文章目录
- 01 Elasticsearch Sink 基础概念
- 02 Elasticsearch Sink 工作原理
- 03 Elasticsearch Sink 核心组件
- 04 Elasticsearch Sink 配置参数
- 05 Elasticsearch Sink 依赖管理
- 06 Elasticsearch Sink 初阶实战
- 07 Elasticsearch Sink 进阶实战
- 7.1 包结构 & 项目配置
- 项目配置application.properties
- 日志配置log4j2.properties
- 项目pom.xml文件
- 7.2 实体类ElasticsearchEntity
- 7.3 客户端工厂类CustomRestClientFactory
- 7.4 回调函数类CustomRequestConfigCallback
- 7.5 客户端配置类CustomHttpClientConfigCallback
- 7.6 Es操作类CustomElasticsearchSinkFunction
- 7.7 异常处理类CustomActionRequestFailureHandler
- 7.8 作业主类ElasticsearchSinkStreamJobAdvancedDemo
01 Elasticsearch Sink 基础概念
Flink的Elasticsearch Sink是用于将Flink数据流(DataStream)中的数据发送到Elasticsearch的组件。它是Flink的一个连接器(Connector),用于实现将实时处理的结果或数据持续地写入Elasticsearch集群中的索引中。
下面是一些关于Flink的Elasticsearch Sink的基础概念:
- 数据源(Source):Flink数据流的源头,可以是各种数据源,例如Kafka、文件系统、Socket等。Elasticsearch Sink通常是连接到Flink数据流的末端,用于将最终处理结果或数据写入Elasticsearch。
- Elasticsearch集群:一个或多个Elasticsearch节点的集合,用于存储和处理数据。Elasticsearch提供了分布式的数据存储和搜索功能。
- 索引(Index):在Elasticsearch中,索引是存储相关数据的地方,类似于关系数据库中的表。每个索引可以包含多个文档(Document),每个文档包含一个或多个字段(Field)。
- 文档(Document):在Elasticsearch中,文档是最小的数据单元。它们以JSON格式表示,并存储在索引中。
- Elasticsearch Sink:是Flink的一个数据接收器,用于将数据流中的数据发送到Elasticsearch集群中的特定索引。Sink负责将Flink数据流中的事件转换为Elasticsearch要求的格式,并将其发送到指定的索引。
- 序列化与映射:在将数据写入Elasticsearch之前,通常需要对数据进行序列化和映射。序列化是将数据从Flink的内部表示转换为Elasticsearch要求的JSON格式。映射则是定义如何将Flink数据流中的字段映射到Elasticsearch文档中的字段。
- 并行度控制:Elasticsearch Sink支持并行度控制,可以根据需要调整并发写入Elasticsearch的任务数量。这有助于优化性能并避免对Elasticsearch集群造成过大的负载。
总的来说,Flink的Elasticsearch Sink是一个关键的组件,用于将实时处理的结果或数据可靠地写入Elasticsearch中,从而支持各种实时数据分析和搜索应用。
02 Elasticsearch Sink 工作原理
Elasticsearch Sink 是 Apache Flink 提供的一个连接器,用于将 Flink 数据流中的数据发送到 Elasticsearch 集群中。以下是 Elasticsearch Sink 的工作原理:
- 数据流入 Flink 程序: 数据首先从外部数据源(如 Kafka、RabbitMQ、文件系统等)进入到 Flink 程序中。Flink 以流式处理的方式处理数据,这意味着数据会一条一条地进入 Flink 的数据流中。
- 数据转换与处理: 一旦数据进入 Flink,您可以对数据进行各种转换和处理。这可能包括数据清洗、转换、聚合、窗口操作等。在您的 Flink 程序中,您可以通过各种 Flink 的算子来实现这些转换和处理。
- Elasticsearch Sink 的配置: 当需要将数据写入 Elasticsearch 时,您需要配置 Elasticsearch Sink。这通常包括指定 Elasticsearch 集群的地址、端口、索引名称等信息。您还可以配置其他参数,例如批量写入的大小、超时时间等。
- 数据发送到 Elasticsearch: 一旦配置完成,Elasticsearch Sink 会将 Flink 数据流中的数据转换为 JSON 格式,并通过 Elasticsearch 的 REST API 将数据发送到指定的索引中。通常,Elasticsearch Sink 会将数据批量发送到 Elasticsearch,以提高写入的效率和性能。
- 序列化与映射: 在发送数据之前,通常需要将 Flink 数据流中的数据序列化为 JSON 格式,并根据 Elasticsearch 索引的映射规则进行字段映射。这确保了发送到 Elasticsearch 的数据与索引的结构一致。
- 容错与错误处理: Flink 提供了容错机制来确保数据的可靠性和一致性。如果在数据发送过程中发生错误,例如网络故障或 Elasticsearch 集群不可用,Flink 会自动进行故障恢复,并重新发送丢失的数据,以确保数据不会丢失。
- 性能优化: 为了提高性能,Elasticsearch Sink 可以通过调整批量写入的大小、并发度等参数来优化性能。这可以减少与 Elasticsearch 的通信开销,并提高写入的效率。
总的来说,Elasticsearch Sink 通过将 Flink 数据流中的数据转换为 JSON 格式,并利用 Elasticsearch 的 REST API 将数据发送到指定的索引中,实现了将实时流数据写入 Elasticsearch 的功能。
03 Elasticsearch Sink 核心组件
Elasticsearch Sink 在 Apache Flink 中是一个核心组件,它负责将 Flink 数据流中的数据发送到 Elasticsearch。下面是 Elasticsearch Sink 的核心组件:
- SinkFunction: SinkFunction 是 Flink 中的一个接口,用于定义将数据发送到外部系统的逻辑。在 Elasticsearch Sink 中,您需要实现 SinkFunction 接口,以将 Flink 数据流中的数据发送到 Elasticsearch。通常,您需要在 SinkFunction 中实现将数据转换为 JSON 格式,并通过 Elasticsearch 的 REST API 将数据发送到指定的索引中。
- BulkProcessor: BulkProcessor 是 Elasticsearch Java 客户端提供的一个功能,用于批量写入数据到 Elasticsearch。在 Elasticsearch Sink 中,BulkProcessor 负责将 Flink 数据流中的数据批量发送到 Elasticsearch。您可以通过 BulkProcessor 来配置批量写入的大小、并发度等参数,以优化写入性能。
- TransportClient 或 RestHighLevelClient: 在 Elasticsearch Sink 中,您可以使用 Elasticsearch Java 客户端的 TransportClient 或 RestHighLevelClient 来与 Elasticsearch 集群进行通信。这些客户端提供了与 Elasticsearch 集群交互的接口,使您可以发送数据到 Elasticsearch、执行查询、索引管理等操作。
- 序列化器(Serializer): 在将数据发送到 Elasticsearch 之前,通常需要将 Flink 数据流中的数据序列化为 JSON 格式。序列化器负责将 Flink 数据流中的数据转换为 Elasticsearch 所需的 JSON 格式。您可以根据具体的数据类型和业务需求来实现自定义的序列化器。
- Elasticsearch 连接配置: 在 Elasticsearch Sink 中,您需要配置与 Elasticsearch 集群的连接信息,包括 Elasticsearch 集群的地址、端口、索引名称等。这些配置信息通常在初始化 Elasticsearch Sink 时进行设置,并在发送数据时使用。
- 容错与错误处理机制: Elasticsearch Sink 需要具备容错和错误处理机制,以确保数据的可靠性和一致性。如果在数据发送过程中发生错误,例如网络故障或 Elasticsearch 集群不可用,Sink 需要能够进行故障恢复,并重新发送丢失的数据,以确保数据不会丢失。
这些组件共同作用,构成了 Elasticsearch Sink 在 Flink 中的核心功能,使得 Flink 用户可以轻松地将实时流数据发送到 Elasticsearch,并实现各种实时数据分析和搜索应用。
04 Elasticsearch Sink 配置参数
nodes :Elasticsearch 集群的节点地址列表
port :Elasticsearch 集群的端口
Elasticsearch 集群的节点地址列表
scheme : Elasticsearch 集群的通信协议,http或https
type :Elasticsearch 集群的文档类型,es7以后是_doc
index :Elasticsearch 集群的索引名称
bulkFlushMaxActions :内部批量处理器,刷新前最大缓存的操作数
bulkFlushMaxSizeMb :刷新前最大缓存的数据量(以兆字节为单位)
bulkFlushInterval :刷新的时间间隔(不论缓存操作的数量或大小如何)
bulkFlushBackoff :是否启用批量写入的退避策略,当Elasticsearch 写入失败时,可以启用退避策略,以避免频繁的重试。此时,setBulkFlushBackoffDelay 和 setBulkFlushBackoffRetries 参数生效。
bulkFlushBackoffDelay :设置批量写入的退避延迟时间,在发生写入失败后,等待指定的延迟时间后再进行重试
bulkFlushBackoffRetries :设置批量写入的最大重试次数,设置在写入失败后的最大重试次数。超过这个次数后,将不再重试
connectTimeout :设置与 Elasticsearch 集群建立连接的超时时间,单位为毫秒。在指定的时间内无法建立连接将会抛出连接超时异常
socketTimeout :设置与 Elasticsearch 连接的套接字超时时间,单位为毫秒。该参数定义了在建立连接后从服务器读取数据的超时时间。
connectionRequestTimeout :设置连接请求超时时间,单位为毫秒。该参数表示从连接池获取连接的超时时间。如果在指定的时间内无法获得连接,将会抛出连接请求超时异常。
redirectsEnabled :设置是否允许重定向。如果设置为true,则当遇到重定向响应时,客户端将跟随重定向并继续请求;如果设置为false,重定向响应将被视为错误。
maxRedirects :客户端允许的最大重定向次数
authenticationEnabled :启用身份验证功能。通过设置该参数为true,可以提供用户名和密码进行身份验证,以连接到 Elasticsearch 集群。
circularRedirectsAllowed :设置是否允许循环重定向。如果设置为true,则允许在重定向过程中发生循环重定向;如果设置为false,则在检测到循环重定向时,将会抛出异常。
contentCompressionEnabled :设置是否启用内容压缩。如果设置为true,则允许客户端和 Elasticsearch 之间进行内容压缩,以减少数据传输量。
expectContinueEnabled :设置是否启用 “Expect: continue” 机制。当设置为true时,在发送请求之前,客户端会发送一个请求头部,询问服务器是否接受请求的主体部分。如果服务器响应允许继续发送请求主体,则客户端会继续发送请求;如果服务器响应拒绝继续发送请求主体,则客户端会放弃该请求。
normalizeUri :设置是否标准化 URI。如果设置为true,则客户端会尝试标准化请求 URI,以便消除多余和重复的斜杠等
05 Elasticsearch Sink 依赖管理
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_1.12</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_1.12</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_1.12</artifactId>
<version>1.14.4</version>
</dependency>
06 Elasticsearch Sink 初阶实战
package com.aurora.demo;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import org.elasticsearch.common.xcontent.XContentType;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.UUID;
/**
* 描述:Flink集成Elasticsearch Connector连接器快速入门运行demo
* 实现实时数据流如何无缝地流向Elasticsearch
*
* @author 浅夏的猫
* @version 1.0.0
* @date 2024-02-13 22:25:58
*/
public class ElasticsearchSinkStreamJobQuickDemo {
private static final Logger logger = LoggerFactory.getLogger(ElasticsearchSinkStreamJobQuickDemo.class);
public static void main(String[] args) throws Exception {
// 创建elasticsearch集群的httpHost连接
HttpHost httpHost = new HttpHost("localhost", 9200, "http");
List<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(httpHost);
// 创建elasticsearchSinkFunction函数对象,专门用于处理数据写入elasticsearchSink算子队列,会自动创建索引
ElasticsearchSinkFunction<JSONObject> elasticsearchSinkFunction = new ElasticsearchSinkFunction<JSONObject>() {
@Override
public void process(JSONObject element, RuntimeContext runtimeContext, RequestIndexer indexer) {
String transId = element.getString("transId");
String tradeTime = element.getString("tradeTime");
String index = "flink_" + tradeTime;
logger.info("交易流水={},数据写入索引{}成功", transId, index);
IndexRequest indexRequest = Requests.indexRequest().index(index).type("_doc").id(transId).source(element, XContentType.JSON);
indexer.add(indexRequest);
}
};
// 构建elasticsearchSink算子Builder
ElasticsearchSink.Builder<JSONObject> esSinkBuilder = new ElasticsearchSink.Builder<>(httpHosts, elasticsearchSinkFunction);
// 每个请求最多发送的文档数量
esSinkBuilder.setBulkFlushMaxActions(1);
// 每次发送请求的时间间隔
esSinkBuilder.setBulkFlushInterval(1000);
//构建elasticsearchSink算子
ElasticsearchSink<JSONObject> sink = esSinkBuilder.build();
// 自定义数据源,模拟生产环境交易接入,每秒下发一个json格式数据
SourceFunction<JSONObject> dataSource = new SourceFunction<JSONObject>() {
@Override
public void run(SourceContext sourceContext) throws Exception {
while (true) {
//交易流水号
String tradeId = UUID.randomUUID().toString();
//交易发生时间戳
long timeStamp = System.currentTimeMillis();
//交易发生金额
long tradeAmount = new Random().nextInt(1000);
//交易名称
String tradeName = "支付宝转账";
JSONObject dataObj = new JSONObject();
dataObj.put("transId", tradeId);
dataObj.put("timeStamp", timeStamp);
dataObj.put("tradeTime", dateUtil(timeStamp));
dataObj.put("tradeAmount", tradeAmount);
dataObj.put("tradeName", tradeName);
//模拟生产,每隔1秒生成一笔交易
Thread.sleep(1000);
logger.info("源交易流水={},原始报文={}", tradeId, dataObj.toJSONString());
sourceContext.collect(dataObj);
}
}
@Override
public void cancel() {
}
};
// 创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 构建数据源
DataStreamSource<JSONObject> dataStreamSource = env.addSource(dataSource);
// 数据源写入数据算子,进行输出到elasticsearch
dataStreamSource.addSink(sink);
// 执行任务
env.execute();
}
/**
* 描述:时间格式化工具类
*
* @param timestamp 时间戳
* @return {@code String }
*/
private static String dateUtil(long timestamp) {
//时间戳加工
timestamp = timestamp / 1000;
// 将时间戳转换为 LocalDateTime 对象
LocalDateTime dateTime = LocalDateTime.ofInstant(Instant.ofEpochSecond(timestamp), ZoneId.systemDefault());
// 定义日期时间格式
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyyMMdd");
// 格式化日期时间对象为指定格式的字符串
String dateTimeFormat = formatter.format(dateTime);
return dateTimeFormat;
}
}
启动上述作业后,根据对应的交易流水号查询es,或者查询es的索引数据,但是索引数据一般是一段时间才更新
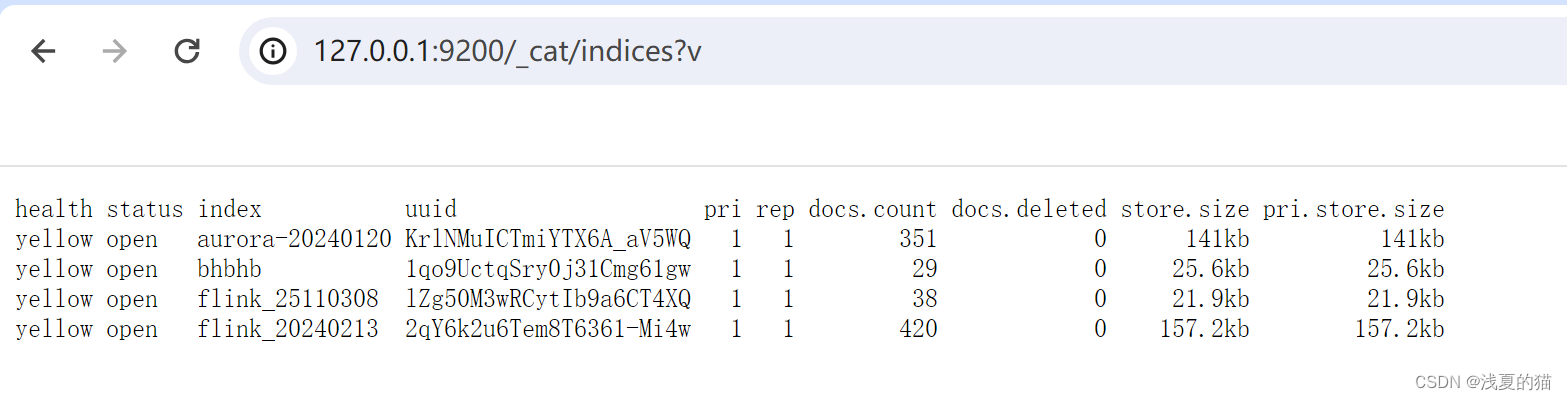
验证1:检查索引数据变化
http://127.0.0.1:9200/_cat/indices?v
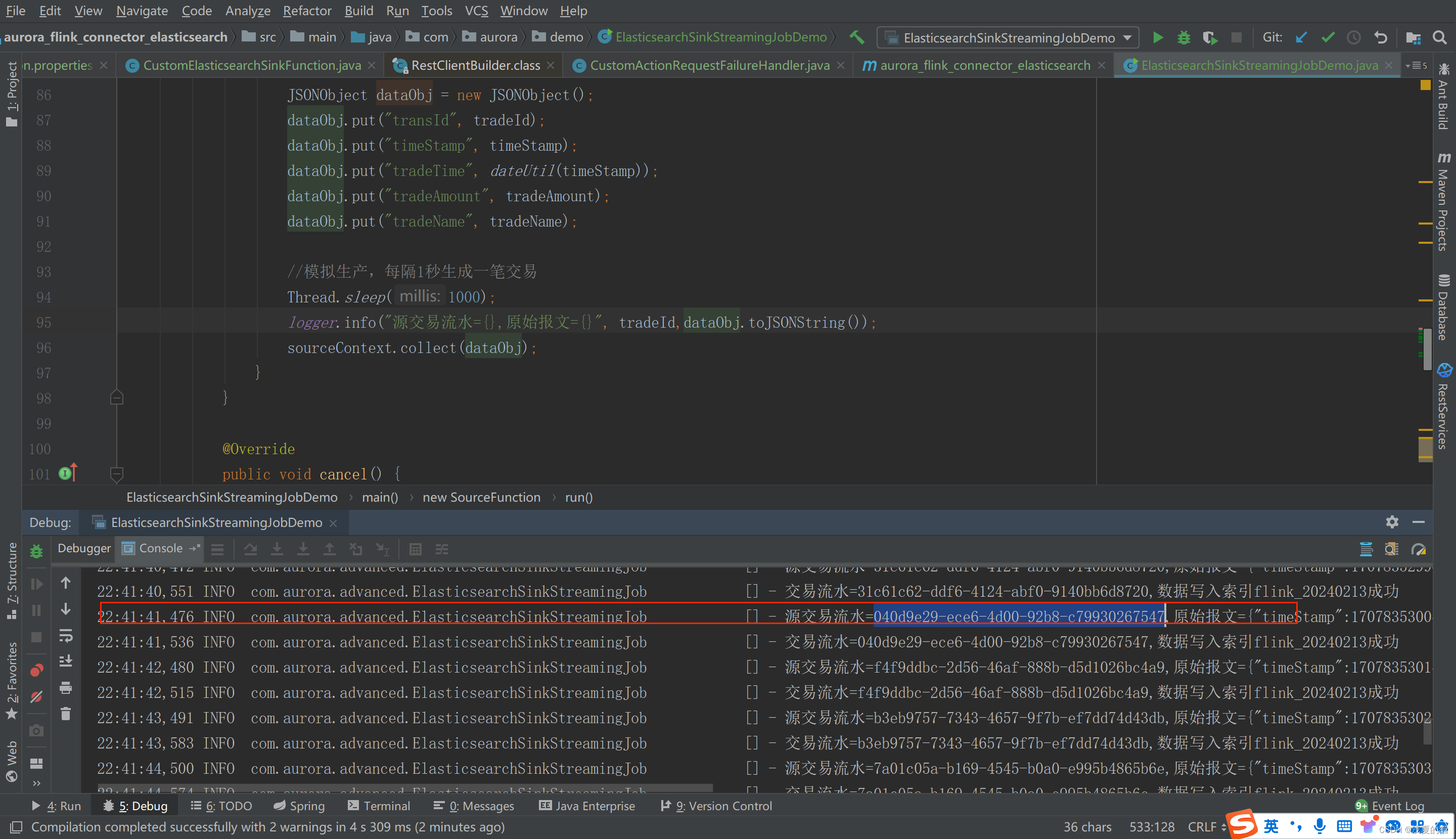
验证2:根据id查询es的文档记录

07 Elasticsearch Sink 进阶实战
进阶实战主要是包括ElasticsearchSink的各种参数配置,以及性能调优
7.1 包结构 & 项目配置
项目配置application.properties
es.cluster.hosts=localhost
es.cluster.port=9200
es.cluster.scheme=http
es.cluster.type=_doc
es.cluster.indexPrefix=flink_
#内部批量处理器,刷新前最大缓存的操作数
es.cluster.bulkFlushMaxActions=1
#刷新前最大缓存的数据量(以兆字节为单位)
es.cluster.bulkFlushMaxSizeMb=10
#刷新的时间间隔(不论缓存操作的数量或大小如何)
es.cluster.bulkFlushInterval=10000
#是否启用批量写入的退避策略,当Elasticsearch 写入失败时,可以启用退避策略,以避免频繁的重试。此时,setBulkFlushBackoffDelay 和 setBulkFlushBackoffRetries 参数生效。
es.cluster.bulkFlushBackoff=false
#设置批量写入的退避延迟时间,在发生写入失败后,等待指定的延迟时间后再进行重试
es.cluster.bulkFlushBackoffDelay=10000
#设置批量写入的最大重试次数,设置在写入失败后的最大重试次数。超过这个次数后,将不再重试
es.cluster.bulkFlushBackoffRetries=3
#设置与 Elasticsearch 集群建立连接的超时时间,单位为毫秒。在指定的时间内无法建立连接将会抛出连接超时异常
es.cluster.connectTimeout=10000
#设置与 Elasticsearch 连接的套接字超时时间,单位为毫秒。该参数定义了在建立连接后从服务器读取数据的超时时间。
es.cluster.socketTimeout=10000
#设置连接请求超时时间,单位为毫秒。该参数表示从连接池获取连接的超时时间。如果在指定的时间内无法获得连接,将会抛出连接请求超时异常。
es.cluster.connectionRequestTimeout=10000
设置是否允许重定向。如果设置为true,则当遇到重定向响应时,客户端将跟随重定向并继续请求;如果设置为false,重定向响应将被视为错误。
es.cluster.redirectsEnabled=false
#客户端允许的最大重定向次数
es.cluster.maxRedirects=3
#启用身份验证功能。通过设置该参数为true,可以提供用户名和密码进行身份验证,以连接到 Elasticsearch 集群。
es.cluster.authenticationEnabled=false
#设置是否允许循环重定向。如果设置为true,则允许在重定向过程中发生循环重定向;如果设置为false,则在检测到循环重定向时,将会抛出异常。
es.cluster.circularRedirectsAllowed=false
#设置是否启用内容压缩。如果设置为true,则允许客户端和 Elasticsearch 之间进行内容压缩,以减少数据传输量。
es.cluster.contentCompressionEnabled=false
#设置是否启用 "Expect: continue" 机制。当设置为true时,在发送请求之前,客户端会发送一个请求头部,询问服务器是否接受请求的主体部分。如果服务器响应允许继续发送请求主体,则客户端会继续发送请求;如果服务器响应拒绝继续发送请求主体,则客户端会放弃该请求。
es.cluster.expectContinueEnabled=false
#设置是否标准化 URI。如果设置为true,则客户端会尝试标准化请求 URI,以便消除多余和重复的斜杠等。
es.cluster.normalizeUri=false
日志配置log4j2.properties
rootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmprootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmp
项目pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.aurora</groupId>
<artifactId>aurora_elasticsearch_connector</artifactId>
<version>1.0-SNAPSHOT</version>
<!--属性设置-->
<properties>
<!--java_JDK版本-->
<java.version>1.8</java.version>
<!--maven打包插件-->
<maven.plugin.version>3.8.1</maven.plugin.version>
<!--编译编码UTF-8-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--输出报告编码UTF-8-->
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<!--json数据格式处理工具-->
<fastjson.version>1.2.75</fastjson.version>
<!--log4j版本-->
<log4j.version>2.17.1</log4j.version>
<!--flink版本-->
<flink.version>1.14.4</flink.version>
<!--scala版本-->
<scala.binary.version>2.12</scala.binary.version>
</properties>
<!--依赖管理-->
<dependencies>
<!-- fastJson工具类依赖 start -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<!-- fastJson工具类依赖 end -->
<!-- log4j日志框架依赖 start -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
<!-- log4j日志框架依赖 end -->
<!-- Flink基础依赖 start -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Flink基础依赖 end -->
<!-- Flink Elasticsearch 连接器依赖 start -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Flink Elasticsearch 连接器依赖 end -->
</dependencies>
<!--编译打包-->
<build>
<finalName>${project.name}</finalName>
<!--资源文件打包-->
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>org.google.code.flindbugs:jar305</exclude>
<exclude>org.slf4j:*</exclude>
<excluder>org.apache.logging.log4j:*</excluder>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.aurora.demo,ElasticsearchSinkStreamingJobDemo</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<!--插件统一管理-->
<pluginManagement>
<plugins>
<!--maven打包插件-->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring.boot.version}</version>
<configuration>
<fork>true</fork>
<finalName>${project.build.finalName}</finalName>
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
<!--编译打包插件-->
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.plugin.version}</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>UTF-8</encoding>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
7.2 实体类ElasticsearchEntity
package com.aurora.advanced;
import java.io.Serializable;
/**
* 描述:elasticsearch实体类
*
* @author 浅夏的猫
* @version 1.0.0
* @date 2024-02-10 20:08:20
*/
public class ElasticsearchEntity implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 集群地址
* */
private String hosts;
/**
* 集群端口
* */
private Integer port;
/**
*执行计划
* */
private String scheme;
/**
* 文档类型,es7一般都是_doc
* */
private String type;
/**
* 索引前缀
* */
private String indexPrefix;
/**
* 内部批量处理器,刷新前最大缓存的操作数
* */
private Integer bulkFlushMaxActions=1;
/**
* 刷新前最大缓存的数据量(以兆字节为单位)
* */
private Integer bulkFlushMaxSizeMb=10;
/**
* 刷新的时间间隔(不论缓存操作的数量或大小如何)
* */
private Integer bulkFlushInterval=10000;
/**
* 是否启用批量写入的退避策略,当Elasticsearch 写入失败时,可以启用退避策略,以避免频繁的重试。
* 此时,setBulkFlushBackoffDelay 和 setBulkFlushBackoffRetries 参数生效。
* */
private Boolean bulkFlushBackoff=false;
/**
* 设置批量写入的退避延迟时间,在发生写入失败后,等待指定的延迟时间后再进行重试
* */
private Integer bulkFlushBackoffDelay=10000;
/**
* 设置批量写入的最大重试次数,设置在写入失败后的最大重试次数。超过这个次数后,将不再重试
* */
private Integer bulkFlushBackoffRetries=3;
/**
* 设置与 Elasticsearch 集群建立连接的超时时间,单位为毫秒。在指定的时间内无法建立连接将会抛出连接超时异常
* */
private Integer connectTimeout=10000;
/**
* 设置与 Elasticsearch 连接的套接字超时时间,单位为毫秒。该参数定义了在建立连接后从服务器读取数据的超时时间。
* */
private Integer socketTimeout=10000;
/**
* 设置连接请求超时时间,单位为毫秒。该参数表示从连接池获取连接的超时时间。如果在指定的时间内无法获得连接,将会抛出连接请求超时异常。
* */
private Integer connectionRequestTimeout=10000;
/**
* 设置是否允许重定向。如果设置为true,则当遇到重定向响应时,客户端将跟随重定向并继续请求;如果设置为false,重定向响应将被视为错误。
* */
private Boolean redirectsEnabled=false;
/**
* 客户端允许的最大重定向次数
* */
private Integer maxRedirects=3;
/**
* 启用身份验证功能。通过设置该参数为true,可以提供用户名和密码进行身份验证,以连接到 Elasticsearch 集群。
* */
private Boolean authenticationEnabled=true;
/**
* 设置是否允许循环重定向。如果设置为true,则允许在重定向过程中发生循环重定向;如果设置为false,则在检测到循环重定向时,将会抛出异常。
* */
private Boolean circularRedirectsAllowed=false;
/**
* 设置是否启用内容压缩。如果设置为true,则允许客户端和 Elasticsearch 之间进行内容压缩,以减少数据传输量。
* */
private Boolean contentCompressionEnabled=false;
/**
* 设置是否启用 "Expect: continue" 机制。当设置为true时,在发送请求之前,客户端会发送一个请求头部,询问服务器是否接受请求的主体部分。
* 如果服务器响应允许继续发送请求主体,则客户端会继续发送请求;如果服务器响应拒绝继续发送请求主体,则客户端会放弃该请求。
* */
private Boolean expectContinueEnabled=false;
/**
* 设置是否标准化 URI。如果设置为true,则客户端会尝试标准化请求 URI,以便消除多余和重复的斜杠等。
* */
private Boolean normalizeUri=false;
/**
* 用于设置 HTTP 请求的路径前缀。
* 这个配置选项通常用于设置反向代理或者负载均衡器等中间件与 Elasticsearch 集群之间的连接
* */
private String pathPrefix;
public String getHosts() {
return hosts;
}
public void setHosts(String hosts) {
this.hosts = hosts;
}
public Integer getPort() {
return port;
}
public void setPort(Integer port) {
this.port = port;
}
public String getScheme() {
return scheme;
}
public void setScheme(String scheme) {
this.scheme = scheme;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getIndexPrefix() {
return indexPrefix;
}
public void setIndexPrefix(String indexPrefix) {
this.indexPrefix = indexPrefix;
}
public Integer getBulkFlushMaxActions() {
return bulkFlushMaxActions;
}
public void setBulkFlushMaxActions(Integer bulkFlushMaxActions) {
this.bulkFlushMaxActions = bulkFlushMaxActions;
}
public Integer getBulkFlushMaxSizeMb() {
return bulkFlushMaxSizeMb;
}
public void setBulkFlushMaxSizeMb(Integer bulkFlushMaxSizeMb) {
this.bulkFlushMaxSizeMb = bulkFlushMaxSizeMb;
}
public Integer getBulkFlushInterval() {
return bulkFlushInterval;
}
public void setBulkFlushInterval(Integer bulkFlushInterval) {
this.bulkFlushInterval = bulkFlushInterval;
}
public Boolean getBulkFlushBackoff() {
return bulkFlushBackoff;
}
public void setBulkFlushBackoff(Boolean bulkFlushBackoff) {
this.bulkFlushBackoff = bulkFlushBackoff;
}
public Integer getBulkFlushBackoffDelay() {
return bulkFlushBackoffDelay;
}
public void setBulkFlushBackoffDelay(Integer bulkFlushBackoffDelay) {
this.bulkFlushBackoffDelay = bulkFlushBackoffDelay;
}
public Integer getBulkFlushBackoffRetries() {
return bulkFlushBackoffRetries;
}
public void setBulkFlushBackoffRetries(Integer bulkFlushBackoffRetries) {
this.bulkFlushBackoffRetries = bulkFlushBackoffRetries;
}
public Integer getConnectTimeout() {
return connectTimeout;
}
public void setConnectTimeout(Integer connectTimeout) {
this.connectTimeout = connectTimeout;
}
public Integer getSocketTimeout() {
return socketTimeout;
}
public void setSocketTimeout(Integer socketTimeout) {
this.socketTimeout = socketTimeout;
}
public Integer getConnectionRequestTimeout() {
return connectionRequestTimeout;
}
public void setConnectionRequestTimeout(Integer connectionRequestTimeout) {
this.connectionRequestTimeout = connectionRequestTimeout;
}
public Boolean getRedirectsEnabled() {
return redirectsEnabled;
}
public void setRedirectsEnabled(Boolean redirectsEnabled) {
this.redirectsEnabled = redirectsEnabled;
}
public Integer getMaxRedirects() {
return maxRedirects;
}
public void setMaxRedirects(Integer maxRedirects) {
this.maxRedirects = maxRedirects;
}
public Boolean getAuthenticationEnabled() {
return authenticationEnabled;
}
public void setAuthenticationEnabled(Boolean authenticationEnabled) {
this.authenticationEnabled = authenticationEnabled;
}
public Boolean getCircularRedirectsAllowed() {
return circularRedirectsAllowed;
}
public void setCircularRedirectsAllowed(Boolean circularRedirectsAllowed) {
this.circularRedirectsAllowed = circularRedirectsAllowed;
}
public Boolean getContentCompressionEnabled() {
return contentCompressionEnabled;
}
public void setContentCompressionEnabled(Boolean contentCompressionEnabled) {
this.contentCompressionEnabled = contentCompressionEnabled;
}
public Boolean getExpectContinueEnabled() {
return expectContinueEnabled;
}
public void setExpectContinueEnabled(Boolean expectContinueEnabled) {
this.expectContinueEnabled = expectContinueEnabled;
}
public Boolean getNormalizeUri() {
return normalizeUri;
}
public void setNormalizeUri(Boolean normalizeUri) {
this.normalizeUri = normalizeUri;
}
public String getPathPrefix() {
return pathPrefix;
}
public void setPathPrefix(String pathPrefix) {
this.pathPrefix = pathPrefix;
}
}
7.3 客户端工厂类CustomRestClientFactory
作用:设置用于创建 Elasticsearch REST 客户端的工厂,可以自定义创建 Elasticsearch REST 客户端的逻辑,实现 ElasticsearchSinkBase.RestClientFactory 接口
package com.aurora.advanced;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.streaming.connectors.elasticsearch7.RestClientFactory;
import org.apache.http.Header;
import org.apache.http.message.BasicHeader;
import org.elasticsearch.client.NodeSelector;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
/**
* 描述:设置用于创建 Elasticsearch REST 客户端的工厂
* 解释:可以自定义创建 Elasticsearch REST 客户端的逻辑,实现 ElasticsearchSinkBase.RestClientFactory 接口
*
* @author 浅夏的猫
* @version 1.0.0
* @date 2024-02-13 00:12:15
*/
public class CustomRestClientFactory implements RestClientFactory {
private ElasticsearchEntity elasticsearchEntity;
public CustomRestClientFactory(ElasticsearchEntity elasticsearchEntity) {
this.elasticsearchEntity = elasticsearchEntity;
}
@Override
public void configureRestClientBuilder(RestClientBuilder restClientBuilder) {
//设置默认的 HTTP 头部信息,这些信息将在每个请求中包含
Header contentType = new BasicHeader("Content-Type", "application/json");
Header authorization = new BasicHeader("Authorization", "Bearer your_access_token");
Header[] headers = {contentType, authorization};
restClientBuilder.setDefaultHeaders(headers);
//设置用于监听节点故障的监听器。当节点发生故障时,可以执行特定的操作
restClientBuilder.setFailureListener(new RestClient.FailureListener());
//配置用于选择与之通信的节点的策略。这涉及到 Elasticsearch 集群中多个节点的选择。
restClientBuilder.setNodeSelector(NodeSelector.ANY);
//为每个请求设置路径前缀。这可以用于将请求定向到特定的子路径。
if(StringUtils.isNoneBlank(elasticsearchEntity.getPathPrefix())){
restClientBuilder.setPathPrefix(elasticsearchEntity.getPathPrefix());
}
//允许在创建每个请求的时候进行额外的请求配置。
restClientBuilder.setRequestConfigCallback(new CustomRequestConfigCallback(elasticsearchEntity));
//允许在创建 CloseableHttpClient 实例时进行额外的 HTTP 客户端配置。
restClientBuilder.setHttpClientConfigCallback(new CustomHttpClientConfigCallback(elasticsearchEntity));
//设置是否启用严格的废弃模式,用于警告有关已弃用功能的使用。
restClientBuilder.setStrictDeprecationMode(false);
}
}
7.4 回调函数类CustomRequestConfigCallback
作用:允许在创建每个请求的时候进行额外的请求配置
package com.aurora.advanced;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.cookie.DefaultCookieSpec;
import org.elasticsearch.client.RestClientBuilder;
/**
* 描述:
* 允许在创建每个请求的时候进行额外的请求配置
* @author 浅夏的猫
* @version 1.0.0
* @date 2024-02-13 23:24:42
*/
public class CustomRequestConfigCallback implements RestClientBuilder.RequestConfigCallback {
private ElasticsearchEntity elasticsearchEntity;
public CustomRequestConfigCallback(ElasticsearchEntity elasticsearchEntity) {
this.elasticsearchEntity = elasticsearchEntity;
}
@Override
public RequestConfig.Builder customizeRequestConfig(RequestConfig.Builder custom) {
// 设置与 Elasticsearch 集群建立连接的超时时间,单位为毫秒。在指定的时间内无法建立连接将会抛出连接超时异常
custom.setConnectTimeout(elasticsearchEntity.getConnectTimeout());
// 设置与 Elasticsearch 连接的套接字超时时间,单位为毫秒。该参数定义了在建立连接后从服务器读取数据的超时时间。如果在指定的时间内没有读取到数据,将会抛出超时异常。
custom.setSocketTimeout(elasticsearchEntity.getSocketTimeout());
// 设置连接请求超时时间,单位为毫秒。该参数表示从连接池获取连接的超时时间。如果在指定的时间内无法获得连接,将会抛出连接请求超时异常。
custom.setConnectionRequestTimeout(elasticsearchEntity.getConnectionRequestTimeout());
// 设置是否允许重定向。如果设置为true,则当遇到重定向响应时,客户端将跟随重定向并继续请求;如果设置为false,重定向响应将被视为错误。
custom.setRedirectsEnabled(elasticsearchEntity.getRedirectsEnabled());
// 设置最大重定向次数。当允许重定向时,该参数指定在遇到重定向响应时,最多可以重定向的次数。
custom.setMaxRedirects(elasticsearchEntity.getMaxRedirects());
// 设置是否允许循环重定向。如果设置为true,则允许在重定向过程中发生循环重定向;如果设置为false,则在检测到循环重定向时,将会抛出异常。
custom.setCircularRedirectsAllowed(elasticsearchEntity.getCircularRedirectsAllowed());
// 设置是否启用内容压缩。如果设置为true,则允许客户端和 Elasticsearch 之间进行内容压缩,以减少数据传输量。
custom.setContentCompressionEnabled(elasticsearchEntity.getContentCompressionEnabled());
// 设置是否启用 "Expect: continue" 机制。当设置为true时,在发送请求之前,客户端会发送一个请求头部,询问服务器是否接受请求的主体部分。
// 如果服务器响应允许继续发送请求主体,则客户端会继续发送请求;如果服务器响应拒绝继续发送请求主体,则客户端会放弃该请求。
custom.setExpectContinueEnabled(elasticsearchEntity.getExpectContinueEnabled());
// 设置是否标准化 URI。如果设置为true,则客户端会尝试标准化请求 URI,以便消除多余和重复的斜杠等。
custom.setNormalizeUri(elasticsearchEntity.getNormalizeUri());
// 设置使用的 Cookie 规范。可以指定客户端在处理与 Elasticsearch 服务器之间的 Cookie 交互时使用的 Cookie 规范
custom.setCookieSpec(new DefaultCookieSpec().toString());
return custom;
}
}
7.5 客户端配置类CustomHttpClientConfigCallback
作用:允许在创建 CloseableHttpClient 实例时进行额外的 HTTP 客户端配置
package com.aurora.advanced;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.cookie.DefaultCookieSpec;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.elasticsearch.client.RestClientBuilder;
/**
* 描述:客户端配置
* 允许在创建 CloseableHttpClient 实例时进行额外的 HTTP 客户端配置
*
* @author 浅夏的猫
* @version 1.0.0
* @date 2024-02-13 23:28:15
*/
public class CustomHttpClientConfigCallback implements RestClientBuilder.HttpClientConfigCallback {
private ElasticsearchEntity elasticsearchEntity;
CustomHttpClientConfigCallback(ElasticsearchEntity elasticsearchEntity) {
this.elasticsearchEntity = elasticsearchEntity;
}
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpAsyncClientBuilder) {
RequestConfig.Builder custom = RequestConfig.custom();
// 设置与 Elasticsearch 集群建立连接的超时时间,单位为毫秒。在指定的时间内无法建立连接将会抛出连接超时异常
custom.setConnectTimeout(elasticsearchEntity.getConnectTimeout());
// 设置与 Elasticsearch 连接的套接字超时时间,单位为毫秒。该参数定义了在建立连接后从服务器读取数据的超时时间。如果在指定的时间内没有读取到数据,将会抛出超时异常。
custom.setSocketTimeout(elasticsearchEntity.getSocketTimeout());
// 设置连接请求超时时间,单位为毫秒。该参数表示从连接池获取连接的超时时间。如果在指定的时间内无法获得连接,将会抛出连接请求超时异常。
custom.setConnectionRequestTimeout(elasticsearchEntity.getConnectionRequestTimeout());
// 设置是否允许重定向。如果设置为true,则当遇到重定向响应时,客户端将跟随重定向并继续请求;如果设置为false,重定向响应将被视为错误。
custom.setRedirectsEnabled(elasticsearchEntity.getRedirectsEnabled());
// 设置最大重定向次数。当允许重定向时,该参数指定在遇到重定向响应时,最多可以重定向的次数。
custom.setMaxRedirects(elasticsearchEntity.getMaxRedirects());
// 启用身份验证功能。通过设置该参数为true,可以提供用户名和密码进行身份验证,以连接到 Elasticsearch 集群。
custom.setAuthenticationEnabled(elasticsearchEntity.getAuthenticationEnabled());
// 设置是否允许循环重定向。如果设置为true,则允许在重定向过程中发生循环重定向;如果设置为false,则在检测到循环重定向时,将会抛出异常。
custom.setCircularRedirectsAllowed(elasticsearchEntity.getCircularRedirectsAllowed());
// 设置是否启用内容压缩。如果设置为true,则允许客户端和 Elasticsearch 之间进行内容压缩,以减少数据传输量。
custom.setContentCompressionEnabled(elasticsearchEntity.getContentCompressionEnabled());
// 设置是否启用 "Expect: continue" 机制。当设置为true时,在发送请求之前,客户端会发送一个请求头部,询问服务器是否接受请求的主体部分。
// 如果服务器响应允许继续发送请求主体,则客户端会继续发送请求;如果服务器响应拒绝继续发送请求主体,则客户端会放弃该请求。
custom.setExpectContinueEnabled(elasticsearchEntity.getExpectContinueEnabled());
// 设置是否标准化 URI。如果设置为true,则客户端会尝试标准化请求 URI,以便消除多余和重复的斜杠等。
custom.setNormalizeUri(elasticsearchEntity.getNormalizeUri());
// 设置使用的 Cookie 规范。可以指定客户端在处理与 Elasticsearch 服务器之间的 Cookie 交互时使用的 Cookie 规范
custom.setCookieSpec(new DefaultCookieSpec().toString());
return httpAsyncClientBuilder.setDefaultRequestConfig(custom.build());
}
}
7.6 Es操作类CustomElasticsearchSinkFunction
作用:实时把数据写入到队列中,再通过批量提交到Elasticsearch中,实现数据写入
package com.aurora.advanced;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import org.elasticsearch.common.xcontent.XContentType;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 描述:自定义elasticsearch sink 算子函数
* ElasticsearchSinkFunction 是用于将数据流写入 Elasticsearch 的接口。
* 它允许您自定义如何将 Flink 流式处理的数据写入 Elasticsearch 索引
*
* @author 浅夏的猫
* @version 1.0.0
* @date 2024-02-12 23:49:22
*/
public class CustomElasticsearchSinkFunction implements ElasticsearchSinkFunction<JSONObject> {
private static final Logger logger = LoggerFactory.getLogger(CustomElasticsearchSinkFunction.class);
private ElasticsearchEntity elasticsearchEntity;
public CustomElasticsearchSinkFunction(ElasticsearchEntity elasticsearchEntity) {
this.elasticsearchEntity = elasticsearchEntity;
}
@Override
public void process(JSONObject element, RuntimeContext runtimeContext, RequestIndexer indexer) {
String transId = element.getString("transId");
String tradeTime = element.getString("tradeTime");
String index = elasticsearchEntity.getIndexPrefix() + tradeTime;
logger.info("交易流水={},数据写入索引{}成功", tradeTime, index);
IndexRequest indexRequest = Requests.indexRequest().index(index).type(elasticsearchEntity.getType()).id(transId).source(element, XContentType.JSON);
indexer.add(indexRequest);
}
}
7.7 异常处理类CustomActionRequestFailureHandler
作用:当sink写Elasticsearch出现异常时,可以自定义操作策略
package com.aurora.advanced;
import org.apache.flink.streaming.connectors.elasticsearch.ActionRequestFailureHandler;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.elasticsearch.action.ActionRequest;
import org.elasticsearch.common.util.concurrent.EsRejectedExecutionException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 描述:es写入异常处理
*
* @author 浅夏的猫
* @version 1.0.0
* @date 2024-02-13 00:04:24
*/
public class CustomActionRequestFailureHandler implements ActionRequestFailureHandler {
private static final Logger logger = LoggerFactory.getLogger(CustomActionRequestFailureHandler.class);
@Override
public void onFailure(ActionRequest action, Throwable throwable, int restStatusCode, RequestIndexer requestIndexer) throws Throwable {
// 处理不同类型的异常
if (throwable instanceof EsRejectedExecutionException) {
// 如果是由于线程池饱和导致的拒绝执行异常,可以采取相应的处理措施
logger.warn("Elasticsearch action execution was rejected due to thread pool saturation.");
// 这里你可以选择执行重试或者其他处理逻辑,例如将数据写入到一个备用存储
// 例如: indexer.add(createAnotherRequest(action));
} else {
// 对于其他类型的异常,默认返回放弃策略
logger.error("Unhandled failure, abandoning request: {}", action.toString());
}
}
}
7.8 作业主类ElasticsearchSinkStreamJobAdvancedDemo
package com.aurora.advanced;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import org.apache.http.HttpHost;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.UUID;
/**
* 描述:Flink集成Elasticsearch Connector连接器进阶Demo
* 实现实时数据流如何无缝地流向Elasticsearch
*
* @author 浅夏的猫
* @version 1.0.0
* @date 2024-02-11 22:06:45
*/
public class ElasticsearchSinkStreamJobAdvancedDemo {
private static final Logger logger = LoggerFactory.getLogger(ElasticsearchSinkStreamJobAdvancedDemo.class);
public static void main(String[] args) {
try {
// 读取配置参数
ElasticsearchEntity elasticsearchEntity = paramsInit();
// 设置elasticsearch节点
List<HttpHost> httpHosts = esClusterHttpHostHandler(elasticsearchEntity);
// 创建esSinkFunction函数
ElasticsearchSinkFunction<JSONObject> esSinkFunction = new CustomElasticsearchSinkFunction(elasticsearchEntity);
// 构建ElasticsearchSink算子builder
ElasticsearchSink.Builder<JSONObject> esSinkBuilder = new ElasticsearchSink.Builder<>(httpHosts, esSinkFunction);
// es参数配置
esBuilderHandler(esSinkBuilder, elasticsearchEntity);
// 构建sink算子
ElasticsearchSink<JSONObject> esSink = esSinkBuilder.build();
// 自定义数据源,模拟生产环境交易接入,json格式数据
SourceFunction<JSONObject> dataSource = new SourceFunction<JSONObject>() {
@Override
public void run(SourceContext sourceContext) throws Exception {
while (true) {
//交易流水号
String tradeId = UUID.randomUUID().toString();
//交易发生时间戳
long timeStamp = System.currentTimeMillis();
//交易发生金额
long tradeAmount = new Random().nextInt(100);
//交易名称
String tradeName = "支付宝转账";
JSONObject dataObj = new JSONObject();
dataObj.put("transId", tradeId);
dataObj.put("timeStamp", timeStamp);
dataObj.put("tradeTime", dateUtil(timeStamp));
dataObj.put("tradeAmount", tradeAmount);
dataObj.put("tradeName", tradeName);
//模拟生产,每隔1秒生成一笔交易
Thread.sleep(1000);
logger.info("交易接入,原始报文={}", dataObj.toJSONString());
sourceContext.collect(dataObj);
}
}
@Override
public void cancel() {
}
};
// 创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 构建数据源
DataStreamSource<JSONObject> dataStreamSource = env.addSource(dataSource);
// 构建sink算子
dataStreamSource.addSink(esSink);
// 运行作业
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 描述:Flink参数配置读取
*
* @return {@code ElasticsearchEntity }
* @throws IOException
*/
private static ElasticsearchEntity paramsInit() throws IOException {
// 通过flink内置工具类获取命令行参数
String propertiesFilePath = "E:\\project\\aurora_dev\\aurora_flink_connector_elasticsearch\\src\\main\\resources\\application.properties";
ParameterTool paramsMap = ParameterTool.fromPropertiesFile(propertiesFilePath);
ElasticsearchEntity elasticsearchEntity = new ElasticsearchEntity();
String hosts = paramsMap.get("es.cluster.hosts");
int port = paramsMap.getInt("es.cluster.port");
String scheme = paramsMap.get("es.cluster.scheme");
String type = paramsMap.get("es.cluster.type");
String indexPrefix = paramsMap.get("es.cluster.indexPrefix");
int bulkFlushMaxActions = paramsMap.getInt("es.cluster.bulkFlushMaxActions");
int bulkFlushMaxSizeMb = paramsMap.getInt("es.cluster.bulkFlushMaxSizeMb");
int bulkFlushInterval = paramsMap.getInt("es.cluster.bulkFlushInterval");
boolean bulkFlushBackoff = paramsMap.getBoolean("es.cluster.bulkFlushBackoff");
int bulkFlushBackoffDelay = paramsMap.getInt("es.cluster.bulkFlushBackoffDelay");
int bulkFlushBackoffRetries = paramsMap.getInt("es.cluster.bulkFlushBackoffRetries");
int connectTimeout = paramsMap.getInt("es.cluster.connectTimeout");
int socketTimeout = paramsMap.getInt("es.cluster.socketTimeout");
int connectionRequestTimeout = paramsMap.getInt("es.cluster.connectionRequestTimeout");
boolean redirectsEnabled = paramsMap.getBoolean("es.cluster.redirectsEnabled");
int maxRedirects = paramsMap.getInt("es.cluster.maxRedirects");
boolean authenticationEnabled = paramsMap.getBoolean("es.cluster.authenticationEnabled");
boolean circularRedirectsAllowed = paramsMap.getBoolean("es.cluster.circularRedirectsAllowed");
boolean contentCompressionEnabled = paramsMap.getBoolean("es.cluster.contentCompressionEnabled");
boolean expectContinueEnabled = paramsMap.getBoolean("es.cluster.expectContinueEnabled");
boolean normalizeUri = paramsMap.getBoolean("es.cluster.normalizeUri");
elasticsearchEntity.setHosts(hosts);
elasticsearchEntity.setPort(port);
elasticsearchEntity.setScheme(scheme);
elasticsearchEntity.setType(type);
elasticsearchEntity.setIndexPrefix(indexPrefix);
elasticsearchEntity.setBulkFlushMaxActions(bulkFlushMaxActions);
elasticsearchEntity.setBulkFlushMaxSizeMb(bulkFlushMaxSizeMb);
elasticsearchEntity.setBulkFlushInterval(bulkFlushInterval);
elasticsearchEntity.setBulkFlushBackoff(bulkFlushBackoff);
elasticsearchEntity.setBulkFlushBackoffDelay(bulkFlushBackoffDelay);
elasticsearchEntity.setBulkFlushBackoffRetries(bulkFlushBackoffRetries);
elasticsearchEntity.setConnectTimeout(connectTimeout);
elasticsearchEntity.setSocketTimeout(socketTimeout);
elasticsearchEntity.setConnectionRequestTimeout(connectionRequestTimeout);
elasticsearchEntity.setRedirectsEnabled(redirectsEnabled);
elasticsearchEntity.setMaxRedirects(maxRedirects);
elasticsearchEntity.setAuthenticationEnabled(authenticationEnabled);
elasticsearchEntity.setCircularRedirectsAllowed(circularRedirectsAllowed);
elasticsearchEntity.setExpectContinueEnabled(expectContinueEnabled);
elasticsearchEntity.setContentCompressionEnabled(contentCompressionEnabled);
elasticsearchEntity.setNormalizeUri(normalizeUri);
return elasticsearchEntity;
}
/**
* 描述:时间格式化工具类
*
* @param timestamp 时间戳
* @return {@code String }
*/
private static String dateUtil(long timestamp) {
timestamp = timestamp / 1000;
// 将时间戳转换为 LocalDateTime 对象
LocalDateTime dateTime = LocalDateTime.ofInstant(Instant.ofEpochSecond(timestamp), ZoneId.systemDefault());
// 定义日期时间格式
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyyMMdd");
// 格式化日期时间对象为指定格式的字符串
String dateTimeFormat = formatter.format(dateTime);
return dateTimeFormat;
}
/**
* 描述:es参数配置
*
* @param esSinkBuilder esSinkBuilder建造器
* @param elasticsearchEntity es实体类
*/
private static void esBuilderHandler(ElasticsearchSink.Builder<JSONObject> esSinkBuilder, ElasticsearchEntity elasticsearchEntity) {
// 设置触发批量写入的最大动作数,
// 解释:当达到指定的最大动作数时,将触发批量写入到 Elasticsearch。如果你希望在每次写入到 Elasticsearch 时都进行批量写入,可以将该值设置为 1
esSinkBuilder.setBulkFlushMaxActions(elasticsearchEntity.getBulkFlushMaxActions());
// 设置触发批量写入的最大数据量
// 解释:当写入的数据量达到指定的最大值时,将触发批量写入到 Elasticsearch。单位为 MB
esSinkBuilder.setBulkFlushMaxSizeMb(elasticsearchEntity.getBulkFlushMaxSizeMb());
// 设置批量写入的时间间隔
// 解释:每隔指定的时间间隔,无论是否达到最大动作数或最大数据量,都会触发批量写入
esSinkBuilder.setBulkFlushInterval(elasticsearchEntity.getBulkFlushInterval());
// 启用批量写入的退避策略
// 解释:当 Elasticsearch 写入失败时,可以启用退避策略,以避免频繁的重试。此时,setBulkFlushBackoffDelay 和 setBulkFlushBackoffRetries 参数生效。
esSinkBuilder.setBulkFlushBackoff(elasticsearchEntity.getBulkFlushBackoff());
// 设置批量写入的退避延迟时间
// 解释:在发生写入失败后,等待指定的延迟时间后再进行重试
esSinkBuilder.setBulkFlushBackoffDelay(elasticsearchEntity.getBulkFlushBackoffDelay());
// 设置批量写入的最大重试次数
// 解释:设置在写入失败后的最大重试次数。超过这个次数后,将不再重试
esSinkBuilder.setBulkFlushBackoffRetries(elasticsearchEntity.getBulkFlushBackoffRetries());
// 设置写入失败时的处理策略
// 解释:可以自定义处理失败的策略,实现 ElasticsearchSinkFunction.FailureHandler 接口
esSinkBuilder.setFailureHandler(new CustomActionRequestFailureHandler());
// 设置用于创建 Elasticsearch REST 客户端的工厂
// 解释:可以自定义创建 Elasticsearch REST 客户端的逻辑,实现 ElasticsearchSinkBase.RestClientFactory 接口
esSinkBuilder.setRestClientFactory(new CustomRestClientFactory(elasticsearchEntity));
}
/**
* 描述:
* elasticsearch 节点配置
*
* @param elasticsearchEntity es实体类
* @return {@code List<HttpHost> }
*/
private static List<HttpHost> esClusterHttpHostHandler(ElasticsearchEntity elasticsearchEntity) {
List<HttpHost> httpHosts = new ArrayList<>();
String[] clusterArray = elasticsearchEntity.getHosts().split(",");
for (String node : clusterArray) {
httpHosts.add(new HttpHost(node, elasticsearchEntity.getPort(), elasticsearchEntity.getScheme()));
}
return httpHosts;
}
}