文章目录
- IO_URING
- 基本介绍
- 常见 I/O 模型
- IO_URING
- 原理
- 核心结构
- 工作模式
- 高级特性
- 用法
- API
- liburing
- 基本流程
- Demo
- 业界示例
- SeaStar / ScyllaDB
- CEPH
- RocksDB
- ClickHouse
IO_URING
基本介绍
常见 I/O 模型
当前 Linux 的几种 I/O 模型:

- 同步 I/O 是目前应用最广的 I/O 模型,其缺点非常明显:大量内存拷贝、系统调用导致上下文切换频繁;随着设备性能越来越高,这种方式已经无法有效利用设备的全部性能。
- AIO 的优点就是通过异步方式和 Linux Kernel 交互,减少了对用户态应用程序的阻塞,提高了并发度,但其最大的缺点就是仅支持 Direct I/O,无法有效利用文件系统和 Page Cache。
- SPDK 通过 Kernal Bypass 的方式实现,其基于 VFIO 在用户态重新实现 NVMe 驱动和协议,无系统调用、无上下文切换、无锁,是目前性能最高的 I/O 模型。但是它仅限于 NVMe,不支持其他磁盘类型,且使用起来非常困难。
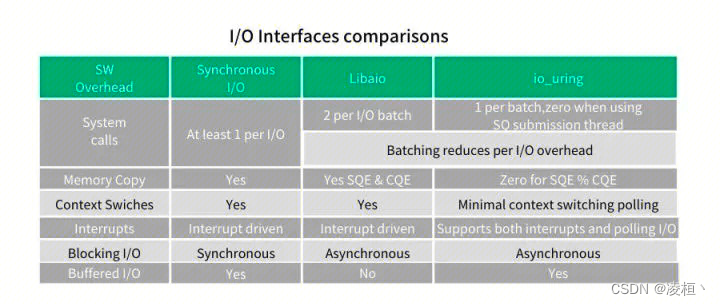
各 I/O 模型的对比
为了弥补上述方案的缺陷,Linux Kernel 5.1 版本加入一个特性——IO_URING
IO_URING
IO_URING 的设计目标是提供一个统一、易用、可扩展、功能丰富、高效的网络和磁盘系统接口。其具有以下几个特点:
- 真正异步:只要设置了合适的 flag,它在系统调用上下文中就只是将请求放入队列, 不会做其他任何额外的事情,保证了应用永远不会阻塞。
- 支持任何类型的 I/O:cached files、direct-access files 甚至 blocking sockets。无需 poll+read/write 来处理 sockets。 只需提交一个阻塞式读(blocking read),请求完成之后,就会出现在 completion ring。
- 可拓展、灵活:基于 IO_URING 甚至能重写 Linux 的每个系统调用。
- 高性能:
- 用户态和内核态共享提交队列(submission queue)和完成队列(completion queue)。
- 用户态支持 Polling 模式,不依赖硬件的中断,通过调用
IORING_ENTER_GETEVENTS不断轮询收割完成事件。 - 内核态支持 Polling 模式,IO 提交和收割可以 offload 给 Kernel,且提交和完成不需要经过系统调用。
- 可以提前注册用户态内存地址/文件描述符,减小地址映射/引用计数的开销。
- ……
原理
核心结构
如下图,每个 IO_URING 实例都有两个环形队列(RingBuffer,通过共享内存实现),由用户态和内核态共同管理。
- 提交队列 submission queue (SQ):用户态线程生产,通过系统调用通知内核消费。
- 完成队列 completion queue (CQ):内核生产,通知用户态消费。
两个队列都提供了无锁接口(内部通过 barriers 同步),都是单生产者,单消费者。
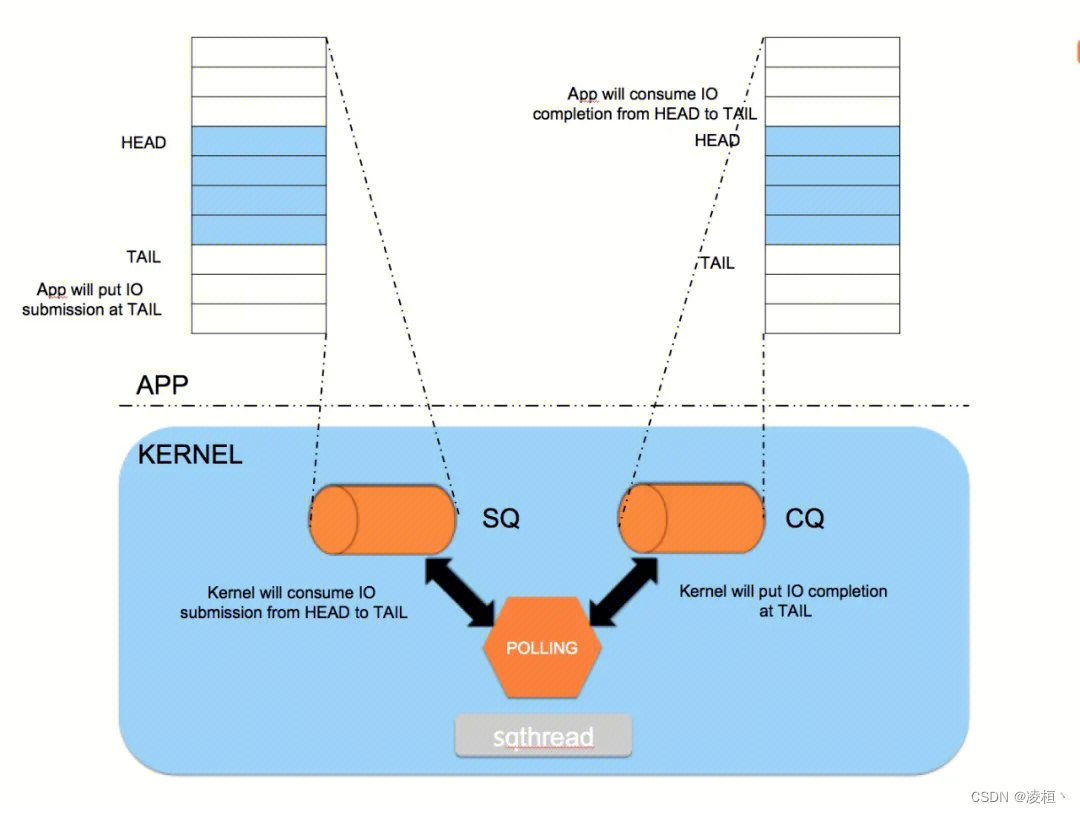
工作方式
- 提交:
- 应用尝试获取一个 SQ Entry,并向 SQ Entry 中填充数据。
- 提交 SQ Entry 到 SQ 中,更新 SQ tail。
- 完成:
- 内核从 SQ head 处取出 SQ Entry 消费,并更新 SQ head。
- 内核为完成的一个或多个请求创建 CQ Entry,更新 CQ tail。
- 应用消费 CQ Entry,更新 CQ head。(无需切换到内核态)
这里的提交和完成都支持批量处理,如连续提交多个 Entry 到 SQ,或持续消费 CQ。
工作模式
- 中断驱动模式(interrupt driven):默认,通过
io_uring_enter通知内核 IO 请求的产生以及阻塞等待内核完成请求。 - 轮询模式(polled):为了提升性能,内核提供了轮询的方式来提交 IO 请求
- 提交 IO 的轮询(SQPOLL):
- 当通过
IORING_SETUP_SQPOLL开启提交队列轮询时,会启动一个内核线程不停的去检查 SQ 是否存在任务,并立即取出任务进行消费。而用户态程序只需要将任务塞进 SQ 提交队列即可,不再需要调用io_uring_enter。当一段时间(sq_thread_idle配置)内没有 Poll 到任何请求时,为了避免线程空转,会将其挂起并通过IORING_SQ_NEED_WAKEUP标志位更新状态到共享内存中。用户进程可以在每次提交任务时,通过该标志位检查内核 SQ 线程是否运行,如果未运行,则需要通过调用io_uring_enter,并使用IORING_SQ_NEED_WAKEUP参数,来唤醒 SQ 线程。 - 由于内核和用户态共享内存,所以完成的时候,用户态遍历直接遍历完成队列消费 CQ Entry 即可。在最理想的情况下,IO 提交和收割都不需要使用系统调用。
- 当通过
- 完成 IO 的轮询(IOPOLL):
- 在传统的模式下,将 I/O 请求提交给块设备后,进程会进入睡眠状态,当块设备处理完 I/O 请求后则会通过一个中断来唤醒进程,通知 I/O 已完成。IO_URING 中可通过
IORING_SETUP_IOPOLL开启块设备轮询操作,即提交 I/O 后不直接进入睡眠,而是启动一个内核线程来循环检查 I/O 是否完成。由于不需要被动等待设备通知,因此可以更快获取 I/O 请求的完成状态,这对于延迟非常低以及 IOPS 很高的设备,能够显著提高性能,同时也避免了高频的中断所带来的性能开销,但同时也提高了 CPU 的开销。 - 仅支持 Direct I/O;仅支持存储设备,且设备/文件系统必须要支持轮询。
- 在传统的模式下,将 I/O 请求提交给块设备后,进程会进入睡眠状态,当块设备处理完 I/O 请求后则会通过一个中断来唤醒进程,通知 I/O 已完成。IO_URING 中可通过
- 提交 IO 的轮询(SQPOLL):
- 内核轮询模式(kernel polled):即同时开启
IORING_SETUP_SQPOLL、IORING_SETUP_IOPOLL,内核会同时轮询 SQ 队列和设备驱动队列,无需主动调用io_uring_enter来触发。在这种模式下应用无需切换到内核态,无需任何系统调用也能够进行提交和完成,只需要在用户态轮询 CQ 即可。
高级特性
- 资源预注册
- 预注册缓冲区:对于频繁操作的 buffer,可以通过
IORING_REGISTER_BUFFERS将 buffer 注册到内核中,避免每次 I/O 时都需要调用get_user_pages、unpin_user_pages进行虚拟地址到物理 Page 的映射。 - 预注册文件描述符:Linux 在执行 I/O 操作时为了避免文件描述符被释放或者关闭,在访问文件时通过
fget增加引用计数,在操作完成后通过fput减少,这也带来了大量的性能开销(https://lwn.net/Articles/787473/)。为了优化这一点,支持通过IORING_REGISTER_FILES提前将文件描述符注册到内核中,使文件描述符的引用计数始终为 1,避免掉这一部份开销。
- 预注册缓冲区:对于频繁操作的 buffer,可以通过
- 链接 I/O 操作:支持通过
IOSQE_IO_LINK将多个 I/O 操作链接在一起,这些操作会通过一次调用同时提交,并按照链接的顺序进行执行。 - 快速轮询:kernel5.7 后引入的新特性,通过
IORING_FEAT_FAST_POLL优化对大量非阻塞文件描述符的轮询操作(用于网络 I/O)。其原理就是维护了一个快速轮询队列(类似 epoll),对于未就绪的描述符不再直接转交给异步线程,而是放入该队列中,内核会定期检查描述符是否就绪,一旦就绪就立即开始进行 I/O 操作。避免了不必要的异步线程创建以及线程阻塞,同时也省去了使用 epoll 的开销。- 当开启
IORING_SETUP_SQPOLL、IORING_SETUP_IOPOLL、IORING_FEAT_FAST_POLL时,在最理想情况下轮询+读/写都能在用户态完成。
- 当开启
用法
API
接口可参考文档:https://tchaloupka.github.io/during/during.io_uring.html
IO_URING 只提供了三个接口:
/*
作用:用于初始化 io_uring 以及 SQ、CQ
参数:
entries:队列深度
params:params
返回值:io_uring 的描述符,失败时返回 -1 并设置 errno
*/
int io_uring_setup(unsigned entries, struct io_uring_params *params);
/*
作用:用于初始化 io_uring 以及 SQ、CQ
参数:
fd:io_uring 描述符
to_submit:指定了 SQ 中提交的 I/O 数量
min_complete:会等待这个数量的 I/O 事件完成再返回;当使用IOPOLL模式时如果未0,则立即返回当前结果。而非0时如果有完成事件,则立即返回;如果没有则poll指定次数或等到线程时间片结束后返回。
flags:标识符
sig:指向信号掩码的指针。调用io_uring_enter时会将当前信号掩码替换为sig,然后等待完成队列中的事件就绪后,再恢复为原始信号掩码
返回值:io_uring 的描述符,失败时返回 -1 并设置 errno
*/
int io_uring_enter(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t *sig);
/*
作用:注册用于异步 I/O 的文件或用户缓冲区
参数:
fd:io_uring 描述符
opcode:操作码
arg:操作指定的参数
nr_args:参数数量
返回值:成功时返回 0,失败时返回 -1 并设置 errno
*/
int io_uring_register(unsigned int fd, unsigned int opcode, void *arg, unsigned int nr_args);
liburing
为了简化 IO_URING 的使用,避免一些繁琐的底层操作(如 ring buffer 管理、memory barrier、mmap 等),Jens Axboe 还封装了一套易用的高级 API —— liburing。
代码仓库:GitHub - axboe/liburing
API 手册:Manpages of liburing-dev in Debian unstable — Debian Manpages
基本流程
- 使用
io_uring_queue_init初始化 io_uring- 如果需要指定特殊参数可以使用
io_uring_queue_init_params
- 如果需要指定特殊参数可以使用
- 注册文件描述符(可选)
io_uring_register_files注册待操作文件描述符,之后操作这些文件时通过索引而不是描述符,减少系统调用,优化开销。io_uring_register_eventfd注册 eventfd,当 I/O 完成后,内核会往这个 fd 中写入一个值,通知异步 I/O 操作已完成。
- 通过
io_uring_get_sqe获取 sqe - 通过
io_uring_prep_$option将 sqe 提交到提交队列中- 如果需要设置 user_data,可以通过
io_uring_sqe_set_data传入。在 I/O 操作完成后可以通过io_uring_cqe_get_data从 cqe 中读出。 - 如果有多个请求,可以使用
io_uring_sqe_set_flags设置IOSQE_IO_LINK,将请求链接到一起进行批处理。
- 如果需要设置 user_data,可以通过
- 通过
io_uring_submit通知 io_uring 从提交队列中消费 sqe - 等待完成队列中的任务就绪
- 阻塞:
io_uring_wait_cqe,阻塞等待有一个 cqe 返回 - 非阻塞:
io_uring_peek_cqe,如果没有就绪的 cqe,则直接报错返回。支持批量操作io_uring_peek_batch_cqe
- 阻塞:
- 当前 cqe 中的数据处理完成后,通过
io_uring_cqe_seen将其标记成已处理,从完成队列中移除。(如果不处理则会一直保留,被重复消费) - 完成所有 I/O 操作后,使用
io_uring_queue_exit销毁 io_uring
Demo
更多例子参考:
- liburgin:https://github.com/axboe/liburing/tree/master/examples
- echo_server:https://github.com/frevib/io_uring-echo-server/blob/master/io_uring_echo_server.c
#include <stdio.h>
#include <fcntl.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include "liburing.h"
#define QD 4
int main(int argc, char *argv[])
{
struct io_uring ring;
int i, fd, ret, pending, done;
struct io_uring_sqe *sqe;
struct io_uring_cqe *cqe;
struct iovec *iovecs;
struct stat sb;
ssize_t fsize;
off_t offset;
void *buf;
if (argc < 2) {
printf("%s: file\n", argv[0]);
return 1;
}
ret = io_uring_queue_init(QD, &ring, 0);
if (ret < 0) {
fprintf(stderr, "queue_init: %s\n", strerror(-ret));
return 1;
}
fd = open(argv[1], O_RDONLY | O_DIRECT);
if (fd < 0) {
perror("open");
return 1;
}
if (fstat(fd, &sb) < 0) {
perror("fstat");
return 1;
}
fsize = 0;
iovecs = calloc(QD, sizeof(struct iovec));
for (i = 0; i < QD; i++) {
if (posix_memalign(&buf, 4096, 4096))
return 1;
iovecs[i].iov_base = buf;
iovecs[i].iov_len = 4096;
fsize += 4096;
}
offset = 0;
i = 0;
do {
sqe = io_uring_get_sqe(&ring);
if (!sqe)
break;
io_uring_prep_readv(sqe, fd, &iovecs[i], 1, offset);
offset += iovecs[i].iov_len;
i++;
if (offset >= sb.st_size)
break;
} while (1);
ret = io_uring_submit(&ring);
if (ret < 0) {
fprintf(stderr, "io_uring_submit: %s\n", strerror(-ret));
return 1;
} else if (ret != i) {
fprintf(stderr, "io_uring_submit submitted less %d\n", ret);
return 1;
}
done = 0;
pending = ret;
fsize = 0;
for (i = 0; i < pending; i++) {
ret = io_uring_wait_cqe(&ring, &cqe);
if (ret < 0) {
fprintf(stderr, "io_uring_wait_cqe: %s\n", strerror(-ret));
return 1;
}
done++;
ret = 0;
if (cqe->res != 4096 && cqe->res + fsize != sb.st_size) {
fprintf(stderr, "ret=%d, wanted 4096\n", cqe->res);
ret = 1;
}
fsize += cqe->res;
io_uring_cqe_seen(&ring, cqe);
if (ret)
break;
}
printf("Submitted=%d, completed=%d, bytes=%lu\n", pending, done,
(unsigned long) fsize);
close(fd);
io_uring_queue_exit(&ring);
return 0;
}
业界示例
SeaStar / ScyllaDB
在 SeaStar 中,reactor 是可插拔的组件(epoll、aio、io_uring),其基于 IO_URING 封装了一个新的 reactor_backend_uring,接管了所有网络和磁盘 I/O(buffer/direct)与事件循环。
实现参考:https://github.com/scylladb/scylladb/commit/1247be44b01b3402e8694dd622f8ed8306053c32
-
网络 I/O:
-
测试环境:8-core x86
-
内核版本:linux v5.7
-
测试参数:
wrk -c 128 -t 4 -
测试数据:https://github.com/scylladb/seastar/pull/1235#discussion_r989364804
-
AIO:
Running 10s test @ http://localhost:10000/
4 threads and 128 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.49ms 109.56us 3.81ms 87.41%
Req/Sec 21.51k 783.10 28.03k 87.84%
862627 requests in 10.10s, 112.71MB read
Requests/sec: 85407.13
Transfer/sec: 11.16MB
IO_URING:
Running 10s test @ http://localhost:10000/
4 threads and 128 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.35ms 400.14us 37.64ms 98.36%
Req/Sec 23.94k 2.36k 26.30k 70.25%
952788 requests in 10.00s, 124.48MB read
Requests/sec: 95266.43
Transfer/sec: 12.45MB
-
磁盘 I/O:
- 测试数据:https://www.scylladb.com/2020/05/05/how-io_uring-and-ebpf-will-revolutionize-programming-in-linux/

ScyllaDB 性能对比
- 测试数据:https://www.scylladb.com/2020/05/05/how-io_uring-and-ebpf-will-revolutionize-programming-in-linux/
CEPH
CEPH 主要是对其底层的存储引擎 BlueStore 进行改造。其原本架构图如下图所示,CEPH 本身就已经在 BlueFS 与磁盘的交互之间抽象出了一个 BlockDevice 层,且原本就采用了 AIO,只需要简单的修改就 API 就可以切换到 liburing,并且其运用了大部分高级特性(SQPOLL、IOPOLL、REGISTER_FILES)。
实现参考:https://github.com/ceph/ceph/pull/27392/files
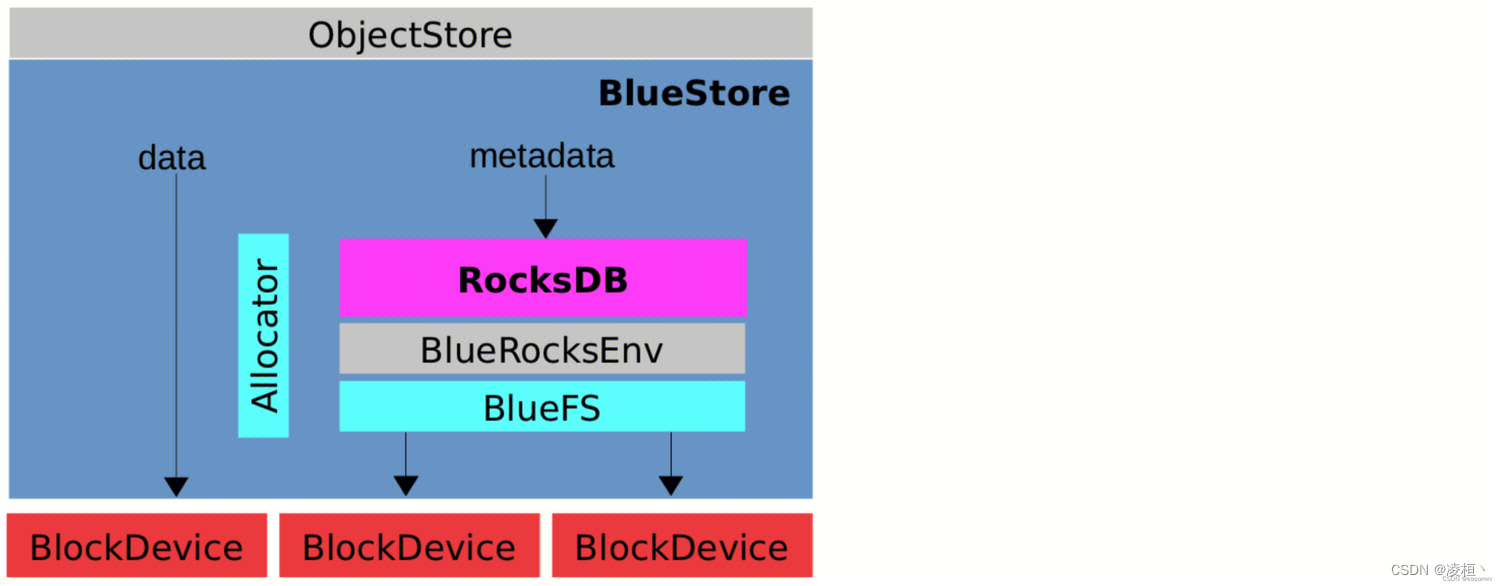
以下是官方给出的测试数据:
内核版本:
linux v5.1
测试参数:
rw=randwrite
iodepth=16
nr_files=1
numjobs=1
size=256m
bluestore_min_alloc_size = 4096
bluestore_max_blob_size = 65536
bluestore_block_path = /dev/ram0
bluestore_block_db_path = /dev/ram1
bluestore_block_wal_path = /dev/ram2
使用AIO:
bluestore_iouring=false
4k IOPS=25.5k, BW=99.8MiB/s, Lat=0.374ms
8k IOPS=21.5k, BW=168MiB/s, Lat=0.441ms
16k IOPS=17.2k, BW=268MiB/s, Lat=0.544ms
32k IOPS=12.3k, BW=383MiB/s, Lat=0.753ms
64k IOPS=8358, BW=522MiB/s, Lat=1.083ms
128k IOPS=4724, BW=591MiB/s, Lat=1.906ms
使用IO_URING:
bluestore_iouring=true
4k IOPS=29.2k, BW=114MiB/s, Lat=0.331ms
8k IOPS=30.7k, BW=240MiB/s, Lat=0.319ms
16k IOPS=27.4k, BW=428MiB/s, Lat=0.368ms
32k IOPS=22.7k, BW=709MiB/s, Lat=0.475ms
64k IOPS=15.6k, BW=978MiB/s, Lat=0.754ms
128k IOPS=9572, BW=1197MiB/s, Lat=1.223ms
IOPS 提升:
Overall IOPS increase is the following:
4k +14%
8k +42%
16k +59%
32k +89%
64k +85%
128k +102%
RocksDB
RocksDB 基于 IO_URING 实现了 PosixRandomAccessFile::MultiRead(),并且也只是使用了最基本的功能。RocksDB 是直接在该接口中构造了一个 uring,一次性将所有读取请求批量填充进去,并循环等待所有请求完成(未让出线程,本质上还是同步读取),如果出现任何异常,则退化至原先的方式(线程池 + pread)。
实现参考:https://github.com/facebook/rocksdb/pull/5881/files
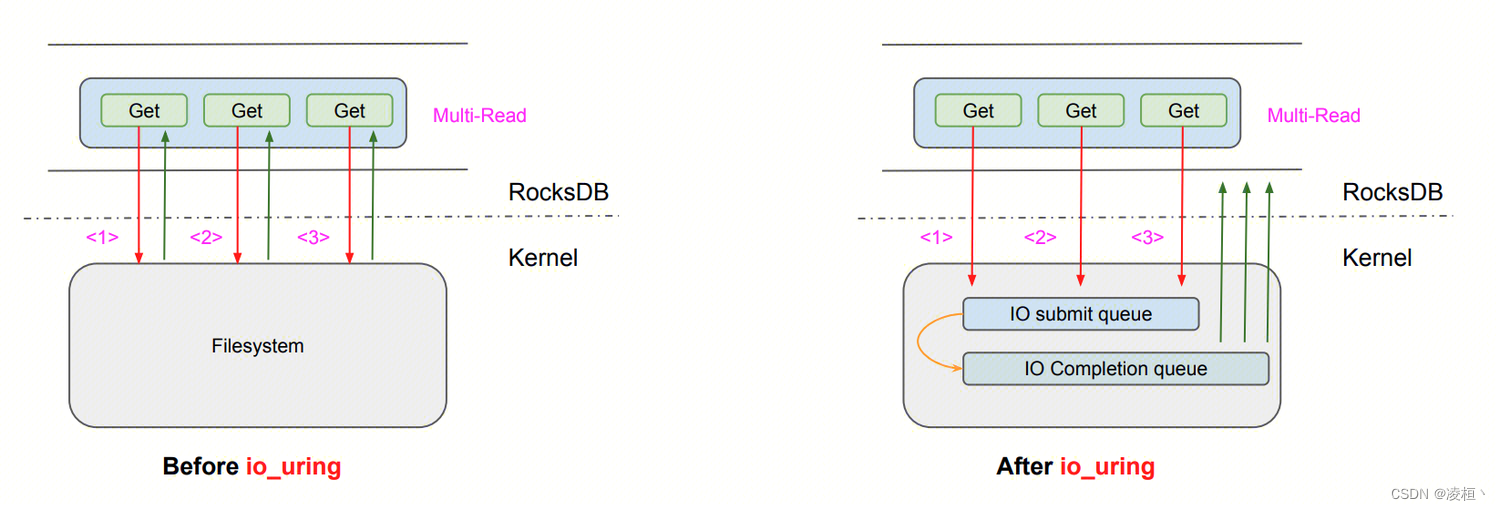
官方给的测试数据如下:
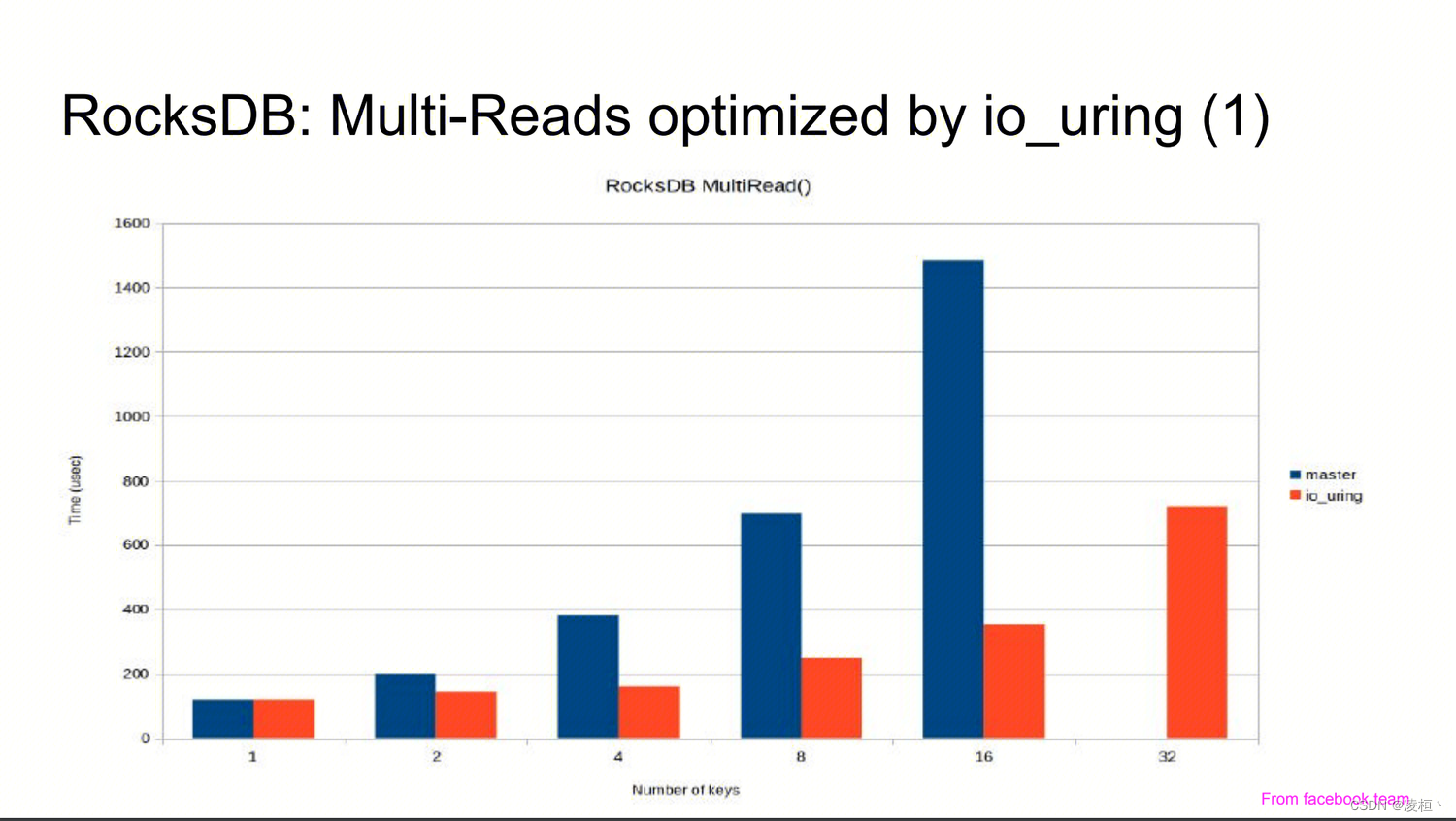
详细数据参考:https://www.slideshare.net/ennael/kernel-recipes-2019-faster-io-through-iouring
除了官方的实现,很多公司都有对 RocksDB 进行 IO_URING 改造,例如 TIKV 用 IO_URING 重构了 wal、sstable 的 write 和 compaction 。
https://openinx.github.io/ppt/io-uring.pdf
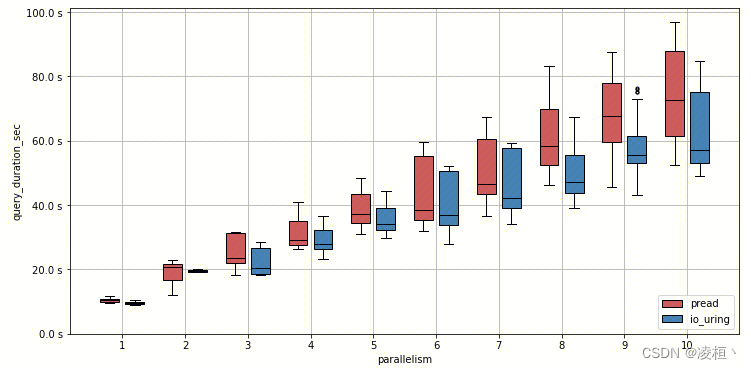
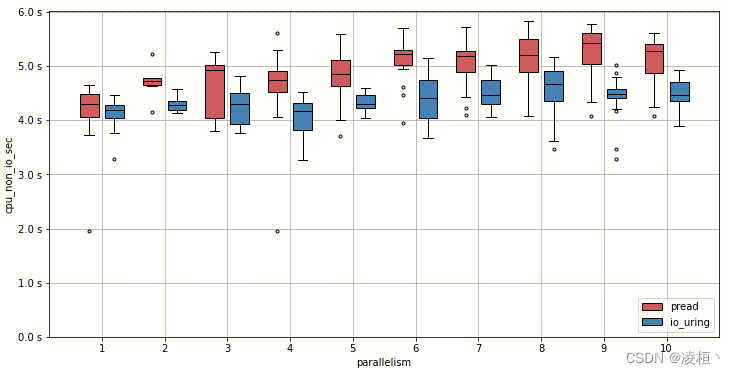
ClickHouse
ClickHouse 只是用了使用了最基础的 IO_URING(未用到高级特性,主要是由于 CK 中需要根据文件大小来动态决定是否使用 PageCache,因此无法兼容 IOPOLL),将文件系统的同步读取改造为异步(OLAP 数据库主要开销在读取上)。ClickHouse 本身就已经抽象出了 Reader 来接管 FS 层的读 I/O,因此他们只需要简单封装一个 IOUringReader 并返回一个异步的 Future 即可完成改造。
实现参考:https://github.com/ClickHouse/ClickHouse/pull/36103/files
官方给出了测试数据
- 测试环境:i7-7700K / 32GB desktop with a 7200rpm WD HDD dis、Linux V5.17
- 测试语句:
select count(ignore(*)) from visits - 测试参数:
min_bytes_to_use_direct_io和local_filesystem_read_prefetch - 测试结果:
+----------------------+---------------+---------------+-------------+-------------+-----------+
| direct_io / prefetch | pread | io_uring | improvement | significant | cpu_usage |
+----------------------+---------------+---------------+-------------+-------------+-----------+
| no / no | 10.75 ± 0.47s | 9.91 ± 0.49s | 7.75% | yes | -1.29% |
| no / yes | 8.86 ± 0.23s | 7.85 ± 0.31s | 11.48% | yes | -2.86% |
| yes / yes | 14.41 ± 0.57s | 11.49 ± 0.28s | 20.27% | yes | -1.74% |
| yes / no | 14.37 ± 0.50s | 14.34 ± 0.47s | 0.25% | no | -24.52% |
+----------------------+---------------+---------------+-------------+-------------+-----------+
在并发场景下,随着并发度的提升,IO_URING 的优势也越来越大。



![【web | CTF】BUUCTF [BJDCTF2020]Easy MD5](https://img-blog.csdnimg.cn/direct/9cd860aade0545c1aa8921eb443bc786.png)




![[word] 手把手教您在word中添加mathtype加载项 #笔记#职场发展](https://img-blog.csdnimg.cn/img_convert/66a609fe87de7e8a79dcee2f85542ff3.png)

