🌞欢迎来到PyTorch 的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
📆首发时间:🌹2024年2月14日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录
前言
Tensor的创建
torch.tensor()-- torch.tensor([])
torch.randn-- torch.randperm
torch.range(begin,end,step)
指定numpy
Tensor运算
A.add() --A.add_()
torch.stack
CUDA
自动求导
backward求导
autograd.grad求导
求最小值
数据
Dataset and DataLoader
DataLoader的参数如下:
Pytorch工具
Variable(变量)
Variable 计算, 梯度
神经网络工具箱torch.nn
nn.Module类
搭建简易神经网络
torch实现一个完整的神经网络
torch.autograd
自定义传播函数
torch.nn.Sequential
torch.nn.Linear
torch.nn.ReLU
torch.nn.MSELoss
使用损失函数的神经网络
torch.optim
前言
Torch 自称为神经网络界的 Numpy, 因为他能将 torch 产生的 tensor 放在 GPU 中加速运算 (前提是你有合适的 GPU), 就像 Numpy 会把 array 放在 CPU 中加速运算. 所以神经网络的话, 当然是用 Torch 的 tensor 形式数据最好咯. 就像 Tensorflow 当中的 tensor 一样. numpy array 和 torch tensor 是可以自由地转换的。
import torch import numpy as np np_data = np.arange(6).reshape((2, 3)) torch_data = torch.from_numpy(np_data) tensor2array = torch_data.numpy() print('\nnumpy array:', np_data) print('\ntorch tensor:', torch_data) print('\ntensor to array:', tensor2array)
Tensor的创建
torch.tensor()-- torch.tensor([])
二者的主要区别在于创建的对象的size和value不同
x=torch.Tensor(2,3) print("dim:",x.dim()) print("size:",x.size()) print('------------') y=torch.Tensor([2,3]) print("dim:",y.dim()) print("size:",y.size())
torch.randn-- torch.randperm
生成的数据类型为浮点型,与numpy.randn生成随机数的方法类似,生成的浮点数的取值满足均值为0,方差为1的正态分布。torch.randperm(n)为创建一个n个整数,随机排列的Tensor。
x = torch.randn(3,4,requires_grad=True) #requires_grad=True表示需要求导 print("x:",x) y = torch.randperm(3) print('------------') print("y:",y)
torch.range(begin,end,step)
生成一个一维的Tensor,三个参数分别的起始位置,终止位置和步长
torch.range(1,10,2) #结果 tensor([1., 3., 5., 7., 9.])指定numpy
很多时候我们需要创建指定的Tensor,而numpy就是一个很好的方式
torch.Tensor(np.arange(6).reshape((2, 3))) #结果 tensor([[0., 1., 2.], [3., 4., 5.]])
Tensor运算
常见的运算 函数 作用 torch.abs(A) 绝对值 torch.add(A,B) 相加,A和B既可以是Tensor也可以是标量 torch.clamp(A,max,min) 裁剪,A中的数据若小于min或大于max,则变成min或max,
即保证范围在[min,max]
torch.div(A,B) 相除,A%B,A和B既可以是Tensor也可以是标量 torch.mul(A,B) 点乘,A*B,A和B既可以是Tensor也可以是标量 torch.pow(A,n) 求幂,A的n次方 torch.mm(A,B.T) 矩阵叉乘,注意与torch.mul之间的区别 torch.mv(A,B) 矩阵与向量相乘,A是矩阵,B是向量,
这里的B需不需要转置都是可以的
A.item() 将Tensor转化为基本数据类型,
注意Tensor中只有一个元素的时候才可以使用,
一般用于在Tensor中取出数值
A.numpy() 将Tensor转化为Numpy类型 A.size() 查看尺寸 A.shape 查看尺寸 A.dtype 查看数据类型 A.view() 重构张量尺寸,类似于Numpy中的reshape A.transpose(0,1) 行列交换 A[1:],A[-1,-1]=100 切面,类似Numpy中的切面 A.zero_() 归零化 torch.stack((A,B),sim=-1) 拼接,升维 torch.diag(A) 取A对角线元素形成一个一维向量 torch.diag_embed(A) 将一维向量放到对角线中,其余数值为0的Tensor A.add() --A.add_()
所有的带_符号的函数都会对原数据进行修改
import torch a = torch.zeros(2,3) a.add(1) print(a) print('------------') a.add_(1) print(a)
torch.stack
stack为拼接函数,函数的第一个参数为需要拼接的Tensor,第二个参数为细分到哪个维度。
A=torch.IntTensor([[1,2,3],[4,5,6]]) B=torch.IntTensor([[7,8,9],[10,11,12]]) C1=torch.stack((A,B),dim=0) # or C1=torch.stack((A,B)) C2=torch.stack((A,B),dim=1) C3=torch.stack((A,B),dim=2) C4=torch.stack((A,B),dim=-1) print(C1,C2,C3,C4)
dim=0,C1 = [ A,B ]
dim=1,C2 = [ [ A[0],B[0] ] , [ A[1],B[1] ] ]
dim=2,C3 = [ [ [ A[0][0],B[0][0] ] , [ A[0][1],B[0][1] ] , [ A[0][2],B[0][2] ] ],
[ [ A[1][0],B[1][0] ] , [ A[1][1],B[1][1] ] , [ A[1][2],B[1][2] ] ] ]
dim=-1,C4 = C3
CUDA
CUDA是一种操作GPU的软件架构,Pytorch配合GPU环境这样模型的训练速度会非常的快。
import torch # 测试GPU环境是否可使用 print(torch.__version__) # pytorch版本 print(torch.version.cuda) # cuda版本 print(torch.cuda.is_available()) # 查看cuda是否可用 #使用GPU or CPU device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 判断某个对象是在什么环境中运行的 a.device # 将对象的环境设置为device环境 A = A.to(device) # 将对象环境设置为COU A.cpu().device # 若一个没有环境的对象与另外一个有环境a对象进行交流,则环境全变成环境a a+b.to(device) # cuda环境下tensor不能直接转化为numpy类型,必须要先转化到cpu环境中 a.cpu().numpy() # 创建CUDA型的tensor torch.tensor([1,2],device)
自动求导
我们为什么要用到这些框架鸭,直接用python写代码不香嘛?难度最大的地方就是反向传播了,反向传播中需要逐层求导(w),并且这个w是一个矩阵。框架比较好的就是自动计算反向传播的求导操作。
神经网络依赖反向传播求梯度来更新网络的参数,求梯度是个非常复杂的过程,在Pytorch中,提供了两种求梯度的方式,一个是backward,将求得的结果保存在自变量的grad属性中,另外一种方式是torch.autograd.grad。
backward求导
使用backward进行求导。这里主要介绍了求导的两种对象,标量Tensor和非标量Tensor的求导。两者的主要区别是非标量Tensor求导的主要区别是加了一个gradient的Tensor,其尺寸与自变量X的尺寸一致。在求完导后,需要与gradient进行点积,所以只是一般的求导的话,设置的参数全部为1。
import numpy as np import torch # 标量Tensor求导 # 求 f(x) = a*x**2 + b*x + c 的导数 x = torch.tensor(-2.0, requires_grad=True) a = torch.tensor(1.0) b = torch.tensor(2.0) c = torch.tensor(3.0) y = a*torch.pow(x,2)+b*x+c y.backward() # backward求得的梯度会存储在自变量x的grad属性中 dy_dx =x.grad dy_dx
# 非标量Tensor求导 # 求 f(x) = a*x**2 + b*x + c 的导数 x = torch.tensor([[-2.0,-1.0],[0.0,1.0]], requires_grad=True) a = torch.tensor(1.0) b = torch.tensor(2.0) c = torch.tensor(3.0) gradient=torch.tensor([[1.0,1.0],[1.0,1.0]]) y = a*torch.pow(x,2)+b*x+c y.backward(gradient=gradient) dy_dx =x.grad dy_dx
autograd.grad求导
import torch #单个自变量求导 # 求 f(x) = a*x**4 + b*x + c 的导数 x = torch.tensor(1.0, requires_grad=True) a = torch.tensor(1.0) b = torch.tensor(2.0) c = torch.tensor(3.0) y = a * torch.pow(x, 4) + b * x + c #create_graph设置为True,允许创建更高阶级的导数 #求一阶导 dy_dx = torch.autograd.grad(y, x, create_graph=True)[0] #求二阶导 dy2_dx2 = torch.autograd.grad(dy_dx, x, create_graph=True)[0] #求三阶导 dy3_dx3 = torch.autograd.grad(dy2_dx2, x)[0] print(dy_dx.data, dy2_dx2.data, dy3_dx3)
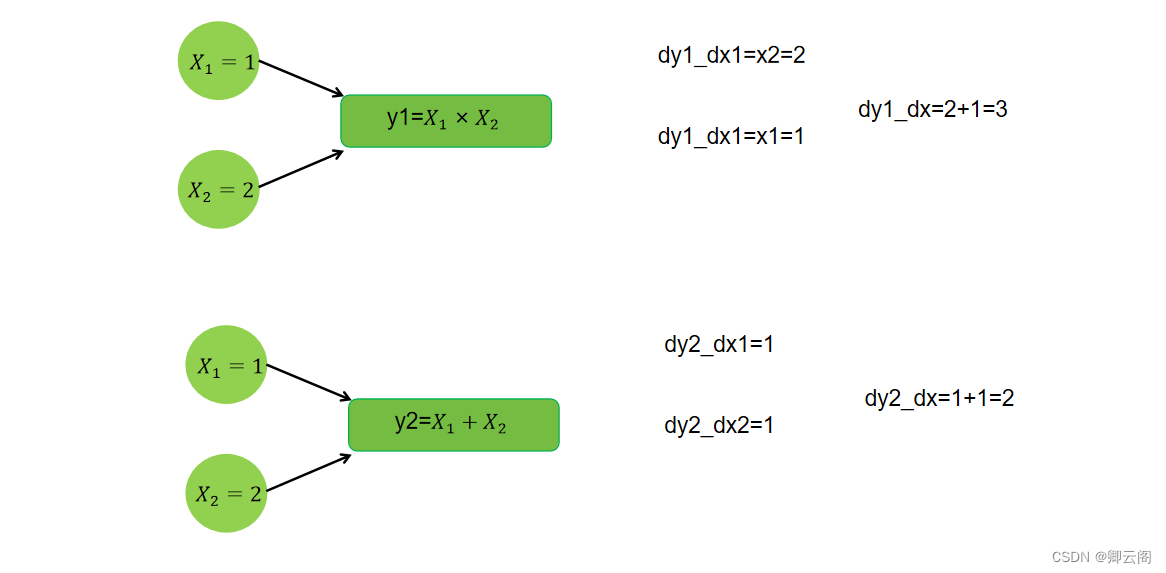
# 多个自变量求偏导 x1 = torch.tensor(1.0, requires_grad=True) x2 = torch.tensor(2.0, requires_grad=True) y1 = x1 * x2 y2 = x1 + x2 #只有一个因变量,正常求偏导 dy1_dx1, dy1_dx2 = torch.autograd.grad(outputs=y1, inputs=[x1, x2], retain_graph=True) print(dy1_dx1, dy1_dx2) # 若有多个因变量,则对于每个因变量,会将求偏导的结果加起来 dy1_dx, dy2_dx = torch.autograd.grad(outputs=[y1, y2], inputs=[x1, x2]) dy1_dx, dy2_dx print(dy1_dx, dy2_dx)
求最小值
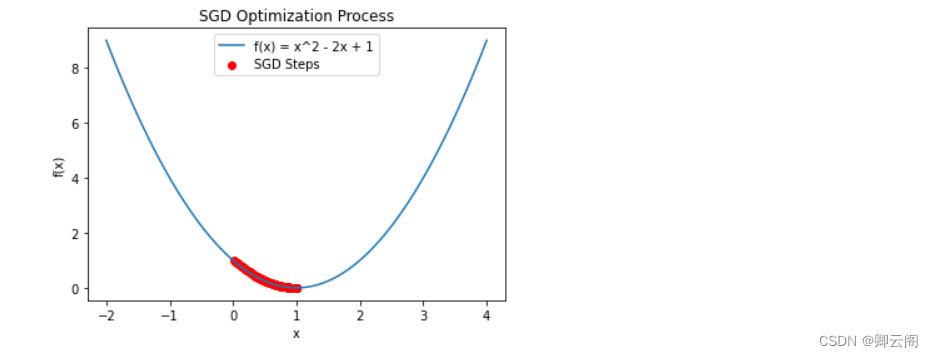
使用自动微分机制配套使用SGD随机梯度下降来求最小值
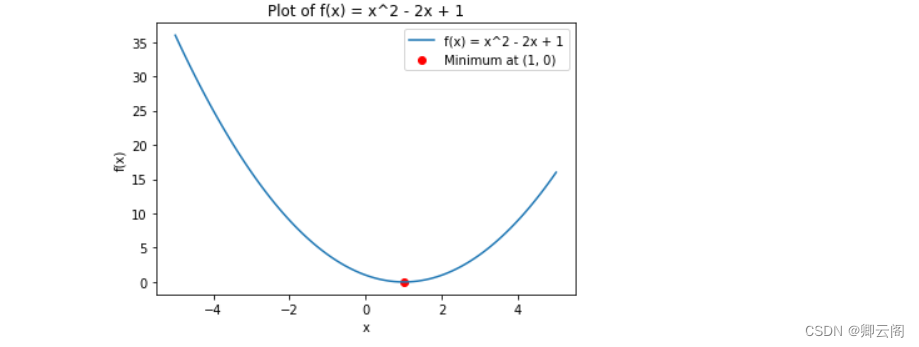
#例2-1-3 利用自动微分和优化器求最小值 import numpy as np import torch # f(x) = a*x**2 + b*x + c的最小值 x = torch.tensor(0.0, requires_grad=True) # x需要被求导 a = torch.tensor(1.0) b = torch.tensor(-2.0) c = torch.tensor(1.0) optimizer = torch.optim.SGD(params=[x], lr=0.01) #SGD为随机梯度下降 print(optimizer) def f(x): result = a * torch.pow(x, 2) + b * x + c return (result) for i in range(500): optimizer.zero_grad() #将模型的参数初始化为0 y = f(x) y.backward() #反向传播计算梯度 optimizer.step() #更新所有的参数 print("y=", y.data, ";", "x=", x.data)
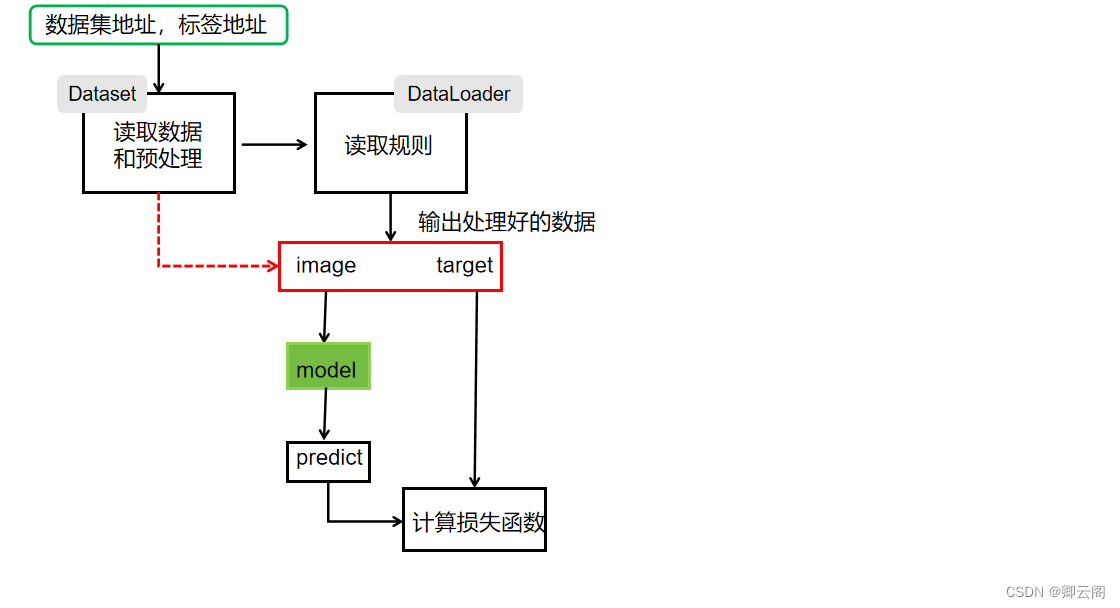
数据
Pytorch主要通过Dataset和DataLoader进行构建数据管道。
Dataset and DataLoader
Dataset 一个数据集抽象类,所有自定义的Dataset都需要继承它,并且重写__getitem__()或__get_sample__()这个类方法 DataLoader 一个可迭代的数据装载器。在训练的时候,每一个for循环迭代,就从DataLoader中获取一个batch_sieze大小的数据。 手动实现简单的Dataset and DataLoader
AI训练时的需求
- 有一个数据集文件夹,里面有100w的样本和标签
- 训练时,通常希望,一次在100w里随机抓取batch个样本,拿去训练
- 如果抓取完毕,则希望重新打乱后,再来一次
dataset,数据集
作用:存储数据集的信息 self.xxx
获取数据集的长度 _ _len_ _
获取数据集某特定条目的内容 _ _getitem_ _
class ImageDataset: def __init__(self,raw_data) self.raw_data = raw_data def __len__(self) return len( self.raw_data) def __getitem__(self,index) image,lable = self.raw_data[index] return image,lable image = [[f"image{i}",i] for i in range(100)] print(image)
dataloader,数据加载器
作用:从数据集随机加载数据,并拼接成一个batch
实现迭代器,可以让使用时,迭代获取数据内容
class DataLoader: def __init__(self, dataset, batch_size): self.dataset = dataset self.batch_size = batch_size def __iter__(self): self.indexs = np.arange(len(self.dataset)) self.cursor = 0 np.random.shuffle(self.indexs) return self def __next__(self): begin = self.cursor end = self.cursor + self.batch_size if end > len(self.dataset): raise StopIteration() self.cursor = end batched_data = [] for index in self.indexs[begin:end]: item = self.dataset[index] batched_data.append(item) return batched_data完整代码:
import numpy as np class ImageDataset: def __init__(self, raw_data): self.raw_data = raw_data def __len__(self): return len(self.raw_data) def __getitem__(self, index): image, label = self.raw_data[index] return image, label class DataLoader: def __init__(self, dataset, batch_size): self.dataset = dataset self.batch_size = batch_size def __iter__(self): self.indexs = np.arange(len(self.dataset)) self.cursor = 0 np.random.shuffle(self.indexs) return self def __next__(self): begin = self.cursor end = self.cursor + self.batch_size if end > len(self.dataset): raise StopIteration() self.cursor = end batched_data = [] for index in self.indexs[begin:end]: item = self.dataset[index] batched_data.append(item) return batched_data # Example usage images = [(f"image{i}", i) for i in range(100)] dataset = ImageDataset(images) loader = DataLoader(dataset, 5) for index, batched_data in enumerate(loader): print(f"Batch {index + 1}:", batched_data)
一图胜千言:
DataLoader的参数如下:
DataLoader( dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, )dataset 数据集,决定数据从哪里读取,以及如何读取
batch_size 批次大小,默认为1
shuffle 每个epoch是否乱序
sampler 样本采样函数,一般无需设置
batch_sampler 批次采样函数,一般无需设置
num_workers 使用多进程读取数据,设置的进程数
collate_fn 整理一个批次数据的函数
Epoch 所有的样本数据都输入到模型中,称为一个epoch Iteration 一个Batch的样本输入到模型中,称为一个Iteration Batchsize 一个批次的大小,一个Epoch=Batchsize*Iteration Pytorch工具
torchvision 图像视频处理 torchaudio 音频处理 torchtext 自然语言处理 Variable(变量)
在 Torch 中的 Variable 就是一个存放会变化的值的地理位置. 里面的值会不停的变化. 就像一个装鸡蛋的篮子, 鸡蛋数会不停变动. 那谁是里面的鸡蛋呢, 自然就是 Torch 的 Tensor 咯. 如果用一个 Variable 进行计算, 那返回的也是一个同类型的 Variable。
import torch from torch.autograd import Variable # torch 中 Variable 模块 # 先生鸡蛋 tensor = torch.FloatTensor([[1,2],[3,4]]) # 把鸡蛋放到篮子里, requires_grad是参不参与误差反向传播, 要不要计算梯度 variable = Variable(tensor, requires_grad=True) print(tensor) print("----------------------------------") print(variable)
Variable 计算, 梯度
我们再对比一下 tensor 的计算和 variable 的计算.
t_out = torch.mean(tensor*tensor) # x^2 v_out = torch.mean(variable*variable) # x^2 print(t_out) print(v_out) # 7.5v_out.backward() # 模拟 v_out 的误差反向传递 # 下面两步看不懂没关系, 只要知道 Variable 是计算图的一部分, 可以用来传递误差就好. # v_out = 1/4 * sum(variable*variable) 这是计算图中的 v_out 计算步骤 # 针对于 v_out 的梯度就是, d(v_out)/d(variable) = 1/4*2*variable = variable/2 print(variable.grad) # 初始 Variable 的梯度 ''' 0.5000 1.0000 1.5000 2.0000 '''直接
print(variable)只会输出 Variable 形式的数据, 在很多时候是用不了的(比如想要用 plt 画图), 所以我们要转换一下, 将它变成 tensor 形式。print(variable) # Variable 形式 """ Variable containing: 1 2 3 4 [torch.FloatTensor of size 2x2] """ print(variable.data) # tensor 形式 """ 1 2 3 4 [torch.FloatTensor of size 2x2] """ print(variable.data.numpy()) # numpy 形式 """ [[ 1. 2.] [ 3. 4.]] """
神经网络工具箱torch.nn
torch.autograd库虽然实现了自动求导与梯度反向传播,但如果我们要完成一个模型的训练,仍需要手写参数的自动更新、训练过程的控制等,还是不够便利。为此,PyTorch进一步提供了集成度更高的模块化接口torch.nn,该接口构建于Autograd之上,提供了网络模组、优化器和初始化策略等一系列功能。
nn.Module类
nn.Module是PyTorch提供的神经网络类,并在类中实现了网络各层的定义及前向计算与反向传播机制。在实际使用时,如果想要实现某个神经网络,只需继承nn.Module,在初始化中定义模型结构与参数,在函数forward()中编写网络前向过程即可。
#这里用torch.nn实现一个MLP from torch import nn class MLP(nn.Module): def __init__(self, in_dim, hid_dim1, hid_dim2, out_dim): super(MLP, self).__init__() self.layer = nn.Sequential( nn.Linear(in_dim, hid_dim1), nn.ReLU(), nn.Linear(hid_dim1, hid_dim2), nn.ReLU(), nn.Linear(hid_dim2, out_dim), nn.ReLU() ) def forward(self, x): x = self.layer(x) return x搭建简易神经网络
下面我们用torch搭一个简易神经网络:
1、我们设置输入节点为1000,隐藏层的节点为100,输出层的节点为10。
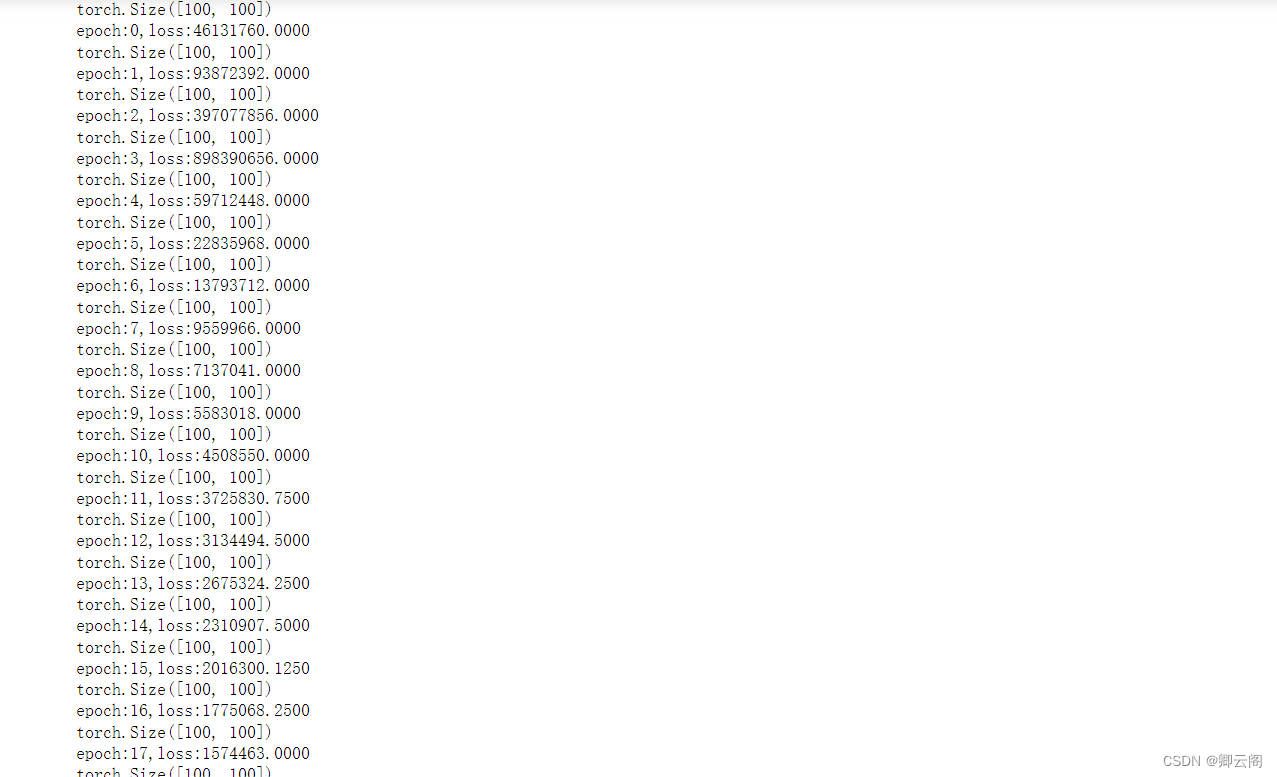
2、输入100个具有1000个特征的数据,经过隐藏层后变成100个具有10个分类结果的特征,然后将得到的结果后向传播。import torch batch_n = 100 # 一个批次输入数据的数量 hidden_layer = 100 input_data = 1000 # 每个数据的特征为1000 output_data = 10 # 生成输入数据 x 和标签数据 y x = torch.randn(batch_n, input_data) # 生成随机输入数据,形状为 (batch_n, input_data) y = torch.randn(batch_n, output_data) # 生成随机标签数据,形状为 (batch_n, output_data) # 初始化权重参数 w1 和 w2 w1 = torch.randn(input_data, hidden_layer) # 输入层到隐藏层的权重,形状为 (input_data, hidden_layer) w2 = torch.randn(hidden_layer, output_data) # 隐藏层到输出层的权重,形状为 (hidden_layer, output_data) epoch_n = 20 # 训练的总轮次 lr = 1e-6 # 学习率 # 训练过程 for epoch in range(epoch_n): # 前向传播 h1 = x.mm(w1) # 矩阵乘法,得到隐藏层的输出,形状为 (batch_n, hidden_layer) h1 = h1.clamp(min=0) # 非线性激活函数,ReLU y_pred = h1.mm(w2) # 矩阵乘法,得到网络的输出,形状为 (batch_n, output_data) # 计算损失 loss = (y_pred - y).pow(2).sum() # 平方损失,即预测值与实际值之间的差异的平方和 print("epoch: {}, loss: {:.4f}".format(epoch, loss.item())) # 打印当前轮次和损失 # 反向传播 grad_y_pred = 2 * (y_pred - y) # 损失关于预测值的梯度 grad_w2 = h1.t().mm(grad_y_pred) # 隐藏层到输出层权重的梯度 grad_h = grad_y_pred.clone() grad_h = grad_h.mm(w2.t()) # 输出层到隐藏层的梯度 grad_h.clamp_(min=0) # 非线性激活函数的梯度,ReLU grad_w1 = x.t().mm(grad_h) # 输入层到隐藏层权重的梯度 # 更新权重 w1 = w1 - lr * grad_w1 # 使用梯度下降更新输入层到隐藏层权重 w2 = w2 - lr * grad_w2 # 使用梯度下降更新隐藏层到输出层权重
torch实现一个完整的神经网络
torch.autograd
import torch from torch.autograd import Variable batch_n = 100#一个批次输入数据的数量 hidden_layer = 100 input_data = 1000#每个数据的特征为1000 output_data = 10 x = Variable(torch.randn(batch_n,input_data),requires_grad=False) y = Variable(torch.randn(batch_n,output_data),requires_grad=False) #用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是False,表示该变量在进行自动梯度计算的过程中不会保留梯度值。 w1 = Variable(torch.randn(input_data,hidden_layer),requires_grad=True) w2 = Variable(torch.randn(hidden_layer,output_data),requires_grad=True) #学习率和迭代次数 epoch_n=50 lr=1e-6 for epoch in range(epoch_n): h1=x.mm(w1)#(100,1000)*(1000,100)-->100*100 print(h1.shape) h1=h1.clamp(min=0) y_pred = h1.mm(w2) loss = (y_pred-y).pow(2).sum() print("epoch:{},loss:{:.4f}".format(epoch,loss.data)) loss.backward()#后向传播 w1.data -= lr*w1.grad.data w2.data -= lr*w2.grad.data w1.grad.data.zero_() w2.grad.data.zero_()
自定义传播函数
其实除了可以采用自动梯度方法,我们还可以通过构建一个继承了torch.nn.Module的新类,来完成对前向传播函数和后向传播函数的重写。在这个新类中,我们使用forward作为前向传播函数的关键字,使用backward作为后向传播函数的关键字。下面我们进行自定义传播函数:
import torch from torch.autograd import Variable batch_n = 64#一个批次输入数据的数量 hidden_layer = 100 input_data = 1000#每个数据的特征为1000 output_data = 10 class Model(torch.nn.Module):#完成类继承的操作 def __init__(self): super(Model,self).__init__()#类的初始化 def forward(self,input,w1,w2): x = torch.mm(input,w1) x = torch.clamp(x,min = 0) x = torch.mm(x,w2) return x def backward(self): pass model = Model() x = Variable(torch.randn(batch_n,input_data),requires_grad=False) y = Variable(torch.randn(batch_n,output_data),requires_grad=False) #用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是F,表示该变量在进行自动梯度计算的过程中不会保留梯度值。 w1 = Variable(torch.randn(input_data,hidden_layer),requires_grad=True) w2 = Variable(torch.randn(hidden_layer,output_data),requires_grad=True) epoch_n=30 for epoch in range(epoch_n): y_pred = model(x,w1,w2) loss = (y_pred-y).pow(2).sum() print("epoch:{},loss:{:.4f}".format(epoch,loss.data)) loss.backward() w1.data -= lr*w1.grad.data w2.data -= lr*w2.grad.data w1.grad.data.zero_() w2.grad.data.zero_()torch.nn.Sequential
torch.nn.Sequential类是torch.nn中的一种序列容器,通过在容器中嵌套各种实现神经网络模型的搭建,最主要的是,参数会按照我们定义好的序列自动传递下去。
import torch from torch.autograd import Variable batch_n = 100#一个批次输入数据的数量 hidden_layer = 100 input_data = 1000#每个数据的特征为1000 output_data = 10 x = Variable(torch.randn(batch_n,input_data),requires_grad=False) y = Variable(torch.randn(batch_n,output_data),requires_grad=False) #用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是F,表示该变量在进行自动梯度计算的过程中不会保留梯度值。 models = torch.nn.Sequential( torch.nn.Linear(input_data,hidden_layer), torch.nn.ReLU(), torch.nn.Linear(hidden_layer,output_data) ) #torch.nn.Sequential括号内就是我们搭建的神经网络模型的具体结构,Linear完成从隐藏层到输出层的线性变换,再用ReLU激活函数激活 #torch.nn.Sequential类是torch.nn中的一种序列容器,通过在容器中嵌套各种实现神经网络模型的搭建, #最主要的是,参数会按照我们定义好的序列自动传递下去。torch.nn.Linear
torch.nn.Linear类用于定义模型的线性层,即完成前面提到的不同的层之间的线性变换。 线性层接受的参数有3个:分别是输入特征数、输出特征数、是否使用偏置,默认为True,使用torch.nn.Linear类,会自动生成对应维度的权重参数和偏置,对于生成的权重参数和偏置,我们的模型默认使用一种比之前的简单随机方式更好的参数初始化方式。
torch.nn.ReLU
torch.nn.ReLU属于非线性激活分类,在定义时默认不需要传入参数。当然,在torch.nn包中还有许多非线性激活函数类可供选择,比如PReLU、LeaKyReLU、Tanh、Sigmoid、Softmax等。
torch.nn.MSELoss
torch.nn.MSELoss类使用均方误差函数对损失值进行计算,定义类的对象时不用传入任何参数,但在使用实例时需要输入两个维度一样的参数方可进行计算。
使用损失函数的神经网络
import torch from torch.autograd import Variable import torch from torch.autograd import Variable loss_fn = torch.nn.MSELoss() x = Variable(torch.randn(100,100)) y = Variable(torch.randn(100,100)) loss = loss_fn(x,y) batch_n = 100#一个批次输入数据的数量 hidden_layer = 100 input_data = 1000#每个数据的特征为1000 output_data = 10 x = Variable(torch.randn(batch_n,input_data),requires_grad=False) y = Variable(torch.randn(batch_n,output_data),requires_grad=False) #用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是F,表示该变量在进行自动梯度计算的过程中不会保留梯度值。 models = torch.nn.Sequential( torch.nn.Linear(input_data,hidden_layer), torch.nn.ReLU(), torch.nn.Linear(hidden_layer,output_data) ) #torch.nn.Sequential括号内就是我们搭建的神经网络模型的具体结构,Linear完成从隐藏层到输出层的线性变换,再用ReLU激活函数激活 #torch.nn.Sequential类是torch.nn中的一种序列容器,通过在容器中嵌套各种实现神经网络模型的搭建, #最主要的是,参数会按照我们定义好的序列自动传递下去。 for epoch in range(epoch_n): y_pred = models(x) loss = loss_fn(y_pred,y) if epoch%1000 == 0: print("epoch:{},loss:{:.4f}".format(epoch,loss.data)) models.zero_grad() loss.backward() for param in models.parameters(): param.data -= param.grad.data*lrtorch.optim
torch.optim包提供非常多的可实现参数自动优化的类,如SGD、AdaGrad、RMSProp、Adam等使用自动优化的类实现神经网络:
import torch from torch.autograd import Variable batch_n = 100#一个批次输入数据的数量 hidden_layer = 100 input_data = 1000#每个数据的特征为1000 output_data = 10 x = Variable(torch.randn(batch_n,input_data),requires_grad=False) y = Variable(torch.randn(batch_n,output_data),requires_grad=False) #用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是F,表示该变量在进行自动梯度计算的过程中不会保留梯度值。 models = torch.nn.Sequential( torch.nn.Linear(input_data,hidden_layer), torch.nn.ReLU(), torch.nn.Linear(hidden_layer,output_data) ) #torch.nn.Sequential括号内就是我们搭建的神经网络模型的具体结构,Linear完成从隐藏层到输出层的线性变换,再用ReLU激活函数激活 #torch.nn.Sequential类是torch.nn中的一种序列容器,通过在容器中嵌套各种实现神经网络模型的搭建, #最主要的是,参数会按照我们定义好的序列自动传递下去。 # loss_fn = torch.nn.MSELoss() # x = Variable(torch.randn(100,100)) # y = Variable(torch.randn(100,100)) # loss = loss_fn(x,y) epoch_n=10000 lr=1e-4 loss_fn = torch.nn.MSELoss() optimzer = torch.optim.Adam(models.parameters(),lr=lr) #使用torch.optim.Adam类作为我们模型参数的优化函数,这里输入的是:被优化的参数和学习率的初始值。 #因为我们需要优化的是模型中的全部参数,所以传递的参数是models.parameters() #进行,模型训练的代码如下: for epoch in range(epoch_n): y_pred = models(x) loss = loss_fn(y_pred,y) print("Epoch:{},Loss:{:.4f}".format(epoch,loss.data)) optimzer.zero_grad()#将模型参数的梯度归0 loss.backward() optimzer.step()#使用计算得到的梯度值对各个节点的参数进行梯度更新。
其它操作参考:API
参考文献:
【1】【Pytorch】2024 Pytorch基础入门教程(完整详细版)_pytorch教程-CSDN博客
【2】带你用pytorch搞深度学习!!!_狂干两万字带你用pytorch搞深度学习-CSDN
【3】变量 (Variable) | 莫烦Python (mofanpy.com)
【Pytorch】Pytorch基础入门教程
news2026/2/14 17:05:16

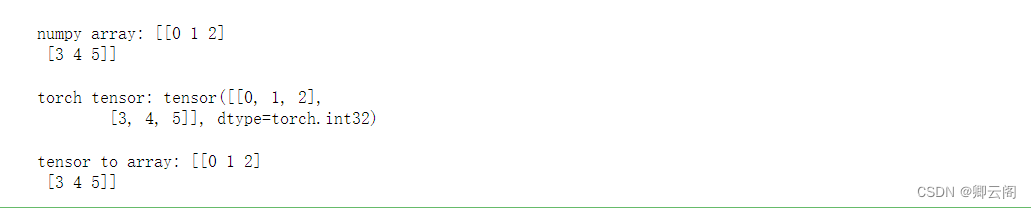













本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1447986.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

【JavaSE篇】——String的常用方法(全面知识覆盖)
目录 字符串常用方法 🎈字符串构造 🎈字符串长度(length) 🎈字符串是否为空(empty) 🎈String对象的比较 🌈比较是否引用同一个对象(boolean) 🌈boolean equals(Object anObject) 方法࿱…

文生图提示词:氛围营造
情感和氛围 --氛围营造 Atmospheric Creation 试图涵盖从温馨舒适到神秘莫测、从明亮活泼到阴暗沉郁的广泛氛围词汇,展示了在艺术创作和环境设计中可以营造的多样化氛围。 Cozy 温馨的 Intimate 亲密的 Inviting 邀请的 Warm 温暖的 Welcoming 欢迎的 Relaxing 放松…
用Python动态展示排序算法
文章目录 选择冒泡插入排序归并排序希尔排序 经常看到这种算法可视化的图片,但往往做不到和画图的人心灵相通,所以想自己画一下,本文主要实现归并排序和希尔排序,如果想实现其他算法可参考这篇 C语言实现各种排序算法[选择&#x…
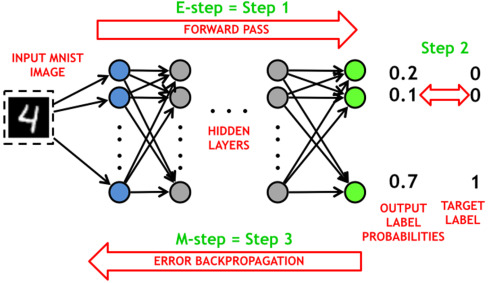
训练深度学习模型的过程
深度学习的训练过程是指通过大量的数据来调整神经网络的参数,以使其能够对输入数据进行准确的预测或分类.
训练神经网络的步骤
损失函数(Loss Function)是一个性能指标,反映神经网络生成接近期望值的值的程度。 损失函数直观上就…

软件实例分享,洗车店系统管理软件会员卡电子系统教程
软件实例分享,洗车店系统管理软件会员卡电子系统教程
一、前言
以下软件教程以 佳易王洗车店会员管理软件V16.0为例说明
软件文件下载可以点击最下方官网卡片——软件下载——试用版软件下载 1、会员卡号可以绑定车牌号或手机号
2、卡号也可以直接使用手机号&a…
cool Node后端 中实现中间件的书写
1.需求
在node后端中,想实现一个专门鉴权的文件配置,可以这样来解释 就是 有些接口需要token调用接口,有些接口不需要使用token 调用
这期来详细说明一下 什么是中间件中间件顾名思义是指在请求和响应中间,进行请求数据的拦截处理…
vivado 使用块综合策略
使用块综合策略
概述
AMD Vivado™合成具有许多策略和全局设置,您可以使用这些策略和设置自定义设计的合成方式。此图显示了可用的预定义策略在“合成设置”和“表:Vivado预配置策略”中提供了一个并排的战略设置的比较。您可以使用RTL或中的属性或XDC…

Bitcoin Bridge:治愈还是诅咒?
1. 引言
主要参考:
Bitcoin Bridges: Cure or Curse?
2. 为何需关注Bitcoin bridge?
当前的Bitcoin bridge,其所谓bridge,实际是deposit: 在其它链上的BTC情况为: 尽管当前约有43.7万枚BTC在其它链上…
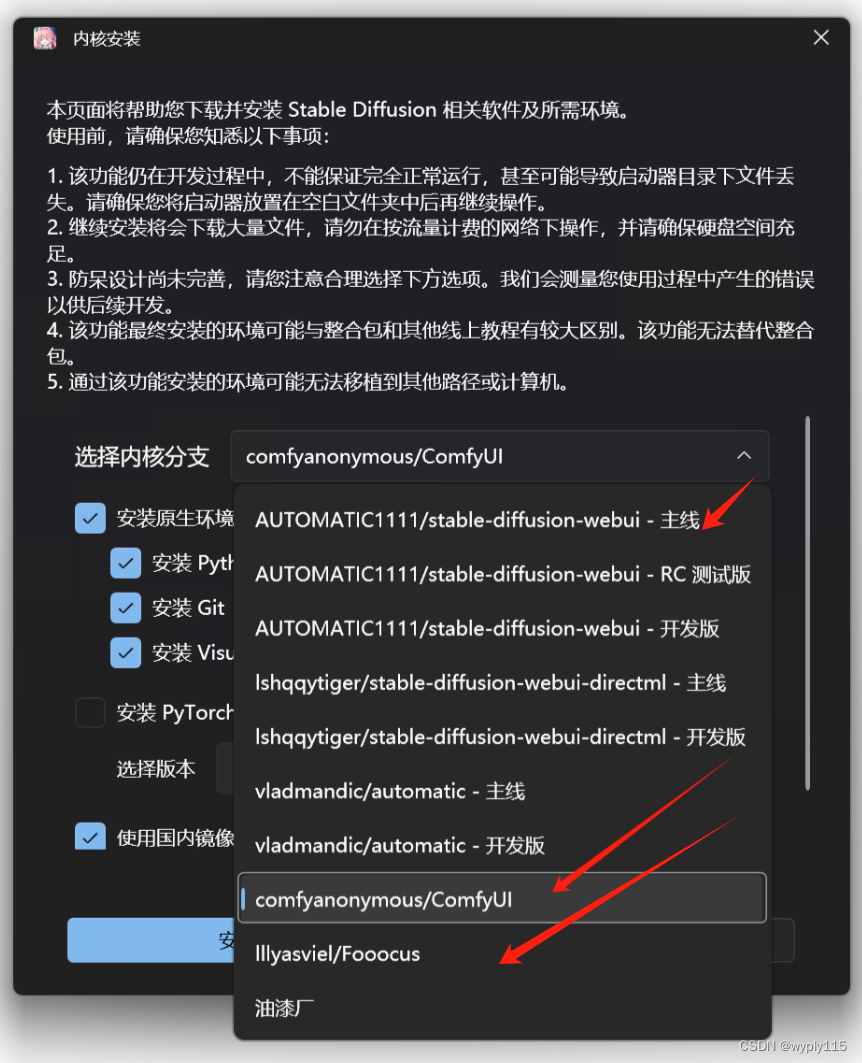
Stable Diffusion主流UI详细介绍
Stable Diffusion目前主流的操作界面有WebUI、ComfyUI以及Fooocus 这里webui和fooocus在人机交互上的逻辑是一样的,fooocus界面更加简洁。 comfyui是在人机交互上是采用流程节点的交互逻辑,和上面略有区别。
界面分别如下: WebUI界面如下 we…
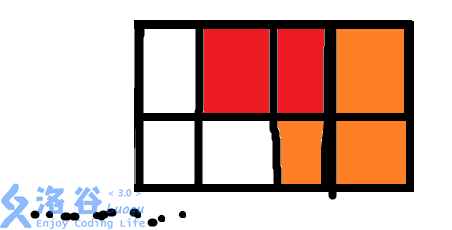
P1990 覆盖墙壁题解
题目
有一个长为N宽为2的墙壁,给你两种砖头:一个长2宽1,另一个是L型覆盖3个单元的砖头。如下图:
0 0
0 00砖头可以旋转,两种砖头可以无限制提供。你的任务是计算用这两种来覆盖N2的墙壁的覆盖方法。例如一个23的墙…

HotCoin Global: 澳洲双牌照持有平台,坚守全球合规之路
前言: 加密交易平台的合规性不仅是相关法规遵守的问题,更是市场透明度和用户公平性的关键。为促使加密市场的交易活动有规范、有秩序地进行,确保加密投资者的资产与交易安全,部分国家明确对加密资产的交易和经营活动进行监督及管…


Solidworks:剖切模型
剖切模型可以看清模型内部。今天设计了一个模型,试验一下如何剖切。 操作很方便,只需要点击一下零件模型上方的剖切按钮,立即就转入剖切视图。剖切后结果如下。
工程图纸中也可以展示剖面视图,操作方法是点击工程图工具页中的“…

计算机组成原理:存储系统【二】
🌈个人主页:godspeed_lucip 🔥 系列专栏:计算机组成与原理基础 🛰️1 Cache概述🛩️1.1 局部性原理🛫1.1.1 空间局部性🛫1.1.2 时间局部性 🛩️1.2 性能指标🛫…

探索IDE的世界:什么是IDE?以及适合新手的IDE推荐
引言
在编程的世界里,集成开发环境(IDE)是我们日常工作的重要工具。无论是初学者还是经验丰富的开发者,一个好的IDE都能极大地提高我们的编程效率。那么,什么是IDE呢?对于新手来说,又应该选择哪…
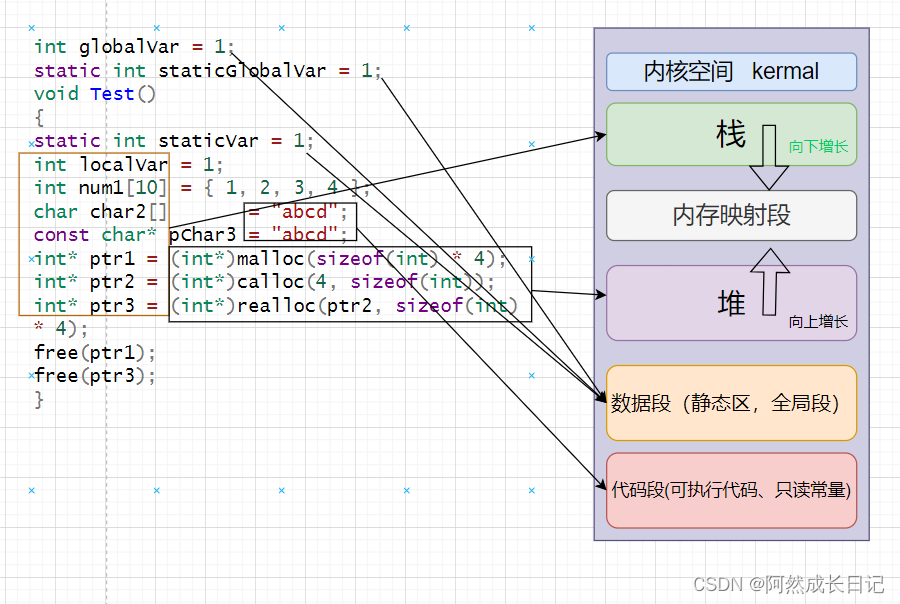
【C++】内存五大区详解
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …

MySQL表的基础操作
创建表
create table 表名(列名 类型,列名 类型……) 注意
1.在进行表操作之前都必须选中数据库
2.表名,列名等一般不可以与关键字相同,如果确定相同,就必须用反引号引住 3.可以使用comment来增加字段说…
多模态论文串讲·下【论文精读·49】最近使用 transformer encoder 和 decoder 的一些方法
大家好,我们今天就接着上次多模态串讲,来说一说最近使用 transformer encoder 和 decoder 的一些方法。
1 BLIP:Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation 我们要过的第一篇论文…

Linux中alarm/setitimer函数(信号函数)
alarm函数 函数原型: unsigned int alarm(unsigned int seconds); 函数描述:设置定时器(闹钟)。在指定seconds后,内核会给当前进程发送 14)SIGALRM信号。进程收到该信号,默认动作终止。每个进程…
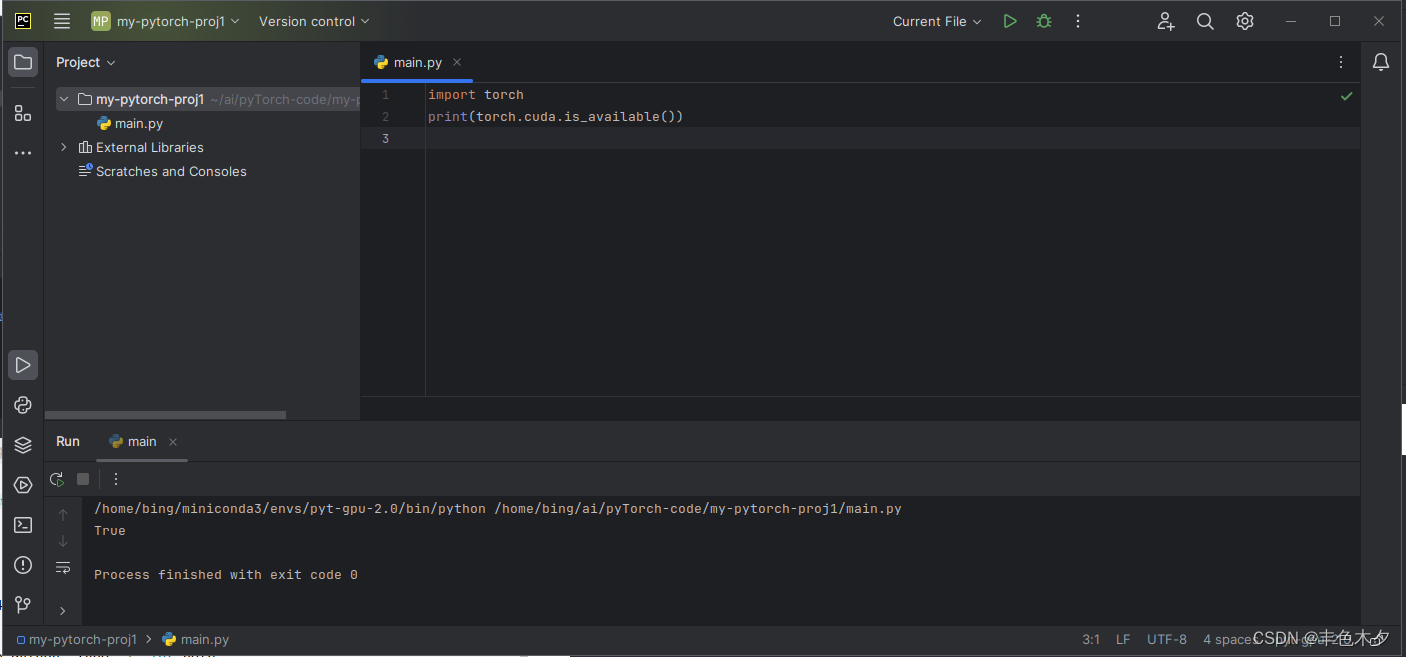
Ubuntu下Anaconda+PyCharm搭建PyTorch环境
这里主要介绍在condapytorch都正确安装的前提下,如何通过pycharm建立开发环境; Ubuntu下AnacondaPyCharm搭建PyTorch环境
系统环境:Ubuntu22.04 conda: conda 23.11.0 pycharm:如下 condapytorch的安装教程介绍,请点击这里&…