文章目录
- 引言
- 基本诉求
- 存储选型考虑的要素
- 分布式存储的野蛮生长史
- 主要开源选型
- GFS(Google File System)
- HDFS (Hadoop Distributed File System)
- minio
- ceph
- TFS
- Swift
- fastDFS
- GridFS
- MooseFS
- GlusterFS
- MogileFS
- 一些国产的xFS
- 阿里
- 腾讯
- 百度
- 京东
- 网易
- 字节跳动
- 美团
- 滴滴
- 结论
- 数据库选型
- 分布式存储选型参考
- 参考链接
引言
当我想自己搭建一个图片服务器时,举手投足,放眼望去,只见技术多如牛毛,不禁拔剑四顾心茫然。如果用阿里云的oss或者七牛,自然不在话下。但如果我不想掏钱呢,用哪些开源组件比较好?于是,不得不坐下来,回顾起一段分布式存储波澜壮阔的发展历程。
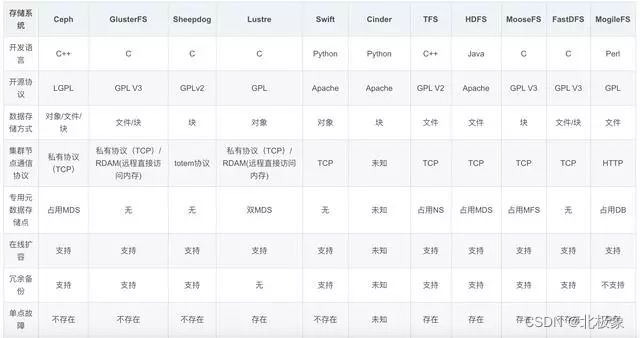
主流的开源方案: Ceph,minio, GlusterFS, Sheepdog,Lustre, Swift,Cinder, TFS, HDFS,MooseFS, FastDFS, MogileFS
基本诉求
我个人的需求:
- 性能比直接读取文件系统要快
- 支持分布式
- 支持小而大量的图片存储,也希望支持10M~100M之间的电子文档如PDF的存储,不知道二者是否有冲突
- 有简洁的控制台,易于监控
- 方便备份,导入导出
其它高级需求:
- 高性能:主要考虑500M以内的小文件,特别是10M以内的文件; 如果是存储海量数据呢?
- 安全性和可靠性/容错性高、数据万无一失:要考虑各种极端情况,包括网络异常,服务器断电,磁盘损坏
- 资源占用较小、运行稳定
- 高可用、支持集群、支持多活
- 支持平滑的扩容
- 较高的并发
美好的图景:
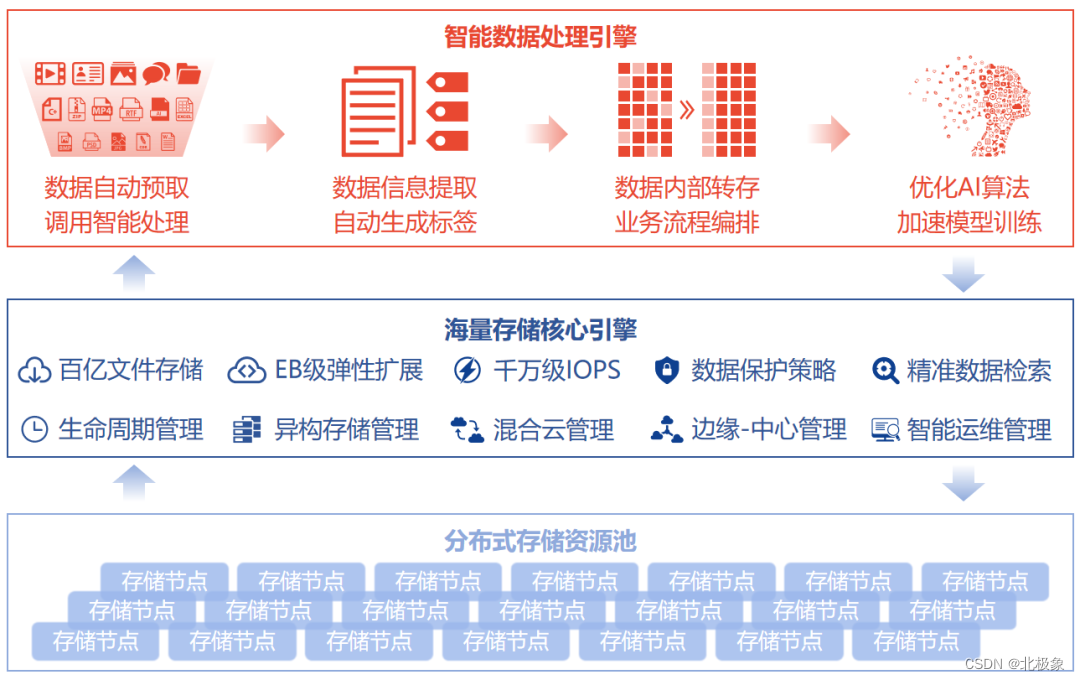
存储选型考虑的要素
- 用户量:用户量预估多少?几百几万还是几亿?
- 数据量:数据量预估多少?日均增量能有多少?
- 读写偏好:数据是读多一些还是写多一些?
- 数据场景:强事务型还是分析型需求?
- 运行性能要求:并发量是多少?高峰、平均、低谷分别预估是多少?
分布式存储的野蛮生长史

几个主要阶段:
- 1980s的网络文件系统
- 1990s的共享SAN文件系统
- 2000s的面向对象并行文件系统
- 2010s的云文件系统
自2003年Google发布分布式文件系统GFS论文以来,陆续出现许多面向不同场景的分布式文件存储(包括对象存储,块存储),大部分仍然是沿袭GFS的架构,在此基础上完善增强,也有少部分系统是另辟蹊径,走了别的道路,这两条路径上都有比较成功的产品。
主要开源选型
先上对比:
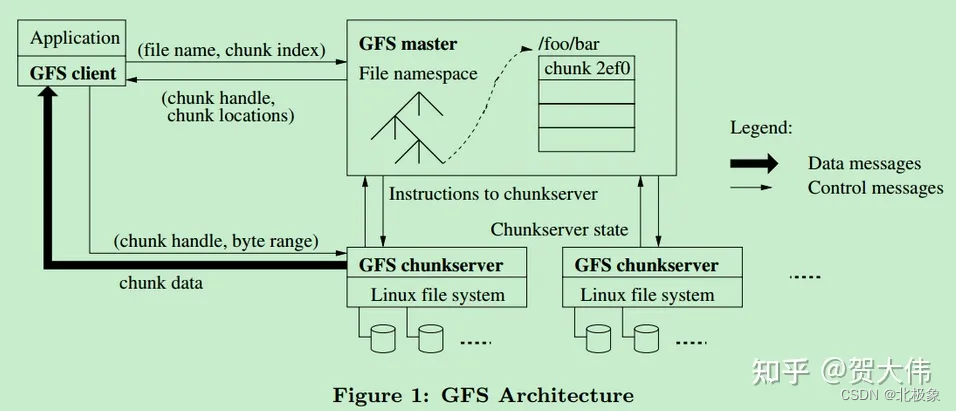
GFS(Google File System)
Google公司为了满足本公司需求而开发的基于Linux的专有分布式文件系统。尽管Google公布了该系统的一些技术细节,但Google并没有将该系统的软件部分作为开源软件发布。
HDFS (Hadoop Distributed File System)
Aapche Hadoop架构是MapReduce算法的一种开源应用。Hadoop 实现了一个分布式文件系统,简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch。
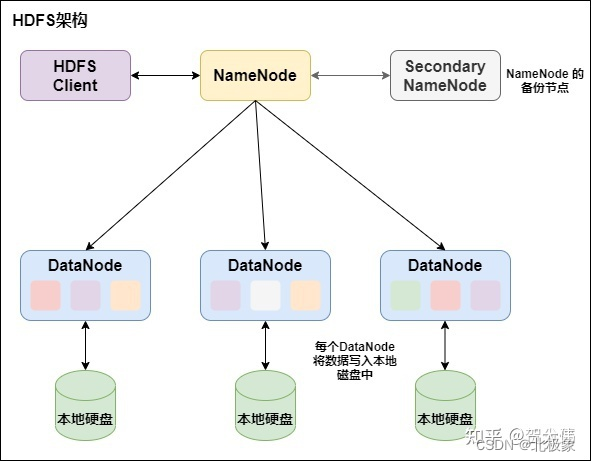
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。
Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。
Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
Secondary NameNode的功能主要是辅助NameNode,分担其工作量;在紧急情况下可以辅助恢复NameNode,但是它不能替换NameNode并提供服务。
HDFS上的一个典型文件大小一般都在G字节至T字节。因此,HDFS可以支持大文件存储。它应该能提供整体上高的数据传输带宽,能在一个集群里扩展到数百个节点。一个单一的HDFS实例应该能支撑数以千万计的文件。
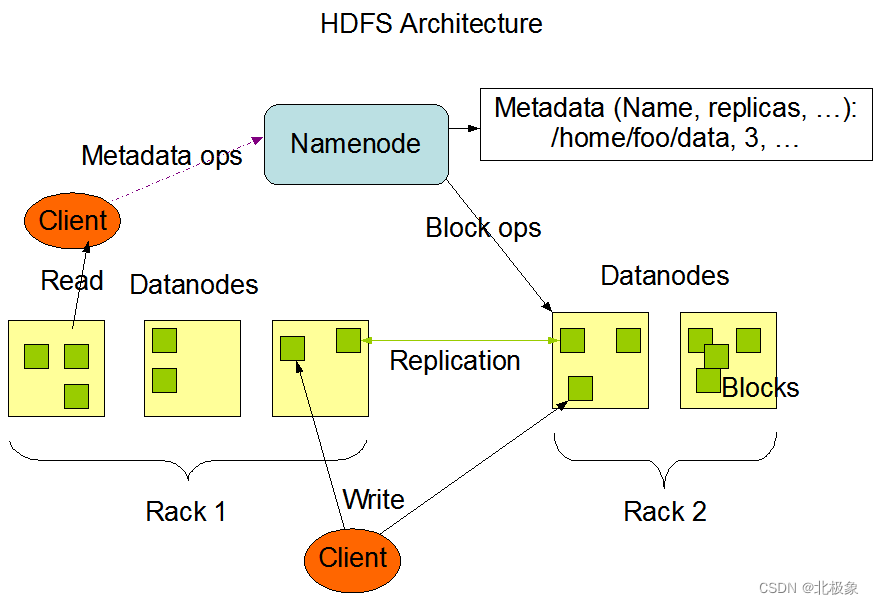
再贴一张图片加深理解:
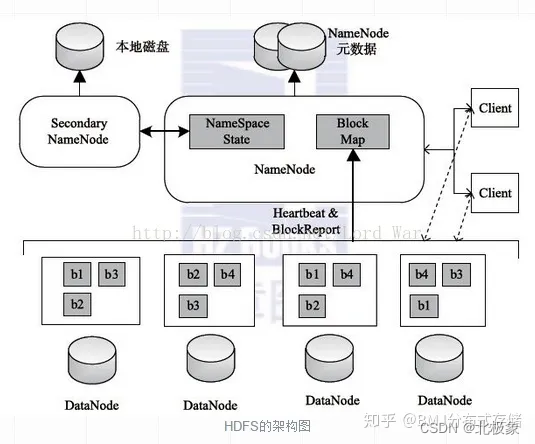
HDFS的优势在于:
1.容错性:数据自动保存多个副本。通过增加副本的形式,提高容错性。其中一个副本丢失以后,可以自动恢复。
2.可以处理大数据:能够处理数据规模达到GB、TB甚至PB级别的数据;能够处理百万规模以上的文件数量。
3.可以构建在廉价的机器上,通过多副本机制,提高可靠性。
缺点:
1.不适合低延时数据访问:比如毫秒级的存储数据,是做不到的。
2.无法高效对大量小文件进行存储:存储大量小文件的话,它会占用 NameNode 大量的内存来存储文件目录和块信息。这样是不可取的,因为 NameNode的内存总是有限的。同时,小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3.不支持并发写入、文件随机修改:一个文件只能有一个写,不允许多个线程同时写。仅支持数据 append(追加),不支持文件的随机修改。
minio
Minio是一个用Golang开发的基于Apache License v2.0开源协议的对象存储服务。MinIO 是世界上最快的对象存储服务器,在标准硬件上,读写速度分贝为 183GB/s 和 171GB/s,对象存储可以作为主要存储层,用于 Spark,Presto,TensorFlow,H20.ai 以及替代产品等各种工作负载用于 Hadoop HDFS。
Minio是一个开源的分布式文件存储系统,它基于 Golang 编写,虽然轻量,却拥有着不错的高性能,可以将图片、视频、音乐、pdf这些文件存储到多个主机,可以存储到多个Linux,或者多个Windows,或者多个Mac,Minio中存储最大文件可以达到5TB。
MinIO 是一种高性能的分布式对象存储系统,它是软件定义的,可在行业标准硬件上运行,并且在 Apache 2.0 许可下,百分百开放源代码。
MinIO是兼容Amazon S3的,换句话说,MinIO可以伪装成Amazon S3,你可以用Amazon S3的SDK操作MinIO。
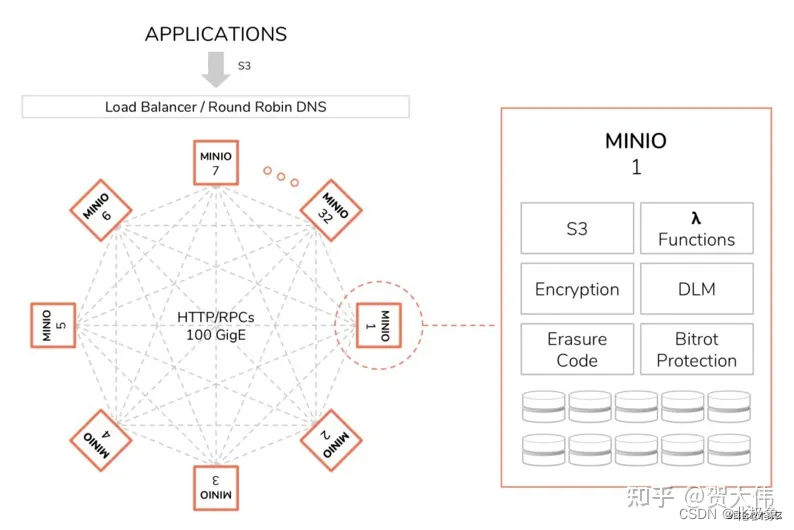
多副本,优点是写入效率高,无需多余的计算,直接存多份即可,数据恢复快,从副本复制就好了。缺点就是存储效率低、占用空间以前需要的磁盘容量直接%20X2%20或者%20X3%20倍了。
ceph
Ceph是去中心化的分布式解决方案,一个可以按对象/块/文件方式存储的开源分布式文件系统。其设计之初,就将单点故障作为首先要解决的问题,因此该系统具备高可用性、高性能及可 扩展等特点。该文件系统支持目前还处于试验阶段的高性能文件系统BTRFS(B-Tree文件系统),同时支持按OSD方式存储,因此其性能是很卓越的, 因为该系统处于试商用阶段,需谨慎引入到生产环境。
优点:
1)支持对象存储(OSD)集群,通过CRUSH算法,完成文件动态定位, 处理效率更高
2)支持通过FUSE方式挂载,降低客户端的开发成本,通用性高
3)支持分布式的MDS/MON,无单点故障
4)强大的容错处理和自愈能力5)支持在线扩容和冗余备份,增强系统的可靠性
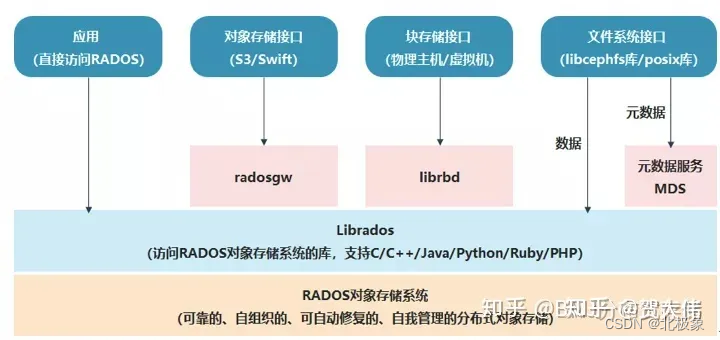
Ceph支持对象存储、块存储和文件存储服务,故称为统一存储。
Ceph的缺点
1.去中心化的分布式解决方案,需要提前做好规划设计,对技术团队的要求能力比较高。
2.Ceph扩容时,由于其数据分布均衡的特性,会导致整个存储系统性能的下降。
TFS
TFS(Taobao File System)是由淘宝开发的一个分布式文件系统,其内部经过特殊的优化处理,适用于海量的小文件存储,目前已经对外开源;
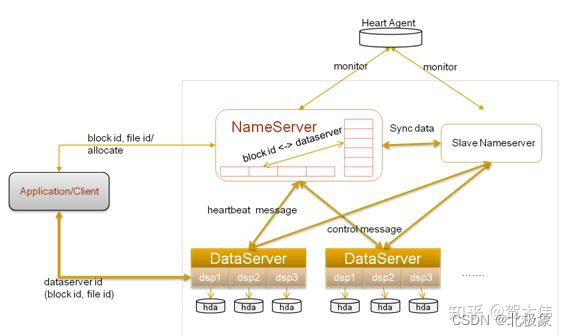
Swift
swift于2008年起步,最初是由Rackspace公司开发的分布式对象存储服务, 2010 年贡献给 OpenStack 开源社区。现如今已部署到大规模公有云的生产环境中使用。
优点在于:极高的数据持久性和完全对称的系统架构、无限的可扩展性。缺点在于原生的对象存储,不支持实时的文件读写、编辑功能。
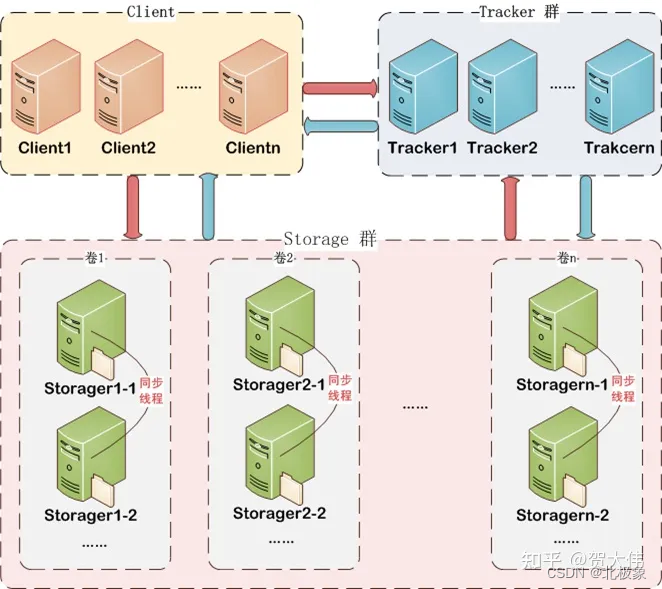
fastDFS
FastDFS是国人开发的一款分布式文件系统,目前社区比较活跃。如上图所示系统中存在三种节点:Client、Tracker、Storage,在底层存储上通过逻辑的分组概念,使得通过在同组内配置多个Storage,从而实现软RAID10,提升并发IO的性能、简单负载均衡及数据的冗余备份;同时通过线性的添加新的逻辑存储组,从容实现存储容量的线性扩容。
文件下载上,除了支持通过API方式,目前还提供了apache和nginx的插件支持,同时也可以不使用对应的插件,直接以Web静态资源方式对外提供下载。
目前FastDFS(V4.x)代码量大概6w多行,内部的网络模型使用比较成熟的libevent三方库,具备高并发的处理能力。
FastDFS是一个开源的轻量级分布式文件系统。它解决了大数据量存储和负载均衡等问题。特别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务,如相册网站、视频网站等等。在UC基于FastDFS开发向用户提供了:网盘,社区,广告和应用下载等业务的存储服务。
FastDFS是一款开源的轻量级分布式文件系统纯C实现,支持Linux、FreeBSD等UNIX系统类google FS,不是通用的文件系统,只能通过专有API访问,目前提供了C、Java和PHP API为互联网应用量身定做,解决大容量文件存储问题,追求高性能和高扩展性FastDFS可以看做是基于文件的key value pair存储系统,称作分布式文件存储服务更为合适。
GridFS
GridFS是基于mongodb存储引擎是实现的“分布式文件系统”,底层基于mongodb存储机制,和其他本地文件系统相比,它具备大数据存储的多个优点。GridFS适合存储超过16MB的大型文件。
GridFS并不是将单个文件直接存储为一个document,而是将文件分成多个parts或者说chunks,然后将每个chunk作为作为一个单独的document存储,然后将chunks有序保存。默认情况下,GridFS的chunk大小位255k。GridFS使用2个collections来存储这些文件,一个collection存储文件的chunks(实际文件数据),另一个则存储文件的metadata(用户自定义的属性,filename,content-type等)。
当用户查询GridFS中的文件时,客户端或者driver将会重新按序组装这些chunks。用户可以range查询文件,也可以获取文件的任意部分的信息,比如:跳过(skip)视频或者音频(任何文件)的中间部,实现“range access of single file”。
对于mongodb而言,每个document最大尺寸为16M,如果想存储一条数据(比如一个文件)超过16M,那么只能使用GridFS支持;GridFS可以支持单个文件尺寸达到数G,读取文件时可以分段读取。此外,GridFS可以从Mongodb的高性能、高可用特性中获益,比如我们可以在“replica set”或者“sharding”架构模式下使用GridFS。
优点:
- 能够简化技术栈,如果已经使用了MongoDB,那么使用GridFS,就不需要其它独立的存储工具了。
- GridFS会自动平衡已有的复制,或者为MongoDB设置的自动分片,所以对文件存储做故障转移或者是横向扩展会更容易 。
- GridFS的功能不错,能自动解决一些其他文件系统遇到的问题,如在同一个目录下存储大量的文件。
缺点:
- 性能较低,不如直接访问文件系统快。
MooseFS
MooseFS是一个高可用的故障容错分布式文件系统,它支持通过FUSE方式将文件挂载操作,同时其提供的web管理界面非常方便查看当前的文件存储状态。
MooseFS文件系统由四部分组成:Managing Server 、Data Server 、Metadata Backup Server 及Client。
GlusterFS
GlusterFS是Red Hat旗下的一款开源分布式文件系统,它具备高扩展、高可用及高性能等特性,由于其无元数据服务器的设计,使其真正实现了线性的扩展能力,使存储总容量可 轻松达到PB级别,支持数千客户端并发访问;对跨集群,其强大的Geo-Replication可以实现集群间数据镜像,而且是支持链式复制,这非常适用 于垮集群的应用场景。
特性
1)目前GlusterFS支持FUSE方式挂载,可以通过标准的NFS/SMB/CIFS协议像访问本体文件一样访问文件系统,同时其也支持HTTP/FTP/GlusterFS访问,同时最新版本支持接入Amazon的AWS系统
2)GlusterFS系统通过基于SSH的命令行管理界面,可以远程添加、删除存储节点,也可以监控当前存储节点的使用状态
3)GlusterFS支持集群节点中存储虚拟卷的扩容动态扩容;同时在分布式冗余模式下,具备自愈管理功能,在Geo冗余模式下,文件支持断点续传、异步传输及增量传送等特点
MogileFS
Perl语言开发的,依赖数据库,Trackers(控制中心):负责读写数据库,作为代理复制storage间同步的数据。
Database:存储源数据(默认mysql)
Storage:文件存储。
除了API,可以通过与nginx集成,对外提供下载服务
一些国产的xFS
阿里
阿里云自研盘古存储平台,包括分布式文件系统(DFS),块存储(ECS云盘),对象存储 (OSS)。另外PolarDB依赖的高性能分布式文件系统PolarFS。
腾讯
自研Ozone是Apache Hadoop社区推出的新一代分布式存储系统,能满足大量小文件的存储问题, 解决Hadoop分布式文件系统在可扩展性上的缺陷,并支持百亿甚至千亿级文件规模的存储。
百度
早期百度分布式文件系统使用MooseFS,在此基础上研发了CCDB-NFS,解决MFS的问题,而后自研分布式文件系统BFS。
京东
京东自研分布式文件存储chubaoFS,整体性能优于Ceph,内部基于RDMA,SPDK等技术进行性能优 化(这部分没有开源),整体性能接近PolarFS,目前已经服务ES和MySQL数据库。
网易
自研分布式块存储Curve,整体性能优于Ceph。
字节跳动
字节之前使用Ceph,后来(2018年以后)自研分布式文件存储(刚刚起步)。
美团
美团云自研分布式对象存储MetaDenvB。 美团云自研分布式块存储Ursa。
滴滴
滴滴使用开源存储Ceph,并在此基础上深度优化。
结论
数据库选型
| 数据类型 | 常见数据库 |
|---|---|
| 关系型 | MySQL、Oracle、DB2、PostgreSQL |
| 非关系型 | Hbase、Redis、MongodDB |
| 行式存储 | MySQL、Oracle、DB2、SQLServer |
| 列式存储 | Hbase、ClickHouse |
| 分布式存储 | Cassandra、Hbase、MongodDB |
| 键值存储 | Memcached、Redis、MemcacheDB |
| 图形存储 | Neo4J、TigerGraph |
| 文档存储 | MongoDB、CouchDB |
分布式存储选型参考
- 适合做通用文件系统的有:Ceph,Lustre,MooseFS,GlusterFS;
- 适合做小文件存储的文件系统有:Ceph,MooseFS,MogileFS,FastDFS,TFS;
- 适合做大文件存储的文件系统有:HDFS,Ceph,Lustre,GlusterFS,GridFS;
- 轻量级文件系统有:MooseFS,FastDFS;
- 简单易用,用户数量活跃的文件系统有:MooseFS,MogileFS,FastDFS,GlusterFS;
- 支持FUSE挂载的文件系统有:HDFS,Ceph,Lustre,MooseFS,GlusterFS。
参考链接
- GridFS,MongoDB的一部分
- FastDFS
- TFS
- SeaweedFS(https://github.com/chrislusf/seaweedfs)
- HBASE(HDFS)
- Ceph
- MooseFS(https://moosefs.com/)
- GlusterFS(http://www.gluster.org/)
- MinIO








![基础算法[四]之图的那些事儿](https://img-blog.csdnimg.cn/485dba8af63d4f1da3bc430c88497283.png)






