目录
19.ByteBuf
19.1 ByteBuf的基本使用
19.2 ByteBuf的扩容机制
19.3 ByteBuf与内存的关系
19.4 ByteBuf的内存结构
19.5 ByteBuf的API
19.5.1 ByteBuf的写操作
19.5.2 ByteBuf的读操作
19.5.3 ByteBuf的slice
19.6 ByteBuf的内存释放
19.6.1 实现API
19.6.2 如何释放?
20.Tomcat的Servlet和SpringMVC的Controller 之间的关系
21.半包粘包(半包黏包)
21.1 什么是半包粘包?
21.2 网络通信架构
21.3 ByteBuf数据处理
21.4 Netty中半包粘包的解决方案
21.4.1 FixedLengthFrameDecoder
21.4.2 LineBasedFrameDecoder
21.4.3 DelimiterBasedFrameDecoder
21.4.4 LengthFieldBasedFrameDecoder
21.4.4.1 情况1
21.4.4.2 情况2
21.4.4.3 情况3
21.4.4.4 情况4
21.4.4.5 情况5
21.4.4.6 代码实操 【头体分离+帧解码器完美解决,最常用,最好用的解决半包粘包问题的方法】
19.ByteBuf
19.1 ByteBuf的基本使用
ByteBuf其实就类似于我们在NIO中学习到的ByteBuffer,是网络通信的过程中传递消息数据的一个数据结构。底层数据存储的数据结构,而在Netty中它也进一步封装了ByteBuffer,也就是ByteBuf,它的功能比ByteBuffer更加强大了。下面说一下都增强了哪些地方:
1.ByteBuf可以自动扩容,以前的ByteBuffer是固定长度的
2.提供了读写指针,方便操作,ByteBuffer没有读写指针,所以需要切换读写的为止,来回切换读写模式,读模式flip,写模式clear,compact或者新建一个
3.内存的池化,减少了内存的重新申请,销毁,提供了复用性
4.零拷贝的优化,netty中的零拷贝尽可能的少占用内存
- 代码
package com.messi.netty_core_02.netty05;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.ByteBufUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class TestByteBuf {
private static final Logger log = LoggerFactory.getLogger(TestByteBuf.class);
public static void main(String[] args) {
//ByteBufAllocator.DEFAULT.buffer() 可以传参,也可以不传参,不传参的话默认大小为256字节
//要是传了最大值上限限定,那么就按照你传递的最大值为准,那么后续ByteBuf的扩容最多扩到你设置的最大值
//如果不传递最大值,那么按照默认的最大值为准,默认的最大值为:Integer.MAX_VALUE
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer(8);
// 写数据进入ByteBuf
byteBuf.writeByte('a');
byteBuf.writeInt(1);
byteBuf.writeInt(2);
byteBuf.writeInt(3);
byteBuf.writeInt(4);
log.info("byteBuf为:{}",byteBuf) ;
log.info("ByteBufUtil.prettyHexDump(byteBuf):{}",ByteBufUtil.prettyHexDump(byteBuf));
}
}- 测试结果
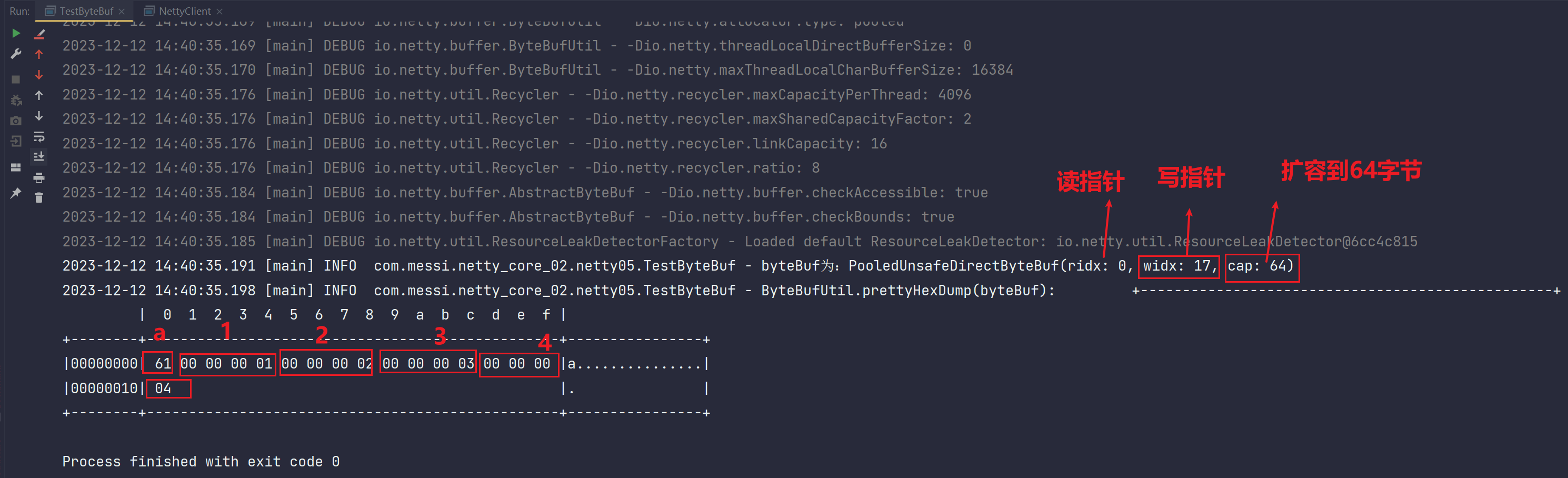
我们看到输出的ByteBuf的写指针widx的位置目前是17,ByteBuf的长度目前扩容到了64,我们初始化设置的只是8个字节。现在随着写入已经扩容到了64字节。
我们再来看下面的那个表,上面的0-f只是表头标识位置的,16个。
下面中间的位置,我们看到第一个16进制61,每个数是四位,两个就是一个字节。61的意思就是a的assic码值。
下面我们写入了1-4四个整形数,每个整形数长度为4个字节,也就是16进制的8个数,
所以就是00 00 00 01这就是那个1
00 00 00 02就是那个写入的2
00 00 00 03就是那个写入的3
00 00 00 04就是那个写入的4
这就对上了,这就是我们写入的情况,而写指针长度位置为17就是我们写入了a 和 1-4一共17个字节。扩
容到了64,这个扩容到64的算法巨几把复杂,但是他就是扩到了64,不是32。
- 细节
为什么使用十六进制表示?
我们再存储一个1000整型值,占用4个字节大小。
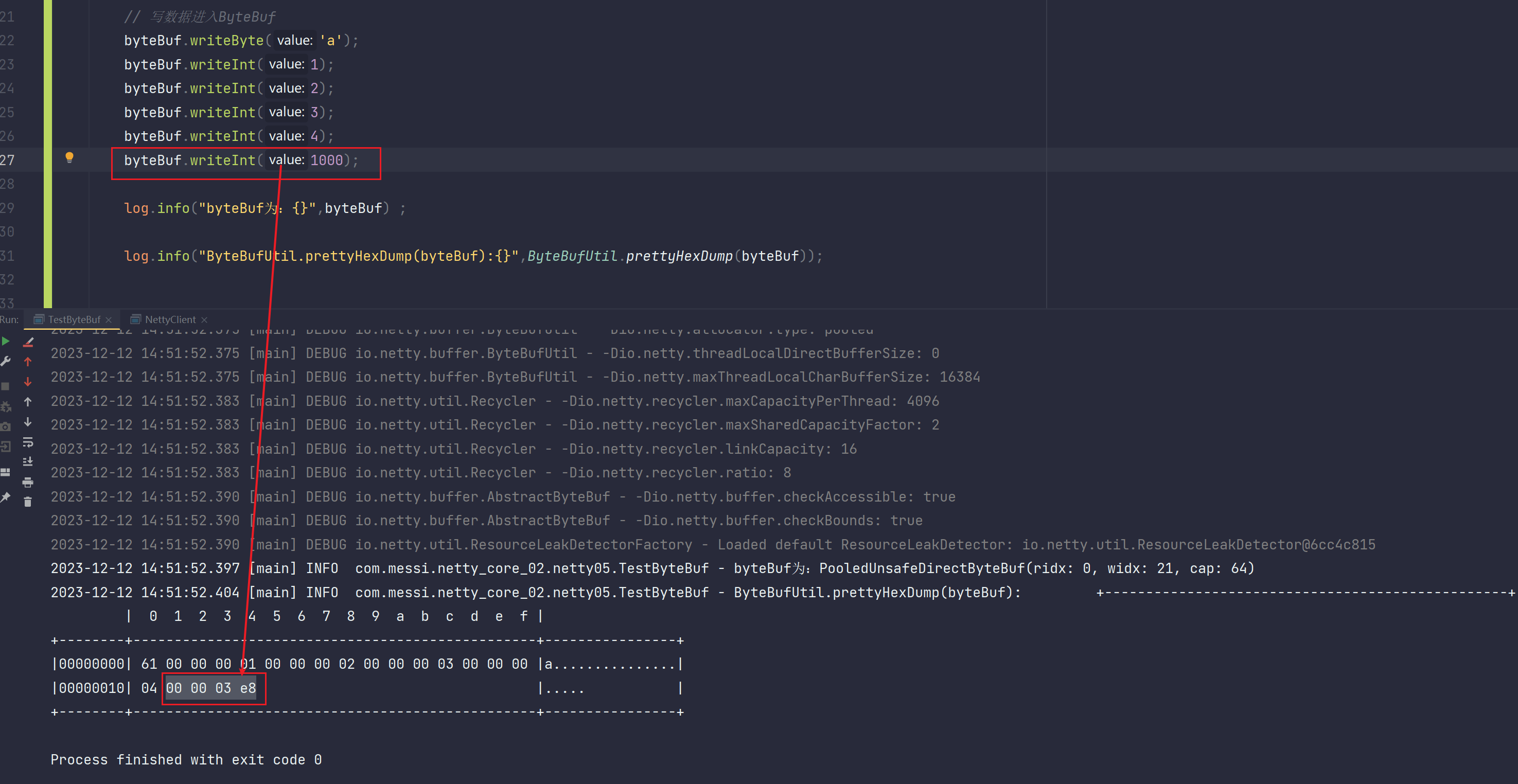
我们知道,一个字节占用8bit,四个字节占用32bit
一bit用一个二进制位可以表示,所以四字节需要32个二进制位可以表示,所以四字节需要8个十六进制位可以表示
两个十六进制位表示一个字节,两个为一组
当存储1000时,十六进制位存储如图所示:00 00 03 e8 ---》3*16*16+e*16+8=3*16*16+15*16+8=1000
为什么e=15?
常识。a=10,b=11.。。。。。。。
chatgpt回答如下所示:

为什么使用十六进制表示?
十六进制在计算机中被广泛使用,特别是在表示字节数据时。它提供了一种紧凑且易读的方式来表示字节的值,对于编程、调试和通信都非常方便。
19.2 ByteBuf的扩容机制
自动扩容,有规律吗?没有
当超过初始容量后,开始扩容,一开始以4的n次方大小进行不断扩容。4的n次方扩容到64字节后,之后不再按照4的n次方扩容,而是按照原数据大小的二倍进行不断扩容。
猜测一下为什么这样?
n次方增长会导致到后续扩容量级别越来越大,每n次方扩容一次,增长的量级太巨大!为了避免内存容量的浪费,所以后续以二倍不断的扩容,而不是4的n次方。
package com.messi.netty_core_02.netty06;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.ByteBufUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class TestByteBuf {
private static final Logger log = LoggerFactory.getLogger(TestByteBuf.class);
public static void main(String[] args) {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer(10);
for (int i = 0; i < 65; i++) {
byteBuf.writeByte(1);
}
log.info("byteBuf为:{}",byteBuf);
log.info("ByteBufUtil.prettyHexDump(byteBuf):{}",ByteBufUtil.prettyHexDump(byteBuf));
}
}
自己测试一下,体会一下ByteBuf扩容的过程。
19.3 ByteBuf与内存的关系
我们知道ByteBuffer是ByteBuf的前身,而ByteBuffer是可以操作堆内存和直接直接内存的。这个概念ByteBuf也是有的,ByteBuf也涉及到这两个概念。
但是默认情况下,ByteBuf创建的是直接内存,可见,Netty比NIO更想要高效。
而且我们知道直接内存就是操作系统内存,不是JVM进程所管理的堆内存,那么对于java来说,那你操作这块内存虽然可以使用映射不用从用户态切换到内核态,也减少了一次数据拷贝,性能是高的,但是实际上你创建的这块直接内存以及销毁这块内存的代价是比堆内存这种JVM自己管理的内存代价是要高出很多很多的。最直观的就是你不能通过JVM的GC管理了,需要你自己去管理这一块操作系统直接内存。
也因为不是堆内存,所以这块内存不会影响GC,所以这块内存的操作不会给GC造成压力
那么ByteBuf是怎么处理直接内存和堆内存的呢?来看下面这组简单的API:
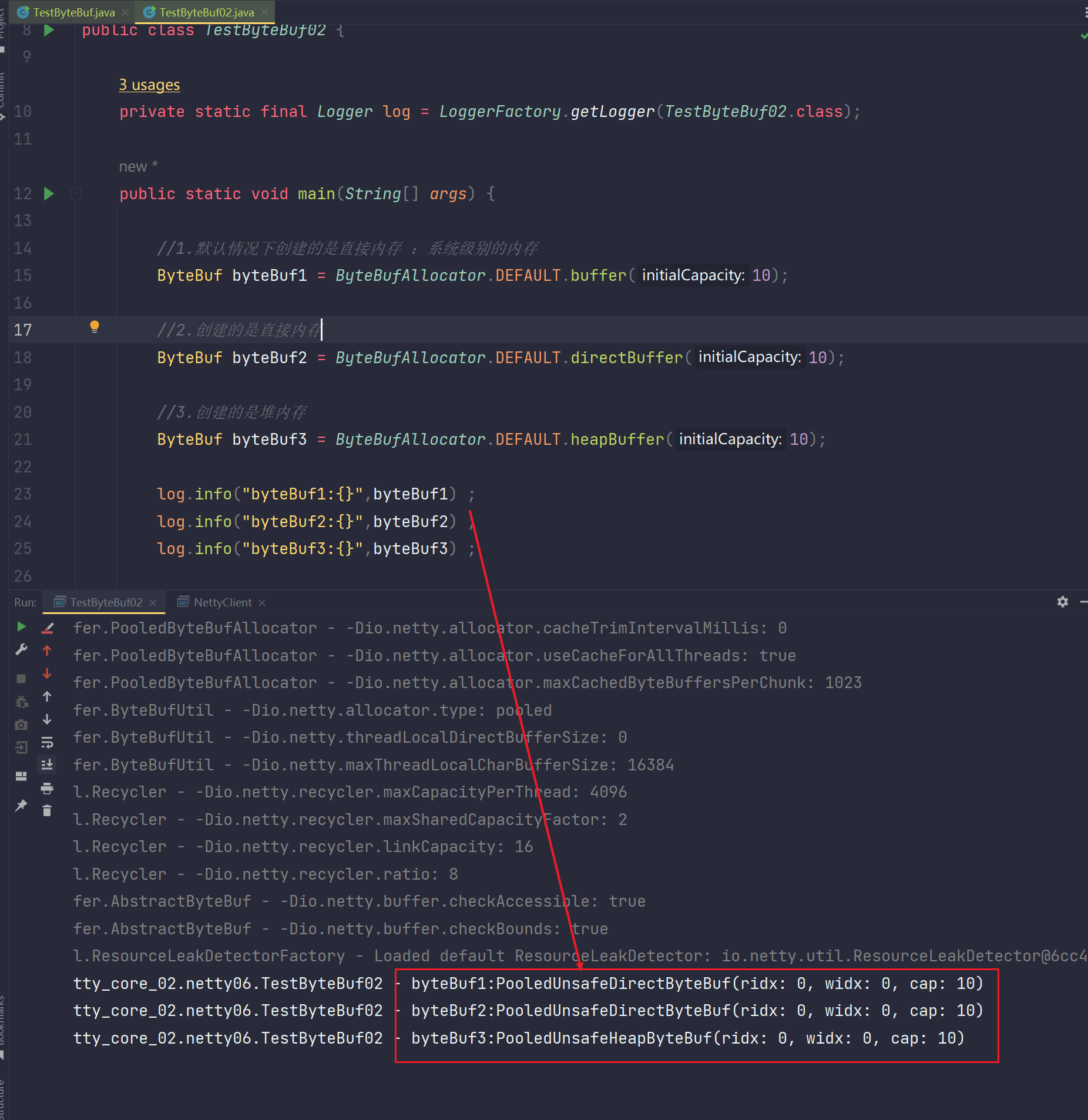
而且我们看到输出的每一个类型前面都是Pool开头的,这个意思就是池化的意思,这就引出我们的ByteBuf的一个特性就是池化的概念。内存ByteBuf池化和线程池池化是一样的,都是可以减少创建的频率,不用在使用时创建,提前创建好,后面开辟内存时直接从池子里面拿就行,它可以在程序初始化启动的时候把池子创建好。把这个创建放到了开始,预先创建好,不用的时候再放回到池子中,不必销毁。后面谁再用谁从池子中拿,不用频繁的创建或销毁,达到复用的效果。
ByteBuf池化是如何池化的?ByteBuf这个池子是怎么做的?
如果ByteBuf是直接内存的话,申请和释放等这些管理,底层都是调用native方法,native方法具体的实现,netty是整合jemalloc这一内存管理器来工作的。jemalloc不仅用在这里,同样可以用作redis的内存管理。
redis的安装是通过源码编译的,是通过make指令,所以redis要想使用jemalloc作为内存管理的话,使用make进行编译redis源码安装时要进行指定相关的参数,如:make -MALLOC=jemalloc (指定内存管理器为jemalloc)
补充:
make和make install的区别:make肯定就是编译源码成二进制,然后计算机就可以识别执行该二进制,redis就运行起来了。
make install相当于windows下的Path设置,设置完后,就可以在任意目录启动redis。

补充:
内存池化减少了内存溢出的可能性,因为约束池子了,不用你到处创建,从池子里拿,被控制了上限。就像Connection连接池一样,预先创建定量的数据库Connection连接,然后同理复用,大量减少开销,避免频繁的创建和销毁。
补充:针对ByteBuf的最大值,最好要进行手动设置并且设置一个合理的值!
举个例子:每一个客户端连接服务端,针对每一个客户端请求,服务端都会分配一个独立的ByteBuf来存储这次请求所对应产生的数据。
如果ByteBuf的最大值设置的不合理(或使用默认最大值),并且为自动扩容,那么可能ByteBuf会不断扩容。如果客户端并发很高的话,ByteBuf则会分配很多份,并且一直扩容,那么JVM进程的内存可能会被压爆。
- 补充:实战,netty如何设置为非池化?
上面我们提到了关于netty内存池化的概念,Bytebuf的池子是里面有很多这个Bytebuf空间预先申请。实际上Netty在4.1版本之前池化是默认关闭的。之后的版本都是默认开启的。当然你可以手动关闭这个池化概念。
-Dio.netty.allocator.type=pooled(开启)/unpooled(关闭):这个启动参数可以关闭池化。这个参数加上就看到你的输出不再有pool这个前缀了。
演示:



- 补充:数据库Connection连接池



IPC和RPC之间有啥区别?


19.4 ByteBuf的内存结构
之前我们操作ByteBuffer的时候,读写数据时,需要切换读写模式,因为他是依赖于position的移动来处理数据写入和读取的位置的。十分麻烦,且容易出错。
但是ByteBuf改变了这个现状,它内部使用了读写的双指针,读就单独通过读指针来控制位置,写就单独通过写指针来控制即可。以前是读和写都依赖position。现在各控制各的,不用你来回切换位置来转换了。
在日志中打印输出一下读写指针:

如下:
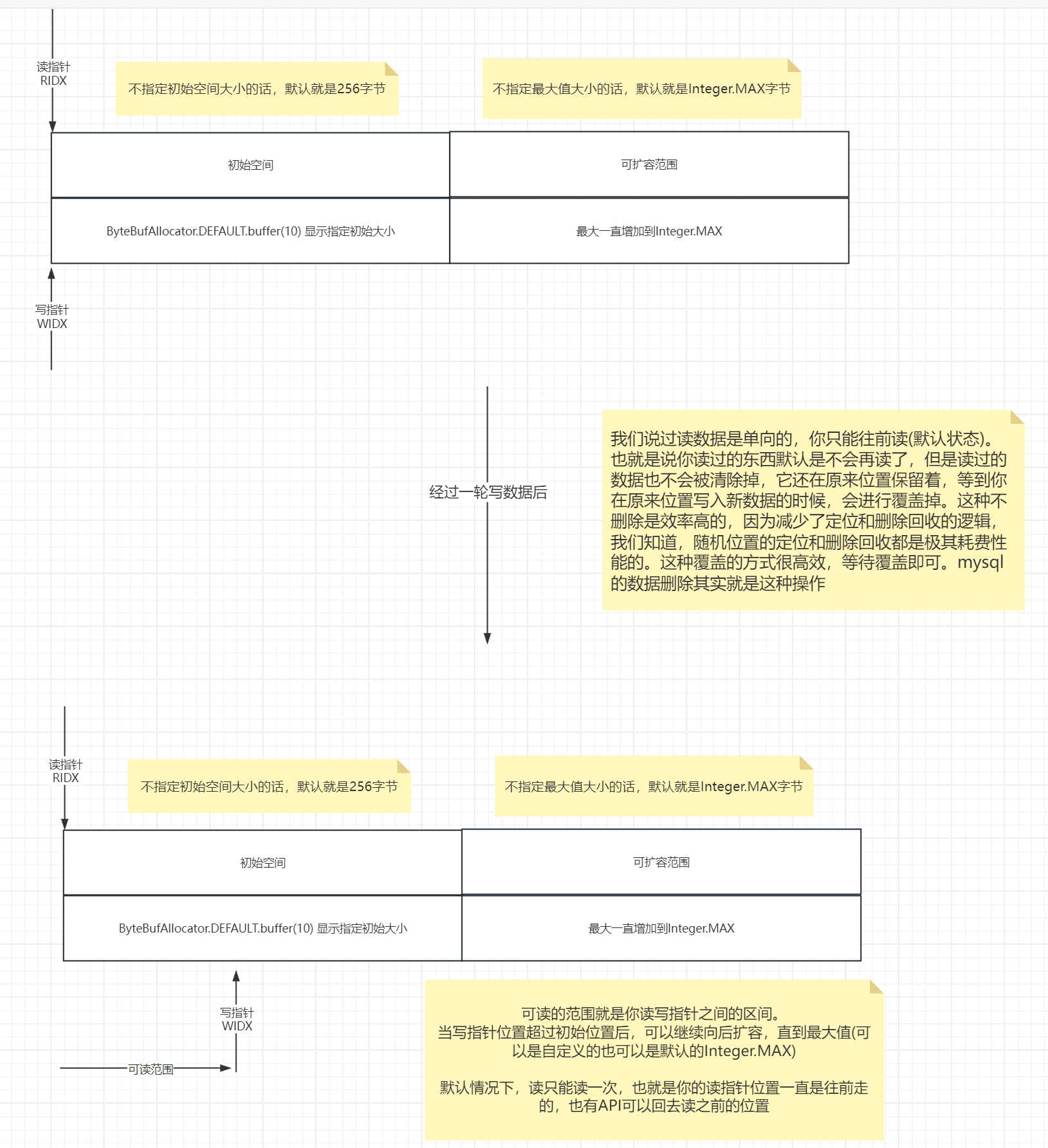
注:
ByteBufAllocator.DEFAULT.buffer(10,30)---->
第一个参数:ByteBuf的初始值大小,默认为256字节,这里显示指定为10字节
第二个参数:ByteBuf最大扩容到多少字节,默认为Integer.MAX,这里显示指定为30字节
19.5 ByteBuf的API
ByteBuf封装了一组读写数据的API,如下
19.5.1 ByteBuf的写操作
public abstract ByteBuf writeInt(int var1);
...
public abstract ByteBuf writeBytes(ByteBuf var1);
...
第一组是写入byte或者byte数组,或者直接就是Int double这类的,只不过Int写入是四个字节,
double是8个字节。这一组写入会改变写指针的位置。
public abstract ByteBuf setIndex(int var1, int var2);
这个是直接指定位置写入对应数据,这个写入是不改变写指针的位置的。而且你这个set的位置不能超过写指针位置,不然就写不进去。
19.5.2 ByteBuf的读操作
1.和写数据一样,readByte是读取数据的,只能是顺序读,每一次read都是挨着读的,他是可以改变读指针位置
2.get是可以获取指定位置的数据,但是不改变读指针的位置。
注意读指针位置不能超过写指针,汇报越界异常
- 代码演示
package com.messi.netty_core_02.netty06;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.ByteBufUtil;
public class TestByteBuf03 {
public static void main(String[] args) {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer(10);
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
// byteBuf.writeByte(1);//写入一个字节
// System.out.println(byteBuf);
// System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
// System.out.println("---------------------------------");
//
// byteBuf.writeInt(10);//写入一个int(4个字节)
// System.out.println(byteBuf);
// System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
// System.out.println("---------------------------------");
// 在给定的示例中,byteBuf.setIndex(9, 9) 设置了读索引和写索引的位置都为 9。
// 这意味着在接下来的操作中,读取和写入都将从索引位置 9 开始。
byteBuf.setIndex(9,9);
byteBuf.writeByte(1);//写入一个字节
byteBuf.writeByte(1);//写入一个字节
byteBuf.writeByte(1);//写入一个字节
byteBuf.writeByte(1);//写入一个字节
byteBuf.writeByte(1);//写入一个字节
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
byteBuf.readByte();//获取一个字节的大小 读指针+1
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
byteBuf.getByte(0);//使用get获取,读指针不改变
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
}
}- 细节
代码:
package com.messi.netty_core_02.netty06;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.ByteBufUtil;
public class TestByteBuf04 {
public static void main(String[] args) {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer(10);
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
byteBuf.writeByte('a');
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
byteBuf.readByte();
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
byteBuf.readByte();
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
}
}
运行结果:
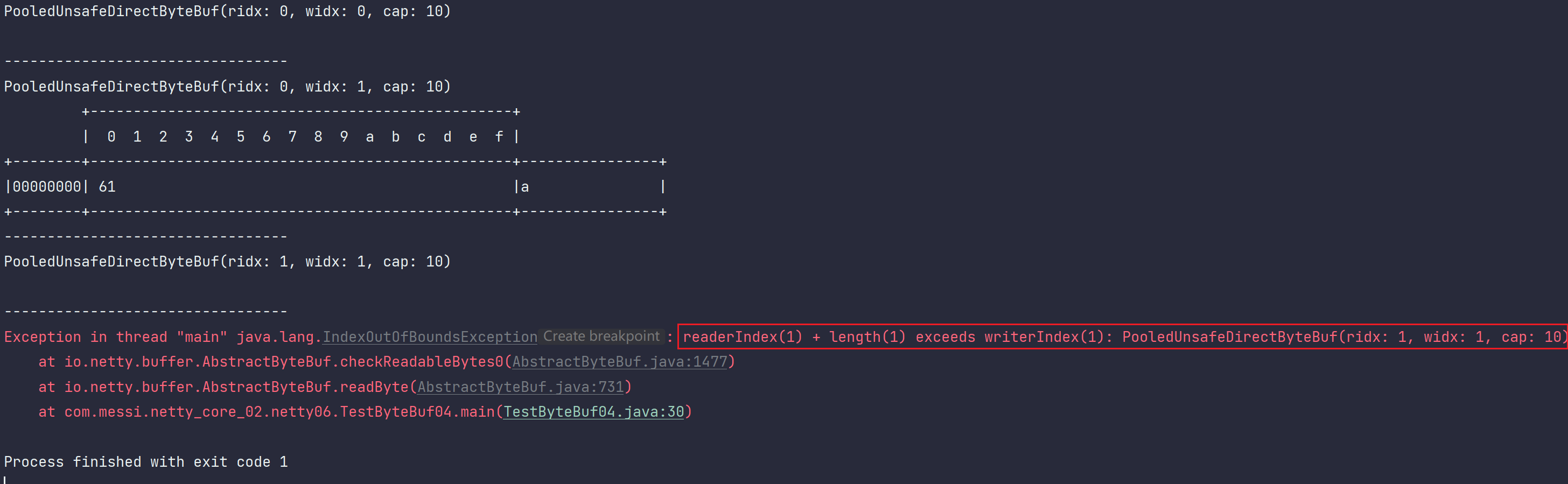
分析:
当你初始化一个ByteBuf的时候,此时读写指针都是0,重合自然也就不输出16进制占用。
PooledUnsafeDirectByteBuf(ridx: 0, widx: 0, cap: 10)
当你写入一字节之后,读指针为0,写指针为1,此时看输出。

当你读取1字节的时候,此时读指针为1,写指针也为1,重合,16进制不输出
PooledUnsafeDirectByteBuf(ridx: 1, widx: 1, cap: 10)
当你再读取的时候,就报异常,读指针越界了,超过了写指针。
如果此时我还想回去读一下1怎么办,可以打标记。或者直接使用get,get直接读取位置为0的位置
即可。因为写入是从位置0写入的。
也可以通过打标记的形式,读写都可以通过打标记来,我们这里只看一下读:
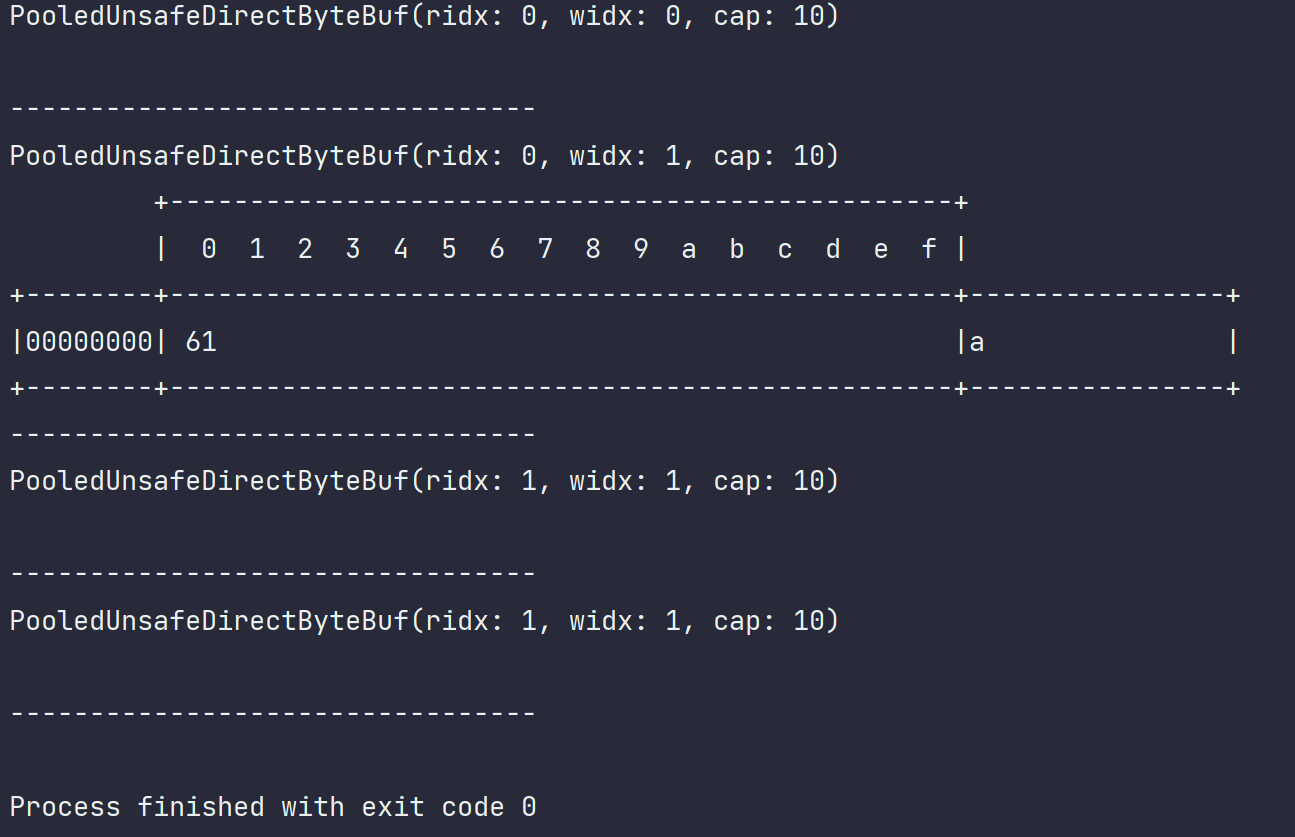
public class TestByteBuf04 {
public static void main(String[] args) {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer(10);
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
byteBuf.writeByte('a');//写入1字节 写指针+1
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
byteBuf.markReaderIndex();//在这里打一个读取标记,标记就是此处的读取指针的位置,为0
byteBuf.readByte();//读取1字节 读指针+1
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
byteBuf.resetReaderIndex();//这里重置读指针位置,回到标记时候的位置也就是0
//再读取1字节,此时就不会再报读取异常错误了。。。
byteBuf.readByte();
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("---------------------------------");
}
}运行结果:
19.5.3 ByteBuf的slice
切片机制
需求:
我们有一个ByteBuf,里面有十个字符,如果我们要求前五个字符去做a操作,后三个字符去做b操作。
常见的做法就是把前五个复制出来到新的一个ByteBuf1,把后三个复制出来到另外一个ByteBuf2中,这样我们使用ByteBuf1去做操作a,ByteBuf2去做操作b。但是这就增加了两次拷贝,,提高了开销成本
于是Netty提供了切片机制,看代码:
这个切片机制可以让你获取ByteBuf的局部数据,而且不会创建新的ByteBuf结构
- 代码
- 运行结果
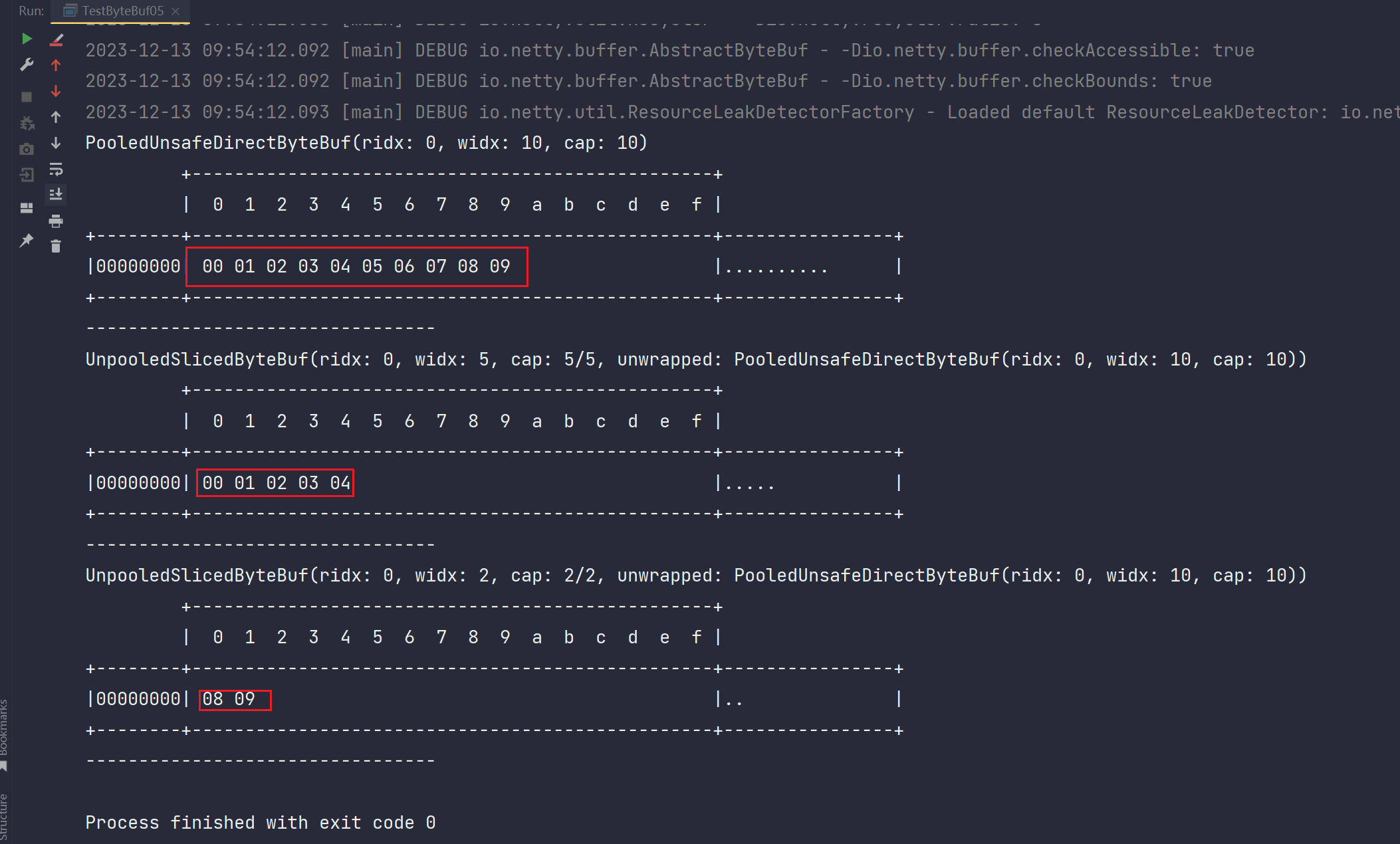
(1)第一个红圈:
初始化10个数据,读指针为0,写指针为10
(2)第一个红圈:
读指针为0,写指针为5,总共5个数据,也就是前五个数据:00 01 02 03 04
(3)第一个红圈:
同理即可
而且我们看到每一个新的ByteBuf1和ByteBuf2,其实都是有了一组新的读写指针,他们的本质是在原来ByteBuf上面产生了一套各自新的读写指针,各自指向它们自己所在分片的数据,不再产生新的ByteBuf,各自通过自己的读写指针来维护自己能获取的数据。
这种我们在实际开发也可以使用这种思路,不用非得创建新的空间,以新的指针标识就行,指针的开销就小了很多。
而且每个切片里面输出的 cap: 2/2是这种形式,最初的是cap: 10这种。
- 我们来验证一下是不是使用的是原来的ByteBuf,没有开辟新的空间呢?
public class TestByteBuf06 {
public static void main(String[] args) {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer(10);
for (int i = 0; i < 10; i++) {
byteBuf.writeByte(i);
}
System.out.println(byteBuf);
System.out.println(ByteBufUtil.prettyHexDump(byteBuf));
//申请分片
ByteBuf byteBuf1 = byteBuf.slice(0, 5);
ByteBuf byteBuf2 = byteBuf.slice(8, 2);
//先申请分片,然后这里释放掉byteBuf
byteBuf.release();
//这里我们按道理 已经申请到了分片ByteBuf,要是分片产生了新空间的话,这里自然不受byteBuf释放的影响
System.out.println(ByteBufUtil.prettyHexDump(byteBuf1)) ;
System.out.println(ByteBufUtil.prettyHexDump(byteBuf2)) ;
}
}运行结果:

我们在上面申请完了分片之后,释放这个ByteBuf这里我们按道理已经申请了,要是产生了新空间自然不受上面释放的影响,看下输出。上面输出会报错,就是因为他本质是一个空间没产生新的,所以你上面释放之后下面再获取就失败异常了。
所以我们要避免这样的错误回收,因为还有很多需要的人在引用着这块ByteBuf空间的,所以就要增加引用计数器,如下代码:
package com.messi.netty_core_02.netty06;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.ByteBufUtil;
public class TestByteBuf07 {
public static void main(String[] args) {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer(10) ;
for (int i = 0; i < 10; i++) {
byteBuf.writeInt(i);
}
System.out.println(ByteBufUtil.prettyHexDump(byteBuf)) ;
System.out.println("初始化的byteBuf引用计数器为:" + byteBuf.refCnt()) ;
//申请完了分片之后
ByteBuf byteBuf1 = byteBuf.slice(0, 5);
//因为分片使用了byteBuf这一ByteBuf空间,所以要增加引用计数+1,此时计数就为2,初始值为1
//因为它们是同一块ByteBuf空间,所以增加的其实就是byteBuf,此时byteBuf计数为2
byteBuf1.retain();
System.out.println("byteBuf1增加1之后的byteBuf引用计数器为:" + byteBuf.refCnt());
ByteBuf byteBuf2 = byteBuf.slice(8, 2);
//同理分析即可; 此时byteBuf计数为3
byteBuf2.retain();
System.out.println("byteBuf2增加1之后的byteBuf引用计数器为:" + byteBuf.refCnt());
//由于申请分片的时候,我们对所引用的ByteBuf空间:byteBuf1和byteBuf2分别进行计数+1
//但是我们知道:分片实际上引用的也是同一ByteBuf空间:byteBuf。所以实际上byteBuf的计数变为3
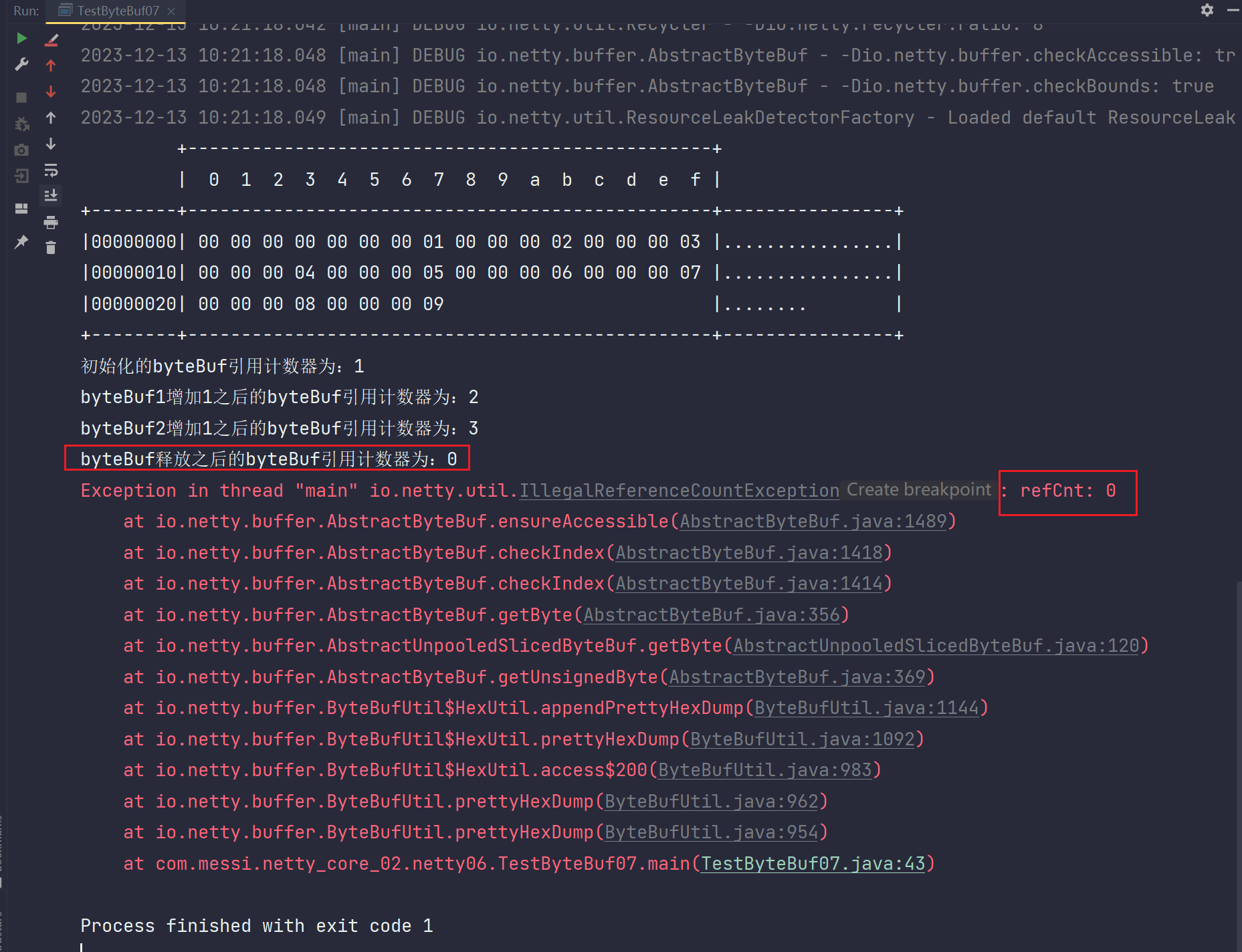
//这里要释放byteBuf内存,调用一次release(),byteBuf计数减1,所以3-1=2,byteBuf空间依然存在
byteBuf.release();
System.out.println("byteBuf释放之后的byteBuf引用计数器为:" + byteBuf.refCnt());
//引入计数器后,在byteBuf释放一次后,byteBuf1和byteBuf2都不受影响
System.out.println(ByteBufUtil.prettyHexDump(byteBuf1));
System.out.println(ByteBufUtil.prettyHexDump(byteBuf2));
}
}运行结果:

补充:
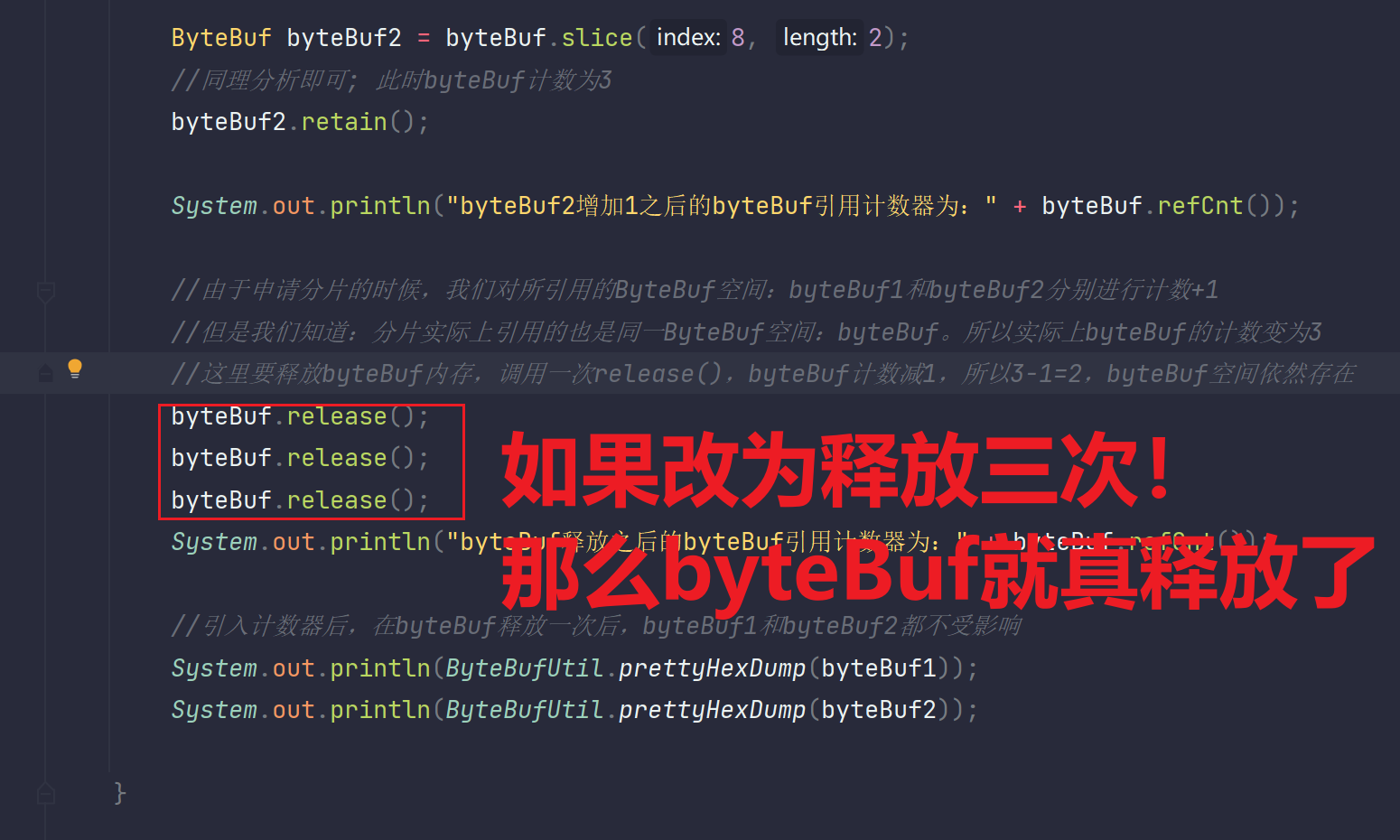
由于byteBuf真释放掉了,所以byteBuf1和byteBuf2所对应的指针就不能再引用byteBuf这一空间了,所以就报错了。
19.6 ByteBuf的内存释放
19.6.1 实现API
#内存释放的种类,ByteBuf可以申请堆内存和直接内存,而且可以内存池化,那么我们就从以下几个角度来分析一下:
1.堆内存,你就算释放了也得等待GC回收。所以释放不是立即就回收了,而且也要遵循GC的机制
2.直接内存,直接内存就是操作系统内存,操作系统内存的回收也会有系统的机制,也不是说立即就回收的
以上两种内存netty都是可以进行池化的,如果是池化的内存更加不会销毁,就是放回池子中等待下一个使用
#基于以上的分析,我们可以知道,内存释放不等于销毁这块内存,也可能就是立即释放 [ 可能正好赶上GC或者系统回收了]
正式因为这种复杂繁多的释放方式,所以netty就为了约束开发手段,给用户更加方便的操作入口,netty统一封装了一个回收接口。设计了统一的内存释放接口
这个接口就是ReferenceCounted,这个接口的实现提供了对于对象的引用计数的功能。ByteBuf就实现了这个接口,我们来看一下:
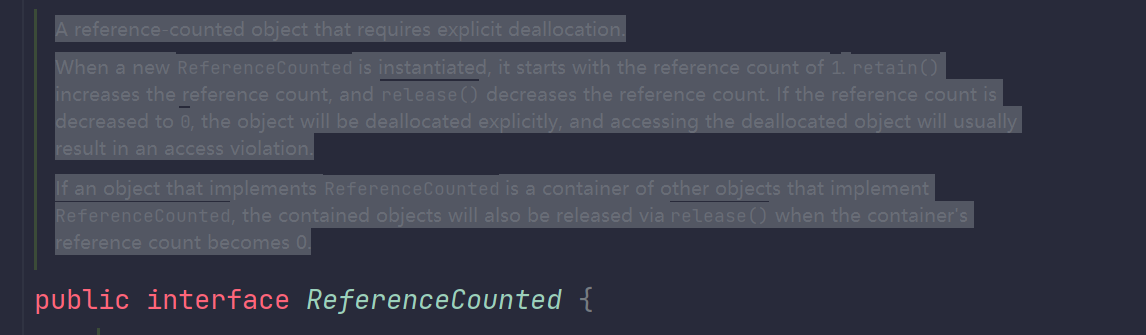
A reference-counted object that requires explicit deallocation.
When a new ReferenceCounted is instantiated, it starts with the reference count of 1. retain() increases the reference count, and release() decreases the reference count. If the reference count is decreased to 0, the object will be deallocated explicitly, and accessing the deallocated object will usually result in an access violation.
If an object that implements ReferenceCounted is a container of other objects that implement ReferenceCounted, the contained objects will also be released via release() when the container's reference count becomes 0.
----》使用Deepl翻译一下
需要显式删除的引用计数对象。
当实例化一个新的引用计数对象时,它的引用计数从 1 开始。retain() 会增加引用计数,release() 会减少引用计数。如果引用计数减少到 0,该对象将被明确地解除分配,而访问解除分配的对象通常会导致访问违规。
如果一个实现了 ReferenceCounted 的对象是其他实现了 ReferenceCounted 的对象的容器,那么当容器的引用计数变为 0 时,所包含的对象也将通过 release() 被释放。
------》
以上操作都是需要显式的,举个例子:
ByteBuf是实现了ReferenceCounted接口的,所以他就有这个功能:
所以当我们创建出来ByteBuf的时候,ByteBufAllocator.DEFAULT.buffer();此时的reference count引用计数就是1
然后当你在使用ByteBuf之后再调用一下byteBuf1.retain()就会计数器+1
然后当你调用byteBuf1.release()会减一,这样就会维护这个计数器的个数。
当计数器为0的时候就会被回收了。只是我们前面一直使用的main方法,运行完就结束了,所以就不需要做,实际开发需要维护这个,底层源码肯定也做了这个实现。
19.6.2 如何释放?
上面说了,我们使用main方法的时候这个程序结束自己就释放了,你进程都没了。
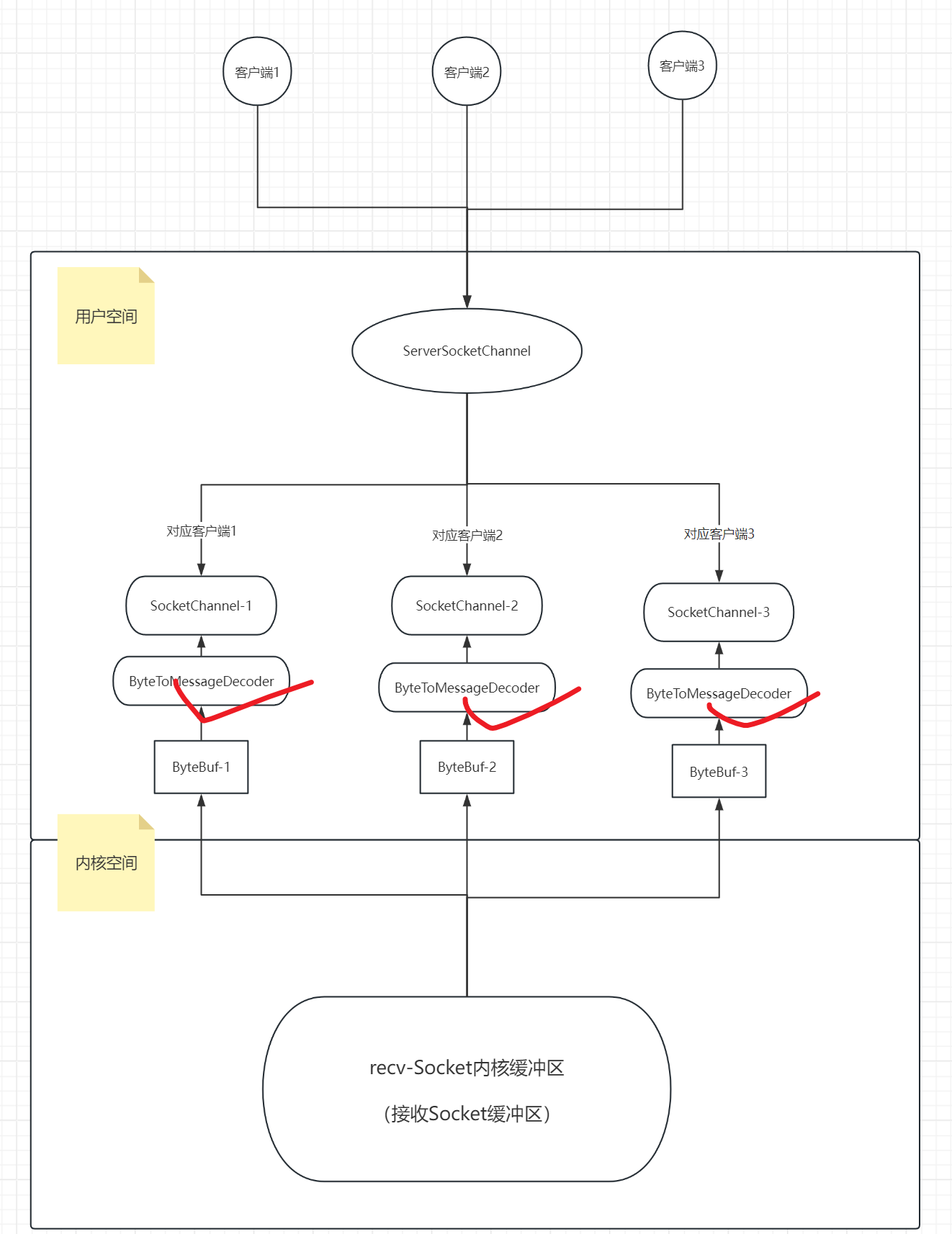
但是实际开发的时候,在一个web环境里面,你如何释放,或者netty如何帮我们释放,我们先来回顾一下在netty中哪里使用了ByteBuf。我们说过数据从客户端编码之后被发送去客户端,服务端拿到的就是ByteBuf,然后服务端再解码为字符串。所以其实就是服务端代码在用,那我们来看一下服务端的一个架构图。

重点分析:
Handler就是处理数据的,netty中的数据就是存在于ByteBuf这一数据结构中,ByteBuf基于内存。但是ByteBuf只限于在netty中使用,当你在handler中处理完了之后,需要转为其他框架能读写的类型再传出,ByteBuf是netty特有的数据类型,你不可能让spring框架使用你这个ByteBuf类型的数据吧?所以你需要在Handler处理器中把ByteBuf类型数据进行解码成字符串类型或json字符串,意思就是把ByteBuf类型转换成不依赖任何框架都能读取的数据类型,这样无论是spring框架还是其他框架都可以读取成功。
如果类推到Web的MVC三层架构,其实netty可以充当的角色为Controller层,通过网络通信IO读取到客户端发来的数据后,在netty中以ByteBuf类型进行封装这一网络二进制数据,然后在Handler中把ByteBuf转换成Service层可以识别读取的数据类型,然后把在netty的handler中可以直接调用Service层的业务逻辑,把转换好的数据直接传递过去。你想一想,netty是不是充当的为Controller层?对吧。
其实在最常见的Tomcat-MVC-web开发中,关于netty 做的通信,数据处理,协议封装这些操作,Tomcat都会有对应的一系列解决方案来做了,比如说:Tomcat服务器软件是由java代码编写的,其中通过NIO编程方式实现了网络通信,然后数据处理也在Tomcat中封装好了,协议封装的是Http协议。当然Tomcat做到的事情还有很多,比如说:作为web容器来管理所有的Servlet,肯定是对于请求转发有关系的。Servlet就是对应一个个的Controller,本质上相同,但是不同。
为什么Tomcat网络通信用NIO而不用Netty?
因为那时候还没有Netty或Netty还没有很成熟!如果有现如今的成熟高性能的Netty,百分之99可能用Netty做网络通信。Netty就是基于TCP/UDP做的一系列网络通信协议封装,其实底层都是一样的,都是调用socket-api,再往下就是调用操作系统启的TCP协议栈或UDP协议栈,TCP协议栈再往下调用的就是硬件网卡驱动程序,再往下就是网卡,再往下就是通过光纤,网线进行网络传输。
Netty的诞生:

Tomcat的诞生:
所以我们知道数据在handler中被处理,自然也就是在handler里面被释放掉,我们自己实现的时候要释放也应该在handler里面释放,所以我们来看一下handler的代码:
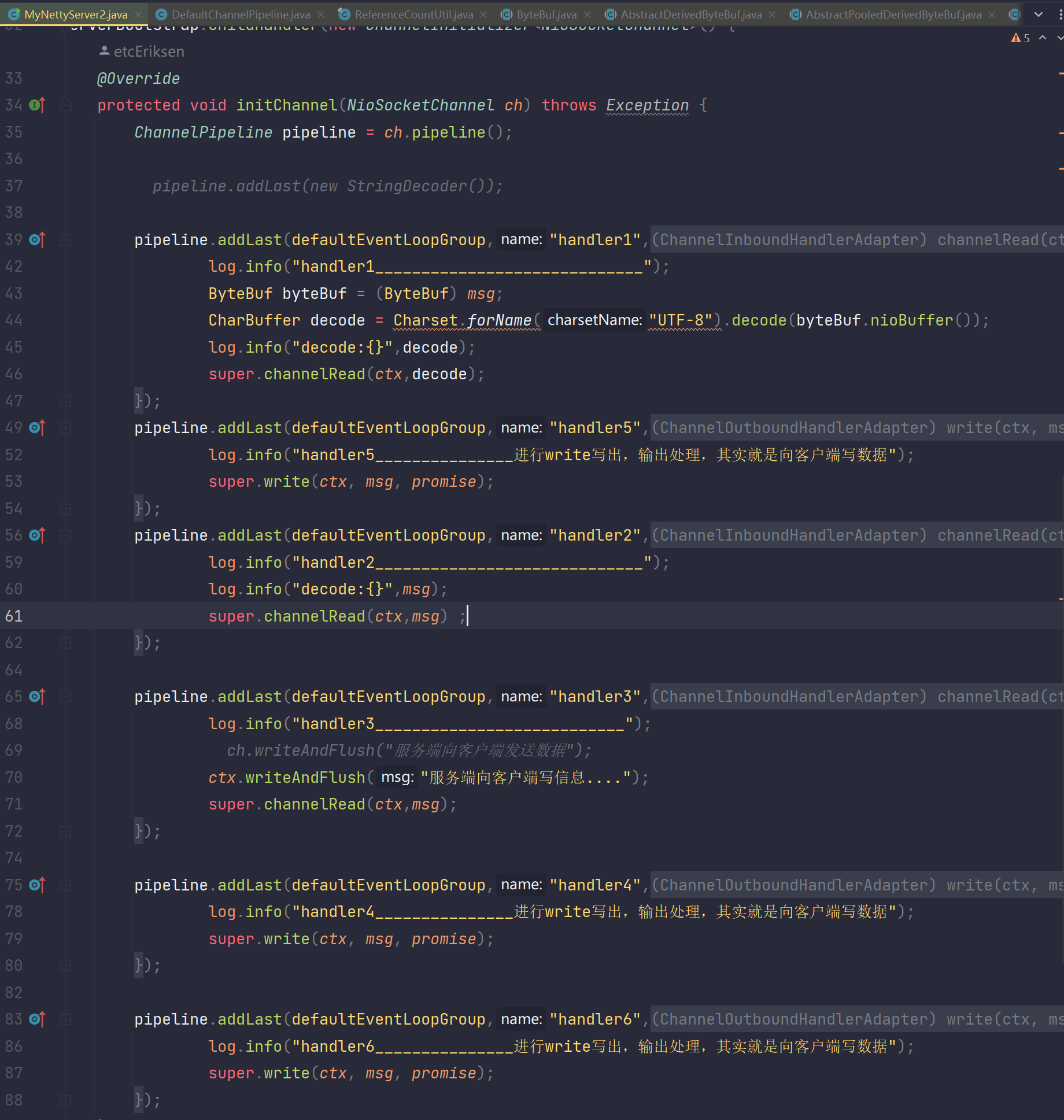

- 读数据的操作
我们已经知道了每一个handler里面的msg其实就是ByteBuf类型,而当读入数据的时候,他的路程节点是head->h1->h2->h3->tail这样,也就是数据在读进来的时候在tail节点中结束了他的使命,所以其实在tail中实际上就应该会被销毁引用计数,那么我们来看tail对应的源码TailContext类。
源码追踪如下:

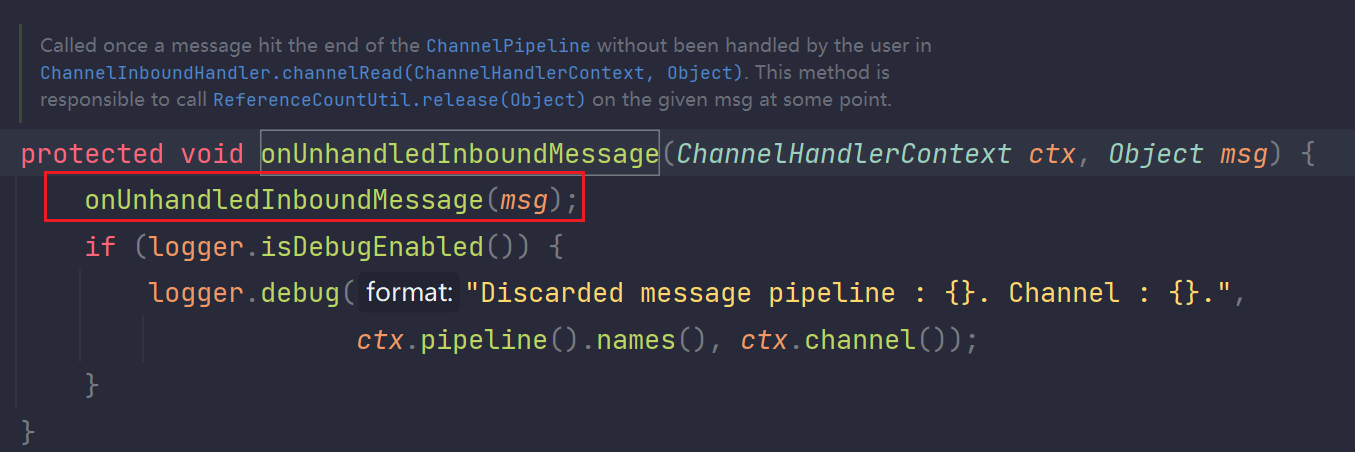
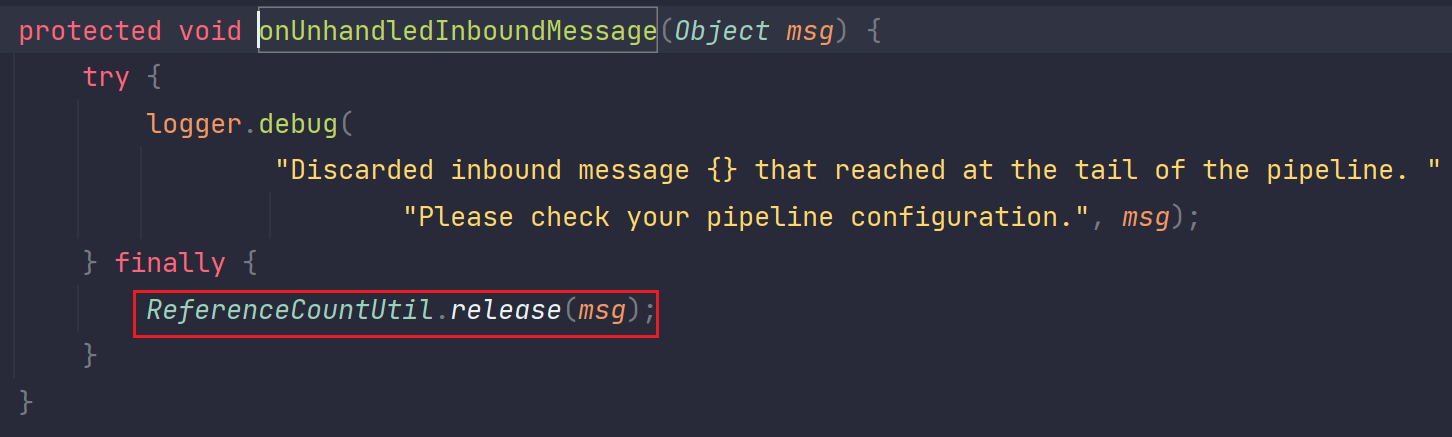

我们看到最后他就是在TailContetx里面被释放了。所以符合我们的预期。
但是这里有一个问题:
我们上面看到TailContext中最终的释放必须要满足对象是if(msg instanceof ReferenceCounted)类型,我们知道ByteBuf就是ReferenceCounted类型的对象。但是如果你无法保证在数据最后一步到达tail节点的时候依然是ByteBuf类型的数据。那么这个空间也就无法被释放了吗?
1、当我们在服务端读数据进来的时候,可能第一个或者前几个是一个StringDecoder()这种解码器,他上 来就把你的数据从ByteBuf处理成为了字符串,那么你一直往后传的就是字符串,那你最后就算到了tail节点也是无法被释放的。
这种你不用担心,StringDecoder作为内置的会把这片ByteBuf回收了,后面的数据是字符串,也就是JVM空间了,后面走GC回收。
2、我们说数据在hander要想往下走得调用super.channelRead(ctx,msg);这个,如果我们在到达tail
之前有一个handler没调用,那就断了,最后也到达不了tail也无法被回收,这种你就要再最后一次使用
ByteBuf的时候手动的做释放。
所以不管如何,你都要在最后一次使用做释放。你可以自己实现一个handler放在必经之路上面,在里面释放,或者直接在最后一个使用的handler里面释放。
不释放可能存在内存泄露的风险
- 写数据的操作
在写出数据的时候他的流程是从h6开始写,也就是h6->h5->h4->head,所以他是在head结束的,自然这个会在head里面被处理,这个就不看了,可以去HeadContext里面看一下,肯定有这个操作。
20.Tomcat的Servlet和SpringMVC的Controller 之间的关系


21.半包粘包(半包黏包)
21.1 什么是半包粘包?
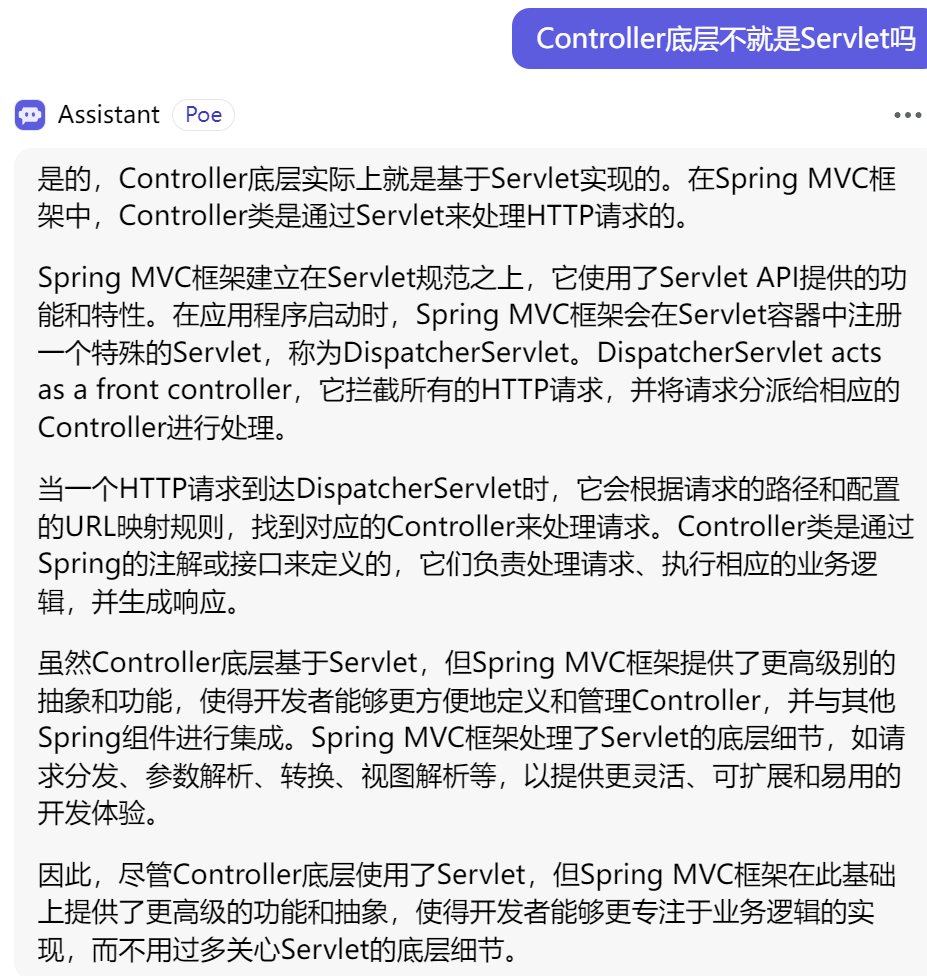
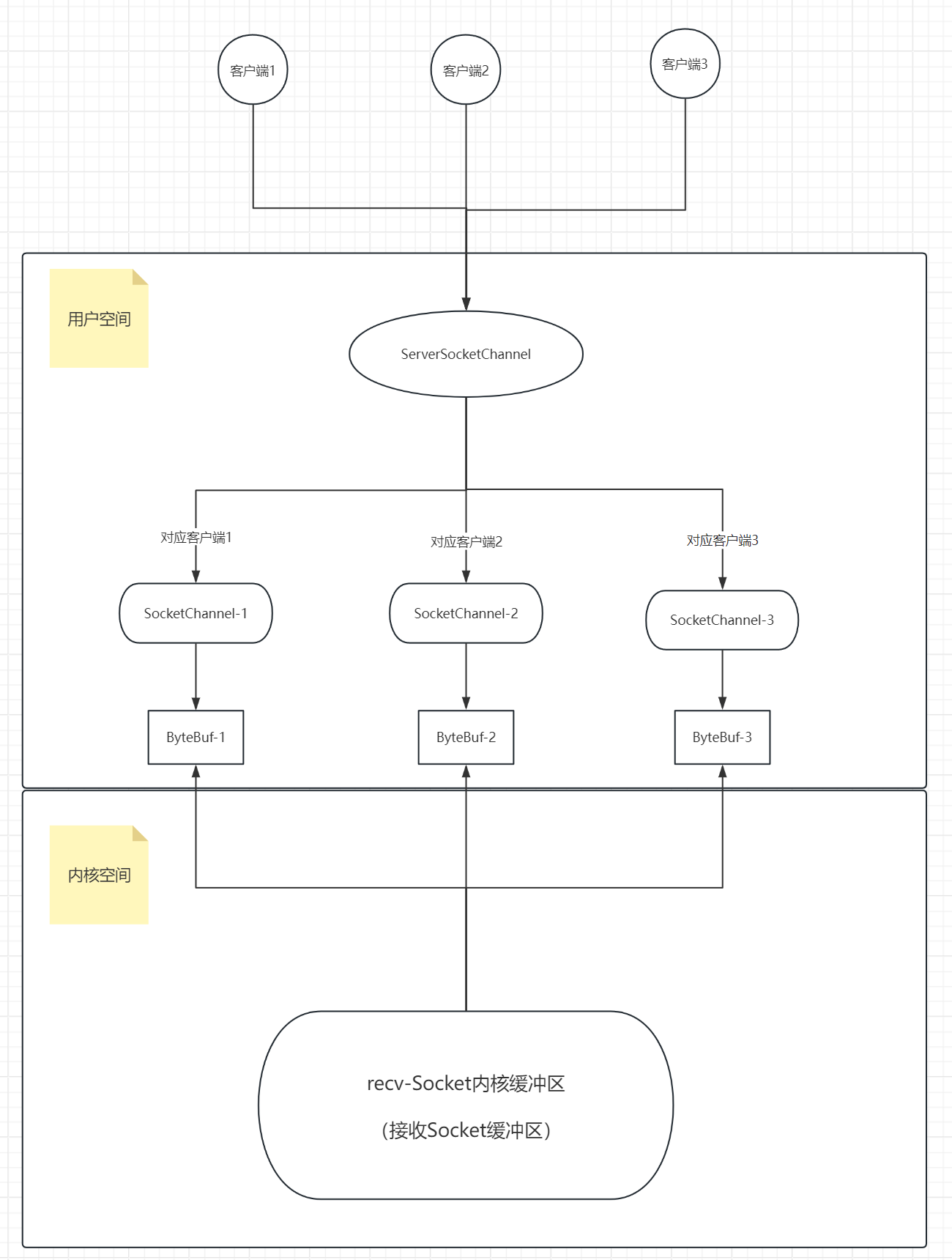
注释:以下的半包粘包分析是站在Socket内核缓冲区向ByteBuffer应用程序缓冲区发数据的过程可能产生的半包粘包的情况分析。为什么要做一个这样的特殊说明呢?因为收发数据不仅仅是发生在Socket内核缓冲区,在网络通信的过程中,涉及到数据的收发发生在三个地方:1.应用程序层面ByteBuffer缓冲区 2.Socket内核缓冲区 3.传输数据层面的滑动窗口收发数据
一旦涉及到收发数据,就一定会存在发多了,发少了,收多了,收少了的问题,所以都有可能产生半包粘包的问题。但是半包粘包的问题产生原因都是相通相同的。
首先来解释一下是半包粘包:
我们的服务端接收客户端数据,接收过来的数据是放在内核Socket缓冲区的,该Socket缓冲区是大小限制的。
半包发生的情况:
当我们的一个数据过来的时候超过了Socket缓冲区的大小,它一次无法接收全,那就分开两次接收。第一次的一部分打满了Socket缓冲区后就刷新到应用程序的ByteBuffer缓冲区中,此时你通过应用程序socketChannel.read(ByteBuffer缓冲区)读取出来,此时你看到的只是消息的一部分数据,第二部分的消息数据会在下一次过来,这就导致了半包。
粘包发生的情况:
当我们的一个数据要比Socket内核缓冲区小,这就可能导致一个数据打不满Socket缓冲区,也就不会立马刷到应用程序的ByteBuffer缓冲区中,所以Socket内核缓冲区会接收多个数据过来,最终终于填满了Socket内核缓冲区,此时刷新拷贝数据到ByteBuffer应用程序缓冲区,但是此时服务端应用程序看到的是连接着的多个数据,不是一个一个的,这就是粘包
半包和粘包同时发生的情况:
既有多个小数据包过来,多个小的数据包没有把Socket内核缓冲区打满,此时其实就已经粘包了。但是紧接着一个大也过来了,但是恰好Socket缓冲区无法一次接收完全,大的一部分正好塞满了Socket内核缓冲区,然后刷新给应用程序,由于把大数据给分掉刷新给应用程序了,所以也产生了半包。
- 半包粘包产生的例子
注释:非常重要的一点,为什么写的是ByteBuffer缓冲区/Socket内核缓冲区/滑动窗口收发数据???
因为收发数据不仅仅是发生在Socket内核缓冲区,在网络通信的过程中,涉及到数据的收发发生在三个地方:1.应用程序层面ByteBuffer缓冲区 2.Socket内核缓冲区 3.传输数据层面的滑动窗口收发数据
一旦涉及到收发数据,就一定会存在发多了,发少了,收多了,收少了的问题,所以都有可能产生半包粘包的问题。所以一开始说的半包粘包的定义分析是站在Socket内核缓冲区向ByteBuffer应用程序缓冲区发数据的过程可能产生的半包粘包的情况分析
- 半包粘包产生的原因
这一切的原因就是因为TCP,我们程序处理数据,最终发送和接收都是在网络上处理的,也就是要经过TCP的处理。
而TCP本身又是面向字节流的,无边界的处理协议,也就是它不区分你发送的多个数据的结构,它是一个字节流,一个个字节,没有结构,所以不能区分你的数据结构,最终到达对端的就是无结构的,看不到你的数据结构。
它只懂得接收,满了之后就去发送给应用程序,所以你的什么字符串哪里是头哪里是尾,TCP不知道。这就是说这个玩意,它从最底层的网络协议那里就已经决定了你这个半包粘包的问题是无法避免的。
在传输层无法避免,那么只能去应用层去做一些处理来解决这一半包粘包的问题。因为毕竟我们用户看到的是要有结构的,所以在应用程序编程中就要对数据进行做边界化处理和约束,得到正确的对端发送的数据
总结:
因为TCP是流式传输数据,消息是没有边界的,所以肯定会出现半包粘包问题。因为UDP传输是报式传输,所以UDP无半包,粘包问题


21.2 网络通信架构
橘子哥的架构图:
- 自我绘制,并且总结步骤和细节
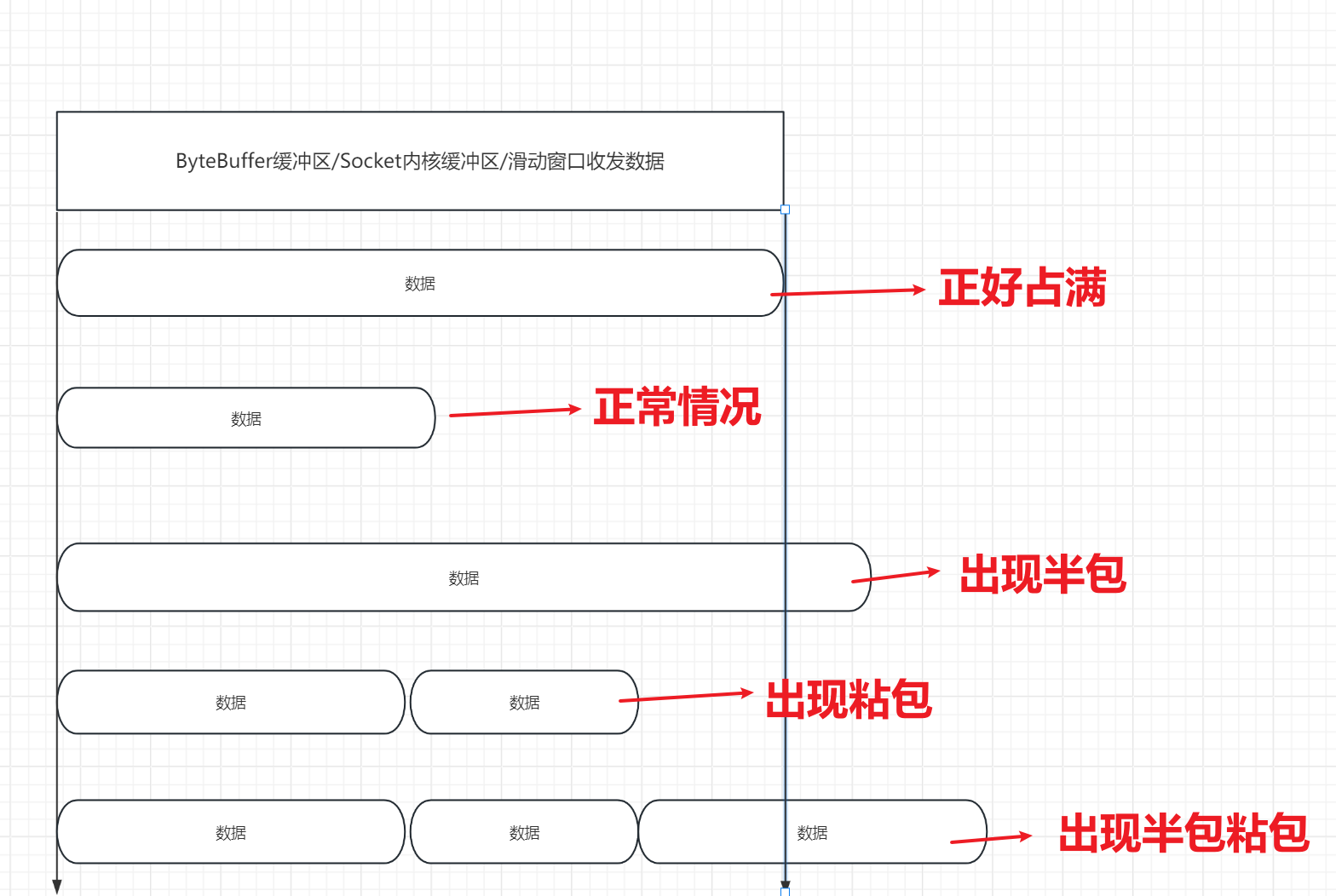
针对图中的黄色标记处进行逐个分析一下:
(1)socketChannel.write(byteBuf):socketChannel.write(byteBuf)的返回值就是它写入socket缓冲区数据的大小。socket缓冲区写满了,你就写不进去了,必须调用flush()刷新Socket缓冲区的数据通过网络传输出去才能腾出空间让socketChannel.write继续去写。所以当你有时候会发现该返回值为0,说明Socket缓冲区已经被写满了,需要flush刷新通过网络把数据发送出去。仔细分析一下,socketChannel.write的返回值为0跟网络是否能够传输没有本质上的关系,当网络断开不能再收发数据了,但是此时只要Socket内核缓冲区是有剩余空间的,那么socketChannel.write一定可以写,一定会有大于0的返回值
(2)数据一开始先在ByteBuffer缓冲区,当我们调用socketChannel后会把数据写给拷贝给Socket内核缓冲区。因为ByteBuffer是用户态的内存存储的,但是用户态不能和硬件网卡做交互。要想发出去数据,必须和网卡做交互,所以一定会拷贝数据到内核态。
(3)Socket缓冲区的大小在理论上一定是要大于ByteBuffer应用缓冲区的!为什么?
因为我们从用户缓冲区写数据到Socket内核缓冲区时,我们肯定不希望ByteBuffer往Socket缓冲区写一次,Socket缓冲区就发一次,太耗费性能了。我们想要做到批量发送,如果想要批量一次发送,那么Socket缓冲区就要足够的大,有足够的能力进行不断的接收ByteBuffer写出的数据,等Socket缓冲区攒够一批后,再发送。
(4)内核态如何把数据拷贝传输给到网卡的?
通过一种DMA技术,DMA技术其实就是利用DMA芯片去完成了原本应该交给CPU完成的任务和工作。你可以把它视为一个小CPU,该芯片具备基本的CPU核心结构去完成数据处理和拷贝。其实就是为了减轻CPU的压力,DMA辅助CPU处理拷贝数据
(5)
在链路层数据是以帧的形式传递的,滑动窗口实际上是一种数据帧传输的优化。我们这里不说物理层的二进制bit传输,也不说物理介质使用高低电平去传输,毕竟二进制没有意义,我们略去物理层,看数据链路层。实际上在这里从硬件发去服务端的时候,数据因为MTU拆分包的存在他就是分包发送的,这里也可以叫做数据帧,也就是我们哪里放在的ByteBuffer数据,在经过各层网络处理被处理位一个一个大小固定的数据包,这个拆分要注意,它是按照大小拆分的,不是按你发送的数据结构,不考虑你的内容语义,而是TCP根据它的所规定的大小进行拆分,以一种流的形式传输,所以肯定会存在半包粘包问题。所以必须在应用程序所在的应用层去解决该问题。

------》
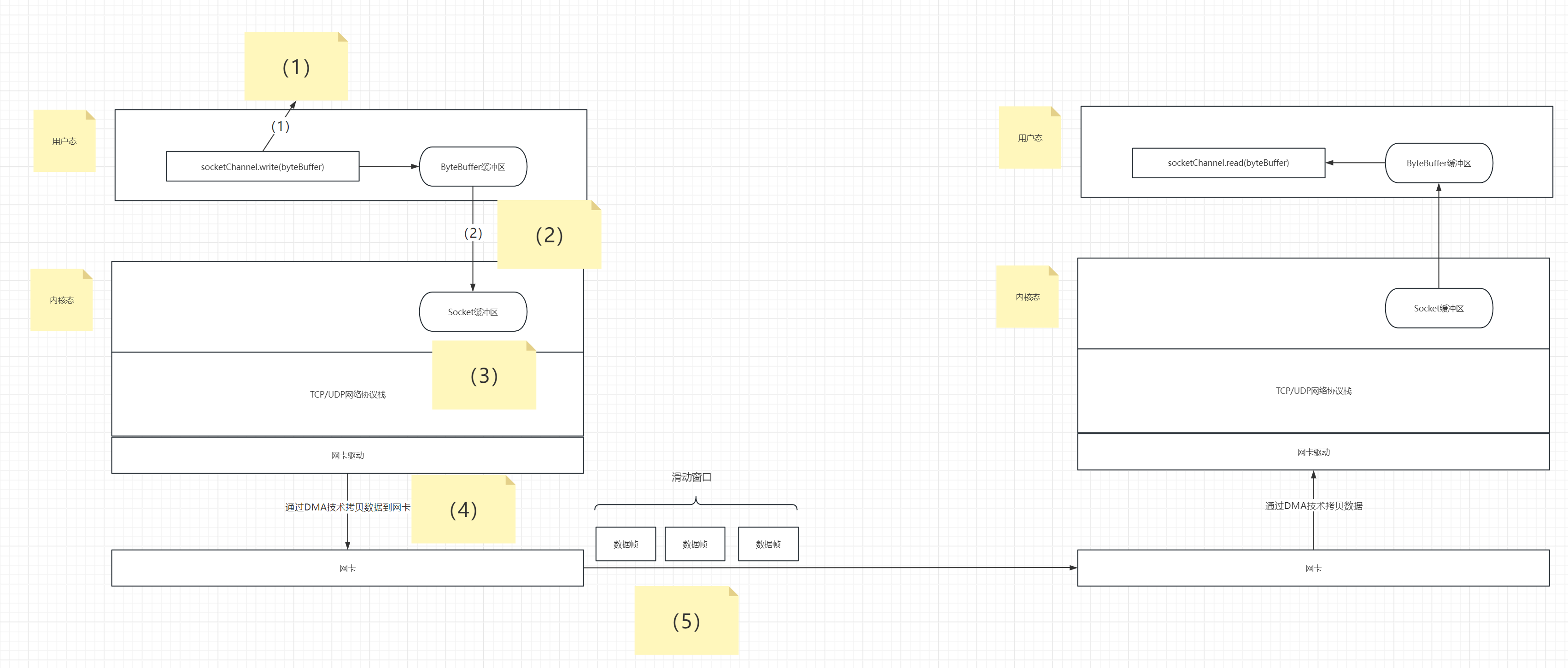
滑动窗口是啥?---》
在未引入滑动窗口之前,我们网络传输是一个数据帧一个数据帧进行传输的,当客户端传输一个数据帧给服务端,服务端接收成功后,服务端会返回一个ACK给客户端。客户端接收到这一ACK后,客户端会传输下一个数据帧给服务端,服务端接收成功后,会再一次返回一个ACK给客户端。以此类推。这种传输方式是以串行化的传输,效率很低。
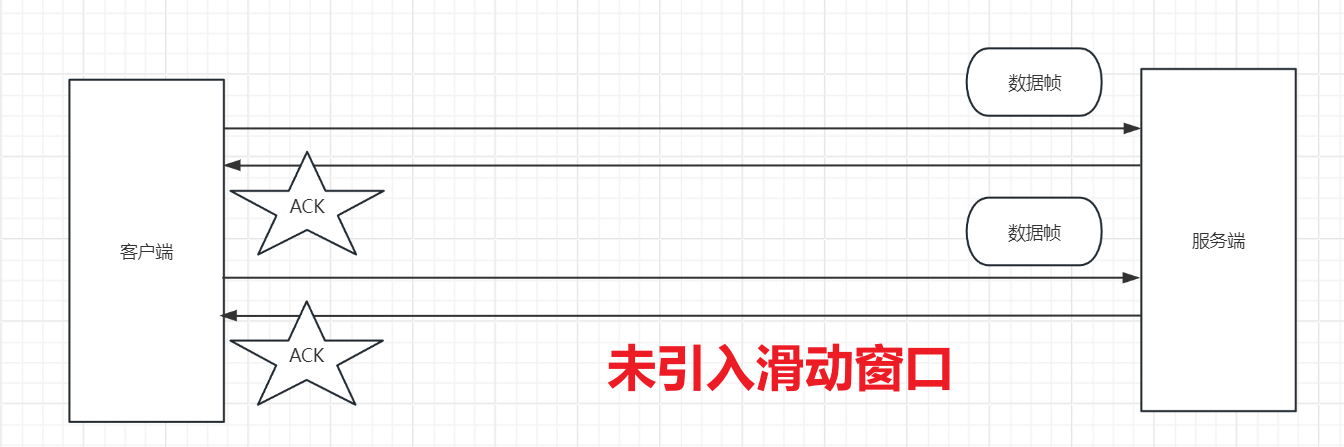
所以为了改善这种串行传输方式,我们不再一次发送一个数据帧,而是一次发送多个数据帧。为了好举例,我这里假设一个具体的数值,但是一定不是真实网络传输数值!假设说客户端一次发送三个数据帧给服务端,服务端肯定不是一次性接收完三个数据帧,而是一个数据帧一个数据帧进行接收。每当服务端接收到一个数据帧后,服务端会返回一个ACK给客户端。当服务端接收到数据帧1后,返回一个ACK给客户端。客户端接收到ACK,会发送数据帧4给服务端,此时可能服务端又接连处理了数据帧2和3,又会返回两个ACK给客户端,客户端接收到ACK后,又会接连发送新的数据帧给服务端。如果服务端处理客户端数据帧的速度以及返回ACK的速度足够快,完全是并发状态。体会一下是不是。关键点还是在于,从之前"客户端一次只能发送一个数据帧,只有等到该数据帧的ACK返回后才能发送下一个数据帧"转变到现如今"客户端一次发送多个数据帧给服务端,服务端依次接收到这多个数据帧并且会依次返回多个ACK给客户端,客户端依次接收到多个ACK并依次继续发送数据帧给服务端"。
客户端一次发送多个数据帧的大小就是滑动窗口的大小,客户端可以根据服务端处理数据帧的速度(即响应客户端ACK的速度)进行动态的控制滑动窗口的大小。

但是滑动窗口是动态变化,以客户端为发送方为例,它的发送滑动窗口的变化是根据服务端接收处理数据帧的性能而决定的,服务端也同样具有一个滑动窗口,只不过这个滑动窗口为接收滑动窗口。当然服务端也可以充当发送方,同理即可。

但是滑动窗口底层是怎么工作的,当消息数据帧丢失了或ACK丢失了该怎么解决呢?见下面这篇文章
一篇带你读懂TCP之“滑动窗口”协议 - 掘金
- 补充
1.同一台计算机内核中的接收Socket缓冲区和发送Socket缓冲区绝对不是同一个,如果是同一个,那么数据不就串了吗,不就乱了吗?对吧。接收缓冲区是recv-Socket缓冲区,发送缓冲区是send-Socket缓冲区
2.在某一时刻,客户端发送数据给服务端,客户端有一个独立的发送方滑动窗口,服务端有一个独立的接收方滑动窗口。这两个滑动窗口分别与对应Socket缓冲区之间的关系:

这两个滑动窗口是时刻根据对方ACK,发送数据帧的数量,以及自身Socket缓冲区剩余空间大小进行不断的动态调整的。
发送方滑动窗口决定了发送方可以发送的数据量,接收方滑动窗口决定了接收方可以接收的数据量。
总结:
发送方滑动窗口的大小等于其send-socket内核缓冲区剩余的大小,发送方滑动窗口的大小代表着发送方可以发送的数据量大小,发送数据时,应用程序会把数据先写入存储在socket内核缓冲区,发送方发出去的能力越多(发送方滑动窗口越大),意味着send-socket缓冲区剩余的空间越多,所以可以推出socket内核缓冲区的剩余大小等于发送方滑动窗口的大小
接收方滑动窗口的大小等于其recv-socket内核缓冲区剩余的大小,接收方滑动窗口的大小代表着接收方可以接收的数据量大小,接收数据时,应用程序会先把数据读取存储到socket内核缓冲区,接收方读取的能力越多(接收方滑动窗口越大),意味着recv-socket内核缓冲区剩余的空间越多,所以可以推出接收方滑动窗口的大小等于其recv-socket内核缓冲区剩余的大小
当然二者滑动窗口是动态变化的。
Socket内核缓冲区的大小默认为65536字节
- 在TCP中,半包粘包问题一定存在
在网络通信的过程中,涉及到数据的收发发生在三个地方:1.应用程序层面ByteBuffer缓冲区 2.Socket内核缓冲区 3.传输数据层面的滑动窗口收发数据。一旦涉及到收发数据,就一定会存在发多了,发少了,收多了,收少了的问题,所以都有可能产生半包粘包的问题。但是半包粘包的问题产生原因都是相通相同的。这里面都有半包和黏包的问题出现,可见半包黏包的出现是不可避免的在TCP这种编程下面。
而要在netty中解决这问题,就需要netty在存储数据的地方做处理。
存储数据的地方有两个,一个是ByteBuf,一个是内核缓冲区。
内核缓冲区这个是在内核里面控制的
而ByteBuf,我们之前写了一些ByteBuf的API,但是实际上在netty中,他会帮我们处理好这个东西,我们程序员看到的就是数据,字符串等等。用于传输数据,网络通信的ByteBuf是netty帮我们创建管理的。也就是在netty内部管理的,
# 1、那我们如何获取,处理?netty帮我们创建的ByteBuf的初始化大小又是多少呢?换言之我们如何获取netty内部封装好的ByteBuf呢?
我们前面写的代码可以看到数据其实是在Handler中流转的,不管是inbound还是outbound,所以我们获
取或者说和ByteBuf数据交互的地点就在Handler中。
21.3 ByteBuf数据处理
- ByteBuf是在Handler中处理的
public class MyNettyServer {
private static final Logger log = LoggerFactory.getLogger(MyNettyServer.class);
public static void main(String[] args) {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.group(new NioEventLoopGroup(1),new NioEventLoopGroup(8));
DefaultEventLoopGroup defaultEventLoopGroup = new DefaultEventLoopGroup() ;
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(defaultEventLoopGroup,"handler1",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.info("handler1处理,接收到的客户端来的数据为:{}",msg) ;
super.channelRead(ctx,msg) ;
}
});
}
});
serverBootstrap.bind(8000);
}
}在上面的代码中,服务端代码添加了一个Handler,除了head这第一个Handler,前面没有什么解码的处理,也不存在其他handler对客户端的数据处理。这里本质上对应的就是网络通信架构中的接收端的。
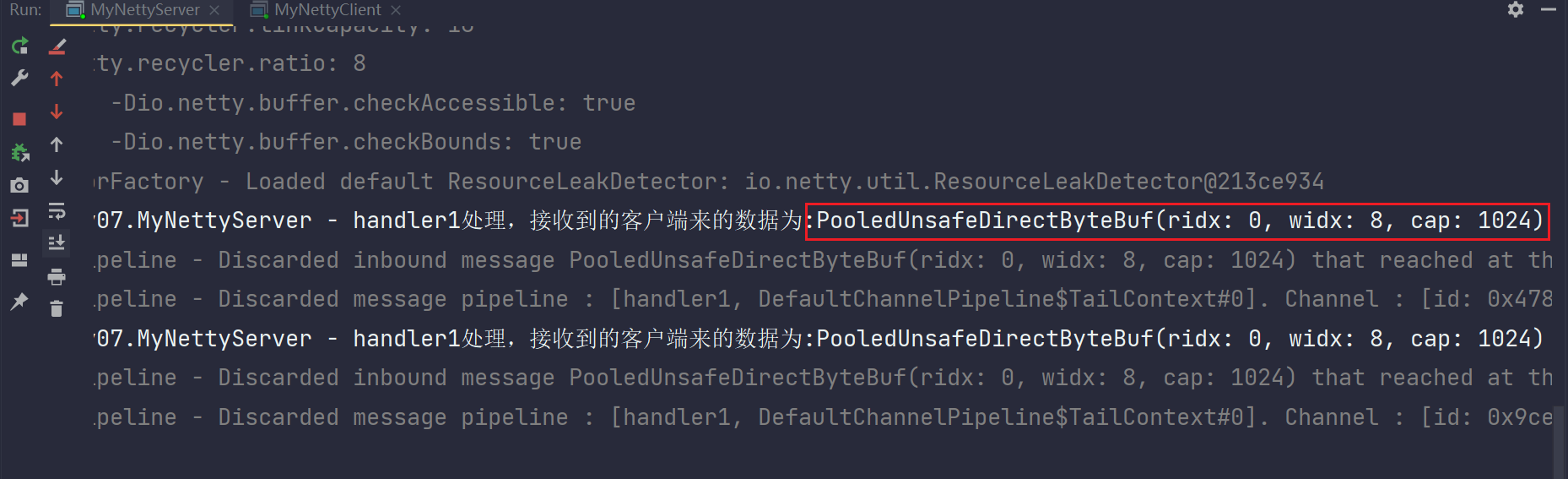
此时我们在应用程序已经看到了数据,只不过是ByteBuf结构的,对应这个位置就是数据已经到了程序了。
所以此时我们就可以回顾上面的三个问题了:
1.如何获取netty中的ByteBuf?
上面已经看到了,我们可以在pipeline中的第一个非head的inboundHandler中来获取到ByteBuf,其实就是第一个过来的还没被应用程序处理过的数据msg就是ByteBuf类型的。但是你需要保证你的客户端过来的数据最终由ByteBuf类型转换成String类型或其他与特定框架无关的java数据类型---->毕竟最终你通过Handler(相当于Controller层)进行调用业务Service层的方法时,你肯定不能传输netty特有的类型ByteBuf过去吧?你肯定需要传输解码后的java数据类型。
2.netty中创建的ByteBuf默认大小是多少?要不要改?能不能改?怎么改?
默认大小是1024字节
这个值需要自定义改,但是要在生产测试环境中寻求一个适合的数值,一个最优解。虽然你看1024字节不大,才1M,但是当你客户端并发巨大时,ByteBuf是不是会创建很多份?对吧。内存会爆的。
能改,怎么改?
这个大小时handler从socket内核缓冲区接收到的字节流大小,然后在用户内存中创建一个数据结构ByteBuf来存储从socket内核缓冲区中接收的字节流,这个ByteBuf的大小是handler那边的概念,handler是属于serverBootstrap.childHandler方面的,因为child是SocketChannel的东西,所以ByteBuf大小的设置应该放在这里。(肯定是建立连接后才能收发数据的呀,所以肯定是在childHander, SocketChannel层面做文章的)
child这个是socketChannel的,而Bytebuf就是数据IO的,也就属于socketChannel,所以我们
要在child设置。如下:

3.Socket缓冲区的大小能不能改?
也可以改。netty封装了ChannelOption,netty底层会调用操作系统函数去做修改。我们可以调用netty为我们提供的api函数去修改。改动的就是接收端socket内核缓冲区的大小,记住:socket内核缓冲区的剩余大小等于滑动窗口的大小。所以我们修改了socket缓冲区的初始值,就相当于修改了该socket缓冲区所对应的滑动窗口大小,你思考一下,socket缓冲区初始状态不就是全剩余一点没使用过的吗?那不就是滑动窗口的大小。
怎么改?
前面修改的ByteBuf是对于每一个网络客户端连接而言的,也就是针对每一个SocketChannel(每一个客户端连接ServerSocketChannel给其分配一个SocketChannel)来说的,每一个连接(SocketChannel)都有自己的ByteBuf处理(独立的数据处理),那么对于每一个SocketChannel独立的ByteBuf的大小设置,我们使用的就是childHandler的api
但是对于Socket内核缓冲区来说,是可以对应很多个客户端连接 即对应多个SocketChannel,所以Socket内核缓冲区是全局级别的,我们知道SocketChannel是ServerSocketChannel分配的,所以对于Socket内核缓冲区的大小设置,我们是去设置ServerSocketChannel相关的api的,所以就是serverBootstrap.option。childOption是对应SocketChannel的。
如下所图:
Socket缓冲区的大小修改设置方式如下:

补充:
在netty应用程序中你可以修改操作系统级别的TCP参数,比如说:recv-Socket内核缓冲区的大小
因为滑动窗口大小等于自身socket缓冲区的剩余大小,一开始socket缓冲区肯定都剩余,所以得出:设置的接收socket缓冲区大小初始值 其实就是等同于接收端滑动窗口的初始值。
为什么我们在netty中去设置一些系统级别的参数的值呢?
1.方便。如果Netty不做封装,我们如果想要修改系统级别的参数值可能需要执行很复杂的linux指令命令。而netty直接为你封装成了一个类ChannelConfig
2.安全。你要是直接修改系统级别参数的话,可能修改的是全局范围内的,一处修改 所有计算机程序(可不是只有你自己写的netty程序,而是整个计算机的程序)都会使用该修改后的系统级别的参数值。但是你在netty上修改,起作用的可能只有你这一个程序。
细节:
修改接收端netty为你创建的ByteBuf这一应用层缓冲区的大小,注意是接收端。由于这是局部SocketChannel中的变量,所以使用的是childOption这一方法进行修改的。多说一嘴,使用netty与nio不同,在netty中直接为你封装创建好ByteBuf这一缓冲区,然后通过回调channelRead,把创建好的ByteBuf传递给参数Object msg,msg就接收到ByteBuf这一创建好的缓冲区,我们就可以直接使用了。
netty是如何回调的???
我们编写的用户程序只需要传递new ChannelInoundhandlerAdapter并且重写回调方法来进行告知netty即可,netty完成相关的封装逻辑(底层源码就是干这个的)后会通过你传递的对象进行回调其重写的channelRead方法。

而以上我们配置的缓冲区大小也依旧会导致半包粘包的问题出现,因为TCP是流式无边界的字节流传输,如果不在应用层进行加控制,加处理,肯定会出现半包粘包问题的。
具象化说一下:网络传输过程中,我们如果不看二进制层面,往上看一层的话,那么数据是以数据帧的形式传输的,我们知道网卡根据滑动窗口进行接收许多数据帧然后存储到socket内核缓冲区中,但是你知道,socket内核缓冲区默认大小为65534,应用层的ByteBuf再读取socket内核缓冲区的数据,ByteBuf默认大小为1024字节,数据帧可能一个只有几十字节,所以ByteBuf或Socket内核缓冲区很有可能一次读取非常多的数据帧,所以一定会出现粘包问题,半包问题同理也一定会出现的。所以为了解决这一问题,我们必须在应用层做一些工作和处理,当拿到ByteBuf数据(里面包含了满满的数据帧,粘包,半包问题产生了已经),我们需要对这个ByteBuf进行帧处理,可以通过netty封装的一些帧解码器,比如后续总结的:LengthFieldBasedFrameDecoder等。其实做的事情就是:在拿到ByteBuf这一字节流原始数据帧数据后不直接解码(如果直接解码,会出现半包粘包问题),而是通过netty内置的ByteToMessageDecoder子类对应的许多种内置解码器,去把ByteBuf解码成一条条的Message,得到的Message都是不存在半包粘包问题的。

21.4 Netty中半包粘包的解决方案
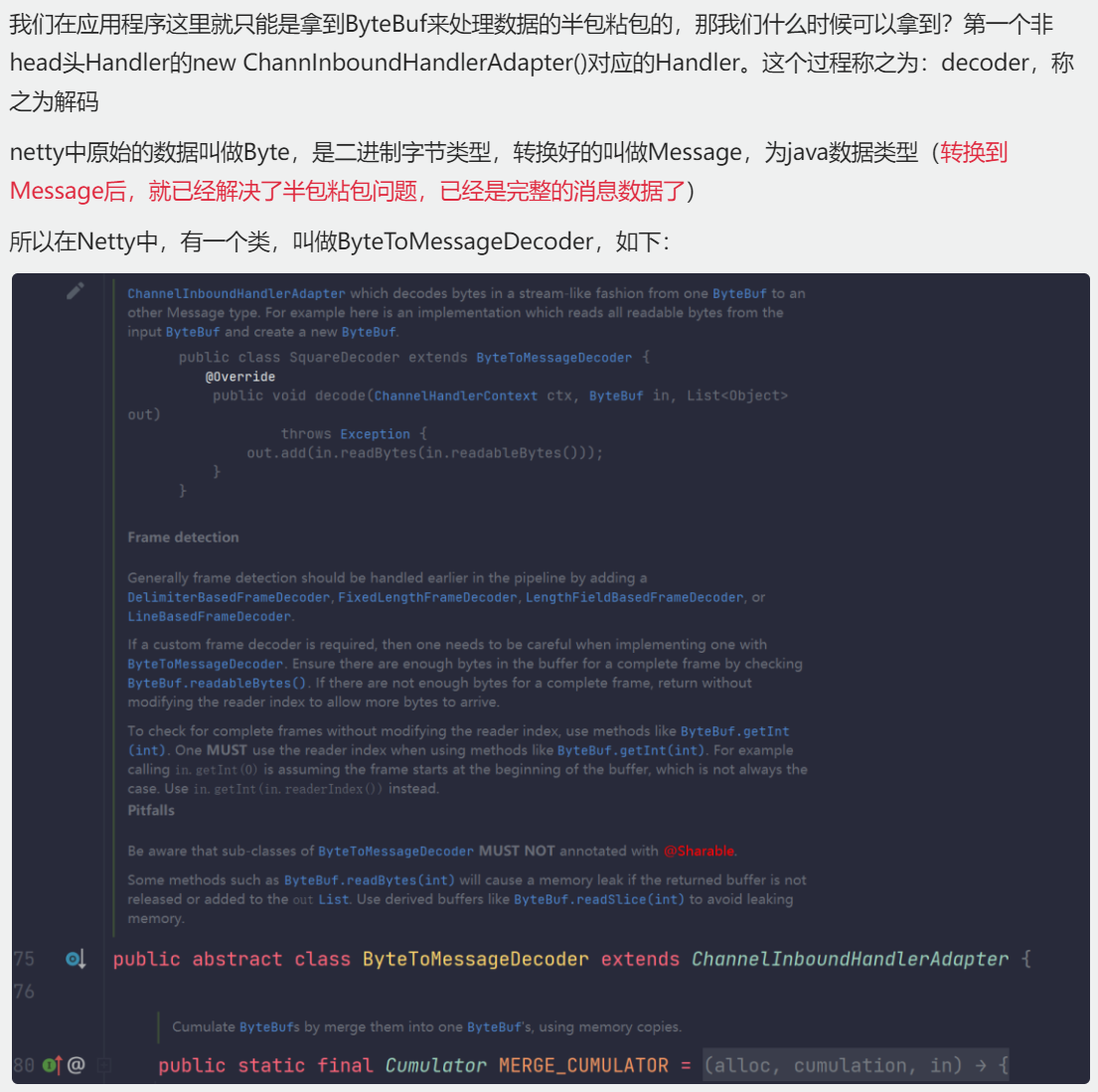
我们在应用程序这里就只能是拿到ByteBuf来处理数据的半包粘包的,那我们什么时候可以拿到?第一个非head头Handler的new ChannInboundHandlerAdapter()对应的Handler。这个过程称之为:decoder,称之为解码
netty中原始的数据叫做Byte,是二进制字节类型,转换好的叫做Message,为java数据类型(转换到Message后,就已经解决了半包粘包问题,已经是完整的消息数据了)
所以在Netty中,有一个类,叫做ByteToMessageDecoder,如下:

注释翻译见下:
Frame detection
Generally frame detection should be handled earlier in the pipeline by adding a DelimiterBasedFrameDecoder, FixedLengthFrameDecoder, LengthFieldBasedFrameDecoder, or LineBasedFrameDecoder.
帧检测
一般来说,帧检测应在流水线的较早阶段通过添加:基于分隔符的帧解码器(DelimiterBasedFrameDecoder)、固定长度帧解码器(FixedLengthFrameDecoder)、基于长度字段的帧解码器(LengthFieldBasedFrameDecoder)或基于行的帧解码器(LineBasedFrameDecoder)来处理。
If a custom frame decoder is required, then one needs to be careful when implementing one with ByteToMessageDecoder. Ensure there are enough bytes in the buffer for a complete frame by checking ByteBuf.readableBytes(). If there are not enough bytes for a complete frame, return without modifying the reader index to allow more bytes to arrive.
如果需要自定义帧解码器,则在使用 ByteToMessageDecoder 实现时需要小心。通过检查 ByteBuf.readableBytes() 来确保缓冲区中有足够的字节来处理一个完整的帧。如果缓冲区中没有足够的字节来存储一个完整的帧,则无需修改读取器索引即可返回,以允许更多字节到达。
To check for complete frames without modifying the reader index, use methods like ByteBuf.getInt(int). One MUST use the reader index when using methods like ByteBuf.getInt(int). For example calling in.getInt(0) is assuming the frame starts at the beginning of the buffer, which is not always the case. Use in.getInt(in.readerIndex()) instead.
To check for complete frames without modifying the reader index, use methods like ByteBuf.getInt(int). One MUST use the reader index when using methods like ByteBuf.getInt(int). 例如,调用 in.getInt(0) 会假设帧从缓冲区的起始位置开始,但实际情况并非总是如此。请使用 in.getInt(in.readerIndex()) 代替。
Pitfalls
Be aware that sub-classes of ByteToMessageDecoder MUST NOT annotated with @Sharable.
Some methods such as ByteBuf.readBytes(int) will cause a memory leak if the returned buffer is not released or added to the out List. Use derived buffers like ByteBuf.readSlice(int) to avoid leaking memory.
陷阱
请注意,ByteToMessageDecoder 的子类不得使用 @Sharable 进行注解。
如果返回的缓冲区未被释放或添加到 out List,ByteBuf.readBytes(int) 等方法将导致内存泄漏。请使用 ByteBuf.readSlice(int) 等派生缓冲区来避免内存泄漏。
所以根据这个注释来看,我们目前得出四种处理半包和粘包的思路,也就是如下这四个子类:
基于分隔符的帧解码器(DelimiterBasedFrameDecoder)
固定长度帧解码器(FixedLengthFrameDecoder)
基于长度字段的帧解码器(LengthFieldBasedFrameDecoder)
基于行的帧解码器(LineBasedFrameDecoder)
21.4.1 FixedLengthFrameDecoder
固定长度的帧解码器,帧就是我们接收过来的ByteBuf数据。

我们看官方给出的例子的意思就是:我们每个消息Message都是定长的,例子里面给出的是3,实际上可以设置为任意长度,但是一旦长度确定,那么长度就不能再变化了,每一个消息都这么长。
其实有点类似UDP数据报传输,客户端与服务端之间协商一个数据报的大小,然后客户端发送的时候每一个数据报为这么大,服务端解析的时候也依照该数据报大小进行解码。其实和定长消息是一个原理。
我们来解释一下这个例子,就是我们约定消息长度是3,ABC,DEF这种都是三个,是正常的数据,但是A,BC这种就是半包,DEFG这种就是粘包
那他怎么处理的呢?它的方法很简单就是已经知道了消息长度为3,那么我们就可以按照这个长度把消息固定的拆解出来。那么可能有一个问题,我们的消息长度如果约定为6字节,可是有的客户端发送的消息长度就是2呢?也就是说,客户端发送的消息长度不足约定的长度呢,所以要控制。如果不足约定长度,那么使用特殊字符填充剩余空间,比如可以使用 * 来填充,ofcourse,服务端接收的每条独立的消息为6字节,可能这6字节中有 * 这个字符就是为了来占位的,我们在接收到每一条消息后,都要进行处理消除掉它们的 * 号
可以很明显的得出它的优缺点:
优点:
简单,容易理解,你客户端服务端就约定好消息长度就ok
缺点:
很死板,一旦约定好消息长度,消息就不能超过这个长度,你超过了,他拆完了就取不到超过的部分。。这和UDP有啥区别,都不安全了。
很浪费空间,一旦约定好长度,如果有的消息相对特别小,那是不是要浪费很多长度去做无意义的填充呢,对吧,这种就是使用无用的数据占用有限的空间。
- 操作一下,先来看一下没有定长解码器来处理半包粘包问题的时候是啥表现
客户端:
public class MyNettyClient {
public static void main(String[] args) throws InterruptedException {
Bootstrap bootstrap = new Bootstrap() ;
bootstrap.channel(NioSocketChannel.class);
bootstrap.group(new NioEventLoopGroup());
bootstrap.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LoggingHandler());
pipeline.addLast(new StringEncoder());
}
});
Channel channel = bootstrap.connect(new InetSocketAddress(8000)).sync().channel();
channel.writeAndFlush("leomessiRonaldo");
System.out.println("MyNettyClient.main");
}
}客户端写出一句话,但是本质上是两句话,只不过放在一个字符串里面,我们当然希望服务端在接收到的时候解析成两句话这才符合一个对话的意思。即:客户端发送"leomessiRonaldo",我们希望服务端接收到时理解解析成"leomessi"和"Ronaldo"
服务端:
public class MyNettyServer {
private static final Logger log = LoggerFactory.getLogger(MyNettyServer.class);
public static void main(String[] args) {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.group(new NioEventLoopGroup(1),new NioEventLoopGroup(8));
DefaultEventLoopGroup defaultEventLoopGroup = new DefaultEventLoopGroup() ;
//设置socket内核缓冲区的大小,注意这里设置的接收recv-socket内核缓冲区的大小
// serverBootstrap.option(ChannelOption.SO_RCVBUF,100);
//设置ByteBuf的大小
// serverBootstrap.childOption(ChannelOption.RCVBUF_ALLOCATOR,new AdaptiveRecvByteBufAllocator(16,32,64));
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LoggingHandler());
pipeline.addLast(defaultEventLoopGroup,"handler1",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.info("handler1处理,接收到的客户端来的数据为:{}",msg) ;
super.channelRead(ctx,msg) ;
}
});
}
});
serverBootstrap.bind(8000);
}
}我们看一下服务端接收到情况:
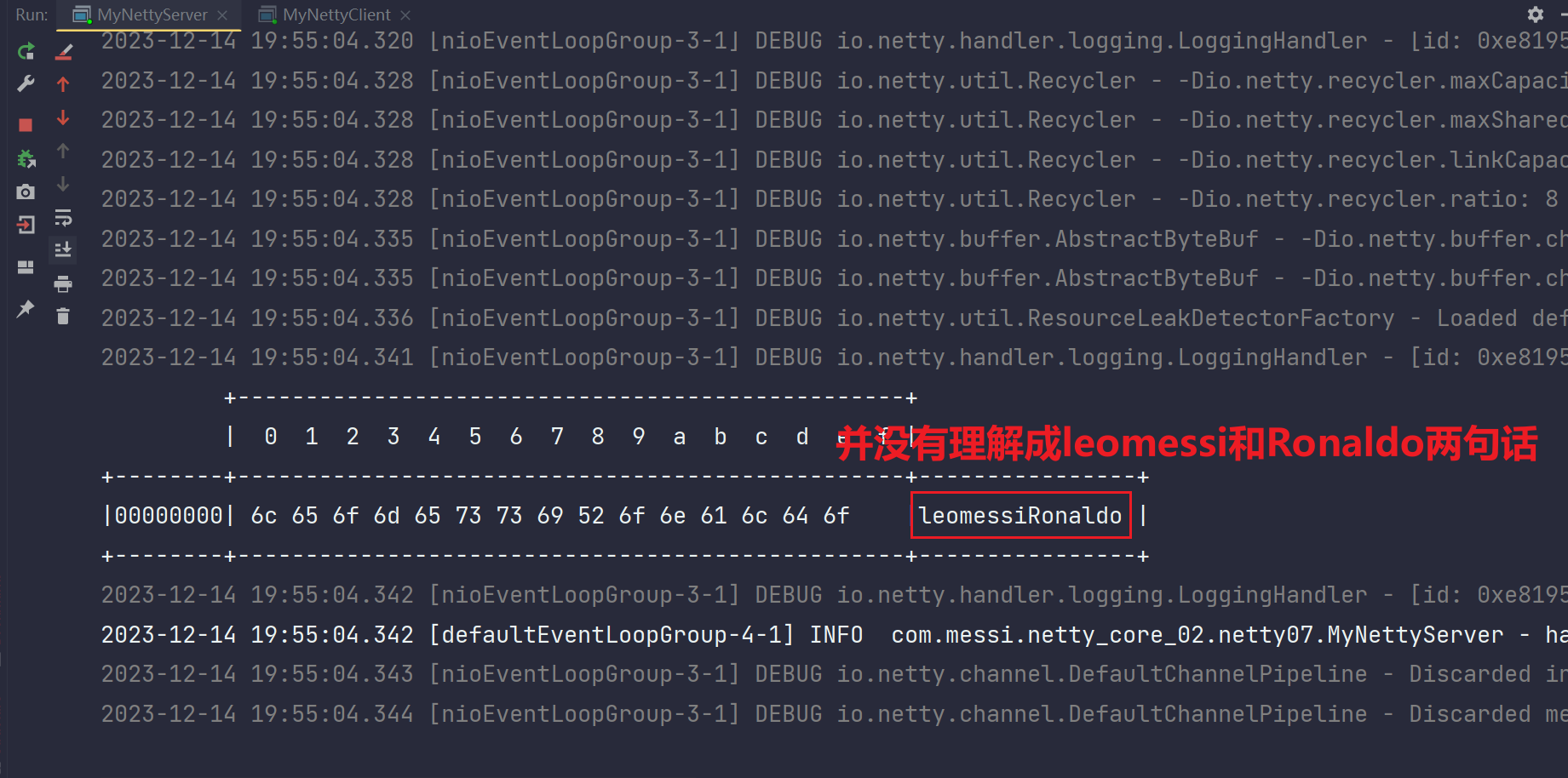
我们在客户端写出的数据是一个多个字符字符串,我们知道bytebuf的长度默认1024,而且内核的
socket缓冲区大小也是超过这个长度的,所以这个数据肯定能一次被对端接收,但是我们要的带着业务
属性的数据其实是leomessiRonaldo这样的东西,这才是一个对话,所以这是个黏包。
但是这里尝试另外一种方式客户端发送数据,第一次发送leomessi完成后,再发Ronaldo,看看服务端接收时会不会分开接收:

客户端输出:
可见,客户端分两次发送消息数据
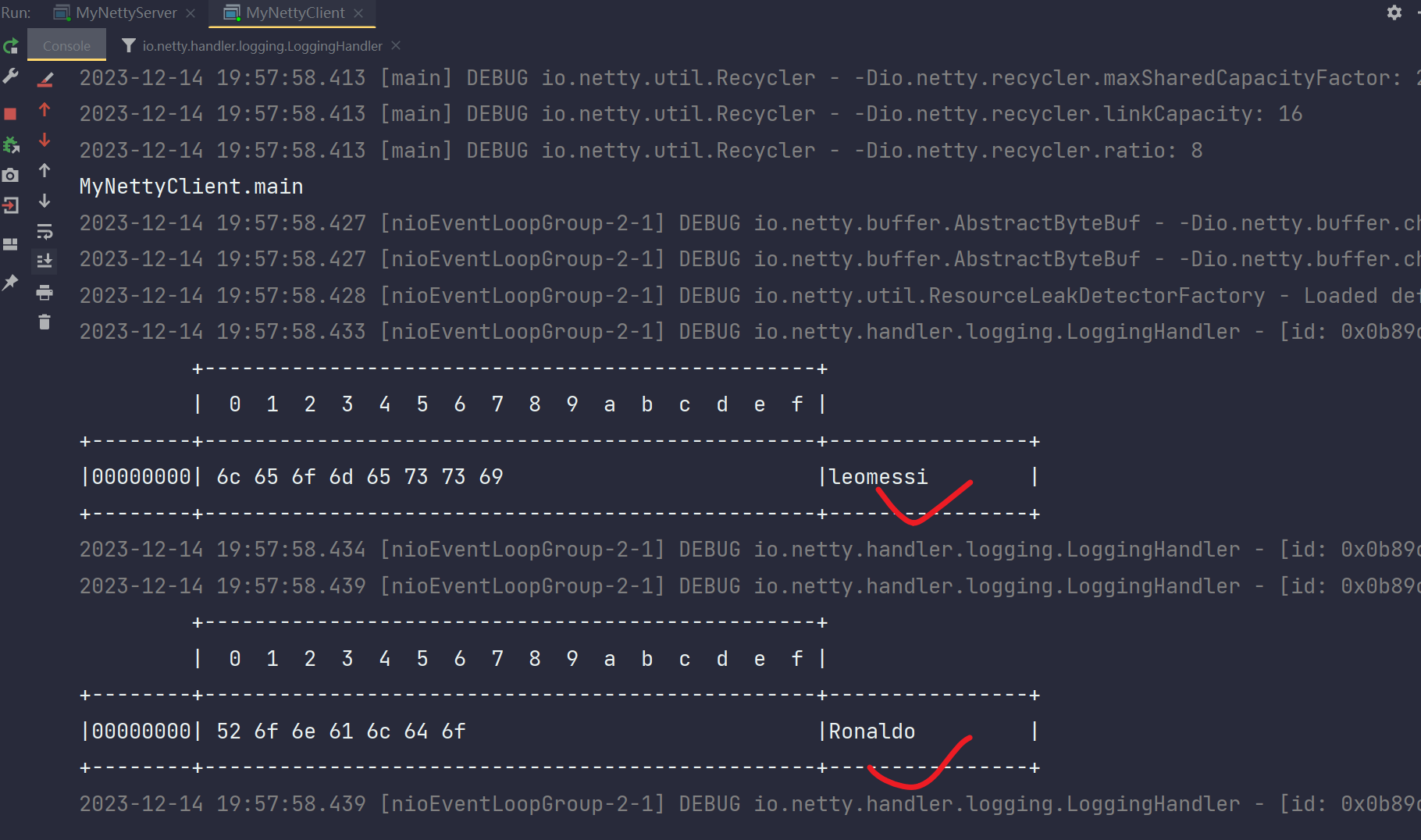
服务端输出:

由于Socket内核缓冲区默认大小为65534字节,ByteBuf默认大小为1024字节,所以都可以一次性可以接收leomessi和Ronaldo。我们知道,缓冲区就是为了提升性能,socket内核缓冲区或ByteBuf缓冲区不会一个字节一字节的进行接收,而是会批量收发。所以出现粘包的可能性有三种:1.滑动窗口大小导致收发数据 2.socket缓冲区的收发数据 3.ByteBuf的收发数据,TCP网络协议栈对数据的操控是一个可逆的过程,他不会把一个消息数据直接变化成半包或粘包,TCP在发送数据时,会将应用程序传输的数据进行分段,并添加TCP头部信息。在接收端,TCP会根据TCP头部信息将分段的数据进行重组,还原为应用程序可用的数据。还原成可用数据后,需要读取到缓冲区,无论是Socket还是ByteBuf的空间大小还是滑动窗口的大小,都有可能一次性读取多条消息数据造成粘包,也可能最后一条消息塞不下导致半包。
这个例子中,虽然客户端发送了两次,第一次发送leomessi,第二次发送Ronaldo,但是对于服务端接收而言,无论是socket缓冲区还是ByteBuf的空间,都具有一次接收完的能力,所以产生粘包,服务端输出得到leomessiRoaldo,把独立的两条消息当作为一条消息来处理了。这就是粘包
- 使用FixedLengthFrameDecoder进行解决
我们约定一个固定的长度来解决这个传输问题,我们知道:leomessi为8字节,Ronaldo为7字节,选取较大的8字节作为每一个消息的固定长度,不足8字节的消息使用 * 进行补齐
客户端:
package com.messi.netty_core_02.netty07;
import io.netty.bootstrap.Bootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.string.StringEncoder;
import io.netty.handler.logging.LoggingHandler;
import java.net.InetSocketAddress;
public class MyNettyClient {
public static void main(String[] args) throws InterruptedException {
Bootstrap bootstrap = new Bootstrap() ;
bootstrap.channel(NioSocketChannel.class);
bootstrap.group(new NioEventLoopGroup());
bootstrap.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LoggingHandler());
pipeline.addLast(new StringEncoder());
}
});
Channel channel = bootstrap.connect(new InetSocketAddress(8000)).sync().channel();
channel.writeAndFlush("leomessi");
channel.writeAndFlush("Ronaldo");
System.out.println("MyNettyClient.main");
}
}- 服务端
package com.messi.netty_core_02.netty07;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.FixedLengthFrameDecoder;
import io.netty.handler.logging.LoggingHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MyNettyServer {
private static final Logger log = LoggerFactory.getLogger(MyNettyServer.class);
public static void main(String[] args) {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.group(new NioEventLoopGroup(1),new NioEventLoopGroup(8));
DefaultEventLoopGroup defaultEventLoopGroup = new DefaultEventLoopGroup() ;
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
//我们这里设置一个定长的解码器,长度为8,来处理半包和粘包的问题,其解析的定长为8字节
pipeline.addLast(new FixedLengthFrameDecoder(8));
pipeline.addLast(new LoggingHandler());
pipeline.addLast(defaultEventLoopGroup,"handler1",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.info("handler1处理,接收到的客户端来的数据为:{}",msg) ;
super.channelRead(ctx,msg) ;
}
});
}
});
serverBootstrap.bind(8000);
}
}在客户端我们看到如下输出:

再看服务端输出内容:
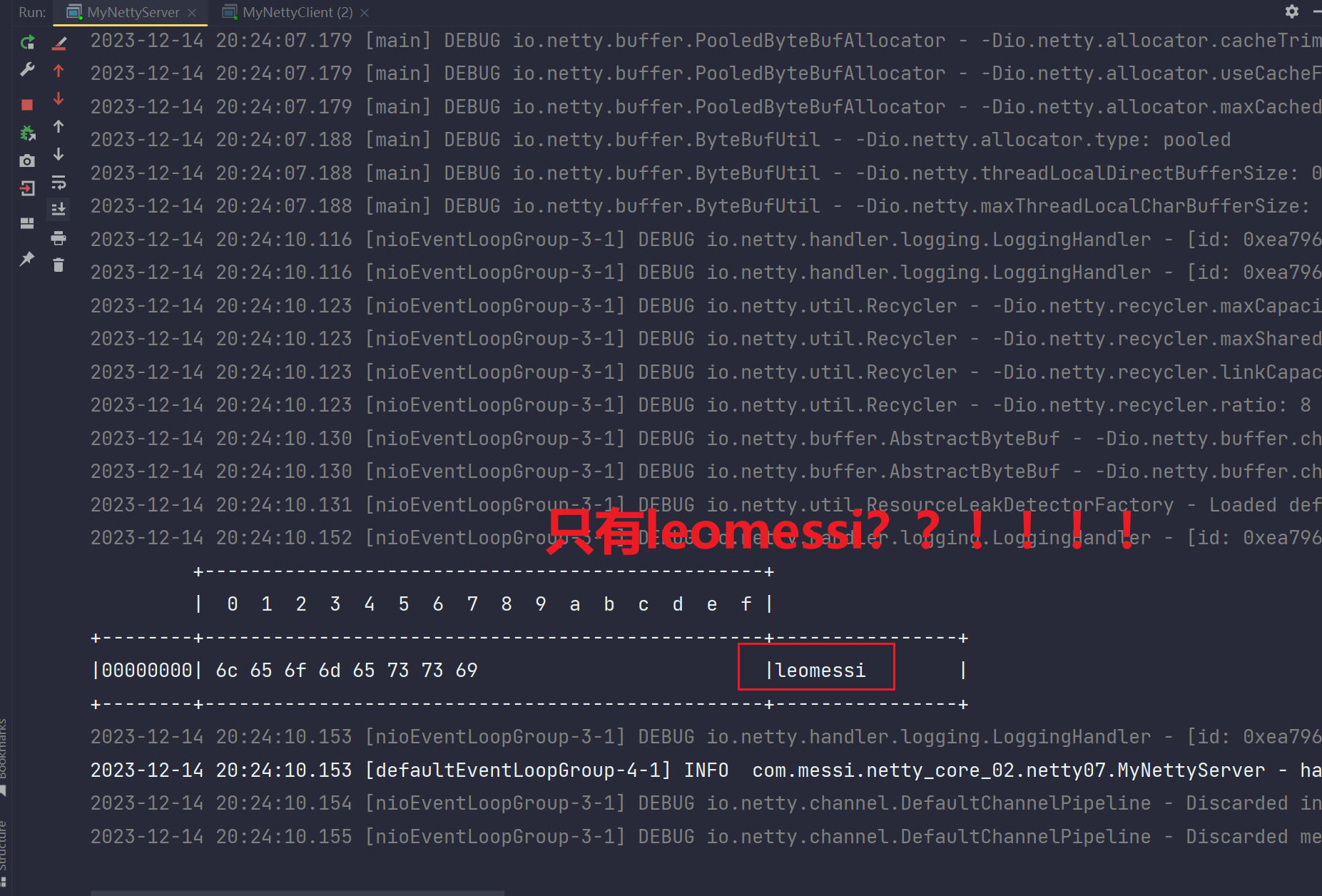
麻了,就收到了leomessi这句话,Ronaldo没输出,仔细检查发现我在Ronaldo不够8个长度,我也没用*补齐,所以那个不足8字节的Ronaldo没处理,可见这个玩意竟然会丢掉不足固定长度的。那么我给不足的补上星号会如何呢?
修改客户端:
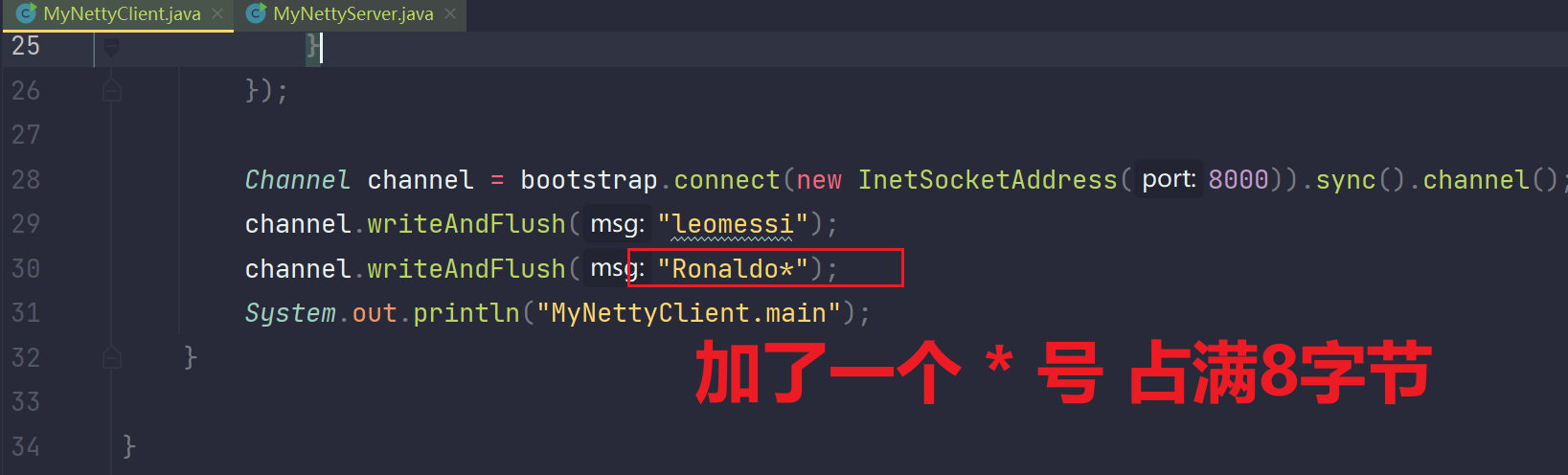
然后看一下服务端的输出:
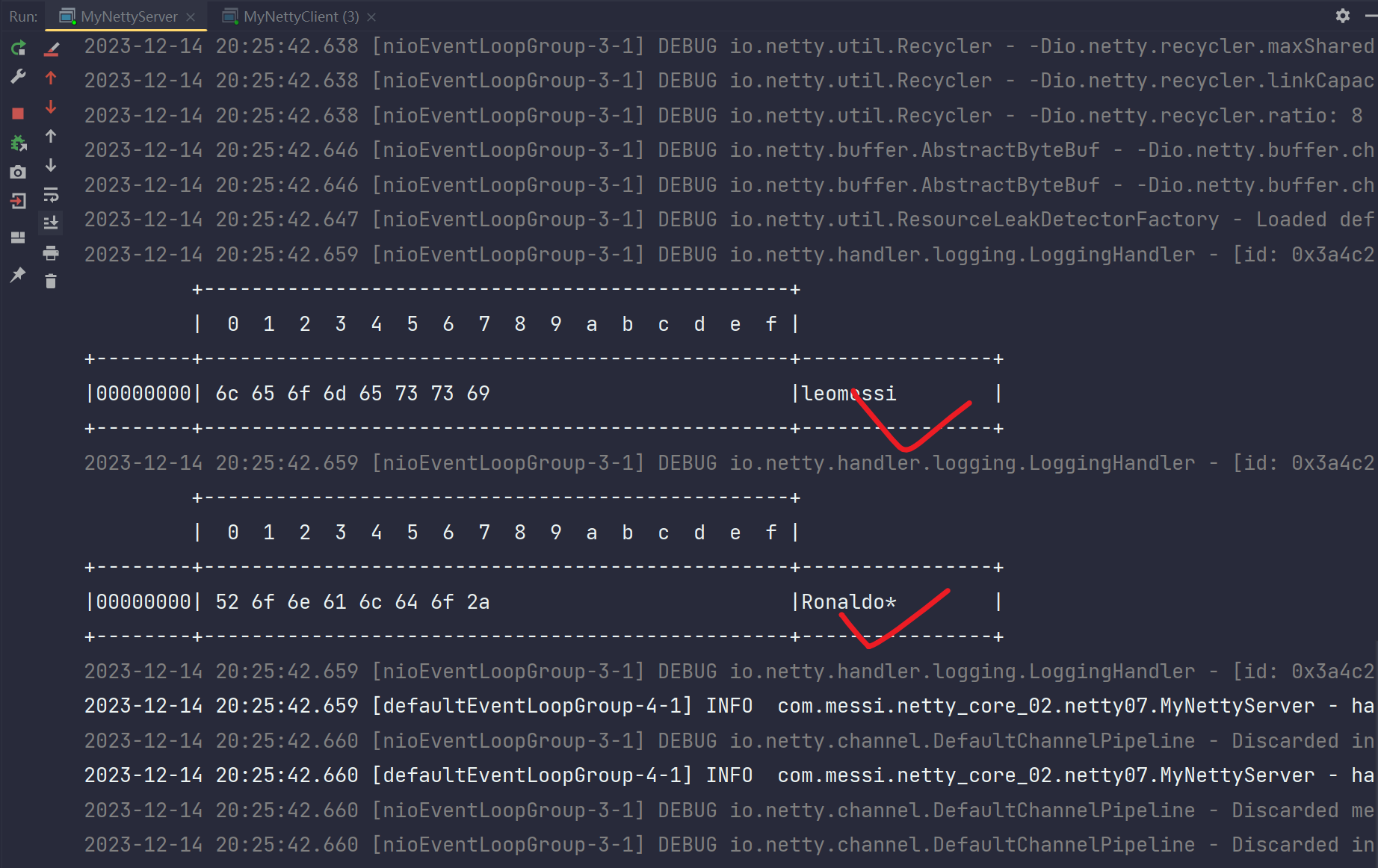
发现Ronaldo接收成功,消息也独立了,但是恶心的是Ronaldo后面加了一个*,这没办法,这是为了凑够8字节搞的,因为服务端规定:"它一次只能接收8字节的消息数据,不足8字节的消息数据会直接丢掉"。所以你必须占满8字节,至于这个*号,你使用replace("*","")方法进行去掉就行。这样就得到了最原始的消息数据。
那么关于黏包他解决了,那么半包呢,其实想都不用想也能解决,因为本质就是固定人为理解的长度。不关你是啥,他都会为你过来不满足要求的长度做拆分,我们来模拟一下半包。半包的模拟有很多种方式,我们不妨先来复习一下半包。半包就是就是我应该接收的是leomessi,你因为缓冲区大小限制给我发过来一个leo,一个me,ssi这种,那我知道你说的是什么几把。
知道了原理,那这里复刻半包就简单了,我可以选择发一个巨长的,让他半句话就打满缓冲区后面的发不进来,就半包了。但是你这个巨长,我就不想弄了,麻烦。
那么我可以改一下缓冲区大小,这个前面在ByteBuf的时候弄过,我们来看一下。因为ByteBuf的大小最小是16,所以我们要把那句话弄的长一点,才能符合半包。leomessiRonaldo666666这个长度超过16,然后我们在代码改一下缓冲长度。
- 复现半包
客户端:
package com.messi.netty_core_02.netty07;
import io.netty.bootstrap.Bootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.string.StringEncoder;
import io.netty.handler.logging.LoggingHandler;
import java.net.InetSocketAddress;
public class MyNettyClient {
public static void main(String[] args) throws InterruptedException {
Bootstrap bootstrap = new Bootstrap() ;
bootstrap.channel(NioSocketChannel.class);
bootstrap.group(new NioEventLoopGroup());
bootstrap.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LoggingHandler());
pipeline.addLast(new StringEncoder());
}
});
Channel channel = bootstrap.connect(new InetSocketAddress(8000)).sync().channel();
// channel.writeAndFlush("leomessi");
// channel.writeAndFlush("Ronaldo*");
channel.writeAndFlush("leomessiRonaldo666666");
System.out.println("MyNettyClient.main");
}
}服务端:
package com.messi.netty_core_02.netty07;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.FixedLengthFrameDecoder;
import io.netty.handler.logging.LoggingHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MyNettyServer {
private static final Logger log = LoggerFactory.getLogger(MyNettyServer.class);
public static void main(String[] args) {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.group(new NioEventLoopGroup(1),new NioEventLoopGroup(8));
DefaultEventLoopGroup defaultEventLoopGroup = new DefaultEventLoopGroup() ;
//设置socket内核缓冲区的大小,注意这里设置的接收recv-socket内核缓冲区的大小
// serverBootstrap.option(ChannelOption.SO_RCVBUF,8);
//接收端的每个连接的ByteBuf内存大小,每个连接自己创建接收ByteBuf数据的大小
// 我们这里定为16,也就是一次只能接收16个长度,不足的下一次发
serverBootstrap.childOption(ChannelOption.RCVBUF_ALLOCATOR,new AdaptiveRecvByteBufAllocator(16,16,16));
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
//我们这里设置一个定长的解码器,长度为8,来处理半包和粘包的问题,其解析的定长为8字节
// pipeline.addLast(new FixedLengthFrameDecoder(8));
pipeline.addLast(new LoggingHandler());
pipeline.addLast(defaultEventLoopGroup,"handler1",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.info("handler1处理,接收到的客户端来的数据为:{}",msg) ;
super.channelRead(ctx,msg) ;
}
});
}
});
serverBootstrap.bind(8000);
}
}客户端输出:
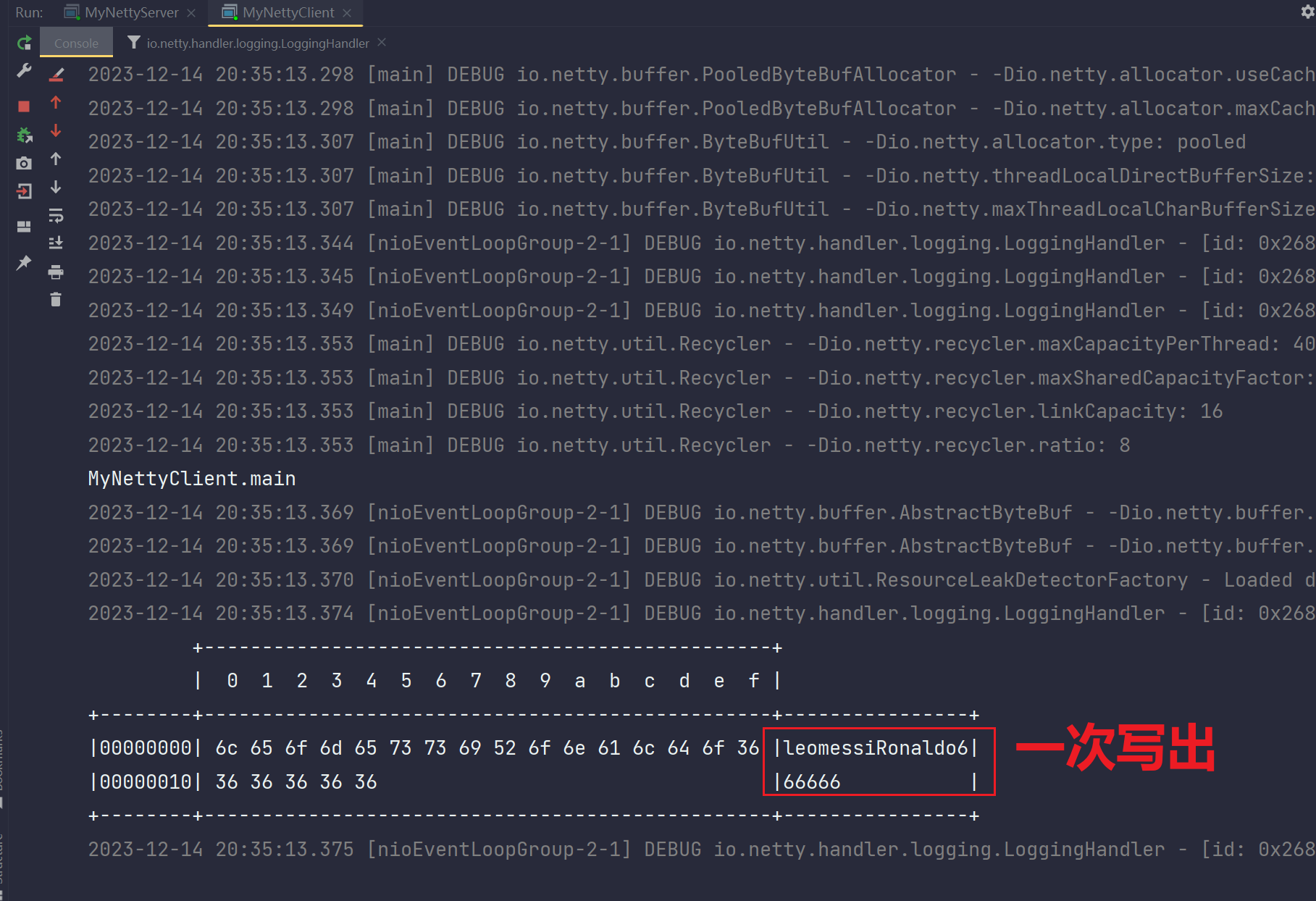
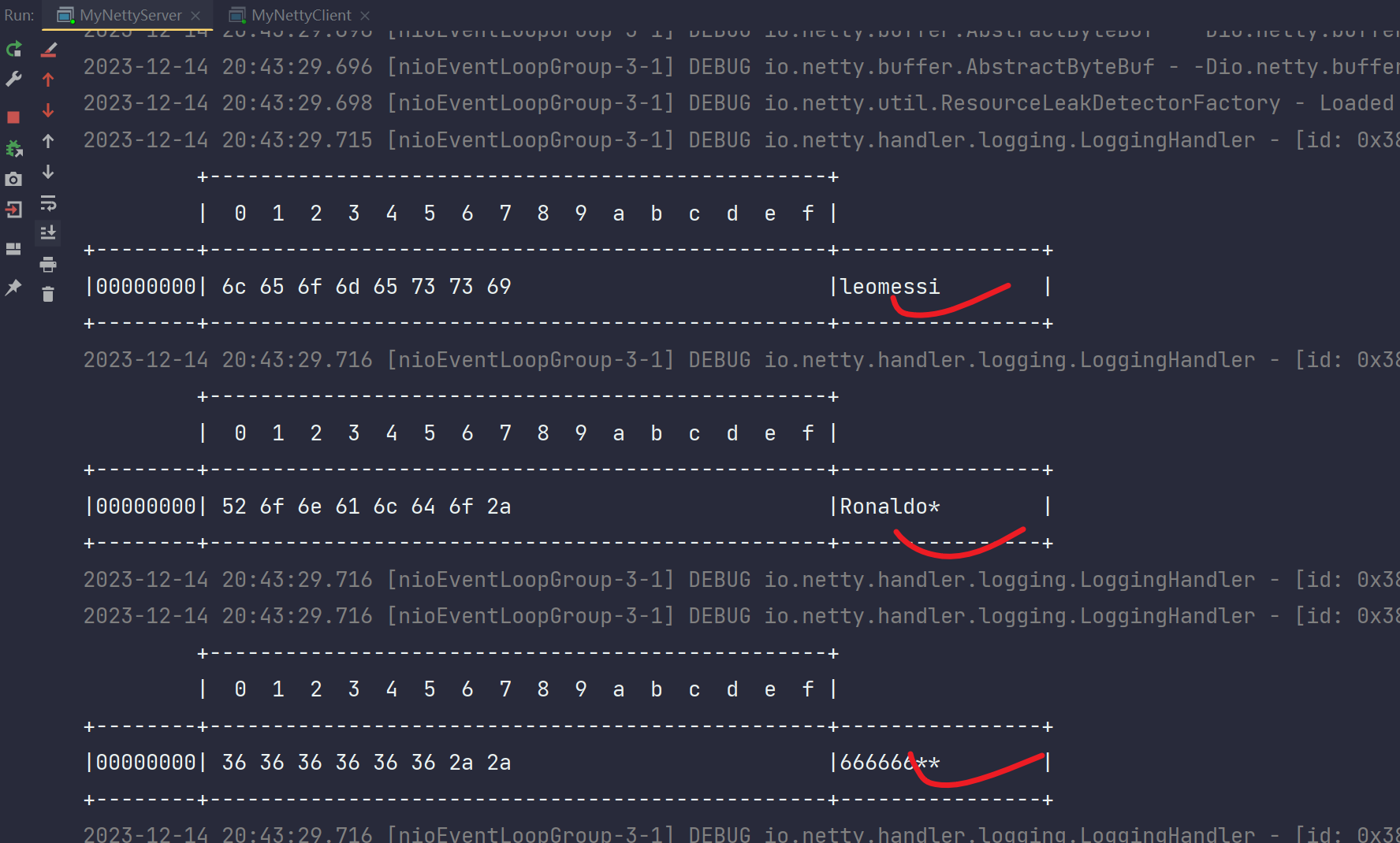
服务端输出:

通过这个现象可以看出,半包粘包同时产生,我们想要的是:服务端分别依次接收三句话:1.leomessi 2.Ronaldo 3.666666
所以在服务端要进行帧解码器规定限制,如何规定?
leomessi 为8字节
Ronaldo 为7字节
666666 为6字节
选取最大的leomessi(8字节)作为帧解码器的固定长度,意思就是帧解码器只能解析8字节大小的消息数据,如果不足8字节则不按一条消息解析。
修改服务端代码:
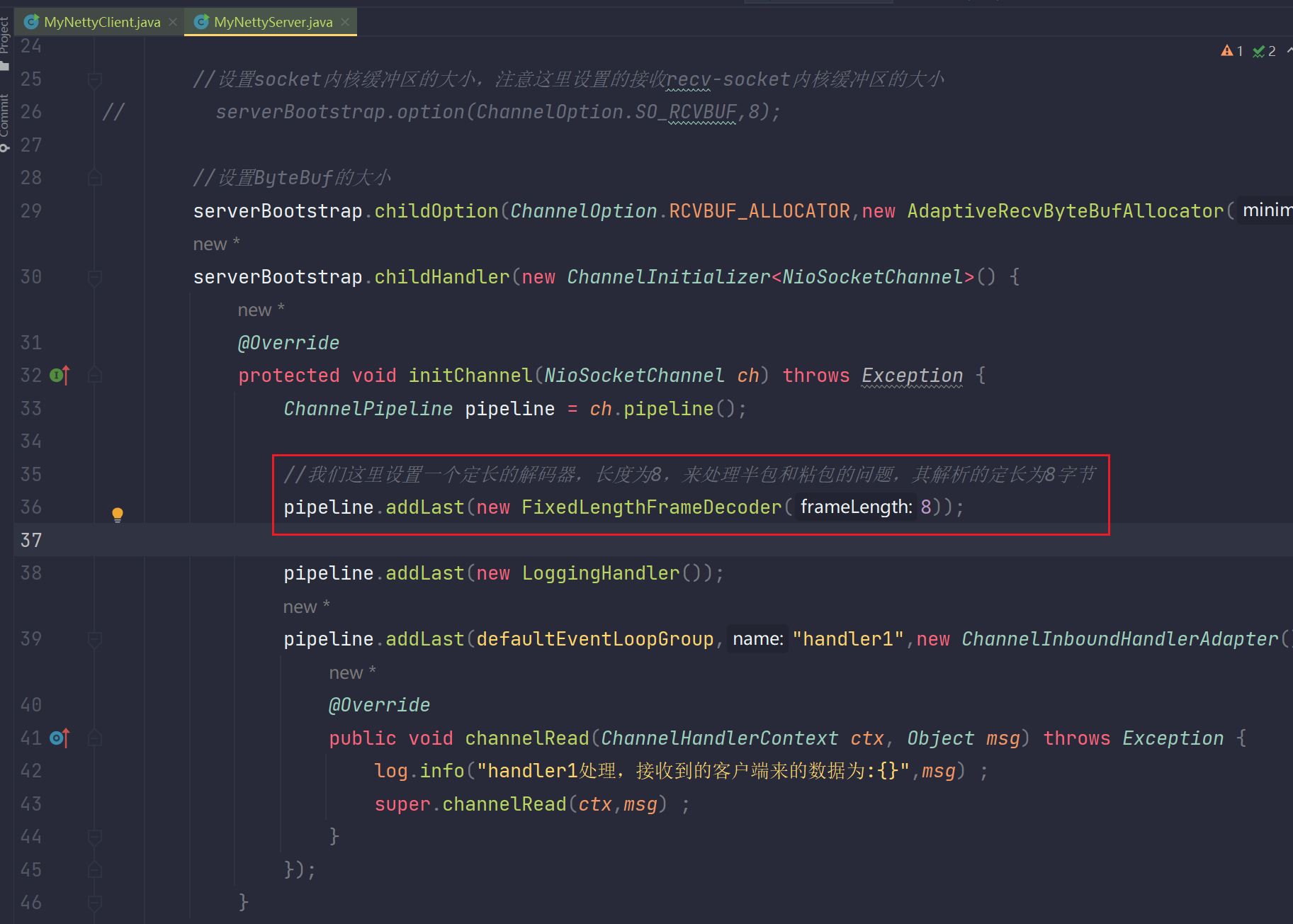
修改客户端代码:

运行输出如下:
客户端输出:
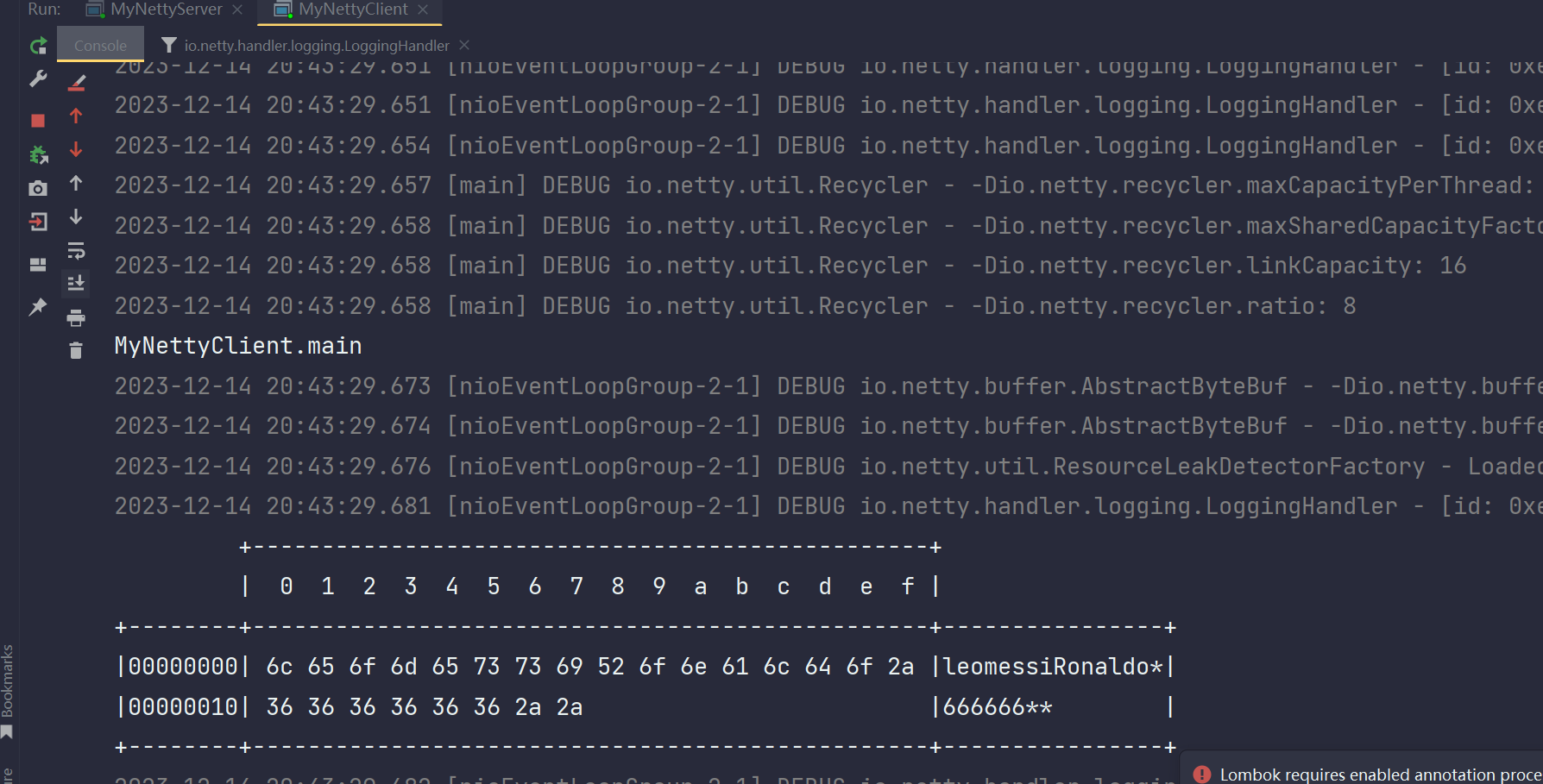
服务端输出:
成功解决半包粘包问题!
21.4.2 LineBasedFrameDecoder
这是第二个处理半包黏包的解码器。
他工作的方式就很朴素。他不要求定长,对于长度无要求,他的设计是要求你在你每一个完整的消息结
尾有一个约定的分隔符,那么我服务端拿到之后就按照你得这个分隔符来拆分消息,得到合理的消息。

- 演示一下
package com.messi.netty_core_02.netty07;
import io.netty.bootstrap.Bootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.string.StringEncoder;
import io.netty.handler.logging.LoggingHandler;
import java.net.InetSocketAddress;
public class MyNettyClient2 {
public static void main(String[] args) throws InterruptedException {
Bootstrap bootstrap = new Bootstrap() ;
bootstrap.channel(NioSocketChannel.class);
bootstrap.group(new NioEventLoopGroup());
bootstrap.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LoggingHandler());
pipeline.addLast(new StringEncoder());
}
});
Channel channel = bootstrap.connect(new InetSocketAddress(8000)).sync().channel();
channel.writeAndFlush("leomessi\nRonaldo\n666666\n");
System.out.println("MyNettyClient.main");
}
}package com.messi.netty_core_02.netty07;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.FixedLengthFrameDecoder;
import io.netty.handler.codec.LineBasedFrameDecoder;
import io.netty.handler.logging.LoggingHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MyNettyServer2 {
private static final Logger log = LoggerFactory.getLogger(MyNettyServer.class);
public static void main(String[] args) {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.group(new NioEventLoopGroup(1),new NioEventLoopGroup(8));
DefaultEventLoopGroup defaultEventLoopGroup = new DefaultEventLoopGroup() ;
//设置socket内核缓冲区的大小,注意这里设置的接收recv-socket内核缓冲区的大小
// serverBootstrap.option(ChannelOption.SO_RCVBUF,8);
//设置ByteBuf的大小
// serverBootstrap.childOption(ChannelOption.RCVBUF_ALLOCATOR,new AdaptiveRecvByteBufAllocator(16,16,16));
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
//我们这里设置一个定长的解码器,长度为8,来处理半包和粘包的问题,其解析的定长为8字节
// pipeline.addLast(new FixedLengthFrameDecoder(8));
//这里使用LineBasedFrameDecoder,传参一个整形意思是当你传过来的消息长度超过50字节,这里就不做拆分处理了,直接放弃。
pipeline.addLast(new LineBasedFrameDecoder(50));
pipeline.addLast(new LoggingHandler());
pipeline.addLast(defaultEventLoopGroup,"handler1",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.info("handler1处理,接收到的客户端来的数据为:{}",msg) ;
super.channelRead(ctx,msg) ;
}
});
}
});
serverBootstrap.bind(8000);
}
}
输出:

客户端输出:

服务端输出:
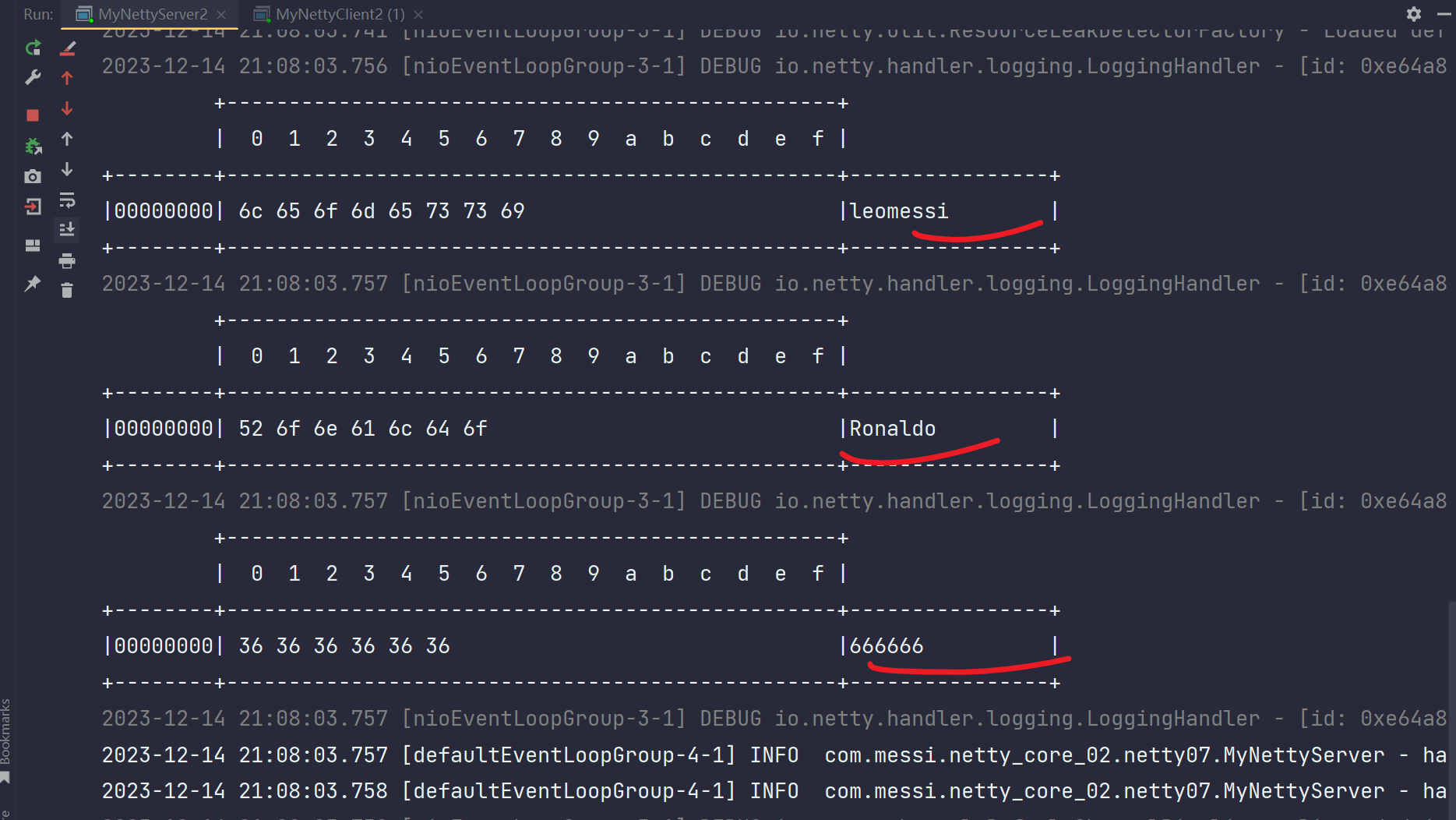
输出成功,解决问题。
但是问题来了,我们说这个帧解码器设置的长度为50,就是一旦发送数据的长度超过50,可能缓冲区就放不下了,那么它是怎么处理的呢?我们再调整一下缓冲区的大小,再测试一下:
修改服务端代码:
运行发现,输出依旧成功正常,无半包粘包问题,即使客户端发生了超过ByteBuf缓冲区大小的数据,但是依旧正常,说明与ByteBuf大小无关。
那我们不改缓冲区大小,就是单纯把那个LineBasedFrameDecoder的最大长度改为5,这个5就破
坏了我们的那个消息长度超过5才有了分割符了,看看效果。

输出:
服务端输出:
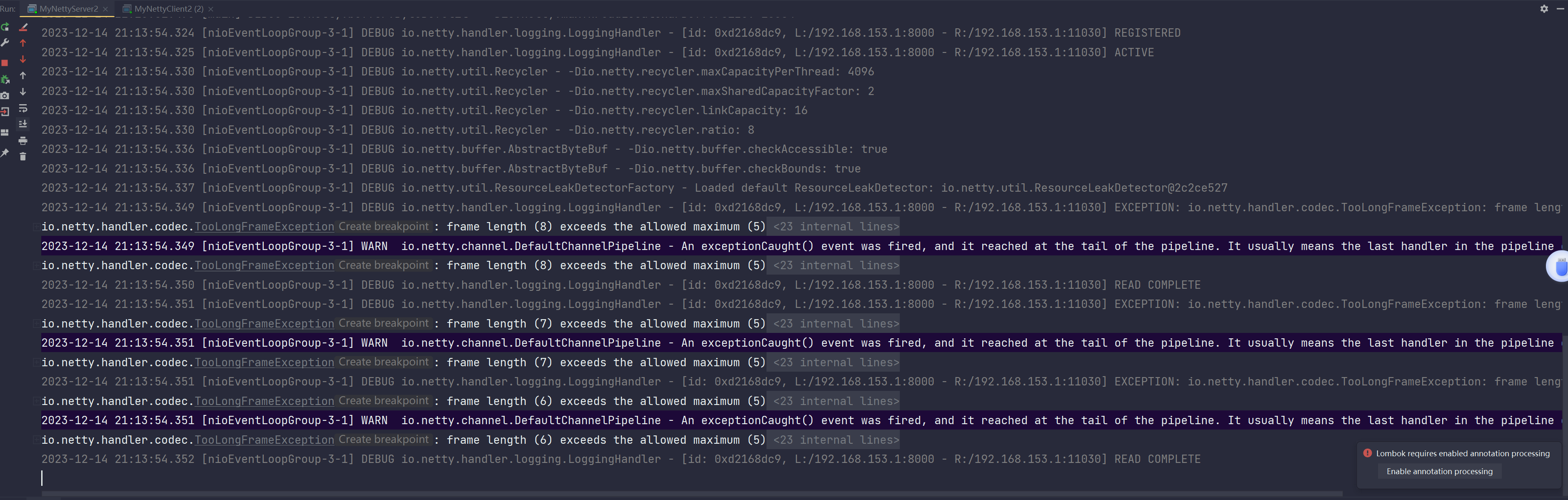
客户端输出:

报错了,所以可以看到他直接不处理了,抛出异常。
所以我们可以看到他的基本用法了。但是他有一个弊端,就是只能使用\n和\r\n的拆分。不能用别的,
对于netty这种大佬级别的框架,这个不会这么死的。于是引出了新的一种解码器。
21.4.3 DelimiterBasedFrameDecoder
DelimiterBasedFrameDecoder这个解码器和上面那个一个意思,就是利用的分割,但是他比较灵活,可以自己指定分割的字符。可以看一下他的构造器。
public DelimiterBasedFrameDecoder(int maxFrameLength, ByteBuf delimiter)
简单测试一下吧
- 客户端
package com.messi.netty_core_02.netty07;
import io.netty.bootstrap.Bootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.string.StringEncoder;
import io.netty.handler.logging.LoggingHandler;
import java.net.InetSocketAddress;
public class MyNettyClient3 {
public static void main(String[] args) throws InterruptedException {
Bootstrap bootstrap = new Bootstrap() ;
bootstrap.channel(NioSocketChannel.class);
bootstrap.group(new NioEventLoopGroup());
bootstrap.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LoggingHandler());
pipeline.addLast(new StringEncoder());
}
});
Channel channel = bootstrap.connect(new InetSocketAddress(8000)).sync().channel();
channel.writeAndFlush("leomessiopRonaldoop666666op");
System.out.println("MyNettyClient.main");
}
}- 服务端
package com.messi.netty_core_02.netty07;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.Unpooled;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.DelimiterBasedFrameDecoder;
import io.netty.handler.codec.FixedLengthFrameDecoder;
import io.netty.handler.codec.LineBasedFrameDecoder;
import io.netty.handler.logging.LoggingHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MyNettyServer3 {
private static final Logger log = LoggerFactory.getLogger(MyNettyServer.class);
public static void main(String[] args) {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.group(new NioEventLoopGroup(1),new NioEventLoopGroup(8));
DefaultEventLoopGroup defaultEventLoopGroup = new DefaultEventLoopGroup() ;
//设置socket内核缓冲区的大小,注意这里设置的接收recv-socket内核缓冲区的大小
// serverBootstrap.option(ChannelOption.SO_RCVBUF,8);
//设置ByteBuf的大小
serverBootstrap.childOption(ChannelOption.RCVBUF_ALLOCATOR,new AdaptiveRecvByteBufAllocator(16,16,16));
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new DelimiterBasedFrameDecoder(50, Unpooled.wrappedBuffer("op".getBytes())));
pipeline.addLast(new LoggingHandler());
pipeline.addLast(defaultEventLoopGroup,"handler1",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.info("handler1处理,接收到的客户端来的数据为:{}",msg) ;
super.channelRead(ctx,msg) ;
}
});
}
});
serverBootstrap.bind(8000);
}
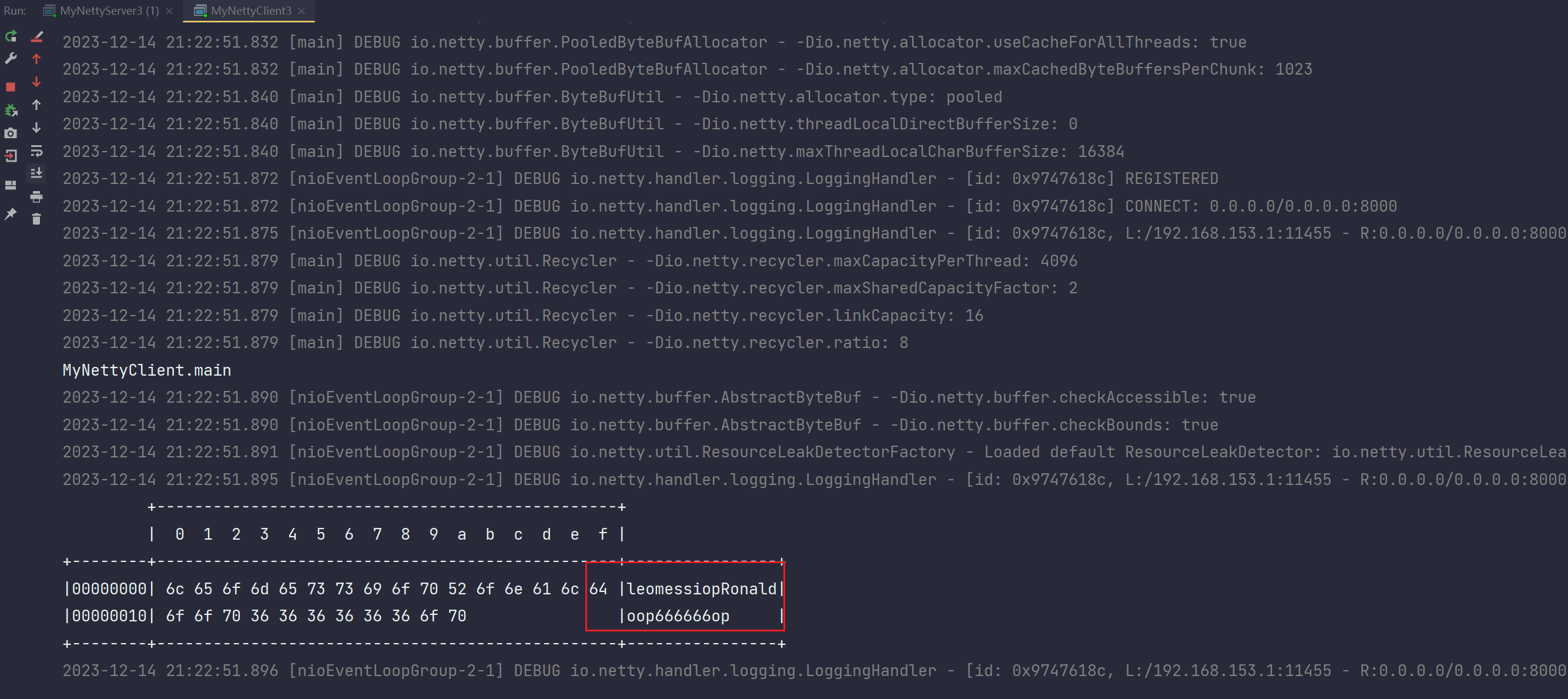
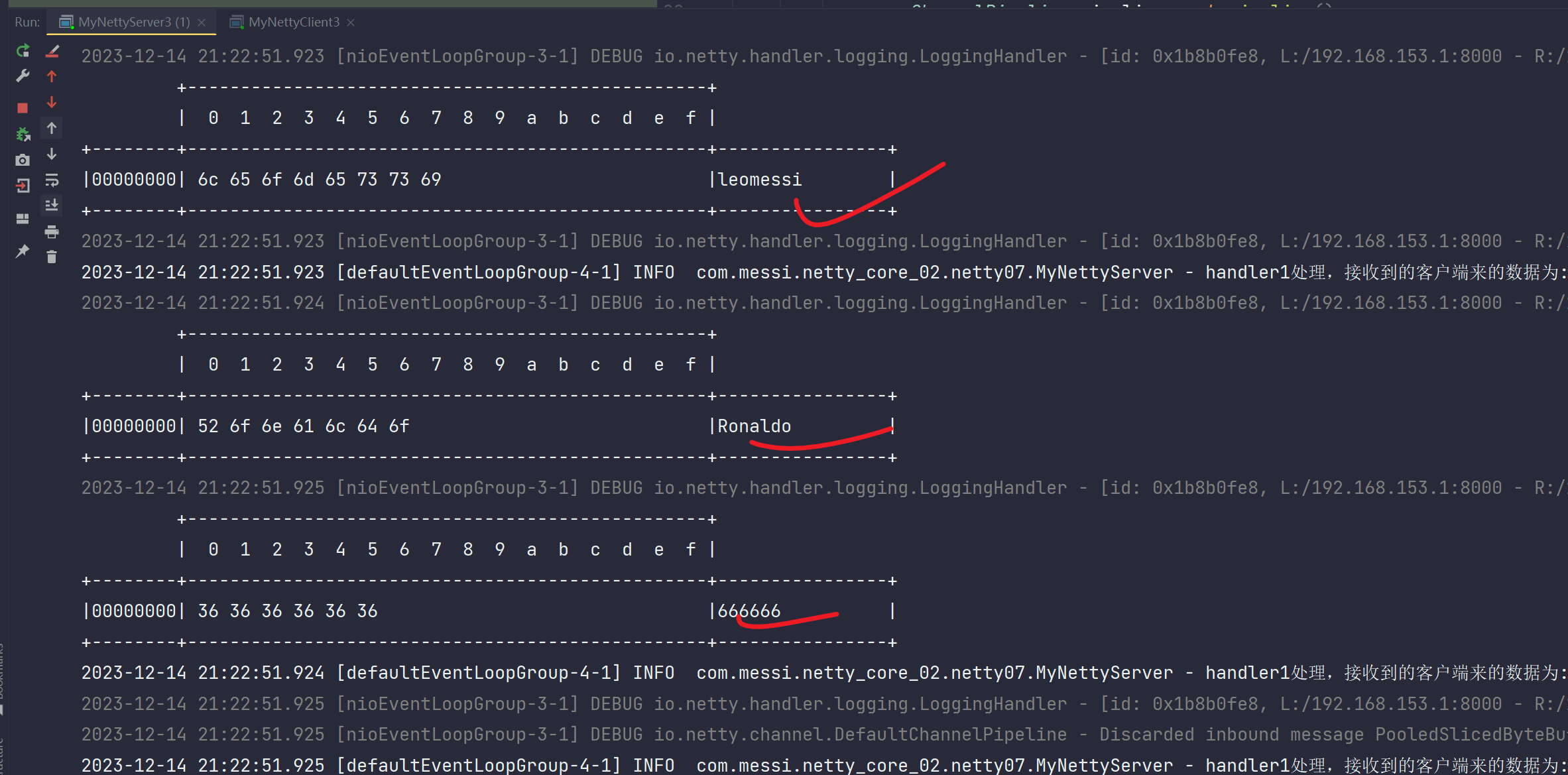
}- 输出
输出成功,解决半包粘包问题。

客户端输出:
服务端输出:
以上三种都是基于约定的分割来拆分的,这个无可厚非,因为TCP传输数据是无边界的流,也就是字节
流。既然无边界,那么自然无法在对端准确识别出边界,就需要约定。 一旦服务端进行约定和限制,那么客户端就要去遵守这一约定和限制,那必然会造成很多局限性。
比如说:第一种定长解码器的空间浪费问题,死板问题,客户端开发发送消息时麻烦的问题。
第二种和第三种分隔符解码器虽然好了很多,但是也有局限性,当发送消息的长度突然不符合服务端解码器规定的长度,在这种特殊情况下,服务端的解码器就无法解码成功了。服务端解码器的长度设置肯定是根据最常见的情况设置,对于特殊情况特别大数据的传输,解码会有问题。
所以netty引入了头体分离式的第四种编码器,这种编码器十分灵活,可灵活处理大字节数和小字节数的数据。
但是netty引出了第四种思路来解决半包和黏包,这种思路在网络协议的包中很常见,就是头体分离。也
就是一个消息分为两部分。
头部信息:存放一些消息的信息,比如长度,比如编码格式,比如时间戳等等。
数据体信息:存放真实的数据内容。
我们根据头部信息得知数据的长度,然后就可以解码读取到数据体信息中真实的数据了。数据可以很大,也可以很小,应对特殊情况,这个解码器非常好用。
头体分离才是主流,王道。
21.4.4 LengthFieldBasedFrameDecoder
这个是最重要,最常用的帧解码器。先给出一个必知要点:两个十六进制位表示一个字节
比如说:0X000C--->有4个十六进制位,占用2字节
A decoder that splits the received ByteBufs dynamically by the value of the length field in the message. It is particularly useful when you decode a binary message which has an integer header field that represents the length of the message body or the whole message.
LengthFieldBasedFrameDecoder has many configuration parameters so that it can decode any message with a length field, which is often seen in proprietary client-server protocols. Here are some example that will give you the basic idea on which option does what.
2 bytes length field at offset 0, do not strip header
The value of the length field in this example is 12 (0x0C) which represents the length of "HELLO, WORLD". By default, the decoder assumes that the length field represents the number of the bytes that follows the length field. Therefore, it can be decoded with the simplistic parameter combination.
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = 0
initialBytesToStrip = 0 (= do not strip header)
BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
+--------+----------------+ +--------+----------------+
| Length | Actual Content |----->| Length | Actual Content |
| 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+
2 bytes length field at offset 0, strip header
Because we can get the length of the content by calling ByteBuf.readableBytes(), you might want to strip the length field by specifying initialBytesToStrip. In this example, we specified 2, that is same with the length of the length field, to strip the first two bytes.
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = 0
initialBytesToStrip = 2 (= the length of the Length field)
BEFORE DECODE (14 bytes) AFTER DECODE (12 bytes)
+--------+----------------+ +----------------+
| Length | Actual Content |----->| Actual Content |
| 0x000C | "HELLO, WORLD" | | "HELLO, WORLD" |
+--------+----------------+ +----------------+
2 bytes length field at offset 0, do not strip header, the length field represents the length of the whole message
In most cases, the length field represents the length of the message body only, as shown in the previous examples. However, in some protocols, the length field represents the length of the whole message, including the message header. In such a case, we specify a non-zero lengthAdjustment. Because the length value in this example message is always greater than the body length by 2, we specify -2 as lengthAdjustment for compensation.
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = -2 (= the length of the Length field)
initialBytesToStrip = 0
BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
+--------+----------------+ +--------+----------------+
| Length | Actual Content |----->| Length | Actual Content |
| 0x000E | "HELLO, WORLD" | | 0x000E | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+
3 bytes length field at the end of 5 bytes header, do not strip header
The following message is a simple variation of the first example. An extra header value is prepended to the message. lengthAdjustment is zero again because the decoder always takes the length of the prepended data into account during frame length calculation.
lengthFieldOffset = 2 (= the length of Header 1)
lengthFieldLength = 3
lengthAdjustment = 0
initialBytesToStrip = 0
BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes)
+----------+----------+----------------+ +----------+----------+----------------+
| Header 1 | Length | Actual Content |----->| Header 1 | Length | Actual Content |
| 0xCAFE | 0x00000C | "HELLO, WORLD" | | 0xCAFE | 0x00000C | "HELLO, WORLD" |
+----------+----------+----------------+ +----------+----------+----------------+
3 bytes length field at the beginning of 5 bytes header, do not strip header
This is an advanced example that shows the case where there is an extra header between the length field and the message body. You have to specify a positive lengthAdjustment so that the decoder counts the extra header into the frame length calculation.
lengthFieldOffset = 0
lengthFieldLength = 3
lengthAdjustment = 2 (= the length of Header 1)
initialBytesToStrip = 0
BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes)
+----------+----------+----------------+ +----------+----------+----------------+
| Length | Header 1 | Actual Content |----->| Length | Header 1 | Actual Content |
| 0x00000C | 0xCAFE | "HELLO, WORLD" | | 0x00000C | 0xCAFE | "HELLO, WORLD" |
+----------+----------+----------------+ +----------+----------+----------------+
2 bytes length field at offset 1 in the middle of 4 bytes header, strip the first header field and the length field
This is a combination of all the examples above. There are the prepended header before the length field and the extra header after the length field. The prepended header affects the lengthFieldOffset and the extra header affects the lengthAdjustment. We also specified a non-zero initialBytesToStrip to strip the length field and the prepended header from the frame. If you don't want to strip the prepended header, you could specify 0 for initialBytesToSkip.
lengthFieldOffset = 1 (= the length of HDR1)
lengthFieldLength = 2
lengthAdjustment = 1 (= the length of HDR2)
initialBytesToStrip = 3 (= the length of HDR1 + LEN)
BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
+------+--------+------+----------------+ +------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xCA | 0x000C | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+------+--------+------+----------------+ +------+----------------+
2 bytes length field at offset 1 in the middle of 4 bytes header, strip the first header field and the length field, the length field represents the length of the whole message
Let's give another twist to the previous example. The only difference from the previous example is that the length field represents the length of the whole message instead of the message body, just like the third example. We have to count the length of HDR1 and Length into lengthAdjustment. Please note that we don't need to take the length of HDR2 into account because the length field already includes the whole header length.
lengthFieldOffset = 1
lengthFieldLength = 2
lengthAdjustment = -3 (= the length of HDR1 + LEN, negative)
initialBytesToStrip = 3
BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
+------+--------+------+----------------+ +------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xCA | 0x0010 | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+------+--------+------+----------------+ +------+----------------
对于上述是该类的注释,我们先做以下分析:
我们来看这个解码器的构造函数:
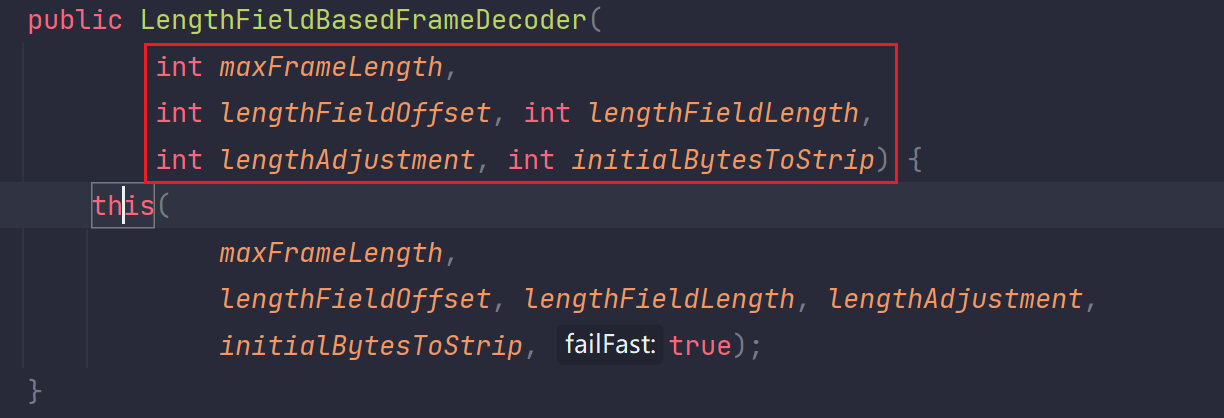
我们看到它有五个参数,其中第一个就是控制整个消息数据的最大长度的,超过这个长度就会抛出异常,这个就是看你业务设计,这个就是看你业务设计了,你业务需求有多大就设置多大,这里不分析。
实际上的半包粘包解决是依赖于后面四个参数来解决的,并且把源码注释贴出来,注释中把它们的功能都描述了一遍,后面看完例子再回头看注释就会很明确。
Creates a new instance.
Params:
maxFrameLength – the maximum length of the frame. If the length of the frame is greater than this value, TooLongFrameException will be thrown.
lengthFieldOffset – the offset of the length field
lengthFieldLength – the length of the length field
lengthAdjustment – the compensation value to add to the value of the length field
initialBytesToStrip – the number of first bytes to strip out from the decoded frame
----》deepl翻译
创建一个新实例。
参数
maxFrameLength - 帧的最大长度。如果帧的长度大于此值,将产生 TooLongFrameException 异常。
lengthFieldOffset - 长度字段的偏移量
lengthFieldLength - 长度字段的长度
lengthAdjustment - 要添加到长度字段值的补偿值
initialBytesToStrip - 要从解码帧中剥离的第一个字节数
21.4.4.1 情况1
来解释第一种情况:
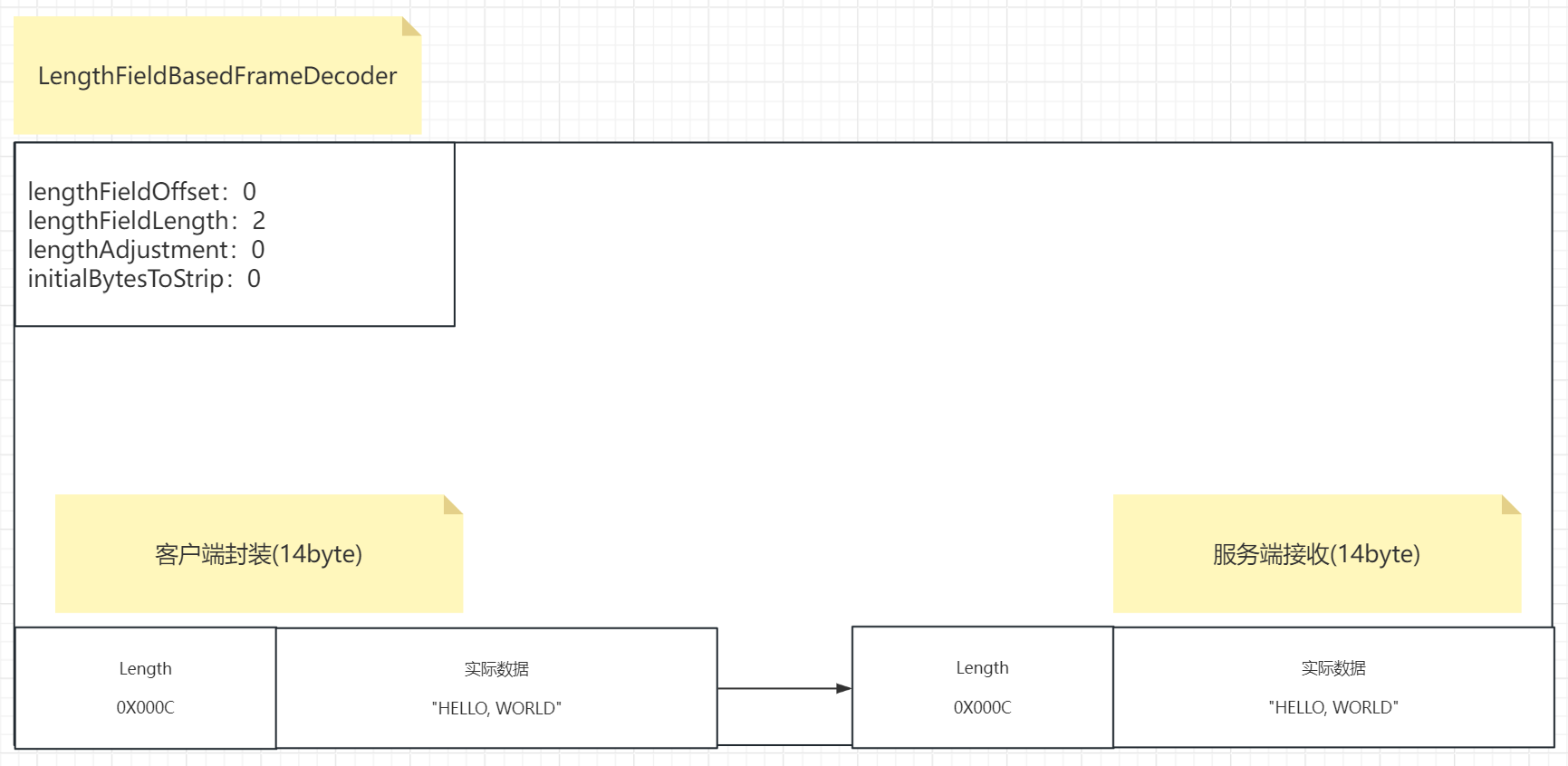
首先我们看到的这个数据在编码的时候没有设计什么分隔符,也没有什么固定长度。它是使用了一种叫做头体分离的设计。如图所示:把这个消息数据分为两部分,第一部分是头,也就是Length字段,该字段的值是以16进制进行表示的,两个16进制位表示一个字节,所以该字段占用两个字节的大小。并且16进制的C表示十进制数值12,该Length字段值为12表示后面第二部分的实际数据"HELLO, WORLD"这个字符串的长度为12字节,分析一下:该字符串一共有10个字符+1个逗号+1个空格,占用12字节的存储空间,所以0X000C表示的实际上是实际数据所占用的长度大小。所以可以看出这个消息数据在构建的时候就已经在头部标明了消息体实际数据的长度,而消息体的真实数据就放在消息头的后面。
而这个消息在LengthFieldBasedFrameDecoder的处理主要受控于上面四个参数,我们看到这里的例子中那四个参数为:
lengthFieldOffset:0 表示Length字段在消息中的偏移量,当前情况对应的Length字段就是位于该消息的第一部分,直接顶头,所以该值就是0
lengthFieldLength:2 表示Length这个属性字段在消息中占用的长度,因为0X000C这是一个16进制数,0X是标识位不计算,两个十六进制位占用1个字节,所以00为1字节,0C为1字节,一共2字节,所以这个值就是2
lengthAdjustment:0 这个参数这里还没涉及到,当前情况处于简单情况,后面会使用到,所以这里设置为0,该字段表示的是Length属性字段与实际数据体属性之间的间隔长度,可能不挨着,中间跳过多少呢?如果不挨着,中间跳过2字节,那么该字段值就是2。但是本例子中,Length字段与真实数据挨着,所以该值为0
initialBytesToStrip:0 这个参数这里还没涉及到,当前情况处于简单情况,后面会使用到,所以这里设置为0,该字段实际上就表示最终获取消息要不要去除头部字段的长度,去除多少个长度,所谓头部字段就是除去实际数据体的所有字段。由于我们这里先全部获取,所以设置为0。
所以此时客户端封装完这个消息数据后,数据大小其实为14字节,因为头占了两个字节,实际数据消息只占用了两个字节大小。
而服务端接收到之后,它是如何读取的呢?
基于这个控制之下,我们其实就能完整的处理这个消息数据,我们来看一下是不是能做到控制消息了:
服务端接收到消息数据之后,读取这四个参数发现:lengthFieldOffset为0,表示Length字段没有发生偏移或者说偏移为0,直接从初始位置读取Length这一字段数据。
那么读取多少个长度呢?第二个参数lengthFieldLength为2,表示头部信息在消息数据中占用了两个字节大小,那么就读取两个字节的内容数据,发现是0X000C,于是发现Length字段的值为12字节,此时他就知道实际内容长度是12字节,然后往后读取12个字节就得到了"HELLO, WORLD"这一真实内容,后面两个参数因为都是0,此时还没有生效,所以都先不说了。
此时就可以了,服务端再接收到数据之后按照设置的字段属性的值就能获取到必要的消息的信息,从而截取到想要的部分。
此时我们看到这四个属性完成了对于消息的完整的获取,他通过设置一些额外的标识来界定消息的位置,从而实现解析的结果完整和正确。
21.4.4.2 情况2
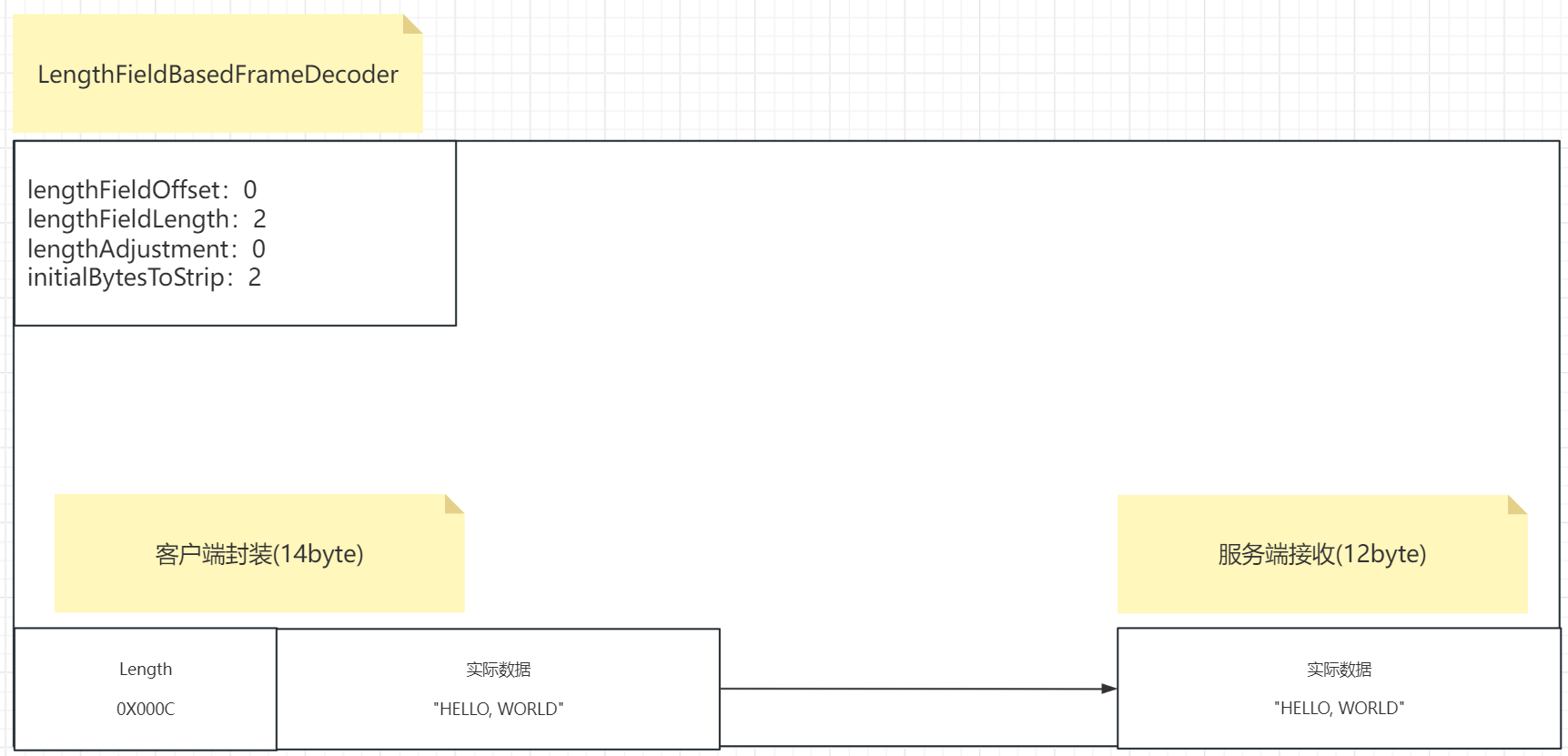
# 我们来解释第二种情况。
情况2和情况1并无太大区别,就是在服务端接收到数据之后获取的真实的数据,没有消息的头部length,他剥离了消息头,拿到了真实的数据。这个也是通过四个参数去控制的。我们看一下。
我们看到这里的例子中那四个参数为:
lengthFieldOffset:0 表示length在消息中的偏移量,我们这个length就是在这个消息的第一部分,
直接顶头,所以就是0.
lengthFieldLength:2 表示length这个属性在消息中占的长度,因为0x000C这是个16进制数,0x是标识不说,00占一个字节 0C占一个字节,共两个字节,所以这个值就是2.
lengthAdjustment:0:这个参数这里还没涉及,我们这个例子处于简单模式,后面会用到,设置为0即可。实际表示length属性和实际数据属性之间的间隔长度,可能不挨着,中间跳过多少,目前我们这个例子是挨着的,所以就是0.
initialBytesToStrip:2 这个参数表示最终获取消息要不要去除头部的长度,去除剥离多少个长度,只
取实际内容,这里设置为2,也就是说最终结果去除2个字节的长度,其实就是去除了头了,得到了真实数据。
所以此时客户端封装完这个消息之后,数据大小其实是14字节,因为头占了两个字节,实际数据消息占了十二个字节。
而服务端收到之后,他是如何读取呢?
基于这个控制之下,我们其实就能完整的处理这个消息,我们来看一下是不是能做到控制消息了:
服务端收到之后,读取这四个参数发现,lengthFieldOffset为0,length没有发生偏移或者说偏移为0,直接从初始位置读取length,那么读取多少个长度呢,第二个参数lengthFieldLength为2,表示头部信息在消息占了两个字节,那就读取两个字节的内容,发现是0X000C,于是发现Length的值是12,此时他就知道实际内容长度是12字节,然后往后读12个字节就得到了"HELLO, WORLD"真实内容。
后面initialBytesToStrip:2就要剥离两个字节的头部,那就去掉了,得到真实的数据。
此时我们看到这四个属性完成了对于消息的完整的获取,他通过设置一些额外的标识来界定消息的位置,从而实现解析的结果完整和正确。
21.4.4.3 情况3
# 我们来解释第三种情况。
情况3的消息相对比上面有些复杂,在length前面多一个header的内容,这个很常见,网络编程里面你的消息头部设计会有很多头有时候,TCP也是这样的,ip报头,tcp报头各种内容。
我们看到这里的例子中那四个参数为:
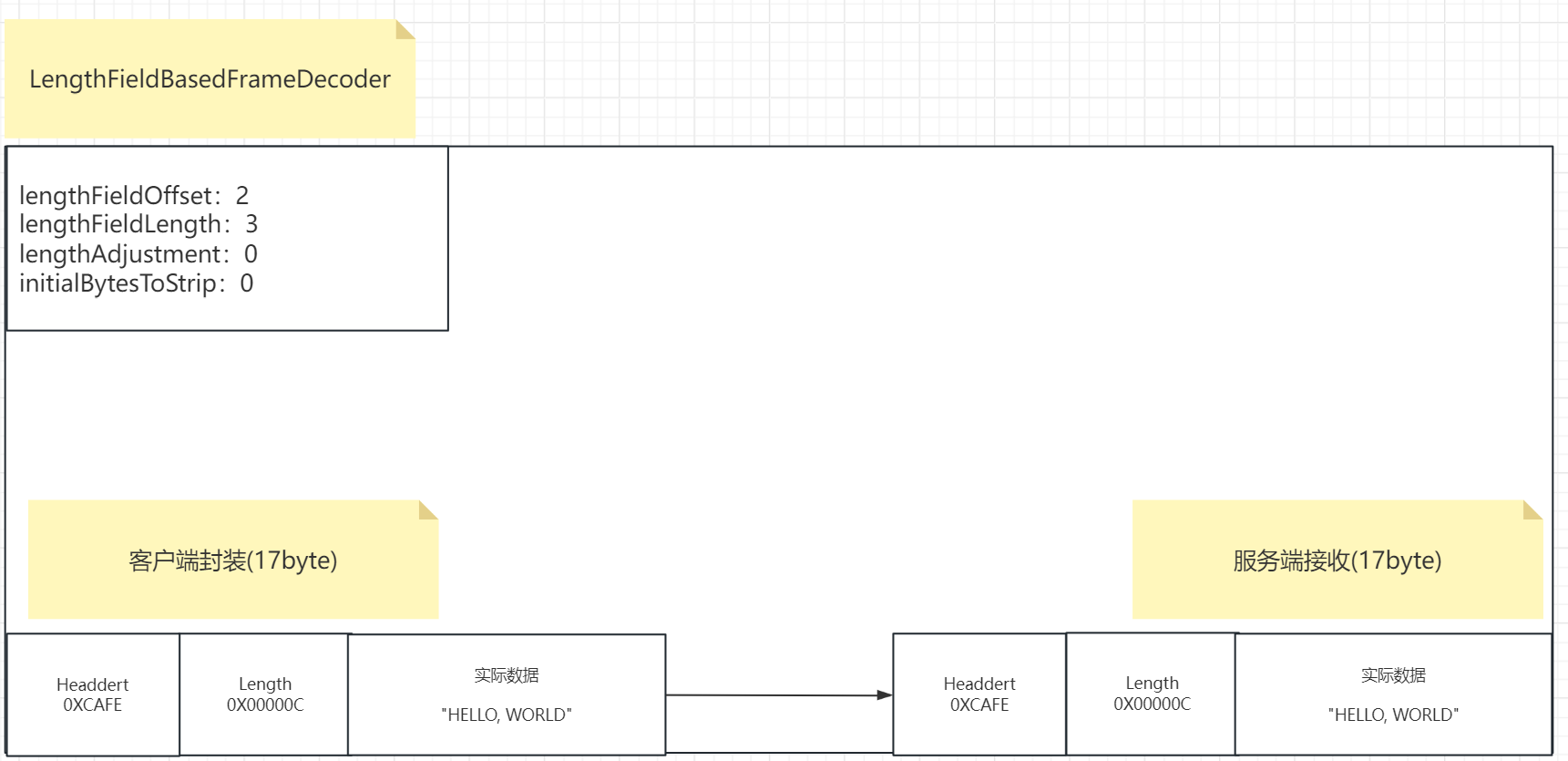
lengthFieldOffset:2 表示length在消息中的偏移量,我们这个length属性此时不在消息的顶头位置
了,他的前面有一个heder1的内容,这个header1长度是2字节,所以legth属性的位置是在消息顶格偏移
两个字节的位置,也就是header1的后面,此时就能定位length的位置了。
lengthFieldLength:3 表示length这个属性在消息中占的长度,因为0X00000C这是个16进制数,0x是标识不说,00 00占两个字节 0C占一个字节,共三个字节,所以这个值就是3.此时就能说明kength这个属性是存储在三个字节长度里面的,读取这三个字节的存储的值就能读取到length的值。
lengthAdjustment:0:这个参数这里还没涉及,我们这个例子处于简单模式,后面会用到,设置为0即可。实际表示length属性和实际数据属性之间的间隔长度,可能不挨着,中间跳过多少,目前我们这个例子是挨着的,所以就是0.
initialBytesToStrip:0 这个参数表示最终获取消息要不要去除头部的长度,去除剥离多少个长度,只
取实际内容,这里设置为0,我们假定不剥离头部,接收端全部接收,所以就是0。
所以此时客户端封装完这个消息之后,数据大小其实是17字节,因为head1占了两个字节,存储length占了三个字节,实际数据消息占了十二个字节。
而服务端收到之后,他是如何读取呢?
基于这个控制之下,我们其实就能完整的处理这个消息,我们来看一下是不是能做到控制消息了:
服务端收到之后,读取这四个参数发现,lengthFieldOffset为2,length位置存在偏移,偏移两个字节,那就跳过两个字节开始读取到的就是length属性。
那么读取多少个长度呢,第二个参数lengthFieldLength为3,表示头部信息在消息占了3个字节,那就读取3个字节的内容,发现是0X00000C,0X00000C表示的值是12,于是发现Length的值是12,此时他就知道实际内容长度是12字节,然后往后读12个字节就得到了"HELLO, WORLD"真实内容。
后面initialBytesToStrip:0 不剥离头部,全部获取,所以服务端拿到的就是全部整个消息 header1 length 还有实际数据。
此时我们看到这四个属性完成了对于消息的完整的获取,他通过设置一些额外的标识来界定消息的位置,从而实现解析的结果完整和正确。
21.4.4.4 情况4
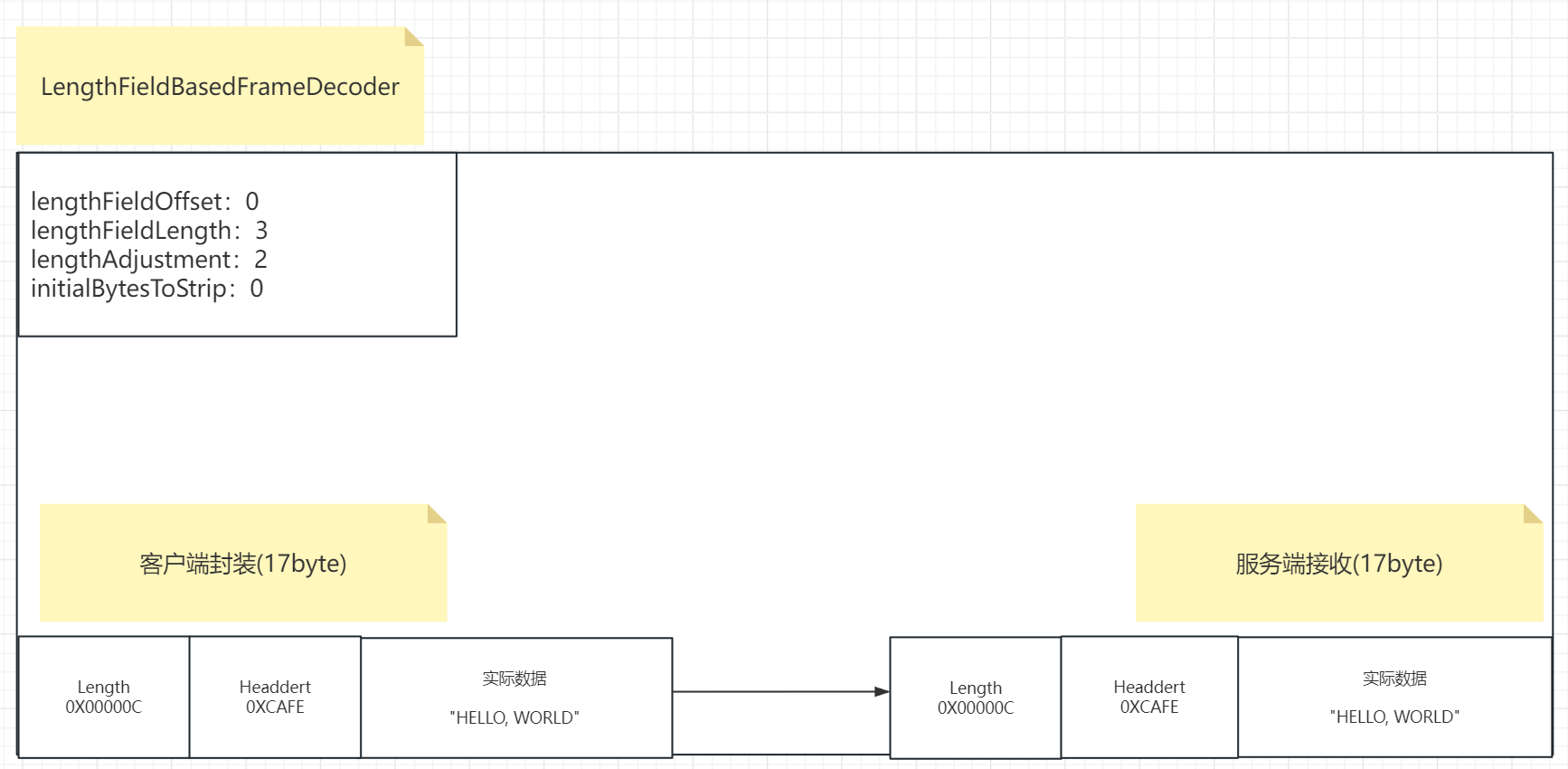
# 我们来解释第四种情况。
情况4的消息相对比上面有些复杂,此时的length位于消息的顶格部分,而在length和实际数据之间加了一个header1的部分。这个情况将会引出lengthAdjustment属性。
我们看到这里的例子中那四个参数为:
lengthFieldOffset:0 表示length在消息中的偏移量,我们这个length此时位于消息的顶格部分,所
以偏移量为0。
lengthFieldLength:3 表示length这个属性在消息中占的长度,因为0X00000C这是个16进制数,0x是标识不说,00 00占两个字节 0C占一个字节,共三个字节,所以这个值就是3.此时就能说明kength这个属性是存储在三个字节长度里面的,读取这三个字节的存储的值就能读取到length的值。
lengthAdjustment:2:表示length属性和实际数据属性之间的间隔长度,可能不挨着,中间跳过多少,目前我们这个例子的length的位置和实际数据之间不是挨着的,中间间隔着一个存储0XCAFE的header1的东西,其长度为2字节,因为CA FE每两个内容是一个字节。所以这个表示了length和实际数据的距离也就是2。这个参数的目的是为了当length和数据不挨着的时候,能明确跳过多长找到实际数据的位置,因为length是表示实际数据的长度的,你得在通过lengthFieldOffset的偏移在读到length的时候还能找到实际数据。
initialBytesToStrip:0 这个参数表示最终获取消息要不要去除头部的长度,去除剥离多少个长度,只
取实际内容,这里设置为0,我们假定不剥离头部,接收端全部接收,所以就是0。所以此时客户端封装完这个消息之后,数据大小其实是17字节,因为head1占了两个字节,存储length占了三个字节,实际数据消息占了十二个字节。
而服务端收到之后,他是如何读取呢?
基于这个控制之下,我们其实就能完整的处理这个消息,我们来看一下是不是能做到控制消息了:
服务端收到之后,读取这四个参数发现,lengthFieldOffset为0,length位置顶格了,直接读取就
行,那么读取多少个长度呢,第二个参数lengthFieldLength为3,表示头部信息在消息占了3个字节,那就读取3个字节的内容,发现是0X00000C,0X00000C表示的值是12,于是发现Length的值是12,此时他就知道实际内容长度是12字节。但是此时lengthAdjustment:2,他表示length和数据存在距离为2,所以他要跳过2字节的长度去读取真是数据,跳过2字节往后读12个字节就得到了"HELLO, WORLD"真实内容。后面initialBytesToStrip:0 不剥离头部,全部获取,所以服务端拿到的就是全部整个消息header1 length 还有实际数据。
此时我们看到这四个属性完成了对于消息的完整的获取,他通过设置一些额外的标识来界定消息的位置,从而实现解析的结果完整和正确。
21.4.4.5 情况5

# 我们来解释第五种情况。
情况5的消息相对比上面有些复杂,消息分为四个部分,两个head分别存储一字节的内容,而length位于两个head之间,实际数据依然是hello world
我们看到这里的例子中那四个参数为:
lengthFieldOffset:1 表示length在消息中的偏移量,我们这个length此时位于head1之后,所以是
偏移量为1
lengthFieldLength:2 表示length这个属性在消息中占的长度,因为0X000C这是个16进制数,0x是标识不说,00 一个字节 0C占一个字节,共两个字节,所以这个值就是2.此时就能说明Length这个属性是存储在两个字节长度里面的,读取这两个字节的存储的值就能读取到length的值。
lengthAdjustment:1 表示length属性和实际数据属性之间的间隔长度,可能不挨着,中间跳过多少, 目前我们这个例子的length的位置和实际数据之间不是挨着的,中间间隔着一个存储0XFE的head2的东西,其长度为1字节,因为FE每两个内容是一个字节。所以这个表示了length和实际数据的距离也就是1。这个参数的目的是为了当Length和数据不挨着的时候,能明确跳过多长找到实际数据的位置,因为Length是表示实际数据的长度的,你得在通过lengthFieldOffset的偏移在读到length的时候还能找到实际数据。
initialBytesToStrip:3 这个参数表示最终获取消息要不要去除头部的长度,去除剥离多少个长度?这里设置为3,所以我们在最后接收要剥离掉三个字节的长度,三个字节就是head1 length这两个部分的内容,最后就剩head2和实际数据了。
所以此时客户端封装完这个消息之后,数据大小其实是17字节,因为head1占了两个字节,存储length占了三个字节,实际数据消息占了十二个字节。
而服务端收到之后,他是如何读取呢?
基于这个控制之下,我们其实就能完整的处理这个消息,我们来看一下是不是能做到控制消息了:
服务端收到之后,读取这四个参数发现,lengthFieldOffset为1,length发生偏移,跳过一个字节
就是length的位置进行读取length属性,那么读取多少个长度呢,第二个参数lengthFieldLength为2,表示length信息在消息占了2个字节,那就读取2个字节的内容,发现是0X000C,0X0000C表示的值是12,于是发现Length的值是12,此时他就知道实际内容长度是12字节。
但是此时lengthAdjustment:1,他表示length和数据存在距离为1,所以他要跳过1字节的长度去读取真实的数据,跳过1字节往后读12个字节就得到了"HELLO, WORLD"真实内容。
后面initialBytesToStrip:3 需要剥离头部,去掉消息的前面三个字节,所以最后拿到的就是head2 还有实际数据。
此时我们看到这四个属性完成了对于消息的完整的获取,他通过设置一些额外的标识来界定消息的位置,从而实现解析的结果完整和正确。
- 所以经过了五个例子,我们再来回顾这几个属性看一下

maxFrameLength - 消息帧的最大长度。如果消息帧的长度大于此值,将产生 TooLongFrameException 异常。
lengthFieldOffset - 偏移多少才能找到Length字段属性?如果Length字段属性顶头存写,那么该值为0
lengthFieldLength - Length字段属性的长度为多少,字节为单位
lengthAdjustment - Length字段属性和真实的长度数据值之间相隔多少字节数?
initialBytesToStrip - 客户端传输给服务端的消息数据,最终要进行跳过舍弃掉多少字节数?该属性一般用在舍弃头部的数据所使用。
----》橘子哥笔记:
maxFrameLength: 这个不说了,最大长度,超出则抛出异常。
the maximum length of the frame. If the length of the frame is greater than
this value, {@link TooLongFrameException} will be thrown.
lengthFieldOffset:length这个属性在消息中的偏移量。他的意义是不管消息多复杂,让你在消息中找到length属性,因为这个属性是表示实际内容的长度的只有找到这个长度才能知道实际内容占多大,然后进行读取。
the offset of the length field
lengthFieldLength:length这个属性在消息中的长度。length表示的是实际内容的长度,可能是
100,lengthFieldLength这个属性是表示这个100存储的字节长度,读取这个字节长度的内容就能得到这个值,解析出来这个100,而不是说lengthFieldLength这个属性为100.而是存储100占得长度。
the length of the length field
lengthAdjustment:length和数据之间的间隔长度,length属性可能和你的实际内容在整个消息中不挨着,这个属性用来告诉你跳跃多少找到内容。
the compensation value to add to the value of the length field
initialBytesToStrip:剥离消息头部信息的长度,有的时候我们不需要获取的部分,和我们业务无关,那我们可以选择剥离掉,那你会说为啥不需要的还放消息里面呢,你不放我不就不管了吗,你以为消息只给你一个人发啊?
the number of first bytes to strip out from the decoded frame
其实他也是要约定的,双方约定好,然后在代码中设置好你的四个属性,然后对端的服务端拿到netty这
个解码器就能针对你的属性给你剥离也好,解析也罢得到符合你业务的结果。其中最重要的就是length
和实际数据部分。
21.4.4.6 代码实操 【头体分离+帧解码器完美解决,最常用,最好用的解决半包粘包问题的方法】
- 客户端
package com.messi.netty_core_02.netty07;
import io.netty.bootstrap.Bootstrap;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.channel.Channel;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.ChannelPipeline;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.string.StringEncoder;
import io.netty.handler.logging.LoggingHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.net.InetSocketAddress;
public class LengthFieldClient {
private static final Logger log = LoggerFactory.getLogger(LengthFieldClient.class);
public static void main(String[] args) throws InterruptedException {
Channel channel = null;
ByteBuf byteBuf = null;
NioEventLoopGroup group = null;
try {
group = new NioEventLoopGroup();
Bootstrap bootstrap = new Bootstrap();
bootstrap.channel(NioSocketChannel.class);
bootstrap.group(group);
bootstrap.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LoggingHandler());
pipeline.addLast(new StringEncoder());
}
});
channel = bootstrap.connect(new InetSocketAddress(8000)).sync().channel();
String msg1 = "hello xxxx";
String msg2 = "hi xxxx";
//创建一个消息数据
byteBuf = ByteBufAllocator.DEFAULT.buffer();
/**
* 创建一个消息,其结构为:
* 第一部分写入一个int类型,其中int类型本身就是占用4字节的长度,这里存储的就是Length字段属性,存储的就是实际真实数据的长度
* 第二部分写入一个头,可以理解为我们之前作图时画出的head1或head2使用byte写入,占用1字节,写入的内容为1
* 第三部分写入真实数据的内容,也就是msg1字符串
*/
byteBuf.writeInt(msg1.length());
byteBuf.writeByte(1);
byteBuf.writeBytes(msg1.getBytes());
/**
* 创建第二个消息,其结构为:
* 第一部分写入一个int类型,其中int类型本身就是占用4字节的长度,这里存储的就是Length字段属性,存储的就是实际真实数据的长度
* 第二部分写入一个byte类型,写入一个头,相当于是之前作图时画出的head1或head2.使用byte写入,占用1字节,写入的内容为2
* 第三部分写入真实的数据的内容,也就是msg2字符串
*/
byteBuf.writeInt(msg2.length());
byteBuf.writeByte(2);
byteBuf.writeBytes(msg2.getBytes());
channel.writeAndFlush(byteBuf);
} catch (InterruptedException e) {
log.info("exception is {}", e.getMessage());
} finally {
group.shutdownGracefully();
}
}
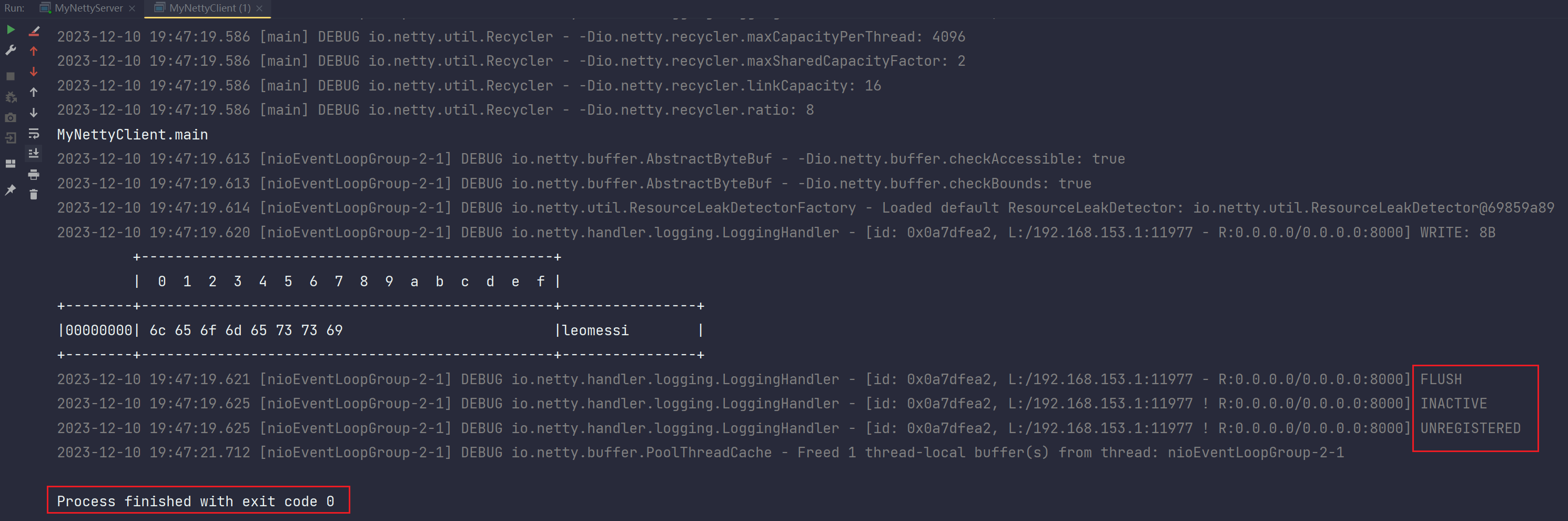
}客户端发出的消息数据,结构如下:

lengthFieldOffset:0,因为length的位置就是在每个消息的顶格,没有偏移
lengthFieldLength::4,length写入用的writeint,每个Int占用四字节长度,所以存储length值的
长度是4字节
lengthAdjustment,1,length属性在消息中和实际数据的距离之间隔着一个head,长度是用writebyte写入的,是1个字节,所以这个属性值为1
initialBytesToStrip,0,我们先不剥离,所以这里设置为0
有了这四个属性,那么服务端代码就呼之欲出了。
但是在我们使用这四个属性之前先看看没有解码器会发生什么,
- 不做处理的服务端
package com.messi.netty_core_02.netty07;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.LengthFieldBasedFrameDecoder;
import io.netty.handler.logging.LoggingHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class LengthFieldServer {
private static final Logger log = LoggerFactory.getLogger(LengthFieldServer.class);
public static void main(String[] args) {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.group(new NioEventLoopGroup(1),new NioEventLoopGroup(8));
DefaultEventLoopGroup defaultEventLoopGroup = new DefaultEventLoopGroup();
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LoggingHandler());
pipeline.addLast(defaultEventLoopGroup,"handler1",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.info("msg:{}",msg);
super.channelRead(ctx, msg);
}
});
}
});
serverBootstrap.bind(8000);
}
}
运行结果:
客户端:
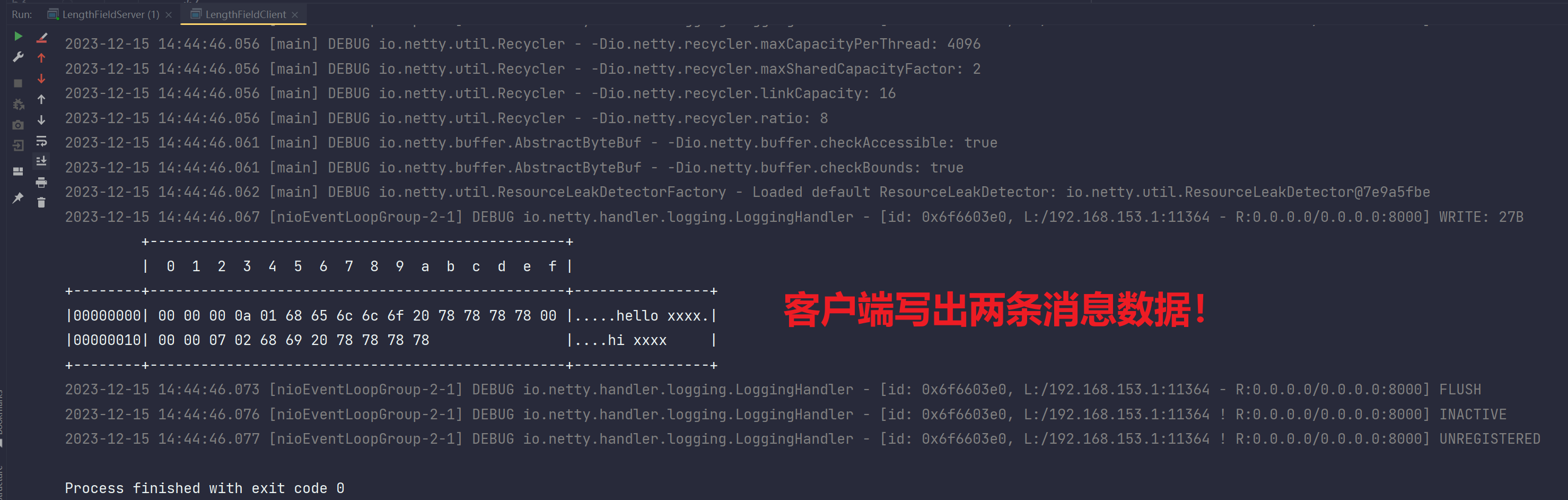
服务端:

- 加入帧解码器的服务端
package com.messi.netty_core_02.netty07;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.LengthFieldBasedFrameDecoder;
import io.netty.handler.logging.LoggingHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class LengthFieldServer {
private static final Logger log = LoggerFactory.getLogger(LengthFieldServer.class);
public static void main(String[] args) {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.group(new NioEventLoopGroup(1),new NioEventLoopGroup(8));
DefaultEventLoopGroup defaultEventLoopGroup = new DefaultEventLoopGroup();
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LengthFieldBasedFrameDecoder(1024,0,4,1,0));
pipeline.addLast(new LoggingHandler());
pipeline.addLast(defaultEventLoopGroup,"handler1",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.info("msg:{}",msg);
super.channelRead(ctx, msg);
}
});
}
});
serverBootstrap.bind(8000);
}
}再看运行结果:
客户端输出:
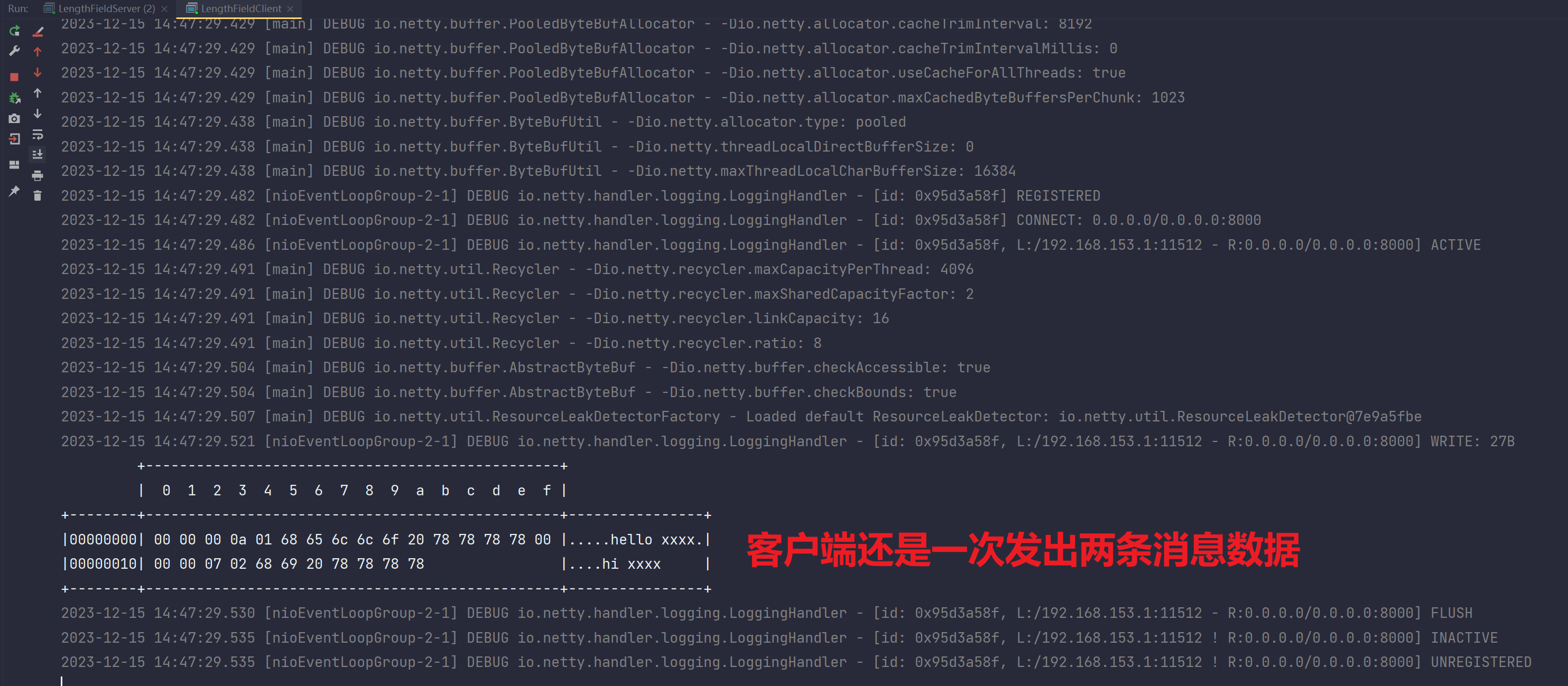
服务端输出:
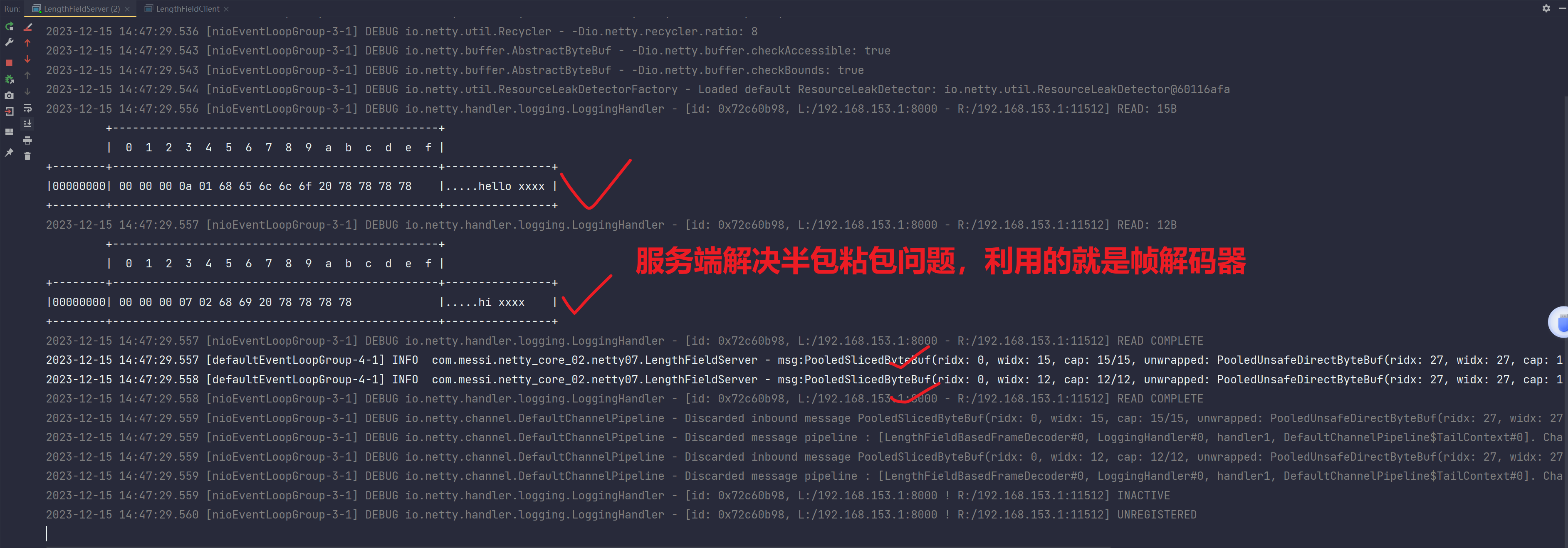
总结:
从Socket缓冲区中读取出数据到ByteBuf,其实当我们拿到的ByteBuf应用层缓冲区中的数据依旧是存在半包粘包问题的,但是我们使用帧解码器就是为了解决ByteBuf的半包粘包,保证最终解码出的消息数据是无半包粘包问题的:
![前沿重器[42] | self-RAG-大模型决策的典型案例探究](https://img-blog.csdnimg.cn/img_convert/9180d10a66419327b603b4f547c0f20e.png)



![[ai笔记3] ai春晚观后感-谈谈ai与艺术](https://img-blog.csdnimg.cn/img_convert/3f79d9ca4a9b800a1dfa88c5a5190ac6.png)