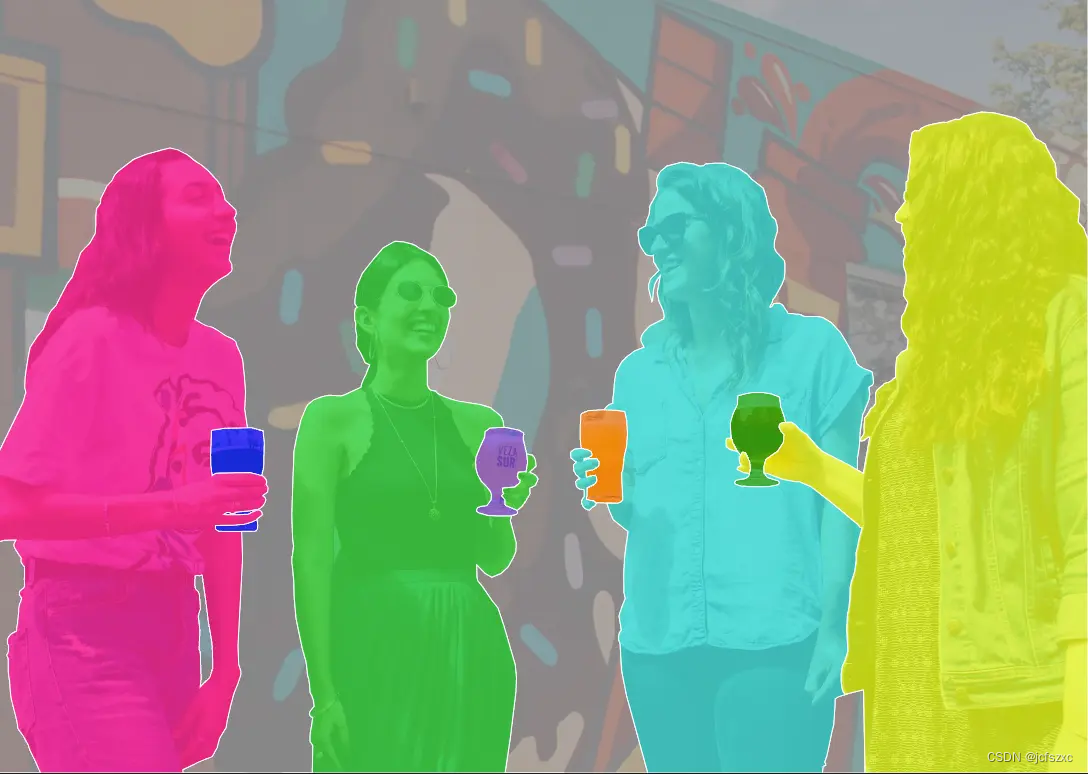PyTorch深度学习实战(26)——多对象实例分割
- 0. 前言
- 1. 获取并准备数据
- 2. 使用 Detectron2 训练实例分割模型
- 3. 对新图像进行推断
- 小结
- 系列链接
0. 前言
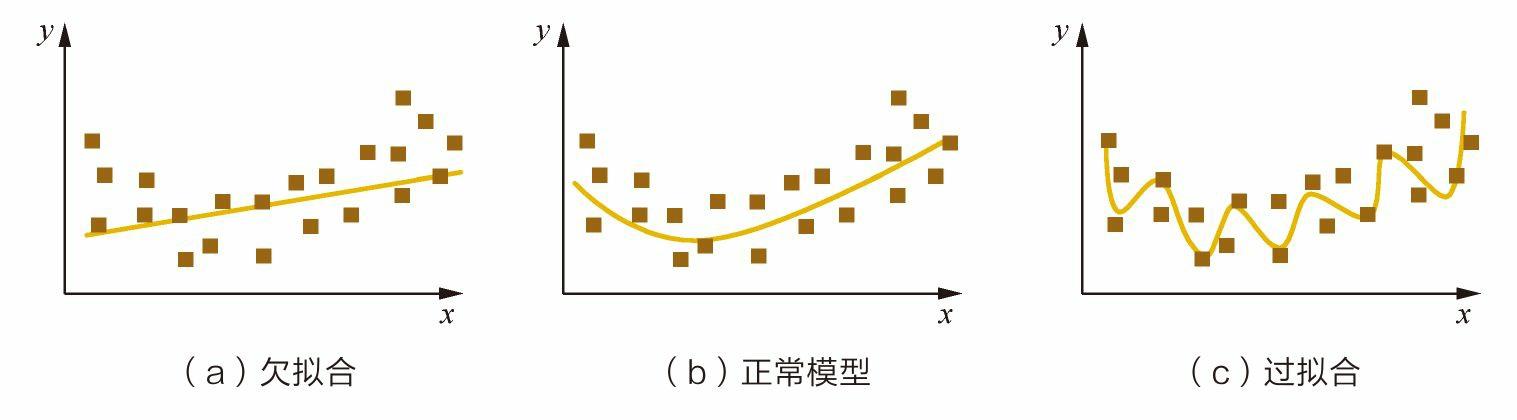
我们已经学习了多种图像分割算法,在本节中,我们将学习如何使用 Detectron2 平台以及 Google 开放图像数据集执行多对象实例分割任务。Detectron2 是 Facebook 团队打造的人工智能框架,其中包括了高性能的对象检测算法实现,包括 Mask R-CNN 模型等。Detectron2 支持一系列与目标检测和人体姿态估计等相关的任务,此外,Detectron2 还增加了对语义分割和全景分割的支持。通过利用 Detectron2,我们能够通过使用少量代码构建目标检测、分割和姿态估计模型。在本节中,我们将介绍如何从 Google 开放图像数据集中获取数据,将数据转换为 Detectron2 可接受的 COCO 格式,并训练模型执行实例分割,最后,介绍如何使用训练后的模型对新图像进行推理。
1. 获取并准备数据
Google 开放图像数据集 (Google Open Images) 是由 Google 开发和维护的一个大规模图像数据集,用于计算机视觉领域的研究和开发。该数据集包含了数百万张标记和分类的图像,涵盖了广泛的主题和场景。在本节中,我们使用 Google 开放图像数据集,为了减少训练的时间,我们仅仅使用其中一部分数据集,而不使用整个数据集。
(1) 安装所需的库:
pip install openimages
(2) 下载所需的标注文件,包括分割标注文件 train-annotations-object-segmentation.csv 和类别文件 dict.csv。
(3) 指定希望模型预测的类别 required_classes:
import pandas as pd
from glob import glob
import os
import numpy as np
import cv2
required_classes = 'person,dog,bird,car,elephant,football,jug,laptop,Mushroom,Pizza,Rocket,Shirt,Traffic sign,Watermelon,Zebra'
required_classes = [c.lower() for c in required_classes.lower().split(',')]
classes = pd.read_csv('dict.csv', header=None)
classes.columns = ['class','class_name']
classes = classes[classes['class_name'].map(lambda x: x in required_classes)]
(4) 获取 required_classes 对应的图像 ID 和掩码:
df = pd.read_csv('train-annotations-object-segmentation.csv')
data = pd.merge(df, classes, left_on='LabelName', right_on='class')
subset_data = data.groupby('class_name').agg({'ImageID': lambda x: list(x)[:2000]})
subset_data = ([y for x in subset_data.ImageID.tolist() for y in x])
subset_data = data[data['ImageID'].map(lambda x: x in subset_data)]
subset_masks = subset_data['MaskPath'].tolist()
考虑到海量数据集会增加训练成本,在 subset_data 中每个类别只使用 2000 张图像,我们也可以修改每个类别所用数据样本数量。使用以上代码,可以获取图像对应的 ImageId 和 MaskPath 值。接下来,我们继续从 Google 开放图像数据集中下载实际图像和蒙版。
(5) 下载掩码数据子集,Google 开放图像数据集有 16 个用于掩码 ZIP 文件,包括 train-masks-0.zip、train-masks-1.zip、train-masks-2.zip、train-masks-3.zip、train-masks-4.zip、train-masks-5.zip、train-masks-6.zip、train-masks-7.zip、train-masks-8.zip、train-masks-9.zip、train-masks-a.zip、train-masks-b.zip、train-masks-c.zip、train-masks-d.zip、train-masks-e.zip 和 train-masks-f.zip,下载以上 ZIP 文件。每个 ZIP 文件只包含 subset_masks 中的一些掩码,因此下载之后我们只读取所需掩码文件:
if not os.path.exists('masks'):
os.mkdir('masks')
def fname(file):
return file.split('/')[-1]
for c in '0123456789abcdef':
tmp_mask = 'train-masks-{}/*.png'.format(c)
tmp_masks = glob(tmp_mask)
items = [(m, fname(m)) for m in tmp_masks]
items = [(i,j) for (i,j) in items if j in subset_masks]
for i,j in items:
os.rename(i, f'masks/{j}')
(6) 下载 ImageId 对应的图片:
masks = glob('masks/*.png')
masks = [fname(mask) for mask in masks]
subset_data = subset_data[subset_data['MaskPath'].map(lambda x: x in masks)]
subset_imageIds = subset_data['ImageID'].tolist()
from openimages.download import _download_images_by_id
if not os.path.exists('images'):
os.makedirs('images')
_download_images_by_id(subset_imageIds, 'train', './images/')
(7) 压缩所有图像、掩码和标注文件并保存,用于以后模型训练:
import zipfile
files = glob('images/*.jpg') + glob('masks/*.png') + ['train-annotations-object-segmentation.csv', 'dict.csv']
with zipfile.ZipFile('data.zip','w') as zipme:
for file in files:
zipme.write(file, compress_type=zipfile.ZIP_DEFLATED)
if not os.path.exists('train'):
os.makedirs('train')
os.rename('images', 'train/myData')
os.rename('masks', 'train/annotations')
由于目标检测数据集有多种不同标注格式,为了标准化,Detectron 需要使用一种严格的训练数据格式。虽然可以使用自定义数据集格式并将其提供给 Detectron,但是将训练数据保存为 COCO 格式会使训练更加容易。这样,我们就在不改变训练数据的情况下利用其他训练算法(如 Detectron Transformers (DETR))。
(8) 以 COCO 格式定义所需类别:
import datetime
INFO = {
"description": "MyData2023",
"url": "None",
"version": "1.0",
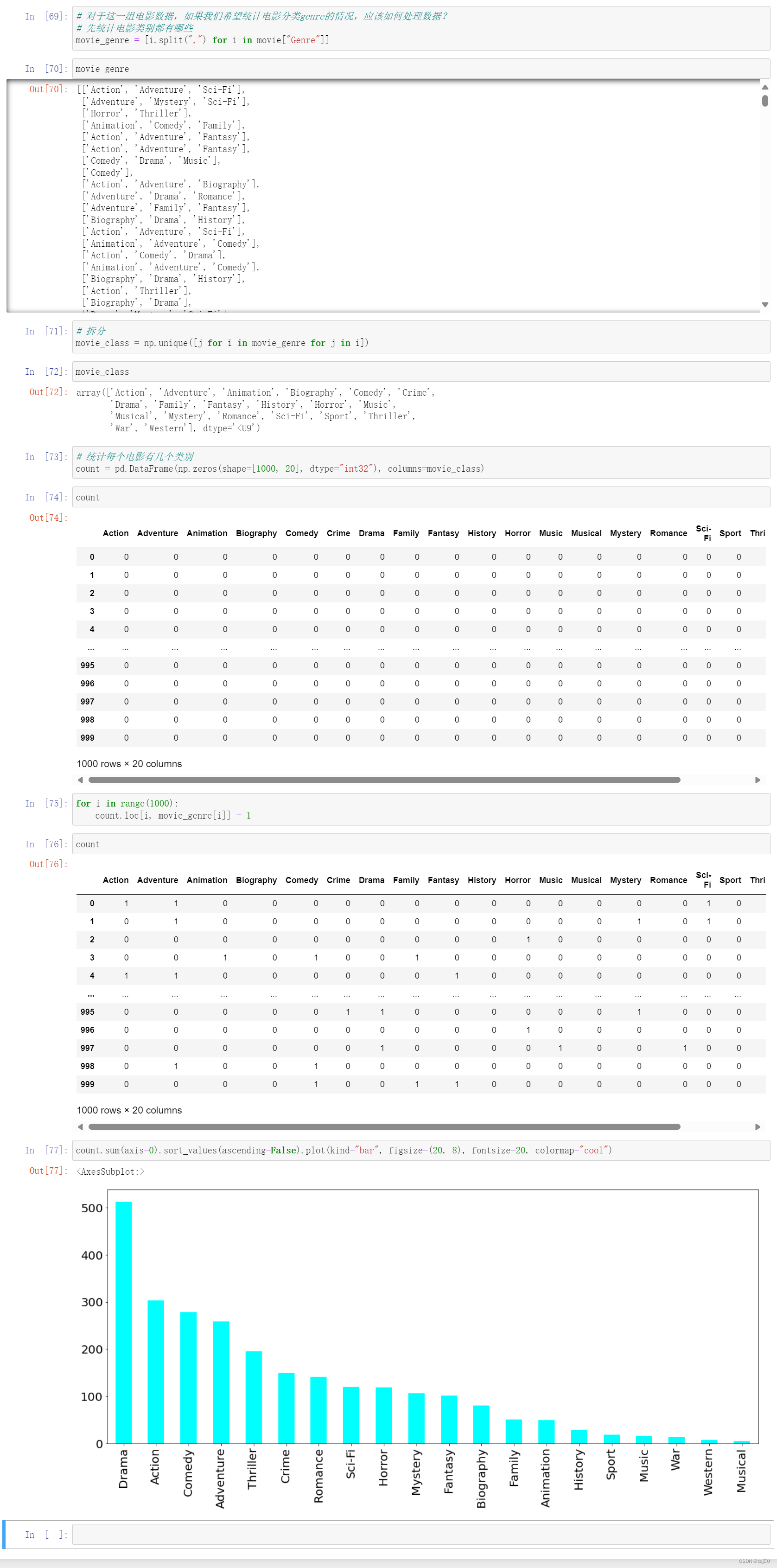
"year": 2023,
"contributor": "sizhky",
"date_created": datetime.datetime.utcnow().isoformat(' ')
}
LICENSES = [
{
"id": 1,
"name": "MIT"
}
]
CATEGORIES = [{'id': id+1, 'name': name.replace('/',''), 'supercategory': 'none'} for id,(_,(name, clss_name)) in enumerate(classes.iterrows())]
在以上代码中,在 CATEGORIES 的定义中,创建了一个名为 supercategory 的新键。例如: Man 和 Woman 类别都属于 Person 这个超类别。在本节中,由于我们对超类别不感兴趣,将其指定为 none。
导入相关库,并创建一个空字典,其中包含保存 COCO JSON 文件所需的键值:
from pycococreatortools import pycococreatortools
from os import listdir
from os.path import isfile, join
from PIL import Image
coco_output = {
"info": INFO,
"licenses": LICENSES,
"categories": CATEGORIES,
"images": [],
"annotations": []
}
定义包含图像位置和标注文件位置信息的变量:
ROOT_DIR = "train"
IMAGE_DIR, ANNOTATION_DIR = 'train/myData/', 'train/annotations/'
image_files = [f for f in listdir(IMAGE_DIR) if isfile(join(IMAGE_DIR, f))]
annotation_files = [f for f in listdir(ANNOTATION_DIR) if isfile(join(ANNOTATION_DIR, f))]
循环遍历每个图像文件名,并将信息填充到 coco_output 字典中的 images 键中:
image_id = 1
for image_filename in image_files:
image = Image.open(IMAGE_DIR + '/' + image_filename)
image_info = pycococreatortools.create_image_info(image_id, os.path.basename(image_filename), image.size)
coco_output["images"].append(image_info)
image_id = image_id + 1
(9) 循环遍历每个分段标注,并将信息填充到 coco_output 字典中的 annotations 键中:
def stem(filename):
return filename.split('.')[0]
segmentation_id = 1
for annotation_filename in annotation_files:
image_id = [f for f in coco_output['images'] if stem(f['file_name'])==annotation_filename.split('_')[0]][0]['id']
class_id = [x['id'] for x in CATEGORIES if x['name'] in annotation_filename][0]
category_info = {'id': class_id, 'is_crowd': 'crowd' in image_filename}
binary_mask = np.asarray(Image.open(f'{ANNOTATION_DIR}/{annotation_filename}').convert('1')).astype(np.uint8)
annotation_info = pycococreatortools.create_annotation_info(segmentation_id, image_id, category_info, binary_mask, image.size, tolerance=2)
if annotation_info is not None:
coco_output["annotations"].append(annotation_info)
segmentation_id = segmentation_id + 1
(10) 将 coco_output 保存在 JSON 文件中:
coco_output['categories'] = [{'id': id+1, 'name': clss_name, 'supercategory': 'none'} for id,(_,(name, clss_name)) in enumerate(classes.iterrows())]
import json
with open('images.json', 'w') as output_json_file:
json.dump(coco_output, output_json_file)
获取 COCO 格式的文件后,就可以很容易地使用 Detectron2 框架来训练模型。
2. 使用 Detectron2 训练实例分割模型
(1) 安装 Detectron2,在安装正确的库之前,首先应该检查 CUDA 和 PyTorch 版本,以 PyTorch 1.9 和 CUDA 11.3 为例,使用相应的文件:
$ pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu113/torch1.9/index.html
$ pip install pyyaml pycocotools
(2) 导入相关 detectron2 库:
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
from detectron2.engine import DefaultTrainer
重新获取所需的类:
required_classes = 'person,dog,bird,car,elephant,football,jug,laptop,Mushroom,Pizza,Rocket,Shirt,Traffic sign,Watermelon,Zebra'
required_classes = [c.lower() for c in required_classes.lower().split(',')]
cclasses = pd.read_csv('dict.csv', header=None)
classes.columns = ['class','class_name']
classes = classes[classes['class_name'].map(lambda x: x in required_classes)]
(3) 使用 register_coco_instances 注册创建的数据集:
from detectron2.data.datasets import register_coco_instances
register_coco_instances("dataset_train", {}, "images.json", "train/myData")
register_coco_instances 函数接受四个参数,第一个参数是数据集的名称,用于唯一标识该数据集;第二个参数是一个空字典,通常用于存储一些额外的元数据信息;第三个参数是标注文件的路径;最后一个参数是图像文件夹的路径。可以通过类似方式注册任意数量的数据集。
(4) 定义 Detectron2 配置文件 cfg 中的参数。
配置文件 (cfg) 是一个特殊的 Detectron 对象,它包含用于训练模型的所有相关信息:
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.DATASETS.TRAIN = ("dataset_train",)
cfg.DATASETS.TEST = ()
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml") # pretrained weights
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025 # pick a good LR
cfg.SOLVER.MAX_ITER = 8000 # instead of epochs, we train on 5000 batches
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 512
cfg.MODEL.ROI_HEADS.NUM_CLASSES = len(classes)
使用配置文件可以设置训练模型所需的所有主要超参数,merge_from_file 方法用于从配置文件导入核心参数,mask_rcnn_R_50_FPN_3x.yaml 配置文件使用以 FPN 作为主干网络进行预训练的 mask_rcnn,此配置文件还包含有关预训练模型的其他信息,例如优化器和损失函数。
(5) 训练模型:
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=True)
trainer.train()
训练完成后,可以使用该模型预测类别、边界框以及自定义数据集中定义的类别对象的分割掩码。
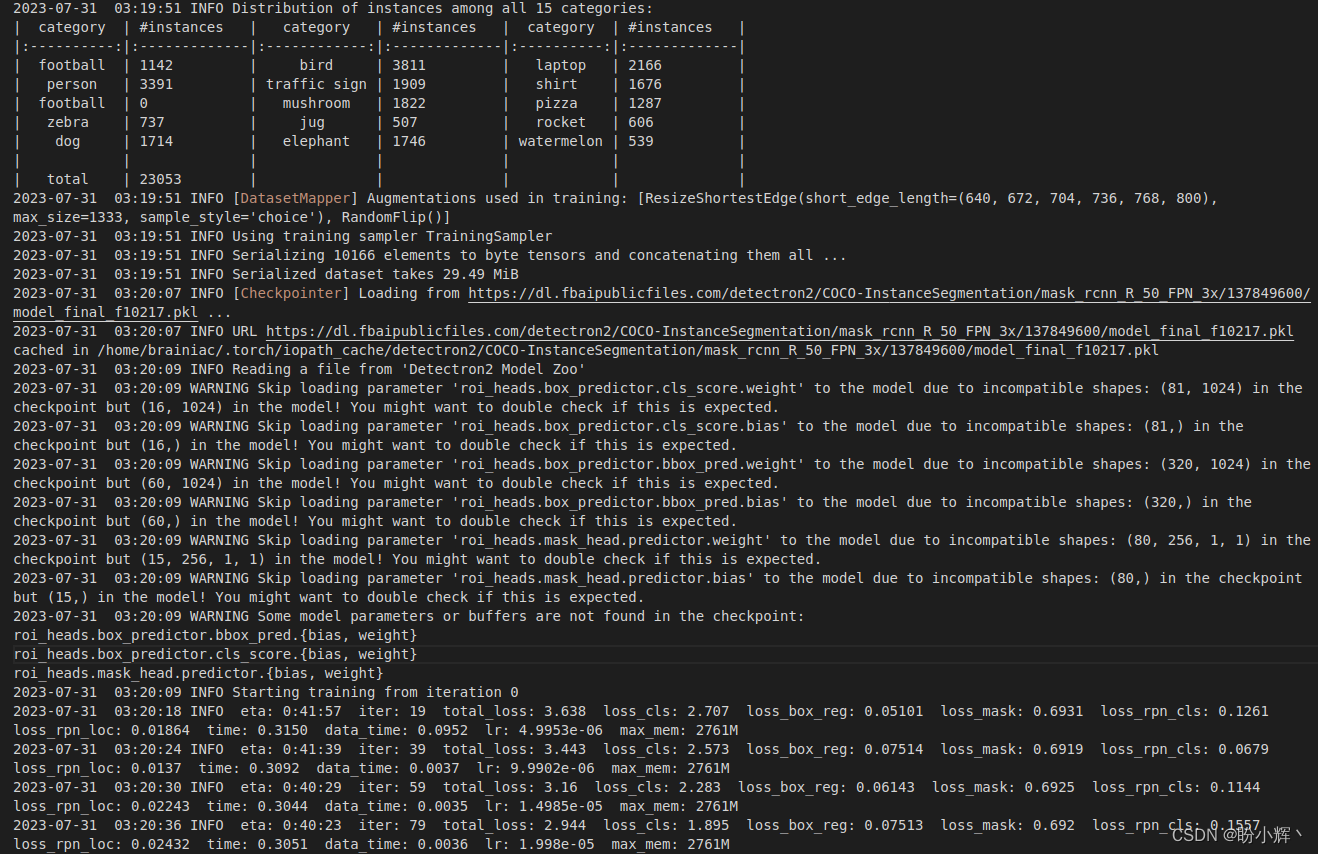
将模型保存在指定文件夹中:
import shutil
import random
from matplotlib import pyplot as plt
shutil.copy('output/model_final.pth', 'output/trained_model.pth')
模型训练完成后,在下一小节中,我们将对新图像进行推断。
3. 对新图像进行推断
为了对新图像进行推断,我们首先加载模型,设置概率阈值,并将其传递给 DefaultPredictor 方法。
(1) 加载训练好的模型权重,使用相同的 cfg 配置文件并加载模型权重:
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "trained_model.pth")
(2) 设置对象属于某一类别的概率阈值:
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.25
(3) 定义 predictor 方法:
predictor = DefaultPredictor(cfg)
(4) 对新图像进行分割并将其可视化。
加载图像文件,随机绘制 40 张图像分割结果:
from detectron2.utils.visualizer import ColorMode
files = glob('train/myData/*.jpg')
for _ in range(40):
im = cv2.imread(random.choice(files))
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1],
scale=0.5,
metadata=MetadataCatalog.get("dataset_train"),
instance_mode=ColorMode.IMAGE_BW
)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
plt.imshow(out.get_image())
plt.show()
Visualizer 是 Detectron2 绘制对象实例的方式,模型预测输出是张量字典,Visualizer 将它们转换为像素信息并将绘制在图像上。Visualizer 接受以下参数作为输入:
im:要可视化的图像scale:绘制图像的大小,在以上代码中,将图像缩小50%metadata:数据集的类别信息,主要是索引到类别的映射,用于将原始张量输入解码为人类的可读实际类别instance_mode:指定模型突出显示的分割像素
创建了 Visualizer 类对象后,就可以用其绘制模型的实例预测并显示图像,代码输出结果如下所示:
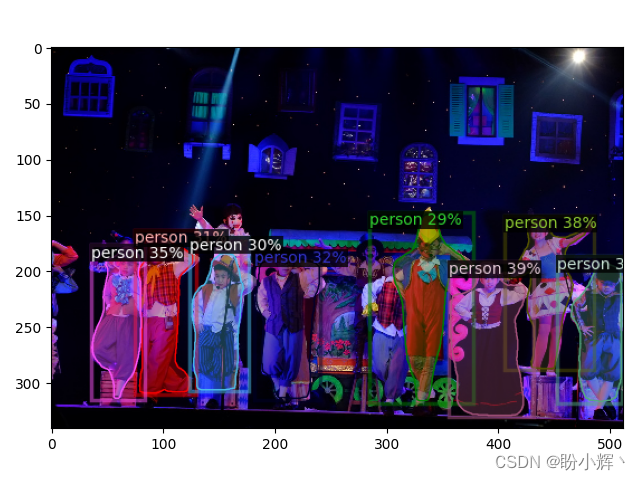
从以上输出可以看出,模型能够准确地识别出人物对应的像素。
小结
Detectron2 是用于计算机视觉任务的深度学习库,构建与 PyTorch 框架之上,并提供了一套灵活且高性能的工具,用于对象检测、实例分割和人体关键点检测等任务。其使用了先进的技术和优化策略,如特征金字塔网络、RoI Align 操作等,以提高模型的感受野和对小目标的检测能力。本节中,介绍了如何安装和使用 Detectron2 库,并通过使用 COCO 数据格式提高模型训练效率。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——使用U-Net架构进行图像分割
PyTorch深度学习实战(24)——从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(25)——自编码器(Autoencoder)
PyTorch深度学习实战(26)——卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(27)——变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(28)——对抗攻击(Adversarial Attack)
PyTorch深度学习实战(29)——神经风格迁移
PyTorch深度学习实战(30)——Deepfakes
PyTorch深度学习实战(31)——生成对抗网络(Generative Adversarial Network, GAN)
PyTorch深度学习实战(32)——DCGAN详解与实现
PyTorch深度学习实战(33)——条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(34)——Pix2Pix详解与实现