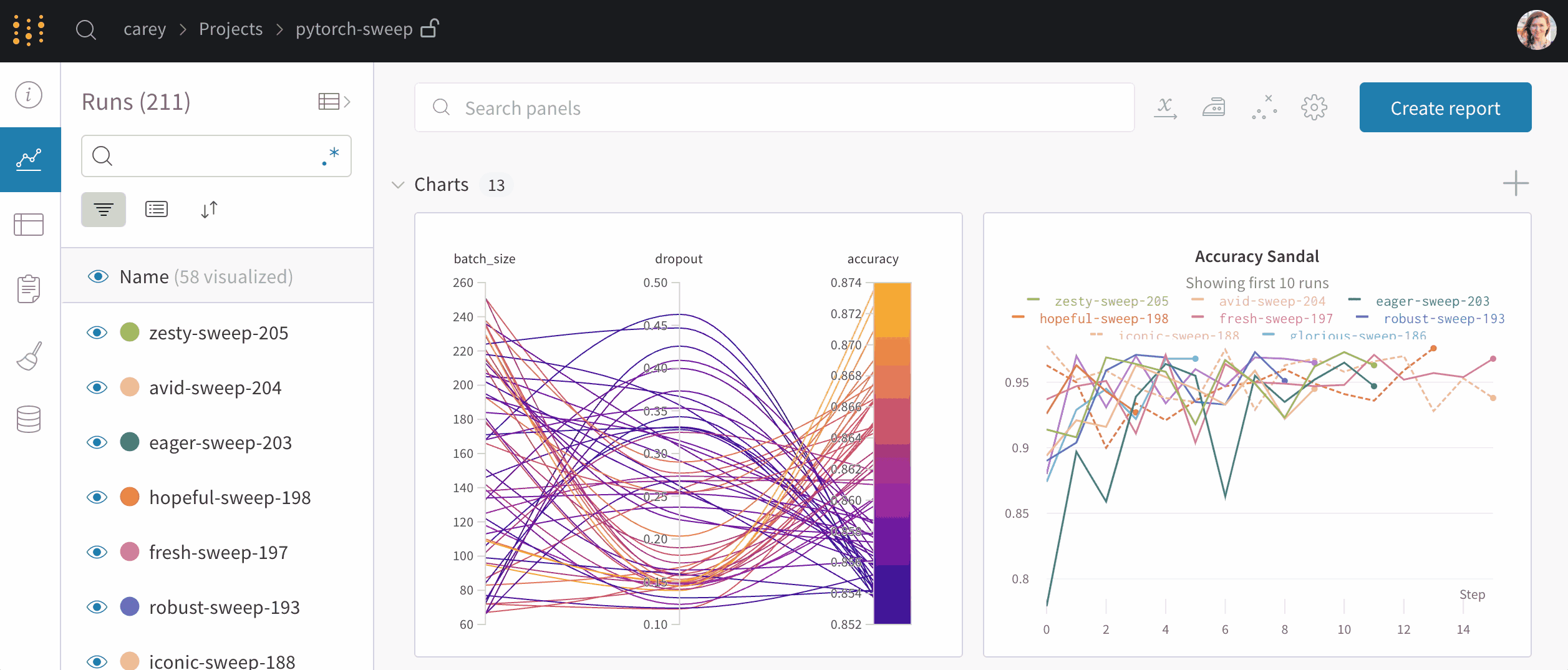
上图(单击展开)显示了每次运行上述脚本时跟踪的损失和准确性。创建的每个运行对象都显示在“运行”列中。每个运行名称都是随机生成的。
下一步是什么?
探索 W&B 生态系统的其余部分。
1.查看 W&B 集成,了解如何将 W&B 与您的 ML 框架(如 PyTorch)、ML 库(如 Hugging Face)或 ML 服务(如 SageMaker)集成。
2.使用 W&B 报告组织运行、嵌入和自动化可视化、描述您的发现并与协作者共享更新。
3.创建 W&B 项目,以跟踪机器学习管道每个步骤的数据集、模型、依赖项和结果。
4.使用 W&B Sweeps 自动执行超参数搜索并探索可能模型的空间。
5.了解数据集,可视化模型预测,并在中央仪表板中共享见解。
常见问题
在哪里可以找到我的 API 密钥?登录 www.wandb.ai 后,API 密钥将位于“授权”页面上。
如何在自动化环境中使用 W&B?如果您在运行 shell 命令(例如 Google 的 CloudML)不方便的自动化环境中训练模型,您应该查看我们的环境变量配置指南。
你们是否提供本地本地安装?是的,您可以在自己的计算机上或私有云中私有托管 W&B,请尝试使用此快速教程笔记本来了解如何操作。注意,要登录到wandb本地服务器,您可以将host标志设置为本地实例的地址。
如何暂时关闭 wandb 日志记录?如果正在测试代码并想要禁用 wandb 同步,请设置环境变量 WANDB_MODE=offline。
W&B 集成使在现有项目中设置实验跟踪和数据版本控制变得快速而简单。有关如何将 W&B 与您选择的框架集成的更多信息,请参阅《W&B 开发人员指南》中的“集成”一章。
🔥 PyTorch的
🌊 TensorFlow/Keras
🤗 拥抱脸变压器
⚡️ PyTorch 闪电
💨 XGBoo斯特
🧮 Sci-Kit 学习
W&B 托管选项
权重和偏见在云中可用或安装在您的私有基础设施上。通过以下三种方式之一在生产环境中设置 W&B 服务器:
- 生产云:使用 W&B 提供的 terraform 脚本,只需几个步骤即可在私有云上设置生产部署。
- 专用云:在您选择的云区域中,在 W&B 的单租户基础架构上进行托管的专用部署。
- 本地/裸机:W&B 支持在本地数据中心的大多数裸机服务器上设置生产服务器。通过运行快速开始,轻松开始在本地基础架构上托管 W&B。
wandb server
有关详细信息,请参阅《W&B 开发人员指南》中的托管文档。
![【sgCreateTableData】自定义小工具:敏捷开发→自动化生成表格列数据数组[基于el-table]](https://img-blog.csdnimg.cn/direct/6aba114194844c62b8bf03cba32ba571.gif)