目录
一、介绍
二、背景知识
三、了解功能缩放
四、特征缩放方法
五、特征缩放的重要性
六、实际意义
七、代码
八、结论
一、介绍
特征缩放是机器学习和数据分析预处理阶段的关键步骤,在优化各种算法的性能和效率方面起着至关重要的作用。本文深入探讨了特征缩放的本质,探讨了其不同的方法,强调了其重要性,并考虑了其在机器学习模型中的应用的实际意义。
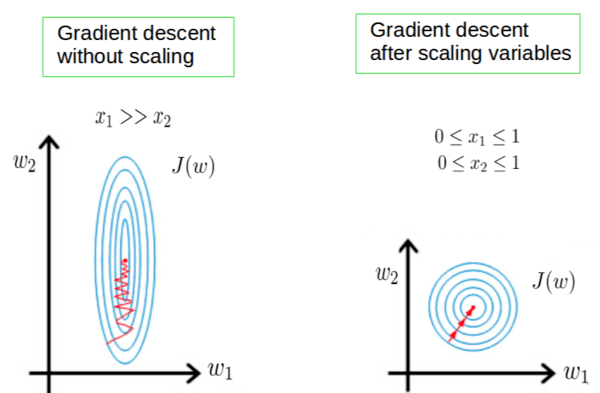
在机器学习的世界里,算法学会寻找模式并做出决策,特征缩放是很好的均衡器,确保每个特征,无论其原始规模如何,都有一个在数据合唱中同样响亮的声音。
二、背景知识
特征缩放是一种用于机器学习和数据挖掘的数据预处理方法,用于对数据的自变量或特征的范围进行归一化。在机器学习的背景下,特征缩放可能至关重要,因为它直接影响使用距离计算的算法的性能,例如 k 最近邻 (KNN) 和 k 均值聚类,并且会显着影响神经网络和支持向量机中使用的梯度下降优化方法的性能。
有几种常见的特征缩放方法:
1 最小-最大缩放(归一化):
- 该方法单独缩放和转换每个特征,使其在训练集的给定范围内,例如,介于 0 和 1 之间。要素归一化值的计算公式为:
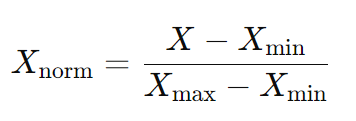
- 其中 X 是原始值,minXmin 是要素的最小值,maxXmax 是要素的最大值。
2 标准化(Z 分数归一化):
- 此方法对要素进行缩放,使其具有 0μ=0 和 1 σ=1 的标准正态分布属性,其中 μ 是平均值(平均值),σ 是与平均值的标准差。样本的标准分数(也称为 z 分数)的计算方法如下:
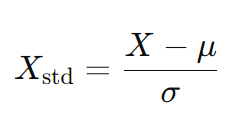
- 标准化不会将值绑定到特定范围,这对于某些算法来说可能是一个问题(例如,神经网络通常期望输入值范围为 0 到 1)。
3 最大Abs缩放:
- 单独缩放和转换每个特征,使训练集中每个特征的最大绝对值为 1.0。它不会移动/居中数据,因此不会破坏任何稀疏性。
4 Robust 缩放的:
- 此方法删除中位数并根据分位数范围(通常是四分位距,IQR)缩放数据。它对异常值具有鲁棒性,当数据包含许多异常值或我们不想假设特征的正态分布时,会使用它。
特征缩放应用于数据的自变量或特征,以标准化数据的范围。这在计算数据点之间距离的算法中非常重要,或者当特征具有不同的单位和比例时,因为它可以使训练过程更快,并减少卡在局部最优状态的机会。但是,缩放技术的选择可能取决于算法和数据的具体特征。
三、了解功能缩放
特征缩放是对数据中自变量或特征范围进行归一化或标准化的过程。该技术的主要目标是确保没有一个特征因其规模而主导模型,从而使算法在训练过程中更快、更有效地收敛。对于依赖于距离计算的模型(例如 k 最近邻 (KNN) 和 k 均值聚类)或使用梯度下降优化方法(包括神经网络和支持向量机 (SVM))的模型,这一点尤为重要。
四、特征缩放方法
有几种常见的功能缩放方法,每种方法都有其独特的应用和优点:
- 最小-最大缩放(归一化):此方法调整数据的缩放比例,使其适合特定范围,通常为 0 到 1。它适用于假定数据处于有限间隔但对异常值敏感的算法。
- 标准化(Z 分数归一化):与归一化不同,标准化不会将值绑定到特定范围,这使得它适用于不假设特定数据分布的算法。它将特征转换为均值为零,标准差为一,从而促进对数据规模敏感的算法更快地收敛。
- 最大 Abs 缩放:此技术按每个要素的最大绝对值缩放。这对于已经居中的数据或稀疏数据非常有用,其中零是一个有意义的值。
- 强大的扩展性:通过删除中位数并根据分位数范围缩放数据,鲁棒缩放可减轻异常值的影响。当数据集包含许多异常值或数据不服从正态分布时,它特别有利。
五、特征缩放的重要性
特征缩放通过确保特征对结果的贡献相等来增强机器学习算法的性能,从而防止由于数据的固有规模而产生的偏差。例如,在梯度下降算法中,特征缩放可以显著加快收敛速度,因为它确保向最小值迈出的步长在所有维度上都是成比例的。同样,在计算数据点之间距离的聚类算法和模型中,要素缩放可确保距离度量不会因要素比例而偏斜。
六、实际意义
在实践中,特征缩放方法的选择取决于所使用的算法和数据的具体特征。对于决策树或随机森林等算法,可能不需要特征缩放,因为这些模型对数据规模不敏感。然而,对于支持向量机、神经网络和基于距离的算法,特征缩放对于模型性能和准确性至关重要。
此外,异常值的存在会显着影响使用哪种缩放方法。例如,最小-最大缩放可能对异常值高度敏感,可能会将大部分数据压缩到一个小范围内。在这种情况下,可靠的扩展或标准化可能更合适。
七、代码
为了使用完整的 Python 代码示例来说明特征缩放,我们将创建一个合成数据集,应用不同的特征缩放技术,并可视化这些技术对数据集的影响。我们还将包含指标来评估缩放对简单机器学习模型的影响。
步骤 1:创建合成数据集
首先,我们将使用 创建一个具有不同比例特征的合成数据集。sklearn.datasets.make_classification
步骤 2:应用特征缩放技术
我们将应用以下功能缩放技术:
- 最小-最大缩放
- 标准化(Z 分数归一化)
- 最大腹肌缩放
- 强大的扩展能力
步骤 3:可视化要素缩放的效果
在应用每种缩放技术之前和之后,我们将使用绘图来可视化数据集。
步骤 4:评估对机器学习模型的影响
作为一个简单的评估,我们将使用逻辑回归模型来查看特征缩放如何影响其性能。我们将数据集拆分为训练集和测试集,应用缩放,训练模型,然后使用准确性作为指标对其进行评估。
让我们开始对这个过程进行编码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler, MaxAbsScaler, RobustScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Step 1: Create a synthetic dataset
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.5], random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Function to apply scaling and train a logistic regression model
def apply_scaling_and_evaluate(scaler):
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Train logistic regression model
model = LogisticRegression(random_state=42)
model.fit(X_train_scaled, y_train)
# Predict and evaluate
predictions = model.predict(X_test_scaled)
accuracy = accuracy_score(y_test, predictions)
# Plotting
plt.scatter(X_train_scaled[:, 0], X_train_scaled[:, 1], c=y_train, cmap='viridis', alpha=0.5)
plt.title(f"{scaler.__class__.__name__} - Accuracy: {accuracy:.2f}")
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
# Original Data Plot
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis', alpha=0.5)
plt.title("Original Data")
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
# Apply and visualize different scaling techniques
scalers = [MinMaxScaler(), StandardScaler(), MaxAbsScaler(), RobustScaler()]
for scaler in scalers:
apply_scaling_and_evaluate(scaler)解释:
- 创建合成数据集:我们使用 生成一个具有两个特征的数据集。然后,将数据集拆分为训练集和测试集。
make_classification - 应用缩放技术:对于每种缩放技术,我们创建一个缩放器对象,将其拟合到训练数据上,并转换训练集和测试集。
- 训练和评估模型:我们在缩放数据上训练逻辑回归模型,并通过计算测试集的准确性来评估其性能。
- 可视化:对于每种缩放技术,我们绘制缩放的特征以可视化数据分布的变化。
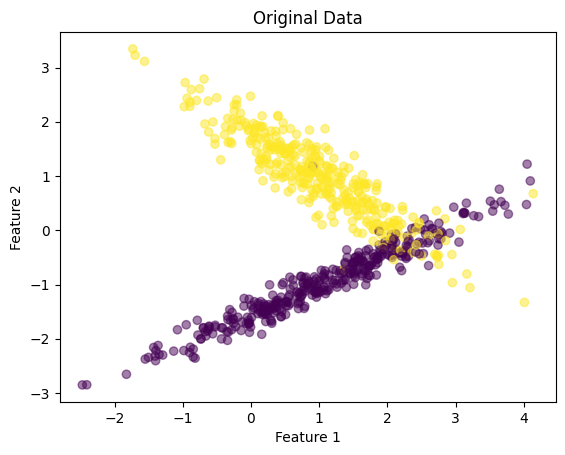
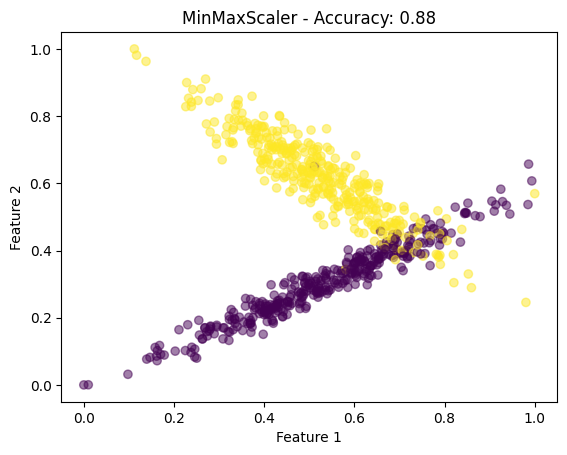
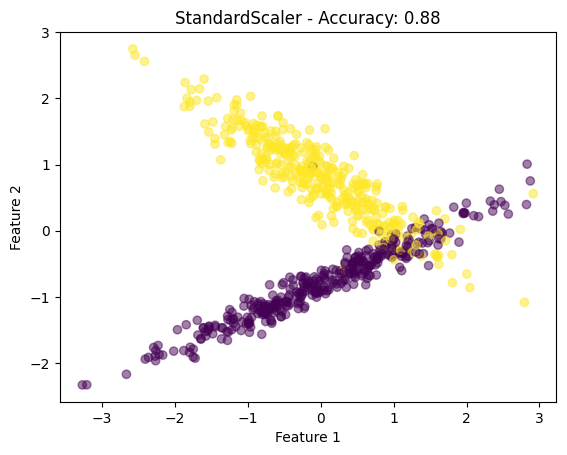
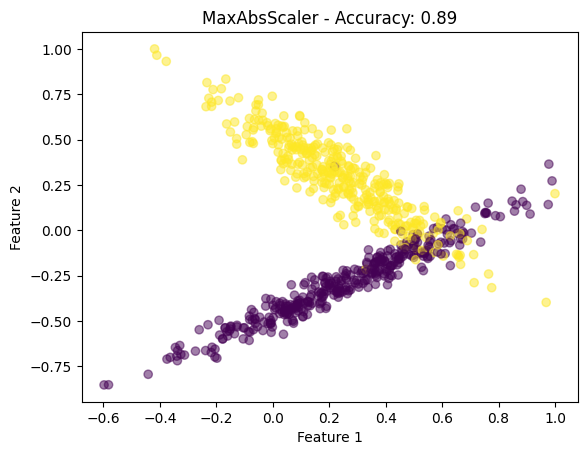
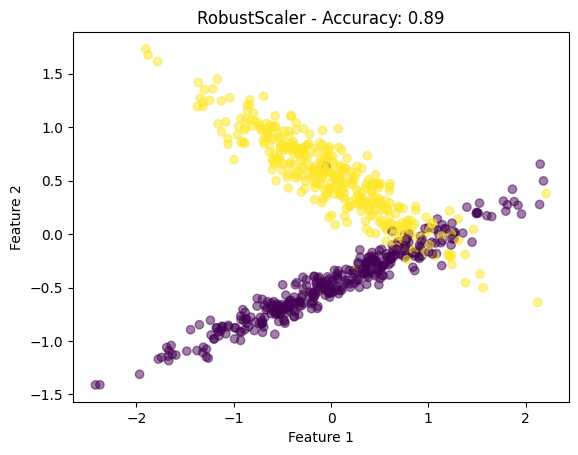
此代码全面概述了如何在 Python 中应用特征缩放、可视化其效果以及评估对简单机器学习模型的影响。
八、结论
特征缩放是机器学习算法预处理数据的基本步骤,可确保特征的缩放不会使模型产生偏差。通过了解并适当应用不同的特征缩放方法,数据科学家可以提高机器学习模型的性能、效率和准确性。因此,特征缩放不仅有助于算法的最佳功能,而且还强调了在机器学习和数据分析的更广泛背景下进行深思熟虑的数据预处理的重要性。