大数据基础平台搭建-(五)Hive搭建
大数据平台系列文章:
1、大数据基础平台搭建-(一)基础环境准备
2、大数据基础平台搭建-(二)Hadoop集群搭建
3、大数据基础平台搭建-(三)Hadoop集群HA+Zookeeper搭建
4、大数据基础平台搭建-(四)HBase集群HA+Zookeeper搭建
5、大数据基础平台搭建-(五)Hive搭建
目录
- 大数据基础平台搭建-(五)Hive搭建
- 一、部署架构
- 二、Hadoop集群各节点分布情况
- 三、Hive搭建前准备
- 1、Hadoop集群搭建完成
- 2、Zookeeper集群搭建完成
- 3、HBase集群搭建完成
- 4、mysql数据库
- 5、各组件版本说明
- 四、Hive搭建
- 1、在hnode5上部署Hive
- 1).解压安装包
- 2).配置环境变量
- 3).为Hive元数据创建数据库
- 4).为Hive添加mysql数据库驱动
- 5).修改hive的环境变量
- 6).修改hive-size.xml
- 7).初始化元数据配置表
- 五、Hive服务启动
- 1、启动metastore服务
- 2、启动hiveserver2服务
- 3、以root用户通过beeline连接hive
一、部署架构
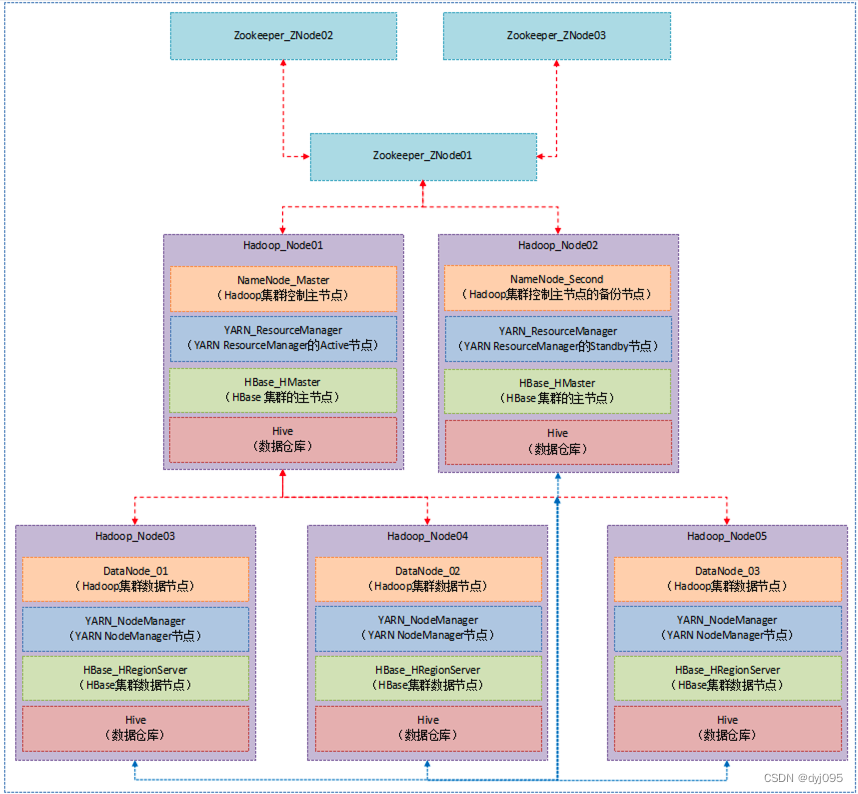
二、Hadoop集群各节点分布情况
| 序号 | 服务节点 | NameNode节点 | Zookeeper节点 | HMaster节点 | HRegionServer节点 | Hive节点 |
|---|---|---|---|---|---|---|
| 1 | hNode1 | √ (主) | √ | √ (主) | - | - |
| 2 | hNode2 | √ (备) | √ | √ (备) | - | - |
| 3 | hNode3 | - | √ | - | √ | - |
| 4 | hNode4 | - | - | - | √ | - |
| 5 | hNode5 | - | - | - | √ | √ |
三、Hive搭建前准备
1、Hadoop集群搭建完成
参见大数据基础平台搭建-(三)Hadoop集群HA+Zookeeper搭建
2、Zookeeper集群搭建完成
参见大数据基础平台搭建-(三)Hadoop集群HA+Zookeeper搭建中的**【三、搭建Zookeeper集群】**部分
3、HBase集群搭建完成
参见大数据基础平台搭建-(四)HBase集群HA+Zookeeper搭建
4、mysql数据库
用于存储Hive元数据信息,mysql服务的安装就不在文章中体现了,大家可以配置一个已经安装的mysql数据库即可。
5、各组件版本说明
| 序号 | 软件名称 | 版本 | 说明 |
|---|---|---|---|
| 1 | JDK | 1.8 | |
| 2 | Hadoop | 3.3.4 | |
| 3 | HBase | 3.8.0 | 列式数据库 |
| 4 | Zookeeper | 2.4.15 | |
| 5 | Hive | 3.1.3 | Hadoop数据仓库工具 |
| 6 | mysql | 5.7.39 | Hadoop数据仓库工具 |
四、Hive搭建
1、在hnode5上部署Hive
1).解压安装包
[root@hnode1 ~]# cd /opt/hadoop
[root@hnode5 hadoop]# tar -xzvf ./apache-hive-3.1.3-bin.tar.gz
2).配置环境变量
[root@hnode1 hadoop]# vim /etc/profile
#Hive
export HIVE_HOME=/opt/hadoop/apache-hive-3.1.3-bin
export PATH=$HIVE_HOME/bin:$PATH
[root@hnode1 hadoop]# source /etc/profile
3).为Hive元数据创建数据库
[root@dbserver opt]# mysql -uroot -p
mysql> create database hiveDB_metastore charset=utf8;
4).为Hive添加mysql数据库驱动
将mysql-connector-java-5.1.12-bin.jar(mysql驱动jar)上传到/opt/hadoop/apache-hive-3.1.3-bin/lib/目录下
5).修改hive的环境变量
[root@hnode1 hadoop]# cd /opt/hadoop/apache-hive-3.1.3-bin/conf
[root@hnode5 conf]# cp ./hive-env.sh.template ./hive-env.sh
[root@hnode5 conf]# vim hive-env.sh
export HIVE_CONF_DIR=/opt/hadoop/apache-hive-3.1.3-bin/conf
export JAVA_HOME=/usr/java/jdk1.8.0_271
export HADOOP_HOME=/opt/hadoop/hadoop-3.3.4
export HIVE_AUX_JARS_PATH=/opt/hadoop/apache-hive-3.1.3-bin/lib
6).修改hive-size.xml
[root@hnode5 conf]# cp ./hive-default.xml.template ./hive-site.xml
[root@hnode5 conf]# vim ./hive-site.xml
#把hive-site.xml 中所有包含 ${system:java.io.tmpdir}替换成/opt/hadoop/apache-hive-3.1.3-bin/iotmp.
:%s#${system:java.io.tmpdir}#/opt/hadoop/apache-hive-3.1.3-bin/iotmp#g
#如果系统默认没有指定系统用户名,那么要把配置${system:user.name}替换成当前用户名root
:%s/${system:user.name}/root/g
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.2.186:3306/hiveDB_metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
</property>
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hnode5:9083</value>
</property>
<!-- 使用 JDBC 方式访问 Hive; 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hnode5</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
7).初始化元数据配置表
[root@hnode5 conf]# schematool -initSchema -dbType mysql -verbose
五、Hive服务启动
1、启动metastore服务
# 方式一 以后台模式运行
[root@hnode5 conf]# hive --service metastore &
# 方式二 输出信息指向黑洞
[root@hnode5 conf]# hive --service metastore 2>&1 >/dev/null &
2、启动hiveserver2服务
# 方式一 以后台模式运行
[root@hnode5 conf]# hive --service hiveserver2 &
# 方式二 输出信息指向黑洞
[root@hnode5 conf]# hive --service hiveserver2 >/dev/null 2>&1 &
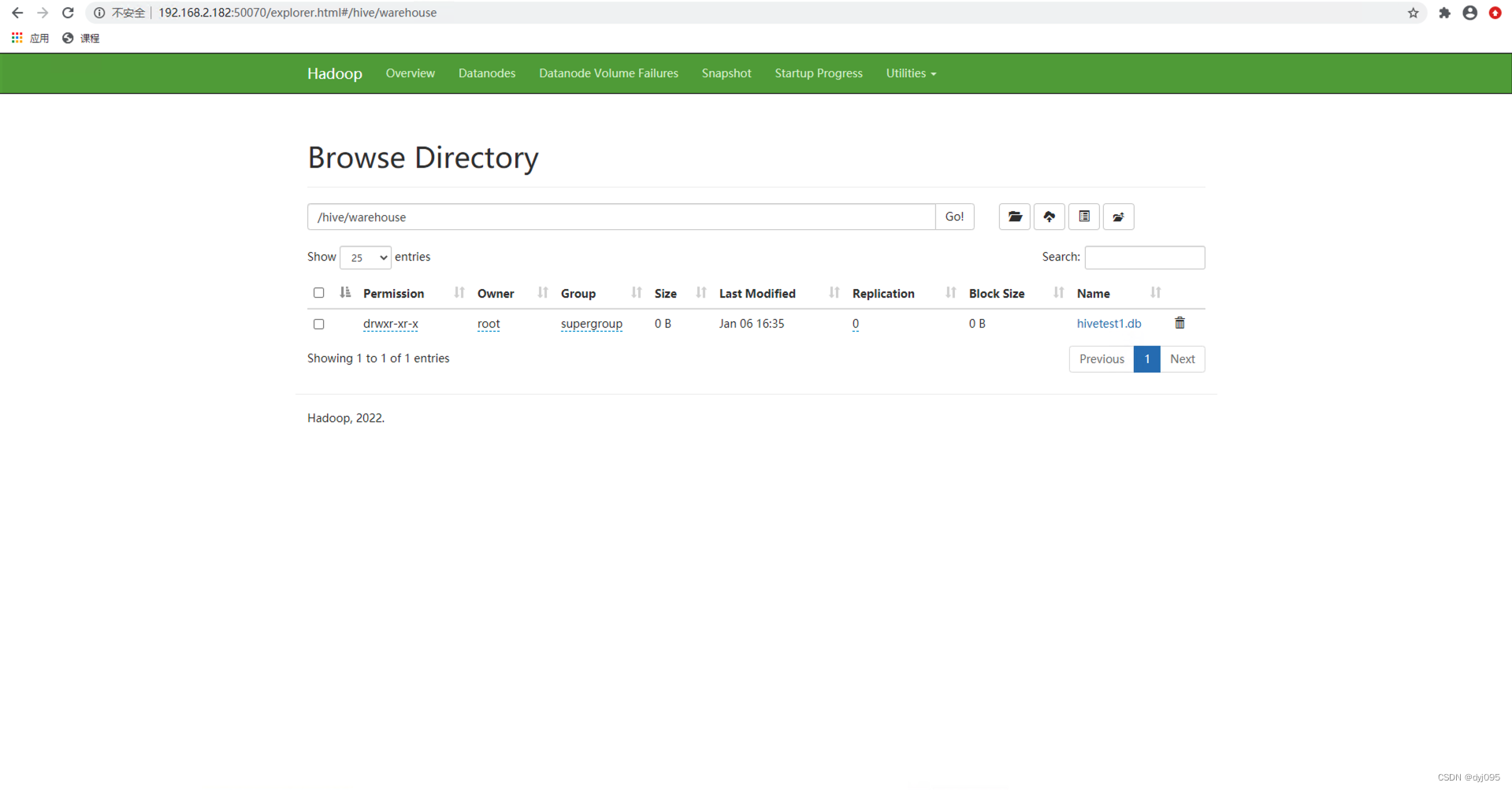
3、以root用户通过beeline连接hive
# 在HDFS上创建Hive目录/hive/warehouse,并赋予777权限
[root@hnode1 opt]# hdfs dfs -mkdir -p /hive/warehouse
[root@hnode1 opt]# hadoop fs -chmod -R 777 /hive
[root@hnode1 opt]# hadoop fs -chmod -R 777 /hive/warehouse
# 设置hadoop代理用户
[root@hnode1 opt]# vim /opt/hadoop/hadoop-3.3.4/etc/hadoop/core-site.xml
<property>
<!-- 注意是root,根据自己实际部署hadoop的用户的组来进行设置 -->
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
将core-size.xml分发给其它所有hadoop节点,然后重启hadoop集群和Hive服务
[root@hnode5 opt]# beeline
beeline> !connect jdbc:hive2://hnode5:10000
Connecting to jdbc:hive2://hnode5:10000
Enter username for jdbc:hive2://hnode5:10000: root
Enter password for jdbc:hive2://hnode5:10000: ******
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hnode5:10000> create database hivetest1;
0: jdbc:hive2://hnode5:10000> show databases;
OK
INFO : Compiling command(queryId=root_20230106163527_be98a4b0-c479-43e1-bef8-8ef1b7ebff5c): show databases
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=root_20230106163527_be98a4b0-c479-43e1-bef8-8ef1b7ebff5c); Time taken: 0.042 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230106163527_be98a4b0-c479-43e1-bef8-8ef1b7ebff5c): show databases
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20230106163527_be98a4b0-c479-43e1-bef8-8ef1b7ebff5c); Time taken: 0.015 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+
| database_name |
+----------------+
| default |
| hivetest1 |
+----------------+
2 rows selected (0.089 seconds)
0: jdbc:hive2://hnode5:10000>