一、需求
1、现在我们有一组从2006年到2016年1000部最流行的电影数据
数据来源:https://www.kaggle.com/damianpanek/sunday-eda/data
2、问题1
想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
3、问题2
对于这一组电影数据,如果我们想看Rating、Runtime (Minutes)的分布情况,应该如何呈现数据?
4、问题3
对于这一组电影数据,如果我们希望统计电影分类genre的情况,应该如何处理数据?
二、实现
1、问题1
# 综合案例
movie= pd.read_csv("./IMDB-Movie-Data.csv")
movie
# 想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
# 评分的平均分
movie["Rating"].mean()
# 导演的人数信息
np.unique(movie["Director"]).size
2、问题2
# 对于这一组电影数据,如果我们想看Rating、Runtime (Minutes)的分布情况,应该如何呈现数据?
import matplotlib.pyplot as plt
# 创建画布
plt.figure(figsize=(20,8), dpi=100)
# 绘制直方图
plt.hist(movie["Rating"], 20)
# 修改刻度
max_ = movie["Rating"].max()
min_ = movie["Rating"].min()
plt.xticks(np.linspace(max_, min_, num=21))
# 添加网格
plt.grid(linestyle="--", alpha=0.8)
# 显示图像
plt.show()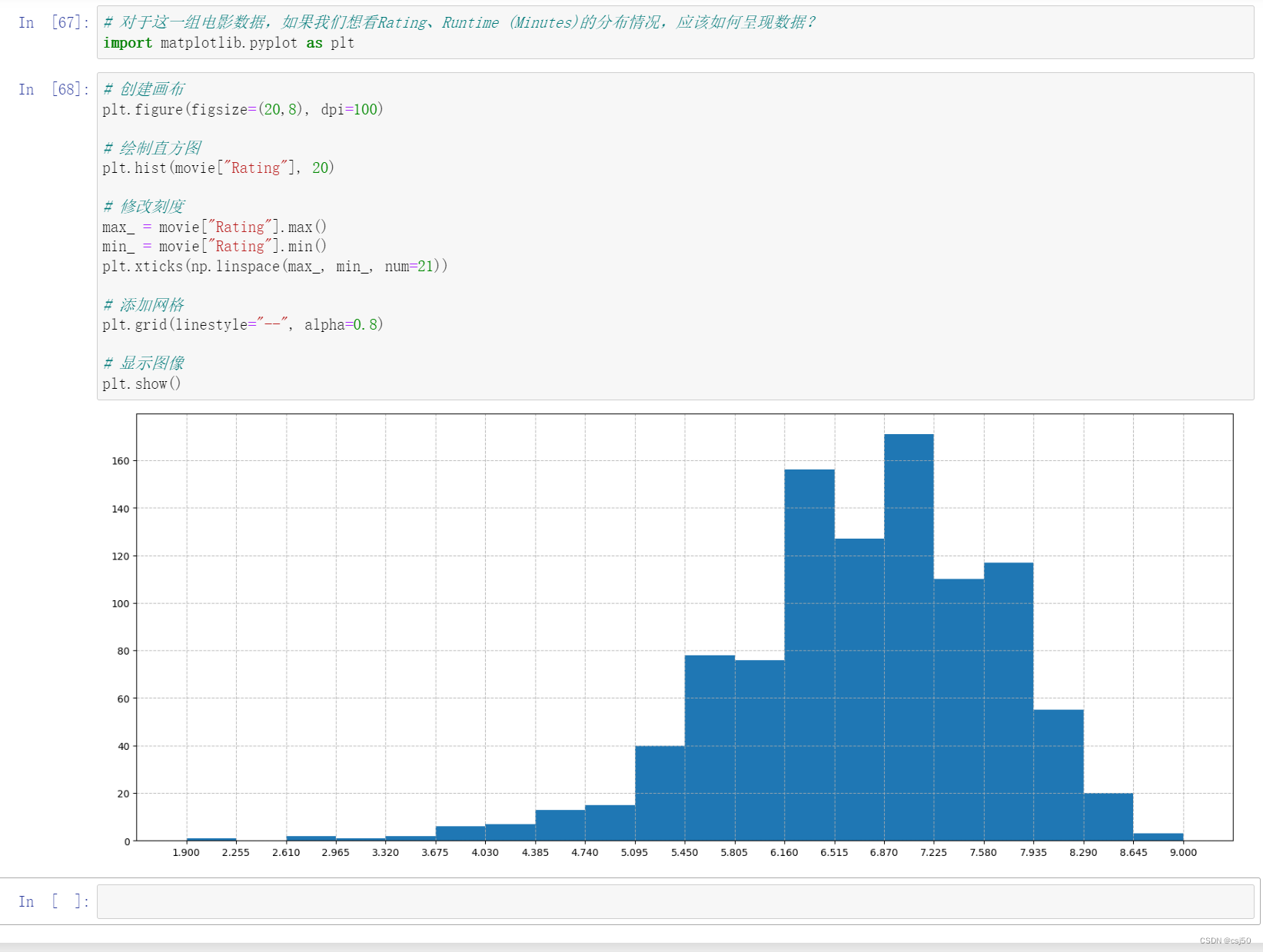
3、问题3
思路分析:
(1)创建一个temp_df,全为0的dataframe,列索引值为电影的分类
(2)遍历每一部电影,temp_df中把分类出现的列的值置为1
(3)求和
# 对于这一组电影数据,如果我们希望统计电影分类genre的情况,应该如何处理数据?
# 先统计电影类别都有哪些
movie_genre = [i.split(",") for i in movie["Genre"]]
movie_genre
# 拆分
movie_class = np.unique([j for i in movie_genre for j in i])
movie_class
# 统计每个电影有几个类别
count = pd.DataFrame(np.zeros(shape=[1000, 20], dtype="int32"), columns=movie_class)
count
for i in range(1000):
count.loc[i, movie_genre[i]] = 1
count
count.sum(axis=0).sort_values(ascending=False).plot(kind="bar", figsize=(20, 8), fontsize=20, colormap="cool")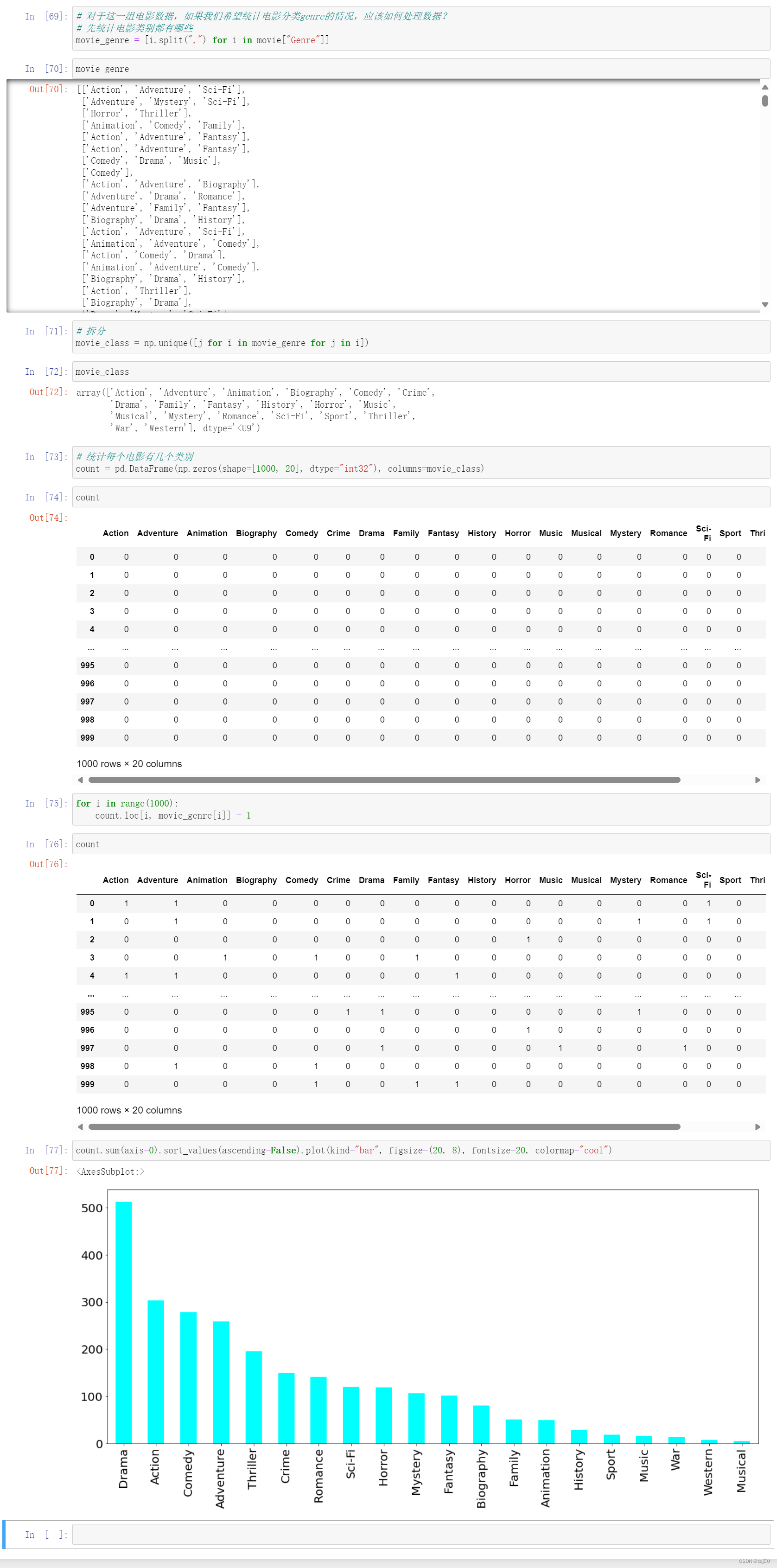
三、小结
pandas高级数据处理
缺失值处理
缺失值是NaN类型
判断是否存在np.nan缺失值
pd.isnull(df).any()
pd.notnull(df).all()
两种思路
删除df.dropna()
替换sr.fillna(value, replace=)
缺失值是其他默认符号
替换df.replace(to_replace="?", value=np.nan)
按照处理nan的步骤
数据离散化
分组
自动分组pd.qcut(data, bins)
自定义分组pd.cut(data, bins)
转换
pd.get_dummies(分好组的数据, prefix=)
数据合并
按方向合并
pd.concat((a,b), axis=)
按索引合并
pd.merge(left, right, how="inner", on=)
交叉表与透视表
pd.crosstab(value1, value2)
df.pivot_table([字段], index=)
分组与聚合
用dataframe.groupby(by=).聚合函数()
用sr.groupby(sr).聚合函数()