监督学习(Supervised Learning)监督学习是一种学习方式,其中模型从标记的训练数据中学习。这意味着每个训练样本都是由输入向量和相应的目标输出(也称为标签)组成的。模型的任务是学习输入到输出的映射函数,以便当提供新的、未见过的数据时,模型能够预测出正确的输出。
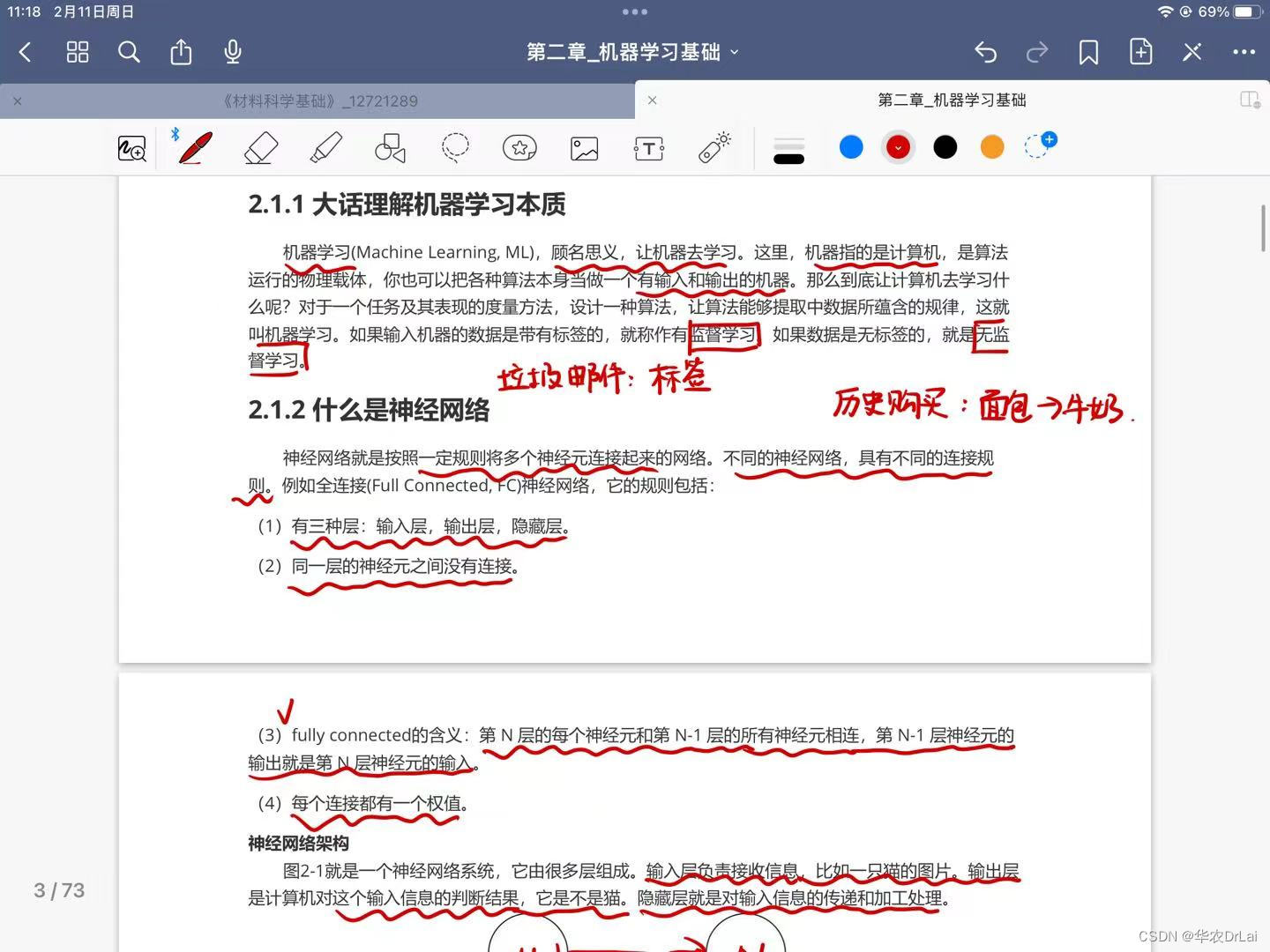
例子:邮件分类:根据邮件内容将邮件自动分类为“垃圾邮件或“非垃圾邮件”。这里,邮件内容是输入,而“垃圾邮件“或“非垃圾邮件”的非监督学习(Unsupervised Learning)非监督学习是一种学习方式,其中模型只通过输入数据来学习,而没有相应的输出标签。
非监督学习的目标通常是发现数据中的隐藏结构、模式或知识。这种学习方式常用于聚类、降维和关联规则学习等任务。
例子:客户细分:根据顾客的购买历史、浏览习惯等信息,将顾客分成不同的群体或细分市场。这里,模型需要自行发现顾客之间的相似性和差异性