🚀 作者 :“码上有前”
🚀 文章简介 :后端高频面试题
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬
后端高频面试题--设计模式下篇
- 后端高频面试题--设计模式上篇
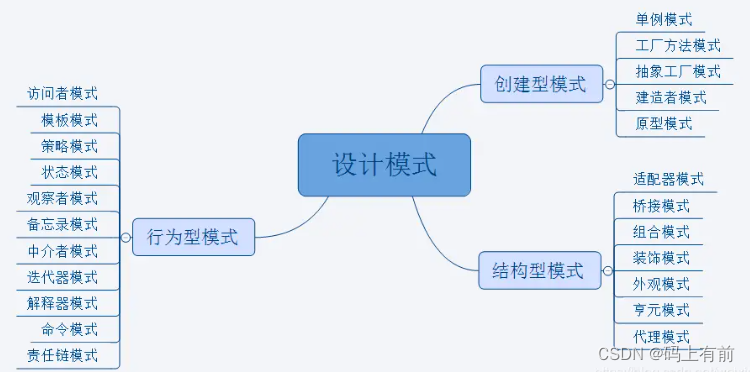
- 设计模式总览
- 模板方法模式
- 怎么理解模板方法模式
- 模板方法模式的优缺点
- 模板方法模式的应用场景
- 代码实现模板方法模式
- 外观模式
- 怎么理解外观模式
- 外观模式的优缺点
- 外观模式的应用场景
- 代码实现外观模式
- 原型模式
- 怎么理解原型模式
- 原型模式的优缺点
- 原型模式的应用场景
- 代码实现原型模式
- 策略模式
- 怎么理解策略模式
- 策略模式的优缺点
- 策略模式的应用场景
- 代码实现策略模式
后端高频面试题–设计模式上篇
后端高频面试题–设计模式上篇
设计模式总览
模板方法模式
怎么理解模板方法模式
模板方法模式是一种行为型设计模式,它定义了一个操作中的算法骨架,将一些步骤延迟到子类中实现。模板方法模式通过模板方法来控制算法的结构,同时允许子类根据需要重写特定步骤,以实现自己的行为。
在模板方法模式中,有两个关键角色:
-
模板方法(Template Method):
模板方法是一个抽象方法或虚拟方法,定义了算法的骨架。它通常是一个具体的方法,其中包含了一系列的步骤或操作,这些步骤按照一定的顺序执行。模板方法可以包含具体实现,也可以调用抽象方法或钩子方法。 -
抽象方法(Abstract Method)和钩子方法(Hook Method):
抽象方法是模板方法中的一个或多个方法,它们由抽象类或接口定义,并延迟到子类中实现。子类必须提供这些抽象方法的具体实现。钩子方法是在模板方法中声明的一个空方法或具有默认实现的方法,子类可以选择性地重写钩子方法。
模板方法模式的核心思想是将算法的结构固定下来,但允许具体的实现细节在子类中进行扩展。通过定义模板方法和抽象方法,模板方法模式提供了一种框架,促使代码重用和扩展。
模板方法模式的优点包括:
- 提供了一种固定算法结构,方便代码复用和维护。
- 允许子类根据需要重写特定步骤,实现自己的行为。
- 通过钩子方法,允许子类选择性地扩展或修改算法的行为。
模板方法模式适用于以下场景:
- 当需要定义一个算法的骨架,但允许具体步骤的实现在子类中变化时。
- 当希望通过继承和多态来实现代码重用和扩展时。
- 当有一些通用操作可以放在父类中,而具体实现可以在子类中实现时。
需要注意的是,模板方法模式使用继承来实现算法的扩展,这可能导致类层次结构的膨胀。此外,由于模板方法在父类中被定义,因此子类对算法结构的修改受到限制。因此,在使用模板方法模式时需要仔细设计类的层次结构和方法的可扩展性。
模板方法模式的优缺点
模板方法模式是一种常用的设计模式,它在定义算法的骨架的同时,允许子类根据需要重写特定的步骤,以实现自己的行为。下面是模板方法模式的一些优缺点:
优点:
- 代码复用:模板方法模式通过将算法的结构固定在父类中,可以在子类中重用这个算法,避免了重复编写相同的代码。
- 提高了扩展性:通过在模板方法中定义抽象方法或钩子方法,子类可以根据需要实现自己的具体步骤,从而灵活地扩展或修改算法的行为。
- 降低了代码的重构风险:由于模板方法模式将算法的核心逻辑固定在父类中,只允许子类实现特定的步骤,因此在修改算法时,只需关注修改对应的步骤,减少了对整个算法的影响,降低了代码的重构风险。
缺点:
- 类层次结构的扩展:模板方法模式使用继承来实现算法的扩展,这可能导致类层次结构的膨胀。每个变体的实现都需要创建一个具体的子类,当变体较多时,类的数量会增加。
- 父类对子类的依赖:在模板方法模式中,父类定义了算法的骨架,而子类负责实现具体的步骤。这使得父类对子类有一定的依赖性,子类的实现可能会影响算法的整体结构。
- 不适合算法的所有步骤都需要扩展:如果算法的所有步骤都需要在子类中进行扩展,那么模板方法模式可能不适用。因为这样会导致在每个子类中重写所有的步骤,增加了代码的重复性和复杂性。
总的来说,模板方法模式在提供代码复用和扩展性方面具有一定的优势,但需要注意类层次结构的扩展和父类对子类的依赖。在使用模板方法模式时,需要仔细考虑算法的结构和步骤的扩展性,以及权衡代码的复用和灵活性之间的关系。
模板方法模式的应用场景
模板方法模式适用于以下场景:
-
算法的骨架固定:当有一个算法的基本骨架已经确定,但其中的某些具体步骤可以有不同的实现方式时,可以使用模板方法模式。例如,一个订单处理流程中,包括接收订单、验证订单、处理支付、发货等步骤,这些步骤的顺序是固定的,但每个步骤的具体实现方式可能会有所不同。
-
代码复用和扩展:当有多个类或方法存在相似的行为模式时,可以将这些相似的行为提取到父类中的模板方法中,以实现代码的复用。同时,通过允许子类重写特定的步骤,可以在不修改父类的情况下扩展或修改行为。
-
框架和库的设计:模板方法模式广泛应用于框架和库的设计中。框架提供一个抽象的模板方法,定义了整体的流程和结构,而具体的实现则由使用框架的开发者提供。这样可以保持框架的稳定性,并提供给开发者一定的灵活性。
-
算法和流程的变体:当存在多个算法或流程的变体时,可以使用模板方法模式。通过定义一个模板方法,将算法或流程的共同部分提取到父类中,而将变体的实现细节留给子类。这样可以在不同的子类中实现不同的变体,而不会影响整体的结构和逻辑。
总的来说,模板方法模式适用于具有固定结构但可变实现的场景,例如订单处理、框架和库设计、算法和流程的变体等。它提供了一种灵活的方式来定义算法的骨架,并允许子类根据需要进行扩展和修改。
代码实现模板方法模式
以下是一个简单的代码示例,展示了如何使用模板方法模式来实现一个炒菜的模板:
from abc import ABC, abstractmethod
class CookTemplate(ABC):
def cook(self):
self.prepareIngredients()
self.boilWater()
self.cookIngredients()
self.serveDish()
def prepareIngredients(self):
print("准备食材")
def boilWater(self):
print("煮水")
@abstractmethod
def cookIngredients(self):
pass
def serveDish(self):
print("上菜")
在这个示例中,CookTemplate 是一个抽象类,定义了一个模板方法 cook(),该方法定义了炒菜的整体流程。它依次调用了准备食材(prepareIngredients())、煮水(boilWater())、炒食材(cookIngredients())和上菜(serveDish())的步骤。
prepareIngredients() 和 boilWater() 是具体的步骤,它们在父类中已经有了默认的实现。而 cookIngredients() 是一个抽象方法,它需要在子类中进行具体的实现。
下面是一个具体的子类实现:
class StirFryCook(CookTemplate):
def cookIngredients(self):
print("炒菜")
class BoilCook(CookTemplate):
def cookIngredients(self):
print("煮菜")
在这个示例中,StirFryCook 和 BoilCook 是两个具体的子类,它们分别实现了 cookIngredients() 方法,用于具体的炒菜和煮菜步骤。
下面是示例的使用代码:
stir_fry_cook = StirFryCook()
stir_fry_cook.cook()
boil_cook = BoilCook()
boil_cook.cook()
运行以上代码,将会得到如下输出:
准备食材
煮水
炒菜
上菜
准备食材
煮水
煮菜
上菜
通过模板方法模式,我们可以定义炒菜的整体流程,并在子类中实现具体的炒菜或煮菜步骤,从而实现了代码的复用和扩展。
外观模式
怎么理解外观模式
外观模式(Facade Pattern)是一种结构型设计模式,它提供了一个统一的接口,用于访问子系统中一组复杂的接口。外观模式通过将复杂的子系统封装在一个简单的接口背后,简化了客户端与子系统之间的交互,提供了一个更高层次的接口,使得客户端更容易使用子系统。
理解外观模式可以从以下几个方面入手:
-
封装复杂性:外观模式通过封装一组复杂的接口,将其隐藏在一个简单的接口后面。它提供了一个高级别的接口,客户端只需要与外观对象进行交互,而无需了解内部的复杂实现细节。这样可以降低客户端的复杂性,并提供了一种简化接口的方式。
-
提供简化接口:外观模式提供了一个简化的接口,将多个子系统的功能组合在一起。客户端只需要调用外观对象的方法,而不需要直接与多个子系统的接口进行交互。这样简化了客户端的代码,减少了对子系统的依赖。
-
解耦客户端和子系统:外观模式将客户端与子系统之间解耦,客户端不需要知道子系统的具体实现和内部结构。当子系统发生变化时,只需调整外观对象的代码,而不会影响到客户端的代码。这提供了一种松耦合的方式,增加了系统的灵活性和可维护性。
-
提高可扩展性:外观模式对于添加新的子系统或更改现有子系统相对较容易。由于客户端只与外观对象进行交互,所以在添加新的子系统时,只需在外观对象中添加相应的方法即可。这样可以避免对客户端代码的修改,提高了系统的可扩展性。
总的来说,外观模式通过提供一个简化的接口,封装复杂的子系统,解耦客户端和子系统,提高了系统的可用性、可扩展性和可维护性。它是一种很好地组织和管理复杂系统的方式,使得客户端更容易使用和理解系统的功能。
外观模式的优缺点
外观模式(Facade Pattern)作为一种设计模式,具有以下优点和缺点:
优点:
-
简化接口:外观模式提供了一个简化的接口,将复杂的子系统隐藏起来,使得客户端更容易使用。客户端只需要与外观对象进行交互,而不需要了解子系统的内部结构和复杂性。
-
解耦客户端和子系统:外观模式将客户端与子系统解耦,客户端不需要直接与多个子系统进行交互。这样当子系统发生变化时,只需修改外观对象即可,而不会影响到客户端的代码。这提高了系统的灵活性和可维护性。
-
提高可扩展性:外观模式对于添加新的子系统或更改现有子系统相对较容易。由于客户端只与外观对象进行交互,所以在添加新的子系统时,只需在外观对象中添加相应的方法即可。这样可以避免对客户端代码的修改,提高了系统的可扩展性。
-
提高了系统的安全性:外观模式可以通过将敏感的子系统接口隐藏起来,提供一个受控的访问点。客户端只能通过外观对象来访问子系统,而无法直接调用子系统的方法。这样可以增加系统的安全性,防止客户端滥用或错误使用子系统的功能。
缺点:
-
不符合开闭原则:外观模式的缺点是当需要修改系统的功能时,可能需要修改外观对象的代码。如果系统中存在多个外观对象,那么修改的范围可能会更大。这违反了开闭原则(对扩展开放,对修改关闭),需要谨慎设计外观对象的接口。
-
可能引入性能问题:由于外观模式将多个子系统封装在一个接口中,可能会导致性能问题。如果某个子系统的操作非常复杂或耗时较长,那么在调用外观对象的方法时可能会出现性能瓶颈。在这种情况下,需要仔细考虑是否使用外观模式。
-
可能降低灵活性:外观模式的目的是简化接口,隐藏复杂性。但这也意味着客户端可能无法直接访问子系统的所有功能。如果客户端需要直接使用某个子系统的特定功能,而外观对象没有提供相应的方法,那么就无法通过外观模式实现。
需要根据具体的情况来评估外观模式的适用性。在设计系统时,应该权衡外观模式的优点和缺点,并根据具体需求和设计目标来决定是否使用外观模式。
外观模式的应用场景
外观模式(Facade Pattern)适用于以下场景:
-
简化复杂的子系统:当系统中存在复杂的子系统,其接口众多并且相互之间存在依赖关系时,可以使用外观模式来封装这些复杂性,提供一个简单的接口供客户端使用。外观模式可以隐藏子系统的复杂性,使得客户端更容易使用和理解系统的功能。
-
提供统一的接口:当系统中存在多个子系统,而客户端需要与这些子系统进行交互时,可以使用外观模式提供一个统一的接口。外观对象作为一个中间层,将客户端与子系统解耦,客户端只需要与外观对象进行交互,而不需要直接了解和调用多个子系统的接口。
-
系统的独立性和可移植性:当系统中的子系统发生变化时,如果客户端直接依赖于子系统的接口,那么客户端的代码需要修改。使用外观模式可以降低客户端与子系统的耦合度,当子系统发生变化时,只需要修改外观对象的代码,而不会影响到客户端的代码。这提高了系统的独立性和可移植性。
-
系统的安全性和访问控制:外观模式可以提供一个受控的访问点,限制客户端对子系统的访问。外观对象可以隐藏敏感的子系统接口,只提供有限的访问权限。这有助于提高系统的安全性,并防止客户端滥用或错误使用子系统的功能。
总的来说,外观模式适用于需要简化复杂子系统、提供统一接口、降低耦合度、提高系统的独立性和安全性的场景。它可以帮助简化客户端与子系统的交互,提供一个更高级别的接口,使得客户端更容易使用和理解系统的功能。
代码实现外观模式
以下是一个简单的外观模式的代码实现示例:
# 子系统A
class SubsystemA:
def operationA(self):
print("SubsystemA operation")
# 子系统B
class SubsystemB:
def operationB(self):
print("SubsystemB operation")
# 子系统C
class SubsystemC:
def operationC(self):
print("SubsystemC operation")
# 外观类
class Facade:
def __init__(self):
self.subsystemA = SubsystemA()
self.subsystemB = SubsystemB()
self.subsystemC = SubsystemC()
def operation(self):
self.subsystemA.operationA()
self.subsystemB.operationB()
self.subsystemC.operationC()
# 客户端代码
facade = Facade()
facade.operation()
在上述代码中,我们有三个子系统 (SubsystemA, SubsystemB, SubsystemC),每个子系统都有自己的操作(operationA, operationB, operationC)。然后我们创建了一个外观类 Facade,它封装了这些子系统,并提供了一个名为 operation 的方法,该方法在内部调用了子系统的相应操作。
在客户端代码中,我们创建了一个 Facade 对象,并调用了其 operation 方法。客户端只需要与外观对象进行交互,而不需要了解底层子系统的复杂性和实现细节。外观对象负责协调子系统的操作,并提供一个简单的接口给客户端使用。
这样,通过外观模式,我们可以将复杂的子系统封装起来,使得客户端更容易使用和理解系统的功能。当需要修改子系统时,只需修改外观类的代码,而不会影响到客户端的代码,从而提高了系统的灵活性和可维护性。
原型模式
怎么理解原型模式
原型模式(Prototype Pattern)是一种创建型设计模式,它通过复制(克隆)现有对象来创建新对象,而不是通过使用构造函数直接创建。原型模式基于一个原型对象,通过复制该原型对象来创建新的对象,使得创建过程更加灵活和高效。
理解原型模式可以从以下几个方面来考虑:
-
对象的复制:原型模式的核心概念是对象的复制。原型对象作为一个可复制的对象,可以通过复制自身来创建新的对象。这种复制可以是浅复制(只复制对象的基本属性,引用类型属性仍然共享)或深复制(复制对象的所有属性和引用类型属性)。通过复制现有对象,可以避免重复创建相似对象的开销,提高对象的创建效率。
-
原型与实例的关系:原型对象作为一个样板,可以被多个实例所共享。当需要创建新的对象时,可以通过克隆原型对象来创建新的实例。原型模式允许动态地添加或修改原型对象,从而影响所有基于该原型创建的实例,实现了原型和实例之间的解耦。
-
原型注册与管理:原型模式通常会使用一个原型管理器(Prototype Manager)来注册和管理原型对象。原型管理器充当一个仓库,用于存储和获取原型对象。客户端可以通过原型管理器来获取所需类型的原型对象,并进行克隆创建新的实例。
-
适用性:原型模式适用于以下情况:当创建新对象的过程比较复杂或耗时时,可以使用原型模式来复制已有对象,避免重复的初始化过程;当需要动态地添加或修改对象的属性时,可以通过修改原型对象来影响所有创建的实例;当系统需要保护对象免于被修改时,可以使用原型模式,因为克隆的对象是独立的,不会影响到原型对象。
总结来说,原型模式通过克隆现有对象来创建新对象,提供了一种灵活、高效的对象创建方式。它可以避免重复的初始化过程,提高对象创建效率,同时也允许动态地添加或修改对象的属性。理解原型模式有助于在需要创建对象时选择适当的创建方式,并在系统中实现对象的复制和管理。
原型模式的优缺点
原型模式是一种创建型设计模式,它具有以下优点和缺点:
优点:
-
减少对象的创建成本:原型模式通过复制现有对象来创建新对象,避免了重复的初始化过程,从而提高了对象的创建效率。
-
灵活性和扩展性:通过原型模式,可以动态地添加或修改原型对象的属性,从而影响所有基于该原型创建的实例。这种灵活性使得系统更容易进行扩展和升级。
-
对象的创建与使用分离:原型模式将对象的创建和使用逻辑分离。客户端只需要通过原型对象来克隆新对象,而不需要关心具体的创建细节,降低了客户端与具体类之间的耦合度。
-
保护对象的不可变性:通过原型模式创建的对象是独立的,对其中一个对象的修改不会影响到其他对象。这种保护对象的不可变性有助于构建稳定的系统。
缺点:
-
对象的深复制可能较复杂:在原型模式中,对象的复制通常使用深复制来保证克隆对象的独立性。但是,深复制可能涉及到复杂的对象结构和引用关系,导致实现起来比较复杂。
-
需要为每个类实现克隆方法:在原型模式中,每个需要被克隆的类都需要实现克隆方法。对于大型系统或者对象较多的情况,可能需要为很多类都添加相应的克隆方法,增加了代码量。
-
克隆方法的正确性:为了正确地实现克隆方法,需要保证对象的所有属性都能被正确地复制。如果有些属性无法被克隆或者被克隆的结果不符合预期,可能会导致克隆出的对象与原始对象之间存在差异。
总体来说,原型模式在适当的场景下能够提供灵活的对象创建和复制机制,减少对象创建成本,同时也具有一些实施上的复杂性。在使用原型模式时,需要考虑对象结构的复杂性、克隆方法的正确性以及性能等因素。
原型模式的应用场景
原型模式适用于以下场景:
-
对象的创建成本高:当创建一个对象的过程非常耗时或复杂时,可以使用原型模式来复制现有对象来创建新的对象,从而避免重复的初始化工作,提高对象创建的效率。
-
对象的创建与使用分离:当对象的创建和使用逻辑相互耦合,难以进行独立维护和扩展时,可以使用原型模式来将对象的创建与使用分离。通过原型模式,可以将对象的创建逻辑放在原型对象中,而将对象的使用逻辑放在客户端中,从而降低耦合度并提高系统的灵活性。
-
动态配置对象:当需要根据不同的配置来创建对象时,可以使用原型模式。通过原型模式,可以创建一个原型对象,然后根据不同的配置对原型对象进行克隆,从而得到不同配置的对象实例。
-
保护对象的不可变性:当需要保护对象免于被修改时,可以使用原型模式。因为通过原型模式创建的对象是独立的,对其中一个对象的修改不会影响到其他对象。
-
原型管理与资源共享:当系统需要管理一组相似对象,并且这些对象之间共享一些资源时,可以使用原型模式。通过原型管理器,可以注册和管理一组原型对象,并在需要时克隆这些对象来创建新的实例。
总的来说,原型模式适用于需要复制现有对象来创建新对象的场景,特别是当创建对象的成本高、创建与使用逻辑耦合、需要动态配置对象、保护对象不可变性以及原型管理与资源共享等情况下。原型模式可以提高对象创建的效率、降低耦合度并增加系统的灵活性。
代码实现原型模式
下面是一个使用原型模式的简单代码示例:
import copy
# 原型类
class Prototype:
def __init__(self):
self.name = "Prototype"
def clone(self):
return copy.deepcopy(self)
# 客户端代码
prototype = Prototype()
print("Original Object:", prototype.name)
# 克隆对象
clone_obj = prototype.clone()
print("Cloned Object:", clone_obj.name)
在上述代码中,定义了一个原型类 Prototype,它包含一个 clone 方法用于克隆自身。在 clone 方法中使用 copy.deepcopy() 函数进行深拷贝,确保克隆出的对象是独立的。
在客户端代码中,首先创建一个原型对象 prototype,输出其名称。然后通过调用 clone 方法克隆出一个新的对象 clone_obj,并输出其名称。可以看到,克隆出的对象与原型对象具有相同的属性值。
原型模式的关键在于克隆方法,通过克隆方法复制现有对象来创建新对象,而不是通过构造函数直接创建。这样可以避免重复的初始化过程,提高对象的创建效率,并确保克隆出的对象是独立的。
需要注意的是,在实际使用中,原型模式可能涉及到更复杂的对象结构和克隆逻辑。此处的示例只是一个简单的演示,以便理解原型模式的基本概念和实现方式。
策略模式
怎么理解策略模式
策略模式(Strategy Pattern)是一种行为型设计模式,它允许在运行时选择算法的行为,将算法封装成独立的策略对象,并使它们可以互相替换。策略模式将算法的选择与算法的实现分离,使得算法可以独立于客户端而变化,提供了一种灵活的解决方案。
理解策略模式可以从以下几个方面来考虑:
-
策略对象:策略模式中的策略对象是封装了具体算法的对象。每个策略对象实现了一种特定的算法,可以根据需要进行替换。策略对象通常具有一个公共的接口,以便于客户端与策略对象进行交互。
-
策略选择:策略模式允许在运行时动态地选择使用哪种算法。客户端可以根据具体情况选择合适的策略对象,并将其传递给上下文对象。上下文对象会在需要时调用策略对象的方法来执行相应的算法。
-
策略的替换:由于策略对象之间具有相同的接口,因此它们可以互相替换,而不会对客户端代码造成影响。这使得客户端能够灵活地改变算法的行为,而无需修改原有的代码。
-
适用性:策略模式适用于以下情况:当一个系统需要在多个算法中选择一种,且这些算法之间的差异较大时;当需要在运行时动态地切换算法时;当一个类有多个行为变体,而不希望使用条件语句来实现时。
总结来说,策略模式通过将算法封装成独立的策略对象,使得算法的选择与算法的实现分离,提供了一种灵活的解决方案。客户端可以在运行时选择合适的策略对象,并将其传递给上下文对象来执行相应的算法。理解策略模式有助于在需要根据不同的情况选择不同的算法时,设计灵活、可扩展的系统。
策略模式的优缺点
策略模式(Strategy Pattern)具有以下优点和缺点:
优点:
-
算法的独立性:策略模式将每个算法封装在独立的策略对象中,使得算法可以独立于客户端而变化。这样可以方便地添加、删除或修改算法,而不会影响到客户端代码。
-
可扩展性:由于策略模式将算法的选择与算法的实现分离,添加新的策略对象非常方便。可以根据需要定义新的策略对象,并在运行时动态地选择使用哪种策略对象,从而实现系统的可扩展性。
-
简化复杂的条件语句:使用策略模式可以避免使用大量的条件语句来选择不同的算法。将算法封装在独立的策略对象中,使得客户端代码更加清晰,易于理解和维护。
-
提高代码的复用性:策略模式中的策略对象可以在不同的上下文中重复使用,从而提高代码的复用性。同样的策略对象可以被多个客户端使用,避免了重复编写相同的代码。
缺点:
-
增加类的数量:使用策略模式会引入多个策略对象,这可能会增加类的数量。如果算法较少或者简单,引入策略模式可能会使代码变得复杂,增加系统的复杂性。
-
客户端需要了解不同的策略对象:客户端需要了解不同的策略对象以及它们之间的区别,以便在运行时进行选择。这可能增加了客户端代码的复杂性。
-
上下文对象的管理:策略模式中,上下文对象需要持有一个策略对象,并在需要时调用策略对象的方法。这可能需要一定的管理和协调工作,特别是在多线程环境下可能存在并发访问的问题。
综上所述,策略模式通过将算法封装成独立的策略对象,提供了一种灵活、可扩展的解决方案。它具有算法的独立性、可扩展性以及简化复杂的条件语句等优点。然而,需要注意增加类的数量、客户端了解不同策略对象以及上下文对象的管理等缺点。在具体应用策略模式时,需要权衡考虑这些优缺点,并根据实际需求进行设计和实施。
策略模式的应用场景
策略模式(Strategy Pattern)适用于以下场景:
-
算法的多样性:当系统中存在多个算法,并且这些算法之间可以相互替换,而且每个算法都可以独立于客户端而变化时,可以使用策略模式。例如,一个电商平台的结算系统可以根据不同的促销策略(如满减、折扣、赠品等)来计算订单的最终金额。
-
条件语句的复杂性:当系统中存在大量的条件语句来选择不同的算法时,可以考虑使用策略模式来简化代码。策略模式将每个算法封装在独立的策略对象中,使得客户端代码更加清晰、易于理解和维护。
-
运行时动态选择算法:当需要在运行时动态地选择使用哪种算法时,可以使用策略模式。通过将不同的算法封装在独立的策略对象中,客户端可以根据具体情况选择合适的策略对象,并将其传递给上下文对象来执行相应的算法。
-
系统的扩展性:当系统需要支持新的算法或者变体时,策略模式可以提供一种灵活的解决方案。通过添加新的策略对象,可以方便地扩展系统的功能,而不需要修改已有的代码。
-
避免使用继承扩展功能:当需要扩展或变化的是算法而不是对象本身时,策略模式比继承更加灵活。策略模式通过组合和委托来实现算法的扩展,而不是通过继承,避免了继承带来的静态耦合。
总而言之,策略模式适用于存在多个算法、需要动态选择算法、需要简化复杂的条件语句、支持系统的扩展性以及避免使用继承扩展功能的场景。它提供了一种灵活、可扩展的算法选择解决方案,可以提高代码的可维护性和可复用性。
代码实现策略模式
下面是一个使用策略模式的简单代码示例,以展示如何在实践中实现策略模式:
# 定义策略接口
class PaymentStrategy:
def pay(self, amount):
pass
# 定义具体的策略类
class CreditCardPaymentStrategy(PaymentStrategy):
def pay(self, amount):
print("Paid {} amount using credit card.".format(amount))
class PayPalPaymentStrategy(PaymentStrategy):
def pay(self, amount):
print("Paid {} amount using PayPal.".format(amount))
class AliPayPaymentStrategy(PaymentStrategy):
def pay(self, amount):
print("Paid {} amount using AliPay.".format(amount))
# 定义上下文类
class ShoppingCart:
def __init__(self, payment_strategy):
self.payment_strategy = payment_strategy
def pay(self, amount):
self.payment_strategy.pay(amount)
# 客户端代码
if __name__ == '__main__':
# 创建具体的策略对象
credit_card_strategy = CreditCardPaymentStrategy()
paypal_strategy = PayPalPaymentStrategy()
alipay_strategy = AliPayPaymentStrategy()
# 创建上下文对象,并设置具体的策略对象
shopping_cart = ShoppingCart(credit_card_strategy)
# 进行支付
shopping_cart.pay(100)
# 动态切换策略对象
shopping_cart.payment_strategy = paypal_strategy
shopping_cart.pay(200)
shopping_cart.payment_strategy = alipay_strategy
shopping_cart.pay(300)
在这个示例中,我们定义了一个策略接口 PaymentStrategy,并实现了具体的策略类 CreditCardPaymentStrategy、PayPalPaymentStrategy 和 AliPayPaymentStrategy。这些具体的策略类实现了 pay 方法来执行相应的支付操作。
我们还定义了一个上下文类 ShoppingCart,它接收一个策略对象作为参数,并在 pay 方法中调用策略对象的 pay 方法来进行支付操作。
在客户端代码中,我们创建了具体的策略对象,并将其传递给上下文对象 ShoppingCart。然后,我们可以通过调用 pay 方法来执行支付操作。通过动态切换策略对象,我们可以在运行时选择不同的支付策略。
运行以上代码,将输出以下结果:
Paid 100 amount using credit card.
Paid 200 amount using PayPal.
Paid 300 amount using AliPay.
这个示例展示了如何使用策略模式将不同的支付方式封装成独立的策略对象,并根据需要动态地选择使用哪种支付策略。这样,客户端代码可以方便地调用相应的支付策略,而不需要关心具体的实现细节。
祝大家新年快乐,学业有成,万事如意!🚀
嘿嘿都看到这里啦,乖乖 点个赞吧