constexpr
constexpr的隐含意思是在编译阶段求值,对于一些求值操作,如果声明为constexpr,那么会编译器会尝试在编译阶段进行计算求值,如果求值成功,则用结果进行替换。
一个常用的例子是如下:
constexpr int factorial(int n) {
return n <= 1 ? 1 : (n * factorial(n - 1));
}
int main() {
auto num = factorial(10); // 编译阶段求得值,可从汇编查看
return 0;
}如果一个变量声明为constexpr,那么意味着在编译阶段就要获得其值,比如如下这个例子:
#include <iostream>
constexpr int factorial(int n) {
return n <= 1 ? 1 : (n * factorial(n - 1));
}
int main() {
int i = 10;
constexpr auto num = factorial(i);
return 0;
}因为num被声明为constexpr,所以正如前面所说,在编译阶段求值,又因为i是一个非常量表达式,所以编译器报错如下:
<source>: In function 'int main()':
<source>:10:35: error: the value of 'i' is not usable in a constant expression
10 | constexpr auto num = factorial(i);
| ^
<source>:9:8: note: 'int i' is not const
9 | int i = 10;
| ^
Compiler returned: 1if语句初始化
这个是自C++17才支持的,可以在if语句中进行初始化,随后进行条件判断,如下:
if (int a = 0; a != 10);也可以像下面这样:
std::vector<int> v;
// operation
if (auto size = v.size()); 引用赋值不会改变其初始指向
示例:
int x = 2, y = 3;
int &r1 = x;
int &r2 = y;
r1 = r2;
std::cout << x << " " << y << " " << r1 << " " << r2;在上述代码中,虽然最后r1被赋值为r2,但是其仍然指向x,这样的结果就是x的值也被修改了。最后输出结果为3 3 3 3
enum vs enum类
传统的enum,如果像下面这样定义:
enum Colors {
Red,
Green,
Blue
};
enum OtherColors {
Yellow,
Blue
};编译器会报如下错误:
<source>:16:5: error: 'Blue' conflicts with a previous declaration
16 | Blue
| ^~~~
<source>:11:5: note: previous declaration 'Colors Blue'
11 | Blue
| ^~~~为了解决这个问题,引入了enum class,如下:
enum class Colors {
Red,
Green,
Blue
};
enum class OtherColors {
Yellow,
Blue
};modules
示例如下:
// Vector.h:
class Vector {
public:
Vector(int s);
double& operator[](int i);
int size();
private:
double∗ elem; // elem points to an array of sz doubles
int sz;
};// Vector.cpp:
#include "Vector.h" // get Vector’s interface
Vector::Vector(int s) :elem{new double[s]}, sz{s} {
}
double& Vector::operator[](int i) {
return elem[i];
}
int Vector::size() {
return sz;
}// user.cpp
#include "Vector.h" // get Vector’s interface
#include <cmath> // get the standard-librar y math function interface including sqrt()
double sqrt_sum(Vector& v) {
double sum = 0;
for (int i=0; i!=v.siz e(); ++i)
sum+=std::sqr t(v[i]); // sum of square roots
return sum;
}最终格式如下:
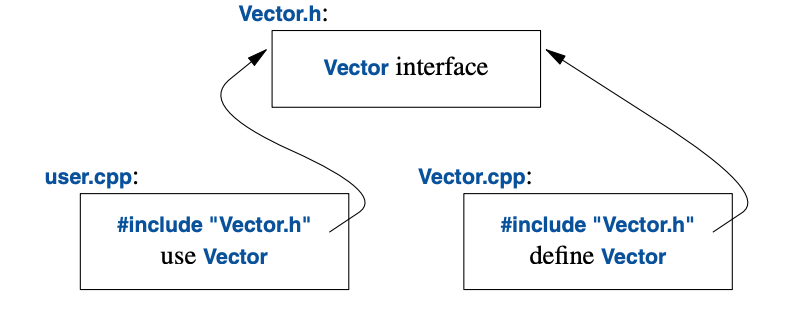
可以单独对user.cpp 和 Vector.cpp编译,生成.o文件,这是因为上述示例使用了#include操作,预处理器在遇到#include的时候,会将其中的内容完整的拷贝一份到相应的文件,这就导致每个.cpp都有头文件Vector.h的一个副本,代码体积膨胀不说,还增加了编译时间。
为了解决上述问题,引入了modules,使用module优化上述代码,如下:
// Vector.cpp
module;
export module Vector; // defining the module called "Vector"
export class Vector {
public:
Vector(int s);
double& operator[](int i);
int size();
private:
double∗ elem; // elem points to an array of sz doubles
int sz;
};
Vector::Vector(int s) :elem{new double[s]}, sz{s} {
}
double& Vector::operator[](int i) {
return elem[i];
}
int Vector::siz e() {
return sz;
}
expor t int size(const Vector& v) { return v.siz e(); }// user.cpp
import Vector; // get Vector’s interface
#include <cmath> // get the standard-librar y math function interface including sqrt()
double sqrt_sum(Vector& v) {
double sum = 0;
for (int i=0; i!=v.siz e(); ++i)
sum+=std::sqr t(v[i]); // sum of square roots
return sum;
}对于这块的内容,可以详细阅读之前的文章:
未来已来:C++ modules初探
纯虚函数
如果其中一个成员函数使用= 0,那么该函数为纯虚函数,继承于存在纯虚函数的子类,其必须实现该函数:
class Base {
public:
void fun() = 0;
};
class Derived : public Base {
public:
void fun() {}
}如果声明一个存在纯虚函数的类,那边编译器会报错如下:
<source>:21:8: error: initializer specified for non-virtual method 'void Base::fun()'
21 | void fun() = 0;
| ^~~派生
判断一个类是否继承于另外一个类,可以使用如下方式:
template<typename Base, typename T>
inline bool IsDerivedOf(T *ptr) {
return dynamic_cast<Base*>(ptr) != nullptr;
}智能指针
智能指针可以避免内存泄漏,此处文章较多,可以参考:
智能指针-使用、避坑和实现
一次诡异的内存泄漏
显式构造
对于如下这种:
class Vector {
public:
Vector(int sz);
}可以使用Vector v = 3;这种方式进行初始化,往往这种并不是我们希望看到的,所以可以使用关键字explicit来强制显式初始化:
class Vector {
public:
explicit Vector(int sz);
}move语义
自C++11起引入了move语义,不过这个很容易引起初学者的误解,其实move()本身并不做任何操作,其只是进行了简单的类型转换,而真正的移动操作需要类实现者进行定义。
STL对其定义如下:
template<typename _Tp>
constexpr typename std::remove_reference<_Tp>::type&&
move(_Tp&& __t) noexcept
{ return static_cast<typename std::remove_reference<_Tp>::type&&>(__t); }如果需要深入了解其特性,可以参考文章:
【Modern C++】深入理解移动语义
CTAD
CTAD为Class Template Argument Deduction的缩写,中文称为类模板参数推导,在C++17之前,我们需要像下面这样写:
std::pair<int, double> p1 = {1, 3.41};现在我们可以如下这样写:
std::pair p2 = {1, 3.41};可以参考文章【ModernCpp】新特性之CTAD
字面量
如果我们像下面这样写:
auto s = "hello";s会被编译器推导为const char*,为了使得其为std::string类型,有以下几种方式:
auto s1 = std::string("hello");
std::string s2 = "hello";
auto s3 = "hello"s;前两种方式比较常见,第三种方式是Modern cpp的新特性,俗称字面量。在这个语法中,"hello"是字符串字面值,而"s"是用户定义字面量的后缀,它将字符串字面值转换为std::string对象。
COW VS SSO
COW,想必大家都清楚其原理,这个机制很常用,比较常见的如fork等操作,在STL中也有用到这个,比如gcc5.1之前的string中,先看如下代码:
std::string s("str");
std::string s1 = s;
char *p = const_cast<char*>(s1.data());
p[2] = '\0';
std::cout << s << std::endl;
std::cout << s1 << std::endl;输出结果无非以下两种:
st
st或者
str
st第一种基于gcc5.1前的版本编译,第二种输出基于5.1之后的版本编译,这两个输出的不同正是源于gcc5.1之前的版本对于string的复制采用了COW操作。
自gcc5.1之后,字符串优化采用了新的机制,即SSO,其为Small String Optimization的简写,中文译为小字符串优化,基本原理是:当分配大小小于16个字节时候,从栈上进行分配,而如果大于等于16个字节,则在堆上进行内存分配