前沿重器
栏目主要给大家分享各种大厂、顶会的论文和分享,从中抽取关键精华的部分和大家分享,和大家一起把握前沿技术。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。(算起来,专项启动已经是20年的事了!)
2023年文章合集发布了!在这里:又添十万字-CS的陋室2023年文章合集来袭
往期回顾
前沿重器[37] | 大模型对任务型对话的作用研究
前沿重器[38] | 微软新文query2doc:用大模型做query检索拓展
前沿重器[39] | 对话式推荐系统——概念和技术点
前沿重器[40] | 高级RAG技术——博客阅读
前沿重器[41] | 综述-面向大模型的检索增强生成(RAG)
在上一期(前沿重器[41] | 综述-面向大模型的检索增强生成(RAG))提到的综述文章中,有提到一篇比较有意思的论文——self-RAG,个人感觉这篇论文除了RAG本身,还有就是在大模型做系统内部决策这块,都具有很大的参考意义,因此今天我打算重点讨论一下这篇论文。
材料列表:
论文:https://arxiv.org/abs/2310.11511
讲解:https://zhuanlan.zhihu.com/p/662654185
翻译:https://zhuanlan.zhihu.com/p/663814320
文章中可能会涉及一些对RAG的基本概念,此处不再赘述,大家具体可以看我以前RAG的文章补充一下。
前沿重器[40] | 高级RAG技术——博客阅读
心法利器[104] | 基础RAG-向量检索模块(含代码)
心法利器[105] 基础RAG-大模型和中控模块代码(含代码)
心法利器[106] 基础RAG-调优方案
前沿重器[41] | 综述-面向大模型的检索增强生成(RAG)
整体方案框架
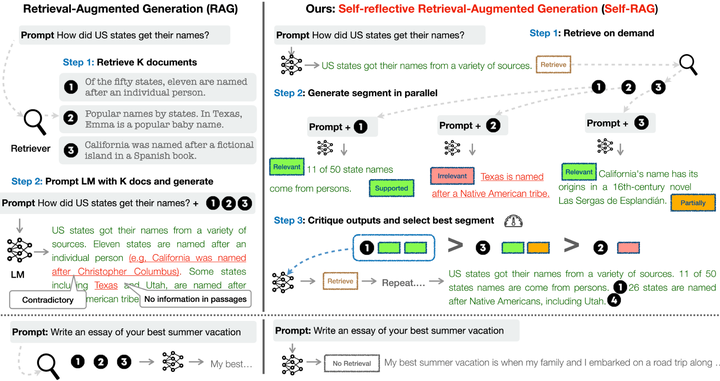
如图所示,左边是普通RAG的操作方法,先对query进行检索,然后把检索结果TOP N和原始query一起放入大模型,让大模型输出结果,而右边,作者训练了模型,用于判断query和检索到的模型之间的关系,判断是都需要进一步检索以及本身回复的质量。
本文中,作者把这种分析文章质量与进一步检索称为RAG系统对自身的反思(critique,虽说直译是评论,但我自己感觉翻译为反思更合适)。
相比一般的RAG,这里本质上其实是多做了四个判断:
此刻是否进行检索,输入为query或query以及回复y,输出为是、否以及继续。(Retrieve标签)
文档是否和query有关,输入为query和文档d,输出为相关和不相关。(IsREL标签)
文档是否足够支持回答query,输入为query、文档d和回复y,输出为完全支持、部分支持和不支持。(IsSUP标签)
回复是否有效,输入为query以及回复y,输出为1-5共5个档位。(IsUSE标签)
流程上,是这样的:

这里,作者用Retrieve标签判断是否还需要进行检索,如果是不需要检索了则会输出最终的返回结果,其他三个标签,则用于doc以及最终可能的输出的的排序。
这里提一个小问题,在这里是什么含义,输入没提及,而且和M也不一样,这个在全文里我也没找到提示。
有了这个框架和流程,实际上我们关心的就是这几点:
检索使用的是什么方法。
这个生成模型M是如何构造和生成的。
标签如何产生作用的,其中retrieve标签在上面的流程图里还挺明显的,但是另外3个怎么用还不明确)。
回答了这3个问题,这篇论文里的方法就算理解清楚了。
具体方案细节
检索方案
检索方案本身不是论文的主要创新点,因此找一个用作baseline即可,作者用的是Contriever-MS MARCO,没记错是21年的论文(https://arxiv.org/abs/2112.09118),后续22年是v4更新,其本质是一种基于对比学习的训练方法,和同期的simcse有些类似,此处不赘述。
个人感觉其实可以选更新的模型,亦或者是提供一下有关这块的准确率之类的数据,验证或者讨论检索这块本身占实际问题的占比,然后分析self-RAG这块对这方面的优化的情况,这样可以进一步明确self-RAG的收益,甚至是可以对比经过self-RAG筛选前后的结果对大模型输出的影响,毕竟我们根据经验其实会发现,即使检索模块结果是相关的,文档交给大模型了,大模型仍旧有不小的概率会出错,通过这个,可能可以探索出检索正确和大模型预测正确之间的这个gap的具象化表现。
模型训练
此处需要训练的模型有两个,一个是单独用于进行标签预测的评论模型C(直译是批评,但感觉更像是评论模型),另一个是生成模型M。
首先是评论模型模型C,它本身并不在推理流程里,他本身是用于进行离线的标签生成,最终要服务于生成模型M的训练。评论模型这块,我把全文里有关这方面的重点进行了梳理(主要是方法、实验、附录里都有):
首先,大体思路上,使用用GPT4配合prompt生成数据,然后进行训练,标签预测模型的选择进行过少量实验,选的是Llama2-7B。
标签分类本身就是分类任务,但是使用的生成模型的方式来处理的,而分类本身是有概率的,这个概率的计算就是用各个类的token对应的概率做归一化来作为分类的概率,这个分类概率无论是用作损失还是用作预测都是这么用的,此时训练使用中可以使用最简单的LM语言模型的损失函数——极大似然估计(说白了就是MLM任务),即判断对应token的概率即可,这个我在前面的文章里有提及这个的具体操作手法和代码(前沿重器[33] | 试了试简单的prompt)。
有一个我挺好奇的点,我在文中没有找到,如果有小伙伴找到了欢迎补充——这4个标签具体用的4个模型还是1个(根据符号推测评论模型C没有角标,所以是1个模型,但不确定)。
我相信有挺多人关注这个标签预测的准确率的,我自己也觉得有一定的分析空间,在这里:

我自己的分析:
首先,这里只是用了两个基座模型进行对比,结果发现Llama2-7b遥遥领先,但感觉对比有点少。
对不同的标签,效果差异挺大的,前面2个还不错(虽然isSup标签在FLAN上效果很差),后面两个标签的准确率不算高。
说白了这个标签预测的效果,我个人觉得只能算差强人意,但这种质量的中间变量结果就能让端到端带来提升,这个确实没想到。
第一点好奇,用FLAN这个比较差的效果来做self-RAG的推理,效果会损失多少,换个说法,标签预测错误对整体结果的敏感性,不太了解。
第二点好奇,因为本身是分类任务,虽然是相对复杂的句子对分类,但在数据默认比较充足的情况下为什么不考虑直接尝试用分类的方法来做,例如bert之类的,虽然直观感觉因为缺少世界知识,我对bert这个级别的模型效果不报很高期待,但还是挺想知道这类型问题在小模型上的效果和用7B模型的差异。
有了评论模型的预测结果,就可以训练生成器M了,这里的生成器M,本质上是有两个任务:
预测评价标签,即Retrieve/IsREL/IsSUP/IsUSE。
预测生成结果。
有关生成器M的训练,样本的生成如下(这里又莫名出现了)。

可以看到,评价模型C的作用就是辅助生成样本,生成样本后,用于训练M。关键点梳理:
相比评价模型C,M的训练用的是next token预测的损失函数。
推理上M既要用于标签的预测,也要用于最终的回复生成的预测。
标签的作用和推理
有了标签,我们就可以开始推理了。
首先,此处作者提出的是一个自适应的方式,该自适应方式能提供更灵活的调节方案,以进行更高程度的可控性,技能应对知识检索类似比较严格的场景,也能应对一些类似个人经验文章的创新性场景。这个自适应性本质其实是阈值的控制,这点是论文有提及的比较重点的部分,融入在本方案里。
根据前文提及的标签预测,每个标签都会有对应概率,这个概率就能够用于进行阈值计算,如果retrieve标签超过阈值,则会进行进一步的检索,否则就不进行检索。
然后就是算分的过程,对检索出来的每个结果,都会进行算分,如下:
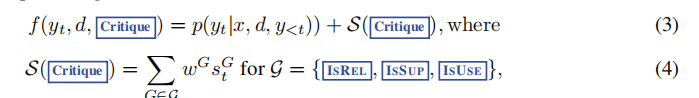
这里的是指每个标签的概率了,而这里的权重则是超参可以进行灵活调整。
另外,对于这个的计算,即每个标签的得分计算,在附录里面也有更详细的解释:

一些补充讨论
这篇文章虽然方案本身具有比较强的参考价值,其内核以及一些细节还有很多值得探讨的地方,这里有比较有参考价值的发现,也有值得我们进一步思考和研究的点。叠甲,这里并非指出论文的错误,而是基于现有论文的一些思路延伸,也有可能作者讨论到了但是我并未找到,这个就是我的问题了。
评论者相比强化学习的关系。self-RAG一定程度的本质,是在整个RAG过程中,引入了一个“评论者”来帮忙决策答案内容的评价,这点和强化学习中的“奖励模型”有异曲同工之妙,只不过这个奖励模型仅在训练阶段使用,而并非推理阶段,这两者的差别在作者看来,“评论者”更倾向于下游的控制,灵活性会更高,但RLHF这种模式其实更能贴合人类的预期,这应该是功能上或者是主观上的对比。至于端到端的效果,亦或者两者结合的效果,作者倒是没有做直接对比,只是用了开源数据做了一个指令微调,这点应该还有进一步实验的空间。
评论模型的模型方案选择。最开始其实我并不能理解为什么作者会使用大模型作为标签预测的基础模型,但在对问题的逐步了解,也能够明白,有关“IsREL标签”之类的标签,背后很大程度依赖“世界知识”,例如问题和query的匹配,这个问题抽象出来其实就是一个不对称的句子对分类问题,这个任务固然小模型也能做,但小模型一般只能学习到训练数据相关的“知识”,而并非推理的相关本身,且对没学到的,依旧是不会,因此使用大模型作为基础模型是合理的。但话锋一转,尽管我们有预期,小模型效果可能一般,但从实验角度,小模型差多少,是否就不可用,这里是一个值得探索的问题,另一个角度,用更大的模型,是否还有收益,我们不得而知。
不同的评论模型对最终self-RAG效果的影响。有留意到评论模型在IsREL标签和IsUSE标签的效果都不是很好(80.2/73.5),但仍旧能在后面带来不小的收益,那么,这个步骤的效果好坏,对最终效果的影响大小,在进一步的优化中,我们是否有需要关注这块的效果,是否需要调优,这块的灵敏度分析应该是挺有必要的。注意这个问题和上面问题的差异,上面一段聊的是大小模型对评价模型本身任务的效果的影响,这一段是不同评价模型及其效果对最终端到端的self-RAG的影响,两者有较大差别
标签的设计问题。在这里,作者设计了4个标签,除了retrieve标签外,另外3个标签都具有一定的相似性,然而为什么要拆成3个,以及还是否需要拆,这个可能是有一定技巧的,灵敏度分析里只分析了IsUSE标签是否删除下的波动,结果是差异不大,但是其他3个倒是没有讨论,再扣得细小一些,这里用的self-RAG的数据似乎和上面大表的数据好像不太一致,不知道是不是我自己没看清,有一些奇怪。
小结
在RAG系统中,self-RAG在内部引入了决策模块(论文里是叫评价模型),用于对是否检索进行决策以及对检索结果进行评价,从而提升了RAG的整体效果。这个思想对我而言还是有很大启发的,而其中还有很多细节还有待进一步研究和尝试。




![[ai笔记3] ai春晚观后感-谈谈ai与艺术](https://img-blog.csdnimg.cn/img_convert/3f79d9ca4a9b800a1dfa88c5a5190ac6.png)