目录
6 数值型函数
7 字符串函数
8 流程控制函数
9 聚合函数
10 分组查询 (group by)
11 分组过滤 (having)
12 限定查询 (limit)
13 多表查询
13.1 连接条件关键词 (on、using)
13.2 连接算法
13.3 交叉连接 (cross join)
13.4 内连接 (inner join)
13.5 外连接 (left join、right join)
14 子查询
14.1 select 子查询 (只需了解)
14.2 from 子查询
14.3 where 子查询
15 查询顺序总结
6 数值型函数
|

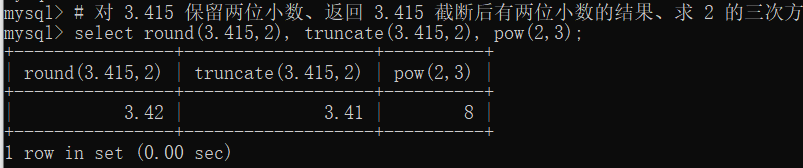
7 字符串函数
|




8 流程控制函数
|

9 聚合函数
|
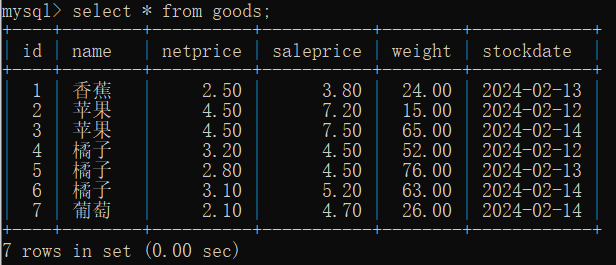

10 分组查询 (group by)
|

11 分组过滤 (having)
|
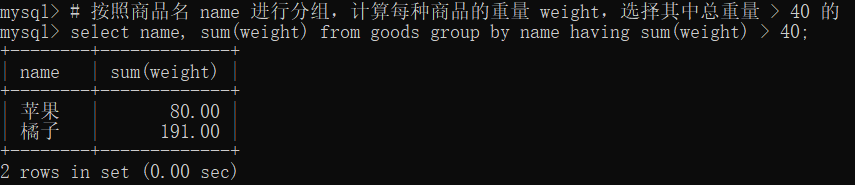
12 限定查询 (limit)
|

13 多表查询
sales 表
drop table if exists sales;
create table sales (
id int primary key auto_increment,
name varchar(20),
saleprice float(7,2)
)charset=utf8;
insert into sales(id, name, saleprice) values
(1, '香蕉', 3.8),
(3, '苹果', 7.5),
(4, '橘子', 4.5),
(7, '葡萄', 4.7);
- 交叉连接:cross join (,)
- 内连接:(inner) join
- 外连接:left (outer) join、right (outer) join、union
MySQL join 语法官方文档:
MySQL 5.7 Reference Manual / ... / JOIN Clause
https://dev.mysql.com/doc/refman/5.7/en/join.html
13.1 连接条件关键词 (on、using)
| 执行顺序:
|
13.2 连接算法
| 参考文档: MySQL 连接查询超全详解
补充 left join | right join 连接算法,瞎编的伪代码,具体可以看官方文档: MySQL 5.7 Reference Manual / ... / Nested Join Optimization
注:MySQL 8.0 版本提供了 hash join 连接算法,其他版本仍是 nested loop join 连接算法,尽量少用 join,不同时连接三张表 |


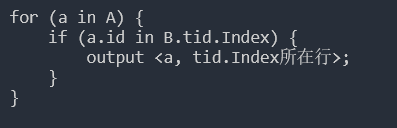

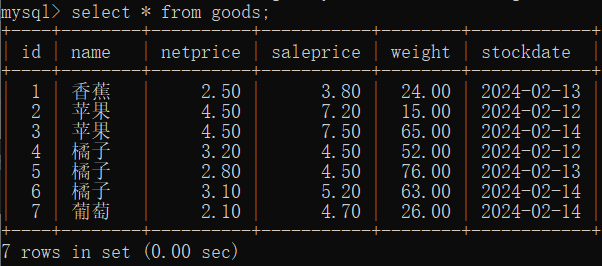
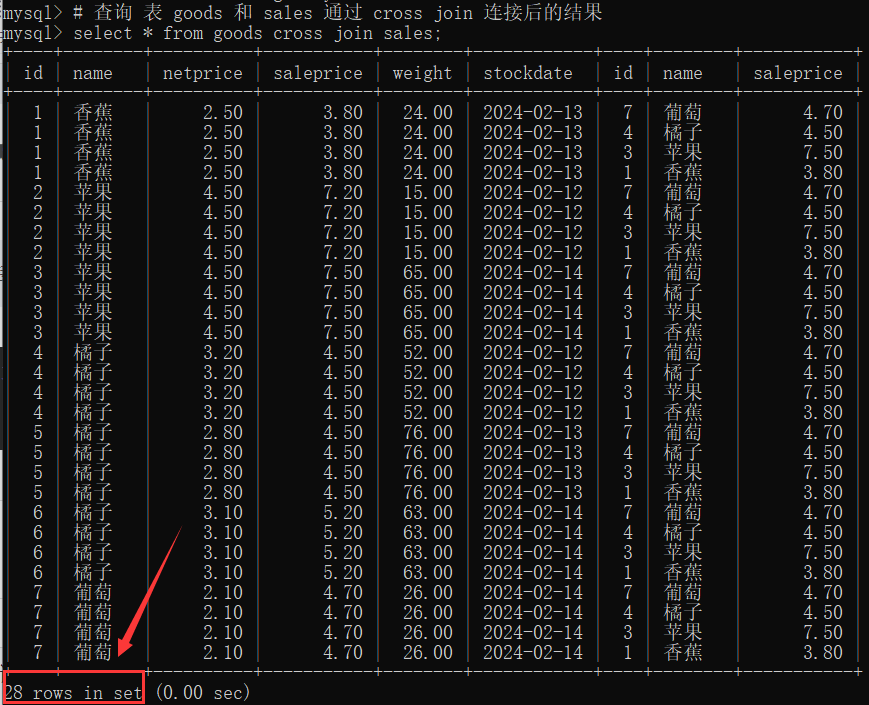
13.3 交叉连接 (cross join)
|

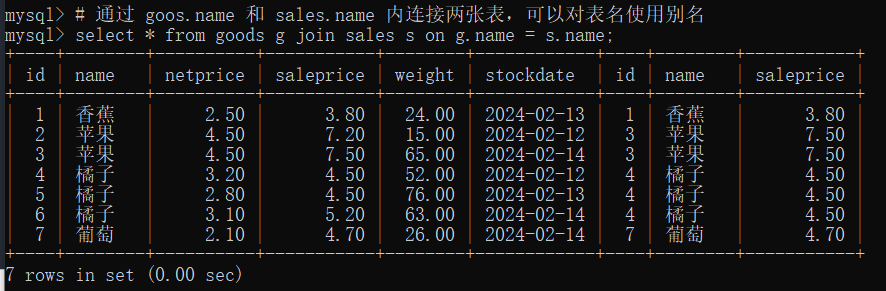
13.4 内连接 (inner join)
|

13.5 外连接 (left join、right join)
|




14 子查询
|
14.1 select 子查询 (只需了解)
|

14.2 from 子查询
|
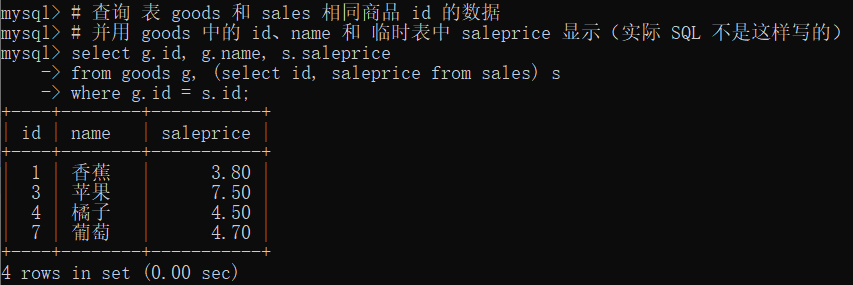
14.3 where 子查询
|

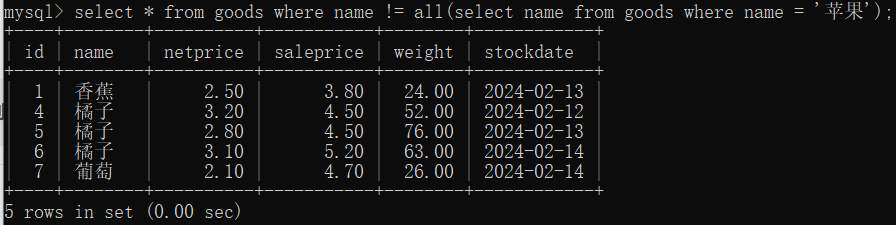
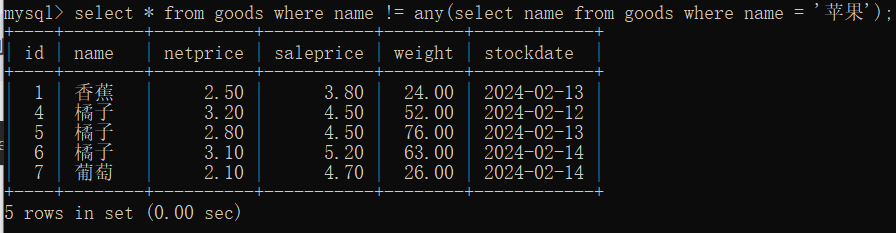

15 查询顺序总结
|