【CV论文精读】BEVFormer Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
BEVFormer:通过时空Transformer学习多摄像机图像的鸟瞰图表示

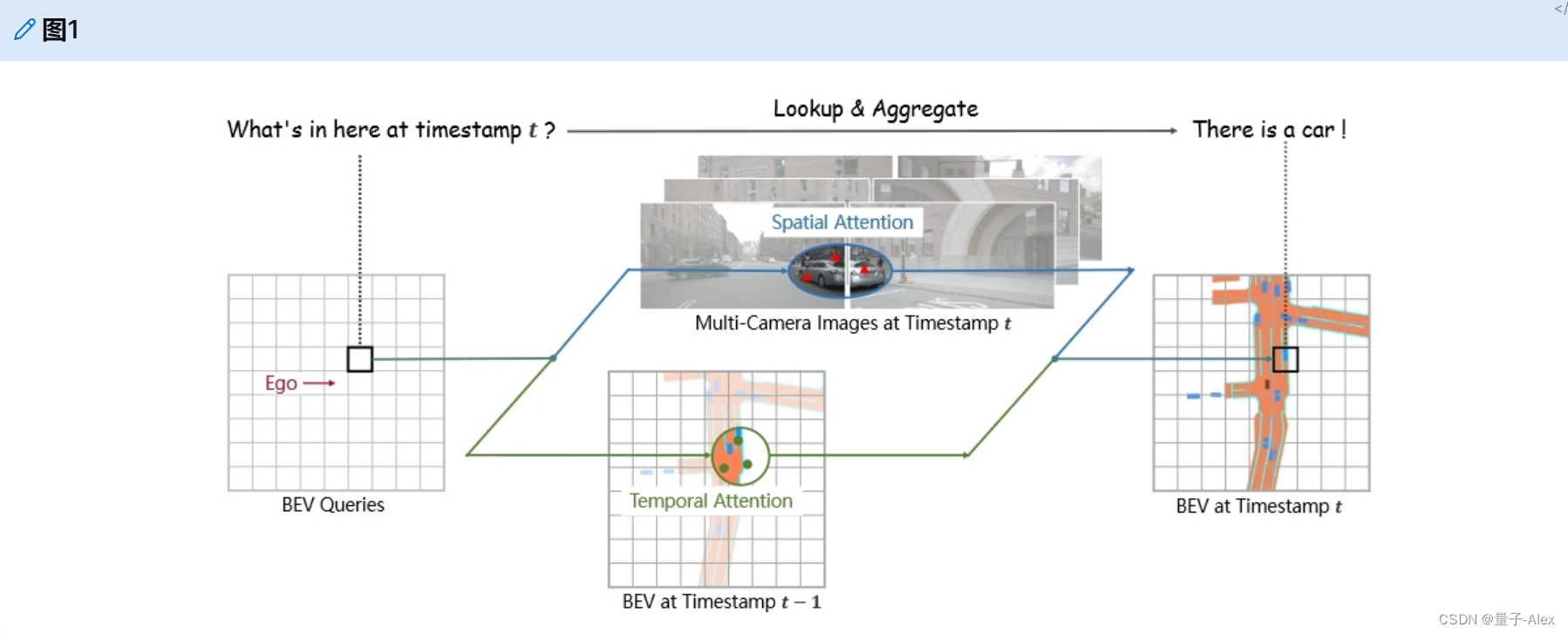
图1:我们提出了BEVFormer,这是一种自动驾驶的范式,它应用Transformer model和时间结构从多摄像头输入中生成鸟瞰(BEV)特征。BEVFormer利用查询来查找空间/时间空间,并相应地聚合时空信息,因此有利于感知任务的更强表示。
0.论文摘要与作者信息
摘要
3D视觉感知任务,包括基于多摄像头图像的3D检测和地图分割,对于自动驾驶系统至关重要。在这项工作中,我们提出了一个称为BEVFormer的新框架,它通过时空Transformer学习统一的BEV表示,以支持多个自动驾驶感知任务。简而言之,BEVFormer通过预定义的网格形状的BEV queries与空间和时间进行交互,从而利用空间和时间信息。为了聚集空间信息,我们设计了空间交叉注意力,每个BEV query从跨摄像机视图的感兴趣区域中提取空间特征。对于时间信息,我们提出时间自注意力来循环融合历史BEV信息。我们的方法在nuScenes测试集上实现了新的56.9%的NDS指标,比以前的SOTA高出9.0分,与基于激光雷达的基线的性能相当。我们进一步表明,BEVFormer显著提高了低能见度条件下物体速度估计和召回的准确性。
代码位置:
https://github.com/fundamentalvision/BEVFormer
作者信息
李志琦 1,2∗
王文海 2∗
李弘扬 2∗
谢恩泽 3
司马崇昊 2
路通 1
乔宇 2
代季峰 2
1 南京大学
2 上海人工智能实验室
3 香港大学
1.研究背景
3D空间中的感知对于自动驾驶、机器人等各种应用至关重要。尽管基于激光雷达的方法取得了显著进展[43,20,54,50,8],但基于相机的方法[45,32,47,30]近年来吸引了广泛关注。除了部署成本低之外,与基于激光雷达的相机相比,相机还具有检测远距离物体和识别基于视觉的道路元素(例如,交通灯、红绿灯)的理想优势。在自动驾驶中,对周围场景的视觉感知有望从多个摄像头给出的2D线索中预测3D边界框或语义图。最直接的解决方案是基于单目框架[45,44,31,35,3]和跨相机后处理。这种框架的缺点是,它单独处理不同的视图,无法跨摄像机捕捉信息,导致性能和效率低下[32,47]。
作为单目框架的替代,一个更统一的框架是从多摄像机图像中提取整体表示。鸟瞰图(BEV)是周围场景的常用表示,因为它清楚地呈现了物体的位置和比例,并适用于各种自动驾驶任务,如感知和规划[29]。尽管以前的地图分割方法证明了BEV的有效性[32,18,29],但基于BEV的方法在3D对象检测中并未显示出优于其他范式的显著优势[47,31,34]。潜在的原因是3D对象检测任务需要强大的BEV特征来支持精确的3D边界框预测,但是从2D平面生成BEV是不存在稳定的唯一解。生成BEV特征的流行BEV框架基于深度信息[46,32,34],但这种范式对深度值或深度分布的准确性很敏感。因此,基于BEV的方法的检测性能会受到复合误差的影响[47],不准确的BEV特征会严重影响最终性能。因此,我们有动机设计一种不依赖于深度信息的BEV生成方法,并且可以自适应地学习BEV特征,而不是严格依赖于3D先验。Transformer model使用注意力机制来动态聚集有价值的特征,在概念上满足了我们的需求。
用BEV特征执行感知任务的另一个动机是BEV是连接时间和空间的理想桥梁。对于人类的视觉感知系统来说,时间信息在推断物体的运动状态和识别遮挡物体方面起着至关重要的作用,视觉领域的许多工作已经证明了使用视频数据的有效性[2,27,26,33,19]。然而,现有的最先进的多摄像机3D检测方法很少利用时间信息。重大挑战是自动驾驶是时间关键的,场景中的对象变化很快,因此简单地堆叠交叉时间戳的BEV特征会带来额外的计算成本和干扰信息,这可能并不理想。受递归神经网络(RNNs)[17,10]的启发,我们利用BEV特征递归地传递从过去到现在的时间信息,这与RNN模型的隐藏状态具有相同的精神。
为此,我们提出了一种基于Transformer model的鸟瞰(BEV)编码器,称为BEVFormer,它可以有效地聚合来自多视角相机的时空特征和历史BEV特征。从BEVFormer生成的BEV特征可以同时支持多个3D感知任务,如3D物体检测和地图分割,这对于自动驾驶系统是有价值的。如图1所示,我们的BEVFormer包含三个关键设计,即(1)网格形状的BEV queries,通过注意力机制灵活地融合空间和时间特征,(2)空间交叉注意力模块,从多摄像机图像中聚合空间特征,以及(3)时间自注意力模块,从历史BEV特征中提取时间信息,这有利于运动物体的速度估计和严重遮挡物体的检测,同时带来可忽略的计算开销。借助BEVFormer生成的统一特征,该模型可以与不同的特定任务头协作,如可变形DETR[56]和mask decoder[22],用于端到端的3D对象检测和地图分割。
我们的主要贡献如下:
• 我们提出了BEVFormer,这是一种时空Transformer model编码器,可以将多摄像机和/或时间戳输入投影到BEV表示中。通过统一的BEV功能,我们的模型可以同时支持多种自动驾驶感知任务,包括3D检测和地图分割。
•我们设计了可学习的BEV queries以及空间交叉注意力层和时间自注意力层,分别从交叉摄像机中查找空间特征和从历史BEV中查找时间特征,然后将它们聚合成统一的BEV特征。
•我们根据包括nuScenes[4]和Waymo[40]在内的多个具有挑战性的基准对提议的BEVFormer进行了评估。与现有技术相比,我们的BEVFormer始终实现了改进的性能。例如,在可比的参数和计算开销下,BEVFormer在nuScenes测试集上实现了56.9%的NDS,比以前的最佳检测方法DETR3D[47]高出9.0分(56.9%比47.9%)。对于地图分割任务,我们还实现了最先进的性能,在最具挑战性的车道分割上比Lift-Splat[32]高出5.0多分。我们希望这个简单而强大的框架可以作为后续3D感知任务的新基线。
2.相关工作
2.1 基于Transformer model的2D感知
最近,一个新的趋势是使用Transformer model来重新制定检测和分割任务[7,56,22]。DETR[7]使用一组object queries直接由交叉注意力decoder生成检测结果。然而,DETR的主要缺点是训练时间长。可变形DETR[56]通过提出可变形注意力解决了这个问题。与DETR中普通的全局注意不同,可变形注意与感兴趣的局部区域相互作用,只对每个参考点附近的K个点进行采样并计算注意结果,从而提高了效率并显著缩短了训练时间。可变形注意机构通过以下方式计算:
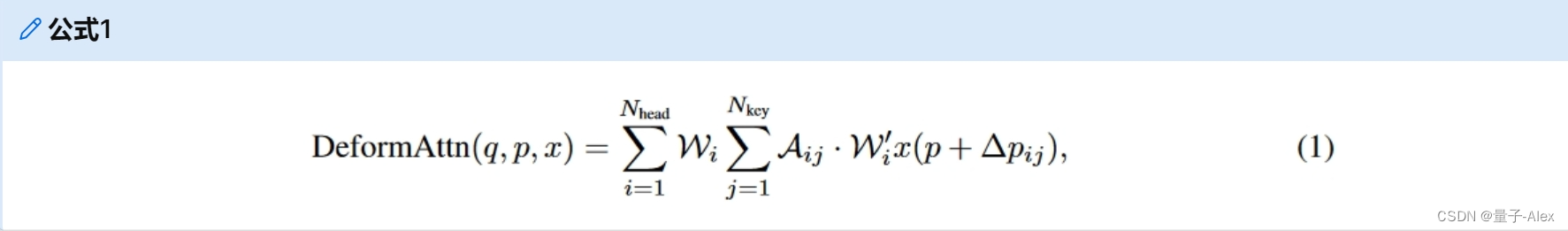
其中 q , p , x q, p, x q,p,x分别表示queries、参考点和输入特征。 i i i是注意力头的索引, N h e a d N_{head} Nhead表示注意头的总数。 j j j是采样的key的索引, N k e y N_{key} Nkey是每个头的总采样key的数量。 W i ∈ R C × ( C / H h e a d ) W_i ∈ \mathbb{R}^{C×(C/Hhead)} Wi∈RC×(C/Hhead)和 W i ′ ∈ R ( C / H h e a d ) × C W^′_i ∈ \mathbb{R}^{(C/Hhead)×C} Wi′∈R(C/Hhead)×C是可学习权重,其中C是特征维数。 A i j ∈ [ 0 , 1 ] A_{ij} ∈ [0, 1] Aij∈[0,1]是预测的注意力权重,并通过 ∑ j = 1 N k e y A i j = 1 ∑^{N_{key}}_{j=1} A_{ij} = 1 ∑j=1NkeyAij=1进行归一化。 ∆ p i j ∈ R 2 ∆p_{ij} ∈ \mathbb{R}^2 ∆pij∈R2是参考点p的预测偏移。 x ( p + ∆ p i j ) x(p + ∆p_{ij}) x(p+∆pij)表示位置 p + ∆ p i j p + ∆p_{ij} p+∆pij处的特征,其通过双线性插值提取,如Dai等所述[12]。在这项工作中,我们将可变形注意力扩展到3D感知任务,以有效地聚集空间和时间信息。
2.2 基于摄像机的3D感知
以前的3D感知方法通常独立执行3D目标检测或地图分割任务。对于3D目标检测任务,早期的方法类似于2D检测方法[1,28,49,39,53],其通常基于2D边界框来预测3D边界框。王等[45]遵循先进的2D检测器FCOS[41]并直接预测每个目标的3D边界框。DETR3D[47]在2D图像中投影可学习的3Dqueries,然后对相应的特征进行采样,用于端到端的3D边界框预测,而无需NMS后处理。另一种解决方案是将图像特征转换为BEV特征,并从自上而下的视图预测3D边界框。方法利用来自深度估计[46]或分类深度分布[34]的深度信息将图像特征转换为BEV特征。OFT[36]和ImVoxelNet[37]将预定义的体素投影到图像特征上,以生成场景的体素表示。最近, M 2 B E V M^2BEV M2BEV[48]进一步探索了基于BEV特征同时执行多个感知任务的可行性。
实际上,从多摄像机要素生成BEV要素在地图分割任务中得到了更广泛的研究[32,30]。一种简单的方法是通过逆透视映射(IPM)将透视图转换为BEV[35,5]。此外,Lift-Splat[32]基于深度分布生成BEV特征。方法[30,16,9]利用多层感知器学习从透视图到BEV的翻译。PYVA[51]提出了一种将前视单目图像转换为BEV的交叉视图Transformer model,但这种范式不适用于融合多摄像机特征[42]考虑到全局注意力机制的计算成本。除了空间信息之外,先前的工作[18,38,6]也通过堆叠来自几个时间戳的BEV特征来考虑时间信息。堆叠BEV特征将可用的时间信息限制在固定的持续时间内,并带来额外的计算成本。在这项工作中,所提出的时空Transformer model通过考虑空间和时间线索来生成当前时间的BEV特征,并通过RNN方式从先前的BEV特征中获得时间信息,这只带来很少的计算成本。
3.BEVFormer
将多摄像头图像特征转换为鸟瞰(BEV)特征可以为各种自动驾驶感知任务提供统一的周围环境表示。在这项工作中,我们提出了一个新的基于Transformer model的BEV生成框架,它可以通过注意机制有效地聚合来自多视角相机的时空特征和历史BEV特征。
3.1 总体架构
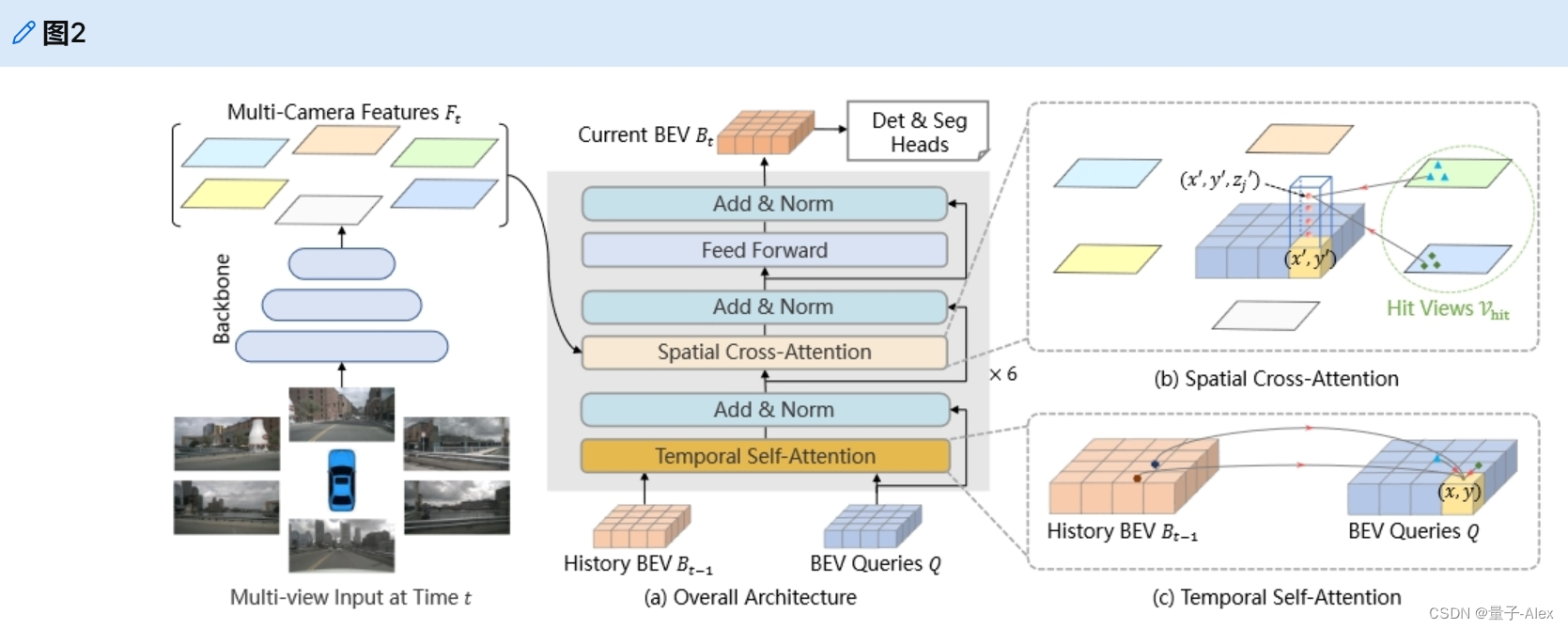
如图2所示,BEVFormer有6个编码器层,每个编码器层都遵循transformers[42]的传统结构,除了三个定制的设计,即BEV queries、空间交叉注意李和时间自注意力。具体来说,BEVqueries是网格形状的可学习参数,旨在通过注意力机制从多摄像机视图查询BEV空间中的特征。根据BEV queries,空间交叉注意力和时间自注意力是与BEV queries一起工作的注意力层,用于从多摄像机图像中查找和聚合空间特征以及从历史BEV中查找和聚合时间特征。
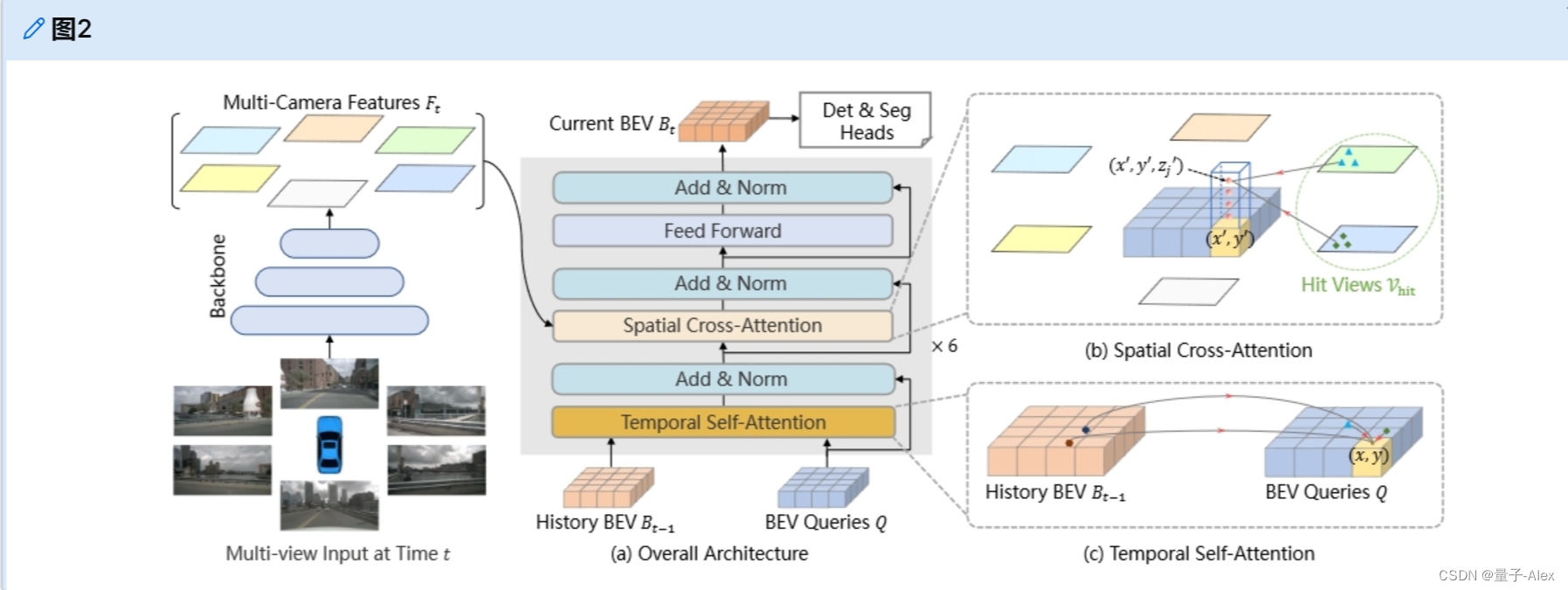
图2 BEVFormer的整体架构。(a)BEVFormer的编码器层包含网格形状的BEV query、时间自注意力和空间交叉注意力。(b)在空间交叉注意力中,每个BEV query仅与感兴趣区域中的图像特征交互。(c)在时间自注意力中,每个BEV查询与两个特征交互:当前时间戳处的BEV查询和前一时间戳处的BEV特征。
在推理过程中,在时间戳t处,我们将多个摄像机图像馈送到主干网络(例如,ResNet-101[15]),并获得不同摄像机视图的特征 F t = { F t i } i = 1 N v i e w F_t = \{F^i_t \}^{N_{view}}_{i=1} Ft={Fti}i=1Nview,其中 F t i F^i_t Fti是第i个视图的特征, N v i e w N_{view} Nview是摄像机视图的总数。同时,我们保留了先前时间戳t-1处的BEV特征 B t − 1 B_{t−1} Bt−1。在每个encoder层中,我们首先使用BEV查询Q通过时间自注意力从先前的BEV特征 B t − 1 B_{t−1} Bt−1中查询时间信息。然后使用BEV查询Q通过空间交叉注意力从多摄像机特征 F t F_t Ft中查询空间信息。在前馈网络[42]之后,编码器层输出细化的BEV特征,这是下一个encoder层的输入。在6个堆叠encoder层之后,生成当前时间戳t处的统一BEV特征 B t B_t Bt。以BEV特征 B t B_t Bt为输入,3D检测头和地图分割头预测感知结果,如3D边界框和语义图。
3.2 BEV Queries
我们预定义一组网格形状的可学习参数 Q ∈ R H × W × C Q ∈ \mathbb{R}^{H×W×C} Q∈RH×W×C作为BEVFormer的查询,其中H,W是BEV平面的空间形状。具体来说,位于Q的 p = ( x , y ) p = (x, y) p=(x,y)处的查询 Q p ∈ R 1 × C Q_p ∈ \mathbb{R}^{1×C} Qp∈R1×C负责BEV平面中相应的网格单元区域。BEV平面中的每个网格单元对应于s米的真实世界大小。默认情况下,BEV功能的中心对应于ego汽车的位置。遵循常见的实践[14],我们在将BEV queries Q输入到BEVFormer之前,将可学习的位置嵌入添加到BEV queries Q中。
3.3 空间交叉注意力
由于多摄像头3D感知(包含
N
v
i
e
w
N_{view}
Nview摄像头视图)的输入规模较大,vanilla 多头注意力[42]的计算成本极高。因此,我们开发了基于可变形注意力的空间交叉注意力[56],这是一个资源高效的注意力层,其中每个BEV查询
Q
p
Q_p
Qp仅跨相机视图与其感兴趣的区域进行交互。然而,可变形注意力最初是为2D感知设计的,因此3D场景需要一些调整。如图2(b)所示,我们首先将BEV平面上的每个查询提升到类似支柱的查询[20],从支柱中采样
N
r
e
f
N_{ref}
Nref 3D参考点,然后将这些点投影到2D视图。对于一个BEV查询,投影的2D点只能落在某些视图上,而其他视图不会被命中。这里,我们将点击视图称为
V
h
i
t
V_{hit}
Vhit。之后,我们将这些2D点视为查询
Q
p
Q_p
Qp的参考点,并围绕这些参考点从命中视图
V
h
i
t
V_{hit}
Vhit中采样特征。最后,我们对采样特征进行加权和,作为空间交叉注意力的输出。空间交叉注意(SCA)的过程可以表述为:

其中i是相机视图索引,j是参考点索引,
N
r
e
f
N_{ref}
Nref是每个BEV查询的总参考点。
F
t
i
F^i_t
Fti是第i个相机视图的特征。对于每个BEV查询
Q
p
Q_p
Qp,我们使用投影函数
P
(
p
,
i
,
j
)
P(p, i, j)
P(p,i,j)来获得第i个视图图像上的第j个参考点。
接下来,我们介绍如何从投影函数p获得视图图像上的参考点。我们首先计算位于Q的
p
=
(
x
,
y
)
p = (x, y)
p=(x,y)处的查询
Q
p
Q_p
Qp对应的真实世界位置
(
x
′
,
y
′
)
(x′, y′)
(x′,y′),作为等式3
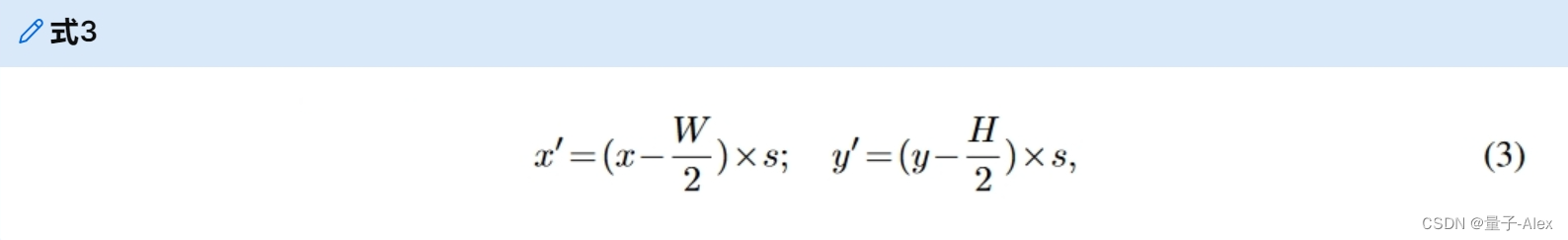
其中H,W是BEV查询的空间形状,s是BEV网格的分辨率大小,以及
(
x
′
,
y
′
)
(x′, y′)
(x′,y′)是ego car位置为原点的坐标。在3D空间中,位于
(
x
′
,
y
′
)
(x′, y′)
(x′,y′)的目标将出现在z轴上
z
′
z′
z′的高度。所以我们预定义了一组锚高度
{
z
j
′
}
j
=
1
N
r
e
f
\{z^′_j \}^{N_{ref}}_{j=1}
{zj′}j=1Nref,以确保我们可以捕捉到出现在不同高度的线索。以这种方式,对于每个查询
Q
p
Q_p
Qp,我们获得3D参考点
(
x
′
,
y
′
,
z
j
′
)
j
=
1
N
r
e
f
(x′, y′, z^′_j)^{N_{ref}}_{j=1}
(x′,y′,zj′)j=1Nref的支柱。最后,我们通过摄像机的投影矩阵将3D参考点投影到不同的图像视图,投影矩阵可以写成:
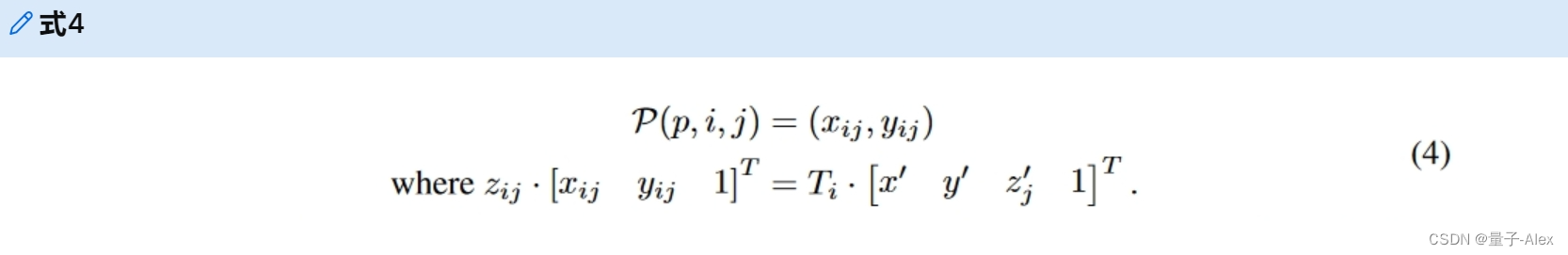
这里,
P
(
p
,
i
,
j
)
P(p, i, j)
P(p,i,j)是从第j个3D点
(
x
′
,
y
′
,
z
j
′
)
(x′, y′, z^′_j)
(x′,y′,zj′)投影的第i个视图上的2D点,
T
i
∈
R
3
×
4
T_i ∈ \mathbb{R}^{3×4}
Ti∈R3×4是第i个相机的已知投影矩阵。
3.4 时间自注意力
这里, P ( p , i , j ) P(p, i, j) P(p,i,j)是从第j个3D点 ( x ′ , y ′ , z j ′ ) (x′, y′, z^′_j) (x′,y′,zj′)投影的第i个视图上的2D点, T i ∈ R 3 × 4 T_i ∈ \mathbb{R}^{3×4} Ti∈R3×4是第i个相机的已知投影矩阵。
3.4 时间自注意力
除了空间信息,时间信息对于视觉系统理解周围环境也是至关重要的[27]。例如,在没有时间线索的情况下,从静态图像中推断运动物体的速度或检测高度遮挡的物体是具有挑战性的。为了解决这个问题,我们设计了时间自我注意,它可以通过结合历史BEV特征来表示当前环境。
给定当前时间戳t处的BEV查询Q和时间戳
t
−
1
t-1
t−1处保留的历史BEV特征
B
t
−
1
B_{t−1}
Bt−1,我们首先根据自我运动将
B
t
−
1
B_{t−1}
Bt−1与Q对齐,以使相同网格处的特征对应于相同的真实世界位置。这里,我们将对齐的历史BEV特征
B
t
−
1
B_{t−1}
Bt−1表示为
B
t
−
1
′
B^′_{t−1}
Bt−1′。然而,从时间
t
−
1
t-1
t−1到t,可移动物体在现实世界中以各种偏移移动。在不同时间的BEV特征之间构建相同对象的精确关联是具有挑战性的。因此,我们通过时间自注意力(TSA)层对特征之间的时间联系进行建模,该层可以写成如下:

其中 Q p Q_p Qp表示位于 p = ( x , y ) p = (x, y) p=(x,y)的BEV查询。此外,与普通的可变形注意不同,时间自我注意中的偏移量p是通过Q和 B t − 1 ′ B^′_{t−1} Bt−1′的concat来预测的。特别是,对于每个序列的第一个样本,时间自注意力将退化为没有时间信息的自注意力,其中我们用重复的BEV查询 { Q , B t − 1 ′ } \{Q, B^′_{t−1}\} {Q,Bt−1′}替换BEV特征 { Q , Q } \{Q, Q\} {Q,Q}。
与[18,38,6]中简单堆叠BEV相比,我们的时间自我注意可以更有效地模拟长时间依赖。BEVFormer从先前的BEV特征中提取时间信息,而不是多个堆叠的BEV特征,因此需要更少的计算成本和更少的干扰信息。
3.5 BEV特征的应用
由于BEV特征 B t ∈ R H × W × C B_t ∈ \mathbb{R}^{H×W ×C} Bt∈RH×W×C是一种多功能的2D特征图,可用于各种自动驾驶感知任务,因此可以基于2D感知方法[56,22]开发3D目标检测和地图分割任务头,只需稍加修改。
3.5.1 3D目标检测
我们设计了一种基于2D探测器可变形DETR的端到端3D检测头[56]。修改包括使用单尺度BEV特征Bt作为解码器的输入,预测3D边界框和速度而不是2D边界框,并且仅使用L1损失来监督3D边界框回归。通过检测头,我们的模型可以端到端地预测三维边界框和速度,而无需NMS后处理。
3.5.2 地图分割
我们设计了一个基于2D分割方法全景分割器的地图分割头[22]。由于基于BEV的地图分割基本上与常见的语义分割相同,我们利用[22]的掩码解码器和类固定查询来针对每个语义类别,包括汽车、车辆、道路(可行驶区域)和车道。
3.6 实施细节
3.6.1 训练阶段
对于时间戳t处的每个样本,我们从过去2秒的连续序列中随机采样另外3个样本,这种随机采样策略可以增加自我运动的多样性[57]。我们将这四个样本的时间戳表示为 t − 3 , t − 2 , t − 1 t−3, t−2, t−1 t−3,t−2,t−1和 t t t。对于前三个时间戳的样本,它们负责循环生成BEV特征 { B t − 3 , B t − 2 , B t − 1 } \{B_{t−3}, B_{t−2}, B_{t−1}\} {Bt−3,Bt−2,Bt−1},该阶段不需要梯度。对于时间戳 t − 3 t−3 t−3的第一个样本,没有先前的BEV特征,时间自注意力退化为自注意力。在时间t,模型基于多摄像机输入和先验BEV特征 B t − 1 B_{t−1} Bt−1生成BEV特征 B t B_t Bt,使得 B t B_t Bt包含跨越四个样本的时间和空间线索。最后,我们将BEV特征 B t B_t Bt输入检测和分割头,并计算相应的损失函数。
3.6.2 推理阶段
在推理阶段,我们按时间顺序评估视频序列的每一帧。前一个时间戳的BEV特征被保存并用于下一个时间戳,这种在线推理策略是省时的,并且与实际应用一致。虽然我们利用时间信息,但我们的推理速度仍然与其他方法相当[45,47]。
4.实验
4.1 数据集
我们在两个具有挑战性的公共自动驾驶数据集上进行实验,即nuScenes数据集[4]和Waymo开放数据集[40]。
nuScenes数据集[4]包含1000个场景,每个场景大约持续20秒,关键样本以2Hz标注。每个样本由来自6台摄像机的RGB图像组成,具有360°水平FOV。对于检测任务,有来自10个类别的140万个带注释的3D边界框。我们按照[32]中的设置来执行BEV分割任务。该数据集还提供了检测任务的官方评估指标。使用地平面上的中心距离而不是联合上的3D交集(IoU)来计算nuScenes的平均精度(mAP),以匹配预测结果和地面真实情况。nuScenes度量还包含5种类型的真正度量(TP度量),包括ATE、ASE、AOE、AVE和AAE,分别用于测量平移、比例、方向、速度和属性误差。nuScenes还将nuScenes检测得分(NDS)定义为
N
D
S
=
1
10
[
5
m
A
P
+
∑
m
T
P
∈
T
P
(
1
−
m
i
n
(
1
,
m
T
P
)
)
]
NDS = \frac{1}{10} [5mAP+∑_{mTP∈TP}(1−min(1, mTP))]
NDS=101[5mAP+∑mTP∈TP(1−min(1,mTP))],以捕获nuScenes检测任务的所有方面。
Waymo开放数据集[40]是一个大规模的自动驾驶数据集,拥有798个训练序列和202个验证序列。请注意,Waymo提供的每一帧的五幅图像只有大约252°的水平FOV,但提供的注释标签是围绕ego汽车的360°。我们移除这些在训练和验证集中的任何图像上都不可见的边界框。由于Waymo开放数据集是大规模和高速率的[34],我们通过从训练序列中每5帧采样一次来使用训练分割的子集,并且仅检测车辆类别。我们使用3D IoU的阈值0.5和0.7来计算Waymo数据集上的地图。
按照前面的方法[45,47,31],我们采用两种类型的主干:从FCOS3D[45]检查点初始化的ResNet101-DCN[15,12]和从DD3D[31]检查点初始化的VoVnet-99[21]。默认情况下,我们利用FPN[23]输出的多尺度特征,其大小为1/16、1/32、1/64,维数为C=256。对于nuScenes上的实验,BEV查询的默认大小为200 × 200,X轴和Y轴的感知范围为[−51.2m, 51.2m],BEV网格的分辨率s大小为0.512米。我们对BEV查询采用可学习的位置嵌入。BEV编码器包含6个编码器层,并不断细化每层中的BEV查询。每个编码器层的输入BEV特性
B
t
−
1
B_{t−1}
Bt−1相同,不需要梯度。对于每个局部查询,在可变形注意机制实现的空间交叉注意模块中,它对应于3D空间中不同高度的
N
r
e
f
=
4
N_{ref}=4
Nref=4个目标点,预定义的高度锚点从5米到3米均匀采样。对于2D视图要素上的每个参考点,我们在每个头部的该参考点周围使用四个采样点。默认情况下,我们用24个epoch训练我们的模型,学习率为
2
×
1
0
−
4
2×10^{−4}
2×10−4。
对于Waymo上的实验,我们更改了一些设置。由于Waymo的摄像系统无法捕捉ego汽车周围的整个场景[40],BEV查询的默认空间形状为300 × 220,X轴的感知范围为[−35.0m, 75.0m],Y轴为[−75.0m, 75.0m]。每个网格的分辨率s为0.5 m。本车在(70,150)的BEV。基线。为了消除任务头的影响并公平地比较其他BEV生成方法,我们使用VPN[30]和Lift-Splat[32]来替换我们的BEVFormer,并保持任务头和其他设置不变。我们还通过在不使用历史BEV特征的情况下将时间自注意力调整为普通自注意力,将BEVFormer调整为称为BEVFormer-S的静态模型。
4.3 3D目标检测结果
我们使用检测头对我们的模型进行检测任务训练,只是为了与以前最先进的3D对象检测方法进行公平的比较。在表1和表2我们报告了nuScenes检验和val集的主要结果。在公平的训练策略和可比的模型尺度下,我们的方法在val集(51.7%NDS对42.5%NDS)上优于以前的最佳方法DETR3D[47]超过9.2分。在测试集上,我们的模型在没有花里胡哨的情况下实现了56.9%的NDS,高于DETR3D(47.9%NDS)9.0分。我们的方法甚至可以实现与一些基于激光雷达的基线相当的性能,如SSN(56.9%NDS)[55]和PointPainting(58.1%NDS)[43]。
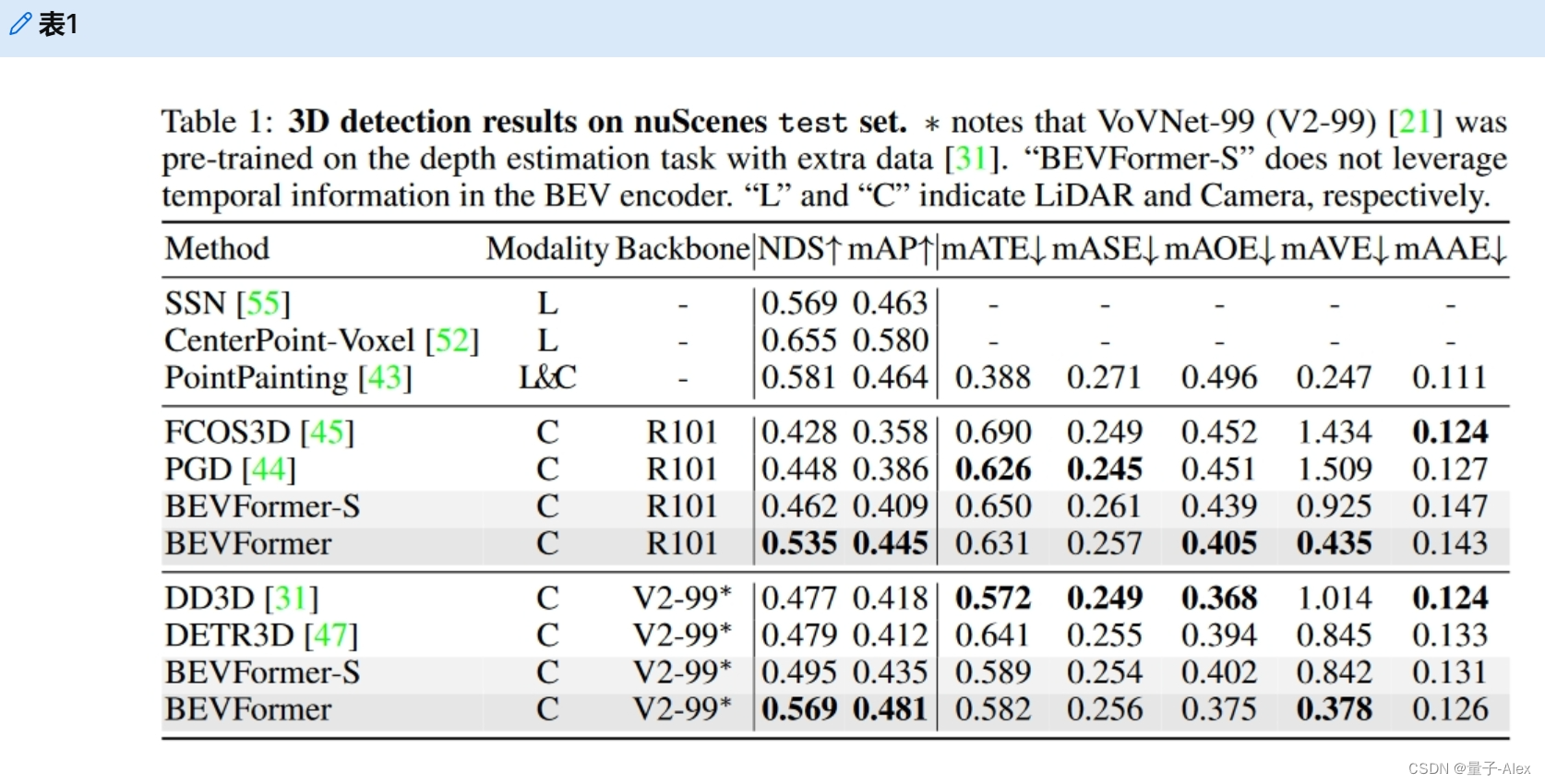 表1 nuScenes测试集上的3D检测结果。*注意到VoVNet-99(V2-99)[21]是用额外数据[31]对深度估计任务进行预训练的。“BEVFormer-S”不利用BEV编码器中的时间信息。“L”和“C”分别表示激光雷达和照相机。
表1 nuScenes测试集上的3D检测结果。*注意到VoVNet-99(V2-99)[21]是用额外数据[31]对深度估计任务进行预训练的。“BEVFormer-S”不利用BEV编码器中的时间信息。“L”和“C”分别表示激光雷达和照相机。
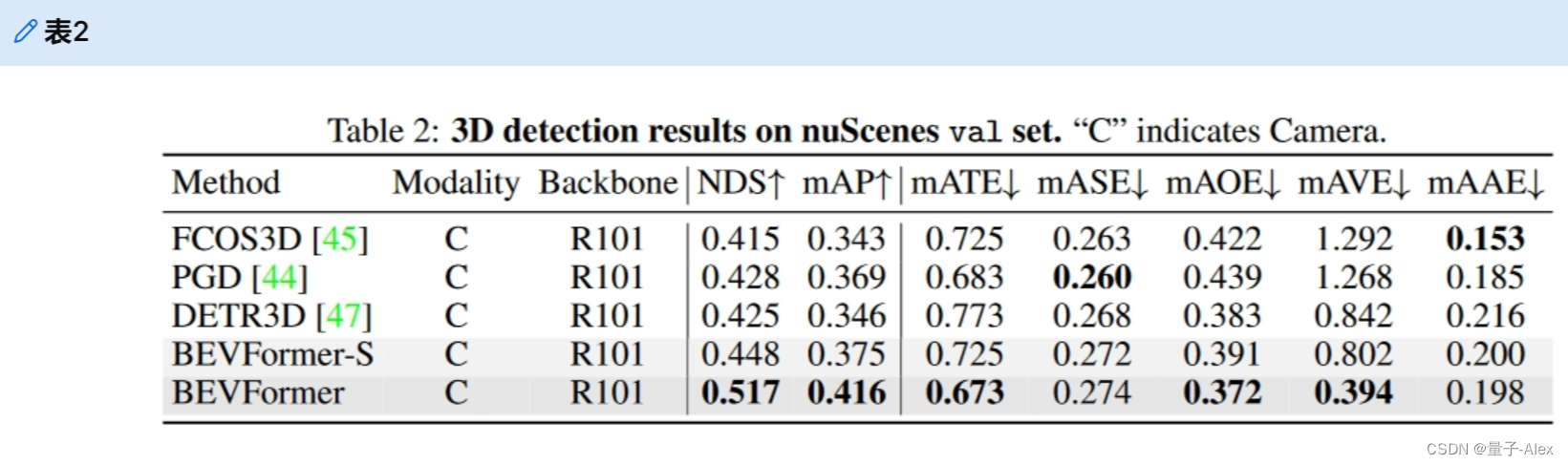 以前基于摄像机的方法[47,31,45]几乎无法估计速度,我们的方法表明,时间信息在多摄像机检测的速度估计中起着至关重要的作用。在测试集上,BEVFormer的平均速度误差(mAVE)为0.378 m/s,远远优于其他基于相机的方法,接近基于激光雷达的方法的性能[43]。
以前基于摄像机的方法[47,31,45]几乎无法估计速度,我们的方法表明,时间信息在多摄像机检测的速度估计中起着至关重要的作用。在测试集上,BEVFormer的平均速度误差(mAVE)为0.378 m/s,远远优于其他基于相机的方法,接近基于激光雷达的方法的性能[43]。
我们还在Waymo上进行实验,如表3所示。根据[34],我们用IoU标准0.7和0.5评估车辆类别。此外,我们还采用nuScenes度量来评估结果,因为基于IoU的度量对于基于相机的方法来说太具有挑战性。由于一些基于相机的作品在Waymo上报告了结果,我们也使用DETR3D的官方代码在Waymo上进行实验进行比较。我们可以观察到,在IoU标准为0.5的1级和2级困难中,BEVFormer的平均精度优于DETR3D,航向信息(APH)[40]分别为6.0%和2.5%。在nuScenes指标上,BEVFormer的表现优于DETR3D,NDS利润率为3.2%,AP利润率为5.2%。我们还在前置摄像头上进行了实验,以比较BEVFormer和CaDNN[34],CaDNN是一种单目3D检测方法,在Waymo数据集上报告了他们的结果。在IoU标准为0.5的1级和2级难度中,BEVFormer的APH分别为13.3%和11.2%,优于CaDNN。
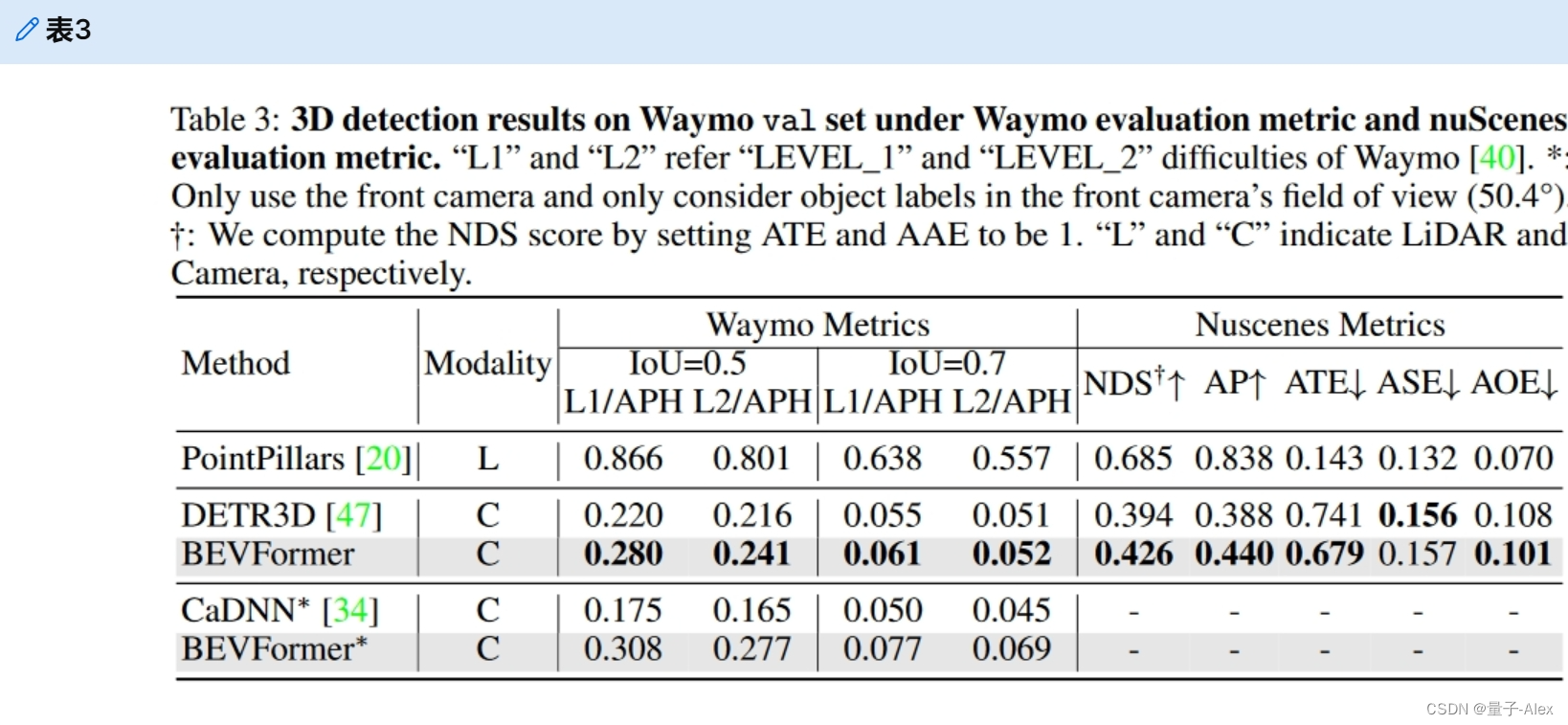
表3:在Waymo评估度量和nuScenes评估度量下Waymo val集上的3D检测结果。“L1”和“L2”指的是Waymo[40]的“1级”和“2级”难度。*:仅使用前置摄像头,并且仅考虑前置摄像头视野(50.4°)中的对象标签。†我们通过将ATE和AAE设置为1来计算NDS评分。“L”和“C”分别表示激光雷达和照相机。
4.4 多任务感知结果
我们用检测头和分割头来训练我们的模型,以验证我们的模型对多任务的学习能力,结果显示在表4中.在相同设置下比较不同的BEV编码器时,除了道路分割结果与BEVFormer-S相当外,BEVFormer在所有任务中都实现了更高的性能。例如,在联合训练中,BEVFormer在检测任务上比Lift-Splat*[32]高出11.0分(52.0%NDS对41.0%NDS),在车道分割上比IoU高出5.6分(23.9%对18.3%)。与单独训练任务相比,多任务学习通过共享更多模块,节省了计算成本,减少了推理时间,包括主干和BEV编码器。在本文中,我们表明由我们的BEV编码器生成的BEV特征可以很好地适应不同的任务,并且具有多任务头的模型训练在检测任务和车辆分割上表现得更好。然而,联合训练的模型在道路和车道分割方面的表现不如单独训练的模型,这是多任务学习中称为负迁移的常见现象[11,13]。
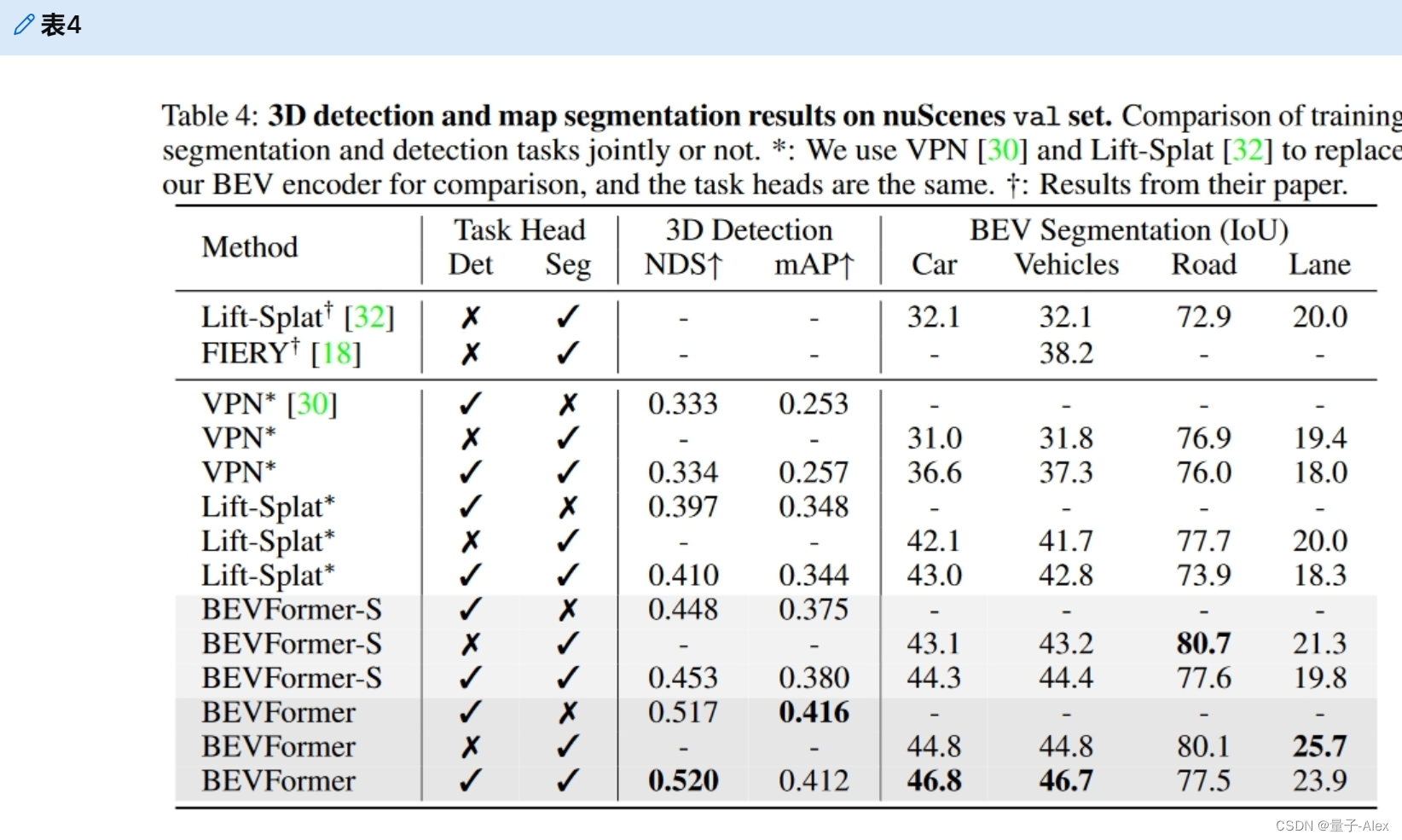
nuScenes val集上的三维检测和地图分割结果。训练分割和检测任务联合与否的比较。*:我们使用VPN[30]和Lift-Splat[32]来代替我们的BEV编码器进行比较,任务头是相同的。†:他们论文的结果。
4.5 消融实验
为了深入研究不同模块的影响,我们对带有检测头的nuScenes val集进行了消融实验。更多消融研究见附录。
4.5.1 空间交叉注意力的有效性
为了验证空间交叉注意的效果,我们使用BEVFormer-S进行消融实验,以排除时间信息的干扰,结果如表5。默认的空间交叉注意力是基于可变形注意力。为了进行比较,我们还构建了另外两个具有不同注意机制的基线:(1)用全局注意力代替可变形注意力;(2)使每个查询只与其参考点而不是周围的局部区域交互,这类似于以前的方法[36,37]。为了进行更广泛的比较,我们还用VPN[30]和Lift-Spalt[32]提出的BEV生成方法替换了BEVFormer。我们可以观察到可变形的注意力在一个可比较的模型尺度下显著优于其他注意力机制。全局注意力消耗太多GPU内存,点交互感受野有限。稀疏注意力实现了更好的性能,因为它与先验确定的感兴趣区域相互作用,平衡了感受野和GPU消耗。
4.5.2 时间自注意力的有效性
从表1和表4,我们可以观察到,在相同的设置下,BEVFormer比BEVFormer-S有显著的改进,尤其是在具有挑战性的检测任务上。时间信息的作用主要体现在以下几个方面:(1)时间信息的引入大大提高了速度估计的精度;(2)利用时间信息预测目标的位置和方向更加准确;(3)如图3所示,由于时间信息包含过去的物体线索,我们对严重遮挡的物体获得更高的回忆。为了评估BEVFormer在具有不同遮挡级别的对象上的性能,我们根据nuScenes提供的官方可见性标签将nuScenes的验证集分为四个子集。在每个子集中,我们还计算匹配过程中中心距离阈值为2米的所有类别的平均召回率。所有方法的预测框最大数量为300,以公平地比较召回率。在只有0-40%的物体可以可见的子集上,BEVFormer的平均召回率优于BEVFormer-S和DETR3D,幅度超过6.0%。
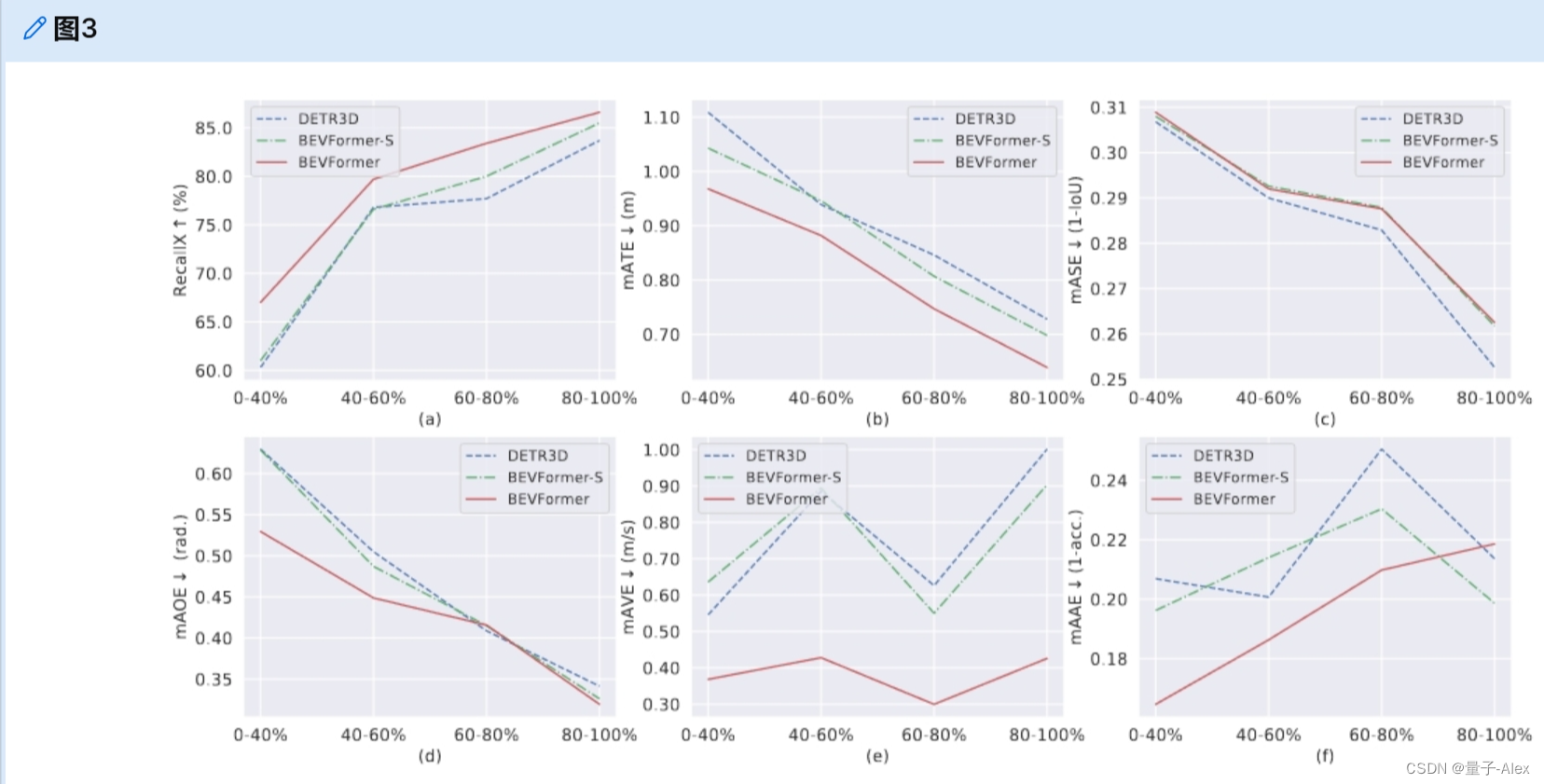
图3:具有不同可见性的子集的检测结果。我们根据{0-40%,40-60%,60-80%,80-100%}的对象可以可见的可见性将nuScenes val集分为四个子集。(a):在时间信息的增强下,BEVFormer对所有子集都有更高的召回率,尤其是对能见度最低的子集(0-40%)。(b)、(d)和(e):时间信息有利于平移、定向和速度精度。©和(f):不同方法之间的尺度和属性误差差距很小。时间信息无助于对象的比例预测。
4.5.3 模型规模与延迟
我们在表6中比较了不同配置的性能和延迟。我们从是否使用多尺度视图特征、BEV查询的形状和层数三个方面对BEVFormer的尺度进行了消融,以验证性能和推理延迟之间的权衡。我们可以观察到,在BEVFormer中使用一个编码器层的配置C实现了50.1%的NDS,并将BEVFormer的延迟从最初的130ms减少到25ms。配置D具有单比例视图功能、较小的BEV尺寸和仅1个编码器层,在推理过程中仅消耗7毫秒,尽管与默认配置相比损失了3.9个点。但由于多视角图像输入,限制效率的瓶颈在于主干,高效的自动驾驶主干值得深入研究。总的来说,我们的架构可以适应各种模型规模,并灵活地权衡性能和效率。

nuScenes val集上不同模型配置的延迟和性能。延迟是在V100 GPU上测量的,主干是R101-DCN。输入图像形状为900 × 1600。“MS”注意到多尺度视图功能。
4.6 可视化结果
我们在图4中示出复杂场景的检测结果。BEVFormer产生了令人印象深刻的结果,除了在小的和远程对象中的一些错误。附录中提供了更多定性结果。

图4:BEVFormer在nuScenes val集上的可视化结果。我们在多摄像机图像和鸟瞰图中展示了3D bboxes预测。
5.讨论与结论
在这项工作中,我们提出了BEVFormer从多摄像机输入生成鸟瞰图特征。BEVFormer可以有效地聚合空间和时间信息,并生成强大的BEV特征,同时支持3D检测和地图分割任务。
局限性。目前,基于相机的方法与基于激光雷达的方法在效果和效率上仍有一定差距。对于基于相机的方法来说,从2D信息精确推断3D位置仍然是一个长期的挑战。
更广泛的影响。BEVFormer证明了使用来自多摄像机输入的时空信息可以显著提高视觉感知模型的性能。BEVFormer展示的优势,如更准确的速度估计和对低可见物体的更高回忆,对于构建更好、更安全的自动驾驶系统及其他系统至关重要。我们相信BEVFormer只是以下更强大的视觉感知方法的基线,基于视觉的感知系统仍有巨大的潜力有待探索。
6.附录
附录A 实施细节
在这一节中,我们提供了所提出的方法和实验的更多实现细节。
A.1 训练策略
按照之前的方法[47,56],我们用24个时期训练所有模型,每个GPU的批量大小为1(包含6个视图图像),学习速率为 2 × 1 0 − 4 2×10^{−4} 2×10−4,主干的学习速率乘数为0.1,我们用余弦退火衰减学习速率[24]。我们采用权重衰减为 1 × 1 0 − 2 1×10^{−2} 1×10−2的AdamW[25]来优化我们的模型。
A.2 VPN and Lift-Splat
在这项工作中,我们使用VPN[30]和Lift-Splat[32]作为两条基线。为了公平比较,主干和任务头与BEVFomer相同。
VPN。我们在这项工作中使用官方代码1。受MLP大量参数的限制,VPN很难生成高分辨率的BEV(例如200 × 200)。为了与VPN进行比较,在这项工作中,我们通过两个视图转换层将单尺度视图特征转换为50 × 50的低分辨率BEV。
Lift-Splat。我们用两个额外的卷积层增强了Lift-Splat2的相机编码器,以便在可比的参数数下与我们的BEVFormer进行公平的比较。其他设置保持不变。
VPN代码
Fetching Data#1nhx
Lift-Splat代码
Fetching Data#xiv0
A.3 任务头
检测头。我们为每个三维边界框预测了10个参数,包括3个参数
(
l
,
w
,
h
)
(l, w, h)
(l,w,h)代表每个框的尺度,3个参数
(
x
o
,
y
o
,
z
o
)
(x_o, y_o, z_o)
(xo,yo,zo)代表中心位置,2个参数
(
c
o
s
(
θ
)
,
s
i
n
(
θ
)
)
(cos(θ), sin(θ))
(cos(θ),sin(θ))代表物体的偏航
θ
θ
θ,2个参数
(
v
x
,
v
y
)
(v_x, v_y)
(vx,vy)代表速度。在训练阶段只使用L1损失和L1成本。在[47]之后,我们使用900个对象查询,并在推理过程中保留300个具有最高置信度分数的预测框。
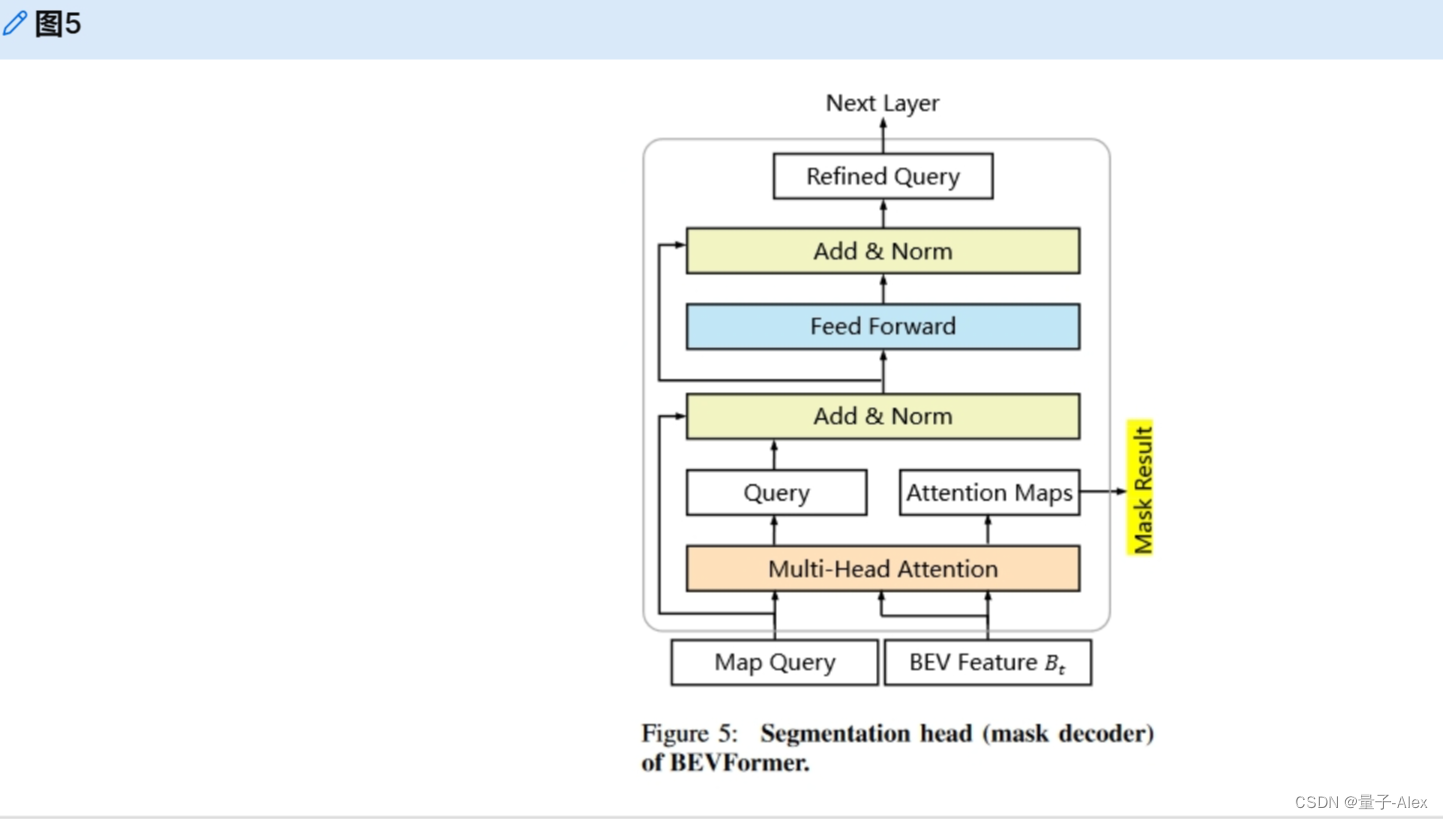
分割头。如图5所示,对于语义映射的每个类别,我们遵循[22]中的掩码解码器,使用一个可学习的查询来表示该类,并基于来自普通多头注意力的注意力映射来生成最终的分割掩码。
A.4 空间交叉注意力
全局注意力。除了可变形注意力[56],我们的空间交叉注意力也可以通过全局注意力(即vanilla 多头注意力)来实现[42]。使用全局注意力的最直接的方法是使每个BEV查询与所有多摄像机特征交互,并且这种概念性的实现不需要摄像机校准。然而,这种简单方法的计算成本是负担不起的。因此,我们仍然利用相机的内在和外在来决定一个BEV查询应该交互的点击视图。这种策略使得一个BEV查询通常只与一个或两个视图交互,而不是与所有视图交互,使得在空间交叉注意力中使用全局注意力成为可能。值得注意的是,与依赖于精确的相机内在和外在的其他注意力机制相比,全局注意力对相机校准更稳健。
附录B 相机外参的鲁棒性
BEVFormer依靠相机内部和外部来获得2D视图上的参考点。在自动驾驶系统的部署阶段,外部可能会由于校准误差、相机偏移等各种原因而产生偏差。如图6所示,我们显示了不同相机外部噪声水平下的模型结果。与BEVFormer-S(点)相比,BEVFormer-S利用基于可变形注意力[56]的空间交叉注意,并对参考点周围的特征进行采样,而不仅仅是与参考点交互。在可变形注意的情况下,BEVFormer-S的鲁棒性比BEVFormer-S(点)强。例如,当噪声水平为4时,BEVFormer-S的NDS下降15.2%(通过1-0.380 0.448计算),而BEVFormer-S的NDS(点)下降17.3%。与BEVFormer-S相比,BEVFormer仅下降了14.3%的NDS,这表明时间信息也可以提高相机外部的鲁棒性。根据[32],我们表明,当用噪声外星训练BEVFormer时,BEVFormer(噪声)具有更强的鲁棒性(仅下降8.9%NDS)。利用基于全局注意力的空间交叉注意力,即使在摄像机外部噪声为4级的情况下,BEVFormer(global)也具有很强的抗干扰能力(NDS下降4.0%)。原因是我们没有利用相机外部来选择BEV查询的ROI。值得注意的是,在最恶劣的噪声下,我们看到BEVFormer-S(全局)甚至优于BEVFormerS(38.8%NDS对38.0%NDS)。
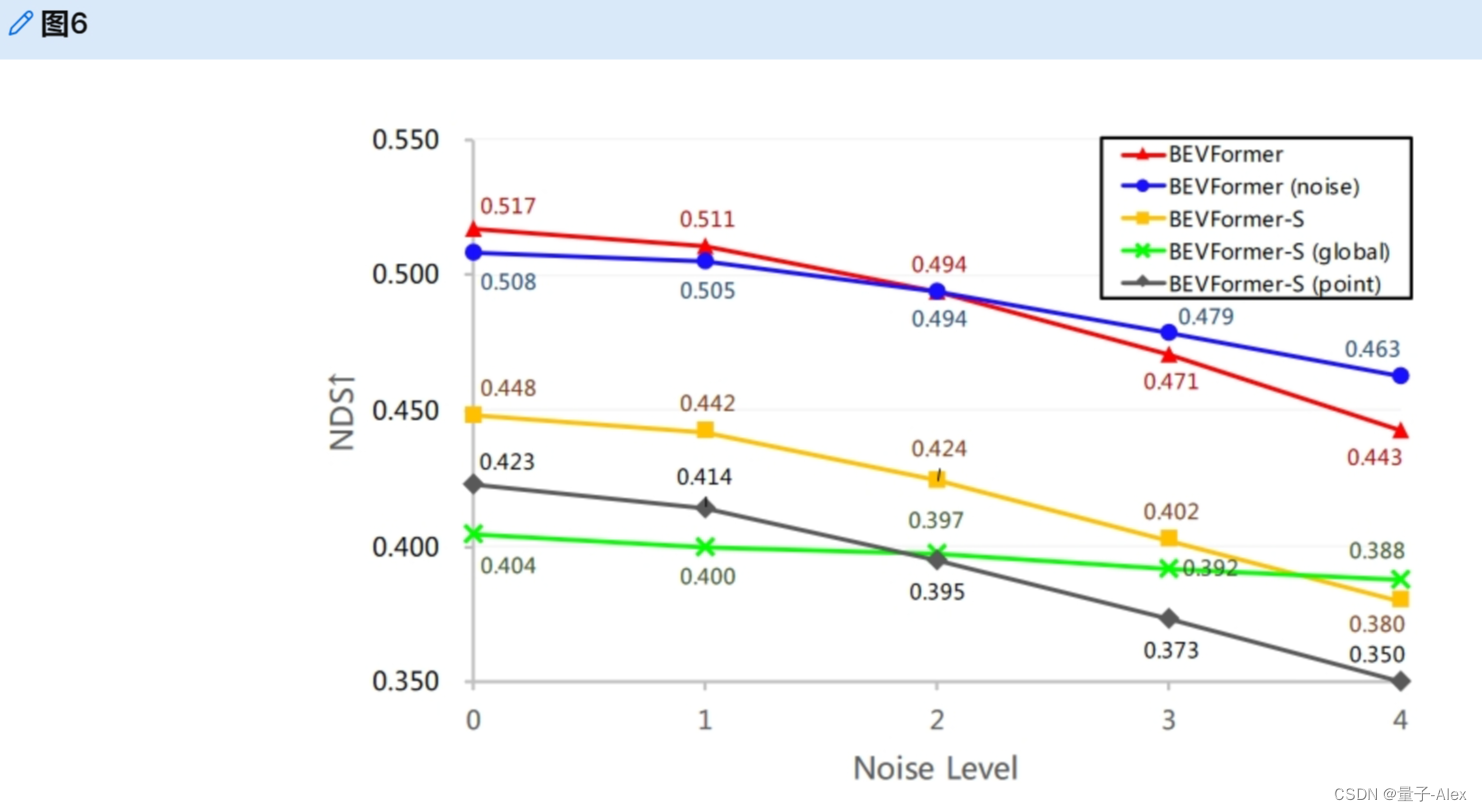
图6:在不同水平的相机外部噪声下,nuScenes val集上的方法的NDS。对于第i级噪声,旋转噪声从均值等于0且方差等于i的正态分布中采样(旋转噪声以度为单位,每个轴的噪声是独立的),平移噪声从均值等于0且方差等于5i的正态分布中采样(平移噪声以厘米为单位,每个方向的噪声是独立的)。“BEVFormer”是我们的默认版本。“BEVFormer(noise)”是用有噪声的外部变量(noise level=1)训练的。“BEVFormer-S”是BEVFormer的静态版本,空间交叉注意力由可变形注意力实现[56]。“BEVFormer-S(全局)”是由全局注意力(即普通多头注意力)实现的空间交叉注意力的BEVFormer-S[42]。“BEVFormer-S(point)”是具有点空间交叉注意力的BEVFormer-S,其中我们仅通过去除预测的偏移和权重,将可变形注意力的交互目标从局部区域降级到参考点。
附录C 消融实验
训练过程中帧数的影响。表7显示了训练期间帧数的效果。我们看到nuScenes val集上的NDS随着帧数的增长而不断上升,并在帧数≥4时开始趋于平稳。因此,我们在实验中将训练期间的帧数默认设置为4。
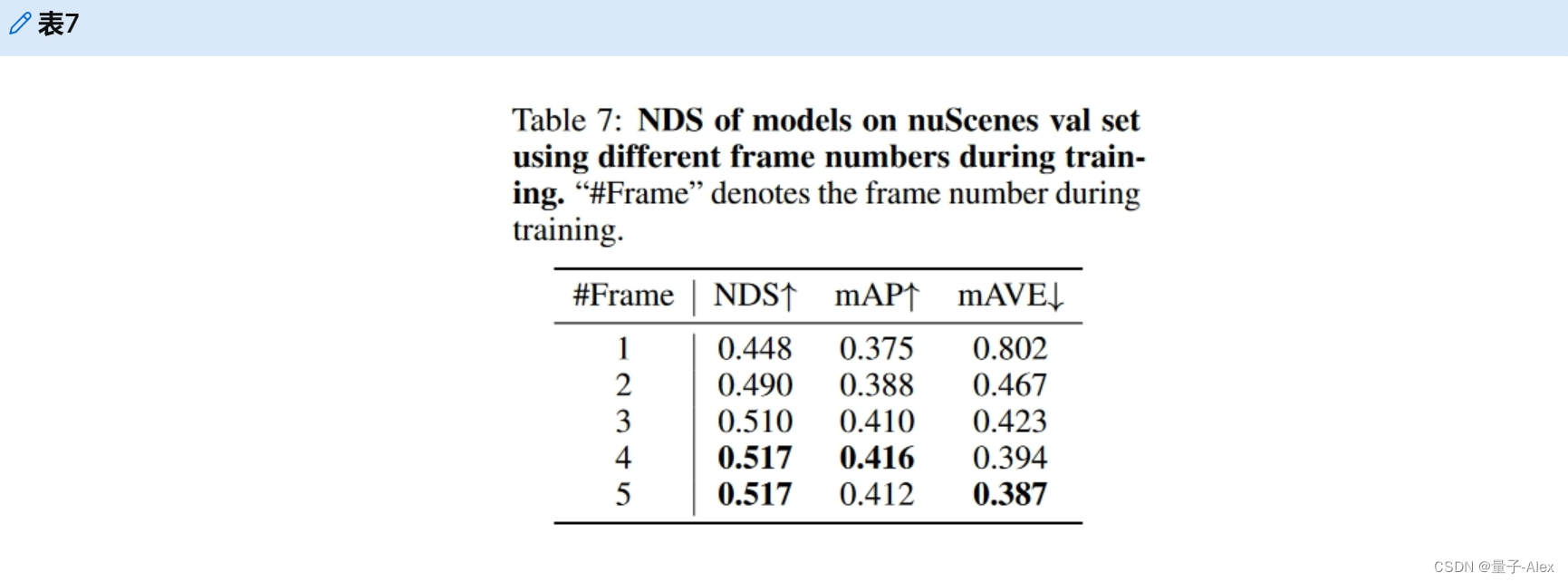
表7:训练期间使用不同帧数的nuScenes val集上模型的NDS。“#frame”表示训练期间的帧数。
一些设计的效果。表8显示了几个消融研究的结果。比较#1和#4,我们看到将历史BEV特征与自我运动对齐对于表示与当前BEV查询相同的几何场景是重要的(51.0%NDS对51.7%NDS)。比较#2和#4,从5帧中随机采样4帧是提高性能的有效数据增加策略(51.3%NDS对51.7%NDS)。与仅使用BEV查询来预测时间自我注意模块期间的偏移和权重相比(见#3),使用BEV查询和历史BEV特征(见#4)包含更多关于过去BEV特征和益处位置预测的线索(51.3%NDS对51.7%NDS)。
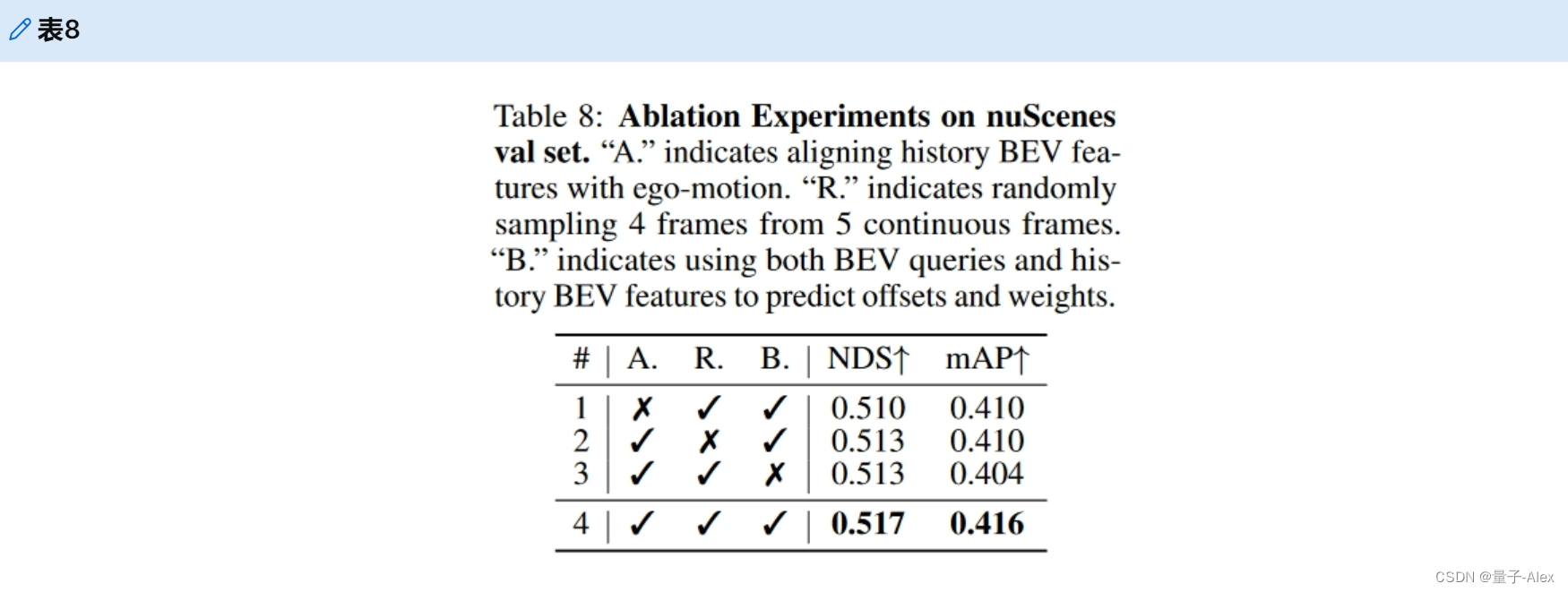
表8:nuScenes val装置上的消融实验。“A”表示将历史BEV特征与自我运动对齐。“R”表示从5个连续帧中随机采样4个帧。“B”表示同时使用BEV查询和历史BEV特征来预测偏移和权重。
附录D 可视化
如图7所示,我们将BEVFormer与BEVFormer-S进行比较。利用时间信息,BEVFormer成功检测到两条被电路板遮挡的总线。我们还在图8中示出对象检测和地图分割结果,其中我们看到检测结果和分割结果高度一致。我们在图9中提供了更多的地图分割结果,其中我们看到,利用由BEVFormer生成的强BEV特征,语义地图可以通过简单的掩码解码器很好地预测。

图7:BEVFormer和BEVFormer-S在nuScenes val集合上的比较。我们可以观察到,BEVFormer可以检测到高度遮挡的物体,这些物体在BEVFormer-S的预测结果中被遗漏(红圈)。
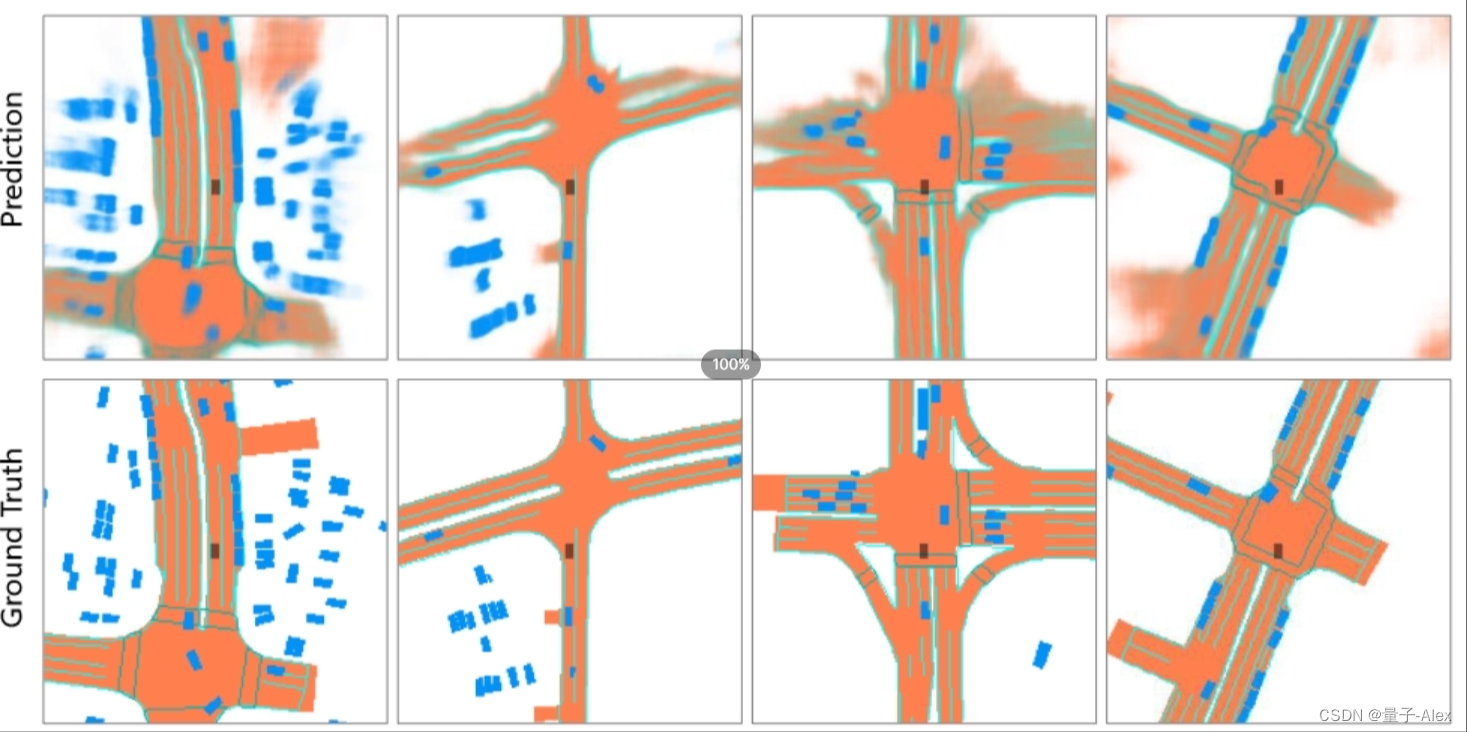
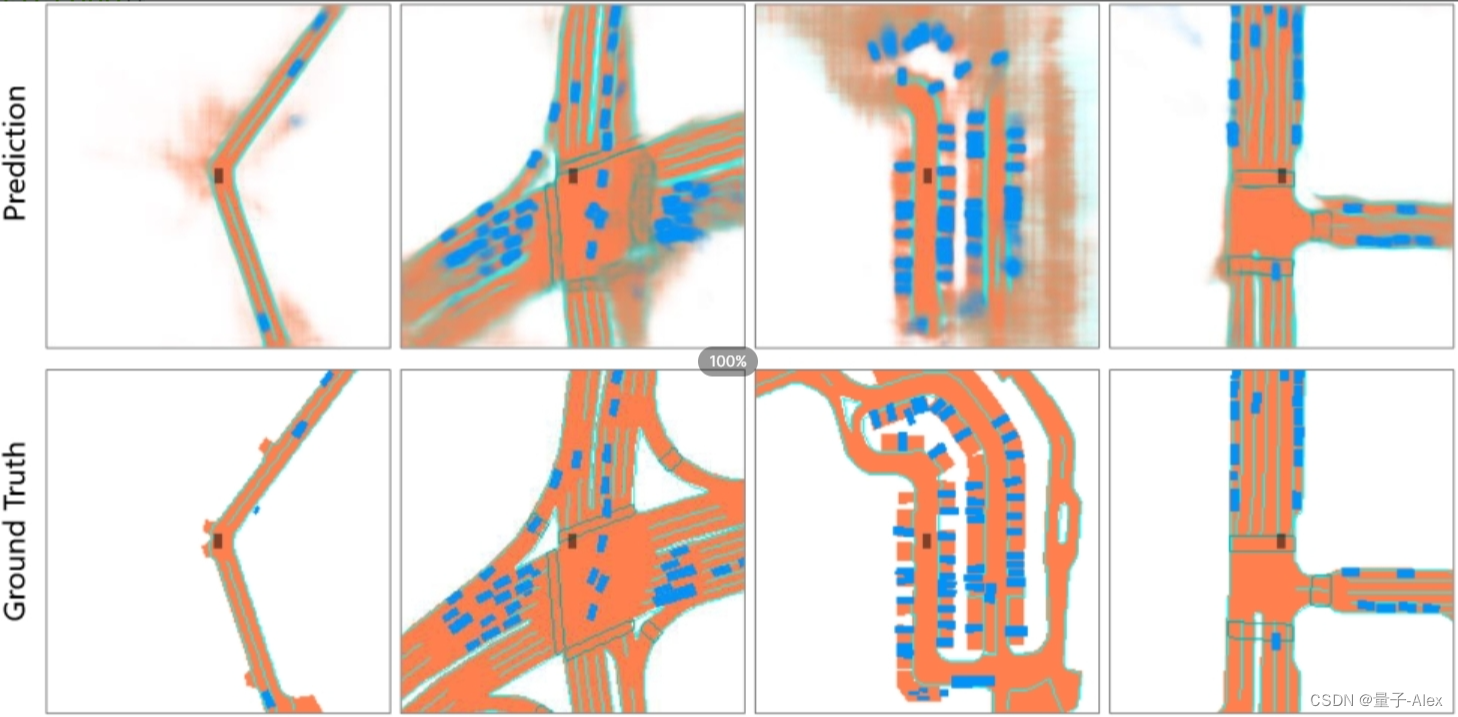
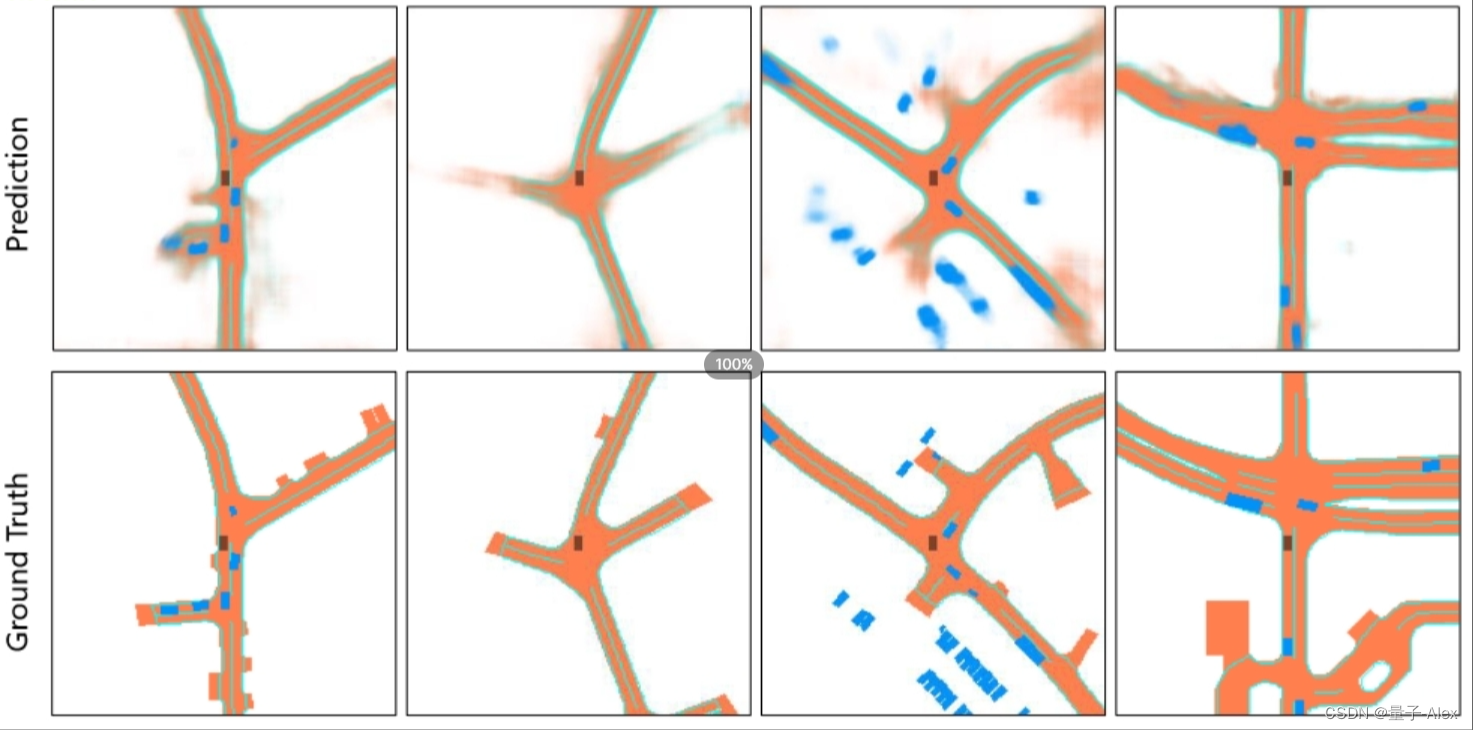
 图8:目标检测和地图分割任务的可视化结果。我们分别用蓝色、橙色和绿色显示车辆、道路和车道分段。
图8:目标检测和地图分割任务的可视化结果。我们分别用蓝色、橙色和绿色显示车辆、道路和车道分段。