文章目录
- 10.1 机器学习在爬虫中的应用
- 10.1.1 重点基础知识讲解
- 10.1.2 重点案例:使用机器学习进行自动化内容抽取
- 10.1.3 拓展案例 1:利用深度学习识别复杂的网页结构
- 10.1.4 拓展案例 2:机器学习辅助的动态反反爬虫策略
- 10.2 处理 JavaScript 重度依赖的网站
- 10.2.1 重点基础知识讲解
- 10.2.2 重点案例:使用 Selenium 抓取动态内容
- 10.2.3 拓展案例 1:使用 Puppeteer 与 Pyppeteer
- 10.2.4 拓展案例 2:利用 Chrome Headless 模式进行高效抓取
- 10.3 爬虫技术的未来趋势
- 10.3.1 重点基础知识讲解
- 10.3.2 重点案例:使用机器学习模型进行智能内容抽取
- 10.3.3 拓展案例 1:利用云函数自动化爬虫任务
- 10.3.4 拓展案例 2:动态适配反爬虫机制的智能爬虫
10.1 机器学习在爬虫中的应用
机器学习技术的融入为爬虫领域带来了革命性的变革,使得爬虫不再仅仅依赖于硬编码的规则,而是能够学习和适应,从而更加智能化地处理复杂的数据抓取任务。
10.1.1 重点基础知识讲解
- 自动化内容抽取:通过机器学习模型,爬虫可以自动识别和抽取网页中的关键信息,比如文章标题、作者、发布日期等,无需手动编写抽取规则。
- 智能反反爬虫:机器学习模型可以帮助爬虫识别和适应网站的反爬虫机制,通过模拟人类用户行为或自动调整请求策略来绕过限制。
- 网页分类与识别:利用机器学习对网页进行分类,帮助爬虫快速识别目标数据所在页面,提高数据抓取的准确性和效率。
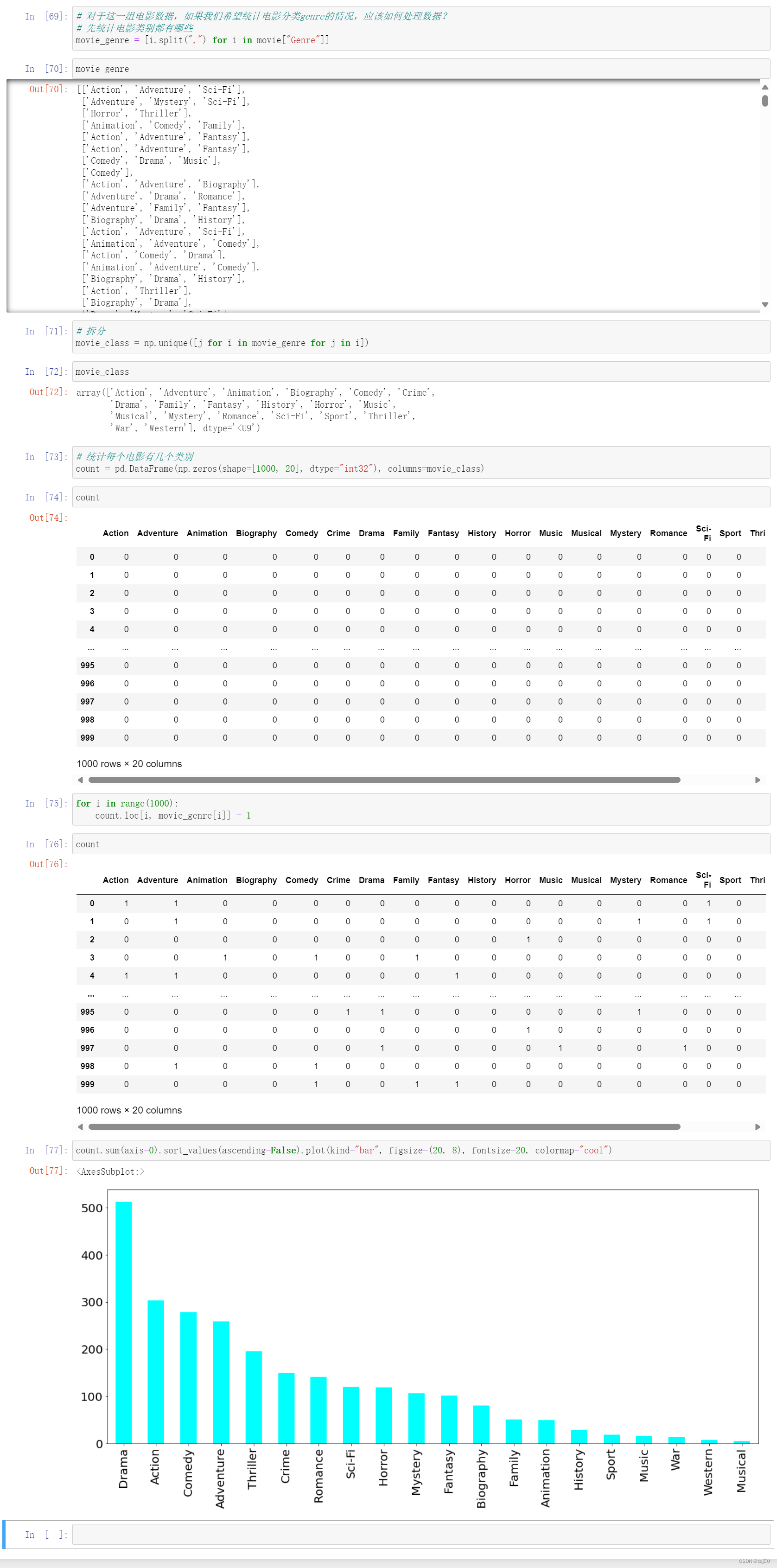
10.1.2 重点案例:使用机器学习进行自动化内容抽取
假设我们要从多个新闻网站抓取新闻文章,包括标题、作者和正文内容。我们可以使用机器学习模型自动识别这些元素。
# 使用 BeautifulSoup 解析 HTML,scikit-learn 构建分类器
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
# 假设有已标记的训练数据
train_data = [...] # 训练数据,格式为 [(html_content, label), ...]
labels = [...] # 标签,如 'title', 'author', 'content'
# 提取特征并训练模型
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
model.fit([d[0] for d in train_data], labels)
# 在新的网页上应用模型进行内容抽取
def extract_content(html):
soup = BeautifulSoup(html, 'html.parser')
predicted = model.predict([soup.get_text()])
return predicted[0] # 返回预测的标签
# 使用模型抽取内容
html = "<html>...</html>" # 新网页的 HTML 内容
content_label = extract_content(html)
print(f"抽取的内容标签: {content_label}")
10.1.3 拓展案例 1:利用深度学习识别复杂的网页结构
对于结构复杂或经常变化的网站,传统的基于规则的抽取方法可能不够有效。深度学习,尤其是卷积神经网络(CNN)和递归神经网络(RNN),可以用来识别和解析复杂的网页结构。
# 这是一个概念性代码示例
# 假设我们有一个训练好的深度学习模型来识别和解析网页内容
model = load_pretrained_deep_learning_model()
def parse_web_page(html):
# 将 HTML 内容转换为模型可接受的格式,如将标签转换为特征向量
features = convert_html_to_features(html)
# 使用模型预测网页结构
structure = model.predict(features)
return structure
html = "<html>...</html>" # 网页 HTML 内容
page_structure = parse_web_page(html)
print(f"网页结构: {page_structure}")
10.1.4 拓展案例 2:机器学习辅助的动态反反爬虫策略
随着网站反爬虫技术的不断进步,使用机器学习来自动调整爬虫的行为,以适应这些反爬虫机制变得尤为重要。
# 概念性代码示例
# 假设我们训练了一个模型来预测请求特定网站时最佳的请求间隔和请求头信息
model = load_adaptive_request_model()
def make_request(url):
# 使用模型预测最佳请求参数
request_params = model.predict_best_request_params(url)
response = requests.get(url, headers=request_params['headers'], timeout=request_params['timeout'])
return response
url = "http://example.com/data"
response = make_request(url)
print(f"响应状态码: {response.status_code}")
通过将机器学习技术应用于爬虫项目,我们可以大大提高爬虫的智能化程度和适应性,使其能够更有效地抓取和处理网络数据。随着技术的发展,我们期待机器学习在爬虫领域的应用会越来越广泛和深入。

10.2 处理 JavaScript 重度依赖的网站
随着现代网页技术的发展,越来越多的网站开始大量使用JavaScript来增强用户体验,实现动态内容加载。这对传统的基于HTML静态解析的爬虫构成了挑战,因为这些动态生成的内容在原始的HTML源代码中是不可见的。
10.2.1 重点基础知识讲解
- Headless浏览器:Headless浏览器是没有图形用户界面的浏览器,它能够完全在后台运行。使用Headless浏览器可以执行JavaScript,渲染页面内容,从而让爬虫能够抓取到动态加载的数据。
- Selenium:Selenium 是一个自动化测试工具,可以用来模拟用户在浏览器中的操作,如点击、滚动等,非常适合处理需要与页面交互才能加载数据的情况。
- Puppeteer:Puppeteer 是一个Node库,它提供了一套高级API来控制Headless Chrome或Chromium。虽然主要用于自动化测试,但也被广泛用于网页内容抓取。
10.2.2 重点案例:使用 Selenium 抓取动态内容
假设我们需要从一个通过点击按钮后才加载内容的网页中抓取数据,可以使用Selenium模拟点击操作并等待内容加载。
from selenium import webdriver
from time import sleep
# 初始化Chrome WebDriver
driver = webdriver.Chrome()
# 打开目标网页
driver.get("http://example.com")
# 模拟点击操作
button = driver.find_element_by_id("loadMore")
button.click()
# 等待页面加载
sleep(5)
# 获取动态加载的内容
content = driver.find_element_by_class_name("new-content")
print(content.text)
# 关闭浏览器
driver.quit()
10.2.3 拓展案例 1:使用 Puppeteer 与 Pyppeteer
对于Python开发者,Pyppeteer 提供了与Puppeteer相似的API,可以用来控制Headless浏览器抓取动态内容。
import asyncio
from pyppeteer import launch
async def fetch_dynamic_content(url):
browser = await launch()
page = await browser.newPage()
await page.goto(url)
await page.waitForSelector('.dynamic-content')
content = await page.querySelectorEval('.dynamic-content', 'node => node.innerText')
print(content)
await browser.close()
asyncio.get_event_loop().run_until_complete(fetch_dynamic_content('http://example.com'))
10.2.4 拓展案例 2:利用 Chrome Headless 模式进行高效抓取
对于需要频繁抓取大量页面的情况,使用Chrome的Headless模式可以提高效率,尤其是结合命令行工具或API进行自动化处理。
# 使用Chrome Headless模式的命令行示例
chrome --headless --disable-gpu --dump-dom http://example.com
在Python中,可以通过调用系统命令或使用相关库(如requests_html)来实现类似的功能,执行JavaScript并获取渲染后的页面内容。
通过这些方法,我们可以有效地处理那些JavaScript重度依赖的网站,获取动态生成的内容。这不仅扩展了爬虫的能力,也为数据抓取的领域开辟了新的可能性。随着技术的进步,我们期待会有更多高效和便捷的工具出现,帮助我们更好地探索数据的世界。

10.3 爬虫技术的未来趋势
随着互联网技术的快速发展,爬虫技术也在不断进化,以适应日益增长的数据需求和不断变化的网络环境。未来的爬虫技术将更加智能、高效,并在尊重数据隐私的前提下进行数据抓取。
10.3.1 重点基础知识讲解
- 人工智能与自然语言处理:集成AI和NLP技术的爬虫可以更好地理解网页内容的语义,提高数据抓取和处理的准确性。
- 分布式与云原生爬虫:随着云计算技术的普及,爬虫项目将更多地采用分布式架构和云原生技术,以提高抓取效率和降低运维成本。
- 反反爬虫策略:随着网站反爬虫技术的不断升级,爬虫需要采用更加智能化的策略来应对,包括动态IP切换、请求头伪装等。
- 合法合规的数据抓取:随着对数据隐私保护意识的增强,合法合规的数据抓取将成为爬虫开发的重要准则。
10.3.2 重点案例:使用机器学习模型进行智能内容抽取
利用机器学习技术,我们可以开发出能够自动识别和抽取网页特定信息的爬虫,无需为每个网站编写特定的解析规则。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
import numpy as np
# 假设我们已经抓取了一系列网页的文本内容
documents = ["网页1的内容", "网页2的内容", ...]
# 使用TF-IDF模型转换文本数据
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(documents)
# 应用K-Means算法进行文本聚类
true_k = 5
model = KMeans(n_clusters=true_k, init='k-means++', max_iter=100, n_init=1)
model.fit(X)
# 打印出每个聚类的前10个关键词
print("Top terms per cluster:")
order_centroids = model.cluster_centers_.argsort()[:, ::-1]
terms = vectorizer.get_feature_names_out()
for i in range(true_k):
print(f"Cluster {i}:")
for ind in order_centroids[i, :10]:
print(f' {terms[ind]}')
print()
10.3.3 拓展案例 1:利用云函数自动化爬虫任务
云函数(如 AWS Lambda、Google Cloud Functions)提供了一种运行爬虫任务的轻量级、低成本方法,无需管理服务器。
import boto3
# 创建AWS Lambda客户端
lambda_client = boto3.client('lambda')
# 调用云函数执行爬虫任务
response = lambda_client.invoke(
FunctionName='MySpiderFunction',
InvocationType='Event', # 异步执行
Payload=json.dumps({'url': 'http://example.com'})
)
10.3.4 拓展案例 2:动态适配反爬虫机制的智能爬虫
开发一个能够实时分析网站反爬虫策略并动态调整自身行为的爬虫系统,以提高数据抓取的成功率。
# 概念性示例,展示动态适配策略的基本思路
def fetch_url(url):
try:
response = requests.get(url, headers=generate_dynamic_headers(url))
# 分析响应,判断是否触发反爬虫机制
if detect_anti_scrap
ing_measures(response):
# 调整策略,如更换IP、修改请求头等
adjust_scraping_strategy()
return fetch_url(url) # 重新尝试抓取
return response
except Exception as e:
handle_error(e)
未来的爬虫技术将更加注重智能化、效率和合规性,同时,随着技术的进步,我们还将看到更多创新的应用场景。面对不断变化的网络环境和数据需求,持续学习和适应新技术将是每个数据探险家的必修课。