专栏导航
JVM工作原理与实战
RabbitMQ入门指南
从零开始了解大数据
目录
专栏导航
前言
一、JIT即时编译器
二、HotSpot中的JIT编译器
三、JIT优化技术
1.方法内联
2.逃逸分析
四、JIT优化建议
总结
前言
JVM作为Java程序的运行环境,其负责解释和执行字节码,管理内存,确保安全,支持多线程和提供性能监控工具,以及确保程序的跨平台运行。本文主要介绍了JIT即时编译器、HotSpot中的JIT编译器、JIT优化技术、JIT优化建议等内容。
一、JIT即时编译器
在Java编程环境中,即时编译器(JIT, Just-In-Time Compiler)是一项核心技术,旨在显著提高应用程序代码的执行效率。Java虚拟机(JVM)通常首先解释执行字节码指令,但随着时间的推移,它会识别出那些频繁执行的代码段,这些被称为“热点代码”。JIT编译器会针对这些热点代码进行优化编译,将它们从字节码形式转换为高效的本地机器码。这一转换过程还包括一系列优化步骤,以进一步提高代码的性能。一旦编译完成,这些优化后的机器码就会被保存在内存中,以便在未来执行时能够直接从内存中读取并运行在计算机的硬件上,从而避免了解释执行带来的额外开销。这种即时编译和优化的方式使得Java应用程序能够在运行时达到接近原生代码的性能水平。

二、HotSpot中的JIT编译器
在 HotSpot 虚拟机中,C1、C2 和 Graal 是三款不同的即时(Just-In-Time, JIT)编译器。它们的主要目标是提高代码的运行效率,但每个编译器在实现这一目标时采用了不同的策略和优化级别。
C1 编译器:
- 特点:C1 编译器的主要特点是编译速度快,但优化程度相对较低。
- 适用场景:因此,它更适合执行时间较短、对编译速度要求较高的代码段,例如启动时的类加载和初始化过程。
- 优化与取消优化:C1 的优化策略相对简单,它主要关注基本的性能提升,如方法内联、类型检查消除等。由于它更注重编译速度,所以在某些情况下,它可能会编译一些不那么优化的代码,以便尽快完成编译任务。取消优化的概念在这里并不明显,因为 C1 的主要目标是快速编译而不是深度优化。
C2 编译器:
- 特点:C2 编译器与 C1 相反,它更注重深度优化,以提高代码的长期运行性能。
- 适用场景:因此,它更适合处理服务端程序中那些长期运行且需要更高性能的代码。
- 优化与取消优化:C2 编译器采用了更为复杂的优化策略,包括高级方法内联、逃逸分析、循环展开、类型剖析等。这些优化可以显著提高代码的运行效率,尤其是在长期运行的程序中。然而,在某些情况下,过度的优化可能会导致代码膨胀(即编译后的代码体积增大),从而影响性能。因此,C2 编译器也会根据代码的运行情况和性能反馈来进行“取消优化”,即撤销一些不太必要或导致性能下降的优化。
C1 和 C2 编译器在优化和取消优化方面有着不同的侧重点。C1 更注重编译速度,而 C2 更注重深度优化。在实际运行中,HotSpot 虚拟机还会根据代码的运行情况和性能反馈来动态选择使用哪个编译器或进行哪些优化。

自JDK 7版本起,HotSpot引入了分层编译机制,该机制使得C1和C2编译器能够协同工作,共同提升代码性能。在分层编译中,整个优化过程被划分为五个不同的等级,每个等级对应着不同的编译策略和优化级别。
| 等级 | 使用的组件 | 描述 | 保存的内容 | 性能分数(1 - 5) |
| 0 | 解释器 | 解释执行记录方法调用次数及循环次数 | 无 | 1 |
| 1 | C1即时编译器 | C1完整优化 | 优化后的机器码 | 4 |
| 2 | C1即时编译器 | C1完整优化,记录方法调用次数及循环次数 | 优化后的机器码; 部分额外信息:方法调用次数及循环次数 | 3 |
| 3 | C1即时编译器 | C1完整优化,记录所有额外信息 | 优化后的机器码; 所有额外信息:分支跳转次数、类型转换等等 | 2 |
| 4 | C2即时编译器 | C2完整优化 | 优化后的机器码 | 5 |
C1和C2编译器各自拥有独立的线程来处理编译任务,这些线程内部维护了一个任务队列,用于存放待编译的代码。通常情况下,即时编译器主要针对方法进行优化,不过在某些情况下,也会对代码中的循环结构进行优化。
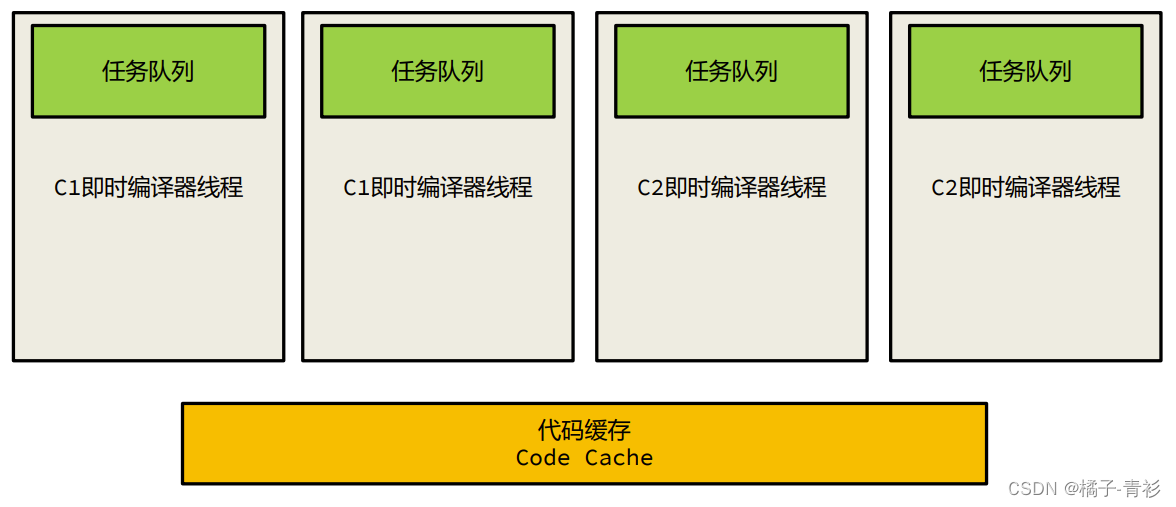
在HotSpot虚拟机中,C1和C2编译器的协作机制是实现高效代码编译和优化的关键。它们之间的协作主要体现在以下几个方面:
- 信息收集和触发阈值:首先,C1编译器在执行代码的过程中会负责收集运行时的各种信息,如方法执行次数、循环执行次数、分支执行次数等。这些信息对于后续的优化至关重要。当这些执行次数达到一个由JVM动态计算的触发阈值时,代码会进入C2编译器进行更深层次的优化。这种触发机制确保了只有经过充分运行和验证的代码才会被进一步优化,从而提高了优化的针对性和效率。

- 优化策略选择:在某些情况下,如果方法的字节码执行次数较少,JVM会评估C1和C2的优化性能。如果认为两者的优化效果相近,那么JVM将停止收集信息,并直接由C1编译器进行优化。这种策略选择机制避免了不必要的开销,确保了编译过程的效率。

- 线程忙碌时的处理:当C1的线程资源紧张,无法及时处理编译任务时,C2编译器会接管这些任务。C2以其强大的优化能力来处理这些代码,确保了程序在忙碌场景下的性能表现。这种机制确保了在高负载情况下,代码仍然能够得到有效的编译和优化。

- 分层编译和协作流程:在C2线程忙碌时,为了保持编译流程的连续性,会先由2层C1编译器进行初步的信息收集和优化。这一阶段的目的是快速积累运行时的基本信息。随后,这些信息会传递给3层C1进行处理。然而,由于3层C1的优化效率相对较低,因此会尽量减少在这一层的停留时间。这种分层编译和协作流程确保了即使在C2忙碌时,代码仍然能够得到一定程度的优化,而不会造成过多的延迟。一旦C2线程空闲,它会接手这些任务,并进行更为深入的优化,从而确保代码的最终性能。

三、JIT优化技术
JIT编译器主要通过方法内联和逃逸分析两种技术来优化代码。
1.方法内联
这是一种将方法体中的字节码指令直接复制到调用方的字节码指令中的技术,它有助于减少栈帧的创建开销,提高代码的执行效率。但并非所有的方法都适合内联,它受到一定的限制,如方法的大小、热点度等。
案例(实际上,涉及的是字节码指令,但为了简化理解和说明,此处采用了源代码进行展示):
int result = add(a, b); public int add(int a, int b) { return a + b; }方法内联结果:
int result = a+ b;
方法内联的限制:在Java虚拟机(JVM)的即时编译器(JIT)中,方法内联是一项重要的优化技术,但并非所有方法都可以或应该被内联。内联的应用受到一系列限制和条件的约束,以确保优化的有效性和代码的性能。以下是方法内联的一些主要限制:
- 字节码指令大小限制:如果一个方法编译后的字节码指令总大小小于35字节,则JIT编译器通常会将其视为轻量级方法,并可能直接进行内联。这个限制可以通过JVM参数-XX:MaxInlineSize=值进行调整,允许更大的字节码大小进行内联。
- 热方法的字节码大小限制:对于编译后的字节码指令总大小在35字节到325字节之间的方法,如果它们被频繁调用(即热方法),JIT编译器也可能会选择进行内联。这个限制可以通过-XX:FreqInlineSize=值参数进行配置,允许根据实际需求调整热方法的内联大小阈值。
- 机器码大小限制:即使一个方法的字节码大小满足上述条件,其编译生成的机器码大小也不能超过1000字节。这是为了确保内联后的代码不会过于庞大,影响执行效率。这个限制可以通过-XX:InlineSmallCode=值参数进行调整。
- 接口实现数量的限制:如果一个接口的实现方法数量超过3个,那么这些方法通常不会被内联。这是因为接口的实现通常具有多态性,内联过多的接口实现方法可能导致代码膨胀和性能下降。
这些限制确保了方法内联的针对性和有效性,避免了不必要的内联操作,从而提高了代码的执行效率和性能。在实际应用中,开发者可以通过调整JVM参数来平衡内联的积极程度和性能表现。
2.逃逸分析
逃逸分析是JIT(Just-In-Time)编译器中的一种高级优化技术,其核心在于判断方法内部创建的对象是否会被方法外部引用。如果JIT编译器确定一个对象不会“逃逸”到方法外部,即该对象的生命周期仅限于当前方法内,那么就可以应用一系列优化策略,如锁消除和标量替换,以提升程序性能。
锁消除:
锁消除是一种针对同步锁的优化手段。在逃逸分析的指导下,如果JIT编译器判断某个对象不会逃逸出当前方法,那么该对象就不会面临多线程并发访问的问题。因此,编译器可以选择消除该对象上的所有锁操作,包括锁的获取、释放以及等待锁的代码。这样可以有效减少线程间的竞争和同步开销,提高程序的执行效率。需要注意的是,锁消除优化在实际应用中并不常见,因为通常情况下,加锁的对象都是设计用来支持多线程并发访问的。
案例:
public void nonEscapingMethod() { synchronized(new Object()) { // ... 锁内的代码逻辑 } }在上述代码中,由于新创建的对象只在nonEscapingMethod方法内部使用,并没有逃逸出去,因此理论上是可以进行锁消除的。
标量替换:
标量替换是逃逸分析中另一种重要的优化手段。在Java虚拟机中,对象内部的基本数据类型成员被称为标量,而对象引用的其他对象则被称为聚合量。当JIT编译器确定一个对象不会逃逸时,它可以选择将该对象拆分成若干个标量,并将这些标量直接在栈上分配而不是在堆上。这样做的好处是可以减少堆内存的分配和垃圾回收的压力,同时还能消除因对象访问带来的间接引用开销,从而提升程序的执行性能。
案例:
public class Point { private int x, y; ... } public void nonEscapingMethod() { Point point = new Point(1, 2); // 仅使用point的x和y属性,不逃逸 ... }在上述代码中,如果Point对象被确定不会逃逸出nonEscapingMethod方法,那么JIT编译器可能会选择将point对象的x和y属性直接作为局部变量处理,而不是在堆上分配一个完整的Point对象。这种优化就是标量替换。
四、JIT优化建议
针对JIT(Just-In-Time)编译器在优化Java代码时的特性,为了确保代码执行时能够获得卓越的性能,建议在编写代码时遵循以下几个关键指导原则:
- 编写小型方法:为了最大化方法内联的效果,应尽可能编写小型且专一的方法。小型方法更有可能被JIT编译器识别为内联候选,从而消除方法调用的开销,提高执行效率。
- 优化高频代码:对于频繁执行的代码段,特别是那些来自第三方依赖库或JDK本身的代码,如果其内部实现过于复杂,可能无法被内联。在这种情况下,可以考虑自行实现一个定制化的、更简洁的版本,以便JIT编译器能够更有效地对其进行优化。
- 控制接口实现数量:接口的实现数量对JIT的内联处理有显著影响。为了促进内联,建议将接口的实现数量限制在最低必要水平,通常不应超过两个。这样可以降低内联的复杂性,提高编译器的优化能力。
- 避免对象逃逸:在高频调用的方法中,如果创建了仅供临时使用的对象,应尽量避免这些对象逃逸到方法外部。对象逃逸可能导致额外的性能开销,如垃圾回收压力增加和可能的锁竞争。通过局部变量的使用或对象池技术,可以有效减少对象逃逸的情况。
总结
JVM是Java程序的运行环境,负责字节码解释、内存管理、安全保障、多线程支持、性能监控和跨平台运行。本文主要介绍了JIT即时编译器、HotSpot中的JIT编译器、JIT优化技术、JIT优化建议等内容,希望对大家有所帮助。
![[计算机网络]---序列化和反序列化](https://img-blog.csdnimg.cn/direct/fd55247bf7494a819f098bbc3cfa6708.png)


![[java基础揉碎]数组 值拷贝和引用拷贝的赋值方式](https://img-blog.csdnimg.cn/direct/2366dd5fbbf045039b0609f60fb32011.png)
![【蓝桥杯冲冲冲】[CEOI2015 Day2] 世界冰球锦标赛](https://img-blog.csdnimg.cn/direct/eb56df1dfcbe45408a5d9b024cd53b02.jpeg#pic_center)
![[高并发] - 1.高并发综述](https://img-blog.csdnimg.cn/direct/786c2a0c57754fe3969064526dcb82b9.png)




![[java基础揉碎]二维数组](https://img-blog.csdnimg.cn/direct/b2fc1dd24f664a89b2c7fd1558813c49.png)