参考资料
Anery/transE: transE算法 简单python实现 FB15k (github.com)
Translating Embeddings for Modeling Multi-relational Data (nips.cc)

输入
![]()
1.数据集S
2.Entities集合E
3.Relations集合L
4.margin hyperparameter γ
5.每个向量的长度 k
初始化
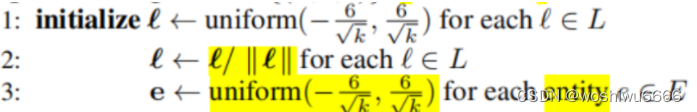
为Entities集合中的每个实体以及Relation集合中的实体,初始化一个向量,并对初始化的向量进行L2范数归一化
其中,相同的entity在头或者在尾出现,都是使用相同的向量
for (int i = 0; i < relation_num; i++) {
for (int j = 0; j < vector_len; j++) {
relation_vec[i][j] = uniform(-6 / sqrt(vector_len), 6 / sqrt(vector_len));
}
}
for (int i = 0; i < entity_num; i++) {
for (int j = 0; j < vector_len; j++) {
entity_vec[i][j] = uniform(-6 / sqrt(vector_len), 6 / sqrt(vector_len));//初始化所有的数据组合都有一个向量
}
norm(entity_vec[i], vector_len);
} static double uniform(double min, double max) {
// generate a float number which is in [min, max), refer to the Python uniform
return min + (max - min) * Math.random();
}用梯度下降更新每个初始化的向量

1.第6行表示,每次迭代,都从数据集中随机抽出大小为b的数据,为Sbatch
2.第7到10行表示,替换头或者尾生成错误的数据,正确和错误的数据是Tbatch中的一个子集
3.根据损失值,分别更新h的向量,l的向量,t的向量,错误的h‘或者错误的t’向量
其中,代码中的更新顺序会和伪代码有略微的差别。另外一个问题是代码的终止条件是按循环的次数,但实际上论文当中写的是按照验证集的预测效果来终止迭代
for (int epoch = 0; epoch < nepoch; epoch++) {
res = 0; // means the total loss in each epoch
for (int batch = 0; batch < nbatches; batch++) {
for (int k = 0; k < batchsize; k++) {
int i = rand_max(fb_h.size());//第i条数据
int j = rand_max(entity_num);//生成一个随机的节点,第j个节点
int relation_id = fb_r.get(i);//第i条数据的relation
double pr = 1000 * right_num.get(relation_id) / (right_num.get(relation_id) + left_num.get(relation_id));//随机选择
if (method == 0) {
pr = 500;
}
if (rand() % 1000 < pr) {
Pair<Integer, Integer> key = new Pair<>(fb_h.get(i), fb_r.get(i));
Set<Integer> values = head_relation2tail.get(key); // 获取头实体和关系对应的尾实体集合
while (values.contains(j)) {
j = rand_max(entity_num);//这个随机节点需要是一个错误的数值,生成尾巴是错误的数据
}
res += train_kb(fb_h.get(i), fb_l.get(i), fb_r.get(i), j, fb_l.get(i), fb_r.get(i), res);
} else {
Pair<Integer, Integer> key = new Pair<>(j, fb_r.get(i));//生成头是错误的数据
Set<Integer> values = head_relation2tail.get(key);
if (values != null) {
while (values.contains(fb_l.get(i))) {
j = rand_max(entity_num);
key = new Pair<>(j, fb_r.get(i));
values = head_relation2tail.get(key);
if (values == null) break;
}
}
res += train_kb(fb_h.get(i), fb_l.get(i), fb_r.get(i), j, fb_l.get(i), fb_r.get(i), res);
}
norm(relation_vec[fb_r.get(i)], vector_len);//归一化
norm(entity_vec[fb_h.get(i)], vector_len);//归一化
norm(entity_vec[fb_l.get(i)], vector_len);//归一化
norm(entity_vec[j], vector_len);//归一化
}
}
System.out.printf("epoch: %s %s\n", epoch, res);
}生成一个随机数
根据数值决定生成错误的头还是错误的尾
double pr = 1000 * right_num.get(relation_id) / (right_num.get(relation_id) + left_num.get(relation_id));//随机选择
if (method == 0) {
pr = 500;
}if (method == 0) {
pr = 500;
}
if (rand() % 1000 < pr) {生成错误的triple
其中这里生成的数据是原数据集中没有的
生成错误的尾实体数据
if (rand() % 1000 < pr) {
Pair<Integer, Integer> key = new Pair<>(fb_h.get(i), fb_r.get(i));
Set<Integer> values = head_relation2tail.get(key); // 获取头实体和关系对应的尾实体集合
while (values.contains(j)) {
j = rand_max(entity_num);//这个随机节点需要是一个错误的数值,生成尾巴是错误的数据
}
res += train_kb(fb_h.get(i), fb_l.get(i), fb_r.get(i), fb_h.get(i), j, fb_r.get(i), res);
} }其中,代码文件中有一个错误的地方,j传递的位置出现了问题
res += train_kb(fb_h.get(i), fb_l.get(i), fb_r.get(i), fb_h.get(i), j, fb_r.get(i),生成错误的头实体数据
Pair<Integer, Integer> key = new Pair<>(j, fb_r.get(i));//生成头是错误的数据
Set<Integer> values = head_relation2tail.get(key);
if (values != null) {
while (values.contains(fb_l.get(i))) {
j = rand_max(entity_num);
key = new Pair<>(j, fb_r.get(i));
values = head_relation2tail.get(key);
if (values == null) break;
}
}计算损失值
只有损失值为正数的时候,才执行embedding的更新

static double train_kb(int head_a, int tail_a, int relation_a, int head_b, int tail_b, int relation_b, double res) {
// 极大似然估计的计算过程
double sum1 = calc_sum(head_a, tail_a, relation_a);
double sum2 = calc_sum(head_b, tail_b, relation_b);
if (sum1 + margin > sum2) { {计算向量距离,即上面的sum1和sum2
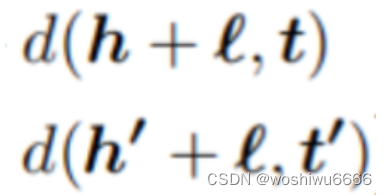
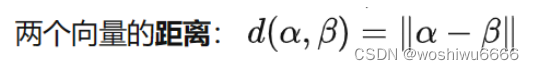
两种计算方式,一种是用绝对值,另一种是开方
其中,sum是对每一位的差值进行累加
static double calc_sum(int e1, int e2, int rel) {
// 计算头实体、关系与尾实体之间的向量距离
double sum = 0;
if (L1_flag) {
for (int i = 0; i < vector_len; i++) {
sum += abs(entity_vec[e2][i] - entity_vec[e1][i] - relation_vec[rel][i]);
}
} else {
for (int i = 0; i < vector_len; i++) {
sum += sqr(entity_vec[e2][i] - entity_vec[e1][i] - relation_vec[rel][i]);
}
}
return sum;
}更新embedding
对正确的embedding中的向量head,relation,tail执行梯度下降
对错误的embedding中的向量head,relation,tail执行梯度下降
gradient(head_a, tail_a, relation_a, head_b, tail_b, relation_b); static void gradient(int head_a, int tail_a, int relation_a, int head_b, int tail_b, int relation_b) {
for (int i = 0; i < vector_len; i++) {
double delta1 = entity_vec[tail_a][i] - entity_vec[head_a][i] - relation_vec[relation_a][i];
double delta2 = entity_vec[tail_b][i] - entity_vec[head_b][i] - relation_vec[relation_b][i];
double x;
if (L1_flag) {
if (delta1 > 0) {
x = 1;
} else {
x = -1;
}
relation_vec[relation_a][i] += x * learning_rate;
entity_vec[head_a][i] += x * learning_rate;
entity_vec[tail_a][i] -= x * learning_rate;
if (delta2 > 0) {
x = 1;
} else {
x = -1;
}
relation_vec[relation_b][i] -= x * learning_rate;
entity_vec[head_b][i] -= x * learning_rate;
entity_vec[tail_b][i] += x * learning_rate;
} else {
delta1 = abs(delta1);
delta2 = abs(delta2);
relation_vec[relation_a][i] += learning_rate * 2 * delta1;
entity_vec[head_a][i] += learning_rate * 2 * delta1;
entity_vec[tail_a][i] -= learning_rate * 2 * delta1;
relation_vec[relation_b][i] -= learning_rate * 2 * delta2;
entity_vec[head_b][i] -= learning_rate * 2 * delta2;
entity_vec[tail_b][i] += learning_rate * 2 * delta2;
}
}
}对更新后的向量,执行归一化
norm(relation_vec[fb_r.get(i)], vector_len);//归一化
norm(entity_vec[fb_h.get(i)], vector_len);//归一化
norm(entity_vec[fb_l.get(i)], vector_len);//归一化
norm(entity_vec[j], vector_len);//归一化完成预测
public void run() throws IOException {
relation_vec = new double[relation_num][vector_len];
entity_vec = new double[entity_num][vector_len];
Read_Vec_File("resource/result/relation2vec.bern", relation_vec);
Read_Vec_File("resource/result/entity2vec.bern", entity_vec);
int head_meanRank_raw = 0, tail_meanRank_raw = 0, head_meanRank_filter = 0, tail_meanRank_filter = 0; // 在正确三元组之前的匹配距离之和
int head_hits10 = 0, tail_hits10 = 0, head_hits10_filter = 0, tail_hits10_filter = 0; // 在正确三元组之前的匹配个数之和
int relation_meanRank_raw = 0, relation_meanRank_filter = 0;
int relation_hits10 = 0, relation_hits10_filter = 0;
// ------------------------ evaluation link predict ----------------------------------------
System.out.printf("Total test triple = %s\n", fb_l.size());
System.out.printf("The evaluation of link predict\n");
for (int id = 0; id < fb_l.size(); id++) {
int head = fb_h.get(id);
int tail = fb_l.get(id);
int relation = fb_r.get(id);
List<Pair<Integer, Double>> head_dist = new ArrayList<>();//预测头
for (int i = 0; i < entity_num; i++) {
double sum = calc_sum(i, tail, relation);//计算所有组合的距离
head_dist.add(new Pair<>(i, sum));
}
Collections.sort(head_dist, (o1, o2) -> Double.compare(o1.b, o2.b));//对headlist排序
int filter = 0; // 统计匹配过程已有的正确三元组个数
for (int i = 0; i < head_dist.size(); i++) {
int cur_head = head_dist.get(i).a;
if (hrt_isvalid(cur_head, relation, tail)) { // 如果当前三元组是正确三元组,则记录到filter中
filter += 1;
}
if (cur_head == head) {
head_meanRank_raw += i; // 统计小于<h, l, r>距离的数量
head_meanRank_filter += i - filter;
if (i <= 10) {
head_hits10++;//不过滤的结果
}
if (i - filter <= 10) {//去掉在数据集中存在,但不是想要的结果数据
head_hits10_filter++;//过滤的结果
}
break;
}
}
filter = 0;
List<Pair<Integer, Double>> tail_dist = new ArrayList<>();//预测尾巴
for (int i = 0; i < entity_num; i++) {
double sum = calc_sum(head, i, relation);
tail_dist.add(new Pair<>(i, sum));
}
Collections.sort(tail_dist, (o1, o2) -> Double.compare(o1.b, o2.b));
for (int i = 0; i < tail_dist.size(); i++) {
int cur_tail = tail_dist.get(i).a;
if (hrt_isvalid(head, relation, cur_tail)) {
filter++;
}
if (cur_tail == tail) {
tail_meanRank_raw += i;
tail_meanRank_filter += i - filter;
if (i <= 10) {
tail_hits10++;
}
if (i - filter <= 10) {
tail_hits10_filter++;
}
break;
}
}
}
System.out.printf("-----head prediction------\n");
System.out.printf("Raw MeanRank: %.3f, Filter MeanRank: %.3f\n",
(head_meanRank_raw * 1.0) / fb_l.size(), (head_meanRank_filter * 1.0) / fb_l.size());
System.out.printf("Raw Hits@10: %.3f, Filter Hits@10: %.3f\n",
(head_hits10 * 1.0) / fb_l.size(), (head_hits10_filter * 1.0) / fb_l.size());
System.out.printf("-----tail prediction------\n");
System.out.printf("Raw MeanRank: %.3f, Filter MeanRank: %.3f\n",
(tail_meanRank_raw * 1.0) / fb_l.size(), (tail_meanRank_filter * 1.0) / fb_l.size());
System.out.printf("Raw Hits@10: %.3f, Filter Hits@10: %.3f\n",
(tail_hits10 * 1.0) / fb_l.size(), (tail_hits10_filter * 1.0) / fb_l.size());
// ------------------------ evaluation relation-linked predict ----------------------------------------
int relation_hits = 5; // 选取hits@5为评价指标
for (int id = 0; id < fb_l.size(); id++) {
int head = fb_h.get(id);
int tail = fb_l.get(id);
int relation = fb_r.get(id);
List<Pair<Integer, Double>> relation_dist = new ArrayList<>();
for (int i = 0; i < relation_num; i++) {
double sum = calc_sum(head, tail, i);
relation_dist.add(new Pair<>(i, sum));
}
Collections.sort(relation_dist, (o1, o2) -> Double.compare(o1.b, o2.b));
int filter = 0; // 统计匹配过程已有的正确三元组个数
for (int i = 0; i < relation_dist.size(); i++) {
int cur_relation = relation_dist.get(i).a;
if (hrt_isvalid(head, cur_relation, tail)) { // 如果当前三元组是正确三元组,则记录到filter中
filter += 1;
}
if (cur_relation == relation) {
relation_meanRank_raw += i; // 统计小于<h, l, r>距离的数量
relation_meanRank_filter += i - filter;
if (i <= 5) {
relation_hits10++;
}
if (i - filter <= 5) {
relation_hits10_filter++;
}
break;
}
}
}
System.out.printf("-----relation prediction------\n");
System.out.printf("Raw MeanRank: %.3f, Filter MeanRank: %.3f\n",
(relation_meanRank_raw * 1.0) / fb_r.size(), (relation_meanRank_filter * 1.0) / fb_r.size());
System.out.printf("Raw Hits@%d: %.3f, Filter Hits@%d: %.3f\n",
relation_hits, (relation_hits10 * 1.0) / fb_r.size(),
relation_hits, (relation_hits10_filter * 1.0) / fb_r.size());
}首先读取训练集中的文件
读取relation的向量,entity的向量
Read_Vec_File("resource/result/relation2vec.bern", relation_vec);
Read_Vec_File("resource/result/entity2vec.bern", entity_vec);以预测head为例
每一条数据为一个测试样例
1.计算每一个答案的距离(分数)
2.对答案降序排名
3.统计过滤的结果,以及不过滤的结果
过滤的结果,在数据集当中有,满足head的条件,但是与这条数据中的head不相同,在计算排名的时候将这些答案过滤掉
// ------------------------ evaluation link predict ----------------------------------------
System.out.printf("Total test triple = %s\n", fb_l.size());
System.out.printf("The evaluation of link predict\n");
for (int id = 0; id < fb_l.size(); id++) {
int head = fb_h.get(id);
int tail = fb_l.get(id);
int relation = fb_r.get(id);
List<Pair<Integer, Double>> head_dist = new ArrayList<>();//预测头
for (int i = 0; i < entity_num; i++) {
double sum = calc_sum(i, tail, relation);//计算所有组合的距离
head_dist.add(new Pair<>(i, sum));
}
Collections.sort(head_dist, (o1, o2) -> Double.compare(o1.b, o2.b));//对headlist排序
int filter = 0; // 统计匹配过程已有的正确三元组个数
for (int i = 0; i < head_dist.size(); i++) {
int cur_head = head_dist.get(i).a;
if (hrt_isvalid(cur_head, relation, tail)) { // 如果当前三元组是正确三元组,则记录到filter中
filter += 1;
}
if (cur_head == head) {
head_meanRank_raw += i; // 统计小于<h, l, r>距离的数量
head_meanRank_filter += i - filter;
if (i <= 10) {
head_hits10++;//不过滤的结果
}
if (i - filter <= 10) {//去掉在数据集中存在,但不是想要的结果数据
head_hits10_filter++;//过滤的结果
}
break;
}
}